
Abstract
Objective
This study aims to leverage annotated textual data from a Massive Open Online Course (MOOC) platform to conduct sentiment analysis of learners’ interactions with nature-based digital interventions, which seeks to enhance sentiment classification and provide insights into learners’ affective experiences, ultimately facilitating timely psychological interventions and improving curriculum design.
Methods
This study leverages the extensive corpus of annotated textual data available on a MOOC platform, encompassing learners’ assessments, inquiries, and recommendations. By performing meticulous sentiment analysis, we aim to understand the subjective sentiments of learners engaging with nature-based digital interventions. To achieve this, we integrate a Bidirectional Long Short-Term Memory (BiLSTM) network with a Conditional Random Field (CRF). The BiLSTM captures word associations in both forward and backward directions, feeding these results into the CRF network to establish the conditional distribution between the feature function and labels. This ensures high-quality feature extraction, precise label assignment, and the derivation of evaluation metrics. Furthermore, adversarial training is introduced to enhance aspect sentiment classification. This involves incorporating perturbations in the embedding space, generating adversarial samples at the embedding layer and semantic feature fusion layer, and combining these with the original samples for model training.
Results
Experimental outcomes demonstrate that the proposed model achieves precision, recall, and F1 scores of 83.71, 85.66, and 84.67 on the SemEval-2014 dataset, and 80.63, 83.06, and 81.76 on the Coursera dataset.
Conclusion
Notably, the sentiment prediction efficacy surpasses that of comparative models, underscoring the proficiency of the proposed scheme. By harnessing the proposed model, educators and administrators can effectively sift through learners’ affective information, facilitating timely psychological interventions and curriculum guidance. This study contributes to the growing body of research on digital mental health interventions within natural settings, providing valuable insights into how technology can support and enhance mental well-being in these contexts.
Keywords
Introduction
Amidst the evolving intersection of natural environments and digital technology, the pedagogical approach to online courses is undergoing profound development. Natural environment refers to virtual or imagery-based representations of nature integrated within digital platforms to enhance the learning experience and foster mental well-being. Particularly in the post-epidemic era, online courses have solidified their position as an indispensable cornerstone of mainstream learning resources. Students engage in autonomous learning through the resources offered by online education platforms, which are now increasingly incorporating elements of natural environments to enhance the learning experience. For instance, online platforms such as Catechism and various video services provide high-quality educational content, while also integrating natural imagery and virtual environments to promote a calming and immersive learning atmosphere.1,2
Despite these advancements, the spatial and temporal separation between teachers and students, compounded by internal and external factors, hampers the effective transfer of knowledge. Students facing academic pressures seek supplementary resources for post-school learning. While a plethora of educational platforms ostensibly caters to diverse learner needs, the abundance of resources can obscure the advantages and limitations of each option, leading to missed opportunities for selecting the most suitable courses. This issue is exacerbated by the lack of a tangible teaching presence in online courses, where learners must rely solely on information provided by the education platform. Paradoxically, these platforms accumulate vast amounts of user data through mass open access, including textual information from pop-ups, course comments, and user-generated content. This data not only reflects learners’ cognitive, behavioral, and emotional states but also offers latent insights for educators and platforms to refine their offerings. 3
In this context, integrating natural environmental elements into online courses could play a crucial role in addressing these challenges. However, the current educational platforms often neglect the significance of the comment section, allowing it to become cluttered with advertising and spam. This oversight not only diminishes learner loyalty but also complicates the process for subsequent learners to make informed decisions. Correctly discerning sentiment from online course reviews remains challenging, highlighting the need for advanced algorithms to accurately predict and analyze user feedback. The integrated learning algorithm, capable of intense learning through algorithmic weighting, presents a significant advantage in exploring educational big data. By consolidating weak classifications into robust classifiers, it effectively adapts to the diverse scenarios within educational big data.4–7
Learners generate substantial behavioral information during online courses, including both unstructured text data (e.g. course reviews and forum discussions) and structured data (e.g. performance in online tests).8,9 Within these datasets lie valuable emotional insights that can greatly enhance the understanding of course quality and effectiveness. This research focuses on assessing course quality through online reviews, aiming to help learners find suitable courses and assist platforms in optimizing their offerings. By incorporating natural elements into online learning environments and leveraging advanced sentiment analysis, this study seeks to provide a more nuanced understanding of user emotions and improve the overall educational experience.
This paper presents a comprehensive framework for sentiment analysis in nature-based digital interventions, leveraging a BiLSTM-CRF model with adversarial training. The second section outlines the methodology, detailing model architecture and data preparation steps. The third section discusses the experiments and results, highlighting the effectiveness of the proposed model compared to baseline approaches. Finally, the fourth section provides a discussion on the implications of the findings, and the fifth section concludes with potential future research directions.
Related works
Sentiment propensity analysis encompasses a variety of methodologies, including sentiment lexicon-based techniques and those leveraging various algorithmic approaches. Each of these methods can be effectively integrated with natural environmental data, enhancing my understanding of public sentiment toward environmental issues and conservation efforts.
