
Abstract
The Daily Living Questionnaire (DLQ) constitutes one of a number of functional cognitive measures, commonly employed in a range of medical and rehabilitation settings. One of the drawbacks of the DLQ is its length which poses an obstacle to conducting efficient and widespread screening of the public and which incurs inaccuracies due to the length and fatigue of the subjects.
Objective
This study aims to use Machine Learning (ML) to modify and abridge the DLQ without compromising its fidelity and accuracy.
Method
Participants were interviewed in two separate research studies conducted in the United States of America and Israel, and one unified file was created for ML analysis. An ML-based Computerized Adaptive Testing (ML-CAT) algorithm was applied to the DLQ database to create an adaptive testing instrument—with a shortened test form adapted to individual test scores.
Results
The ML-CAT approach was shown to reduce the number of tests required on average by 25% per individual when predicting each of the seven DLQ output scores independently and reduce by over 50% when predicting all seven scores concurrently using a single model. These results maintained an accuracy of 95% (5% error) across subject scores. The study pinpoints which DLQ items are more informative in predicting DLQ scores.
Conclusions
Applying the ML-CAT model can thus serve to modify, refine and even abridge the current DLQ, thereby enabling wider community screening while also enhancing clinical and research utility.
Keywords
Introduction
Functional cognition refers to the use of cognitive processes in daily living activities, namely, the ability to perform daily tasks while using cognitive components such as attention and memory.1,2 It is defined as “the ability to use and integrate mental and physical skills to accomplish complex everyday activities.” 3 Successful performance of novel or complex activities depends on the ability to efficiently and effectively use and adapt cognitive processes under a wide range of challenges.
Assessment methods for evaluating functional cognition include cognitive or neuropsychological tests, performance-based assessments and self and informant-report questionnaires. Neuropsychological tests 4 evaluate specific cognitive components and provide baseline profiles, that are norm-referenced yet they do not address the relationship between cognition and function.5–7 Performance-based assessments 8 enable direct observation of cognitive processes and the use of strategies during specific functional activities. 9 Examples include the Executive Function (EF) Performance Test 10 and the Kettle test. 11 However, there is, currently, no gold standard performance-based assessment 12 and the number of functional domains that can be evaluated are limited. 13 Questionnaire-based methods are also common in assessing complex everyday activities and functional cognition. Advantages are cost-effectiveness, minimal training requirements, flexible delivery formats (verbally, by phone, electronically) and anonymous administration to a larger population. Self- and informant reports provide a unique, subjective view of the impact of functional cognition on everyday activities in a real-life context. 14
The Daily Living Questionnaire (DLQ) is a self-report functional cognition instrument that assesses cognitive difficulties in performing higher-level activities including Instrumental Activities of Daily Living (IADLs) (shopping; meal planning), community, work and social participation with the aim of assisting therapists in setting treatment goals. 15 The DLQ is comprised of two parts: Part A focuses on activity and participation, and Part B focuses on everyday cognitive symptoms. See DLQ form in Appendix. Use of self-report questionnaires is recommended, 16 however biases in the form of over- or under-estimation of abilities may emerge. In addition, fatigue related to answering a large number of questions may also affect responses, resulting in incomplete answers or low response rates.16,17 The latter poses an obstacle to conducting efficient and widespread screening of the public for deteriorating functional cognitive abilities. The problem is more acute among individuals with posttrauma, pending medical interventions, long-term COVID and among the elderly community. The goal of this study is to reduce the DLQ questionnaire to a shorter, more efficient assessment.
Machine Learning (ML) algorithms are data-driven and use large datasets to identify patterns in the data and subsequently use these patterns to predict outcomes on novel data. ML is proving to be an effective tool in predicting medical conditions and assisting medical decision-making.18,19 Computerized adaptive testing (CAT) is an algorithm, based on Item Response Theory (IRT); it adapts or customizes questionnaire items to match individual test-taker ability and predicts the final questionnaire score. The CAT process terminates with a final score when the set number of items has been administered or a precision level has been reached. 20 The CAT approach reduces the average number of items to be administered while maintaining the accuracy of the final test score.21,22 Additionally, it facilitates more precise assessments that are tuned to the level and abilities of the individual, in comparison to traditional static questionnaires that employ the same questions for all test-takers without taking into account the unique characteristics of individuals.22,23 In this study we use a novel CAT algorithm that is based on machine learning and is thus termed ML-CAT. Whereas IRT is a logit-based algorithm, the ML-CAT is based on machine learning and does not place assumptions on the distribution (e.g. normal as in IRT) and the distribution of the data may take any form (restricted to having enough and balanced data in each class). Furthermore, IRT considers the responses of the user an item at a time with older items usually having a smaller effect. The ML-CAT assigns equal importance to all item responses up to that point and may rely heavily on the earlier items in the sequence if indeed they are more predictive.
The aim of this study is to predict the final scores of the DLQ assessment using a reduced set of DLQ questions. The ML-based algorithm, ML-CAT will reduce time and fatigue in completing the DLQ, thereby decreasing patient answer bias to the questionnaire. The ML-CAT can assist in the wide screening of subjects and allow researchers and therapists to collect information in a shorter period of time, with higher accuracy. Our research goals are (1) to develop an efficient ML-CAT scheme with reduced item questions while maintaining the accuracy of the final scores, (2) to determine if a computerized DLQ has the potential to shorten the administration time of the DLQ and (3) to determine if there are key DLQ items that are consistently selected by the ML-CAT.
Method
Participants
Correlative studies were conducted between 2007 and 2021 in which participants completed the DLQ and other questionnaires. 15 All studies were approved by the IRB and Ethics committees. One thousand one hundred and eight participants completed the questionnaire. 63.6% were women and mean (SD) age was 55.5 (16.7). Most participants were at a high education level (n = 599). Out of the total, 85.9% of the participants were in good health while 14.1% had a medical condition, such as fibromyalgia, multiple sclerosis, or COVID-19, see Table 1.
Characteristics of the participants (n = 1108).

