
Abstract
Background
Nonalcoholic fatty liver disease (NAFLD) is recognized as one of the most common chronic liver diseases worldwide. This study aims to assess the efficacy of automated machine learning (AutoML) in the identification of NAFLD using a population-based cross-sectional database.
Methods
All data, including laboratory examinations, anthropometric measurements, and demographic variables, were obtained from the National Health and Nutrition Examination Survey (NHANES). NAFLD was defined by controlled attenuation parameter (CAP) in liver transient ultrasound elastography. The least absolute shrinkage and selection operator (LASSO) regression analysis was employed for feature selection. Six algorithms were utilized on the H2O-automated machine learning platform: Gradient Boosting Machine (GBM), Distributed Random Forest (DRF), Extremely Randomized Trees (XRT), Generalized Linear Model (GLM), eXtreme Gradient Boosting (XGBoost), and Deep Learning (DL). These algorithms were selected for their diverse strengths, including their ability to handle complex, non-linear relationships, provide high predictive accuracy, and ensure interpretability. The models were evaluated by area under receiver operating characteristic curves (AUC) and interpreted by the calibration curve, the decision curve analysis, variable importance plot, SHapley Additive exPlanation plot, partial dependence plots, and local interpretable model agnostic explanation plot.
Results
A total of 4177 participants (non-NAFLD 3167 vs NAFLD 1010) were included to develop and validate the AutoML models. The model developed by XGBoost performed better than other models in AutoML, achieving an AUC of 0.859, an accuracy of 0.795, a sensitivity of 0.773, and a specificity of 0.802 on the validation set.
Conclusions
We developed an XGBoost model to better evaluate the presence of NAFLD. Based on the XGBoost model, we created an R Shiny web-based application named Shiny NAFLD (http://39.101.122.171:3838/App2/). This application demonstrates the potential of AutoML in clinical research and practice, offering a promising tool for the real-world identification of NAFLD.
Keywords
Introduction
Nonalcoholic fatty liver disease (NAFLD) has become a major global health concern, affecting approximately 25% of the population worldwide. It is one of the leading causes of chronic liver diseases, which can progress to severe complications such as cirrhosis and hepatocellular carcinoma within 10 to 20 years post-diagnosis. 1 Despite less than 10% of NAFLD patients developing these severe outcomes, the absolute numbers are still considerable, considering the high prevalence of NAFLD. 2 With the global incidence of NAFLD escalating swiftly, there is an imperative need to intensify efforts towards the development of precise, non-invasive diagnostic techniques and the formulation of efficacious prevention strategies for those at elevated risk of NAFLD and its associated progressive liver diseases. Furthermore, the majority of patients with NAFLD are asymptomatic. 3 The timely and accurate identification of individuals predisposed to NAFLD is crucial, facilitating the implementation of targeted interventions that can halt disease advancement, prevent complications, and ultimately alleviate the strain on healthcare infrastructures. 4
While liver biopsy remains the gold standard for diagnosing NAFLD, its invasiveness and potential for complications, including pain, infection, and bleeding, limit its practicality for widespread screening.5,6 The diagnosis of NAFLD via ultrasound examination is often hampered by numerous factors, particularly the subjectivity of the examiner. 5 Previous studies have analyzed NAFLD in the United States population using data from the National Health and Nutrition Examination Survey (NHANES). 7 These studies have relied on diagnostic methods with inherent limitations, such as standard ultrasound and noninvasive biomarkers. Furthermore, liver transient ultrasound elastography (LUTE) (FibroScan), which is based on ultrasonic attenuation of the echo wave measurement (controlled attenuation parameter [CAP]), has emerged as a promising non-invasive diagnostic tool.8–10 Data from transient elastography are now available in the NHANES database (2017–2020), allowing for real-world analysis of NAFLD within the United States population. Traditional scoring systems such as the Fatty Liver Index (FLI), Lipid Accumulation Product (LAP), Hepatic Steatosis Index (HSI), Fatty Liver Disease Index (FLD Index), NAFLD Index, ZJU Index, and Framingham Steatosis Index (FSI) enable non-invasive detection of NAFLD.11–17 However, their clinical utility is compromised by limitations inherent in these traditional algorithms, which constrain further performance enhancements. Advancements in the management and diagnostic accuracy of NAFLD hinge upon the development of sophisticated analytical tools.
Machine learning (ML), a burgeoning field of medicine combining computer science and statistics into medical problems, is being widely used based on its efficient computing algorithms and its ability to deal with massive clinical data.18,19 Developing prediction models based on statistical associations among features from a given input data is one of the most common objectives of ML in medicine. Notably, recent literature20–30 corroborates the formidable capacity of ML in crafting diagnostic models for fatty liver disease. However, the deployment of ML extends beyond mere algorithmic applications; it necessitates a full spectrum of methodical steps, including data pretreatment, feature engineering, ML algorithm selection, and hyperparameter tuning. These steps demand substantial programming experience and ML knowledge, posing substantial hurdles for clinicians. This gap has led to the rise of Automated Machine Learning (AutoML), a significant breakthrough in artificial intelligence that minimizes human oversight and automatically selects optimal algorithms, tunes hyperparameters, and generates robust models.
Zhang et al. developed a rapid and cost-effective tool to enhance the detection of clinically significant prostate cancer using an AutoML platform, leveraging data from routine clinical examinations. 31 Wang et al. developed and validated models to predict 12-month esophageal variceal bleeding using the H2O-automated machine learning platform (algorithms include DL, XGBoost, GLM, GBM, RF, and stacking). 32 Liu et al. utilized AutoML to predict liver metastasis in patients with gastrointestinal stromal tumors, based on an analysis of SEER data. 33 The ability of AutoML to streamline the development of diagnostic tools presents a promising solution for clinicians, particularly in the context of NAFLD. Early detection and accurate diagnosis of NAFLD are critical yet challenging due to the disease's asymptomatic nature. Despite its potential, to the best of our knowledge, there have been few reports on the application of AutoML in diagnosing NAFLD, highlighting this as a nascent yet promising area of research. This study aims to address this gap by investigating the effectiveness of AutoML in identifying the presence of NAFLD using patient demographic data, laboratory results, and physical examination data in the NHANES database, thereby providing a novel approach to improving clinical outcomes for patients with NAFLD.
Utilizing the H2O AutoML platform, this research is designed to leverage data from the NHANES to develop and validate a series of machine learning models for the identification of NAFLD, as determined by FibroScan CAP measurements. By deploying these models and creating the subsequent R Shiny web-based application, Shiny NAFLD, based on the optimal model, we aim to significantly improve clinicians’ diagnostic capabilities. This approach promises a more precise, efficient, and less invasive method for identifying NAFLD compared to existing diagnostic techniques.
Materials and methods
Data source
NHANES, a nationally representative survey of the United States, is administered by the National Center for Health Statistics (NCHS). The NHANES program is notable for its comprehensive approach, integrating both interviews and physical examinations to assess the health and nutritional status of the United States population. Conducted annually since 1999, the survey systematically evaluates a representative national sample of approximately 5000 individuals. The NHANES interview covers a broad spectrum of topics including demographics, socioeconomic status, dietary habits, and health. The examination component of the survey comprises thorough medical assessments, physiological measurements, and laboratory tests, all performed by highly trained medical professionals. Comprehensive details on survey variables can be accessed at https://wwwn.cdc.gov/nchs/nhanes/Default.aspx. The survey was approved by the NCHS research ethics review board, and the consent of all participants was recorded.