Sentiment lexicon-based analysis utilizes a sentiment lexicon to calculate sentiment intensity and categorize the sentiment of a text. 10 A suitable sentiment dictionary must include annotations for sentiment polarity and intensity. Notable dictionaries include the WordNet dictionary, 11 the General Inquirer Lexicon, 12 the KnowledgeNet Hownet dictionary, 13 and NTUSD from National Taiwan University. 13 While this method is computationally efficient and does not require annotated training samples, its accuracy heavily relies on the quality of the lexicon. Therefore, constructing domain-specific lexicons—particularly for environmental topics—is often essential for precise classification. For example, Gandhi et al. 14 introduced mutual information to calculate sentiment values in environmental reviews, while Gaikwad et al. 15 emphasized the varying contributions of different words in determining sentiment tendencies. Tian et al. 16 created a large-scale MOOC sentiment lexicon, enhancing sentiment classification for online teaching review data, which can be adapted to environmental education contexts.
Various algorithmic approaches further enrich sentiment analysis. Techniques such as Naive Bayes and Support Vector Machine are commonly employed to classify texts by constructing models based on known sentiment. 17 While effective in determining emotional tendencies, these methods do not quantify emotional intensity. Despite this limitation, their high classification accuracy and versatility make them widely used. For instance, Esfandiar et al. 18 applied different models to analyze tourist review data, which could also be extended to assess sentiment toward natural parks. Cindo et al. 19 achieved over 85% accuracy in analyzing news sentiment, providing insights into public sentiment regarding environmental policies. Comparative studies have revealed performance variations among different algorithmic techniques, guiding researchers in selecting suitable approaches based on dataset characteristics and analysis goals. 20
In recent years, advanced techniques have also emerged that leverage deep learning for sentiment analysis. For instance, Sharaf et al. 21 employed convolutional neural networks combined with attention mechanisms, eliminating reliance on lexicons. Shoryu et al. 22 demonstrated the effectiveness of recurrent neural networks, particularly with Word2vec and LSTM optimization, on microblog comment data. Georg 23 and Aoumeur 24 highlighted the advantages of Doc2vec over Word2vec in sentiment analysis. Additionally, feature extraction plays a crucial role; for example, Singhania 25 proposed a Replicated Softmax model to enhance categorization accuracy, while Akhtar et al. 26 explored multi-task learning environments for determining sentiment polarity.
Despite these advancements, there is a notable lack of standardized procedures for collecting and analyzing educational big data, particularly in integrating natural environment elements into digital learning platforms. This gap constrains research depth and complicates effective data mining. As educational platforms increasingly incorporate natural elements to enrich learning experiences, research often focuses narrowly on sentiment classification in course reviews, overlooking the nuanced information embedded in these reviews. Current classification techniques frequently require manual text annotation, leading to challenges such as reduced accuracy, inefficient data processing, and substantial resource demands. Addressing these challenges necessitates advanced, automated methods to improve sentiment analysis accuracy and efficiently manage the complex data associated with educational platforms enriched by natural elements.
Methodology
Figure 1 illustrates the detailed methodology for the sentiment analysis framework leveraging BiLSTM-CRF with adversarial training. 27 The process begins with Input Data, which includes reviews, comments, and feedback from MOOC platforms and the SemEval dataset. The data undergoes Data Cleaning, where noise, spam, and advertisements are filtered, and the text is normalized.

Flowchart of proposed model.
Next, Tokenization splits sentences and segments words using Jieba, followed by Word Embedding utilizing the WoBert model to generate contextual vector representations. The Feature Extraction step employs a BiLSTM network to capture semantic relationships in both forward and backward directions. Subsequently, Semantic Fusion integrates contextual and embedding information to enrich semantic understanding.
The refined data is then passed to the Sequence Annotation module using CRF to assign dependency-based labels. To improve model robustness, Adversarial Sample Creation introduces perturbations in the embedding and semantic fusion layers, which are combined with the original data in the Adversarial Sample Integration stage.
Extraction of opinion target
The proposed approach integrates Bidirectional Long Short-Term Memory (BiLSTM) with Conditional Random Fields (CRF) layers to enhance sequence annotation within the context of incorporating natural environment elements into digital learning platforms. This combination is designed to capture dependencies between words while accounting for the additional complexity introduced by natural elements, such as virtual nature scenes or natural imagery in educational content.
In this approach, the BiLSTM network captures semantic relations within input text sequences, processing data in both forward and backward directions to understand context influenced by natural environment elements. This bidirectional analysis allows the model to recognize how such elements impact the context and sentiment of the text. The output from the BiLSTM layer is then fed into the CRF layer, which refines the sequence predictions by generating probability distributions over tagged sequences. This CRF layer considers dependencies between tags across the entire sequence, improving the accuracy of predictions by incorporating the broader context provided by natural environment features within the educational content. As shown in Figure 2, this network structure enables a comprehensive analysis of text that reflects both semantic content and the influence of natural elements, enhancing the overall effectiveness of sentiment classification and sequence annotation in digital learning environments.

BiLSTM-CRF model structure.
The first layer is the input layer of the model (LOOK-UP layer), which maps each word in a sentence to a word vector using unique thermal encoding. Let
The second layer is the BiLSTM layer, designed to extract evaluation objects from online course reviews.
