
Abstract
Objective
This study aims to address the challenge of privacy-preserving Alzheimer’s disease classification using federated learning across various data distributions, focusing on real-world applicability. The goal is to improve the efficiency of classification by minimizing communication rounds between clients and the central server.
Methods
The proposed approach leverages two key strategies: increasing parallelism by utilizing more clients in each communication round and increasing computation per client during the intervals between rounds. To reflect real-world scenarios, data is divided into three distributions: identical and independently distributed, non-identical and independently distributed equal, and non-identical and independently distributed unequal. The impact of extreme quantity distribution skew is also examined. A convolutional neural network is used to evaluate the performance across these setups.
Results
The empirical study demonstrates that the proposed federated learning approach achieves a maximum accuracy of 84.75%, a precision of 86%, a recall of 85%, and an F1-score of 84%. Increasing the number of local epochs improves classification performance and reduces communication needs. The experiments show that federated learning is effective in handling heterogeneous datasets when all clients participate in each round of training. However, the results also indicate that extreme quantity distribution skew negatively impacts classification performance.
Conclusions
The study confirms that federated learning is a viable solution for Alzheimer’s disease classification while preserving data privacy. Increasing local computation and client participation enhances classification performance, though extreme distribution imbalances present a challenge. Further investigation is needed to address these limitations in real-world scenarios.
Introduction
Neurodegenerative disorder mild cognitive impairment (MCI) is characterized as the prodromal stage of cognitive decline that falls between normal aging and the onset of dementia.1–4 It is estimated that
AD is a severe and progressive neurological condition that manifests through a range of cognitive impairments, including gradual memory loss, reasoning difficulties, behavioral changes, communication issues, motor dysfunction, and impaired daily activities, among other cognitive deficits.10–13 The pathology of AD is characterized by abnormal proteins that disrupt brain cells and neurons, leading to the breakdown of signal transmitters crucial for memory retention. 14 AD extends beyond the realm of clinical symptoms; it has profound social, economic, and global implications. 15 The burden on caregivers, often family members, is immense, encompassing emotional, financial, and practical challenges. 16
According to the World Alzheimer Report 2021, Alzheimer’s Disease International (ADI) has reported that up to 75% of people with dementia worldwide remain undiagnosed, and this figure may be as high as 90% in some low- and middle-income countries, where stigma and lack of awareness about dementia pose significant barriers to diagnosis. The number of people living with dementia has surpassed 55 million globally, and this number continues to grow, with projections indicating it could reach 78 million by 2030. 14 The socioeconomic impact of dementia is also substantial, with the worldwide cost expected to have exceeded US$1.3 trillion in 2019 and predicted to rise to over US$2.8 trillion by 2030 due to the increasing number of individuals living with dementia and the associated caregiving expenses. 17 Consequently, it is imperative to focus on preventive measures to combat this debilitating disease for the sake of both healthcare and the economy.
While the precise causes of AD are still a subject of ongoing research, several risk factors have been identified. These risk factors include genetics, family history, head injuries, down syndrome, heart disease, diabetes, stress, stroke, high blood pressure, high cholesterol, and, notably, age.18,19 There are promising anti-amyloid treatments (e.g. aducanumab, lecanemab, etc.) that are clinically indicated in patients with earlier stages of AD, so earlier and accurate detection of AD is important when considering the potential use of these medications.
To detect AD, conventional centralized machine learning models require data to be transmitted to a central server, posing significant privacy vulnerabilities. In contrast, federated learning (FL) offers a methodology for model training that eliminates the need to centralize data, thereby safeguarding the privacy of individuals or entities providing their data. This privacy-preserving approach aligns with the imperative need to protect the confidentiality of such information in an era where data security and privacy concerns are paramount. As such, in this study, we have employed FL to classify AD.
FL is a machine learning paradigm that involves training a model using data from multiple clients, such as mobile phones, tablets, and hospitals, without the need to directly share sensitive training data. This collaborative approach is often facilitated by a central server that orchestrates the learning process.20–22 There are two common settings for FL, which are determined by the network’s size and characteristics: cross-device FL and cross-silo FL.
