
Abstract
Digital teaching diversifies the ways of knowledge assessment, as natural language processing offers the possibility of answering questions posed by students and teachers.
Objective
This study evaluated ChatGPT's, Bard's and Gemini's performances on second year of medical studies’ (DFGSM2) Pathology exams from the Health Sciences Center of Dijon (France) in 2018–2022.
Methods
From 2018 to 2022, exam scores, discriminating powers and discordance rates were retrieved. Seventy questions (25 first-order single response questions and 45 second-order multiple response questions) were submitted on May 2023 to ChatGPT 3.5 and Bard 2.0, and on September 2024 to Gemini 1.5 and ChatGPT-4. Chatbot's and student's average scores were compared, as well as discriminating powers of questions answered by chatbots. The percentage of student–chatbot identical answers was retrieved, and linear regression analysis correlated the scores of chatbots with student's discordance rates. Chatbot's reliability was assessed by submitting the questions in four successive rounds and comparing score variability using a Fleiss’ Kappa and a Cohen's Kappa.
Results
Newer chatbots outperformed both students and older chatbots as for the overall scores and multiple-response questions. All chatbots outperformed students on less discriminating questions. Oppositely, all chatbots were outperformed by students to questions with a high discriminating power. Chatbot's scores were correlated to student discordance rates. ChatGPT 4 and Gemini 1.5 provided variable answers, due to effects linked to prompt engineering.
Conclusion
Our study in line with the literature confirms chatbot's moderate performance for questions requiring complex reasoning, with ChatGPT outperforming Google chatbots. The use of NLP software based on distributional semantics remains a challenge for the generation of questions in French. Drawbacks to the use of NLP software in generating questions include the generation of hallucinations and erroneous medical knowledge which have to be taken into count when using NLP software in medical education.
Introduction
For centuries, medical teaching has been carried out in universities, by recognized peers and leading to the award of a degree of Doctor of Medicine. 1 More recently, the Flexner Report laid the foundations of modern medical education, then known as ‘biomedical education’ inspired by Theodore Billroth's Germanic education system, allowing the integration of scientific and technological advances of the twentieth century into medical education. 2 The improvement of technological tools has enabled the acceleration of human evolution to the present day with the invention of the computer. 3 These innovative technologies include the advent of artificial intelligence in the form of computers and as a discipline known as deep learning.4,5 The deep learning method consists of superimposing several complex mathematical formulae and logical sequences called ‘convolutional neuronal networks’ (CNNs).4,5 CNNs have a wide range of applications, from image recognition and data sorting to natural language processing. Natural language processing (NLP) methods have been increasingly used over the last decade and are currently becoming an integral sub-specialty of deep learning. 6 The uses of NLP are diverse, making it possible, among other things, to decipher a text in a foreign language and translate it instantly, perform precise sorting of defined words in a text, accurately answer specific questions, generate images from a textual description, or generate a manuscript or book automatically or semi-automatically. 6 In its early development, NLP resulted in creating an artificial intelligence-guided instant conversation software (still called a ‘chatbot’), invented in 1964, called ‘ELIZA’. 7 Other chatbots have emerged, particularly for commercial purposes, enabling a customer to talk to customer services without the need for a third party, thus saving waiting time and sometimes unnecessary telephone calls. In medical education, the use of artificial intelligence first appeared on an experimental basis, particularly in medical teaching. 8 The use of NLP in medicine has led to the creation of several chatbots: this technology was applied in 2015 with the creation of a chatbot adapted to the pharmaceutical industry, called ‘Pharmabot’, enabling the therapeutic education of parents wishing to administer medicines to young children, but lacking sufficient medical knowledge. 9 Another chatbot was created in 2017, called Mandy, enabling a ‘clinical pre-interview’ to be carried out and integrated into a decision-making algorithm, in order to easily guide patients towards targeted and rapid care when admitted to emergency departments, which are often short of medical and paramedical staff. 10
The acceleration of the development of NLP and deep learning methods lead to the creation of ChatGPT® (GPT: Generative Pre-trained Transformer), a platform created by OpenAI®, a company founded in the United States by entrepreneur Elon Musk and computer scientist Sam Altman, in collaboration with Amazon Web Services. The software's usefulness lies mainly in generating answers to questions posed by the user, as well as generating manuscripts. 11 At present, the most recent and best-performing version is not free, in contrast with the initial dogma of the OpenAI® company, which presents itself as a ‘not-for-profit enterprise’, although a publicly available free-to-use version with reduced performances is still available. More recently (March 2023), in response to the birth of ChatGPT, another free-to-use publicly available platform founded by the Google company, called Bard®, with identical functionalities to ChatGPT®, was launched in November 2022 (ChatGPT having been born at the beginning of 2022, the result of long-standing work since the creation of OpenAI® in 2015). The Bard platform uses technology derived from GPT-3, corresponding to the third version of the GPT neural network generated by OpenAI®.