Participants
The data was obtained from the NHANES January 2017 to March 2020 database, which contained data on LUTE. A total of 15,560 participants were included. We excluded 5862 participants without CAP data, 677 with ineligible FibroScan data (either < 10 complete FibroScan readings, a fasting time <3 hours, or a liver stiffness interquartile (IQRe) range/median stiffness >30%), and 4515 participants who were not included in the fasting subsample, which chose some participants aged 12 and older to fast for 8 to 24 hours in preparation for the examination the following morning. Additional exclusions were applied to high alcohol consumers, defined in the NHANES alcohol use survey as having an average daily intake of ≥20 g/day and ≥30 g/day for women and men from the NHANES alcohol use survey, or if there were any additional potential factors for liver disease, including viral hepatitis (defined as positive for serum hepatitis B surface antigen or hepatitis C antibody or if hepatitis B or C was reported). The final sample size for our analysis was therefore 4177. The flowchart of the inclusion of this study participants is shown in Figure 1.

Flowchart of the inclusion of study participants.
Fibroscan CAP
By measuring the ultrasonic attenuation of the echo wave, also known as CAP, LUTE can quantify hepatic steatosis.9,10 FibroScan model 502 V2 Touch fitted with a medium (M) or extra-large (XL) wand (probe) was utilized in the NHANES database to measure CAP value. In addition, liver steatosis was assessed using the mean CAP value in more than ten complete measurements taken throughout the examination. Individuals were identified as having NAFLD if the CAP values were ≥302 dB/m, which is regarded as the best cutoff for the detection of hepatic steatosis. 8
Variables
The machine learning models in this study were developed using data from laboratory examinations, anthropometric measurements, and demographic variables from NHANES. The demographic characteristics included gender, age, race, and ratio of family income to poverty (PIR), and anthropometric parameters included weight, body mass index (BMI), arm circumference, waist circumference, hip circumference, systolic pressure (SBP), and diastolic pressure (DBP). The laboratory parameters were composed of alanine aminotransferase (ALT), albumin (ALB), alkaline phosphatase (ALP), aspartate aminotransferase (AST), creatinine (CR), globulin (GLB), gamma-glutamyl transferase (GGT), lactate dehydrogenase (LDH), phosphorus (P), total bilirubin (STB), total calcium (Ca), total protein (TP), uric acid (UA), platelet count (PLT), ferritin, iron, total iron binding capacity (TIBC), transferrin saturation (TSF), glycohemoglobin (HbA1c), fasting plasma glucose (FPG), high-density lipoprotein cholesterol (HDL-C), high-sensitivity c-reactive protein (hs-CRP), insulin (INS), total cholesterol (TC), triglyceride (TG), and low-density lipoprotein-cholesterol (LDL-C) levels. Additionally, the study's main outcome was determined by the presence or absence of hepatic steatosis, indicated by a CAP value of ≥302 dB/m.
Missing data handling
Variables with more than 30% missing values were removed, while those with less than 30% missing values were interpolated using an appropriate technique. The remaining missing data, identified as missing at random, were addressed using the random forest algorithm for multiple imputation and interpolation, as implemented in the R package “mice” (version 3.15.0). 34
Feature selection
Feature selection was conducted through the least absolute shrinkage and selection operator (LASSO) regression analysis, which strategically penalizes coefficient magnitude to streamline the number of predictive variables. The fine-tuning of the regularization parameter, λ, was meticulously carried out via a 10-fold cross-validation method, ensuring a rigorous optimization process. The coefficients of the variables from the lasso regression models were arranged in ascending order. Variables with nonzero coefficients were selected due to their significant contribution to the model's predictive accuracy. LASSO penalizes less important features, reducing model complexity and enhancing interpretability. By focusing on variables with the strongest predictive power, we ensured that only the most relevant and impactful features were included in the final model.
Automated machine learning
The AutoML analysis was implemented using the H2O package (version 3.40.0.1) installed from the H2O.ai platform (http://www.h2o.ai/). For binary classification problems, this platform's AutoML feature automatically employs six distinct algorithms: Gradient Boosting Machine (GBM), Distributed Random Forest (DRF), Extremely Randomized Trees (XRT), Generalized Linear Model (GLM), eXtreme Gradient Boosting (XGBoost), and Deep Learning (DL). XGBoost is a composite method that integrates several decision-tree classifiers. It reduces the discrepancy between predicted and actual values during training by utilizing objective functions. These functions include differentiable convex loss components and regularization terms to enhance model robustness and prevent overfitting. The descriptions of the remaining algorithms can be found in the supplementary documentation. Participants were randomly allocated into two groups, with a training-to-validation set ratio of 7:3. A 5-fold cross-validation was conducted on the training dataset to assess model performance. AutoML used these evaluations to rank the models based on their area under the ROC curve (AUC), considering various combinations of hyperparameters across six distinct algorithms. Following this ranking, the models were evaluated on the validation set to determine their generalization capabilities. The model with the highest AUC on the validation set was selected as the optimal model. Based on the optimal model, an R Shiny web-based application, Shiny NAFLD, was developed to facilitate the practical identification of NAFLD by clinicians. (http://39.101.122.171:3838/App2/).
Evaluation and interpretation of models
To evaluate the performance of the models on the validation set, a confusion matrix was compiled, which included true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN). These metrics were utilized to calculate sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), positive likelihood ratios (LR+), negative likelihood ratios (LR−), and AUCs. This comprehensive analysis allowed for a detailed assessment of the models’ discrimination capabilities. Formulas were as follows: ACC = (TP + TN)/(TP + FP + FN + TN); PPV = TP/(TP + NP); NPV = TN/(TN + FN); LR + = sensitivity/(1-specificity); LR− = (1-sensitivity)/specificity. The calibration curve was applied to evaluate the model's calibration, while the decision curve analysis (DCA) provided insight into the clinical net benefit. Models interpretability was presented in the form of variable importance, SHapley Additive Explanations (SHAP) partial dependence plot (PDP), and Local Interpretable Model-Agnostic Explanations (LIME). Variable importance is used to assess the statistical significance and impact of each feature within the model. The SHAP analysis is an approach that elucidates the separate contributions of each feature in the development of a prediction model while retaining consistency and local accuracy for a particular prediction. 35 In addition, the marginal influence of features on the predicted outcome can also be displayed in PDP, and the LIME analysis provides an understanding of the influence of main features on predictions for randomly selected examples from the validation set.
Statistical analysis
In our study, all statistical analyses were performed using R (version 4.2.2). To assess the normality of the data, the Shapiro–Wilk test was employed, which tests the null hypothesis that the data follow a normal distribution. Continuous data were presented as medians with interquartile ranges (IQR), while categorical variables were reported as counts (percentages). The Wilcoxon rank-sum test, a non-parametric test suitable for continuous variables that are not normally distributed, was applied to the continuous data. This test assumes independent groups and similar distribution shapes. For categorical variables, Pearson's Chi-square test was used to determine associations, assuming that the data are in the form of counts or frequencies, with independent samples. These tests were chosen for their robustness and appropriateness given our data characteristics. A two-sided p-value of less than 0.05 was considered statistically significant, indicating a low probability that the observed differences were due to chance.
