
Abstract
Objective
The electronic medical records (EMRs) corpus for cerebral palsy rehabilitation and its application in downstream tasks, such as named entity recognition (NER), requires further revision and testing to enhance its effectiveness and reliability.
Methods
We have devised an annotation principle and have developed an EMRs corpus for cerebral palsy rehabilitation. The introduction of test-retest reliability was employed for the first time to ensure consistency of each annotator. Additionally, we established a baseline NER model using the proposed EMRs corpus. The NER model leveraged Chinese clinical BERT and adversarial training as the embedding layer, and incorporated multi-head attention mechanism and rotary position embedding in the encoder layer. For multi-label decoding, we employed the span matrix of global pointer along with softmax and cross-entropy.
Results
The corpus consisted of 1405 EMRs, containing a total of 127,523 entities across six different entity types, with 24,424 unique entities after de-duplication. The inter-annotator agreement of two annotators was 97.57%, the intra-annotator agreement of each annotator exceeded 98%. Our proposed baseline NER model demonstrates impressive performance, achieving a F1-score of 93.59% for flat entities and 90.15% for nested entities in this corpus.
Conclusions
We believe that the proposed annotation principle, corpus, and baseline model are highly effective and hold great potential as tools for cerebral palsy rehabilitation scenarios.
Keywords
Introduction
Cerebral palsy (CP) is a group of central motor and postural developmental disorders caused by nonprogressive interference in the developing brain. The prevalence of CP is approximately 3.4‰ in low- and middle-income countries and 1.6‰ in high-income countriess. 1 CP prevalence among individuals aged 0–18 in China was found to be 2.07‰, with a higher prevalence in rural areas compared to urban areas (2.75‰ vs. 1.90‰). From 2008 to 2019, the prevalence showed a mean annual increase of 38.13%, 2 establishing CP as a disorder with a significant disease burden among Chinese children. 3 Addressing motor dysfunction should be the primary focus of clinical rehabilitation therapy and research, 4 as the main symptoms of CP involve abnormal motor development and posture. The knowledge base for motor function rehabilitation in CP can reduce the clinical stress experienced by physicians. It can also improve the capacity of health services and the standard of living for children with CP in low- and middle-income countries, especially in rural areas. The electronic medical records (EMRs) of patients with CP encompass abundant diagnostic and treatment information pertinent to motor function and a wealth of insights provided by physicians. Therefore EMRs are the main data source for building the knowledge base. Nevertheless, the unstructured free text within EMRs necessitates extracting structured information, such as constructing corpus and named entity recognition (NER) task, for subsequent analysis and utilization. Despite the crucial role they play in advancing knowledge for motor function rehabilitation in CP, the construction of an EMRs entity corpus and the task of NER are often overlooked and are not typically implemented.
The existing medical entity corpus presents considerable opportunities for further enhancement and refinement. Firstly, the scarcity of large-scale medical entity corpus is exacerbated by the high cost of annotation and challenges in obtaining EMRs, leading to most available corpus being limited in scale 5 or sourced from official websites 6 and literature 7 rather than real EMRs. Subsequently, the granularity of entity delineation in several Chinese EMRs corpus does not yet meet practical needs, such as the CCKS2017 Task 2 and CCKS2018 Task 1,4,8 in which the symptom entity right lower limb shortening deformity is simply divided into body entity right lower limb and symptom entity shortening deformity. Given the significant emphasis on body structure and motor function levels in CP, motor function rehabilitation is necessary. 9 Using nested entities to represent medical concepts across various levels of granularity enables physicians to focus more precisely on body structures, the aforementioned example needs to be labeled as the nested body entity right lower limb within the symptom entity right lower limb shortening deformity. Furthermore, modified entities can facilitate doctors in assessing the motor function level of CP, such as severely reduced muscle tone or slightly reduced muscle tone. However, the majority of existing corpus of Chinese EMRs8,10,11 have not incorporated modified entities. Thirdly, many studies verify only the consistency among annotators,5,12 that is, inter-annotator agreement (IAA (2,2)), but they often overlook the consistency of the annotators’ own annotations. This oversight may compromise the quality and credibility of the corpus. Therefore, such a corpus, with a suitable scale and high credibility based on real EMRs, would greatly facilitate clinical applications related to CP and provide valuable insights for research and development in the field.