As for the use of latest-generation chatbots, recent studies focused on the use of ChatGPT and Bard in medical education. For example, ChatGPT was used in the United States to test the national medical exam. 12 As a reminder, the United States Licensing Examination (USMLE) consists of two limiting stages: the first, called USMLE Step 1, is based on the evaluation of theoretical knowledge of fundamental disciplines (microbiology, pathology, biochemistry, etc.), and the second, called Step 2, is based on the evaluation of clinical knowledge integrated into a problem. Performance on a panel of questions from the National Board of Medical Examiners (NBME), the official body for assessing medical knowledge in the United States, was 64.4% and 57.8% on two separate tests, respectively. 13 A recent international meta-analysis of ChatGPT performance scores on various multiple-choice questionnaires (MCQ) confirms this recurrent score of around 60% on most of the tests carried out by the software. 14 Other scientific publications are currently highlighting the concept of a ‘digital educational tool’ for ChatGPT and chatbots in general.12,13,15,16 A comparative study carried out in South Korea on an undergraduate parasitology exam concurs with the data observed with the USMLE, with a pass rate of around 60%. 17 More specifically, the rate of correct answers provided by ChatGPT was independent of the level of difficulty of the question, and the rate of acceptability of the answers provided remained low in the event of a wrong answer, thus demonstrating that the answer provided was really wrong and not the result of a random choice. In Taiwan, studies carried out on the pharmacist and family medicine national examinations, showed respective performances ranging from 45.5% to 67.6%, making it impossible to validate the diplomas in the country concerned.18,19 The same is true for the American College of Gastroenterology examination, with scores of around 65%, making it impossible to validate this examination. 20 In addition, a Europe-wide study demonstrated the high performance (58.8%) of ChatGPT 3.5 in the European Exam in Core Cardiology (EECC). 21 In Italy, a study was also carried out on the Italian national competitive examination: ChatGPT 3.5 was able to provide a correct answer to 87.1% of the questions, ranking in the 98th percentile compared with 15,869 Italian medical students. 22 Other studies conducted on biochemistry, hepatology and thoracic surgery exams demonstrate ChatGPT's ability to answer questions requiring academic knowledge with high performance scores23–25 A study carried out on undergraduate Pathological Anatomy questions in the United States demonstrated the high performance of ChatGPT 3.5, particularly in questions requiring only theoretical knowledge of anatomy or histology, without integration of complex clinical problems. 26 The authors noted no significant difference in ChatGPT performance depending on the type of pathology examined. 26 Very recently, a study published in China also demonstrated the ability of ChatGPT 3.5 and 4 to obtain a score sufficient to validate Chinese-language medical examinations, albeit with higher performance for ChatGPT 4. 27 In French language, studies of chatbot performances to medical examinations remain scarce. In the field of cardiology, ChatGPT 3.5 and ChatGPT 4 showed similar performance rates, both answering to approximately 80% of the questions (81 and 84 out of 99 questions) without exposing the patient to a medical risk, however medical misinformation was highlighted as major drawback for its use in medical purposes. 28 Another similar study showed that ChatGPT 4 could pass the European Board of Ophthalmology (EBO) in French language with a 91% success rate. 29
Given the early release of Bard (March 2023 in the USA; July 2023 in France), studies on its potential use in medical education are still rare. Most of these have been carried out in the United States, comparing the performance of ChatGPT and Bard.30,31 These studies conclude that Bard performs less well than ChatGPT.
The objectives of this study is to retrospectively assess the performances of ChatGPT 4, ChatGPT 3.5, Gemini 1.5 Advanced Pro and Bard 2.0 on a series of independent questions (single and multiple response questions) in anatomical pathology, previously submitted to second-year medical students of the Faculty of Health Sciences of Dijon (France) from 2018 to 2022. We also discuss the advantages and drawbacks of the use of chatbots given to students and medical examiners in medical problem solving and knowledge assessment.
Materials and methods
Prior authorizations and study design
Free registration to ChatGPT 4, ChatGPT 3.5, Gemini 1.5 Pro Advanced and Bard 2.0 using a Google account was required prior to the experiments. Consent was obtained from the Faculty of Health Sciences of Dijon (France) to obtain access to grades on THEIA, the French national medical student teaching/scoring software.