Results
Demographic and clinical characteristics
The study included 4177 participants, with data randomly divided into a training set and a validation set at a ratio of 7:3 (2874 in the training set and 1303 in the validation set). After excluding participants with hepatitis and excessive alcohol consumption, 1010 participants (24.2%) were diagnosed with NAFLD. Significant differences were observed between the groups in various demographic, biochemical, clinical, and anthropometric variables. The CAP ≥ 302 dB/m group had a higher proportion of males (training set p < 0.001 and validation set p = 0.043) and a higher median age (p < 0.001 for both sets). Racial distribution also differed significantly, with more non-Hispanic whites in the CAP ≥ 302 dB/m group (p < 0.001 for both sets). No significant differences were found in the ratio of family income to poverty (training set p = 0.804 and validation set p = 0.868). Biochemical measurements such as ALT, ALB, AST, Cr, GLB, GGT, LDH, phosphorus, calcium, total protein, UA, HbA1c, FPG, HDL-C, hs-CRP, insulin, TC, TG, and LDL-C showed significant differences (p < 0.05) between the groups in both sets. Anthropometric measurements, including weight, BMI, arm circumference, waist circumference, and hip circumference, were significantly higher in the CAP ≥ 302 dB/m group (p < 0.05). Blood pressure measurements (SBP and DBP) were also significantly higher in the CAP ≥ 302 dB/m group (p < 0.001). Detailed characteristics are presented in Table 1.
Demographic and clinical characteristics of participants in the training and validation set.

CAP: controlled attenuation parameter; ALT: alanine aminotransferase; ALB: albumin; ALP: alkaline phosphatase; AST: aspartate aminotransferase; Cr: creatinine; GLB: globulin; GGT: gamma glutamyl transferase; LDH: lactate dehydrogenase; P: phosphorus; STB: total bilirubin; Ca: total calcium; TP: total protein; UA: uric acid; BMI: body mass index; SBP: systolic pressure; DB: diastolic pressure; PLT: platelet count; TIBC: total iron binding capacity; TSF: transferrin saturation; HbA1c: glycohemoglobin; FPG: fasting plasma glucose; HDL-C: high-density lipoprotein cholesterol; hs-CRP: high-sensitivity c-reactive protein; TC: total cholesterol; TG: triglyceride; LDL-C: low-density lipoprotein-cholesterol.
n (%); Median [25%,75%].
*Pearson's Chi-squared test; Wilcoxon rank sum test.
Performance of AutoML models and existing scoring systems
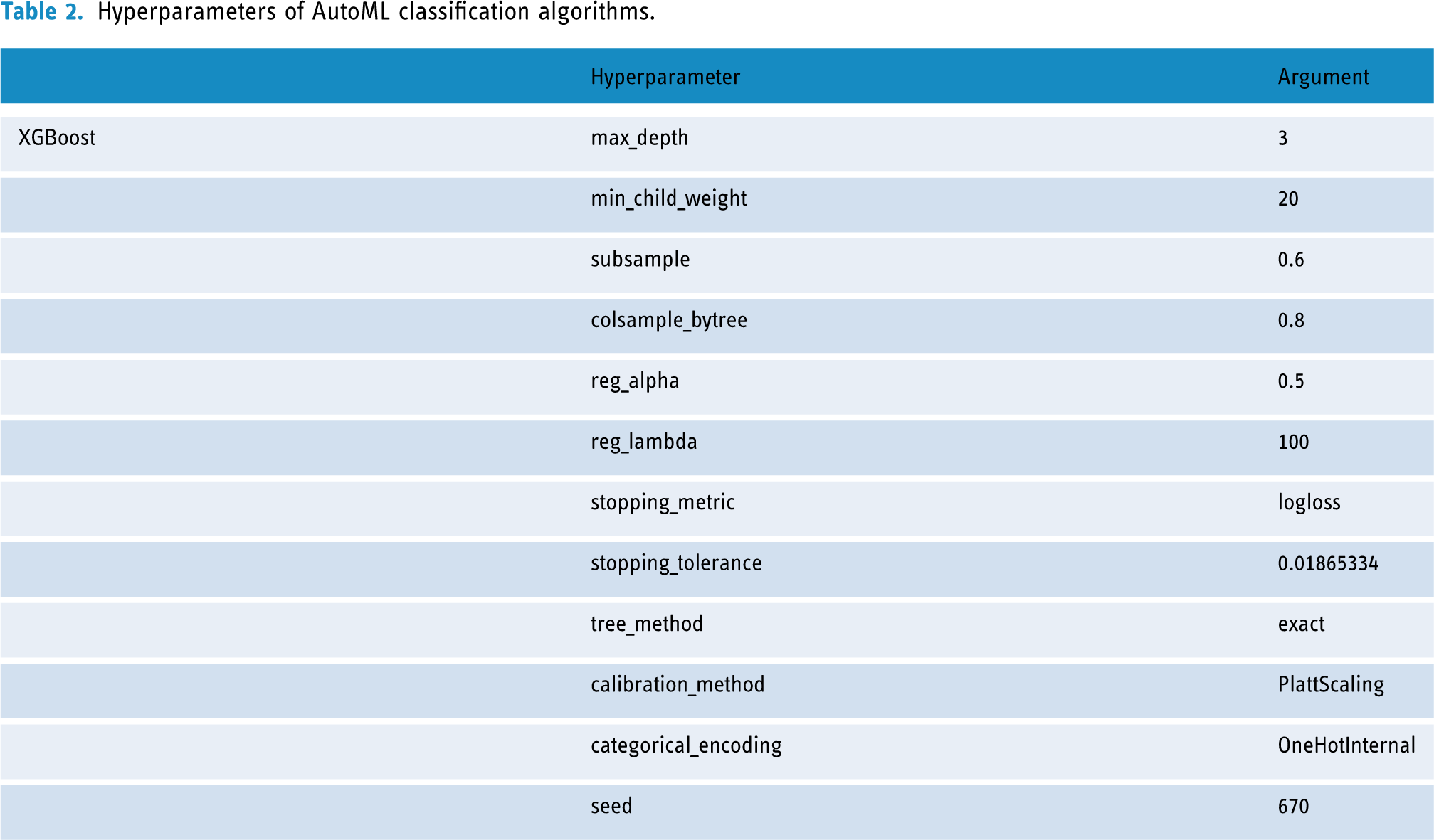
The procedures for the selection of variables are shown in Supplemental Figure 1, with seven key variables with nonzero coefficients identified via the “λ_1se” criterion of LASSO regression analysis, including ALT, waist circumference, HbA1c, FPG, HDL-C, insulin, and TG. The detailed coefficient values of the LASSO regression models are listed in Supplemental Table 1. The AutoML in our study developed a total of 29 models by several machine learning algorithms, including GBM, DRF, XRT, GLM, XGBoost, and DL. The hyperparameters of the optimal XGBoost model are listed in Table 2. The hyperparameters of the remaining assessment models are detailed in Supplemental Table 2.
Hyperparameters of AutoML classification algorithms.
The AUC of each model was tested with the validation set, as shown in Figure 2. According to Table 3, the XGBoost model performed best with the highest AUC value of 0.859 on the validation set. The AUC values obtained by the other models were 0.858 for DL, 0.857 for GBM, 0.853 for GLM, 0.850 for DRF, 0.849 for XRT, 0.838 for FLI, 0.814 for LAP,0.811 for HSI, 0.747 for FLD index, 0.699 for NAFLD index, 0.824 for ZJU index, and 0.844 for FSI.