NER is a natural language processing technology that extracts clinical concepts, including diseases, symptoms, drugs, and other medical named entities, from EMRs. Several machine learning-based algorithms, such as hidden Markov model (HMM) 13 and conditional random field (CRF), 14 have been applied to NER. Compared to machine learning-based approaches, deep-learning-based methods can automatically extract features, thereby minimizing the need for feature engineering. Therefore, the current dominant paradigm for NER is the deep-learning-based approach, such as the bidirectional long short-term memory (BiLSTM) 15 and BiLSTM-CRF model. 16 Further, within deep-learning models, pre-trained models based on transformer 17 are initially trained and unsupervised on extensive text data to acquire generic word representations, which are subsequently fine-tuned using domain-specific data. This approach can notably enhance the model's efficacy in low-resource tasks and facilitate adaptation to downstream applications. 18 The bidirectional encoder representation from transformers (BERT) 19 model is the most prominent pre-trained model in the academic community. Its variants include bertcner in the clinical area of Chinese, as well as the BERT-base in the general domain of Chinese. 20 When recognizing medical entities, the clinical BERT performs better than the general BERT. 21 The BERT-BiLSTM-CRF framework, which integrates the BERT model with BiLSTM-CRF, currently stands as the most commonly employed framework in NER task. 20 Other researchers have also employed multi-head attention mechanism to obtain better results.8,12 In contrast to the CRF, the global pointer (GP) network has the capability to recognize nested entities. 22 Given the ability of the attention mechanism to dynamically adjust attention weights for capturing critical information and the proficiency of the GP in parsing nested entities, it is reasonable to assume that a NER model based on Chinese clinical BERT, the attention mechanism and GP network can achieve excellent performance in recognizing nested entities within the EMRs of the CP.
Therefore, to address the existing lack of an EMRs corpus for CP, we created a high-quality corpus with an improved scale and suitable for clinical tasks. We developed the principles of named entity annotation for EMRs of CP under the direction of medical experts and controlled the quality of the annotations throughout. The EMRs corpus of CP was developed using 1405 EMRs from 281 patients with CP. Moreover, we compared the performance of HMM, CRF, BiLSTM, BERT, attention mechanism, and other approaches to discover a NER model suitable for this corpus. The experiment proves that the Chinese clinical BERT + multi-head attention mechanism + GP strategy outperformed other strategies and was effective in recognizing nested medical entities.
Methods
Corpus construction
The procedure for constructing the EMRs entity corpus is illustrated in Figure 1, including the establishment of the annotation principles, pre-annotation, and formal annotation.

Overall flow chart of corpus construction. (Step 1) Under the guidance of medical experts and by referencing existing annotation guidelines, an initial draft of entity annotation principles for CP EMRs was developed. After the annotators (A1 and A2) became familiar with the annotation principles, a portion of EMRs were chosen for training on the annotation platform. (Step 2) Three rounds of pre-annotation were then conducted. In each round of pre-annotation, two annotators independently labeled the same 10 × 5 EMRs. The annotation principles were refined based on evaluations of inter-annotator agreement (IAA (2,2)) and analyses of discrepancies between the annotators. (Step 3) The objective of the fourth round is to focus on intra-annotator agreement (IAA (2,1)) and the annotation of the remaining EMRs. First, 10 × 5 EMRs were selected to assess the final IAA (2,2). Then, [1 × 5 EMRs] were randomly selected to each annotator, two annotators repeated the labeling of the [1 × 5 EMRs] five times without the annotator's awareness. The IAA (2,1) was calculated across these five annotations to evaluate the consistency of each annotator's entities over time.
Annotation principles
Creating reasonable annotation principles and strictly adhering to them during the annotation procedure are the most crucial steps in constructing the EMRs entity corpus. In Step 1 (shown in Figure 1), with the assistance of medical experts, the initial draft of the annotation principles was created with reference to the 2010 i2b2 annotation guidelines, 23 Chinese medical text annotation guidelines, 24 and the Unified Medical Language System (UMLS) semantic types. Exploring the recognition of modified entities is essential because modified information is crucial for clinicians to assess the severity of a patient's condition. Therefore, six types—SYMPTOM, BODY, TREATMENT, DISEASE, CHECK, and ADJUNCT—were used in the annotation principles to classify the medical entities. Further details on entity boundaries and types, as well as general annotation principles, can be found in Appendix A.2.
Preparatory work
Data preparation: The flow chart for inclusion and exclusion of patients with CP is shown in Figure 2. The inclusion criteria were as follows: patients must meet all three of the following criteria: (a) having a discharge diagnosis of CP, (b) receiving inpatient treatment, and (c) CP listed as the first-listed diagnosis. The exclusion criteria were as follows: patients are excluded if they meet one of the following criteria: (a) five categories of EMRs are incomplete, including medical history characteristics, discharge summary, history of present illness, diagnosis basis, and hospital course, or (b) the presence of other motor function diseases that could significantly affect motor function. As our study utilizes historical EMRs and does not involve the collection of blood or other biological samples, written informed consent from each patient was not required. Instead, the study was reviewed and approved by the ethics committee, which waived the need for individual consent given the nature of the data used. After obtaining approval from the ethics committee of the Children's Hospital Attached to Chongqing Medical University, 281 patients who satisfied both the inclusion and exclusion criteria were selected for this study. Of the 281 patients, 100 patients were hospitalized more than once, resulting in additional EMRs. However, given that the EMRs of the same patient across different times are relatively similar, and to balance the cost of labeling with the diversity of the corpus, this study included only the EMRs from the first hospitalization of each patient. With each patient contributing five categories of EMRs, so we have 1405 EMRs (281 × 5 EMRs, 281 represents the number of patients and 5 represents five categories EMRs of each patient). Prior to labeling, sensitive data from the EMRs, such as the patient's name, ID number, contact information, residential address, and doctor's name, were removed through data desensitization.