Exam submission to chatbots
The study was conducted retrospectively from May 2023 to September 2024, at the University of Burgundy's Health Sciences Center (Dijon, France). The entire database of questions for each exam year session from 2018 to 2022, previously submitted to second-year medical students, was compiled with the results displayed on THEIA (Table 1; Supplemental 1). For each exam session, the questions included five first-order single response questions (SRQ) and 9 second-order multiple response questions (MRQ), for a total of 70 (five exam years including 14 questions each) independent questions. All the questions were exclusively conceived by two pathologists (LM and GT) and exclusively composed of text. For all the students and for each question, data was compiled in a spreadsheet including the scores, averages, discordance rate (i.e., for multiple choice questions, the rate of wrong and/or missed answers) and discriminative power of each question item. The questions were then successively submitted by copying and pasting the text to ChatGPT 3.5 and Bard 2.0 in May 2023 (Figure 1), and ChatGPT 4 and Gemini 1.5 Advanced Pro in September 2024.

Example of ChatGPT 3.5 (top panel) and Bard (down panel) answer to one of the randomly selected single response questions (SRQ). The question submitted to both chatbots in French is ‘What is the objective of tissue fixation? A. Avoid their lysis, B. Be able to perform thin sections, C. Stain tissues, D. Sterilize tissues, E. being able to perform their gross examination’. The correct answer was A. Translation: ChatGPT 3.5 answered ‘The objective of tissue fixation is: A. To avoid their lysis. Tissue fixation is an essential process in histology and pathology. This process aims to preserve tissue structure and the organization of biological tissues by stopping degradation processes and decomposition which would naturally happen after tissue sampling. Fixation allow tissues to be more solid and durable, which allow for performing thin sections, tissue staining, analysis or even being able to perform their gross examination. Tissue fixation impedes the growth of bacteria and enzymes, thus preserving morphology and chemical composition of tissues for further study’. Bard answered: ‘Tissue fixation aims to avoid lysis, to allow for thin sectioning and to allow for tissue to be analyzed microscopically. Tissue staining is a further step. Tissue sterilization is not necessary for fixation. Gross examination of tissues can be performed before tissue fixation, yet it is often harder to be done in fixed tissues. Therefore, the right answer is (A)’.
Studies focusing on the assessment of ChatGPT's and Bard's performances to medical licensing examinations.

Unspecified version.
Scoring of chatbots and students
The answers generated by each chatbot were then entered into a data spreadsheet and compiled with student's results. The chatbot's answers were scored using the same scoring method applied to the students, that is, by discordance scoring. Considering all questions comprising five items, a perfect match is scored 1 point, one discordance is scored 0.5 points, and two discordances are scored 0.2 points. More than three discordances is equivalent to a zero mark for the question. Of note, a discordance is defined either by the failure to select a true answer or by the inappropriate selection of an answer considered false by the medical teacher. Moreover, the discriminating power measures how well an item can discriminate between the ‘high-performance’ student group (defined as having the highest grades) and the ‘low-performance’ student group (defined as having the lowest grades).32,33 The discriminating power can be calculated by subtracting the number of students of the ‘high-performance’ group who answered the question correctly to the number of students of the ‘low-performance’ group who answered the question correctly, all divided by the total number of students.
Reliability of chatbots and effects of prompt engineering
To evaluate the effects of prompt engineering, the questions were submitted in four different successive rounds to ChatGPT 4 and Gemini 1.5 Advanced Pro. Items were scored as previously, and inter-observer variability was assessed using Fleiss’ Kappa score. For one round, the questions were more detailed and labelled as ‘single response question only’ and ‘multiple response question only’, then compared to the original round used for the study using a Cohen's Kappa score.
Data generation and analysis
All the results generated by ChatGPT 4, ChatGPT 3.5, Gemini 1.5 Advanced Pro and Bard 2.0 were then compiled into a data spreadsheet containing the following items: score generated for each question, average score, percentage of deviation from student's average scores, proportion of students who answered exactly as chatbots, and the corresponding discriminative power of questions answered by chatbots. Average scores and medians were also compared between chatbots and medical students. All the statistical analyses of the study were carried out using Microsoft Excel 2021 and GraphPad Prism® 8.0.1.
Results
The data were generated from five classes of students, from 2018 to 2022, divided into ‘high-performance’ and ‘low-performance’ student groups by THEIA (French teaching software) to assess the discriminating power of isolated questions (Table 2). These classes are independent and the questions are non-redundant, except for repeaters (around 1%) who are automatically included in the respective classes.
Number of assessed students per exam year, total, ‘high-performance’ and ‘low-performance’ groups.

