
Abstract
Objective
In dermatological research, the focus on scalp and skin health has intensified, particularly regarding prevalent conditions like dandruff and erythema. This study aimed to utilize YOLOv7 model to develop an automated detection web-based system for these specific scalp lesions.
Methods
Utilizing a dataset of 2200 clinical images, the model's accuracy and robustness were assessed. The raw images were initially preprocessed by the Roboflow tool. We then trained and evaluated the YOLOv7 model, comparing its performance with several baseline models including YOLOv5, YOLOF, and the single-shot detector. Finally, the proposed model was integrated into a flask API-based web application using the flask-ngrok library.
Results
The YOLOv7 demonstrated exceptional performance, attaining a mean average precision of 98.6%, with precision and recall rates of 98.6% and 97.2%, respectively. When benchmarked against baseline models, the YOLOv7 demonstrated enhanced performance metrics both during the training phase and the testing process on unseen data.
Conclusions
This study not only validates the potential of YOLOv7 for scalp lesion diagnostic applications but also brings the integration of sophisticated AI models into practical healthcare solutions.
Introduction
The human scalp is a distinctive dermatological area characterized by its high follicular density and significant sebum production. Scalp disorders can be broadly categorized into inflammatory dermatoses, cicatricial alopecias, infections/infestations, and neoplasia. 1 Inflammatory dermatoses include chronic inflammatory conditions like seborrheic dermatitis and psoriasis, which are driven by underlying inflammatory processes and manifest through symptoms such as hyperkeratosis, excess sebum, and dandruff. 2 Additionally, erythema between hair follicles and follicular erythema/pustules are common signs of infections/infestations, which is typically caused by bacterial pathogens. 3 Cicatricial alopecias are a group of disorders that destroy hair follicles and replace them with scar tissue, resulting in permanent hair loss. This category includes conditions like lichen planopilaris, where hair loss is often irreversible. 4 Neoplasms of the scalp consist of a large group of diseases originating from different cell types and can be divided into benign and malignant tumors. 3 Common benign swellings of the scalp include epidermoid cysts, trichilemmal cysts, lipomas, dermoid cysts, pilomatrixomas, steatocystoma multiplex, and cylindromas. These scalp disorders, while generally not life-threatening, can cause discomfort and may require medical intervention.
Scalp disorders are often precipitated by various factors, including psychological stress and the misuse of hair treatments like straighteners, perming agents, and hair dyes. 5 These practices can lead to allergic reactions, chemical-induced scalp injuries, and an increase in hair fragility. The scalp's condition is also influenced by individual health history, chronic systemic illnesses, and concurrent medication use. 6 Prolonged scalp disorders not only affect physical appearance but also erode self-confidence, create social barriers, and diminish the overall quality of life.5,7 Therefore, it is imperative to diagnose various scalp and hair disorders at an early stage and provide appropriate care and treatment based on accurate diagnostic results.
However, early detection is often hindered by a scarcity of specialists, challenges in accessing healthcare facilities, and a general lack of awareness among patients. 8 This gap underscores a pressing need for a system that allows for quick and straightforward assessment of scalp conditions, enabling patients to take immediate steps toward treatment. Such a system is increasingly in demand, facilitating early intervention and potentially mitigating severe scalp conditions. Moreover, the financial aspect of scalp treatments cannot be overlooked. These treatments often involve substantial costs, making it imperative for healthcare payers to evaluate the cost-effectiveness of new treatment options in managing scalp diseases. 9 Given the high costs and inconveniences associated with current treatment methods, there is an escalating need for more affordable and convenient solutions for monitoring scalp health. 10
Recent advancements in computer graphics have significantly enhanced the capabilities of image processing. This progress allows for the swift and precise rendering of photographs on high-resolution displays, marking a notable development in digital imaging technology. The application of image processing techniques extends broadly across scientific domains, 11 including the analysis of satellite imagery, diverse industrial uses, and the medical field. 12 In light of the previously mentioned challenges in the early detection and diagnosis of scalp conditions, there emerges a need for alternative, more efficient methods. In response to this need, our research introduces a web-based system leveraging the YOLOv7, 13 a state-of-the-art one-stage detector, to automatically identify two common scalp conditions: dandruff and erythema between hair follicles. This approach aims to offer a more effective, lower-cost, and timely diagnosis method.