28
It takes the sentence vector representation, consisting of word vectors processed from the LOOK-UP layer, as input to the bi-directional LSTM for each time step. The hidden state sequences from the positive and negative LSTM outputs are denoted as
The final hidden state sequence output from the BiLSTM layer is given by
The third layer is the CRF layer, primarily used for annotating sentences. The CRF employs a (k + 2) ×(k + 2) transition matrix




Emotions classification
I introduce the concept of Adversarial Training. 29 Initially, WoBert is utilized for the aspect sentiment classification task, and the resulting loss is computed to generate gradients, which are used to create perturbations. These perturbations are introduced to form adversarial samples in both the embedding layer and semantic feature fusion layer. The original samples, along with the adversarial samples, are then input into WoBert for subsequent operations. The WoBert model incorporating adversarial training is denoted as WBAT (Wo Bert-based Adversarial Training). The model structure is illustrated in Figure 3, encompassing the WoBert-based sentiment classification module and the adversarial training module.

WBAT model structure.
WoBert module. Given WoBert's extensive corpus, numerous parameters, and robust word vector representation, it has demonstrated superior performance across various NLP tasks since its introduction. The model's pre-trained capabilities, which capture rich contextual and semantic information, make it highly effective for downstream tasks when fine-tuned. This adaptability is particularly valuable in aspect sentiment classification, where the integration of natural environment elements can enhance contextual understanding.
In aspect sentiment classification tasks, WoBert's pre-trained model is utilized, encompassing several critical components: an input layer, an embedding layer, a semantic feature fusion layer, an encoding layer, a pooling layer, and a classification layer. The input layer processes the text data, while the embedding layer transforms words into dense vectors that capture semantic meanings. The semantic feature fusion layer integrates additional contextual information, potentially including elements related to natural environments, to enrich the model's understanding. The encoding layer further processes these embeddings to capture intricate relationships within the text, followed by the pooling layer, which consolidates features to improve the model's efficiency. Finally, the classification layer assigns sentiment labels based on the processed features, leveraging WoBert's extensive training to deliver accurate and insightful sentiment analysis.
For the aspect sentiment classification task, the total sentence length is set to length = 128, and the word embedding dimension is defined as hidden_size = 768. The operations in this task closely mirror those in the embedding layer, semantic feature fusion layer, and encoding layer of the aspect extraction task. The output of the embedding layer is denoted as
In the input stage, a [CLS] tag is added at the beginning of the sentence. After passing through the encoding layer, this tag contains information about the entire sentence, and during aspectual sentiment polarity analysis, 30 only the information from this tag is utilized. Additionally, based on the lexical labels, Tag Aspect items and aspect words are extracted from the sentence. These are then concatenated after the sentence to form a second sentence, placing emphasis on aspect items and aspect words during the training process. The two sentences are separated by the [SEP] tag in the middle, and an additional [SEP] tag is appended at the end of the second sentence.
In the encoding layer, since the sentiment classification task involves two sentences, it is necessary to assess the distance between the aspect item and the aspect word based on the lexical labels of the two sentences. If the conditions are met, the semantic feature fusion algorithm is executed. In contrast, the aspect extraction task deals with only one sentence, resulting in fewer assessments compared to the aspect sentiment classification task. The pooling layer, not present in the aspect extraction task, is introduced in the aspect sentiment classification task. This layer is responsible for extracting the representation information of [CLS]. Given that [CLS] lacks distinct semantic information, it can be fused with the information of other words as it passes through the encoding layer. Subsequently, it is input into the classification layer for sentiment polarity judgment.
The pooling layer consists of a linear transformation layer and an activation function, using the tanh activation function. The input to the linear transformation layer is the output of the encoding layer, and the output undergoes tanh nonlinear transformation to normalize values between −1 and 1. The formulas used are shown in Equation (5).


Adversarial training module. The essence of adversarial training lies in generating adversarial samples that should not deviate significantly from the original samples while inducing the model to make incorrect judgments. In contrast to the continuous nature of image data in the image domain, the discrete nature of text poses a greater challenge in generating adversarial samples. The prevalent method is to operate at the word vector level. Therefore, in this thesis, adversarial samples are generated at the embedding layer and semantic feature fusion layer. Subsequently, the two adversarial samples are combined to form the overall adversarial sample. The output of the embedding layer is denoted as
In the process of generating adversarial samples, the generation and selection of adversarial perturbations are crucial. We first use loss to generate and select antagonistic samples for


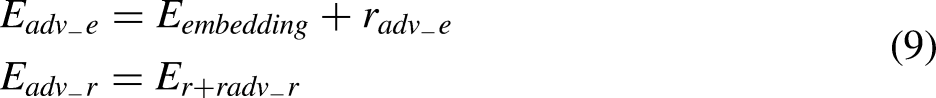
The coding layer encompasses 12 attention layers, each comprising a self-attention module, an intermediate module, and an output module. In the self-attention module, the inputs are the actual length of the sentence and the Mask, representing the actual length of the sentence. If the actual length of the sentence is n, then the first 128-n bits of Mask are set to 1, and the remaining n bits are set to 0. This configuration is designed to assign less weight to the adversarial samples generated for the filled positions in the self-attention calculation. This layer count strikes a balance between ensuring sufficient feature extraction capability and managing computational resources, thereby avoiding issues related to overfitting and training inefficiencies. Additionally, 12 layers have become an empirical standard in processing textual data, widely adopted across multiple tasks and providing reliable performance. Finally, each attention layer focuses on different contextual information, enabling the model to construct higher-level feature representations. This layered feature learning approach enhances the model's robustness against adversarial samples, ultimately improving sentiment classification accuracy.
