
Abstract
Background
The limitations in current medical imaging systems often result in poor visibility and insufficient detail. Such low-quality images hinder the decision-making of medical professionals. The weighted least squares (WLS) model provides a prevalent framework for detail and tone manipulation, but it is non-trivial to solve.
Method
We propose a fast solution to the WLS model. Instead of addressing a large linear system or approximating two-dimensional image processing with multiple one-dimensional procedures, we demonstrate that the model can be solved efficiently using an iterative algorithm. We leverage our method for the detail and tone enhancement of medical images.
Results
(1) For detail enhancement, on the three subsets of X-ray images, the spatial-spectral entropy-based quality (SSEQ) values are 21.15, 29.46, and 31.36; the convolutional neural networks image quality assessment (CIQA) values are 17.67, 25.60, and 26.01; on the computed tomography and magnetic resonance imaging images, the SSEQ and CIQA values are 14.01 and 16.93; it achieves peak signal-to-noise ratio (PSNR) ≥39.39 and structural similarity index (SSIM) ≥0.99; (2) for tone enhancement, the tone mapped image quality index, fidelity, and naturalness values are recorded at 0.7905, 0.9300, and 0.0090; it achieves PSNR ≥50.09 and SSIM ≥0.99. Notably, our method processes a 720P color image in 0.0725 seconds on a modern graphics processing unit.
Conclusion
The proposed method enhances the detail and tone of medical images. It addresses computational challenges inherent in traditional approaches. Its adaptability to diverse applications suggests a promising avenue for improving diagnostic accuracy and patient outcomes in clinical practice.
Introduction
Medical images such as X-rays, computer tomography (CT) scans, magnetic resonance images (MR), laser scanning confocal microscope (LSCM), and ultrasound are vital sources of detailed biological and anatomical tissue information crucial for clinical diagnosis and treatment by healthcare professionals. 1 Capturing conditions and technical limitations often lead to deficiencies in medical images, such as low contrast and poor visibility. Studies of Philip et al. 2 and Macgillivray et al. 3 have indicated that a significant amount of medical images are not of sufficient quality for screening and diagnosis. Furthermore, the deficiencies in medical images would impede the subsequent image analysis tasks.
Driven by the aforementioned factors, there is a pressing need to overcome the deficiencies in medical images. The most popular traditional medical image enhancement methods are based on histogram equalization 4 and its variants.5–7 The histogram-based methods are efficient, but they fail to consider the spatial information and thus may be subjective to the discontinuity between neighboring regions. Another type of traditional medical image enhancement methods rely on the edge-preserving filter, such as the bilateral filter, 8 guided image filter, 9 and bilateral weighted least squares (WLS) filter. 10 However, these filters may exhibit the halo or gradient reversal artifacts. The last type of medical image enhancement methods is based on neural networks, which have been widely applied to MRI and CT images.11–13 The deep learning-based methods are effective, but they typically require a large amount of labeled data to train the model, which is time- and resource-intensive.
As a global image processing technique, the WLS model 14 provides a prevalent framework for detail and tone manipulation, as it produces promising image quality and does not suffer from the halo and gradient reversal artifacts. However, due to the large sparse inhomogeneous Laplacian matrix in the linear system, the WLS model can be rather time-consuming to solve. To accelerate the image processing based on the WLS, researchers attempt to approximate the two-dimensional (2D) process as multiple one-dimensional (1D) processes.15,16 The strategy certainly improves the efficiency, but it would also introduce the streak artifacts and sabotage the quality. The recent development of the deep learning technique provides the researchers with a new tool to explore the possibility of approximating the results of the WLS with neural networks.17–20 However, these methods are either inflexible in tuning parameters or poor in processing quality.
The objective of this article is to develop an efficient and accurate solution to the WLS model for the detail and tone enhancement of medical images. Different from the histogram-based methods,4–7 the proposed method considers the spatial information, thus not being prone to discontinuity between neighboring regions. Unlike the state-of-the-art image enhancement methods based on neural networks,21–23 our method is free of the tedious labor used to define the vague labels of the images. Different from existing filter-based methods,8–10 the proposed method is based on the WLS of the gradients, thus alleviating the halo and gradient reversal artifacts. The naive solution to the WLS model can be time-consuming, thus we propose a fast WLS solution. Unlike existing 1D approximate solutions,15,16our method focuses on the solution in the 2D space, thus being immune to the streak artifacts. Compared to the learning-based approximate solutions,17–20 our method supports parameter tuning, thus being more flexible.