23
Cross-device FL pertains to scenarios where numerous clients participate, each having limited data, bandwidth, and availability, such as mobile devices, laptops, and tablets. In contrast, cross-silo FL involves a smaller number of clients, but each possesses more substantial resources, including institutions like banks, schools, and hospitals. Notably, in cross-silo FL, each client is required to actively engage in the entire training process, which is feasible due to the limited number of clients, typically ranging from two to 100. Figure 1 provides a visual representation and working mechanism of the FL. This privacy-preserving mechanism has significant potential applications in areas like privacy-preserving disease detection and classification. The abovementioned works of FL (explained in more detail in the literature review section) did not conduct experiments based on either different real-world scenarios or with the aim of reducing communication costs while classifying AD. Therefore, the novelty of this research is summarized below:
Conducted an empirical and rigorous study focused on the detection and classification of AD utilizing privacy-preserving FL. Generated synthetic dataset representative of real-world scenarios from the original dataset and conducted experiments to validate the approach’s efficacy. Implemented experiments exploring strategies of increasing parallelism and computation per client to reduce communication costs while classifying AD.

The working mechanism of federated learning (FL) framework. At each communication round
The rest of the article is organized as follows. The “Literature review” section delves into related literature, highlighting potential areas for further research. In the “Methods and materials” section, we describe our method for privacy-preserving AD classification using the FL scheme and provide the materials used in the experimental results analysis. The “Results and discussions” section furnishes the experimental outcomes and discussions, and finally, “Conclusion and future work” section presents the conclusion and outlines future research directions.
Literature review
This section provides several recent studies that were conducted by applying centralized learning (CL) and FL. To safeguard data privacy and address data heterogeneity issues, the researchers by Lei et al. 24 introduced a framework for multi-site federated domain adaptation based on the transformer model. They utilized the transformer to uncover relationships among features from multi-template regions of interest and to harness the complementary information from these templates. Their study encompassed three distinct datasets: the Alzheimer’s Disease Neuroimaging Initiative (ADNI), the Australian Imaging, Biomarker and Lifestyle Flagship Study of Aging (AIBL), and AI4AD data. They conducted both two-way classifications, distinguishing between AD versus healthy control (HC), MCI versus HC, and AD versus MCI, as well as a three-way classification task, separating AD, MCI, and HC. The results showed accuracy rates of 88.75%, 69.51%, and 69.88% for the two-way classification tasks involving AD versus HC, MCI versus HC, and AD versus MCI, respectively.
In their work, 25 the authors introduced an evolutionary deep convolutional neural network (EDCNN) designed for the identification of AD within a privacy-protected FL framework. Their primary emphasis was on convex optimization, to enhance the computational efficiency and accuracy of AD detection. The study involved the utilization of multimodal datasets, including MRI, EEG, and blood test data, each serving as a distinct node within the federated settings. The researchers by Huang et al. 26 dedicated their efforts to developing a privacy-preserving AD classification framework called federated conditional mutual learning (FedCM), designed for client-aware mutual learning. They validated their proposed framework using three different AD datasets: ADNI, Open Access Series of Imaging Studies (OASIS), and AIBL. They conducted two and three-class classifications on the labeled data, differentiating AD, MCI, and HC subjects. In the context of AD versus HC, they achieved remarkable results, attaining a maximum accuracy of 91.9%, a recall of 100%, and a specificity of 91.1% by applying three-dimensional-convolutional neural network (3D-CNN) to the OASIS dataset.
In another secure FL-based approach presented by the researcher, 27 the focus was on the neuroimaging modality. The authors implemented a fully homomorphic encryption mechanism to ensure secure communication and aggregation. They tested their method with the AD datasets (ADNI, OASIS, and AIBL) and the 3D-CNN model. They trained the neural model using three (ADNI phases), four (ADNI phases + OASIS), and five (ADNI phases + OASIS + AIBL) learners or clients. The best performance was achieved with a five-learner setup, resulting in an accuracy of 86%, precision of 80.98%, recall of 81.32%, and an F1-score of 81.14% when considering the ADNI, OASIS, and AIBL datasets. Using the same five learners, the authors achieved an accuracy of 86.12%, a precision of 79.77%, a recall of 82.87%, and an F1-score of 81.22% for centralized settings.