The main contributions of this work are given below:
Utilizing pretrained weights from the MS COCO dataset, we developed a scalp disorder prediction model with YOLOv7. This approach significantly reduces the training time required for the prediction model. We also benchmarked the proposed YOLOv7 model against other prominent one-stage object detectors, such as YOLOv5, YOLOF, and single-shot detector (SSD), to evaluate its performance comprehensively. The proposed model was seamlessly integrated into a user-friendly web application built with flask and ngrok. This application offers an automatic, highly accurate AI-based recognition method, enabling users to assess their scalp health conditions in real-time from any web-enabled device.
The development of this automated detection system marks a significant advancement in scalp health management. It provides a cost-effective and accessible diagnostic tool via the web, enhancing the ability to monitor and manage scalp health effectively.
Related works
To date, research focusing on scalp-related issues remains relatively scarce. This section aims to provide an overview of the existing studies in this area.
Lacarrubba et al. 14 have highlighted the efficacy of scalp hair dermoscopy, also known as scalp image microscopy, in the observation and treatment of various scalp and hair conditions. In another significant study, Rudnicka et al. 15 employed trichoscopy, which combines dermoscopy for both hair and scalp, as a diagnostic tool for conditions like tinea capitis, alopecia areata, and trichotillomania. Furthermore, Kim et al. 10 conducted an evaluation of hair and scalp conditions utilizing microscopic image measurements and analysis techniques.
Lee and Yang 16 introduced an intelligent system for hair and scalp analysis, utilizing advanced technology to evaluate scalp health. Their system integrates a web camera and a microscope image sensor, coupled with the Norwood–Hamilton model for classifying stages of hair loss. This combination enables the system to capture and analyze specific features and parameters from images to assess the condition of an individual's scalp hair. The system was developed on the Nvidia Jetson TK1 platform. This development allows for a simplified process of self-diagnosing scalp hair conditions, making it accessible for consumer use.
Wang et al. 17 conducted an in-depth evaluation of various artificial intelligence methodologies, specifically within the realm of edge computing, for the purpose of intelligent scalp hair detection. The research involved the deployment of the deep learning-focused ImageNet-VGG-f-model alongside a range of machine learning classifiers. This approach allowed for a comprehensive comparison between different AI techniques. A critical aspect of the study was comparing the effectiveness of deep learning methods against traditional machine learning approaches in the context of accuracy and reliability. The findings revealed a significant disparity in performance, with deep learning models, particularly the ImageNet-VGG-f-model, demonstrating a substantially higher accuracy rate, clocking in at 89.77%.
Su et al. 18 developed a sophisticated system for scalp hair inspection and diagnosis, harnessing the capabilities of deep learning technologies. Central to this system is the implementation of a VGG-net model, a renowned architecture in the field of deep learning, specifically tailored for the inspection and diagnosis of scalp hair issues. The system is adept at identifying and evaluating a spectrum of scalp hair conditions, including but not limited to dandruff, hair loss, bacterial presence, excessive oiliness (grease), and allergic reactions. Remarkably, the system achieved a high recognition accuracy rate of 90.9%, underscoring its effectiveness in diagnosing various scalp hair problems.
Huang et al. 19 introduced a pioneering cloud-based system dedicated to the analysis of skin and scalp hair conditions, representing a significant advancement in dermatological technology. The core of this system lies in its application of diverse image processing methodologies, designed to detect and evaluate various conditions and symptoms related to the skin and scalp hair. This comprehensive system is equipped to perform a multitude of analyses, including sensitivity testing of scalp hair, sebum level (oil) assessment, pore examination on the scalp, evaluation of hair density (volume), and analysis of skin pigmentation (tone).
Chang et al. 20 developed an innovative smartphone-integrated system for the diagnosis of scalp hair conditions, leveraging the convenience of mobile technology. At the heart of this system lies the adoption of advanced deep learning algorithms, specifically tailored for the critical task of image recognition associated with scalp health. The system utilizes a compact, portable microscope capable of 200× magnification with an adjustable focus, which is seamlessly connected to a smartphone, enhancing the system's practicality and ease of use. Designed with user-friendliness in mind, this system empowers even individuals with no professional medical training to conduct self-inspections and assessments of their scalp health. This approach significantly promotes the practice of scalp hair healthcare in a home setting.