ROC curves of different models and traditional scoring systems on the validation dataset. (A) ROC curves comparing the performance of various machine learning models. (B) ROC curves comparing the performance of the XGBoost model with traditional scoring systems.
Performance of models on the validation set.
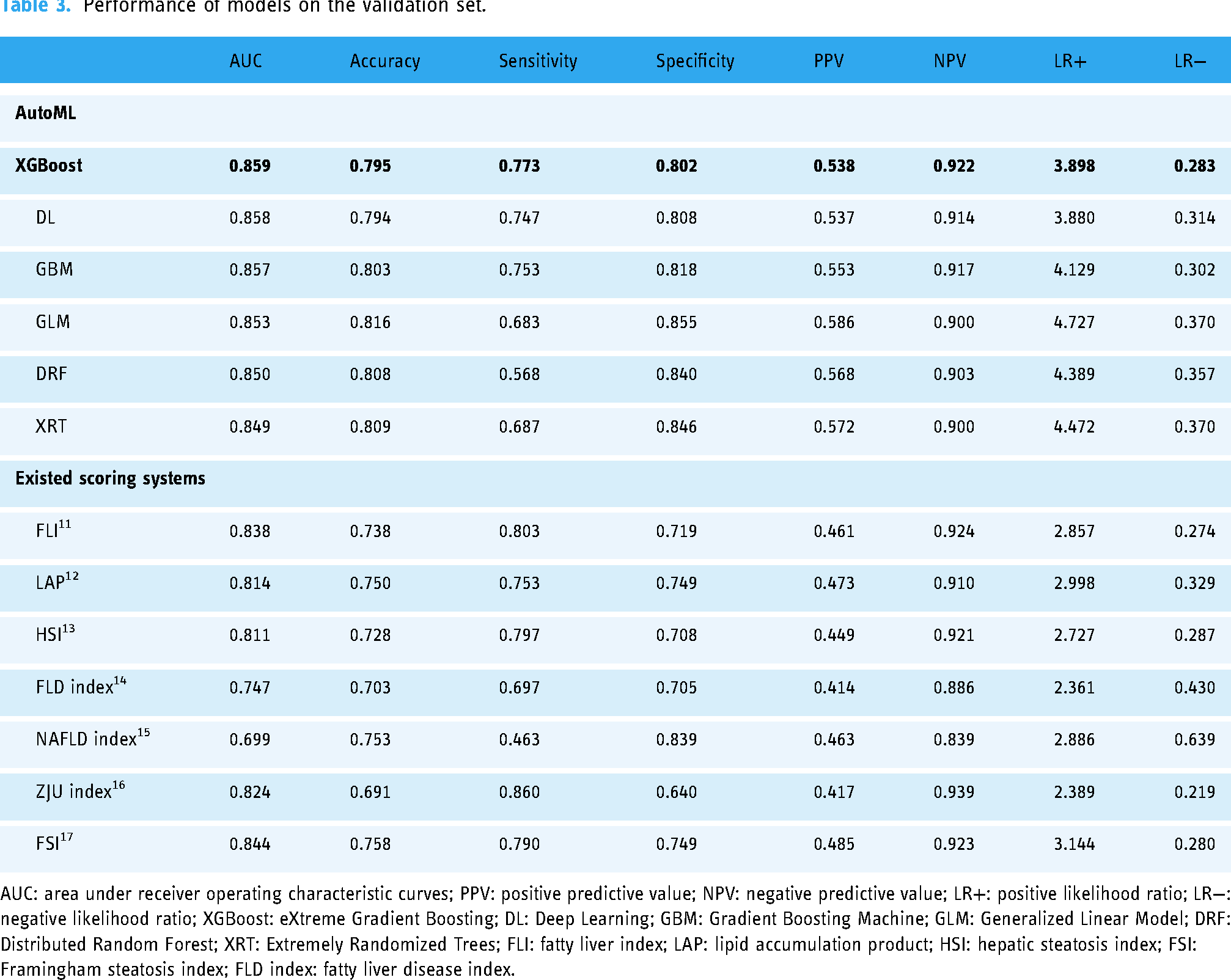
AUC: area under receiver operating characteristic curves; PPV: positive predictive value; NPV: negative predictive value; LR+: positive likelihood ratio; LR−: negative likelihood ratio; XGBoost: eXtreme Gradient Boosting; DL: Deep Learning; GBM: Gradient Boosting Machine; GLM: Generalized Linear Model; DRF: Distributed Random Forest; XRT: Extremely Randomized Trees; FLI: fatty liver index; LAP: lipid accumulation product; HSI: hepatic steatosis index; FSI: Framingham steatosis index; FLD index: fatty liver disease index.
In terms of sensitivity, the XGBoost model achieved a sensitivity of 0.773, indicating strong performance in identifying true positives. This was followed by DL and GBM with sensitivity rates of 0.747 and 0.753, respectively. XRT achieved a sensitivity of 0.687, while DRF had the lowest sensitivity at 0.568. Among the existing scoring systems, the ZJU index and FLI showed higher sensitivities of 0.860 and 0.803, respectively, while the NAFLD index had the lowest sensitivity at 0.463.
For specificity, GLM recorded the highest value at 0.855, demonstrating strong performance in identifying true negatives. XRT and DRF followed with specificities of 0.846 and 0.840, respectively. XGBoost and DL had slightly lower specificities of 0.802 and 0.808. In comparison, the NAFLD index showed the highest specificity among existing scoring systems at 0.839, while the ZJU index had the lowest specificity at 0.640.
Regarding overall accuracy, GLM achieved the best value of 0.816, indicating balanced performance in both sensitivity and specificity. DRF and XRT followed with accuracy values of 0.808 and 0.809, respectively, while XGBoost and DL had accuracies of 0.795 and 0.794. Among the existing scoring systems, the FSI showed the highest accuracy at 0.758, while the FLD index had the lowest accuracy at 0.703. In summary, XGBoost was chosen as the best model due to its highest AUC, strong sensitivity and NPV, and overall balanced performance across key metrics. Other predictive models for fatty liver as detailed in recent studies are catalogued in Supplemental Tables 3 and 4.
An intuitive comparison of the consistency risk assessment model was conducted between the ideal calibration curve and the calibration curves. The evaluation of consistency was further refined by analyzing the slope, ideally valued at 1, and the Brier score, where the deal value is 0, and values exceeding 0.3 indicate poor calibration. The calibration curves presented in Figure 3 demonstrate a robust calibration of the XGBoost model, affirming its reliability. This is evidenced by the close alignment of predicted probabilities with the actual observed probabilities. The model's precision is further highlighted by Brier scores of 0.112 for the training set and 0.121 for the validation set, along with a calibration slope of 1.110 in the training phase and 0.935 in the validation phase. These metrics underscore the model's consistent performance across both the development and application stages.

Calibration curves of the XGBoost model on the training set (A) and the validation set (B). The calibration curves demonstrated a high degree of reliability by showing that the predicted probability was close to the observed probability.
To evaluate the clinical utility of the XGBoost model on NAFLD identification, DCA was conducted. The clinical decision curves, illustrated in Figure 4, revealed that the net benefit of using the model for assessing NAFLD surpassed that of the “no assessment” or “all assessment” regimens. This analysis confirms the XGBoost model as an effective diagnostic tool for NAFLD, demonstrating significant clinical net benefits in identifying the condition.