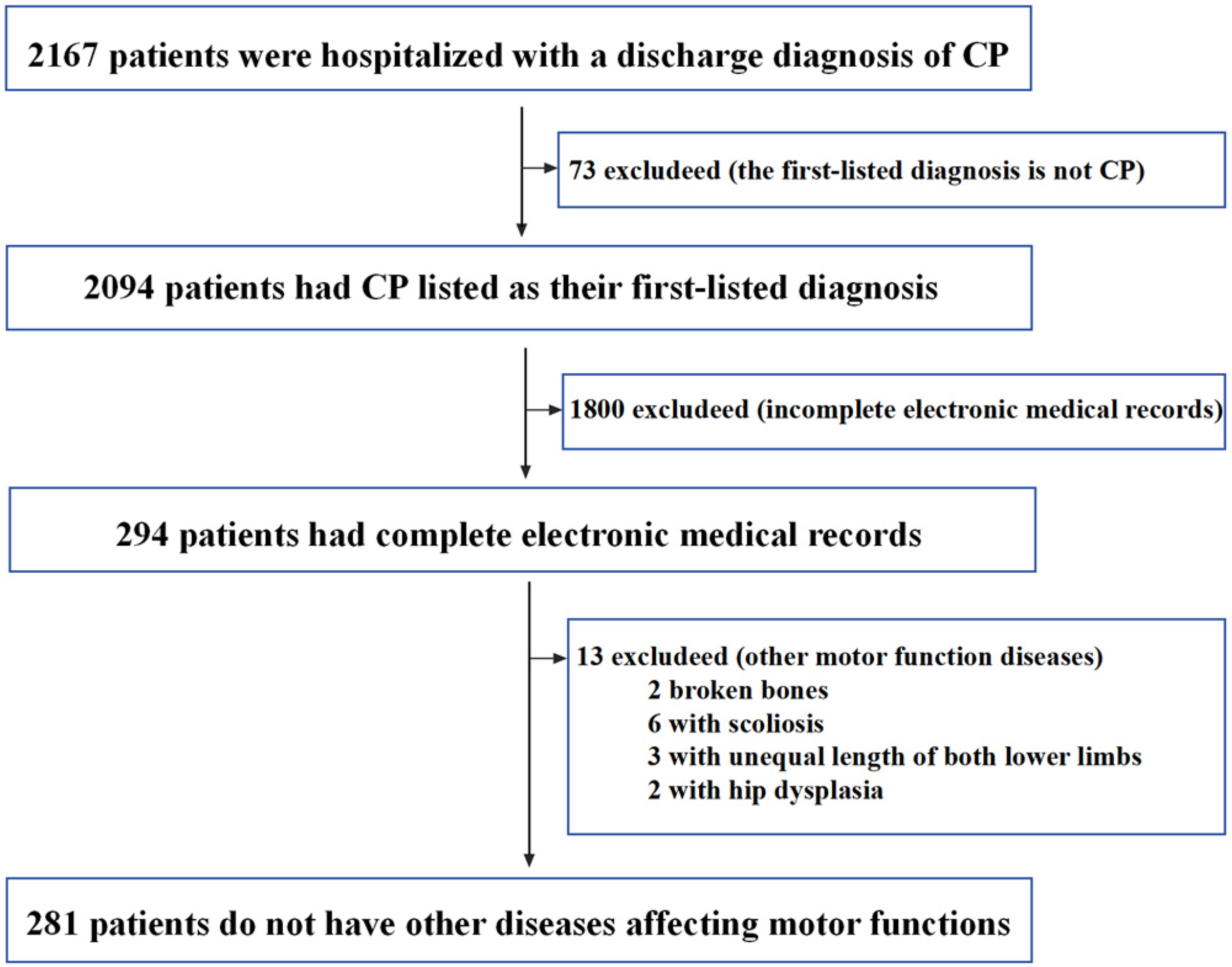
Flowchart for selection criteria of patients with cerebral palsy (CP).
Personnel training: In this study, two annotators (marked as A1 and A2), both master's degree candidates in medical fields, were involved in the annotation process. After the annotators (A1 and A2) became familiar with the annotation principles, a portion of EMRs were chosen for labeling training on the annotation platform (https://labelstud.io/). The labeling training aimed to familiarize annotators with the annotation principles and the proper usage of annotation platform.
Pre-annotation
The quality of a corpus can be evaluated in terms of its consistency and size. In contrast to other corpus, we implemented a more rigorous approach to consistency control. We conducted IAA (2,2) to assess agreement between annotators, and we also verified intra-annotator agreement (IAA (2,1)) for each individual annotator. By incorporating these measures, we aimed to establish standardized corpus. We initially developed a draft of the annotation principles specific to EMRs oriented towards CP rehabilitation. Through multiple iterations of annotation and revision, we ensured a satisfactory level of consistency in the annotated data.