The average scores of second-year medical students were compared to chatbot's average scores (Table 3). Firstly, we observed that the overall median average score of ChatGPT 4 was higher than ChatGPT 3.5, and Gemini's overall scores remained higher than Bard for all exam years (Table 3 and Figure 2). In addition, the medians of the average scores of Bard and students remained similar, however, with lower minima for Bard in comparison to students (Figure 2). The median of average overall scores of ChatGPT 4 and Gemini 1.5 remained similar (Figure 2). Furthermore, we calculated chatbot's deviation percentage from the average student's score: Bard 2.0 harboured negative deviation percentages while ChatGPT 4, ChatGPT 3.5 and Gemini 1.5 consistently showed a positive deviation from student's average scores, ChatGPT 4 outperforming Gemini 1.5 (Figure 2). The student's average scores over the different exam years were consistently lower than ChatGPT 4, ChatGPT 3.5 and Gemini 1.5 (Table 3 and Figure 2), however, student's average scores were often equal to or higher than Bard 2.0 (Figure 2). Finally, the average difference in points (considering a score from 0 to 20) in relation to the weighted student average was 1.3828 for ChatGPT 3.5, -0.0742 for Bard, 4.583 for ChatGPT 4 and 4.2114 for Gemini 1.5. These preliminary data demonstrate the superior performance of ChatGPT 4, ChatGPT 3.5 and Gemini 1.5 in comparison to students in their current publicly available free versions, Bard 2.0 being at the same level of overall performance than students. From our data, one could hypothesize that chatbots could reflect the ‘average’ student's performances, or even the ‘high-performance’ group of students, thus raising concern and opportunities for the use of chatbots for the generation of SRQ and MRQ in medical education.

Chatbot's and student's average scores. Top Panel: Box-plots of verage overall scores of chatbots and students, for every exam year. Middle Panel: Histogram representing the percentage of deviation from student's average score, per exam year. The colours of each graph are indicated at the top of the figure. Bottom Panel: Histogram representing the average score to each exam, per exam year, of chatbots and students. The colours of each graph are indicated at the top of the figure.
Chatbot's and student's average scores to the examinations, per exam year, on a total of 20 points.

To provide detailed analysis chatbot's performances in comparison to second-year medical students, we reported the scores generated by chatbots in comparison to the average scores obtained by the students for each question (Figure 3). We observed that ChatGPT 3.5 and Bard 2.0 showed similar results to students on SRQ (median score for ChatGPT 3.5: 0.75, Bard: 0.5, Students: 0.76), however, newer chatbots outperformed students in solving SRQ (median score for ChatGPT 4: 1, Gemini 1.5: 1). Meanwhile, students outperformed both NLP software on MRQ, regardless of the exam year and/or student group (median score for students: 0.63, ChatGPT 3.5: 0.5 and Bard: 0.5) (Figure 3). As for newer chatbots (i.e., ChatGPT 4 and Gemini 1.5), both outperformed students (median score for students: 0.63, ChatGPT 4: 1, Bard: 1).

Chatbot's and student's scores to question items (from 0 to 1, using discordance scoring). Top-Panel Left: Horizontal box-plot of the overall scores to the 70 question items, for each chatbot and the students. Top-Panel Right: Vertical box-plot of the overall scores to the 14 question items per exam year. The colours of each graph are indicated at the top of the figure. Middle-Panel Left: Horizontal box-plot of single response question's (SRQ) scores to the 25 question items, for each chatbot and the students. Middle-Panel Right: Vertical box-plot of the single response question's (SRQ) scores to the 25 question items, per exam year. The colours of each graph are indicated at the top of the figure. Bottom Panel Left: Horizontal box-plot of multiple response question's (SRQ) scores to the 45 question items, for each chatbot and the students. Bottom-Panel Right: Vertical box-plot of the multiple response question's (SRQ) scores to the 45 question items, per exam year. The colours of each graph are indicated at the top of the figure.
On the basis of our results, newer chatbots similarly outperformed students on both SRQ and MRQ. ChatGPT 3.5 seemingly outperformed Bard 2.0 which resembled the student's average performances. In order to check whether chatbots selected ‘discriminating’ items (i.e., answered to items with a high discriminating power for students) we produced the discriminating power (DISC) of chatbots using as a reference the ‘high-performance’ and ‘low-performance’ student groups who responded identically to the software (Figure 4). Analysis of the DISC of ChatGPT 3.5 and Bard 2.0 revealed identically low medians across all questions (ChatGPT 3.5 DISC median: 0.071; Bard 2.0 DISC median: 0.007). Oppositely, ChatGPT 4 and Gemini 1.5 DISC medians were similar to student's overall DISC median (ChatGPT 4 DISC median: 0.133; Gemini 1.5 DISC median: 0.13; student DISC median: 0.186). Detailed analysis showed closely identical performances for SRQ for both chatbots and students (ChatGPT 3.5 DISC median: 0.21; Bard 2.0 DISC median: 0.19; ChatGPT 4 DISC median: 0.24; Gemini 1.5 DISC median: 0.23; student DISC median: 0.19). In contrast, the discriminating performance of chatbots remained much lower for MRQ in comparison to students (ChatGPT 3.5 DISC median: 0.0158; Bard DISC median: 0; ChatGPT 4 DISC median: 0.056; Gemini 1.5 DISC median: 0.056). These data were reproducible for all exam years (Figure 5). The large differences in DISC medians in MRQ demonstrates students’ ability to outperform chatbots to multiple-response questions, which are often more discriminating than SRQ.