Measures
The DLQ is a self-report questionnaire developed to measure functional cognition as reflected through daily activities performance including IADL, at home, work and community as well as social participation. It includes 52 items scored on a 4-point visual analog scale (from 1—no cognitive difficulty to 4—unable to perform) and is divided into two parts: Part A—activity and participation; Part B—cognitive symptoms and impairments. Factor Analysis (FA) revealed seven scores, each calculated by averaging a subset of test items (see Table 2). 15 High internal consistency was found for all 52 items (0.94) and for Part A and Part B (0.87; 0.94, respectively). See Appendix.
DLQ description.

DLQ: Daily Living Questionnaire.
Procedures
Patients were recruited across several different research studies and were interviewed using the DLQ. 15 Patients’ responses were collected as a database DLQ-DB for use in the ML-CAT method described in this article. Some patients did not answer all questions. Missing data was completed using a Nearest Neighbor approach 24 similar to Hot Deck Imputation, 25 in which each missing score is replaced by the median of the scores of the most similar subjects. Additionally, stratified sampling and augmentation of the data 26 were performed to reduce the bias in scores across subjects in the dataset.
Machine learning model
To allow an adaptive testing protocol, we follow a CAT scheme. 27 Our approach is based on a novel machine learning-based CAT algorithm 28 we term ML-CAT. The algorithm iteratively selects the next DLQ question to be administered to the subject based on the subject's responses. Denote the resulting sequence of DLQ questions as DLQi1, DLQi2,…. In addition to the next question to be administered, the machine learning component also predicts the final DLQ score 1 at each iteration. The iterative process terminates when the predicted DLQ score reaches a high enough confidence value and the final DLQ score is outputted. A schematic diagram is given in Figure 1. We present two types of ML-CAT algorithms: the first predicts a single DLQ score (thus a separate algorithm is used for each of the seven DLQ-output scores) and the second predicts all seven DLQ-output scores concurrently. Details of the ML-CAT method follow.

