
Abstract
Objective
To construct applicable models suitable for predicting the risk of suicidal behavior among individuals with depression, particularly on the progression from no history of suicidal behavior to suicide attempts, as well as from suicidal ideation to suicide attempts.
Methods
Based on a prospective cohort from the UK Biobank, a total of 55,139 individuals aged 50 and above with depression were enrolled in the study, among whom 29,528 exhibited suicidal behavior. Specifically, they were divided into control (25,611), suicidal ideation (24,361), and suicide attempt (5167) groups. Least absolute shrinkage and selection operator (LASSO) regression was used to identify a subset of important features for distinguishing suicidal ideation and suicide attempts. We used the Gradient Boosting Decision Tree (GBDT) algorithm with stratified 10-fold cross-validation and grid-search to construct the prediction models for suicidal ideation or suicide attempts. To address the dataset imbalance in classifying suicide attempts, we used random under-sampling. The SHapley Additive exPlanations (SHAP) were used to estimate the important variables in the GBDT model.
Results
Significant differences in sociodemographic, economic, lifestyle, and psychological factors were observed across the three groups. Each classifier optimally utilized 8–11 features. Overall, the algorithms predicting suicide attempts demonstrated slightly higher performance than those predicting suicidal ideation. The GBDT classifier achieved the highest accuracy, with AUROC scores of 0.914 for suicide attempts and 0.803 for suicidal ideation. Distinctive predictive factors were identified for each group: while depression's inherent characteristics crucially distinguished the suicidal ideation group from controls, some key predictors, including the age of depression onset and childhood trauma events, were identified for suicide attempts.
Conclusions
We established applicable machine learning-based models for predicting suicidal behavior, particularly suicide attempts, in individuals with depression, and clarified the differences in predictors between suicidal ideation and suicide attempts.
Introduction
Suicide is a critical public health issue all over the world because one person dies by suicide every 40 s, leading to substantial personal, family, and economic burdens. 1 Suicides can occur at almost any age across the world, with 79% occurring in low- and middle-income countries, while the highest suicide rates are in high-income countries. 1 Despite various public-health efforts since the World Health Organization's (WHO) first global report on suicide in 2014, limited progress has been made in suicide prevention due to the lack of reliable methods for predicting suicidality and a poor understanding of suicide's biological etiology. 2 Current methods of predicting suicide still mainly rely on self-report measures, such as questionnaires and interviews, which can be too subjective. Therefore, developing effective models for predicting suicidality is crucial to preventing suicide, saving lives, and mitigating the societal risks and negative impacts of suicide.
Suicide is thought to be a complicated dimensional trait that encompasses a broad range of experiences and behaviors, ranging from suicidal ideation to acts of deliberate self-harm and attempted suicide, which occur along a spectrum toward committing suicide. 3 Though there are various risk factors for suicide (e.g., sociodemographic, biological, and psychological factors), studies have found that approximately 90% of individuals who die by suicide were diagnosed with a mental disorder prior to their death,2,4 and more than half of the persons who attempt suicide meet the criteria of Major Depressive Disorder (MDD). 5 Thus, depression and suicide, as independent mental health problems, have received increasing attention among researchers in recent years.
Given the complexity of suicide, recent research has focused on the risk for different components of suicide (e.g., suicidal ideation, non-suicidal-injury, and attempted suicide) and different population groups,6–9 using traditional statistical approaches. However, traditional approaches greatly reduce the number of predictors and interactions that can be examined simultaneously, and may mistake some more complex associations for linearity, thereby weakening the predictive power of findings. Machine Learning (ML) has been introduced into suicide prediction research to compensate for the deficiency of traditional statistical methods, by identifying novel risk factors and interactions, and improving prediction accuracy, with AUCs (Area Under the Curve) ranging from 0.71 to 0.89.10–13 However, research on suicide prediction, including limited research on depression and suicide, has yielded inconsistent and disparate findings, possibly due to relatively small sample sizes and the lack of external validation of models.
The present study was designed to examine suicide behavior in the general population using the UK Biobank, a very large and population-based prospective study, to confirm that depressive disorder is an important predictor of suicide. Moreover, we explored the associations among different stages of suicide in a depressive population and developed prognostic prediction models for suicidal behavior, with a particular focus on suicide attempts.