Decision curve analysis of the XGBoost model on the training set (A) and validation set (B). Decision curve analysis of the XGBoost model on the training and validation set, indicating clinical net benefits of approximately 25%. The threshold probability was represented on the x-axis, while the clinical net benefits were displayed on the y-axis. The grey line indicated the strategy of the assumption that all patients have received the assessment of the XGBoost model, while the horizontal black line demonstrated the strategy of the assumption that no patient has received the evaluation of the XGBoost model.
Interpretation of AutoML models
Furthermore, we identified the most significant clinical features contributing to the identification of NAFLD. The variable importance plot was constructed using XGBoost algorithms. The variable importance plot, shown in Figure 5, ranks these features in descending order of relevance. As depicted in Figure 5, waist circumference emerges as the most crucial risk factor for NAFLD. It is followed by insulin, TG, ALT, FPG, HbA1c, and HDL-C levels. This ranking highlights the relative importance of each variable in the predictive model, with waist circumference having the most substantial impact on NAFLD identification.
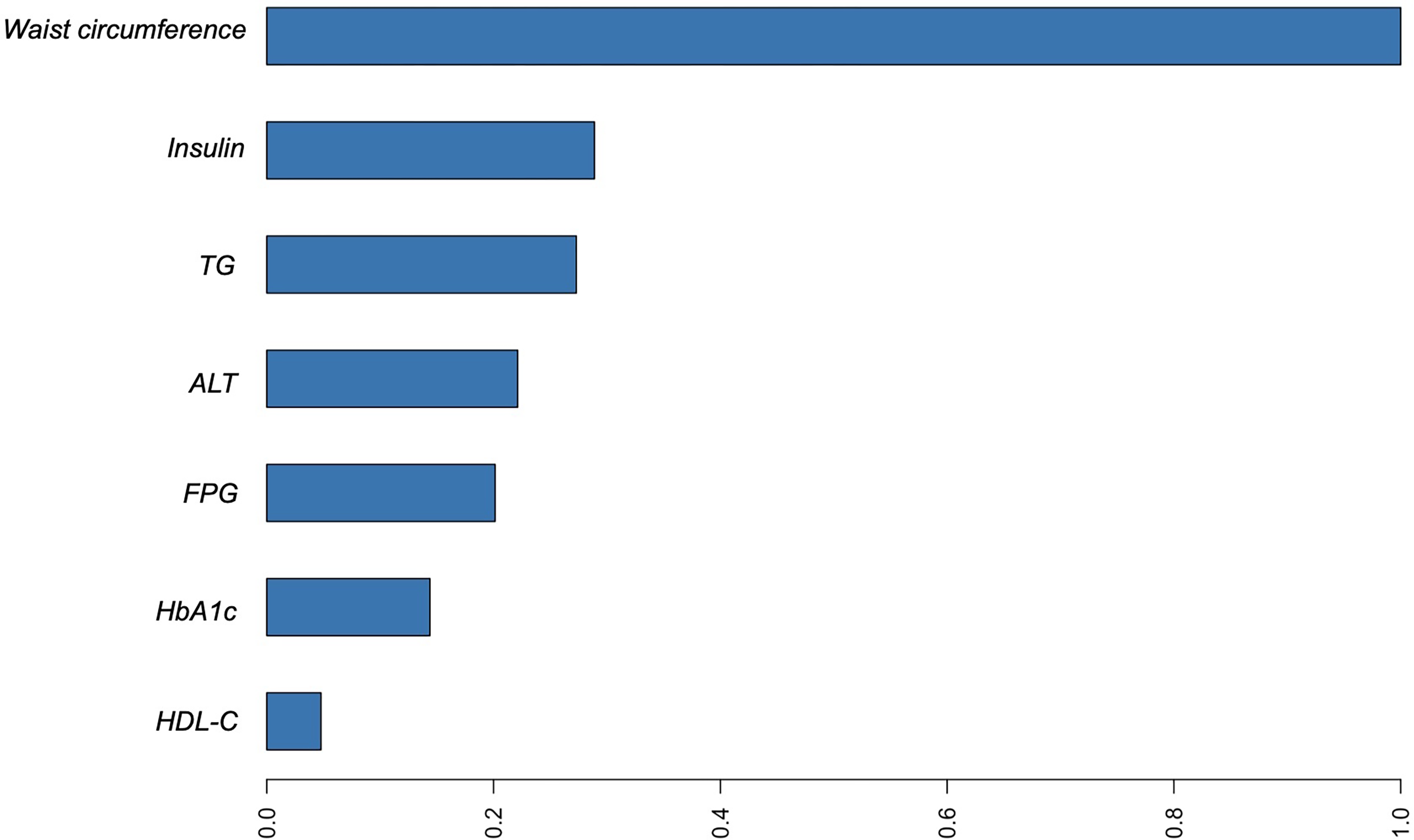
Variable importance of the XGBoost model on the training set.
In Figure 6, we present the SHAP summary plot, which illustrates the contribution of each variable to the prediction of NAFLD for each instance. This plot provides a detailed view of how individual features influence the model's predictions. Notably, the plot shows that higher values of certain features are positively correlated with an increased likelihood of NAFLD. Specifically, waist circumference, insulin levels, ALT, TG, and HbA1c are prominently associated with the presence of NAFLD. Each point on the plot represents a SHAP value for a feature, with the color gradient indicating the normalized value of the feature (ranging from low in blue to high in red). The SHAP values (positioned on the x-axis) reflect the impact of each feature on the model's output. Features with positive SHAP values push the prediction towards higher risk, while negative values push it towards lower risk. For instance, higher waist circumference and insulin levels significantly increase the likelihood of NAFLD, as indicated by their clustering on the right side of the plot with predominantly red points.

SHAP plot of the XGBoost model. The closer the variable values were to 1, the greater the likelihood that NAFLD would be identified.
To interpret the influence of individual features on predicted outcomes, we utilized the PDP technique for interpreting our machine learning model. As presented in Figure 7, waist circumference, insulin, TG, ALT, FPG, and HbA1c exhibit positive correlations with the likelihood of NAFLD. This indicates that higher values of these features are associated with an increased risk of NAFLD. Conversely, HDL-C levels show a negative association with NAFLD, as higher HDL-C levels are associated with a reduced risk.

PDP for the important variables in the XGBoost model.
Figure 8 provides an insightful illustration of the XGBoost model's predictions using the LIME technique. This figure showcases the model's explanations for four randomly selected cases from the validation set, highlighting the contributions of various features to each prediction. The color-coded bars indicate whether each feature supports (blue) or contradicts (red) the predicted outcome. The length of the bars represents the weight of each feature's contribution to the prediction. For instance, in case #7 (label 1, indicating the presence of NAFLD), the XGBoost model predicted a high probability of 0.71 for NAFLD. The most significant variable contributing to the prediction was TG, followed by HbA1c, HDL-C, FPG, waist circumference, ALT, and insulin levels. Similarly, case #3 (label 0, indicating the absence of NAFLD) had a predicted probability of 0.87 for not having NAFLD. The primary contributors to this prediction were TG and HbA1c levels, which strongly contradicted the presence of NAFLD, while HDL-C supported the prediction.