Movahed and Rezaeian 28 introduced a machine learning framework for diagnosing mild AD, focusing on extracting spectral, functional connectivity, and nonlinear features from EEG signals. They utilized the sequential backward feature selection (SBFS) algorithm to choose the most suitable feature subset. Multiple classifiers, including support vector machines (SVM) with linear and RBF kernels, logistic regression (LR), k-nearest neighbor (KNN), decision tree (DT), gentleBoost, naive Bayes (NB), and RushBoost (RB), were examined. Among the classifiers, SVM with 10-fold cross-validation (CV) exhibited the best performance.
Siuly et al. 3 devised a framework for distinguishing mild AD from HC. They employed the stationary wavelet transformation (SWT) method to eliminate low-frequency (including baseline drift) and high-frequency (including power line interference) noise. They analyzed data in non-overlapping 2-second sliding windows. The study introduced the piecewise aggregate approximation (PAA) technique. To evaluate their approach, they used extreme learning machines (ELM), SVM, and KNN with 10-fold CV. Plant et al. 29 proposed a classification framework for distinguishing AD from HC using frequency and time–frequency features extracted from EEG data. They conducted experiments under resting-state eyes open (EO) and eyes closed (EC) conditions, segmenting the EEG signal into 4-second windows. After preprocessing the data, they applied the KNN model with 10-fold CV.
Sarraf et al. 30 presented a method for AD and HC detection using CNN. They utilized MRI and fMRI as their experimental modalities, achieving accuracy rates of 99.9% and 98.84% for the fMRI and MRI pipelines, respectively. Khatun et al. 4 employed single-channel EEG data from Fpz (near the forehead) to classify individuals with MCI from those with normal cognitive functioning. They analyzed the data in 25 ms windows with a 50% overlap across the entire signal. For feature selection, they used the random forest (RF). As classifiers, they utilized SVM with a radial basis function (RBF) kernel and LR with leave-one-out CV.
For early AD detection, an empirical analysis was performed by McBride et al. 5 The researchers explored spectral and complexity features as EEG-based biomarkers to differentiate between normal older individuals, those with MCI, and AD subjects. They considered 24 features and calculated their average values for each channel and 12 brain regions, including left and right regions, as well as a global region representing the average of all regions. They devised a three-way classifier based on a two-way classifier (HC vs. MCI, HC vs. AD, and MCI vs. AD) using a pairwise coupling approach. They applied a quadratic kernel with an SVM classifier for classification under EO, EC, and counting task (CT) conditions.
Aghajani et al. 31 proposed a method for mild AD detection using EEG signals. They aimed to distinguish between healthy individuals and those with mild AD by mapping EEG signals to their corresponding distributed sources via standardized low-resolution brain electromagnetic tomography based on a realistic head model. They proposed using the relative logarithmic transformed power spectrum density of estimated sources as a feature. Singular value decomposition was employed to reduce the number of features and enhance separability.
Plant et al. 29 introduced a sulcal feature-based approach for classifying AD and HC. They computed various features of the sulcal medial surface, including depth, length, mean curvature, Gaussian curvature, and surface area. These features were used in conjunction with an SVM for classification. When tested using 10-fold CV, the model achieved an accuracy of 87.9%, sensitivity of 90.0%, specificity of 86.7%, and an area under the receiver operating characteristic curve (AUC) of 89%.
A comparison of the potentially related works is tabulated in Table 1. Several factors underlie the motivation for this planned research. While conventional CL has been extensively explored for disease detection and classification, limited attention has been given to employing FL. Those few researchers who have ventured into healthcare applications of FL have often omitted empirical analysis.
Comparison of the previously conducted relevant literature for the detection and classification of AD.

AD: Alzheimers disease; FL: federated learning; CL: centralized learning; MRI: magnetic resonance imaging; fMRI: functional magnetic resonance imaging; EEG: electroencephalography; EDCNN: evolutionary deep convolutional neural network; SVM: support vector machine; KNN: k-nearest neighbor; 3D-CNN: three-dimensional convolutional neural network; ELM: extreme learning machine; LR: logistic regression; DT: decision tree; NB: Naive Bayes; RB: RushBoost; HC: healthy control; MCI: mild cognitive impairment; EO: eyes open; EC: eyes closed; CT: counting task; AUC: area under the receiver operating characteristic curve; CV: cross-validation.