The main contributions of this article are:
We decouple the gradient regularization from the weighted scheme. It breaks the foundation of the inhomogeneous Laplacian matrix that leads to high computation costs. We propose a novel iterative solution to the WLS model, which is highly efficient. Our method outperforms existing fast WLS methods in various quality evaluation metrics on the detail and tone enhancement of medical images.
The rest of this article is organized as follows. The “Literature review” section covers the works closely related to our method. The “Proposed method” section provides detailed descriptions of the proposed method. In the “Applications” section, we demonstrate how the proposed method can be applied to the detail and tone enhancement of the medical images. The experimental settings and results are presented in the “Experiment settings” and “Results” sections, respectively. The “Discussion” and “Limitations” sections are presented afterwards. Finally, we conclude the article in the “Conclusion and future work” section and present possible directions for future research.
Literature review
The WLS model 14 is among the most prevalent frameworks for the tone and detail manipulation of images. It aims to minimize the sum of squared errors regularized by the weighted sum of the squared gradients, which is mathematically equivalent to the anisotropic diffusion model 24 with a nontrivial steady state. A key advantage of the model lies in that it substantially mitigates halo effects and gradient reversal artifacts. The suppression of these artifacts significantly improves the overall visual quality of enhanced images. However, despite its effectiveness, the practical implementation of the WLS model presents computational challenges. Specifically, the model requires the solution of a large linear system involving a sparse Laplacian matrix, which poses significant demands on both processing time and memory resources. The computational burden limits the scalability and applicability of the model in real-time or resource-constrained environments.
Numerous efforts have been dedicated to accelerating the solution of the WLS model, driven by the need to address its computational inefficiencies. Min et al. 16 approximated the linear system defined over 2D space with multiple linear systems that are defined over 1D space, so that the large sparse coefficient matrix would become a more manageable tridiagonal matrix, which can be efficiently solved using established numerical techniques. Similarly, Liu et al. 15 seek to approximate the 2D image processing task with multiple 1D ones. However, rather than constructing a four-connected or an eight-connected neighborhood, they adopt a zig-zag neighborhood construction scheme. This innovative strategy allows them to incorporate essential 2D neighborhood information while still capitalizing on the efficiency of 1D processing. Both of the two methods16,15 achieve significant speedups, but the separated 1D processing would cause the streak artifacts.
In recent years, inspired by the booming advancement of deep learning techniques, researchers have started to investigate learning-based methods to approximate the results of the WLS model. A notable contribution in this domain is by Xu et al., 18 who propose a neural network architecture that learns the gradients of the output in a supervised manner. These learned gradients are subsequently utilized to reconstruct the images. Further contributions are illustrated by Chen et al., 17 who design a fully convolutional network that incorporates dilated convolution. This technique significantly widens the receptive field of the network, thus enabling it to capture more contextual information, which translates to improved image quality. Wu et al. 19 attempted to learn the results of the WLS model in low-resolution (LR) space, then upsample the LR results to high-resolution with the trainable guided filtering layer. Thanks to the downsample-process-upsample strategy, the method significantly improves the computational efficiency. However, a common limitation among these learning-based approaches18,17,19 is their lack of support for parameter tuning, which makes them less adaptable to various image processing tasks. To overcome this limitation, Yang et al. 20 proposed an unsupervised learning framework to approximate the results of the WLD model. Different from existing supervised learning-based methods, which require a huge amount of training data with ground truth labels, unsupervised training can be less costly. Nevertheless, the fixed structure of neural networks employed within this framework confines the solution space, which consequently affects the accuracy of the approximations.
In summary, while the original WLS solution delivers promising results, its computational demands are significant. The 1D approximations15,16 of the WLS solution are computationally efficient but often introduce streak artifacts. Furthermore, existing deep learning-based approximations18,17,19,20 show potential for the task, but they frequently suffer from limited flexibility or compromised output quality. Therefore, it is imperative to develop a fast solution to the WLS model that not only produces high-fidelity results but is also highly efficient.
Proposed method
Theoretical background
The WLS model
14
is given as follows:



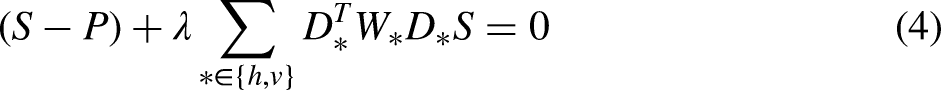

Proposed solution
Different from existing fast solutions that either explore 1D approximation or deep learning-based approximation, in this article, we focus on the WLS model defined over the 2D space. We decouple the gradient regularization from the weighted scheme so that we would have a constrained optimization problem. Then we introduce the augmented Lagrangian multipliers to transform it back into an unconstrained but decoupled optimization problem, which can be optimized alternatively. Each iteration of our solution consists of a least squares problem, together with two elementwise updates. Due to the fact that the Laplacian matrix in the least squares problem is homogeneous, the problem can be efficiently solved in the Fourier domain.
Specifically, we first introduce an auxiliary variable
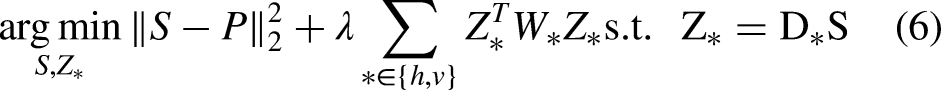




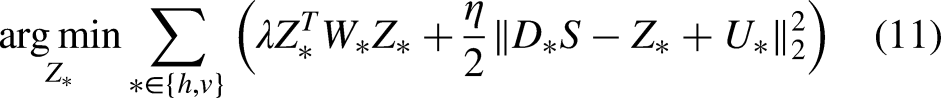

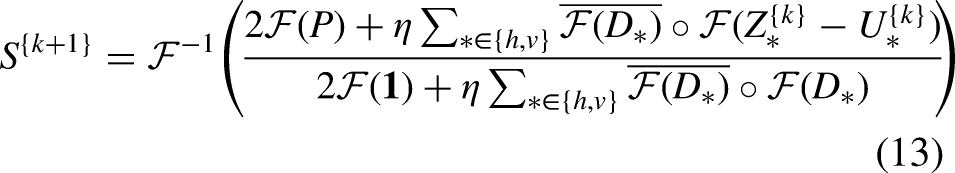
Equation (11) can be conveniently solved as follows:

Equation (12) can be optimized as follows:

The proposed method
Akin to the original WLS model, there are three tunable parameters in our method, that is, λ, α, and K. The former two control the smoothness of the resultant images, while the third one is used to control the approximation accuracy. The recommended ranges for these parameters are
Applications
Due to the limitations of existing medical imaging systems, medical images may be subjected to poor visibility and insufficient details, thus necessitating detail and tone enhancement. The proposed method can facilitate both of the two tasks. In this section, we will detail the procedure of applying the proposed method to these two tasks.
Detail enhancement
For convenient and clear descriptions, we denote the function provided by Algorithm 1 as 



The pipeline of the detail enhancement scheme.

An example of the detail enhancement process: (a) input, (b) base layer, (c) detail layer, and (d) detail-enhanced image.
Figure 3 demonstrates a visual comparison between the proposed method and popular detail enhancement techniques, including histogram equalization and bilateral filtering. It is evident that histogram equalization fails to significantly enhance the details of the image. The bilateral filter enhances the details, but it suffers from the halo artifacts (see the alphabet A). In contrast, our method properly enhances the details while being free of the artifacts.

Visual comparison to popular detail enhancement methods on (a) an input X-ray image. The details in the result of (b) histogram equalization are not significantly enhanced. The result of (c) bilateral filter suffers from the halo artifacts (see the alphabet A). In contrast, the details are properly enhanced in (d) our result without suffering from artifacts.
Tone enhancement
According to the retinex theory,
25
the observed image 