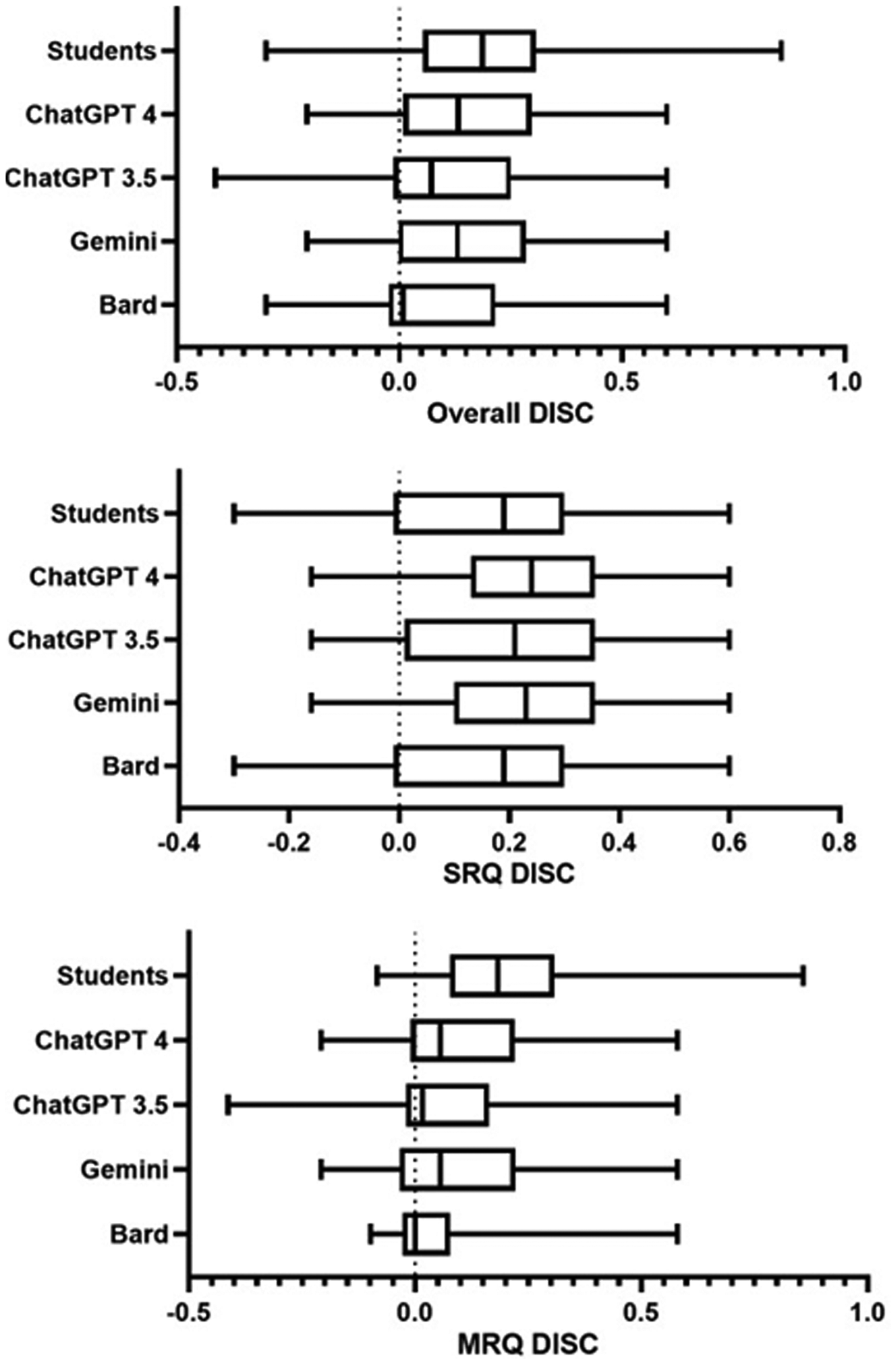
Chatbot and student's discriminating power (DISC), scored from −1 to +1. Higher scores indicate high discriminating power of question items. The y-axis represents the various chatbots and students. The x-axis represents the discriminating power. Top Panel: Horizontal box-plots representing the discriminating power (DISC) of all 70 questions answered by chatbots and students. Middle Panel: Horizontal box-plots representing the discriminating power (DISC) of all 25 single response questions (SRQ) answered by chatbots and students. Bottom Panel: Horizontal box-plots representing the discriminating power (DISC) of all 45 multiple response questions (MRQ) answered by chatbots and students.