As shown in Figure 1, a pre-annotation procedure is executed to ensure a high level of IAA (2,2) in Step 2. At this stage, we performed random sampling without replacement on a subset of 30 × 5 EMRs out of the total 281 × 5 EMRs. These sampled EMRs were evenly divided into three groups to complete three rounds of pre-annotation. The pre-annotation procedure was as follows:
Two annotators independently labeled the same 10 × 5 EMRs. The IAA (2,2) was assessed, and the inconsistencies between the two annotators were analyzed. Under the guidance of medical experts, the annotation principles were updated. The process then returns to step (1) to initiate the subsequent round of pre-annotation based on the most updated annotation principles.
As the annotation principles in the pre-annotation phase were still being updated, the 30 × 5 EMRs were relabeled in the formal annotation phase. In this study, 10 × 5 EMRs from each round proved adequate for achieving satisfactory IAA (2,2); however, future studies should ascertain the appropriate pre-annotation size on a case-by-case basis.
Formal annotation
In step 2, the annotation principles tended to be stable after three rounds of pre-annotation. Subsequently, the formal annotation phase was launched. To further determine whether the annotation principles were stable, we last assessed the IAA (2,2) during the round 4-1 of formal annotations. Specifically, 10 × 5 EMRs were drawn from the remaining 251 × 5 EMRs by sampling without replacement. Two annotators independently annotated the same 10 × 5 EMRs, and the IAA (2,2) was calculated based on the annotation results.
In Step 3 (Figure 1), we focused on the IAA(2, 1) of each annotator. The concept of test-retest reliability 25 was used to assess IAA (2,1). 172 × 5 EMRs were randomly drawn from the remaining 241 × 5 EMRs using sampling without replacement, and subsequently these 172 × 5 EMRs were equally allocated to A1 and A2 for annotation in round 4-2 to 4-10. Each annotator will completed a total of 86 × 5 EMRs for annotation. The mathematical formula of this annotation process was 86 × 5 EMRs = (10 × 5 EMRs) * 4 + (9 × 5 EMRs) * 5 + [1 × 5 EMRs] * 5. *N indicates the number of rounds of annotation that need to be completed, whereas *4 signifies that four rounds of annotations need to be completed. The [1 × 5 EMRs] were randomly selected to each annotator, two annotators repeated the labeling of the [1 × 5 EMRs] five times without the annotator's awareness. To avoid retrieval practice effect, the order of [1 × 5 EMRs] in which each round was randomized. IAA (2,1) was represented by the consistency of the annotators’ results for the [1 × 5 EMRs] across the five rounds of annotations.
Finally, the remaining 69 × 5 EMRs and 30 × 5 EMRs from the pre-annotation phase were formally annotated by two annotators. The labeling process took place at the Children's Hospital of Chongqing Medical University and spanned a total of 6 months.
NER methods
The deep-learning-based NER model typically consists of an embedding layer, a contextual encoder, and a tag decoder. 18 The proposed baseline model utilized the Chinese clinical BERT + adversarial training (AT) as the embedding layer, while the encoder layer incorporated multi-head attention mechanism and rotary position embedding (RoPE). For multi-label decoding, the span matrix of GP, along with softmax and cross-entropy, were employed. The network structure of the model is illustrated in Figure 3.
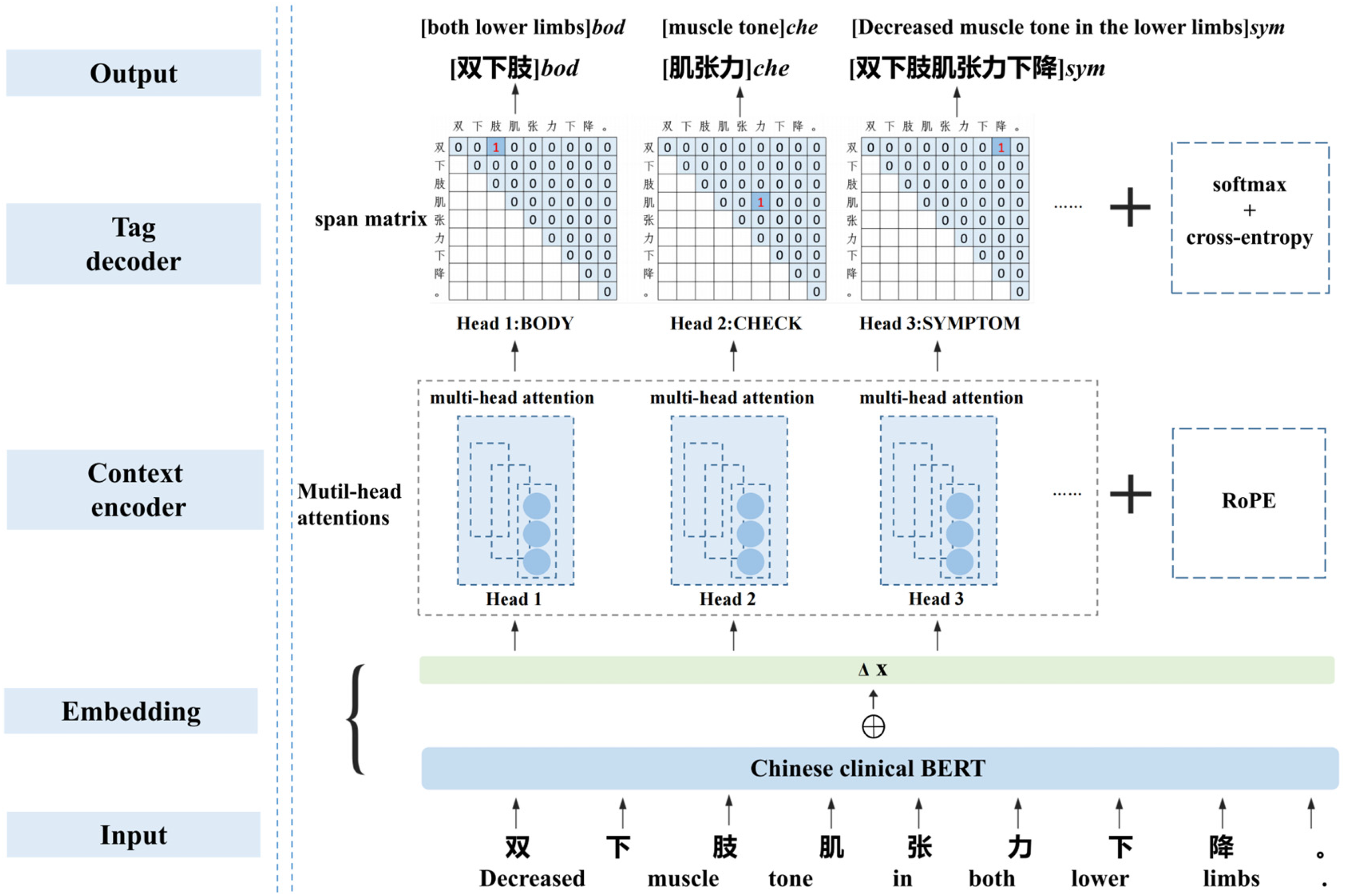
Network structure of the NER model. The leftmost section of the figure is labeled with the names of the model modules, while on the right side, the corresponding details for an example are provided. Take the character string “双下肢肌张力下降” (Decreased muscle tone in the lower limbs.)” as input, the model outputs the result of entity recognition: [双下肢]bod([both lower limbs]bod), [肌张力] che([muscle tone]che), and [双下肢肌张力下降]sym ([Decreased muscle tone in the lower limbs]sym).