Methods
Study population
The UK Biobank is a well-characterized cohort study of over 500,000 adults, 40–69 years of age, at baseline (2006–2010), which includes their extensive phenotypic and genotypic details, based on questionnaires and physical measures. Importantly, it also contains longitudinal follow-up measures of health-related outcomes.14,15 Further information about the UK Biobank is available elsewhere (https://www.ukbiobank.ac.uk/). We derived the mental health outcomes from the UK Biobank Mental Health Questionnaire (MHQ), using established criteria to identify likely disorders and risk profiles, including lifetime depression, manic or hypomania, generalized anxiety disorder, unusual experiences, self-harm, current post-traumatic stress, and hazardous or harmful alcohol consumption, as described elsewhere.15–17 More information on the mental health variables derived in the Supplementary File 1. The present study included a subset of 157,366 individuals (46.4% of the original UK Biobank sample) who completed the online MHQ by August 2017.
Individuals with MDD were identified using the following criteria: (i) lifetime MDD based on the Composite International Diagnostic Interview (CIDI) Short Form; (ii) ICD-coded MDD based on linked hospital admission records; and (iii) self-reported MDD as part of past and current medical conditions. Among the 56,820 individuals who met the criteria for at least one of the three definitions, we excluded 18 individuals who withdrew their informed consent, as well as 1662 individuals who preferred not to answer questions about self-harm, and 249 individuals who had more than 30% missing answers on the MHQ. The UK Biobank has received full ethical approval from the NHS National Research Ethics Service (16/NW/0274), and all the participants provided written informed consent before data collection. The current study was approved by the biomedical research ethics committee of West China Hospital (2020.661). The flow chart of participant selection for the present study is illustrated in Figure 1. We have introduced and followed the transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD) guideline,18,19 with a detailed checklist provided in Supplementary File 2-Table 1.

Flow chart of the study population selection.
Measures of suicide phenotypes
The suicide phenotypes in this study were based on the online MHQ administered in 2016/2017. 20 Suicidal ideation was measured by two questions from the MHQ-Field 20479 (Ever thought that life is not worth living) and Field 20513 (Thoughts that you would be better off dead or of hurting yourself in some way). We re-coded these into a binary variable in which those who responded ‘No’ or ‘Not at all’ to either question were coded as 0 and everyone else was coded as 1. Similarly, suicide attempts were measured using three questions: Field 20480 (Ever deliberately harmed yourself), Field 20481 (Ever harmed yourself in the last 12 months), and Field 20483 (Ever attempted suicide). We used these measures to derive a binary measure of suicide attempts in which individuals were given a score of 0 if they responded negatively to any of the three questions, and a score of 1 if they responded affirmatively to all three questions. To be specific, non-fatal suicide attempts and intentional self-harm were also defined as suicide attempts in this study according to any of the following ICD-10 codes X71–X83, T36-T71, T14. Accordingly, individuals with MDD (n = 55,139) were then classified into three subgroups based on a composite variable, with categories ordered by increasing suicide risk (Figure 1): non-suicidal depressed control participants (n = 25,611), depressed participants with suicidal ideation (n = 24,361), and depressed participants with a history of suicide attempts (n = 5167).
Feature engineering
Data pre-processing
Based on suggestions from psychiatrists and valuable current documents,21–23 we manually inspected and classified 403 candidate variables that were assessed at the time of study enrollment across the domains of social-demographics, lifestyle, family history, physical measures, and longitudinal follow-up of health-related outcomes. The term feature engineering encompasses feature filtering and transformations. The term feature filter refers to eliminating irrelevant features that act as noise to improve prediction accuracy. First, we eliminated 123 variables with more than 20% missing values. For the rest 280 variables for further processing (Supplementary File 2-Table 2), we added an “unknown” category to multi-category variables if some observed values of them were missing. Subsequently, the missing values of categorical variables were assigned the mode, whereas continuous variables were assigned the mean. Categorical variables with n categories were split into n binary variables, namely “one-hot coding.” All continuous variables were normalized; that is, the mean of the scale was set to 0 and the variance was set to 1.