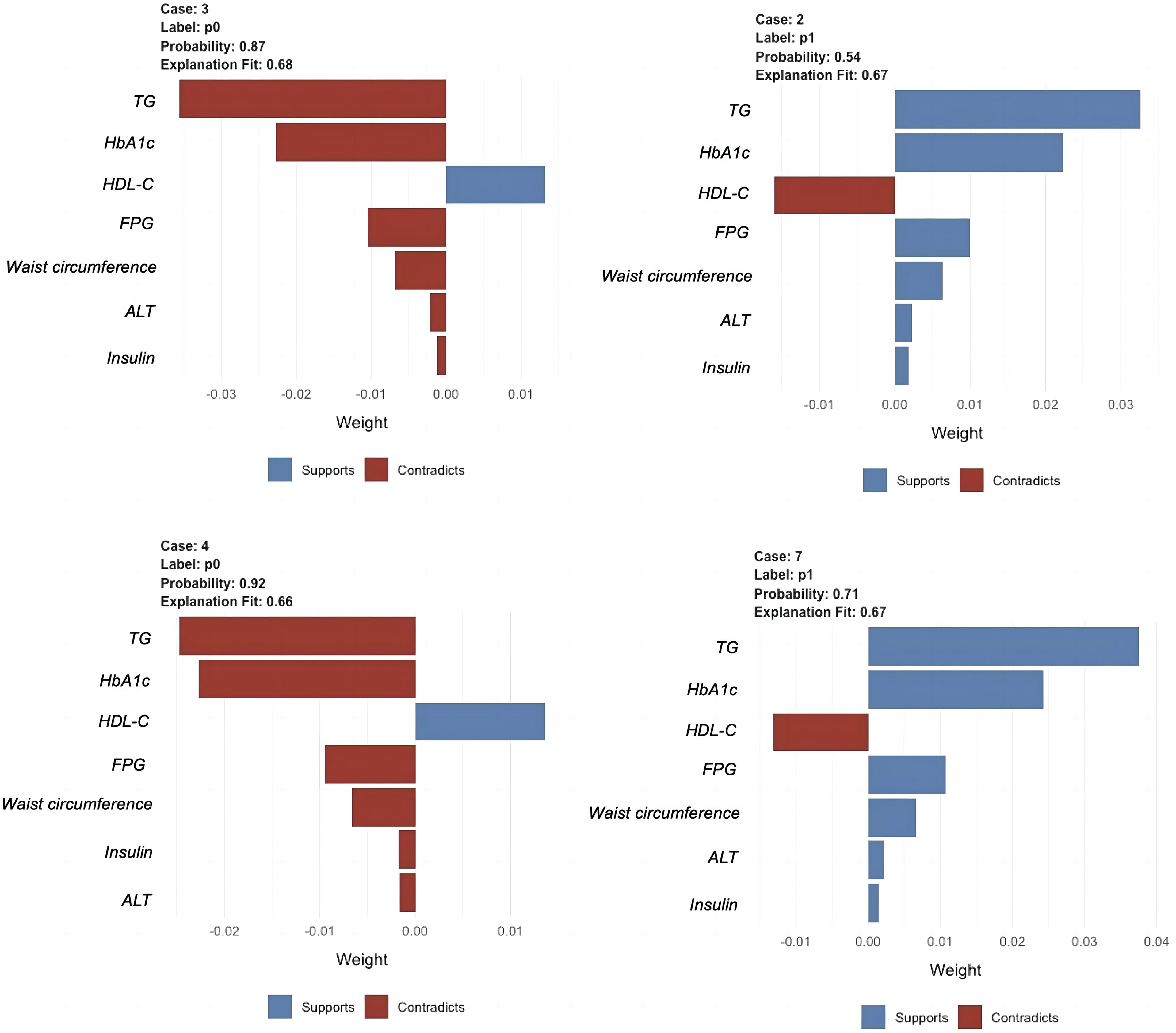
LIME plots of the XGBoost model. Four individuals were selected randomly from the validation set to see the impact of the main features on the outcome.
The code for automated machine learning modeling is available on the following website: https://osf.io/nvwek, while the code for model deployment can be accessed at https://osf.io/6cxmb. Clinical practitioners are invited to further refine and optimize the model by utilizing these open-source resources in their future work.
Discussion
In this investigation, we have developed a series of AutoML models to detect NAFLD utilizing the NHANES database. These models were all superior to existing scoring systems such as FLI, LAP, HSI, NAFLD index, ZJU index, FSI, and FLD index. Notably, the model employing the XGBoost algorithm emerged as the superior performer within the ensemble of AutoML models on the validation set. To augment the interpretability of the model, we implemented an array of explanatory tools including variable importance, SHAP, PDP, and LIME. Additionally, we introduced ‘Shiny NAFLD’, a newly developed R Shiny tool based on the XGBoost model for identifying NAFLD using demographic data and clinical data. ‘Shiny NAFLD’ stands as a testament to the practical utility of our research, offering an accessible platform for healthcare professionals to identify NAFLD.
The significant demographic differences observed in our study suggest that higher CAP values are associated with specific population characteristics. The higher proportion of males and the older median age in the CAP ≥ 302 dB/m group indicate that gender and age may influence liver fat accumulation, as noted previously. 36 The significant racial differences, with a higher proportion of non-Hispanic whites in the CAP ≥ 302 dB/m group, point to potential genetic or lifestyle factors that warrant further investigation. 37
In addition, the biochemical differences highlight several health risks associated with higher CAP values. Consistent with Ayada et al.'s findings, elevated levels of ALT, AST, and GGT suggest that individuals in the CAP ≥ 302 dB/m group may have a higher risk of liver dysfunction. 38 The higher levels of HbA1c and FPG in the CAP ≥ 302 dB/m group underscore a greater prevalence of impaired glucose metabolism or diabetes, which aligns with studies showing a strong association between NAFLD and metabolic disorders such as type 2 diabetes. 39 Additionally, the abnormal lipid profiles, including elevated TC, TG, and LDL-C, suggest an increased risk of cardiovascular diseases, corroborating previous research that highlights the link between NAFLD and cardiovascular risk. 40 Furthermore, the anthropometric measurements further emphasize the health risks, with significantly higher weight, BMI, arm circumference, waist circumference, and hip circumference in the CAP ≥ 302 dB/m group, indicating a strong association between NAFLD and obesity, which is a known risk factor for various metabolic disorders.41,42 Overall, our findings highlight the importance of regular monitoring and targeted interventions for individuals with NAFLD. 43 These individuals are at an increased risk for liver dysfunction, metabolic disorders such as diabetes, cardiovascular issues, and obesity-related complications.38–41 Comprehensive health assessments and personalized treatment plans are crucial for managing these risks and improving health outcomes.
Considering the adverse effects associated with invasive liver biopsies, the subjectivity inherent in ultrasound examinations, and the prohibitive costs associated with FibroScan diagnostics, our AutoML models stand out as high-quality tools for NAFLD diagnosis. Traditional scoring systems, including FLI, 11 LAP, 12 HSI, 13 NAFLD index, 15 ZJU index, 16 FSI, 17 and FLD index, 14 demonstrated inferior accuracy and AUC compared to the models we built using AutoML. This aligns with recent literature emphasizing the need for more accurate and non-invasive diagnostic tools for NAFLD.5,8 In this study, we evaluated a suite of models constructed using AutoML's six algorithms (GBM, DRF, XRT, GLM, XGBoost, and DL) to assess the presence of NAFLD. The XGBoost model demonstrated superior performance with an AUC of 0.859, an accuracy of 0.795, a sensitivity of 0.773, a specificity of 0.802, a PPV of 0.538, an NPV of 0.922, an LR + of 3.898, and an LR− of 0.283. The AUC metric proved particularly useful in addressing the challenges of unbalanced data, as it inherently weights both classes equally, unlike accuracy. 44 Additionally, a high AUC indicates that the model has a strong capability to distinguish between patients with and without NAFLD, making it a reliable measure for evaluating the effectiveness of our diagnostic approach.