DLQ adaptive testing. Flow diagram describing the adaptive testing scheme (see text).
Given the DLQ-DB database (n = 1108), we build ML predictors to predict the final DLQ score. We train numerous ML predictors each of which receives as input a subset of DLQ responses and predicts the final DLQ score together with a confidence measure. Thus, we create a dataset of many such predictors each with a different subset of DLQ responses as input.
Given this dataset of predictors and the DLQ-DB database of testing results, the ML-CAT adaptive testing proceeds as follows. W.l.g, we assume the first DLQ question is given. The following steps are iteratively performed:
Assume the subject has already been administered k-test questions DLQi1 … DLQik. From the dataset of ML predictors, select those predictors that receive as input responses to the set DLQi1 … DLQik plus an additional DLQ answer: DLQnew. From the database DLQ-DB, select M samples that are most similar to the subject in their responses to DLQi1 … DLQik. From among the selected predictors (step 2) find the predictor MLk + 1 that is most accurate in predicting the final DLQ score on the M samples selected in step 3. Set DLQnew as the next question (DLQi(k + 1)) to be administered to the subject. If the confidence of the prediction of MLk + 1 on the M samples (step 3) is above threshold T
Output the final score prediction of model MLk + 1 Stop program. Else: Return to step 1 with the subject's answers to DLQi1 … DLQik, DLQi(k + 1).
The adaptive scheme requires two parameters: M - the number of samples chosen from the database DLQ-DB and threshold T which determines the level of confidence required for the final prediction.
Detailed description of the modeling
The schema of the adaptive testing detailed above may be implemented using any number of ML models. In Eichler et al.,
28
Random Forest
29
was used as the predictor architecture. In this study, we used linear regression models as the predictors since this sufficed to provide excellent results. Each regressor model predictor is trained by receiving as input a subset of k DLQ answers, DLQi1 … DLQik for each of the M samples (step 3) together with the final DLQ score DLQfinal for each sample. The regressor model computes the regression variables that minimize the prediction error 
Results
The ML-CAT adaptive testing scheme was implemented and tested on the DLQ-DB database of assessment results. The approach was tested for the prediction of each of the seven DLQ output scores (A1, A2, A3, A4, B1, B2, B3) independently as well as predicting all seven scores concurrently.
A leave one out 30 scheme was used to assess the adaptive algorithm, where each sample in the DLQ database was used as a subject and the remaining samples were considered as the training set (i.e. as the DLQ-DB database in the algorithm above). The accuracy of score prediction is calculated as the absolute difference between the predicted score and the true score given in the database.
The models are dependent on two hyperparameters: the level of accuracy T and the number M of samples of the database, closest to the subject. These parameters affect both the accuracy of score prediction and the number of questions required of each subject.
Figure 2 plots the average error of prediction (mean absolute difference) as a function of the number of DLQ questions for the seven output scores. For each output score, points represent different values of accuracy (T = 0.001, 0.003, 0.005, 0.007, 0.01, 0.03, 0.05, 0.07, 0.1). Three plots are shown, each for a different value of M, the number of samples in the database to train on (M = 100, 250, 500).

The average error of prediction (mean absolute difference) for the seven output DLQ scores as a function of the number of DLQ questions. For each output score, points are for different values of accuracy (T = 0.001, 0.003, 0.005, 0.007, 0.01, 0.03, 0.05, 0.07, 0.1). Three plots are shown: Top: M = 100, middle: M = 250, bottom: M = 500.
As can be seen in all plots, the error of prediction decreases with increasing number of questions for all output scores, which, in turn, is controlled by the threshold value T. Predicting some DLQ scores require more questions than others (e.g. B1 vs. A4) for the same level of accuracy. It can also be seen that the number of questions to reach a specific level of accuracy, varies across M values, with some DLQ scores requiring more questions than others for higher M (e.g. A2 vs. B3).
To continue the analysis, we consider the tradeoff between accuracy and number of questions and set M = 250 and T = 0.01. We predicted each DLQ output score independently using the ML-CAT model using these values of parameters. Figure 3 shows the average error obtained for each of the DLQ output scores. All errors are smaller than 0.1 MSE with an average error rate of 0.047. Given that the DLQ scores are on a 1–4 scale, these results show high accuracy (low mean absolute error). Figure 4 shows the average number of questions required per DLQ output score to obtain these error rates. These numbers are much lower than the number required by the standard test with savings between 12% and 41% per DLQ score (see Table 3). Figure 5 displays a histogram of the number of times each of the 52 DLQ questions appeared as one of the first three questions in the adaptive testing sequences. Color coding is according to the seven DLQ output scores in the original questionnaire.

