
Abstract
Background
Postpartum urinary incontinence is a fairly widespread health problem in today’s society among women who have given birth. Recent studies analysing the different variables that may be related to Postpartum urinary incontinence have brought to light some variables that may be related to Postpartum urinary incontinence in order to try to prevent it. However, no studies have been found that analyse some of the intrinsic and extrinsic variables of patients during pregnancy that could give rise to this pathology.
Objective
The objective of this study is to assess the most influential variables in Postpartum urinary incontinence by means of machine learning techniques, starting from a group of intrinsic variables, another group of extrinsic variables and a mixed group that combines both types.
Methods
Information was collected on 93 patients, pregnant women who gave birth. Experiments were conducted using different machine learning classification techniques combined with oversampling techniques to predict four variables: urinary incontinence, urinary incontinence frequency, urinary incontinence intensity and stress urinary incontinence.
Results
The results showed that the most accurate predictive models were those trained with extrinsic variables, obtaining accuracy values of 70% for urinary incontinence, 77% for urinary incontinence frequency, 71% for urinary incontinence intensity and 93% for stress urinary incontinence.
Conclusions
This research has shown that extrinsic variables are more important than intrinsic variables in predicting problems related to postpartum urinary incontinence. Therefore, although not conclusive, it opens a line of research that could confirm that the prevention of Postpartum urinary incontinence could be achieved by following healthy habits in pregnant women.
Keywords
Introduction and related work
The International Continence Society defines urinary incontinence (UI) as any involuntary loss of urine. 1 Three types of UI are distinguished: (i) stress, in which the leakage is caused by jumping, sneezing, coughing, etc., that is, by an increase in intra-abdominal pressure not compensated by the muscular activity of the perineum; (ii) urgency (or bladder hyperactivity), in which the leakage is caused by anarchic contractions of the detrusor muscle of the bladder that provoke an imperious and sudden desire to urinate; and (iii) mixed, when the patient presents a combined clinical picture of the two aforementioned ones. 2
Regardless of the type of UI, it is a major medical, social and economic problem, which is increasingly prevalent and greatly reduces the quality of life of women who suffer from it.3,4 Postpartum urinary incontinence is a very common health problem affecting a large number of women worldwide and it is one of the most common postpartum complications. 5 There are a large number of research studies and systematic reviews that provide different conclusions regarding the relationship between the different variables and the occurrence of this symptom of urinary incontinence.6,7
All of these studies yield results that may be useful from a traditional statistical point of view. They have shown that some of the recorded risk variables that influence this health problem are: vaginal delivery, advanced age at gestation, advanced maternal Body Mass Index (BMI), excess weight gain during pregnancy, diabetes, episiotomy, forceps delivery or gestational and prenatal UI. 5 However, as a result of the different artificial intelligence techniques, such as machine learning, among others, they are being increasingly used in this field and, thanks to them, results are being obtained that are of interest to the scientific community and that represent an advance and a novelty in the automation of diagnoses and in the prevention of possible health problems.8–11
For example, in the Kasasbeh et al. 12 study, different machine learning techniques (bagging, AdaBoost and logistic regression, among others) were used to identify or predict the factors that influence different postpartum complications.
In the study carried out by Venkatesh et al. 13 , different predictive machine learning models (extreme gradient boosting model, lasso regression model, logistic regression) are used to predict a woman’s risk of postpartum haemorrhage on admission at delivery.
Other researchers such as Betts et al. 10 succeeded in developing models for predicting neonatal outcomes using machine learning. Their model achieved a high discrimination for neonatal respiratory distress syndrome, in particular, reinforcing tree models gave the best results on the datasets they worked with.
Zhang et al. 8 focused on developing and validating a machine learning model with the aim of predicting the risk of postpartum depression in pregnant women. They used two datasets containing data from 15,197 women and 53,972 women, respectively. They trained five different machine learning models, random forest, decision tree, extreme gradient boosting (XGboost), regularized logistic regression, and multilayer perceptron (MLP).
Machine learning models were also used to identify the pregnant women’s risk of persistent post-traumatic stress following labor. 9 The authors of this study were able to create models that predicted post-traumatic labor stress by 75.8%. This was done using decision trees.
Despite studies applying artificial intelligence techniques to different postpartum health problems, no studies have been found that analyse the possible relationship between intrinsic and extrinsic variables with four variables: occurrence of UI and stress UI and frequency and intensity of UI.
This research therefore studies the application of different machine learning models, adjusting the hyperparameters and adding oversampling techniques, on six different sets of variables to predict the four outcome variables related to UI.
This paper is organized as follows: In section “Methodology,” the classic methods used to compare results and the architectures used in our proposal are explained. Experiments and results, as well as the dataset used, are detailed in section “Experiments and results.” Finally, we conclude in section “Discussion and conclusions.”
Methodology
Classic methods
In order to see which variables are more influential in postpartum urinary incontinence, different variations of the following machine learning techniques have been used: Gaussian Naive Bayes, Complement Naive Bayes, K-nearest neighbors (KNN), and decision trees. Experiments have also been carried out using oversampling techniques such as RandomOver and Smote. In this section, the vanilla version of the methods used will be introduced.
Gaussian Naive Bayes
The Gaussian Naive Bayes classifier is based on the Naive Bayes algorithm and the Naive Bayes algorithm is based on the Bayes Theorem used to calculate conditional probabilities.