Methods and materials
Method overview
Our primary goal is to optimize the efficiency of AD classification through advancements in the FL framework by minimizing the number of communication rounds required during model training. This reduction in communication demands additional computational input, a resource-intensive proposition that we address through two principal strategies: (1) increased parallelism, which entails engaging a larger cohort of clients to perform tasks concurrently during each communication round, leveraging their collective computational power to potentially accelerate the learning process while maintaining or reducing the frequency of required communications; and (2) increased computation per client, where each client is tasked with performing more complex computational tasks within each training cycle, such as advanced processing tasks that contribute to the model’s learning phase, thereby enriching the training process within the same communication interval. To ensure the relevance and applicability of our FL enhancements, we divide the original dataset into three distinct data distributions: identical and independently distributed (IID), non-IID equal, and non-IID unequal, each presenting unique challenges and scenarios that closely mimic the variety of real-world conditions under which FL systems must operate. This setup allows us to thoroughly test the resilience and adaptability of our proposed methodologies in different data environments, providing comprehensive insights into their effectiveness and potential areas for further refinement.
Firstly, the collected image data are preprocessed and then used to create IID, non-IID equal, and non-IID unequal synthetic datasets. These datasets are subsequently used for further experiments. The overview of the proposed methodology is depicted in Figure 2.

An overview diagram of the proposed framework for privacy-preserving AD classification using the FL scheme. AD: Alzheimers disease; FL: federated learning.
Dataset
Our experimental Alzheimer’s dataset contains 6400 T1-weighted MRI images from four classes, each 128
Statistical description of AD dataset.

AD: Alzheimer’s disease; HC: eyes closed.
Impact of the client fraction

Note:
Data preprocessing
This research employed fundamental image processing techniques to prepare the data dynamics for training. The preprocessing procedures are outlined below:
Normalization
Image normalization was carried out to scale every pixel in the image to a range between 0 and 1. This involves transforming the pixel intensity range of the image into a standardized scale, facilitating model learning, and enhancing training effectiveness.
38
Variations in lighting conditions, contrast levels, and color distributions among images can all introduce biases, which normalization helps mitigate. The steps involved in image normalization are as follows. The mean pixel value is subtracted from each pixel in the image, thereby eliminating any inherent data dynamics bias, resulting in pixel values centered at zero. Subsequently, the image is divided by the standard deviation of the pixel values, ensuring that the pixel values have a unit standard deviation. This helps to equalize the scale of different features within the image. Mathematically, it can be defined as follows:
Labeling
The dataset encompasses 416 subjects aged 18 to 96, with 3–4 T1-weighted MRI scans per subject. All subjects are right-handed and of both genders. Among those over 60, 100 have been clinically diagnosed with very mild to moderate AD. Additionally, a reliability subset includes 20 non-demented subjects imaged within 90 days of their initial session. On the other hand, the longitudinal data comprises 150 subjects aged 60–96, scanned at least twice over a year, totaling 373 imaging sessions. Each subject’s scans are obtained in single sessions. Of these subjects, 72 remain consistently non-demented, while 64 are consistently demented, including 51 with mild to moderate Alzheimer’s. Another 14 subjects transitioned from non-demented to demented over time.
Artificial partitioning (synthetic data creation) of centralized dataset
To create a synthetic dataset, we take a labeled centralized dataset and employ some scheme described below to pathologically partition the dataset among a set of Label distribution skew (prior probability shift). Consider a scenario with Data quantity disparity (unbalancedness or quantity skew). Furthermore, variations in the volume of data held by different clients can result in unequal levels of uncertainty in locally updated models and heterogeneity in the frequency of local updates. In real-world applications, the quantity of data may vary significantly among clients, with large institutions, such as hospitals, typically possessing considerably more medical records than smaller clinics. Notably, the distribution of data quantities frequently demonstrates a pattern where substantial datasets are primarily concentrated in a few specific locations, while a vast number of locations have smaller dataset sizes distributed across them.