Following the self-attention module, a new vector representation for each word is obtained, incorporating relationships with other words. The self-attention module concludes with a linear transformation layer, dropout, and layer normalization. The intermediate module comprises a linear transformation layer and the GELU activation function. The output module involves the linear transformation layer, dropout, and layer normalization processes. The output of the previous attention layer is the input of the next attention layer, until all 12 attention layers have been computed, and the output of the coding layer is denoted as
Input
Experiments and analysis
Data sets
The experimental dataset integrates two primary sources: the SemEval-2014 Task 10 31 dataset and student comments from the Coursera online learning platform. 32 Detailed information is shown in Table 1.
Summary of the dataset and its cleansing steps.

The datasets were split into training, validation, and test sets using a 7:2:1 ratio. This ensures that a substantial portion of the data is available for model training while holding out a smaller portion for validation and testing. Removing special characters, URLs, and non-alphanumeric characters standardizes the data. Each piece of text—whether a tweet or a Coursera comment—was labeled as positive, negative, or neutral based on its tone. Advanced sentiment lexicons were used in conjunction with manual annotations to ensure accurate sentiment classification.
Parameter setting
The experimental environment is Windows64 with Python 3.7.3. The backend is built on Keras, a deep-learning framework for TensorFlow, and jieba is utilized for segmentation and lexical annotation. In the model training phase, the optimizer employs adaptive moment estimation. During the testing phase, comment sentences exceeding the maximum length are truncated, and zero padding is applied to shorter sentences. The hidden state dimension of the BiLSTM-CRF is set to 256, and the RMRprop backpropagation algorithm is used for network training, with the learning rate set to 0.001. To mitigate overfitting, a dropout layer is introduced after the Bi-LSTM layer, and the dropout rate is set to 0.5. Due to hardware resource constraints, the batch size cannot be set too large. Smaller values result in slower convergence and longer training times. After several trials, the batch size is ultimately set to eight. In the adversarial training phase, the dropout rate is set to 0.1.
Figure 4 provides visualization results of accuracy and loss for different epochs during the training and validation phases of the model. It is observed that the performance in the training phase improves with an increasing number of epochs, while the performance in the validation phase stabilizes around Epoch 300.
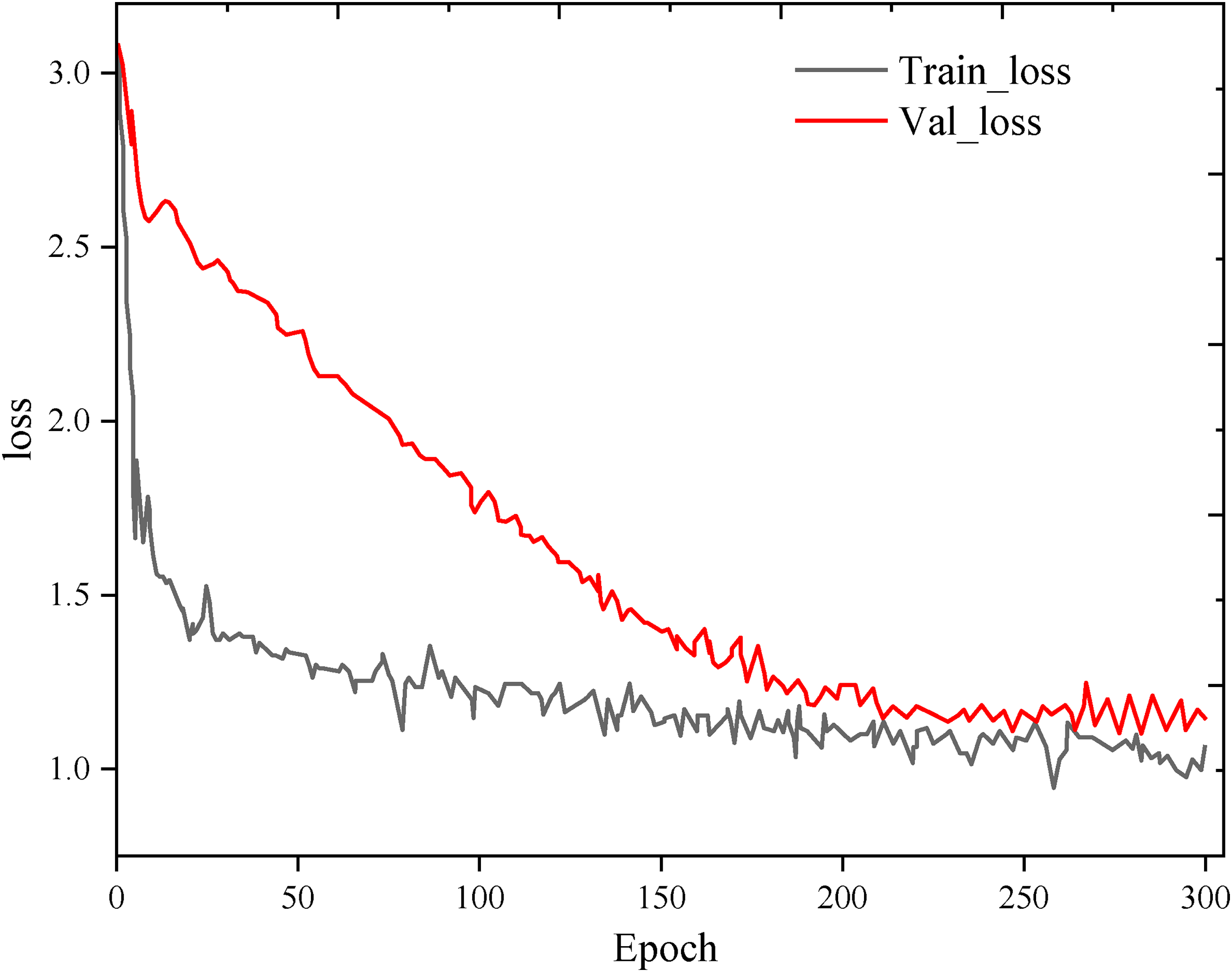
Process of model training.