Embedding layer: Since the introduction of BERT,
19
pre-trained models for downstream tasks have gained popularity because they can learn universal language representations. In our model, we utilized a Chinese clinical BERT called bertcner
20
as the base embedding. During the AT process, small perturbations were introduced to the training samples, allowing the neural network model to adapt and increase its robustness by learning to handle these variations. Therefore, we added perturbations in the gradient direction specifically to the embedding layer of the Chinese clinical BERT. Suppose that the embedding vector of a Chinese clinical BERT is



The simplest approach is to use a sigmoid activation function, which transforms into a n(n + 1)/2 binary classification problem. However, n(n + 1)/2 ≫ f, which leads the problem of severe category imbalance. The single-label classification problem with softmax and cross-entropy does not suffer from category imbalance. To solve the category imbalance problem, Su et al.
28
proposed an extension of softmax and cross-entropy to multi-label classification problems. This method reduces the multi-label classification problem to the difference between the target and non-target scores. The loss function for identifying the entities of type a is given by equation (4).

Results
Results of corpus construction
Consistency evaluation of corpus
The consistency was calculated using the F-score. The annotation result of one annotator (A1) was considered the standard annotation, and the precision (P), recall (R), and F-score of the annotation result of another annotator (A2) were calculated. The consistency was calculated using equations (5)–(7). The F-score ≥ 0.8 between two annotation results is considered to indicate acceptable consistency of the corpus.
29



NER task consists of two subtasks, boundary detection and type identification. 18 Exact-match evaluation requires both the correct identification of the entity boundary and type. 30 In this study, the consistency of the entity was based on exact-match evaluation, which was referred to as entity-level IAA (2,2) or entity-level IAA (2,1). Moreover, the consistency of each Chinese character was evaluated using the BIOES annotation method (B-begin, I-inside, O-outside, E-end, S-single), called label-level IAA(2, 2), as shown in Appendix Table A.1. In particular, the consistency evaluation of a corpus is entity-based. The label-level IAA (2,2) only aims to obtain richer information to update the annotation principles and improve the entity-level IAA (2,2) score. Unless otherwise specified, both IAA (2,2) and IAA (2,1) refer to entity-based consistency evaluation.
The overall entity-level IAA (2,2) is provided in Table 1, while the entity-level IAA (2,2) of six types of entities is listed in Table 2. By introducing label-level IAA (2,2) information(shown in Figure 4), the entity-level IAA (2,2) reached 97.57% in fourth round. This shows that the introduction of label-level IAA (2,2) is effective in updating the annotation principles and enhancing entity-level IAA (2,2). The detailed discussions of label-level IAA (2,2) are presented in Appendix A.3. In addition, equations (5)–(7) were used to calculate IAA (2,1), where and

Label level inter-annotator agreement (IAA (2,2)) statistical analysis diagram of four rounds annotation of six types of entities. The label-level IAA (2,2) of all six types entities exhibited a rising trend, and the B-label, I-label, and E-label of each entity eventually tended to be high and consistent.