The ScalpEye system integrates several components: a mobile application, a cloud-based AI training server, a centralized administrative platform, and a specialized portable microscope designed for scalp hair imaging. 21 This system was crafted with the primary goal of identifying and diagnosing four common scalp hair conditions: hair loss, dandruff, folliculitis, and excessive oiliness (oily hair). The system employs the Faster R-convolutional neural network (CNN) with the Inception ResNet v2 Atrous model for the precise identification of images. Based on experimental data, the ScalpEye system demonstrated exceptionally high average precision rates, ranging from 97.41% to 99.09%, particularly in detecting the four mentioned scalp hair issues within the COCO dataset. The implementation of ScalpEye significantly reduces the time and costs associated with training physical therapists specializing in scalp care. However, a limitation of the system is that it does not directly serve end users.
Jhong et al. 22 advocated for the use of CNNs to assess dandruff severity and the overall health of the scalp. To augment the feature extraction capabilities of the CNN model, the team incorporated the convolutional block attention module, a technique known for enhancing neural network performance. The study employed advanced methods like spinal fully connected networks and depth separable convolution to reduce the overall parameter count of the model, thereby optimizing its efficiency. This approach yielded an impressive accuracy rate of 85.03% in analyzing a dataset comprising 6000 images of various scalp conditions. To facilitate real-world application, the model was integrated with cloud computing and an IoT-based design architecture. This combination enhances the model's applicability in diverse settings. The integration of this technology makes it easier for consumers and professional hairstylists alike to monitor and address scalp issues effectively.
Methodology
This study outlines a comprehensive pipeline for detecting scalp issues, as depicted in Figure 1. The figure illustrates the journey from initial image preprocessing to the final predictive outcome. The initial phase involves preprocessing raw images using the Roboflow 23 tool, which labels these images and converts them into a format suitable for the YOLOv7 detection algorithm. These prepared images are then utilized to train the YOLOv7 detector, a crucial step in developing the model's ability to recognize scalp issues accurately. Posttraining, the model is tested on previously unseen images to evaluate its effectiveness. It identifies scalp issues, marking them with bounding boxes, as a part of its final output. The efficacy of the YOLOv7 model is also benchmarked against several baseline models, including YOLOv5, 24 YOLOF, 25 and the SSD, 26 to gauge its robust performance. Finally, the trained model is then integrated into a flask API-based web application 27 using the flask-ngrok 28 library, making it accessible for end-user interaction and application.
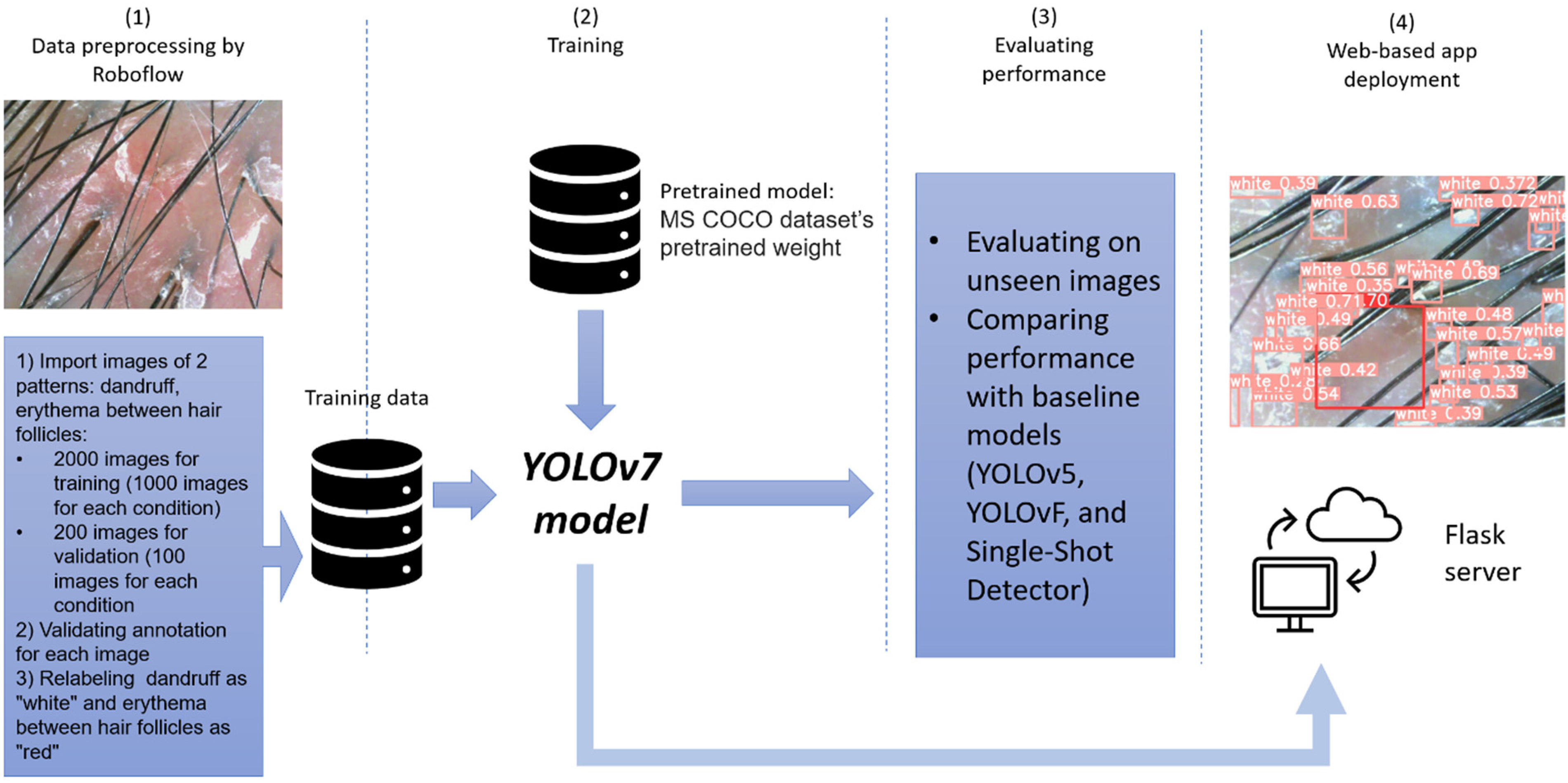
The general process of training and developing a scalp lesion detection system. The development scalp lesion detection system consists of four steps: (1) the raw images are labeled using the Roboflow tool to match the format for the YOLOv7 model; (2) the YOLOv7 model employs these labeled images for training; (3) YOLOv7 model is benchmarked against several baseline models and is tested on unseen data; (4) the trained YOLOv7 model is deployed to the flask server to create a web-based application.