Evaluation indicators
In the attribute term extraction task, precision (P), recall (R), and F1 score are employed as performance metrics. P represents the percentage of correctly predicted positive samples out of all samples with positive prediction categories. RR denotes the percentage of correctly predicted positive samples out of all actual positive samples. F1 score is the harmonic mean of precision and recall, providing a balanced measure.


Comparison of different models
Ablation experiments are conducted to analyze the performance of the proposed framework and determine the role of each component in attribute item extraction and sentiment analysis. The BiLSTM-CRF-WBAT model is compared with the BiLSTM, LSTM, and CRF models by systematically removing or replacing these models within the proposed framework. The accuracy results for attribute term extraction and sentiment polarity identification on the first two datasets are presented in Figures 5 and 6.

Results of ablation experiments (SemEval-2014 dataset).

Results of ablation experiments (Coursera dataset).
It is evident that the BiLSTM-CRF-WBAT model outperforms other models across all indicators. When using only the CRF model, there is a significant decrease in the R index, highlighting that the remote semantic dependency of text obtained by the BiLSTM model significantly enhances keyword extraction performance. When using only LSTM or Bi-LSTM, capturing the depth semantics of the text results in higher R, but P decreases significantly. This emphasizes that the CRF can effectively capture the dependency between the output labels in the proposed framework, thereby improving overall model accuracy. The BiLSTM-CRF-WBAT model maximizes the utilization of dependencies between text content and tag sequences, leading to a substantial improvement in the F1 score.
In the task of attribute item sentiment polarity recognition, the accuracy of BiLSTM surpasses that of LSTM, demonstrating that considering positive and negative word context relations enhances the interpretation of deeper sentiment tendencies. The proposed model, BiLSTM-CRF-WBAT, achieves the best performance, indicating that the fusion of BiLSTM and CRF models effectively improves output quality through probability distribution optimization. The addition of a semantic feature fusion layer enhances the classification effect of the model, and the introduction of adversarial training further improves the classification effect, with the optimal performance achieved when combined with BiLSTM-CRF.
The impact of combining the semantic feature fusion algorithm with adversarial training is investigated. Adversarial samples are generated separately in the embedding layer and the semantic feature fusion layer. Adversarial training is then conducted by merging these adversarial samples with the original samples in the embedding layer and the original samples in the semantic feature fusion layer. Experiments were conducted with different settings, specifically, with s = 9 and s = 4, and ε=0.1 and ε=5.0. The results obtained are illustrated in Figures 7 and 8. To facilitate comparison with results without combining, only the semantic feature fusion algorithms are presented in the figures.