Intra-annotator agreement (IAA (2,1)) of entity-level. The horizontal and vertical axes of the confusion matrix depict the results of same [1 × 5 EMRs] labeled during the n-th repetition. Results of A1 are presented on the left and results of A2 are shown on the right.
Entity-level inter-annotator agreement (IAA (2,2)) evaluation results (

Entity-level inter-annotator agreement results for six types of entities.

Scale evaluation of corpus
In this study, the EMRs of 281 patients with CP were included. Their demographic information, including gender and age, is presented in Figure 6. As shown in the Figure 6(a), 64.06% were male and 35.94% were female. As shown in the Figure 6(b), the ages of patients were divided into five stages: (1) infancy, 0 to 1 years old, encompassing 0 to 12 months of age; (2) early childhood, 1 to 3 years old; (3) preschool, 3 to 6 years old; (4) school age, 6 to 12 years old; and (5) adolescence, 12 to 18 years old. It can be seen from the picture that children aged 1 to 3 years are the most common, followed by those aged 3 to 6 years.

Demographic information of 281 cerebral palsy patients in this corpus.
In Table 3, six types of entities across five categories of EMRs were statistically analyzed after labeling 281 × 5 EMRs. The total number of entities in the corpus is 127,523, the number of unique entities is 24,424. Among the six types of entities, SYMPTOM accounts for the majority, while DISEASE and TREATMENT are relatively few in number. Among these five categories of EMRs, the medical record characteristics encompassed the greatest quantity of entities, whereas the diagnostic basis contained the least number of entities. Therefore, in the subsequent model-training phase, the five categories of EMRs from each patient were combined into training, validation, or test sets to prevent data imbalance. In Table 4, we also counted nested and long entities in the corpus, as identifying these two types of entities is particularly challenging with current NER technology. Nested entities comprise 24.99% of the corpus, while long entities—those exceeding ten Chinese characters—make up 5.98%. After entity de-duplication, the proportions change significantly: nested entities drop to 9.79%, and long entities increase to 19.25%. These differences highlight the impact of de-duplication on entity proportions.
Statistics on six types of entities across five categories of electronic medical records in the corpus.

The numbers in parentheses represent the unique entities after de-duplication.
Statistics on nested and long entities in the corpus.

A long entity is defined as one that exceeds ten Chinese characters in length. The numbers in parentheses represent either the unique entities after de-duplication or the proportions calculated from the unique entities.
Assessment results of NER model
To comprehensively evaluate the model's effectiveness, we compared the performance of our model with other state-of-the-art (SOTA) models including HMM,31,32 CRF, BiLSTM, BiLSTM-CRF,33,34 and BERT-BiLSTM-CRF35–37 for both flat and nested entities in our corpus. The performances of flat entities are listed in the left side of Table 5, it is observed that, except for the lower F1-score of the HMM, the F1-score of the other models do not show significant differences. All of the models achieved excellent performance with F1-score exceeding 90%. The performances of nested entities are listed in the right side of Table 5. Our model identified nested entities significantly better than the other SOTA models, with a F1-score approximately 40% higher than the other models. This indicates that these advanced SOTA methods are suitable for the recognition of flat entities, but they are less effective in recognizing of nested entities in our corpus.
Performance of our named entity recognition model and other SOTA models on flat entities and nested entities (P: precision; R: recall; F1: F1-score; our model: BERT + multi-head attention mechanism + span matrix of global pointer).