Given that early-stage NAFLD is often asymptomatic and, if left untreated, may progress to more severe conditions such as cirrhosis and hepatocellular carcinoma, our research prioritizes the early detection of NAFLD patients, making the sensitivity metric particularly critical. Sensitivity, defined as the proportion of true positives among all confirmed cases, measures our model's ability to correctly identify actual cases of NAFLD. The XGBoost model's high sensitivity of 0.773 underscores its success in accurately detecting NAFLD among those afflicted, which is particularly significant given the asymptomatic nature of early-stage NAFLD, where early detection is crucial for preventing disease progression.
Furthermore, specificity indicates the model's ability to correctly identify patients without NAFLD, thus reducing the rate of false positives. The XGBoost model achieved a specificity of 0.802, minimizing unnecessary further testing and patient anxiety. PPV measures the proportion of true positive results among all positive predictions, with the XGBoost model demonstrating a PPV of 0.538, indicating the reliability of a positive NAFLD diagnosis. NPV represents the proportion of true negative results among all negative predictions, and the XGBoost model showed an impressive NPV of 0.922, highlighting its effectiveness in ruling out NAFLD when the prediction is negative. Moreover, LR + and LR− provide additional insights into the model's diagnostic utility, with a high LR + indicating a strong association between a positive test result and the presence of NAFLD, and a low LR− suggesting that a negative test result is effective in ruling out the disease. Consequently, given its optimal balance of these metrics, the XGBoost model emerged as the most effective tool in our analysis for NAFLD detection.
The XGBoost model demonstrated robust calibration, with Brier scores of 0.112 for the training set and 0.121 for the validation set, and calibration slopes of 1.110 and 0.935, respectively. The DCA showed that the XGBoost model provides a higher net benefit for NAFLD identification compared to “no assessment” or “all assessment” strategies. Combining the results of the calibration curves and DCA, we can assert that our XGBoost model not only performs well in terms of predictive accuracy but also offers tangible benefits in clinical settings. The robust calibration ensures that the predicted risks are reliable, while the decision curve analysis highlights the practical advantages of implementing the model in patient care.
To enhance the interpretability of our XGBoost model, we employed several techniques: variable importance analysis, SHAP, PDP, and LIME. These techniques highlight the most critical predictors, such as waist circumference and insulin levels, and provide detailed insights into how individual features influence the model's predictions. Variable importance analysis ranks features based on their contribution to the model's predictions, thereby identifying the most influential factors. Additionally, SHAP values quantify the contribution of each feature to individual predictions, demonstrating the positive correlation of features like waist circumference and insulin with NAFLD risk. Furthermore, PDP illustrates the relationship between a feature and the predicted outcome while keeping all other features constant, which helps in understanding the marginal effect of a feature. Finally, LIME offers local explanations for specific predictions, providing case-specific insights that clarify the model's decision-making process. By using these methods, we ensure that our model's predictions are understandable, trustworthy, and clinically relevant. These interpretability techniques improve the transparency and applicability of the model, enhancing trust in its use for clinical decision-making.
NAFLD exhibits a complex, bidirectional association with metabolic syndrome components, acting both as a contributing factor and a result of the metabolic syndrome (MetS).1,45 In our study, waist circumference was found to be the most crucial variable in the variable importance plot, followed by insulin, TG, ALT, FPG, HbA1c, and HDL-C. It is noteworthy that the majority of these critical variables (waist circumference, insulin, TG, FPG, and HbA1c) are core components of MetS, which demonstrates the feasibility of metabolic syndrome markers in identifying NAFLD.
Previous research has established waist circumference as an independent risk factor and a potent predictor of NAFLD.46,47 A substantial retrospective study that analyzed physical examination data from Chinese adults yielded predictive models for NAFLD, accentuating the value of waist circumference as an indicator. 20 Several studies have demonstrated a strong correlation between obesity and NAFLD.48–50 However, emerging research suggests that this relationship might be impacted by fat distribution. 51 A condition termed ‘lean NAFLD’ occurs in individuals who develop NAFLD despite having a normal BMI (<25 kg/m2 in non-Asian, <23 kg/m2 in Asian). 52 Such patients usually have central obesity or possess additional metabolic risk factors. 53 A meta-analysis from Pang et al. investigated the independent associations of central and general obesity with NAFLD. 42 Their findings highlighted that the pooled OR for waist circumference (3.14 [2.07–4.77]) was higher compared to BMI (2.85 [1.60–5.08]), with binary variables and using the nonobese cohort as a reference. This indicates that abdominal obesity may pose a higher risk for NAFLD than general obesity.
Insulin has been proven as a strong predictor of NAFLD according to previous studies.54,55 Bril et al. 56 demonstrated that intact molecules of insulin by mass spectrometry hold a high AUC of 0.90 for identifying NAFLD in individuals without diabetes. They also suggested measuring fasting intact insulin levels as a simple, non-invasive method of identifying the presence of NAFLD.
TG and FPG are two key metabolic variables that are modified in fatty liver and have a strong correlation with insulin resistance. 57 Insulin resistance, which is defined as the ability of insulin to inhibit glucose generation, lipid synthesis, and lipolysis, is the underlying cause of hyperglycemia and an increase in TG in NAFLD. Insulin resistance also limits the receptor-mediated entry of insulin into the liver, which reduces insulin clearance.58,59 Furthermore, there will be hyperinsulinemia, leading to hepatic steatosis. 58 Tomizawa et al. reported that TG was the strongest predictor of NAFLD among markers of hyperlipidemia and diabetes. 60 Another study by Liu et al. proposed that elevated levels of circulating TG and high glucose levels are likely to increase the risk for NAFLD. 61 In addition, Zhang et al. observed that individuals with NAFLD had significantly higher FPG and TG levels than those with non-NAFLD. 62 Recently, the triglyceride and glucose index (TyG), derived from the product of TG and FPG, has been validated as a reliable biomarker for identifying NAFLD with a sensitivity of 72.2% and a specificity of 70.5%. 62 Lee et al. have also reported the predictive powers of the homeostatic model assessment for insulin resistance (HOMA-IR), a hepatic insulin resistance index consisting of FPG and Insulin, for predicting NAFLD. 63 Their findings reveal that HOMA-IR exhibits excellent predictive capacity for NAFLD with an AUC of 0.831.