38
In a non-IID equal distribution, the data quantity is equal, whereas in a non-IID unequal data distribution, the quantity varies. In our study, we’ll conduct an experiment based on IID, non-IID equal, and non-IID unequal distribution of our adopted Alzheimer’s dataset. Formally, for the IID settings let us standardize the stochastic optimization problem,


Federated setups
Cross-silo
A discrete entity or organization that manages and controls its unique dataset is commonly referred to as a data silo. When multiple data silos or distinct organizations collaborate to collectively train a unified global model, this variant of FL is recognized as cross-silo FL. Cross-silo FL represents a scenario in which there is a restricted count of participating clients, encompassing entities like banks, schools, and hospitals, each of which possesses more abundant resources. It’s noteworthy that these same data silos can be utilized in both the training phase and the subsequent inference stage. Specifically, in the context of cross-silo FL, the number of clients involved typically ranges from 2 to 100, as noted by Kairouz et al. 38
Client sampling
In cross-silo FL experiments, each client is required to engage in the full training process, since there are only a few clients (about 2–100), so the client sampling rate is 100% or
Federated algorithm
In our experimental setup, we employ the Federated averaging (FedAvg) algorithms to aggregate updates originating from each client, where each client
The FedAvg algorithm is recognized as the most straightforward aggregator method, as mentioned in the reference.
23
To express this mathematically,
Optimizers
For simplicity of hyperparameter tuning and experimental controls, we use minibatch stochastic gradient descent (SGD) for client-local training for all experiments.
Hyperparameters
In our experiment, we set clients to train for
Model structure
For image classification feed-forward deep networks, and in particular convolutional networks, are well-known to provide state-of-the-art results.39,40 Our experiments include a non-convex LeNet5 CNN model.
Evaluation protocol
To assess the efficacy of CNN-based FL settings for the classification of AD, this study employed various essential performance metrics. These metrics primarily rely on the widely used tool known as the confusion matrix. The confusion matrix is illustrated in Table 4. It serves as a performance assessment tool that summarizes the performance of the applied classification model by quantifying true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
Confusion matrix.

TP: true positives; TN: true negatives;FP: false positives; FN: false negatives.
TP: This represents the number of cases correctly predicted as positive. TN: This signifies the number of cases correctly predicted as negative. FP: It accounts for the instances where negative cases were incorrectly predicted as positive. FN: This denotes the count of positive cases erroneously predicted as negative.
Accuracy
Accuracy is defined as the ratio of correctly classified data instances to all data instances.
41
Mathematically,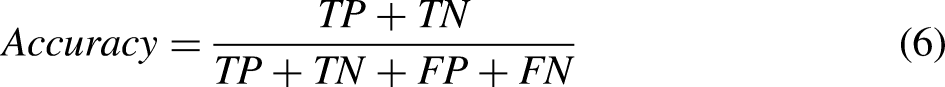
Precision
Precision evaluates the accuracy of the minority class.
42
Mathematically,
Recall
Recall quantifies how many of the actual positive cases were correctly identified among all positive instances.42,43 Mathematically,
F1-score
The F1-score is the harmonic mean of Precision and Recall.41,44 Mathematically:
Results
We first conducted our experiment based on increasing parallelism and then increasing computation per client approach. The findings are presented below:
Increasing parallelism
In the context of our experiment aimed at increasing parallelism, we kept the local epoch,
Increasing computation per client
In this approach of experiment, we fix

Depiction of convergence for the increasing computation per client experiment. (a) Test accuracy versus communication on the non-identical and independently distributed (IID) data distribution. (b) Test accuracy versus communication on the non-IID equal data distribution. (c) Test accuracy versus communication on the non-IID unequal data distribution.
Empirical results for the classification of AD according to increasing computation per client fashion.

AD: Alzheimers disease; IID: identical and independently distributed.
Comparison with previously conducted research using FL.