Average error when predicting each output score independently.

The average number of questions required to predict each DLQ output score independently with error rates given in Figure 3. Summing the average number of questions required of all labels gives 38.85 questions (compare with the original 52 questions).

The number of occurrences of each DLQ question as one of the first three questions in the ML-CAT approach when predicting each outcome measure independently. Color coding is according to the seven DLQ output scores in the original questionnaire (n = 2216).
The average reduction in questions obtained by using the ML-CAT approach compared to the original questionnaire.

ML-CAT: Machine Learning-based Computerized Adaptive Testing; DLQ: Daily Living Questionnaire.
Figure 4 shows that the total number of questions (without repeats) required to predict all DLQ output scores is 38.8 (out of 52) implying a 25.3% reduction. This reduction was obtained when each DLQ output score was predicted independently using a separate ML-CAT process. However further reduction in the number of questions can be obtained by predicting all seven DLQ output scores concurrently, using a single ML-CAT process. Reduction is expected due to correlations between DLQ questions.
Predicting all DLQ output scores concurrently
Instead of seven separate ML-CAT models, a single ML-CAT model was built to predict all seven DLQ output scores concurrently. The same T and M parameters were used as above. As previously, each regressor model predictor was trained by receiving as input a subset of k DLQ answers, DLQi1 … DLQik for each of the M samples (step 3) now, however, with the final seven DLQ output scores supplied for each sample. The regressor model computed the regression variables that minimize the prediction error 
Similar to the above, a leave one out 30 scheme was used to assess the adaptive algorithm. The accuracy of score prediction was calculated as the maximum absolute difference between the predicted and true scores of the subject over all seven output scores.
Figure 6 plots the average error of prediction as a function of the number of DLQ questions for M = 50, 250, 500. Points on the plot are for different values of accuracy thresholds (T = 0.001, 0.003, 0.005, 0.007, 0.01, 0.03, 0.05, 0.07, 0.1). The error of prediction decreases with an increasing number of questions, which in turn is controlled by the threshold value T. However, in comparison to the independent modeling, a higher number of questions were required to reach a level of accuracy when predicting all seven output scores concurrently (compare with Figure 2). This is to be expected as the adaptive algorithm now terminates only when all seven scores are below the threshold (equation (2)). Considering the parameters M = 250 and T = 0.01 as in the models above, an average absolute error of 0.076 (5% error in score value) was obtained with an average of 24.87 questions per subject, implying a 52.2% savings compared to the 25% savings when using independent models. The average error, however, was not uniform across the outcome scores as illustrated in Figure 7. Output scores A4 and B2 show less error and higher accuracy than other output scores. This may be because they require fewer DLQ questions than other output scores and reach higher accuracy before other output scores.

Predicting all seven DLQ scores concurrently. The average error of prediction (mean absolute difference) is plotted as a function of the number of DLQ questions for different accuracy thresholds T. Plots are for M = 50, 250, 500.