The pipeline of the tone enhancement method.
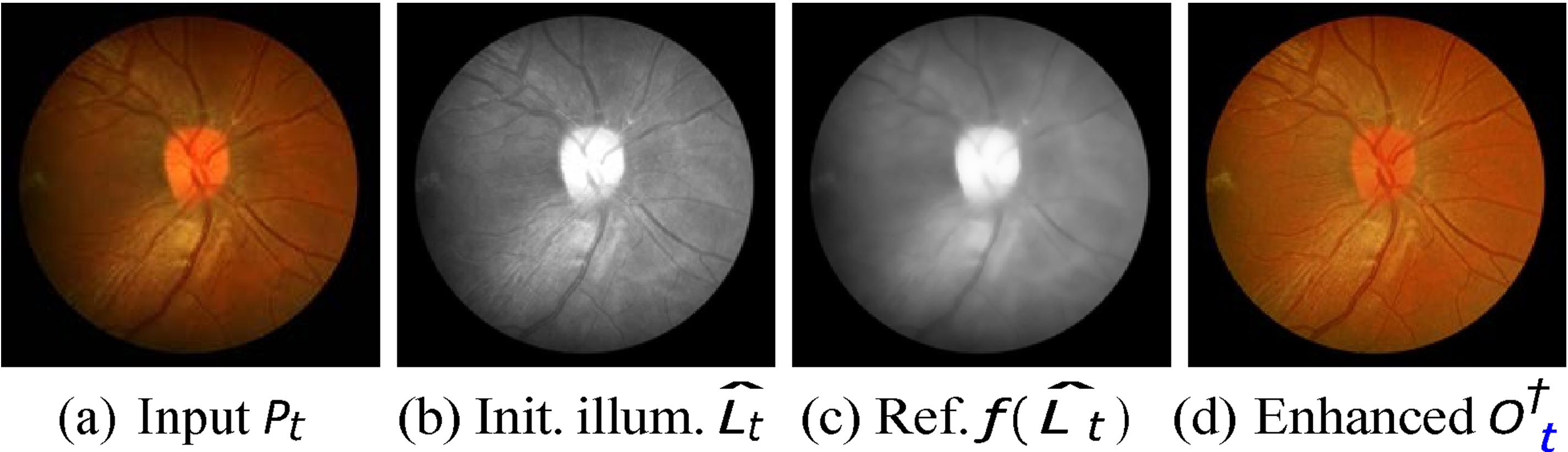
An example of the tone enhancement process: (a) input image, (b) initial illumination map, (c) refined illumination map, and (d) tone-enhanced image.
The visual comparison on the task of tone enhancement is shown in Figure 6. It can be observed that histogram equalization struggles with insufficient contrast. While the bilateral filter addresses the contrast issue, it lacks fine details. Conversely, our method produces a vivid tone-enhanced result with adequate contrast and details.