HbA1c serves as a valuable marker for chronic glycemic control by reflecting average blood glucose levels over the preceding 8–12 weeks. 64 Ma et al. and Bae et al. discovered serum HbA1c level was significantly and independently associated with the risk for NAFLD.65,66 In clinical practice, a mild to moderate elevation in ALT is frequently the sole laboratory abnormality in NAFLD patients and is considered an early, surrogate biomarker for the disease. 67 Furthermore, Zhang et al. conducted research on ALT as a diagnostic tool for NAFLD, with an AUC of 0.715. 62 Additionally, a Mendelian randomization analysis has demonstrated that genetically predicted elevated serum liver enzymes could increase NAFLD risk, whereas HDL-C was linked to a decreased risk of NAFLD. 68
Logistic regression, a linear model commonly employed for binary classification tasks, struggled to tackle complex learning tasks. With the development of machine learning, leveraging algorithms, such as XGBoost, GBM, support vector machine (SVM), deep learning, and DRF, have significantly improved the efficacy of handling more intricate problems. Recent studies69,70 provide robust evidence of the exceptional potential of machine learning in disease diagnosis and the anticipation of risk factors. Qin et al. 23 have demonstrated the efficacy of the SVM model for NAFLD screening achieving an impressive accuracy of 0.801 and an AUC of 0.850, using data from annual health examinations. Additionally, using data from NHANES 1988–1994, Atsawarungruangkit et al. 29 developed a random undersampling boosted trees model to predict NAFLD with an accuracy of 0.711. Due to the use of different databases and diagnostic methods, comparing the results is inappropriate. Noureddin et al. 28 have developed six different machine-learning models to identify NAFLD by leveraging demographic and clinical data from the NHANES 2017–2018 cohort, with participants identified through transient elastography. The performance metrics of the tested models exhibit an AUC in the range of 0.79 to 0.84, an accuracy spanning from 0.75 to 0.79, and a sensitivity varying between 0.53 and 0.71. These figures are comparatively lower than those of our proposed model, which has an AUC of 0.859 and an accuracy of 0.795, underscoring its superior diagnostic efficacy. The use of AutoML automates the selection and tuning of machine learning models, thereby simplifying the process for clinical practitioners and enhancing diagnostic efficacy.
Innovative imaging techniques leverage sophisticated algorithms and neural networks to significantly improve the precision of diagnostics. 71 However, such models require parameter adjustment and feature engineering that rely on human machine learning experts, hence constraining their widespread implementation. Our study addresses this challenge by using the H2O AutoML platform, which automates these processes, making machine learning more accessible to individuals lacking expertise in this domain and enhancing the efficiency of machine learning processes. Moreover, our development of the Shiny NAFLD web application provides a practical and user-friendly tool for healthcare professionals, offering a non-invasive method to enhance diagnostic accuracy. This is particularly significant in the context of NAFLD, where early and accurate diagnosis is crucial for preventing disease progression and implementing effective treatment strategies.
The integration of AutoML into NAFLD diagnostics represents a shift towards a more streamlined, individualized, and objective approach. This innovation is poised to markedly enhance patient outcomes by enabling the early detection of conditions, thereby improving prognoses and reducing dependence on diagnostic methods that are often costly and limited in availability. Particularly advantageous in primary care settings and regions with limited resources, AutoML emerges as a cost-effective and scalable solution, optimizing the distribution of medical resources. The incorporation of AutoML into clinical practices may signify an advancement towards an accessible and efficient strategy for managing NAFLD.
This study highlights several key features: firstly, the application of AutoML streamlines the process of algorithm selection, hyperparameter adjustment, and optimal model output, offering a user-friendly tool for clinicians of varied statistical expertise. Based on the optimal model in AutoML, we present an R Shiny web-based application, Shiny NAFLD, to facilitate the identification of NAFLD in real clinical practice. Secondly, it leverages demographic and clinical information from NHANES, an open-accessed cross-sectional study in the United States, to develop and validate models to identify the presence of NAFLD in study participants. Furthermore, the diagnosis of NAFLD via ultrasound examination is often hampered by numerous factors, particularly the subjectivity of the examiner. This research utilizes the CAP measured at a threshold of ≥302 dB/m through LUTE, which has been shown to yield greater accuracy and sensitivity compared to conventional ultrasound methodologies. Lastly, the study enhances the interpretability of complex ‘black-box’ models through various visualization techniques, such as variable importance, SHAP, PDP, and LIME.
Some limitations of this study should be noted. Firstly, the same database was used for both the training and validation sets, which may constrain the model's generalizability. Using only the NHANES database for modeling may limit the generalizability of our findings, as the dataset may not fully represent diverse populations and clinical settings. To ensure broader applicability, it is essential to test the model with external datasets from various demographic and geographic backgrounds. Additionally, as a retrospective study, there is an inherent risk of selection bias and other potential biases that could affect the findings. Secondly, due to the limitations and restrictions of the NHANES database, secondary causes of hepatic fat accumulation, such as Wilson disease and inborn errors of metabolism (e.g., lecithin-cholesterol acyltransferase deficiency, cholesterol ester storage disease, Wolman disease), could not be ruled out. Additionally, the scope of the data, including any temporal limitations, should be considered, as data collected over a specific time may not capture all relevant trends and patterns. Lastly, there is ongoing debate surrounding the established cutoff values for steatosis when using CAP, suggesting that further research is required to reach a consensus on these diagnostic thresholds. Future research should focus on validating and refining the model across different populations and clinical environments. Additionally, extending this model to incorporate real-time data integration will enhance its usability and adaptability in diverse clinical scenarios.
Conclusion
This study demonstrated the effectiveness of using machine learning algorithms on the H2O AutoML platform to identify NAFLD by analyzing key variables. XGBoost emerged as the best performer, highlighting its potential for clinical diagnosis. We developed Shiny NAFLD, an R Shiny web application (http://39.101.122.171:3838/App2/), providing healthcare professionals with a non-invasive tool to enhance NAFLD diagnostic accuracy and support personalized treatment strategies. Future research should validate the models on external datasets, explore interpretability techniques, and investigate applications to other diseases.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241272535 - Supplemental material for Automated machine learning models for nonalcoholic fatty liver disease assessed by controlled attenuation parameter from the NHANES 2017–2020
Supplemental material, sj-docx-1-dhj-10.1177_20552076241272535 for Automated machine learning models for nonalcoholic fatty liver disease assessed by controlled attenuation parameter from the NHANES 2017–2020 by Lihe Liu, Jiaxi Lin, Lu Liu, Jingwen Gao, Guoting Xu, Minyue Yin, Xiaolin Liu, Airong Wu and Jinzhou Zhu in DIGITAL HEALTH
Footnotes
Acknowledgements
We would like to thank AW and JZ for their assistance and guidance in this research.
Contributorship
AW and JZ researched the literature and conceived the study. LL (Lihe Liu), JL, LL (Lu Liu), JG, GX, MY, and XL were involved in protocol development, gaining ethical approval, and data analysis. LL (Lihe Liu), JL and LL (Lu Liu) wrote the first draft of the manuscript. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
We used publicly available datasets from the official NHANES website (https://wwwn.cdc.gov/nchs/nhanes). NHANES was conducted in accordance with the Declaration of Helsinki and approved by the NCHS Research Ethics Review Board (Continuation of Protocol #2011–17 and Protocol #2018-01, 26 October 2017). More details can be found at ![]() . Therefore, the need for ethical approval was not applicable.
. Therefore, the need for ethical approval was not applicable.
Informed consent statement
Informed consent was obtained from all subjects involved in the study. More details can be found at the following links: https://www.cdc.gov/nchs/nhanes/participant/participant-confidentiality.htm, https://wwwn.cdc.gov/nchs/nhanes/continuousnhanes/documents.aspx?BeginYear=2019, and ![]() .
.
Guarantor
Airong Wu and Jinzhou Zhu.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Youth Program of Suzhou Health Committee (grant number KJXW2019001) and the Suzhou Clinical Center of Digestive Diseases (grant number Szlcyxzx202101).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.