Feature selection
Feature selection has been used to reduce the complexity of predictive models to facilitate better visualization of data and improve the performance of prediction. 20 Based on the above 280 variables, we performed Least Absolute Shrinkage and Selection Operator (LASSO) regression to select a minimum subset of features that accurately classified suicidal behaviors. LASSO is a penalized logistic regression model that selects important predictors by shrinking the coefficients of less important predictors to zero. 24 LASSO uses an embedded feature selection framework through L1 regularization. 25 L1 was set to 0.15 in this study, and four classification models (see Supplementary File 2-Figure 1) were tested to obtain better performance. We calculated variable importance by the principle of “mean decreases in accuracy” 12 to see which variables contributed significantly to optimization of the predictive model. Therefore, the important features that were selected using LASSO were used to build the predictive models (Supplementary File 2-Figure 1).
Statistical analyses
Model building
Imbalance handling and Ml algorithms
Four binary classification tasks were delineated, encompassing the following distinctions: individuals without a history of suicidal behavior versus those with suicidal ideation (25,611 vs. 24,361), individuals without suicidal behavior versus those who have made suicide attempts (25,611 vs. 5167), individuals with suicidal ideation versus those who have made suicide attempts (24,361 vs. 5167), and individuals without suicidal behavior versus those exhibiting any suicidal behavior (25,611 vs. 29,449). Given the extreme imbalance in the datasets for the classifications involving suicide attempts (25,611 vs. 5167 and 24,361 vs. 5167), we adopted the random under-sampling method to address this issue. 26
We used the Gradient Boosting Decision Tree (GBDT) algorithm in this study, which is one of the best algorithms for fitting real distributions in traditional ML algorithms. GBDT models inherently possess greater complexity compared to simpler models, primarily due to their iterative nature. Specifically, GBDT is an iterative decision tree algorithm that consists of multiple decision trees. 27 This iterative process involves sequentially adding trees to correct the errors of previous iterations, thereby enhancing the model's predictive performance. GBDT generates a weak classifier through multiple rounds of iteration, in which each classifier is trained on the basis of the residual of the previous round of classifiers, and the final classifier is improved by continuously reducing the residual generated during the training process. Despite this complexity, GBDT models offer significant interpretability through feature importance scores. 28 These scores elucidate the relative contribution of each feature to the model's predictions, facilitating a deeper understanding of which features are most influential in driving the predictive outcomes. In addition, five other ML algorithms were used to compare model performance: K-Nearest Neighbors, Gaussian Naive Bayes (Gaussian NB), logistic regression, Random Forest (RF), and Support Vector Machine (SVM). These six algorithms have been broadly accepted to solve binary classification problems between suicide attempts and non-suicidal attempts due to their performance and ease of interpretation, implementation, accuracy, and robustness.29,30
Repeated cross-validation and parameter tuning
To avoid reporting biased results and limit over-fitting, ML algorithms are usually validated through cross-validation. 31 K-fold cross-validation is a widely used method to evaluate ML models. After dividing the original data into K subsets (K-fold), the process involves training and evaluating the model K times, with a different fold of the data serving as the validation set each time, and the remaining K-1 folds being used for training the model. 32 To ensure the stability and generalization ability of our models, we adopted a 10-fold cross-validation (K = 10) approach. Specifically, we divided the dataset into training and validation sets in an 8:2 ratio and performed 10-fold cross-validation on the training set. This approach effectively reduces the model's dependence on a single dataset division and provides a more reliable assessment of model performance.
We optimized the model's hyperparameters using a grid search strategy. During the grid search process, we searched for optimal parameter combinations across a wide range of hyperparameters, including the number of trees, learning rate, and maximum depth. Our experimental results indicate that GBDT models achieved optimal performance with default parameter settings. Consequently, we used these simplified default settings for all GBDT classification models, which not only streamlined the training process but also ensured high efficiency. To enhance the robustness of GBDT models against overfitting, we implemented several practical and effective measures. We used regularization techniques (both L1 and L2) to reduce model complexity and employed early stopping to halt training when the validation error ceased to improve, thereby preventing overfitting. Additionally, we limited the maximum depth of each tree to prevent them from becoming overly complex. Together, these measures ensure the stability and generalization ability of the GBDT model during training and validation.