In this research, the YOLOv7 model is utilized in its original architecture without modifications. The adapted version is available for public download from a GIT repository, 29 allowing for broader use. Subsequent subsections in the study provide an in-depth analysis of the various modules of the YOLOv7 model and their specific roles in detecting scalp issues.
YOLOv7 architecture
YOLOv7, 13 the latest iteration following YOLOv6, 30 represents a significant stride forward in the field of object detection. This model is designed to offer substantial improvements in accuracy and performance. A key advantage of YOLOv7 lies in its ability to provide superior object detection capabilities without an escalation in computational and inference demands. This balance of efficiency and performance sets it apart in the realm of AI models. YOLOv7 distinguishes itself from its contemporaries by achieving a reduction of approximately 40% in its parameter count and cutting down 50% of the computation needed compared to other SOTA real-time object detectors. These advancements enable YOLOv7 to conduct faster and more accurate inferences, thereby enhancing its practical applicability in various real-time object detection scenarios.
Figure 2 provides a clear depiction of the YOLOv7 architecture, highlighting its structured design composed of several key elements. The architecture of YOLOv7 is segmented into four primary components: the input section, the backbone network, the neck, and the head. Each plays a distinct role in the object detection process. At the input layer, the model utilizes a trio of advanced techniques: Mosaic data augmentation for diversified training data, adaptive anchor box calculation for optimizing bounding box sizes, and adaptive image scaling for consistent image input. In preparation for analysis by the backbone network, color images undergo preprocessing, where they are uniformly resized to a resolution of 640 × 640 pixels. This standardization is crucial to meet the input requirements of the backbone network.

YOLOv7 model architecture.
The backbone module in the YOLOv7 architecture is a composite of various layers, each contributing to the model's ability to process and analyze images. The Conv-BN-sigmoid linear unit (SiLU) (CBS) layers in the backbone consist of a Convolution (Conv) layer, followed by batch normalization (BN) and an SiLU activation function. This combination is pivotal in extracting image features across multiple scales. The extended latent attention network (ELAN) module, a key part of the backbone, includes numerous convolutional elements. It is designed to manage the shortest and longest gradient paths effectively, enhancing the model's learning efficiency and convergence ability. The max-pooling (MP) component features a max pooling layer along with several convolutional modules. This module uses bifurcated branches to reduce the dimensions and channel count of feature maps by half, aiding in downscaling the image's features. Following the downscaling process, a feature fusion step is implemented. This is crucial for amplifying the model's capability to extract and interpret features from the processed images.