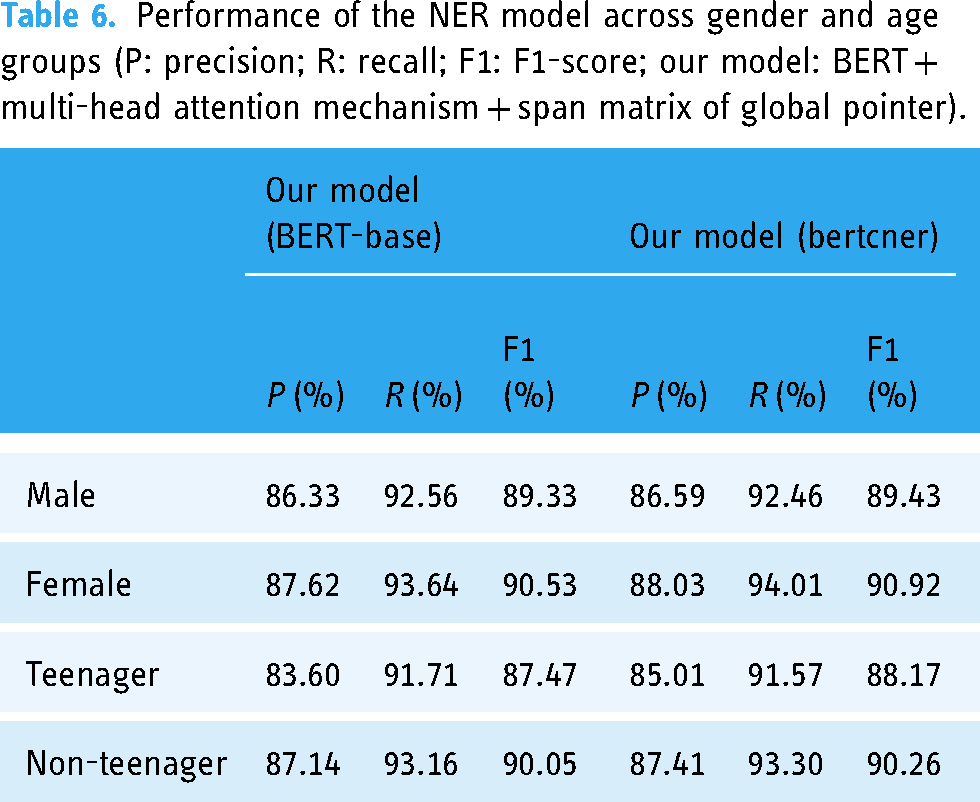
To further objectively assess the performance of our NER model from multiple dimensions, we performed an in-depth analysis of its performance across gender and age groups (Table 6), six types of entities (Figure 7) and five categories of EMRs (Figure 8). In Table 6, the performance of model across gender and age subgroups is consistent with its overall performance (Table 5), though the difference in performance between teenagers and non-teenagers is more pronounced than that between the gender subgroups. Our NER model generally performs well overall but has shown some shortcomings with certain types of entities or specific categories of EMRs. In Figure 7, both NER models perform poorly on the ADJUNCT type compared to other entity types. Additionally, both models exhibit relatively low P-score across all entity types. In Figure 8, both NER models perform the worst on hospital course. Similar to their performance on the six types of entities, both models exhibit relatively low P-value across all categories of EMRs.

Performance of our NER model on six types of entities (P: precision; R: recall; F1: F1-score).

Performance of our NER model across five categories of EMRs (P: precision; R: recall; F1: F1-score).
Performance of the NER model across gender and age groups (P: precision; R: recall; F1: F1-score; our model: BERT + multi-head attention mechanism + span matrix of global pointer).
Discussion
Entity corpus
We constructed a corpus of EMRs for children with CP under the guidance of clinical experts and combined it with clinical requirements under strict quality control. In this study, the IAA (2,2) between the two annotators was first tested across four rounds of labeling. Subsequently, the IAA (2,1) of each annotator was tested using test-retest reliability during the fourth round of formal labeling. And we introduce label-level IAA (2,2) to improve the annotation principle and enhance entity-level IAA (2,2). These approaches ensure more stringent quality control compared to other corpus builds that only calibrate entity-level IAA (2,2). The corpus demonstrated high agreement, as indicated by the IAA (2,2) and IAA (2,1), reflecting the confidence and reliability of the annotations. The corpus was sizable, comprising 1405 real EMRs of CP. The total number of annotated entities reached 127,523, with 24,424 unique entities, surpassing the size of current EMRs entity corpus.8,10,11,20 Furthermore, during our analysis of patient demographics, we discovered that the documentation of Gross Motor Function Classification System (GMFCS) levels and CP classification was incomplete. This lack of thorough documentation could adversely affect future clinical studies. Therefore, we strongly recommend the adoption of standardized and structured documentation practices for medical procedures.
Performance analysis of NER model
In this study, we proposed the hypothesis that a NER model combining Chinese clinical BERT, the attention mechanism, and a GP network would achieve superior performance on CP EMRs, particularly in recognizing nested entities. In Table 5, our model, along with other SOTA models, achieves commendable performance on flat entity recognition tasks. However, when it comes to nested entity recognition, our model demonstrates a significant advantage over the others. The experimental results validate this hypothesis. This success is attributable to the strengths of each component within our model. Replacing BERT-base with bertcner in our model yields better results, demonstrating that Chinese clinical BERT is more effective for entity recognition in the Chinese clinical corpus. Pre-trained on a substantial amount of clinical data, Chinese clinical BERT provides a robust foundation for understanding the nuances of medical language and terminology. Our model (BERT-base), utilizing BERT-base as the embedding layer, demonstrates superior performance compared to the widely used BERT-BiLSTM-CRF (BERT-base) model. This improvement underscores the effectiveness of the multi-head attention mechanism and the GP network in recognizing nested entities. The attention mechanism captures rich contextual semantic information, while the two-dimensional span matrix of the GP network enables appropriate multi-label decoding of nested entities, further enhancing the overall performance. Specifically, for a sentence of length n, there can be up to n(n + 1)/2 candidate entities if there is no restriction on entity length and entities are allowed to be nested within each other. Traditional one-dimensional models like HMM and CRF are limited in their capacity to decode only n labels (which corresponds to n labels, not n entities), take for example the flat entity sequence in Appendix Table A.1. Given that
The specific performance of our NER model is depicted in greater detail in Table 6, Figures 7 and 8. In Table 6, the performance of the model in terms of gender and age is basically consistent with the overall performance of the model (Table 5), demonstrating strong robustness across different demographic groups. In addition, there is a larger difference in performance between the age subgroups compared to the gender subgroups. This disparity is likely due to the relatively balanced gender distribution in the corpus (Figure 6), while the teenager group, representing only 4.27% of the total dataset, has less training data, leading to reduced performance in this subgroup. In Figure 7, both NER models perform poorly on the ADJUNCT type compared to other entity types. We speculate that there are two primary factors contributing to the lower