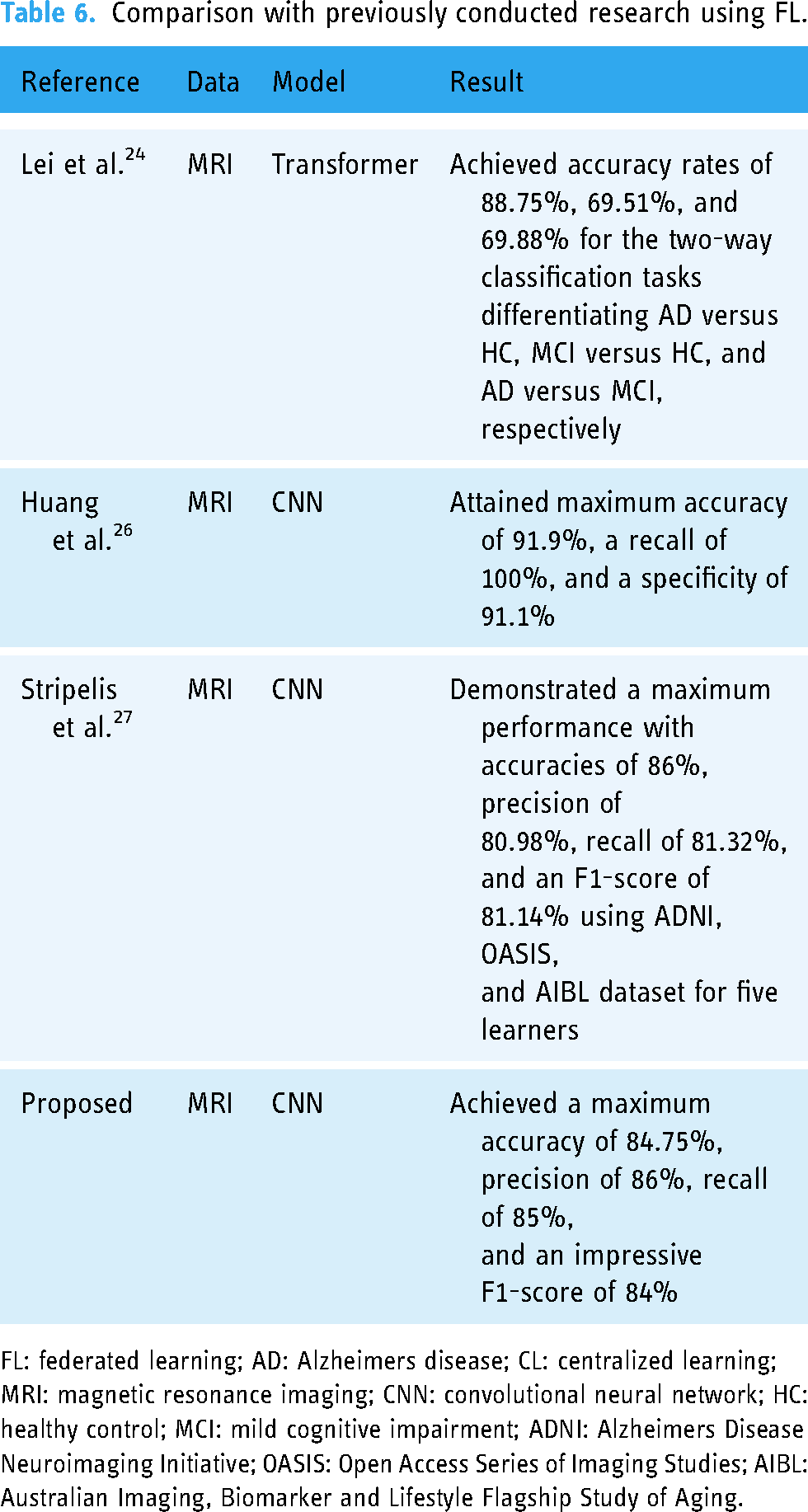
FL: federated learning; AD: Alzheimers disease; CL: centralized learning; MRI: magnetic resonance imaging; CNN: convolutional neural network; HC: healthy control; MCI: mild cognitive impairment; ADNI: Alzheimers Disease Neuroimaging Initiative; OASIS: Open Access Series of Imaging Studies; AIBL: Australian Imaging, Biomarker and Lifestyle Flagship Study of Aging.
Discussions
Data confidentiality in every field is crucial and highly demanded in the present world. With that in mind, this study focuses on the classification of AD using the emerging FL approach. The adopted FL approaches for privacy-preserving AD classification show comparatively satisfactory performance while keeping data private. The following explains this in great detail.