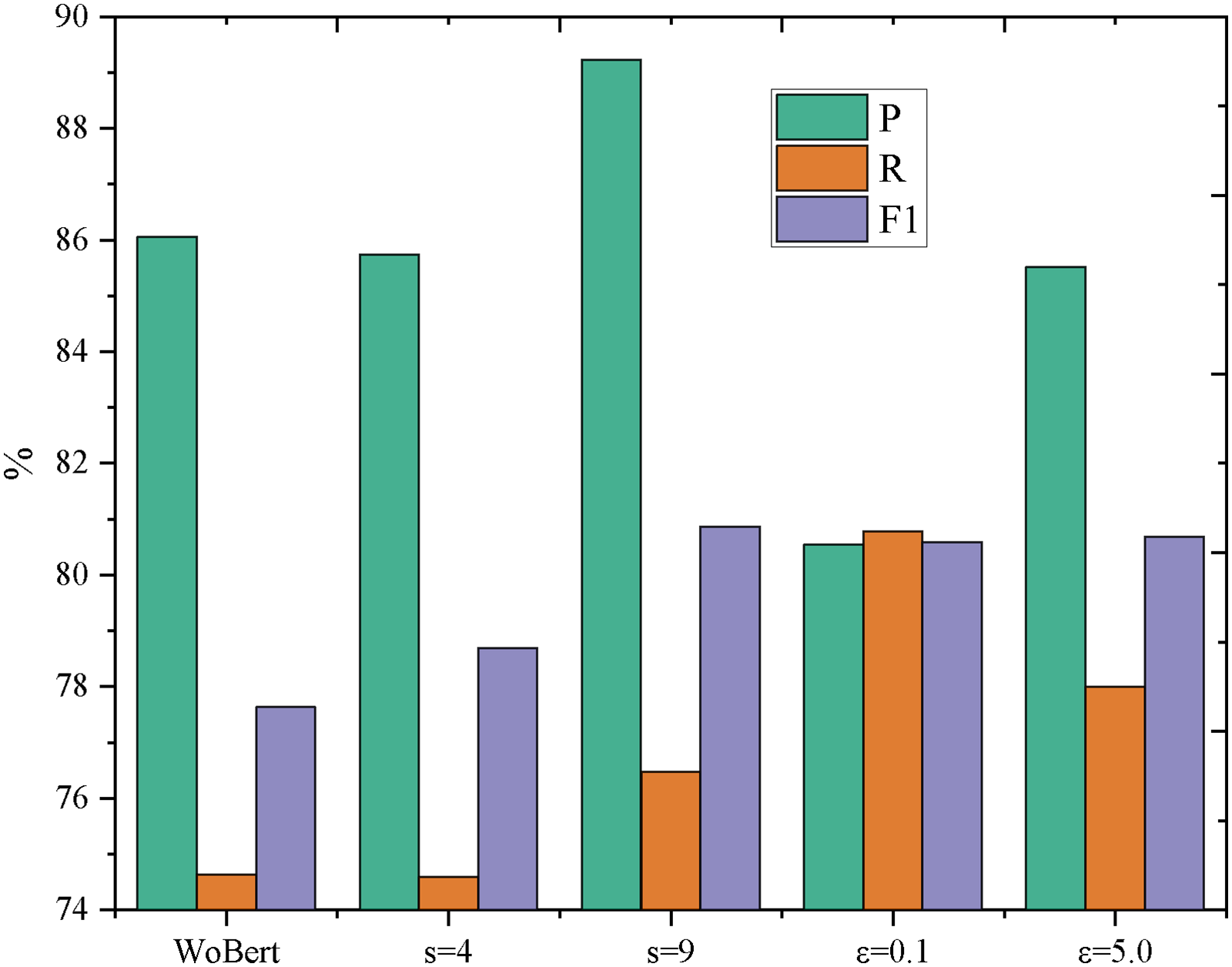
Results of adversarial training (SemEval-2014 dataset).
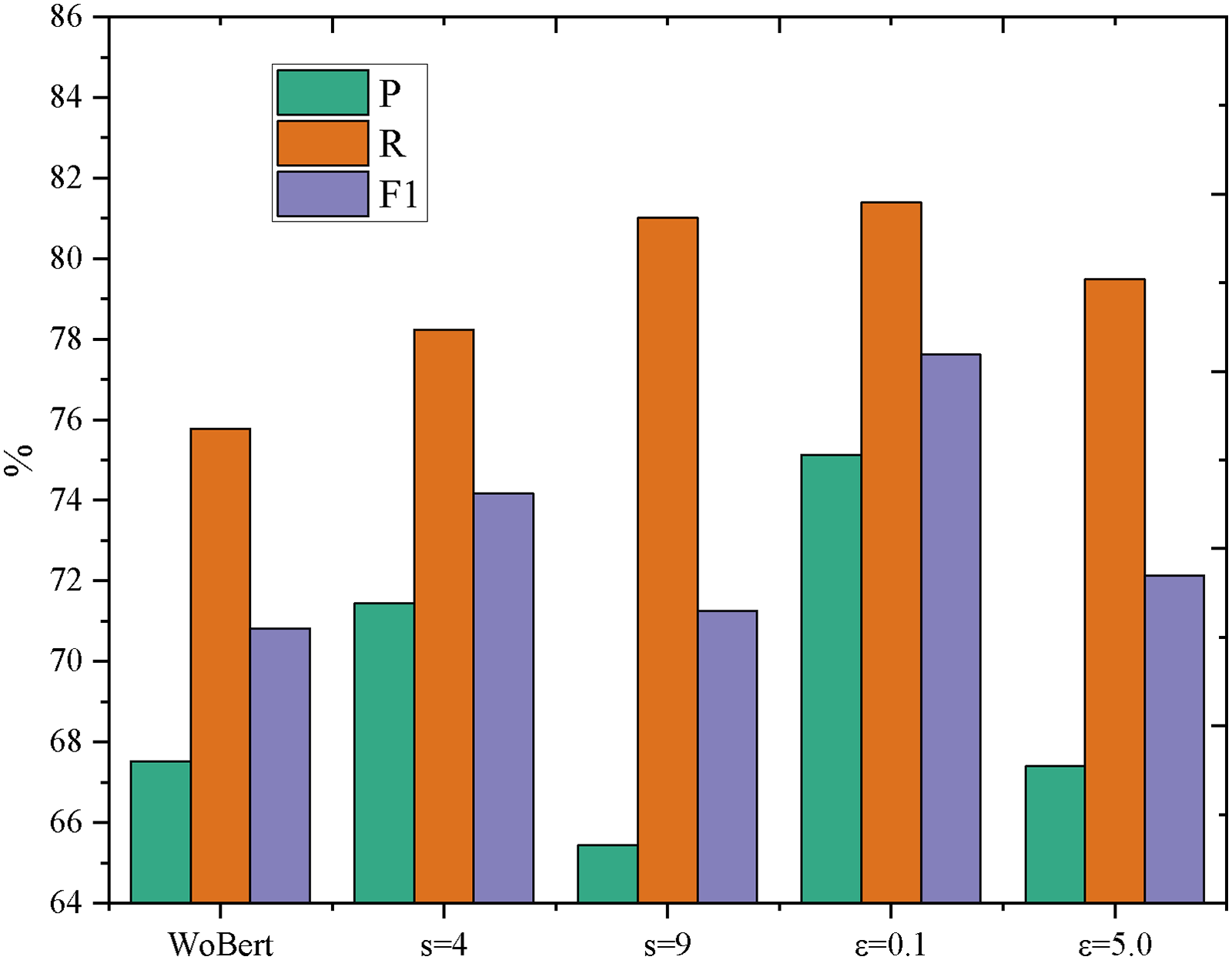
Results of adversarial training (Coursera dataset).
On the SemEval-2014 dataset, the WBAT model with ε=0.1 achieved the highest P, and the WBAT model with s = 9 had the second-highest accuracy. For R, the highest value was obtained by the WBAT model with s = 9 and ε=0.1, while the second-highest value was for the WBAT model with s = 9 and ε=5.0. The F1 score reached the highest value for the WBAT model with s = 9 and the second-highest value for the WBAT model with s = 9 and ε=5.0. On the Coursera dataset, the highest values for P, R, and F1 were all achieved by the WBAT model with s = 4 and ε=0.1. The second-highest values for P and F1 were obtained by the WBAT model with ε=0.1, and the second-highest R value was for the WBAT model with s = 9.
In summary, the model after combining the semantic feature fusion algorithm with adversarial training performed the best, followed by the model containing only adversarial training, then the model containing only the semantic feature fusion algorithm, and the least effective was the model before the improvement.
Additionally, the results were compared with four models: Multi-Generator Attention Network (MGAN), Decision Tree (DT), Convolutional Neural Network-Long Short-term Memory (CNN-LSTM), and eXtreme Gradient Boosting (XGBoost). The comparison results are presented in Figures 9 and 10. MGAN 33 is a generative model designed for processing multimodal data. It excels at capturing correlation information between different modalities using multiple generators and multi-attention mechanisms, making it particularly suitable for multimodal tasks such as multimodal sentiment analysis.

Results of adversarial training (SemEval-2014 dataset).

Results of adversarial training (Coursera dataset).
DT is a supervised learning algorithm based on a tree structure. It makes decisions by conditioning on features and is effective for dealing with structured data and scenarios with fewer features. DTs are commonly used for classification and regression tasks.
CNN-LSTM 34 is a deep-learning model that combines convolutional neural networks with long short-term memory networks. It is widely employed for modeling text sequences.
XGBoost is an integrated learning algorithm within the gradient boosting framework. It is renowned for its efficient gradient boosting, regularization, and feature importance evaluation. XGBoost is commonly used for classification and regression tasks on structured data.