Visual comparison to popular tone enhancement methods on (a) an input fundus image. The result of (b) histogram equalization lacks contrast. The result of (c) bilateral filter lacks details. Conversely, (d) our result is of high quality.
Experiment settings
We have experimented with the proposed method on the detail and tone enhancement of medical images. For the former one, we use the COVID-19 chest X-ray image dataset 26 (317 X-ray images) and a subset (243 CT and MRI images) from the CHAOS dataset. 27 For the latter one, we leverage the retinal fundus image dataset named CHASE-DB1, 28 which consists of 28 retinal images collected from 14 children. The proposed method is rigorously evaluated using the test sets from these datasets.
To comprehensively evaluate the proposed method, we compare it to a variety of fast WLS methods, including the WLS, 14 fast global WLS (FG-WLS), 16 semi-global WLS (SG-WLS), 15 deep edge-aware WLS (DE-WLS), 18 context aggregation WLS (CA-WLS) 17 deep guided WLS (DG-WLS), 19 and unsupervised WLS (UN-WLS). 20 It should be noted that for traditional methods, the parameters are best tuned, whereas for deep learning-based methods, we use the officially pretrained model, where the parameters are not tunable.
We employ both the perception-based and distortion-based image quality measures to quantitatively assess the proposed method. The perception-based measures for the task of detail enhancement include the spatial-spectral entropy-based quality (SSEQ) 29 and convolutional neural networks image quality assessment (CIQA). 30 The perception-based measures for tone enhancement are tone mapped image quality index (TMQI), 31 along with its subindices, that is, fidelity and naturalness. The distortion-based measures for both tasks are the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM). Furthermore, we demonstrate visual results for qualitative evaluation of the two tasks. It should be noted that for SSEQ and CIQA, smaller values indicate better quality, while for TMQI, PSNR, and SSIM, larger values correspond to better quality. Finally, we record and compare the running times of various methods.
Results
Detail enhancement