In our case, the Gaussian Naive Bayes is used. This modification of the initial algorithm allows the work to be carried out with continuous data assuming that they follow a normal (Gaussian) distribution while still maintaining the advantages of the classic method. The Gaussian Naive Bayes conditional probability is calculated by terms of the following equation


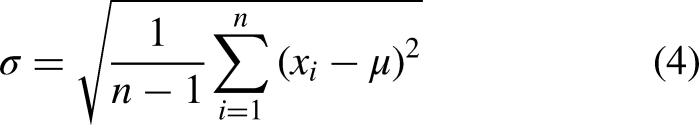
Complement Naive Bayes
This algorithm, derived from the previous ones, is usually used when the dataset with which we are working has unbalanced data, that is, many more elements belonging to some classes than to others.
To solve the problem of unbalanced classes, this algorithm differs from Naive Bayes, because it calculates the probability that an element has of belonging to all classes, instead of calculating the probability that the element has of belonging to a specific class.
The process is as follows: First, for each class, the probability that the data does not belong to it, is calculated. Then, the smallest value of those obtained is selected. And finally, this lowest probability is selected, which tells us that this class is not the one to which the element belongs. This way of calculating which class the data belongs to, is why the method is called Complement Naive Bayes.
K-nearest neighbors
KNN is a well-known method in which the class of the input data is calculated by taking into account the distances from that data to the rest of the elements of each class. More specifically, it is based on selecting the K closest neighbors to the input data. The input data will be classified within the class to which the largest number of the selected k neighbors belong.
The distance between the input data and the rest of the data in the dataset is usually calculated using the Euclidean distance, given by the following equation


Decision tree
The trees are made up of the root node that represents all the data and is the node that will be divided to give rise to the decision nodes. The leaf nodes are those in which we can no longer do more splits. The decision tree algorithm takes into account two important concepts in order to split the data: Entropy and Gini index. Entropy can be defined as the amount of information needed to describe an element and it is given by the following equation