Increasing parallelism
In terms of this approach, the results are presented in Table 3. By selecting
Increasing computation per client
In our experiment, the result obtained by increasing computation per client is presented in Table 5. Involving the detection of AD using an IID data distribution, we attained optimal performance with 82.67% accuracy, 85% precision, 83% recall, and 81% F1-score when we set
For the scenario of non-IID equal data distribution, we achieved an accuracy of 77.81%, precision of 78%, recall of 78%, and an F1-score of 74% by configuring
In the case of a non-IID unequal data distribution, we obtained exceptional results by selecting
This study, while providing valuable insights, does possess several limitations that present opportunities for further investigation. The experimental results showcased herein are derived from a singular CNN model. Consequently, these findings could exhibit variability when replicated with alternative models or under different FL configurations. This suggests a potential area for future research to explore the robustness of our results across a broader range of models and settings. Additionally, the noted decline in classification performance attributed to quantity distribution skew is primarily based on empirical observations. A more comprehensive understanding could be achieved through theoretical analysis, which would provide a deeper insight into the underlying mechanisms affecting performance in varied data distribution scenarios. This dual approach of combining theoretical explorations with empirical validations could significantly enhance the generalizability and reliability of future studies.
In our study, privacy preservation is achieved through the fundamental structure of FL itself, where the raw data remains decentralized on the clients’ devices. The only information shared between the clients and the central server is the model weight updates (gradients), rather than the actual data, which ensures that sensitive information (such as the MRI scans) is not transmitted. This communication of weights during each training round inherently addresses privacy concerns by preventing data leakage. Moreover, while we have not implemented additional privacy-enhancing techniques like differential privacy or secure aggregation in this current work, the FL process alone already mitigates a large portion of privacy risks by keeping the data localized. The communication of only the model weights is a key mechanism to ensure privacy, as it abstracts the raw data from being accessible or shared across entities. However, we agree that adding such techniques could further strengthen privacy guarantees in future work.
Conclusion and future work
In this article, we have conducted an empirical and rigorous analysis of AD detection while prioritizing privacy preservation. Our study delves into strategies for increasing parallelism and computation per client to mitigate communication costs, as evidenced by experiments on AD classification. We have evaluated these methodologies across different data distributions: IID, non-IID equal, and non-IID unequal. Across all distributions, our selected approach has demonstrated satisfactory performance in AD detection. Note that the choice of the non-convex LeNet5 model in this article is driven by its established theoretical advantages and computational efficiency, which we believe suited our initial study aims. To support the robustness of our approach, our evaluation is conducted across diverse datasets, which demonstrated consistent performance. However, we recognize the need for further validation using a variety of models to fully ascertain the generalizability and robustness of our findings. Plans are underway to include additional CNN-based models in our future work to address these critical aspects comprehensively. In our current study, we focused on a four-class classification to demonstrate the capabilities of our proposed methodology in a more complex scenario. We acknowledge the importance of binary and three-class classifications as they may be fundamental in many clinical applications. While these were not included in this article, we are considering these simpler classification tasks for future work to provide a comprehensive evaluation of our methodology across different classification scenarios. This approach will allow us to further validate the versatility and applicability of our proposed methods. Looking ahead, our future research endeavors will focus on exploring personalized FL configurations aimed at developing models tailored to individual clients.
Furthermore, we aim to investigate the incorporation of differential privacy techniques to bolster the security of communication between the central server and each client. These directions promise to enhance both the effectiveness and privacy assurances of FL-based AD detection systems. In addition, to enhance the sophistication of AD detection, it would be beneficial to incorporate multi-modal data, such as blood-based data, PET scans, EEG, and other relevant sources. Applying test cases in active learning and validating the results through biological or medical data would be an important step in further assessing the scalability and robustness of the model in the future.
Footnotes
Acknowledgements
We thank the Computer Science and Engineering Department of Hajee Mohammad Danesh Science and Technology University, Bangladesh for supporting the study process.
Contributorship
Md Abdus Sahid: conceptualization, methodology, software, validation, data curation, data analysis, visualization, and manuscript drafting. Md Palash Uddin: conceptualization, methodology, resources, investigation, manuscript review, manuscript finalization, and supervision. Hasi Saha: investigation, manuscript review, and supervision. Md Rashedul Islam: co-supervision.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
This research is not subject to ethical approval since the research did not have participants (humans or animals).
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Guarantor
MPU.
Informed consent
In accordance with the ICMJE guidelines, we confirm that patient consent was not applicable to this study. This study did not involve human subjects, and all data were obtained from publicly available sources.