The perception-based quality metrics of detail enhancement on the X-ray dataset and CHAOS subset are shown in Table 1 and Figure 7, respectively. It can be drawn that our method consistently achieves a better perceptual quality (including both SSEQ and CIQA) than existing fast WLS methods across all the datasets involved. In fact, our method delivers a comparable perceptual quality to that of the original WLS method. This can be explained by the distortion-based quality metrics of detail enhancement shown in Figure 8, where we see that for different sets of parameters, our method could accurately approximate the results of the original WLS method. Specifically, considering there are 10 iterations (i.e. the value that we use throughout the article), our method could achieve PSNR
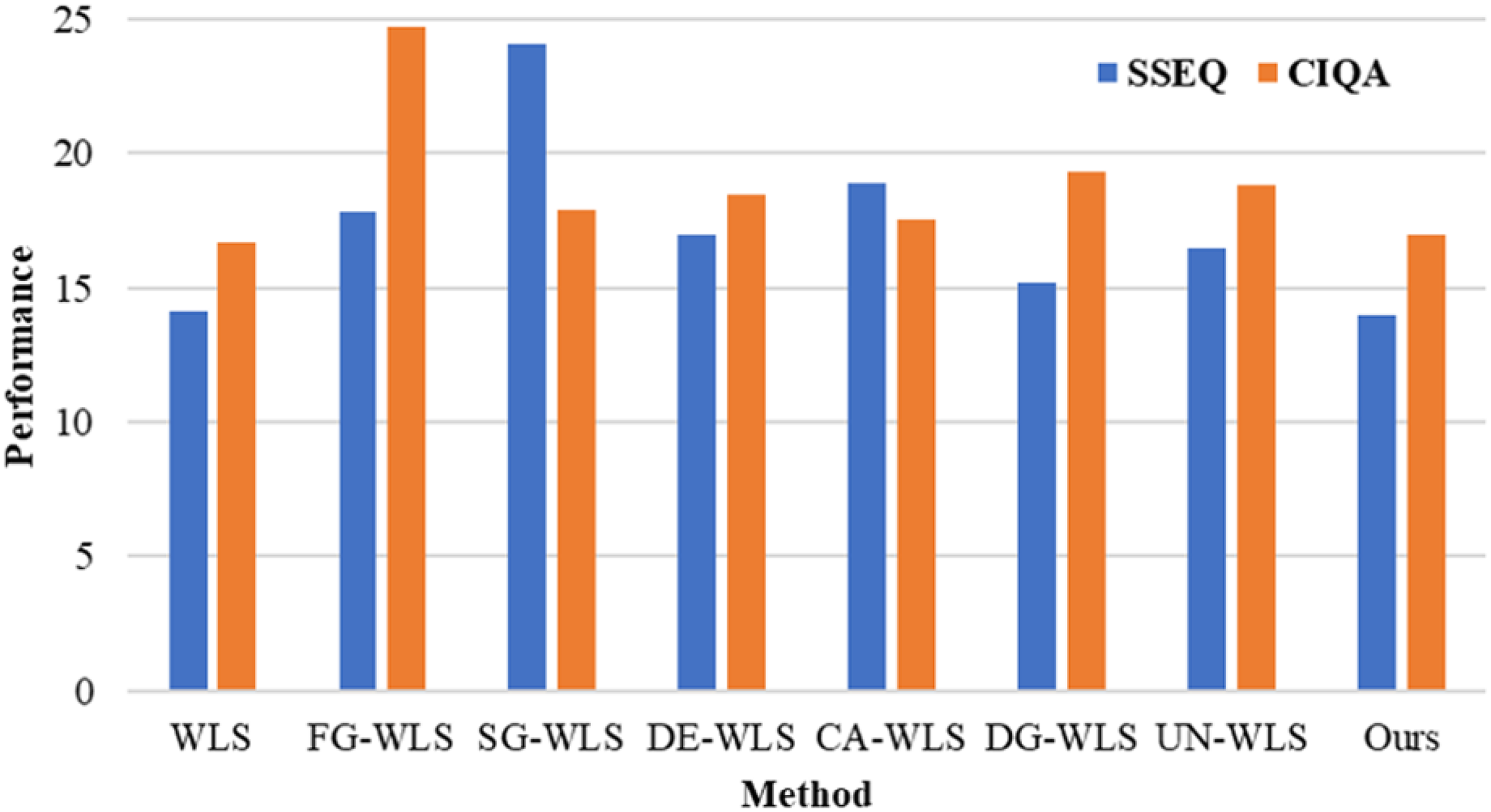
The perception-based quality measures of detail enhancement on the CHAOS subset 27 (CT and MRI images). Smaller values of SSEQ and CIQA indicate better quality. CT: computer tomography; MRI: magnetic resonance images; SSEQ: spatial-spectral entropy-based quality; CIQA: convolutional neural networks image quality assessment.

The distortion-based quality measures for detail enhancement on the X-ray dataset. 26 Larger values of PSNR and SSIM indicate better quality. PSNR: peak signal-to-noise ratio; SSIM: structural similarity index.
The perception-based quality measures of detail enhancement on the COVID-19 X-ray dataset. 26

SSEQ: spatial-spectral entropy-based quality; CIQA: convolutional neural networks image quality assessment; WLS: weighted least squares; FG-WLS: fast global weighted least squares; SG-WLS: semi-global weighted least squares; DE-WLS: deep edge-aware weighted least squares; CA-WLS: context aggregation weighted least squares; DG-WLS: deep guided weighted least squares; UN-WLS: unsupervised weighted least squares.
The superiority of our method on detail enhancement can be also validated from the qualitative results on an X-ray image shown in Figure 9. We can see that due to the separated 1D implementation, FG-WLS suffers from severe streak artifacts (check the areas above the pelvis). UN-WLS does not suffer from artifacts, but its result is of insufficient details. Furthermore, it tends to deviate the color of the image. On the other hand, our method is able to derive a promising result, which is comparable to that of the original WLS method. In the meantime, our method can be much more efficient than WLS. This advantage is further supported by the qualitative results on a CT image presented in Figure 10.