Vertical box-plots of chatbot's and student's discriminating power (DISC) per exam year, for all (top panel), single response (middle panel) and multiple response (bottom panel) questions. The colours of each graph are indicated at the top of the figure.
To evaluate the coherence of answers provided by NLP software to MRQ, a linear regression model was applied (Figure 6): for both software, we showed a negative correlation for all chatbots between the average discordance rate of each question and the scores generated by chatbots (ChatGPT 3.5: slope: −0.5110, p = 0.0456; R²: .089; Bard 2.0: slope: −0.5477, p = .0205; R²: .1187; ChatGPT 4: slope: −0.4735, p = .0820; R²: .06870; Gemini 1.5: slope : −0.3412, p = .1997, R²: .03795). This data confirmed that both NLP software provided better scoring at questions with fewer discordances generated by students, which indicated that the answers of both NLP software were coherent in comparison to the answers provided by students. For the single-answer questions, the average mismatch was equal to 0 (as one answer was sufficient to provide a score of 0/1), thus it was impossible to perform a linear regression for SRQ.

Top panel: percentage of student's and chatbot's identical answers. The percentage is indicated in Y-axis and the exam year is indicated in X-axis. The colours of each graph are indicated at the top of the figure. Bottom Panel: Linear regression analysis for each chatbot's scores (x-axis, predictor) to multiple response questions, in relation to the corresponding discordance rate (y-axis, response).
Moreover, the median percentage of chatbot's and student's identical answers remained higher for ChatGPT 3.5, ChatGPT 4 and Gemini, than for Bard (Figure 6). We observed approximately 30%–40% (mean and median, respectively) of identical responses between students and newer chatbots, with better agreement between Gemini 1.5, ChatGPT4 and students, except for the 2019 session, which showed better agreement from Bard with students, in comparison to ChatGPT 3.5 (Figure 6). Our data demonstrated that in most cases, chatbots answered alike approximately 40% of the students, and provided coherent answers to most questions answered by the medical students.
Finally, in order to assess the variability of chatbot's answers to questions previously submitted to second-year medical students, the same questions were submitted during four successive rounds to ChatGPT 4 and Gemini 1.5. The questions were scored as previously described (i.e., discordance scoring) then a Fleiss’ Kappa was performed between all rounds of questions. We observed substantial variability between each rounds submitted to chatbots: the Fleiss’ Kappa for ChatGPT 4 was 0.636, with an expected agreement of 0.6 and an average Pi of 0.854. For Gemini 1.5, concordance between rounds was shown to be weaker than for ChatGPT 4: indeed, the expected agreement was measured at 0.495, and the Fleiss’ Kappa at 0.4948, with an average Pi of 0.745. This data confirms substantial variability between rounds of questions submitted to chatbots, with greater concordance and reliability of ChatGPT 4 in comparison to Gemini 1.5. Finally, we evaluated the effects of prompt engineering in comparison to the first round of questions used for the study. To do so, we submitted the questions mentioning the reality of questions being SRQ and MRQ or not. A Cohen's Kappa was then measured between the scores of the first round of questions and the ‘prompt-engineered’ round of questions. Interestingly, the Cohen's Kappa was at 0.519 for ChatGPT 4 and 0.36 for Gemini. Taken altogether, our data shows that ChatGPT4 and Gemini 1.5 may suffer from variability in the answers provided, with ChatGPT 4 being more consistent in its answers than Gemini 1.5.
Discussion
In this study, we aimed to test the performance of freely available chatbots ChatGPT (3.5 and 4), Gemini 1.5 Advanced Pro and Bard on a series of isolated questions previously submitted to students. These NLP software are performing increasingly well, raising the question of their potential use as an innovative teaching tool, with promising insights with the future development of the actual versions of ChatGPT and Gemini.