From the results, it is evident that DT performs poorly, which is likely attributed to the adoption of traditional machine learning models for feature extraction and sentiment classification. The CNN-LSTM architecture, despite incorporating word-embedding model training in data preprocessing, lacks sufficient understanding of context and complex semantics when extracting fine-grained attribute items, leading to unsatisfactory training results.
In contrast, the proposed method achieved the best performance. The BiLSTM model, coupled with the CRF model, accurately learns the relationships between words and optimally pairs attribute-sentiment polarity without relying on external knowledge bases such as WordNet or Sentiment Dictionary. Many current sentiment analysis models heavily rely on background knowledge for feature generation, making them less effective when such knowledge is unavailable. The introduction of adversarial samples in the word embedding layer and semantic feature fusion layer, combined with re-training on the original samples, significantly enhances the model's generalization ability.
Discussion
The findings above demonstrate that utilizing the BiLSTM-CRF-WBAT model for fine-grained sentiment analysis significantly enhances the exploration of online course reviews. The BiLSTM component captures intricate contextual relationships within reviews, processing text in both forward and backward directions to understand how natural environment elements—such as virtual nature scenes or environmental imagery—impact sentiment. This dual-direction processing allows for more precise extraction of key information related to teaching and learning experiences influenced by these natural elements, as supported by studies highlighting the importance of context in sentiment analysis. 35 The CRF layer ensures global consistency in sequence annotation, maintaining coherence across the entire review and integrating the influence of natural environment features into the overall sentiment analysis. Previous research has shown that CRF models effectively enhance sequence prediction tasks by ensuring that the predictions are contextually relevant. 36 Additionally, the WBAT mechanism improves focus on crucial words within comments, particularly those related to natural environment aspects, thereby enhancing the model's ability to attend to significant information during sentiment analysis. This mechanism refines attention to specific elements of feedback, such as references to environmental themes or imagery used in course content, consistent with findings by Shi et al., 37 on the efficacy of attention mechanisms in natural language processing.