Explanation by SHAP
The correct interpretation of a prediction model for ML is also a challenge. We used SHapley Additive exPlanation (SHAP) values to provide consistent and locally accurate attribution values for each feature within each prediction model. 33 This is a unified approach for explaining the outcome of any ML model. SHAP values evaluate the importance of the output resulting from the inclusion of feature A for all combinations of features other than A. According to the prediction model, the higher the SHAP value of a feature, the more likely suicidal behaviors will occur. We visualized how a feature's attributed importance changed as its values varied in the plot.
Performance measurement and comparison
The classification fitted models were used to predict the classes (non-suicidal depressed control individuals, and individuals with suicidal behaviors) in the dataset, and the predicted classes were compared with the actual classes. Accuracy, specificity, sensitivity, and F1 scores were calculated along with the Area Under the Curve (AUC) derived from Receiver Operating Characteristics (ROC) curves as performance evaluation indicators. Sensitivity and specificity were measured at different binary-classification thresholds that the authors deemed relevant for clinical practice.
Statistical divergences in AUC between groups were assessed using the Hanley and McNeil method. The cut-off point was determined by maximizing the Youden function 34 (J[c] = Sensitivity[c] + Specificity[c]-1), where c represents any given cut-off to differentiate individuals with suicidal behaviors from individuals with depressive disorders. All tests of significance were two-sided, with p < 0.05 indicating statistical significance. Data analyses were performed using R (version 3.6.2, R Foundation for Statistical Computing, Vienna, Austria) and Python 3.7 (Python Software Foundation Delaware, USA). Relevant Python libraries included the SciPy ecosystem, NumPy, Pandas, and Scikit-learn.
Results
Characteristics of the participants
The final study population consisted of 55,139 participants with MDD, age > 50 years, among whom 29,528 (52.06%) individuals had ever exhibited suicidal behaviors. The class distribution is shown in Figure 1, with 25,611 individuals without suicidal behaviors, 24,361 with suicidal ideation, and 5167 with suicide attempts.
Table 1 illustrates the differences in the variables, such as sociodemographic and economic characteristics, and lifestyle in participants with and without suicidal behaviors. The mean age was 54.6 and 52.3 years for individuals with suicidal ideation and suicide attempts, respectively. Compared with the control group, individuals with suicidal ideation were more likely to be female (72.21% vs. 65.59%), obese (BMI ≥ 29.9, 26.42% vs. 21.24%), cigarette smokers (current or former, 56.82% vs. 43.63%), former drinkers (7.32% vs. 3.00%), and have higher neuroticism scores (mean score, 6.34 vs. 4.79) and had an earlier age of depression onset (24.58 vs. 34.52). However, they were less likely to have a higher household income (≥52,000£, 25.02% vs. 29.21%). More negative life events, including a long-standing illness (46.41% vs. 30.94%) and the non-accidental death of a close genetic family member (10.51% vs. 9.20%), were observed among individuals with suicide attempts compared to the control group, with the exception of depression possibly related to stressful or traumatic events. Similar results were observed when comparing individuals with suicidal ideation to the control group, and comparing individuals with suicide attempts to those with suicidal ideation. Strikingly, individuals with suicidal ideation had the highest scores on both the PHQ-9 and GAD-7 among the study population, whose causes of depression were possibly related to stressful or traumatic events.
Baseline characteristics of the study participants with MDD

The values are reported as median (lower quantile-upper quantile) for continuous variables and number (%) for categorical variables.
aFor current drinker, alcohol consumption level was calculated by converting the reported number of glasses to UK standard unit for each type of alcohol and summing up different types of alcohol. Low risk drinking was defined as alcohol consumption level ≤14 units/week, hazardous drinking was defined as 14–35 units/week (for females) or 14–50 units/week (for males), and harmful drinking was defined as ≥35 units/week (for females) or ≥50 units/week (for males).