The neck network within the YOLOv7 architecture is built upon a path aggregation feature pyramid network framework. This structure is integral to the model's overall functionality. Comprising several CBS blocks, the neck network also incorporates a unique combination of spatial pyramid pooling and convolutional spatial pyramid pooling (SPPCSPP), ELAN-H, and MP elements. The SPPCSPP structure plays a crucial role in expanding the network's perceptual field. It achieves this by merging a CSP structure within the SPP framework, along with a significant residual edge to optimize feature extraction processes. The ELAN-H layer, which harnesses the power of multiple feature layers based on the ELAN module, provides further enhancement to the model's feature extraction capabilities. A key achievement of the neck network is its ability to amalgamate high-level features with low-level ones, resulting in the integration of high-resolution details with high-semantic information. This integration is pivotal for the model's accuracy and effectiveness.
In the YOLOv7 model, the head network plays a crucial role in the final stages of object detection processing. The head network utilizes the Reparameterized Convolutional Block module, which is instrumental in modifying the channel sizes of the output features from various scales. This module effectively transforms the adjusted features into crucial detection data, encompassing bounding boxes, classification categories, and confidence scores. A convolutional layer, functioning as the detection head, is employed for downsampling purposes. This setup allows the model to efficiently detect objects of varying sizes, ranging from large to medium and small, across multiple scales.
Object detection models and their parameters
In this study, the YOLOv7 model was employed as the proposed model for detecting various scalp issues. To evaluate its efficacy, YOLOv7's performance was benchmarked against other notable one-stage object detectors, including YOLOv5, YOLOF, and SSD. These baseline models encompass several SOTA techniques that have been extensively used and validated across various applications. Furthermore, these models are also one-stage object detectors with hyperparameters similar to the YOLOv7 model, ensuring a fair and robust benchmark for evaluating the performance of the proposed YOLOv7 model. The training of YOLOv7, along with the other baseline models, was enhanced through the use of transfer learning. This process utilized pretrained weights from the MS COCO dataset, a widely recognized resource in machine learning for object detection.
Furthermore, to optimize performance of each model, the fine-tuning process of hyperparameters was conducted using a Genetic Algorithm (GA). 31 The GA employs principles of natural selection and genetic variation, optimizing hyperparameters through the iterative recombination and mutation of parameters across generations, thereby cultivating a progeny of models with superior performance metrics. The fitness of each candidate solution is predicated on their performance on a designated validation set, quantified by the mean average precision (mAP) as the fitness value in case of this research. The mutation operator within this genetic framework was enacted with a probability of 0.8 and a mutation variance of 0.2. The number of epochs and iterations were set to 100 and 50, respectively. The hyperparameters’ space scrutinized by the GA encompassed the learning rate (range: 0.0001 to 0.5), momentum (range: 0.5 to 0.99), learning decay (range: 0.0001 to 0.01), and optimizer (range: Adam or SGD). Detailed specifics regarding the optimized parameters employed in the training of these models are systematically presented in Table 1 of the study.
Parameters of YOLOv7 and baseline models.

SSD: single-shot detector.
Experimental environment and evaluation metrics
The experiments conducted in this study were performed on the Ubuntu 22.04 LTS operating system. The hardware infrastructure for the experiments comprised an Intel(R) Core(TM) I9-13900HX (32 CPUs) at 2.2 GHz and equipped with 16 GB of RAM. Additionally, an NVIDIA GeForce RTX 4060 GPU with a memory capacity of 16 GB was employed. In terms of software, Python version 3.8 and PyTorch framework version 2.1 were utilized to train YOLOv7, YOLOv5, YOLOF, and SSD object detection models.
To thoroughly assess the effectiveness of the object detection models, this study employs a suite of three key evaluation metrics, including precision, recall, and mAP. Precision is a critical metric for evaluating classification models. It quantifies the accuracy of a model in identifying true positives, representing the fraction of correct positive predictions among all positive classifications made by the model. Recall is an essential metric that gauges a model's capacity to accurately detect all positive instances. It is calculated as the ratio of correctly identified true positives to the total number of actual positive cases. The mAP is a comprehensive metric used to assess the overall performance of a model's detection results. It takes into account the model's effectiveness at varying threshold levels. The computation of mAP involves organizing all positive samples by their confidence level in descending order. Following this, the precision at each level of confidence is calculated. The final step is to determine the average precision across all these confidence levels. During all experiments, the intersection over union threshold was set at 0.5.