By leveraging the BiLSTM-CRF-WBAT model, sentiment analysis becomes more accurate and granular, allowing for the extraction of critical insights and the establishment of a detailed scoring mechanism for various aspects of the course. This model not only aids learners in understanding the strengths and weaknesses of courses that integrate natural environment elements but also provides a more intuitive and comprehensive evaluation of course quality. Thus, the BiLSTM-CRF-WBAT model significantly enhances the precision of sentiment analysis, offering learners valuable information for informed decision-making in their course selections.
Combining advanced sentiment analysis with insights from natural environment integration allows educational platforms to better understand and respond to the emotional and cognitive needs of their users. 38 This holistic approach improves the accuracy of content recommendations and fosters a more engaging and supportive learning environment, leading to higher student satisfaction, better learning outcomes, and improved mental health. The proposed method automates the extraction of key aspects from student comments and determines their sentiment polarity, particularly regarding how natural environment elements influence feedback.
Through fine-grained sentiment analysis of online course reviews, key information regarding the course—such as teacher lectures, platform stability, and teaching resources—is extracted, especially when courses integrate natural environment elements such as virtual nature scenes or eco-themed content. Each piece of information is assigned a scoring mechanism based on the algorithm, allowing learners to intuitively understand the strengths and weaknesses of the course across various aspects, including the integration of natural elements. This approach empowers learners to make informed decisions when selecting courses that align with their individual needs, shifting the focus of course quality review from experts to participating learners and fostering a more objective and nuanced assessment of online course quality.
Additionally, analyzing feedback related to natural environment aspects can significantly contribute to the improvement of the teaching quality. By examining learners’ comments on how natural elements in the course content affect their learning experience, teachers can gain insights into areas such as the effectiveness of integrating environmental themes into lessons and the overall impact on student engagement. This feedback helps identify specific areas for enhancement in knowledge explanation, teaching methods, and the incorporation of natural themes, leading to optimized teaching outcomes.
The research method also provides educational analysts with a detailed understanding of how natural environment elements influence online education. It addresses existing shortcomings, strengthens effective practices, and guide online education toward better integration of natural themes. Sentiment analysis of learners’ reviews, especially those focusing on environmental aspects, offers clear insights into learners’ emotional responses to these elements. Platforms can leverage this feedback to improve system design, enhance learners’ experiences with natural content, and optimize resource allocation. By tailoring interactive features to better incorporate and highlight natural environment elements, platforms can increase their attractiveness and competitiveness in the online education market.
Conclusion
The experimental results demonstrate that the proposed method effectively leverages the complementary strengths of various component models to enhance the extraction of attribute terms, particularly in contexts where natural environment elements are integrated into online courses. This model achieves superior sentiment analysis accuracy compared to state-of-the-art methods, even in the absence of an external knowledge base. The inclusion of a semantic feature fusion layer and adversarial training, particularly when analyzing sentiment related to environmental themes, further refines classification performance, with the model performing optimally when both enhancements are employed.
In the context of online teacher education courses incorporating natural environment elements, this model is invaluable for understanding learners’ perspectives on how environmental themes influence their learning experience. It helps identify learners’ needs and provides actionable recommendations to enhance course design and implementation. For instance, by integrating virtual nature scenes or eco-friendly content into courses, the model supports teachers in organizing educational activities that resonate with these themes, refining teaching content, and addressing student concerns related to environmental aspects promptly. This proactive approach helps prevent the escalation of negative emotions, transforming potentially problematic feedback into constructive discussions.
While the proposed model demonstrates improved sentiment classification, it has limitations. Reliance on annotated data may limit generalizability to other educational contexts lacking similar datasets. Additionally, implicit sentiment extraction remains challenging, as the model may overlook subtle references to environmental aspects. Overfitting is also a risk given the specific nature of the datasets, suggesting a need for further testing across diverse learning environments. Future research could explore domain adaptation techniques or multimodal approaches to broaden applicability.
Footnotes
Acknowledgements
I thank the anonymous reviewers whose comments and suggestions helped to improve the manuscript.
Consent for publication
Not applicable.
Contributorship
Juanjuan Zang was responsible for study conception, design, interpretation of results, data collection, analysis and the project administration. Juanjuan Zang was responsible for draft manuscript preparation. The author reviewed the results and approved the final version of the manuscript.
Declaration of conflicting interests
The author declared no potential conflict of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
This article does not contain any studies with human participants performed by the author.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is funded by 2024 Shandong Provincial Social Science Planning Project ‘Research on Emotion Recognition and Intervention of Online Learners Based on Context Awareness’, the project number is 24DJYJ13.