Feature importance
Of the 280 predictors, the optimal number of input features was 8–11, as selected by LASSO regression for the four different classifiers that achieved the highest accuracy, varying according to the context and distribution of the data. The importance matrix plot for the LASSO method is shown in Supplementary File 2-Figure 1. These predictors include mental health assessments (i.e., PHQ-9, GAD-7 scores, neuroticism score), depression history (i.e., age at first and last episodes, lifetime number of depressive periods, frequency of worst episodes), sleep and trauma (i.e., trouble falling asleep, depression related to stressful or traumatic events, adverse events in adult life and childhood), demographics (i.e., year of birth, Townsend deprivation index), and health and diet (i.e., number of self-reported non-cancer illnesses, beef and poultry intake). There was substantial overlap in the top-ranked predictors across different models.
Model performance evaluation and contribution of variables
We used the final models with the important features selected by LASSO as input variables. The performances of four classification prediction models for differentiating suicidal behaviors are summarized in Figure 2 and Supplementary File 2-Table 3. A preliminary investigation was carried out to evaluate the performance of various machine learning models. Among these, GBDT consistently outperformed others, including SVM and RF. Figure 2A depicts the ROC curves for different classifications in detail. It shows that the GBDT classifier for differentiating between suicide attempters and controls had the largest value (0.914), followed by distinguishing between suicide attempters and controls (0.803). The confusion matrices and the comparisons of other performance evaluation indicators are shown in Figure 2B and Supplementary File 2-Table 3, respectively.
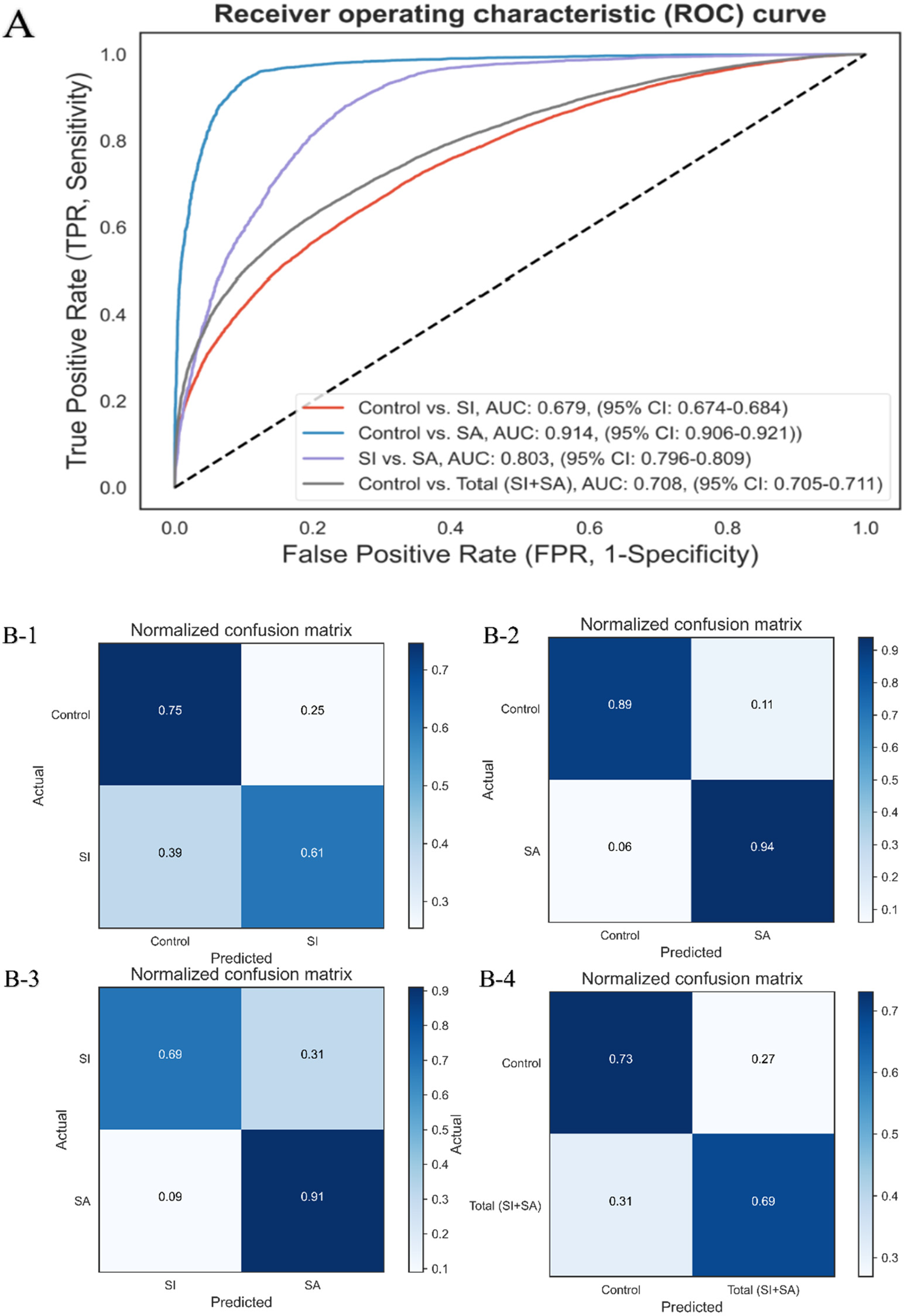
Receiver operating characteristics (ROC) curves and normalized confusion matrices of classifications of GBDT in identifying suicidal behaviors. Abbreviation: CI, confidence interval; ROC, receive operating characteristics. A, The ROC curves for four binary classifications of suicide prediction in individuals with depressive disorders. B, Corresponding normalized confusion matrixes. B-1, individuals without a history of suicidal behavior versus those with suicidal ideation; B-2, individuals without suicidal behavior versus those who have made suicide attempts; B-3, individuals with suicidal ideation versus those who have made suicide attempts; B-4, individuals without suicidal behavior versus those exhibiting any suicidal behavior.