Qualitative results of detail enhancement on (a) an input X-ray image. The result of (b) FG-WLS suffers from the streak artifacts (see the areas above the pelvis). The result of (c) UN-WLS contains insufficient details. (e) Our result is as good as that of (d) WLS, but it can be derived in a much more efficient way. WLS: weighted least squares; FG-WLS: fast global weighted least squares; UN-WLS: unsupervised weighted least squares.

Qualitative results of detail enhancement on (a) an input CT image. The result of (b) FG-WLS suffers from the gradient reversal artifacts (around salient edges). The result of (c) UN-WLS lacks details. (e) Our result is of high quality akin to the result of (d) WLS, but is achieved in a significantly more efficient manner. CT: computer tomography; WLS: weighted least squares; FG-WLS: fast global weighted least squares; UN-WLS: unsupervised weighted least squares.
Tone enhancement
The perception-based quality metrics of tone enhancement are shown in Table 2. It can be observed that our method outperforms existing fast WLS methods in terms of perceptual quality, including TMQI and its subindices. As a matter of fact, our method delivers a comparable perceptual quality to that of the original WLS method. This can be observed from the distortion-based quality metrics illustrated in Figure 11, where our method accurately approximates the results of the original WLS method for various sets of parameters. Specifically, considering there are 10 iterations (i.e. the value that we use throughout the article), our method achieves PSNR

The distortion-based quality measures for tone enhancement. Larger values of PSNR and SSIM indicate better quality. PSNR: peak signal-to-noise ratio; SSIM: structural similarity index.
The perception-based quality measures on tone enhancement.

TMQI: tone mapped image quality index; WLS: weighted least squares; FG-WLS: fast global weighted least squares; SG-WLS: semi-global weighted least squares; DE-WLS: deep edge-aware weighted least squares; CA-WLS: context aggregation weighted least squares; DG-WLS: deep guided weighted least squares; UN-WLS: unsupervised weighted least squares.
The qualitative results shown in Figure 12 further corroborate the advantages of our method. It is evident that FG-WLS suffers from noticeable streak artifacts (as seen in the top-right corner of the circle). While UN-WLS does not exhibit artifacts, its output lacks contrast and details. Conversely, our method yields an impressive result, which is almost identical to the original WLS method. At the same time, our method is notably more efficient than WLS.
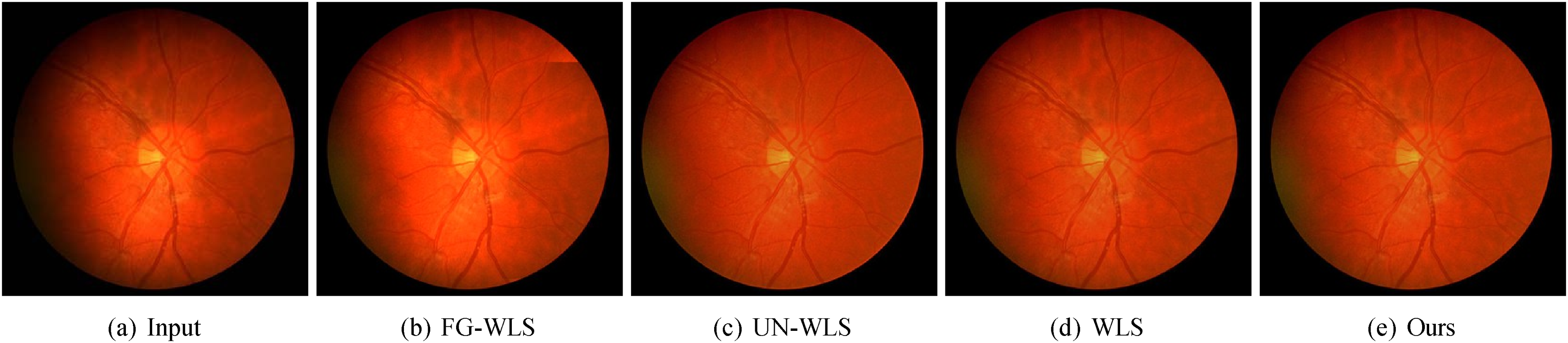
Qualitative results of tone enhancement on (a) an input fundus image. The result of (b) FG-WLS is affected by the streak artifacts (see the top-right corner of the circle). The result of (c) UN-WLS lacks contrast and details. (e) Our result is equally impressive as that of (d) WLS while being much faster to derive. WLS: weighted least squares; FG-WLS: fast global weighted least squares; UN-WLS: unsupervised weighted least squares.
Efficiency
The objective of this article is to develop an efficient solution to the WLS model. Therefore, the running time is a crucial evaluation metric in this article. To this end, we implement our method on both central processing unit (CPU) and graphics processing unit (GPU), and compare its running time to that of existing methods. The running times reported are recorded on an AMD Ryzen 4800H, an NVIDIA RTX 3070 (8 GB GDDR6), and 16 GB main memory. Note that the time is measured in seconds. The running time comparison is shown in Table 3. We can see that our method is faster than most of the existing WLS solutions, except DG-WLS. However, the high accuracy of DG-WLS is attributed to the downsampling-processing-upsampling strategy, which processes the image at LR, and then upsamples it with the assistance of a high-resolution input image. The strategy would significantly accelerate image processing, but it would also sacrifice the image quality, as demonstrated in the previous sections. Our method is highly efficient, it is able to process 720P color images at more than 13 frames per second. Compared to the original WLS, our CPU implementation is about 10 to 14 times faster, our GPU implementation is about 28 to 142 times faster. This validates the fact that our method is a fast solution to the WLS model.
Running times of various methods on images with different resolutions (measured in seconds).