F1-score observed in ADJUNCT. Firstly, the models, including BERT-base and bertcner, lack training data relevant to ADJUNCT entities, which diminishes their recognition capability for this type. Secondly, in Table 3, the total number of ADJUNCT is 11,223, and the number after de-duplication is 4103. The ratio before and after de-duplication is small compared to other types of entities, indicating that the same ADJUNCT occurs less frequently in the training data. In Figure 8, both NER models perform the worst on hospital course. As shown in Table 3, the number of de-duplication ADJUNCT in hospital course is 1,357, which is significantly higher than that of other categories of EMRs. In addition, in Table 4, the percentage of de-duplication long entities in hospital course is as high as 27.12%. We speculate that the large number of ADJUNCT and long entities in hospital course both contribute to the increased difficulty for the NER model. In both the six types of entities shown in Figure 7 and the five categories of EMRs in Figure 8, the P-score of model is relatively low. This suggests that the model likely recognizes many irrelevant entities. Upon conducting a comprehensive error analysis, the fact that the NER model incorrectly identifies redundant entities was confirmed, such as one month of treatment in a local hospital ADJUNCT entity is redundantly divided into nested entities such as one month of treatment and a local hospital. Improving the recognition accuracy of the ADJUNCT type and reducing the recognition of redundantly entities are the primary enhancement directions for future research.
Clinical and social potential
Children with CP and their families endure significant long-term rehabilitation challenges and economic pressures. The capacity for pediatric rehabilitation services in China remains inadequate, with a pronounced disparity in the distribution of resources. To address this dilemma, it is crucial to leverage extensive medical data for in-depth analysis to enhance rehabilitation medical services and improve the quality of life for these children. The EMRs of CP not only contain critical diagnostic and treatment information but also encapsulate the clinical reasoning of physicians, offering substantial knowledge reuse potential. Nevertheless, much of the information within EMRs exists as unstructured text, posing challenges for direct analysis and utilization. By extracting key information from EMRs, a knowledge base for motor function rehabilitation in CP can be developed. This knowledge base will encompass detailed data on medical histories, treatment plans, and rehabilitation outcomes, facilitating the systematic synthesis and dissemination of rehabilitation experiences. Integrated into a clinical decision support system, this knowledge base leverages massive case data to provide evidence-based recommendations, assisting clinicians in making more informed and precise decisions. For instance, the knowledge base enables physicians to efficiently identify similar cases and review their treatment plans, thereby crafting more personalized rehabilitation strategies for new patients and enhancing rehabilitation outcomes.
Conclusion
In this study, we successfully constructed a high-quality and comprehensive corpus of EMRs specifically for CP rehabilitation, meticulously annotated and rigorously evaluated for consistency. The incorporation of test-retest reliability in the annotation process underscores the confidence and reliability of the data. Building on this corpus, we developed a robust NER model using advanced deep-learning techniques, including Chinese Clinical BERT, multi-head attention, and the GP network. Our model excels in recognizing nested entities, enabling more nuanced and detailed analysis of CP patient data. This endeavor established a solid foundation of data and models for advanced mining and analysis of extensive CP EMRs. The results are expected to significantly advance knowledge representation and facilitate intelligent applications in related medical fields.
Limitations
We must acknowledge that our study has certain limitations. Future research could benefit from gathering a larger dataset of EMRs from multiple medical centers to further expand the corpus. Additionally, there is a need to focus on enhancing the performance of ADJUNCT type entities and hospital course category EMRs, which could improve overall model performance. Addressing these limitations will contribute to more robust and comprehensive findings in subsequent studies.
Footnotes
Code and data availability
The code and data used in this study are available upon request. To access the datasets, please contact the corresponding author at gq_jin18@outlook.com. We will provide the relevant materials to researchers for reproducibility and further analysis.
Contributorship
Meirong Xiao performed management activities to annotate, designing computer programs, mathematical formulations, and specifically writing the initial draft. Qiaofang Pang did testing of existing code components, and writing—reviewing and editing. Yean Zhu suggested ideas, specifically critical review. Shuai Lang did validation and supervision. Guoqiang Jin suggested ideas, specifically critical review, and did supervision.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
Institutional Review Board of Children's Hospital of Chongqing Medical University (No. 2023242).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Jiangxi Province 03 Special and 5G Project (No. 20224ABC03A04), and in part by the Key Research and Development Program of Jiangxi Province (No. 20202BBE53021).
Guarantor
Yean Zhu.