In our study, the median of the average scores for the various exams was around 13/20 (65%) for ChatGPT 3.5, showing similarities with the data in the literature. Indeed, most of the exams undertaken by ChatGPT 3.5 showed scores around 12/20 or 60%.12,13,15‒17 For Bard 2.0, the rare data in the literature demonstrated lower scores than ChatGPT 3.5, in similar proportions to those observed in our work (approximately 10%–15% difference between the mean scores of ChatGPT 3.5 and Bard 2.0).30,31
In addition, our results show several interesting facts about NLP software in terms of how it is used, understood and reasoned about. Firstly, we have shown that ChatGPT 3.5 outperforms Bard 2.0. These results can simply be explained by the fact that ChatGPT 3.5 is much older than Bard 2.0, which was developed a few months or even years later, and ChatGPT 3.5 therefore has more learning and experience than Bard. As a reminder, ChatGPT 3.5 has around 175,000 billion virtual ‘synapses’, compared with the human brain, which has 100,000 billion.34,35 In our work, ChatGPT 3.5 and Bard demonstrated equivalent or even superior performance for SRQ compared with second-year medical students. Yet, one has to bear in mind that the structure of ChatGPT 3.5 and Bard 2.0 software is based on distributional semantics, which consists of pre-training neural networks to recognize and associate more than 300 million words. 36 Distributional semantics enables computers to associate words to give them a meaning in a specific context, or even to associate them with already pre-established data in the literature available online, as in the case of ChatGPT 3.5 and Bard 2.0. 11 Therefore, the use of distributional semantics for enabling the restitution of fundamental knowledge, often requested by students in SRQ, could remain an easy task for NLP software. We can therefore formulate the hypothesis that distributional semantics-based ChatGPT 3.5 and Bard 2.0 software are poorly able to integrate remote information and answer multiple response questions which usually require complex reasoning. In our study, we demonstrated that students were better at answering MRQ than ChatGPT 3.5 and Bard 2.0, especially if these questions discriminated between ‘high-performance’ and ‘low-performance’ student groups. These data points towards the fact that ChatGPT 3.5 and Bard 2.0 harbour a mode of reasoning which would probably not be sufficient to answer MRQ of increasing complexity.
With the rapid evolution of newer generations of chatbots being freely available up to date, the evaluation of ChatGPT 3.5 and Bard 2.0 could remain obsolete at the end of the study. We then further aimed to assess the performances of ChatGPT 4 and Gemini 1.5 Advanced Pro. Comparative studies conducted in the United States demonstrate the superiority of ChatGPT 4.0 over ChatGPT 3.5.30,37 Despite the lower performances of Bard when compared to ChatGPT 3.5, recent up-to-date studies on newer chatbots showed that Gemini 1.5 Advanced Pro might be a strong competitor against ChatGPT 4 in terms of providing accurate answers to medical problems such as in the field of ophthalmology or dental medicine38–40 In pathology, one study performed on domain-specific knowledge of pathology using ChatGPT 3.5 and ChatGPT 4 confirms the superiority of ChatGPT 4 in comparison to ChatGPT 3.5, with specific high-level performances in pulmonary pathology and disease mechanisms and low-level performances in renal, genetic disorders and gastrointestinal pathology. 41 This study emphasizes on the high amount of knowledge generated by chatbots in contrast with answers qualified as ‘awkward’ and ‘irrelevant’. 41 Another study using board-style clinical pathology knowledge questions confirmed our data: ChatGPT 4 showed an overall performance of approximately 65%, with higher scores on ‘easy’ questions than on ‘intermediate’ and ‘difficult’ questions. 42 As for the assessment of answer variability to examinations, our study showed that Gemini showed more variability than ChatGPT 4 when generating consistent answers. In pathology, one study comparing the performances of ChatGPT 4 and Bard in the interpretation of pathological images showed that Bard had a tendency to be less consistent and generate more hallucinations. 43
Up to date, the release of ChatGPT-o1 in September 2024 might bring new insights in clinical reasoning, and student evaluation. Indeed, the new ‘preview-only’ version raises higher expectations in the field of research and education, as this version brings more complex reasoning (‘step-by-step’ approach) in exchange of longer delays for answering questions. 44 However, ChatGPT-o1 remains prone to hallucinations and multi-lingual variability. 45 Further studies will be required in order to assess the performances, potential usefulness and drawbacks of ChatGPT-o1 in medical education.