The average error on each output score when predicting all scores concurrently.
When applying the ML-CAT approach to DLQ score assessment, every subject is assessed using a different set of questions since questions are selected adaptively per subject. However, it was found that some questions consistently appear among the leading questions for most subjects. Figure 8 displays a histogram of the number of times each of the 52 DLQ questions appeared as one of the first three questions in a subject's adaptive testing sequence when predicting all outcome measures concurrently. Color coding of the bars are according to the DLQ output scores each question is associated with in the original questionnaire. Questions (13, 20, 31, 45, 51) (Table 4) are frequently selected early in the adaptive test sequence, compared to other DLQ questions. Most likely these questions, although originally associated with only one DLQ output score, are in fact informative to several output scores. They are then chosen by the model, early in the testing process, thus contributing to reducing the number of questions required to reach the set level of accuracy.
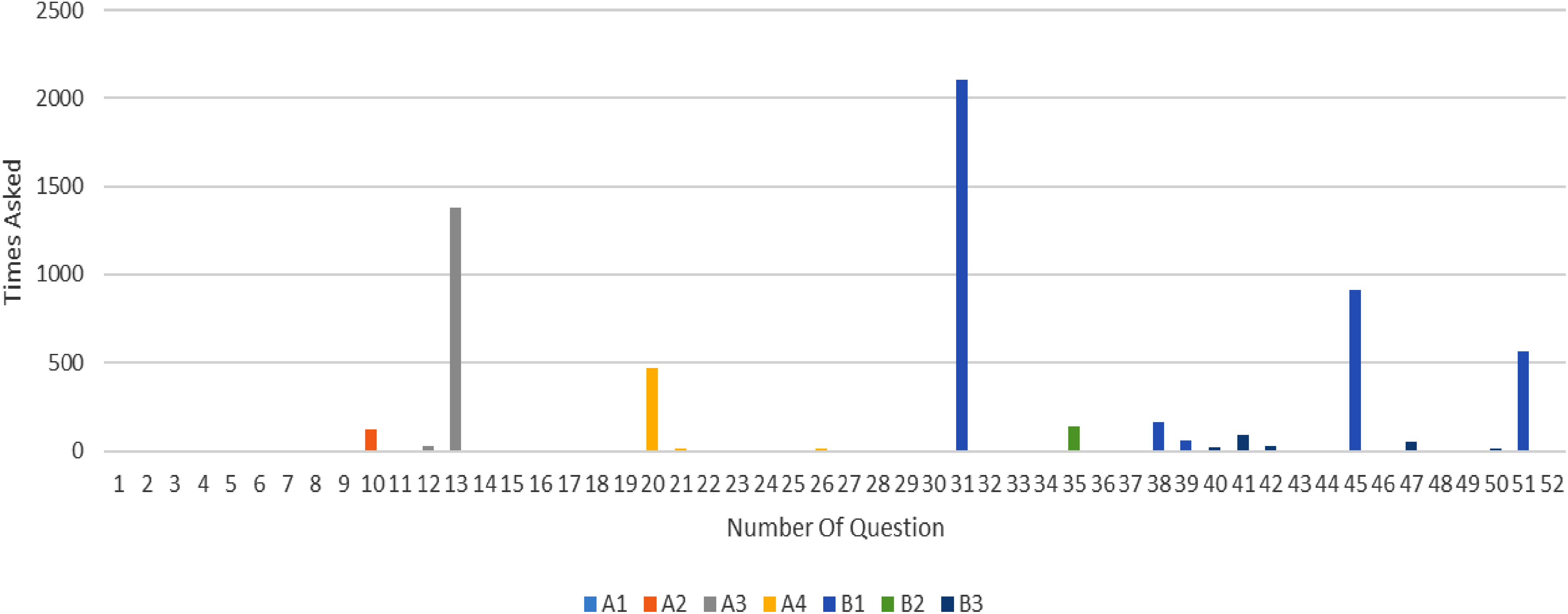
The number of times each DLQ question appeared as one of the first three questions when predicting all outcome measures concurrently. Color coding of the bars are according to the DLQ output scores each question is associated with in the original questionnaire (n = 2216).
A description of the frequently selected questions by ML-CAT.