The SHAP model to estimate important variables with the GBDT model used the variables selected by LASSO. The features were sorted in descending order by Shapley values (Figure 3). The advantage of SHAP values is that the SHAP mean value reflects the impact of the feature on the sample identification or the contribution of the feature to sample identification. The larger the SHAP value is, the larger the contribution of the feature is to sample identification. 33 Figure 3A presents the significance of depression history, including related trauma events, severity, duration, and frequency, in the classification model that distinguishes the suicidal ideation group from the control group. In distinguishing the suicide attempt group from the control group or the suicidal ideation group, the important predictors, as shown in Figure 3B and C, are the age of onset of depression and adverse events in adult life and childhood. There were only five common features that differentiated persons with suicide attempts from controls and persons with suicidal ideation, including adverse events in adult life and childhood, age, the Townsend deprivation index, and age at first-onset of depression.

SHAP framework for the top features in the suicide prediction model. Abbreviation: CTS-5, Childhood Trauma Screener-5 item; GAD-7, Generalized Anxiety Disorder-7 questions; Q5, Questions-5 item survey for adult domestic violence; SHAP, SHapley Additive exPlanations. Features on the right of the risk explanation bar pushed the risk higher, and features on the left pushed the risk lower. A, individuals without a history of suicidal behavior versus those with suicidal ideation; B, individuals without suicidal behavior versus those who have made suicide attempts; C, individuals with suicidal ideation versus those who have made suicide attempts; D, individuals without suicidal behavior versus those exhibiting any suicidal behavior.
Categorization of Ml scores
The population was separated into two groups (low and high ML scores), using the maximal Youden's index as the optimal cut-off value for distinguishing controls from the and suicidal ideation group. Figure 4 shows the suicide attempt risk scores relative to the control group (0.235) and the suicidal ideation group (0.21).

Receiver-operating characteristics (ROC) curves for suicidal behavior prediction using the maximum Youden's index. Abbreviation: CI, confidence interval; ROC, receive operating characteristics.
Discussion
In this study, leveraging a large community-based UK Biobank cohort, focusing on individuals over 50 years of age with depression, recognized as a high-risk group for suicidal behavior,2,35,36 we developed machine learning models to accurately predict the risk of suicidal behavior, particularly focusing on the risk of suicide attempts among individuals with depression and those with depressive disorders who have suicidal ideation, achieving AUROC scores of 0.914 and 0.803, respectively.