Formulas for precision and recall are articulated in equations (1) and (2), respectively: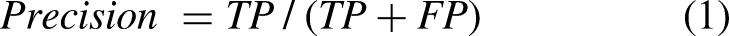

Average precision (AP) is a measure that captures the area under the curve formed by plotting recall (as the abscissa) against precision (as the ordinate). The calculation of AP is expressed in equation (3) as follows:

Flask API-based web application deployment
Flask 27 is a widely utilized web application framework within the Python programming environment, primarily employed for the development of web applications. Recognized as a micro framework, flask is characterized by its minimalistic design, requiring little reliance on external libraries. This aspect of flask makes it a popular choice for streamlined web application development. In a typical flask application structure, there are two primary directories: the “static” folder and the “template” folder. The “static” folder conventionally houses images and other media to be displayed on the web pages, while the “template” folder contains HTML files crucial for the frontend of the application. To enhance the reach and accessibility of the developed application, this project incorporates the “flask-ngrok” 28 library. This Python library facilitates the deployment and demonstration of the application on the internet using the ngrok tool, which is particularly useful for sharing the application hosted on a local machine.
Dataset
This research utilized a specialized dataset for scalp image analysis, which is openly available through AI Hub, 32 named Scalp Images by Type. This dataset was compiled by Aram Huvis, a company based in South Korea. The original dataset comprises over 100,000 images. For our research, we employed the secondary dataset that contains detailed annotation information for each image. A team of three dermatologists from Seoul National University Bundang Hospital meticulously validated the categorization of these images by pattern type and severity, including both classification and segmentation masks. From an extensive analysis of various scalp conditions, six significant and visually quantifiable patterns were selected for study: microkeratin, excess sebum, erythema between hair follicles, follicular erythema/pustule, dandruff, and hair loss. For each identified patterns, the images were systematically classified into four severity stages: none (0), mild (1), moderate (2), and severe (3). The images in this dataset are encoded in JPEG format, each with a resolution of 640 × 480 pixels. The file sizes range between 225 and 263 kB. Representative images from this dataset are exhibited in Figure 3.

Representative images from the dataset.
In this study, a strategic decision was made to focus on specific scalp lesions out of the six identified in the dataset. Microkeratin and excess sebum exhibit overlapping symptoms and are notably linked as primary contributors to dandruff.33,34 In the progression of follicular erythema/pustule, erythema between hair follicles typically emerges as an initial symptom, indicating the onset of this condition. Due to limitations in our GPU resources, it was not feasible to train models on the entirety of the original dataset's images. Consequently, the research focused on two main scalp lesions: dandruff and erythema between hair follicles, for object detection analysis. For model training, a total of 2000 images were strategically selected (1000 images for each condition). Additionally, 200 images (100 images for each condition) were set aside for validation purposes. We labeled dandruff as “white” and erythema between hair follicles as “red” during the experimental process.
Given that the original annotation information from the dataset was in Korean, we employed the Roboflow tool to assist in validating the annotations of a total of 2200 selected images. The annotations were carefully reviewed and translated from Korean to English. Specifically, during the experimental process, we relabeled dandruff as “white” and erythema between hair follicles as “red.”
Experimental results
Training and validation losses of the proposed YOLOv7 model
The YOLOv7 model training was conducted over a span of 100 epochs, after which a visualization tool was employed to observe the training process and determine the best epoch. In Figure 4, the visualization is represented through six distinct loss plots, with each serving a specific purpose in evaluating the training and validation process. The upper row of images in the figure displays the training losses, whereas the lower row presents the validation losses. Within these rows, the first column indicates the positioning loss, the second column reflects the confidence level loss, and the third column represents the loss related to the alignment of the predicted frame with the actual frame. The verification process revealed that the YOLOv7 model demonstrated a consistent decrease in losses, stabilizing at minimal levels after the completion of 100 epochs.

The proposed YOLOv7 model's training and validation losses. (a) Box training loss. (b) Objectness training loss. (c) Classification training loss. (d) Box validation loss. (e) Objectness validation loss. (f) Classification validation loss.
Performance comparison
The performance of the YOLOv7 model was rigorously evaluated alongside other contemporary object detection models such as YOLOv5, YOLOF, and SSD. Table 2 succinctly summarizes the performance metrics, including precision, recall, and mAP, providing a quantitative basis for comparing the effectiveness of each model. When measured against YOLOv7, the YOLOF model exhibits a considerable decline in precision (22.7%), recall (28.6%), and mAP (24.5%), indicating a substantially lower detection accuracy which falls short for real-time detection applications. The SSD model demonstrates an 8.9% decrease in precision, a 13.4% decrease in recall, and a 9.3% decrease in mAP, suggesting that while it can fulfill real-time detection requirements, it does so with less accuracy than YOLOv7. YOLOv5, while closer in performance to YOLOv7, still shows a slight reduction in precision (1.2%), recall (0.5%), and mAP (0.7%), making it a competent model for real-time detection but not as precise as YOLOv7. The empirical results underscored the superior overall performance of YOLOv7 in detecting scalp lesions, outperforming the baseline models in precision, recall, and mAP.