Conclusion
Our work confirms the data in the literature in terms of the actual performances of NLP software ChatGPT 3.5 and Bard 2.0 being less performant than newer versions ChatGPT 4 and Gemini 1.5 Advanced Pro, and demonstrates the value of MRQ as a tool for discriminating between ‘high-performance’ and ‘low-performance’ student groups. In the literature, the contribution that NLP software could make in medical teaching is addressed, promoting its positive aspects and issuing its major drawbacks. The positive aspects of artificial intelligence are highlighted, for example in helping to draw up a personalized educational programme, improving the evaluation of student performance, or carrying out graduated and progressive evaluations throughout medical education. More specifically, scientific articles have been published evaluating the development of isolated questions by ChatGPT 3.5 in comparison with medical teachers: a multicentre study (Hong Kong, Saudi Arabia, Singapore, Ireland, United Kingdom) demonstrated that ChatGPT 3.5 could generate SRQ and MRQ 10 times faster than actual teachers, albeit with less relevance and clarity which remained acceptable to the authors. Despite the software's ability to generate isolated questions in less time, recent studies on Bard 2.0 and ChatGPT 3.5 agree on that these software programs can generate relevant SRQ, however, the generation of MRQ provided poor outcomes, confirming the data observed in our work. Furthermore, our data showed that this statement also comes true for ChatGPT 4 and Gemini 1.5 Advanced Pro, as students were able to be more performant in answering questions with a high discriminating power. Studies performed on Gemini 1.5 and ChatGPT 4 have a global tendency to emphasize on the high performances of both chatbots, however, cautious advice is raised for their use in daily routine, as both chatbots could generate inconsistent answers, giving the impression of a ‘perceived trustworthiness potentially obscuring factual inaccuracies’ as told by Meyer et al. Another aspect that should be taken into count when generating questions or using these chatbots is prompt engineering, with lists of prompts being developed to improve the use of chatbots in order to specify the need for the teacher/student. As shown in our study, substantial variability might exist for the same questions over time, chatbots being constantly updated with new knowledge and their generative pretrained transformers being improved every single day.
Finally, a major pitfall is raised in some studies of medical manuscript generation by ChatGPT 3.5 and Bard 2.0: these software can potentially generate ‘hallucinations’. These ‘hallucinations’ correspond to erroneous data, deviating from the main subject or context, or fabricated by the ChatGPT 3.5 and Bard 2.0 software. In order to remedy this common problem of ‘hallucination’ generation, a new software called ‘SelfCheckGPT’ has been developed, capable of detecting ‘hallucinations’ in text generated by ChatGPT.
At present, data on the use of NLP in French-language medical education remains scarce and poorly studied. The use of ChatGPT 3.5 and Bard 2.0 appears promising for the future, making it possible to envisage, for example, its integration into a teaching software (e.g., THEIA—France) in order to measure student performance, adapt questions, and generate adaptive knowledge checks during medical teaching at the Faculty of Medicine. The use of functions such as generating images from text and vice versa for histopathological image recognition and pathology report generation would make it possible in the future to improve knowledge control and test the training of pathology residents, who are often confronted with sometimes critical cases involving heavy responsibilities early in their career. The generation of health disinformation and erroneous medical knowledge has recently been raised as a major drawback against its use in medical education and patient information. Further studies on French-language SRQ and MRQ will improve our understanding of the performance of these NLP software packages, which are then publicly available to students and teachers.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241310630 - Supplemental material for Performance assessment of ChatGPT 4, ChatGPT 3.5, Gemini Advanced Pro 1.5 and Bard 2.0 to problem solving in pathology in French language
Supplemental material, sj-docx-1-dhj-10.1177_20552076241310630 for Performance assessment of ChatGPT 4, ChatGPT 3.5, Gemini Advanced Pro 1.5 and Bard 2.0 to problem solving in pathology in French language by Georges Tarris and Laurent Martin in DIGITAL HEALTH
Footnotes
Acknowledgements
We would like to thank Pr. Thomas Alexander McKEE and Pr. Laura RUBBIA-BRANDT (University of Geneva), Pr. Marc MAYNADIE (University of Burgundy – Dean of the Health Sciences Center) and Pr. Benoit TERRIS (Université Paris Cité).
Authors’ note
Georges Tarris and Laurent Martin are also affiliated with University of Burgundy Health Sciences Center.
Contributorship
GT and LM contributed to conceptualization.GT and LM contributed to writing and editing.
Data availability
The authors confirm that the data supporting the findings of this study are available within the article and its supplementary material. Raw data of this study are available from the corresponding author upon reasonable request, and with permission of the University of Burgundy.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethics approval
The study was performed using anonymized archival data, for which written informed consent was waived. Permission to access data was given prior to the study by the University of Burgundy's Health Sciences Center (Dijon, France). The study was considered in accordance to the principles of good clinical practice, this trial being outside French Jardé's Law, the need for Ethics Committee approval was waived by the Committee for the Protection of Persons (CPP) Est I.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Fondation Clément Drevon, Fondation pour la Recherche Nuovo-Soldati,
Financial support
Georges Tarris was awarded the Nuovo Soldati foundation grant and the Clément Drevon foundation grant for the accomplishment of this work.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.