We found that there was a significant overlap among the top-ranked predictors across different models. When predicting overall suicidal behavior, including both ideation and attempts in individuals with depression, we identified key factors such as neuroticism, GAD-7 scores, and trauma experienced during childhood and adulthood, which align with findings from a substantial body of previous research on suicide prediction.4,37–39 Notably, basic sociodemographic variables had relatively limited predictive value, suggesting that a combination of clinical and psychosocial factors may provide more promising prediction accuracy.40,41 Furthermore, the algorithms in this study predicting suicide attempts demonstrated slightly higher classification performance than those predicting suicidal ideation, consistent with findings from a population-based study of Korean adults. 42 Interestingly, the inherent characteristics of depression, including related trauma events, severity, duration, and frequency, play a crucial role in distinguishing the suicidal ideation group from the control group in the classification model. In contrast, when distinguishing the suicide attempt group from the control group or the suicidal ideation group, key predictors include the age of onset of depression and childhood trauma events, among other intriguing findings. We also noted the contribution of other factors, such as beef or poultry intake and the number of non-cancerous diseases. Consistent with earlier research, 43 the incidence of non-cancerous diseases underscores the strong relationship between lifestyle factors and mental health. While previous studies on suicide did not investigate the intake of beef and poultry, our analysis suggests a potential link between protein intake and depressive episodes. For instance, a study in a Brazilian population revealed a 165% increase in the risk of depression among individuals who abstain from meat, highlighting a possible association. 44
Extreme imbalance is a characteristic feature of medical big data, where individuals with a specific disease represent only a small portion of the total population. The low prevalence rate of suicidal behavior significantly complicates the task of precise predictive modeling. Given the nearly 1:5 ratio of individuals who have attempted suicide to those experiencing suicidal ideation or exhibiting no suicidal actions in our study, we identified an imbalance that required a strategic solution. Consequently, we applied the under-sampling technique, which has a proven track record for enhancing model efficacy in the medical research field.45,46 This imbalance issue also explains why some AI models do not meet clinical expectations in real-world implementation. Typically, supervised machine learning models are evaluated on balanced datasets, leading to potential deviations from real-world scenarios. Our GBDT classifier demonstrated high accuracy and F1 score on the test set when distinguishing between suicide attempters and controls, as well as between suicide attempters and those with suicidal ideation. However, the specificity was relatively low. In the real world, most AI models struggle to achieve both a low misdiagnosis rate and a low missed diagnosis rate simultaneously. Therefore, while not all individuals predicted by the model to be at risk will attempt suicide—only a small portion may—the model effectively helps identify high-risk individuals who need early intervention and close observation. This makes the model suitable for clinical application and provides it with high practical value.
The suicide prediction model we have developed targets a high-risk group widely recognized as being at risk—those with depression. These individuals regularly visit relevant health institutions for treatment needs, so early identification can lead to effective intervention. For instance, this system helps care providers identify individuals with depression who may progress to suicidal ideation, allowing for preventive measures to be taken before any suicide attempts occur. If an individual demonstrates a notable increase in the severity, duration, and frequency of their condition, they may be identified as being at high risk of suicidal ideation. Subsequently, they would be recommended for appropriate follow-up, such as psychological counseling services and professional mental health care. More importantly, in clinical practice, it is well understood that a series of questions related to suicidal behaviors are an essential part of the psychiatric assessment for patients with depression. Based on our suicide attempt prediction model, physicians can now identify individuals at risk of suicide attempts with a reduced set of questions, and pay particular attention to those who have experienced adverse events in childhood or adulthood, thereby enhancing the therapeutic value of existing suicide prevention treatments and care.
Despite a widespread acknowledgment of the ethical challenges associated with using machine learning in suicide research and prevention,47,48 there is a consensus that bias and the lack of consistency and transparency are among the primary concerns. Therefore, implementing such algorithms could lead to a high rate of false positives and unnecessary interventions. As discussed earlier in our review, false positives may not be problematic when the cost of intervention is low. Moreover, adhering to current reporting guidelines for clinical prediction and diagnostic models using machine learning (TRIPOD-ML and STARD-AI) promotes consistency and transparency in reporting.