ML-CAT: Machine Learning-based Computerized Adaptive Testing.
Discussion
In this study, the ML-CAT algorithm was used to predict DLQ scores in order to adapt and shorten the DLQ assessment. The approach was shown to reduce the number of questions without affecting accuracy, thus shortening administration time.
Items 13, 20, 31, 45, and 51 of the DLQ questionnaire, were most often selected by the ML-CAT early in the test sequence, implying that these items are more informative than other DLQ items. Two of the items are in DLQ part A (activities and participation): social activities with others (item 13) and organizing and managing finances (item 20). Prior FA analysis 15 revealed that item 13 is a component of the community/participation factor (A3), while item 20 is a component of the complex tasks factor (A4). Participation in social activities (item 13) involves the integration of executive functions with other complex cognitive processes that may be impacted by mild cognitive difficulties.31,32 For example, subtle cognitive deficits can result in misinterpretations of social signals, context, emotions, behaviors, or verbal statements.33,34 Organizing and managing finances (item 20) have been identified as being sensitive to mild cognitive impairment35,36 because it requires the integration of different executive function skills. Complex activities such as managing finances and social activities may be informative in understanding the subject's ability to participate in activities in general and thus is a good predictor of several of the DLQ output scores.
Three of the items are in DLQ part B (cognitive symptoms or impairments): inhibition of irrelevant information (item 31), planning (item 45) and initiation (item 51). Inhibition is the ability to control one's attention, behavior, thoughts and emotions by intentionally preventing the production of an automatic and impulsive response, delaying gratification or resisting distraction.37,38 Initiation involves generating ideas or plans and beginning activities without procrastination. 38 Planning refers to the capacity to recognize the need for action, define goals, conceptualize a sequence of steps, and choose from alternative methods. Prior factor analysis 15 revealed that all three items are components of the EF factor (B1). The most plausible reason that these three items predict the DLQ scores, is that EF components are considered to be the underlying mechanism for planning and coping with complex cognitive, functional, and social activities.39–41 Deficient executive function has been found to predict participation and functional outcomes across different health conditions (e.g. Stroke), 42 as well as in healthy populations. 38 EF represents a set of general-purpose control processes that regulate thoughts and behavior, 38 are correlated with skill and engagement in activities, 43 and as such, have a strong impact on all seven factors of the DLQ. Additionally, they are an important aspect when assessing functional-cognition in general, and therefore support the internal validity of the DLQ.
We note a bias in our originally collected data since most participants were healthy. However, the DLQ specifically assesses cognitive difficulties in performing IADL activities, at home, work and in the community as well as social participation. Therefore, unlike an IADL measure that assesses levels of independence, the DLQ would not be expected to show perfect scores in the healthy population (even if indicating high functioning), since there are everyday tasks that present cognitive challenges that may be perceived even by healthy individuals as more mentally challenging. Indeed, not all of our healthy population reported perfect scores (A1—65.3%, A2—60.1%, A3—62%, A4—46.6%, B1—51.8%, B2—57.1%, B3—64.4%). To ensure any remaining biases the ML algorithms were performed using stratified sampling and augmentation to further reduce any bias effects. Nevertheless, this could have possibly overestimated the accuracy of the short DLQ. We, suggest, as a future study, to test the ML-DLQ on a neurological population The current study, however, provides a proof-of-concept of an application that can choose the appropriate questions based on the subject's answers, thus, making it easier for clinicians to administer this questionnaire.
Conclusion
In, conclusion, adaptive DLQ testing was implemented using the ML-based ML-CAT. which maximizes test efficiency by selecting the most appropriate items for each individual, without affecting the accuracy of the test score. It was shown that this approach reduces the original questionnaire of 52 items, to less than 25 questions per person on average—a reduction of more than 50%, while maintaining very high accuracy (error rate 0.076 or average 5% error). This abbreviated test may thus facilitate the testing and data collection process, reduce assessment time, and subject fatigue, and thus increase the rate of response. In addition, it may be utilized for wider screening of individuals with cognitive disabilities and other health-related problems in the community.
Footnotes
Authors’ contributions
Panovka and Salman are principal student authors and contributed equally, Hel-Or advisor. Data collection: Adamit, Josman, and Rosenblum. Algorithm development, machine learning, data analysis and results: Panovka, Salman, and Hel-Or. Writing of manuscript: Panovka, Salman, and Hel-Or. Editing and review of manuscript: Adamit, Josman, and Toglia.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval and consent to participate
All studies were in accordance with the ethical standards of the University of Haifa institutional ethics committee and with Helsinki approval. All participants signed informed consent.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Guarantor
Hagit Hel-Or.
Informed Consent
No images of subjects included in the study. Permission was received from copyright holder to use the questionnaires in this study.
Notes
Appendix—The Daily Living Questionnaire (DLQ)
Name: Date:
Every day we perform many tasks that require mental effort, also known as cognition. During the course of our lives, we may experience difficulties with these mental efforts or cognitive tasks. The following is a list of activities that you may perform as part of your life.
Please CIRCLE the number which best describes how much mental or cognitive difficulty you generally have doing each of the following activities. If the activity does not apply to you (e.g. you have never done this activity) please circle N/A.