WLS: weighted least squares; FG-WLS: fast global weighted least squares; SG-WLS: semi-global weighted least squares; DE-WLS: deep edge-aware weighted least squares; CA-WLS: context aggregation weighted least squares; DG-WLS: deep guided weighted least squares; UN-WLS: unsupervised weighted least squares; CPU: central processing unit; GPU: graphics processing unit.
Parameters
The parameters λ, α, and K have a significant impact on the enhanced results, as demonstrated in Figure 13. Specifically, the balancing parameter λ and the edge amplitude α control the spatial scale of the elements to be enhanced, that is, larger values of λ and α render more elements to be recognized as details, thus enabling the proposed method to enhance larger-scale details. The iteration count K determines the accuracy in approximating the original WLS solution. A larger value of K corresponds to a better approximation accuracy. Empirically, the enhanced images would barely change when

The impact of parameters on the enhanced results. λ: balancing parameter; α: edge amplitude; K: iteration count.
Discussion
Our method achieves impressive results as demonstrated in the previous sections. However, the performance can be further improved by tuning the best parameters for individual images. An important common task for various applications is automatic parameter setting. To this end, the images with the best quality need to be chosen through meticulously designed subjective and objective studies. This can be done by gathering a diverse set of images and having them rated by professionals to ensure a comprehensive understanding of what constitutes “best” in different applications. Then the relationship between the optimal parameters and the image features, such as brightness, contrast, texture, and color distribution can be established with supervised learning. The importance of features can be determined according to the perception-based image quality. By understanding how these features correlate with the optimal parameters, we can develop models or algorithms that predict the parameter settings for new images based on their features.
In this article, we experiment with the proposed method on the detail enhancement of the X-ray images and the tone enhancement of the retinal fundus image. For the X-ray images, our focus is on enhancing fine details that are crucial for accurate diagnosis. For the retinal fundus images, which capture the inner surface of the eye, including the retina, optic disc, macula, and blood vessels, our method focuses on improving the tone and contrast. These images are essential for diagnosing and monitoring various ocular diseases, such as diabetic retinopathy, glaucoma, and age-related macular degeneration. However, our method is not limited to only detail enhancement or tone enhancement. As a matter of fact, these two enhancement techniques can be used in combination to improve the overall quality of the images, thereby providing clearer and more detailed visual information for medical practitioners.
Enhanced image quality can lead to better visualization of critical structures and pathologies, which results in more accurate diagnoses and reduces chances of misdiagnosis. Furthermore, improved diagnostic capabilities can lead to earlier detection and treatment of conditions, ultimately enhancing patient outcomes and satisfaction. The proposed method can be integrated into clinical workflows by developing plugins or modules with user-friendly interfaces and embedding them into radiology software. The enhanced images can be also linked to the electronic health records, which allows for seamless access to improved images alongside patient history and other relevant data. However, technical challenges may arise when integrating the new method with existing imaging systems and workflows as it requires significant IT support and resources. Moreover, the proposed method must undergo rigorous validation to ensure its safety and efficacy in clinical settings. Obtaining regulatory approval can be a lengthy and complex process.
Limitations
While the proposed method for detail and tone enhancement in medical images shows promising results, several limitations need to be taken into account:
The effectiveness of the proposed method may diminish when applied to images with extreme noise levels. Medical images may contain significant noise due to various factors such as low signal-to-noise ratios, patient movement, or equipment limitations. In these situations, the enhancement process may inevitably amplify the noise rather than the relevant features, thus leading to degraded image quality. This limitation suggests that additional preprocessing steps, such as advanced denoising techniques, may be necessary to improve the performance of the proposed method on images with heavy noise.
The performance of the proposed method is likely to be compromised when dealing with very LR images. LR images inherently lack detail, which can impede the enhancement process. The proposed method relies on the presence of sufficient image information to effectively enhance details and tones. In scenarios where the resolution is too low, the method may struggle to produce meaningful enhancements, thus resulting in images that appear blurred or lack clarity.
Although the method has been validated on specific types of medical images, such as COVID-19 chest X-rays, MRI, CT, and retinal fundus images, its applicability to other imaging modalities (e.g. ultrasound and endoscopy images) or non-medical images remains uncertain. Different imaging techniques possess unique characteristics, such as varying noise profiles, contrast levels, and types of artifacts. As a result, the performance of the proposed method may not be consistent across all image types.
Conclusion and future work
In this article, we propose an efficient WLS method for the detail and tone enhancement of the medical images. To this end, we propose to firstly decouple the gradient regularization from the weighted scheme so that the foundation of the inhomogeneous Laplacian matrix is broken. Then we propose a novel solution based on the ADMM and the Fourier domain optimization. Different from existing deep learning-based approximations of the WLS method, our method support parameter tuning, which are more flexible. Different from existing separated 1D implementations, our method focuses on 2D image processing, thus being free of the streak artifacts. The proposed method is highly efficient, it is able to process 720P color images in real time. To evaluate the proposed method, we experiment with the proposed method on the detail enhancement of the X-ray images and the tone enhancement of the retinal fundus images. A variety of perception- and distortion-based image quality measures are leveraged, including SSEQ, CIQA, TMQI, PSNR, and SSIM. Both quantitative and qualitative results substantiate the superiority of the proposed method.
There are several promising directions for future research and applications. The enhanced image quality produced by our method could be integrated into automated diagnostic systems to improve the accuracy of image analysis and interpretation. For instance, by providing clearer and more detailed images, the method could assist radiologists and ophthalmologists in diagnosing conditions such as diabetic retinopathy, glaucoma, and other ocular diseases more effectively. Furthermore, the versatility of the proposed method allows for its potential application across various medical imaging modalities, including endoscopy, and ultrasound images. Future research endeavors will focus on extending the applicability of our method to additional imaging modalities. Besides, creating user-friendly software tools that incorporate our method could facilitate its adoption by medical professionals. Such tools could provide intuitive interfaces for image enhancement, which allows clinicians to easily improve image quality without requiring extensive technical knowledge. Finally, even though the proposed solution is highly efficient, it is not yet ready for extremely high-resolution images. Further efforts are needed to improve the solution. Possible directions include the moth-flame,32,33 cuckoo,34,35 multi-verse,36,37 and chimp38,39 optimization algorithms.
Footnotes
Acknowledgements
We would like to express our deepest gratitude to the people who developed the dataset involved in this article, including Pranav Raikote and Christopher G. Owen, etc.
Contributorship
YY and WB: conceptualization; WD, WB, and YY: data curation; WB, WD, and YY: methodology; WB, QZ, QG, SB, and YY: formal analysis; YY: supervision; WB, QZ, QG, SB, and YY: validation; WB: writing–original draft; WD, QZ, QG, SB, and YY: writing–review and editing.
Consent statement
Patient consent was not required for the present manuscript, as the datasets in this study are publicly available.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethics approval
Not applicable.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was funded by National Natural Science Foundation of China (Ref: 61402205), China Postdoctoral Science Foundation (Ref: 2015M571688), Jiangsu University (Ref: 13JDG085), Jiangsu Province Elderly Health Project (Ref: LD2021039), and Zhenjiang Key Laboratory of Health and Life Sciences (Ref: GZSYS202304).
Guarantor
YY.