The study aims to identify the characteristics and important predictors of suicidal behaviors among individuals over 50 years of age, as well as to develop and evaluate ML models for accurately differentiating between individuals with and without suicidal ideation and suicide attempts. Characteristics of depression significantly influence predicting the risk of suicidal ideation. In contrast, key predictors for suicide attempts include the age of onset of depression and childhood trauma events, highlighting distinct factors for each outcome. Our focus was particularly on comparing individuals without a history of suicidal behavior to those who have made suicide attempts, as well as comparing individuals with suicidal ideation to those who have made suicide attempts. The findings of this study have significant implications for suicide prevention and mental health interventions for middle-aged and older adults.
A notable limitation of this study includes its cross-sectional design, which does not account for the frequency or sequence of suicidal behaviors, thus hindering causal inferences and longitudinal assessment of risk factors. Causal inferences and longitudinal assessment of risk factors. When defining outcomes, we relied on self-reports and inpatient ICD coding, missing data from emergency departments that have traditionally been the primary source for identifying suicide cases in previous research.49,50 Therefore, cases with less severe outcomes require further investigation. Finally, to ensure high-quality data in mental health research, the sample was limited to individuals with depression who completed the MHQ, with the youngest participant being 50 years old. The candidate predictors were restricted by the available data sources, and the resulting models were not clinically derived, leading to limited validation. Consequently, our findings may not be generalizable to the entire UK population or other populations.
Conclusions
In conclusion, using the UK Biobank cohort, we have established applicable machine learning-based models that accurately predict the risk of suicidal behavior in individuals with depression.
These models identify distinct predictive factors at various stages of suicidal behavior and have demonstrated strong performance in assessing the risk of suicide attempts. This underscores the potential of these models to identify individuals at medium to high risk within the general population of those over 50 with depression, thereby aiding in the development of cost-effective suicide prevention strategies.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241287450 - Supplemental material for Predicting suicidal behavior in individuals with depression over 50 years of age: Evidence from the UK biobank
Supplemental material, sj-docx-1-dhj-10.1177_20552076241287450 for Predicting suicidal behavior in individuals with depression over 50 years of age: Evidence from the UK biobank by Jian Zhang, Yujun Liu, Chao Zhang, Yilong Chen, Yao Hu, Xiujia Yang, Wentao Liu, Wei Zhang, Di Liu and Huan Song in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076241287450 - Supplemental material for Predicting suicidal behavior in individuals with depression over 50 years of age: Evidence from the UK biobank
Supplemental material, sj-docx-2-dhj-10.1177_20552076241287450 for Predicting suicidal behavior in individuals with depression over 50 years of age: Evidence from the UK biobank by Jian Zhang, Yujun Liu, Chao Zhang, Yilong Chen, Yao Hu, Xiujia Yang, Wentao Liu, Wei Zhang, Di Liu and Huan Song in DIGITAL HEALTH
Footnotes
Abbreviations
Acknowledgements
This research has been conducted using the UK Biobank Resource under Application 54803. This work uses data provided by patients and collected by the NHS as part of their care and support. This research used data assets made available by National Safe Haven as part of the Data and Connectivity National Core Study, led by Health Data Research UK in partnership with the Office for National Statistics and funded by UK Research and Innovation (grant ref: MC_PC_20029 and MC_PC_20058). We thank all the sponsors and team members involved in West China Biomedical Big Data Center and Med-X Center for Informatics, Sichuan University.
Author contributions
HS and WZ were responsible for the study concept and design. JZ, YC, and YH did the data and project management. JZ, and YC did the data cleaning and analysis. YL, CZ, WL, and XY interpreted the data. JZ and DL drafted the manuscript. All the authors approved the final manuscript as submitted and agree to be accountable for all aspects of the work.
Availability of data and materials
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Declaration of generative Ai in scientific writing
We didn’t use generative artificial intelligence (AI) and AI-assisted technologies in the writing process.
Ethical approval
The UK Biobank study has received full ethical approval from the NHS National Research Ethics Service (16/NW/0274), and all the participants provided written informed consent before data collection. The current study was approved by the biomedical research ethics committee of West China Hospital (2020.661).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by The 1.3.5 project for disciplines of excellence, West China Hospital, Sichuan University, (grant number ZYYC21005 to HS).
Guarantor
Huan Song
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.