Comparison of the proposed YOLOv7 model with baseline models in experiment.

SSD: single-shot detector; mAP: mean average precision.
Testing on unseen data
The practical assessment of the YOLOv7 model and other baseline models for identifying scalp lesions was examined using a video excerpt obtained from a YouTube video (available online: https://www.youtube.com/watch?v=NRiKipabPOM, accessed on 21 January 2024). We trimmed this video during a 10-s interval from 24:01 to 24:11. This segment has been made available for watching in the supplementary video file titled “Test.mp4.” Object detection outcomes from this video snippet are demonstrated in Figure 5, showcasing the comparative performance of YOLOv7, YOLOv5, and SSD models. Observations for each model were recorded at the fifth-second mark of their respective experimental videos. Full experimental videos, named “yolov7_exp.mp4,” “yolov5_exp.mp4,” and “SSD_exp.mp4,” have been included as part of the supplemental materials to provide a full account of the object detection process of each model.

Object detection outcomes from a YouTube video snippet. (a) YOLOv7 model's real-time detection results on unseen data. (b) YOLOv5 model's real-time detection results on unseen data. (c) SSD model's real-time detection results on unseen data.
In Figure 5(a), real-time detection by the YOLOv7 model is displayed, which proficiently identified objects of “white” and “red” labels on the scalp with marked precision, surpassing other models in the identical scalp region. Figure 5(b) presents the detection prowess of the YOLOv5 model in real-time. Despite achieving slightly less precision compared to YOLOv7, YOLOv5 was able to detect more quantity of objects. The performance of the SSD model is depicted in Figure 5(c). While the SSD managed to identify a comparable number of objects as YOLOv5, its precision per object was notably inferior. In tests involving data not previously seen by the models, YOLOv7 consistently outperformed the other models, achieving the highest level of accuracy in detecting various objects.
Web platform testing
To create an application that is easy for users to navigate and interact with, we deployed a basic web platform application by utilizing a flask server and the ngrok package. Figure 6 displays the main page of our web application. In order to identify scalp issues using our pretrained YOLOv7 model, users need to click on the “Symptom detection” icon beside the “Home” symbol. Figure 7 displays the content of the page that appears when the “Symptom detection” icon is clicked. This page encompasses three crucial components. The first element is the “Choose file” field employed for the purpose of file selection. The second one is the “Reset” button, which allows the user to clear the file path in case of an incorrect selection. The third one is the “Execute” button, which initiates the object recognition process of the YOLOv7 model for the uploaded video. Figure 8 illustrates the outcome page following the completion of the detection procedure.

The main page of our web platform.

The “symptom detection” page of our web platform.

The “symptom detection” page of our web platform on the hold-out test set.
Discussions
In this research, we introduced a web-based platform designed to autonomously identify scalp disorders such as dandruff and erythema. This platform is accessible via a web-based application that enhances user engagement by simplifying the examination of scalp health. For the development and validation of deep learning models, we compiled a dataset consisting of 2200 images derived from clinical environments. The performance evaluation indicated that the YOLOv7 algorithm excelled, achieving mAP of 98.6%, precision and recall rates of 98.6% and 97.2%, respectively. Comparative analyses with baseline models like YOLOv5, YOLOF, and SSD demonstrated that YOLOv7 outperformed these benchmarks during both training and testing on unseen data. To facilitate the practical application of our findings, we developed an accessible web application using flask and ngrok, expanding the availability of our research to end users.
Several literatures revealed various approaches to predicting the severity of scalp conditions. Prior studies indicated a classification accuracy of 85.03% for dandruff 22 and between 75.73% and 95.75% for hair loss.35–37 While certain studies achieved notable accuracy using CNN with attention mechanisms 18 or ensemble models, 30 they predominantly addressed single scalp disorders and classification tasks. Our research, however, enabled simultaneous detection of multiple conditions. Our object detection model can show real-time results with segmentation boxes indicating the affected areas on the patient's scalp.
One previous study, 21 which developed the ScalpEye system, addressed a similar context with us that solve the object detection task for scalp conditions. The ScalpEye system 21 diagnoses four prevalent scalp conditions (dandruff, erythema, hair loss, and oily scalp) through a mobile application. Despite its broader diagnostic capabilities compared to our system, ScalpEye's utility is confined to mobile devices. Conversely, our system is accessible via any web-enabled device, offering greater flexibility. Performance-wise, ScalpEye recorded an Average Precision (AP) of 97.41% for dandruff and 97.61% for erythema. It means that the overall mAP for predicting dandruff and erythema of this system is 97.51%. Our YOLOv7 model, however, showed a slight improvement in detecting dandruff and erythema with an mAP of 98.6%, underscoring its superior diagnostic accuracy in these specific conditions.
From a medical perspective, combining follicular erythema and pustules into a single category is problematic, as they represent distinct dermatological conditions. Follicular erythema is typically an early indicator of inflammation and may precede the development of pustules. 38 In contrast, pustules are localized accumulations of pus within hair follicles and often require the exclusion of infectious causes, such as bacterial or fungal infections. 39 Recognizing these clinical differences is essential, and pustules should be classified separately in diagnostic applications to ensure accurate diagnosis and appropriate treatment planning. Misclassification could result in inadequate treatment and potentially overlook underlying infections that need specific medical interventions. In light of this, future research utilizing this dataset, particularly those addressing all six types of scalp conditions or including follicular erythema/pustules pattern, should separate these conditions into distinct categories.
While the study presents notable findings, it acknowledges certain constraints that bound its scope and outcomes. Due to the computational restrictions posed by the available GPU resources, this research concentrated on identifying only dandruff and erythema among the six types of scalp lesions cataloged in the original dataset. Future investigations are encouraged to broaden the dataset utilization, encompassing a more extensive array of data and labels to facilitate comprehensive detection across all scalp lesion symptoms. The current study employed the original YOLOv7 architecture, highlighting an opportunity for future research to explore modified versions of the model or newer YOLO iterations such as YOLOv8, YOLOv9, and YOLOv10. These advanced methods may offer enhanced detection capabilities. The potential refinement of the YOLOv7 architecture is a prospective area for future research, aiming to elevate the performance levels beyond those achieved in this study, particularly when diversifying the detection of scalp lesion indicators. Presently, the web-based platform is limited to processing video uploads for the detection of real-time scalp issues. Looking ahead, there are plans to refine this functionality by incorporating direct detection through a mini-microscope connected to a computer. Additionally, we aim to meld a mobile application with our web server, simplifying the detection process for users. This mobile utility will allow individuals to attach a microscope lens to their camera phones and undertake symptom detection independently at home. With the mobile application, users will be able to forward detection videos to scalp therapists and dermatologists, thereby facilitating efficient telemedicine consultations and time-saving benefits.
Conclusions
This investigation sought to determine the potential for automated identification of scalp lesions, leveraging cutting-edge deep learning object detection technology such as YOLOv7 model. A dataset comprising 2200 images from actual clinical settings was curated for the purpose of training and validating the deep learning algorithms under consideration. The experimental results revealed that YOLOv7 distinguished itself with a mAP of 98.6%, alongside a precision and recall of 98.6% and 97.2%, respectively. When benchmarked against baseline models such as YOLOv5, YOLOF, and SSD, the YOLOv7 demonstrated enhanced performance metrics both during the training phase and the testing process on unseen data. To bridge the gap between research and real-world applications, a user-friendly web application was developed utilizing flask and the ngrok library, thereby facilitating broader access to our research for end users.
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Footnotes
Contributions
Conceptualization: H.V.N and B.H; software: H.V.N; methodology: H.V.N and B.H; validation: H.V.N and B.H; investigation: H.V.N and B.H; writing—original draft preparation: H.V.N; formal analysis: B.H; writing—review and editing: H.V.N and B.H; visualization: H.V.N.; supervision: B.H; project administration: B.H; funding acquisition: B.H. All authors have read and agreed to the published version of the manuscript.
Data availability statement
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethics approval
Ethical approval was not required as this study data is open sourced, and the original research has already been conducted.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2018R1D1A1B07041091, NRF-2021S1A5A8062526) and the National R&D Program for Cancer Control through the National Cancer Center (HA23C02410061582062860001) and local government-university cooperation-based regional innovation projects (2021RIS-003).
Guarantor
Haewon Byeon.
Informed consent statement
Informed consent was obtained from all subjects involved in the study.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.