Oversampling
Oversampling techniques are widely used on unbalanced data sets to improve methods and results.14,15Ways of balancing classes can be to delete data from the majority class, or duplicate data from the minority class. In this article we will use RandomOver and SMOTE as oversampling methods.
RandomOver: It is a very simple technique that randomly selects samples from the minority class with a replacement and duplicates them, until both sets are balanced.
SMOTE: Using this technique, 16 no new duplicate data is generated, but synthetic data similar to that of the minority class is created. In the data generation process, first, a sample is randomly selected to generate similar data. The k closest neighbors to that random sample are calculated, which, by default, are five neighbors. The new data are generated using a distance metric to compute the difference between the feature vector and the selected neighbors. That difference vector is multiplied by a random value of between 0 and 1 and this new vector is the new generated data.
Experiments and results
Dataset
The dataset was obtained after a non-randomized controlled trial among women selected for their interest in participating in the study through information provided at their primary care centre (at their first obstetric consultation with the midwife and/or gynaecologist or through information leaflets, handed out at the care centre). Recruitment was carried out in three primary care centres attached to the same hospital, where all participants gave birth. During the year prior to this study (2019), 397 babies were born in the municipality in which this study was carried out.
The following inclusion criteria were defined for participation in the study (a) women between 18 and 40 years of age; (b) term delivery (week 37 or more); (c) singleton gestation and cephalic presentation; (d) pregnancy without complications or added risks during gestation for the development of a normal vaginal delivery; (e) no participation in any other psychoprophylaxis intervention; (f) delivery at the Hospital Nuestra Señora de Sonsoles (Spain). The following exclusion criteria were defined simultaneously (a) any contraindication to vaginal delivery; (b) medical diagnosis of any urogynecological pathology prior to the gestational process; (c) any history of caesarean delivery and/or history of perineal injury (episiomoty and/or perineal tear of any grade); (d) failure to give informed consent to participate in the study or failure to attend all scheduled intervention and/or assessment sessions.
A dataset was generated by collecting information from 93 women who gave normal vaginal birth. Table 1 details all of the extrinsic variables, Table 2 details the intrinsic variables, and Table 3 sets out the result variables collected for each patient.
Description of the extrinsic variables collected from each patient and possible values.

Description of the intrinsic variables collected from each patient and possible values.

Description of the results variables collected from each patient and possible values.

Experimental setup
In the first stage, data pre-processing was carried out to clean the data and format them in a suitable format to work with. The variables were separated into intrinsic, extrinsic and outcome variables. Of the existing outcome variables, four were found to be unbalanced with the sample of 93 patients collected and were therefore discarded for the present study. Thus, we worked with the following outcome variables:
The group of intrinsic variables consists of 16 variables and the group of extrinsic variables consists of 15 variables. The variables belonging to each group are detailed in Table 1.
Pipelines were generated to convert the categorical variables using a LabelEncoder and the continuous variables were scaled. After this, a selection of best features was performed using SelectKBest and ExtraTrees. In this way, six groups of features were generated for each of the four outcome variables as follows:
Table 4 shows which variables formed part of the aforementioned groupings for each of the four variables resulting from this study.
Selection of the best extrinsic, intrinsic, and global variables for each of the four outcome variables using SelectKBest.

A k-fold cross-validation with 10 folds has been performed for all experiments to avoid randomisation. Each model has been evaluated using the most appropriate hyperparameter selection techniques according to the input data to which they were applied. In addition, RandomOver and SMOTE oversampling techniques were applied in some of them.
The experiments consisted of applying the following models to predict the four outcome variables (UI, FREQ_UI, INT_UI, and STRESS_UI). The nomenclature of the models used is detailed in Table 5.
Nomenclature and description of models trained for the experiments.

Results
Figures 1 and 2 show four graphs representing the results obtained by the eight aforementioned classification models, applied to each of the four outcome variables to be predicted using the six aforementioned groups of variables: presence of UI (Figure 1), frequency of UI (Figure 3), intensity of UI (Figure 4), and whether urinary incontinence was stress UI (Figure 2).

F1-score for the variable urinary incontinence (UI).

F1-score for the variable stress urinary incontinence (UI).

F1-score for the variable frequency of urinary incontinence (UI).

F1-score for the variable intensity of urinary incontinence (UI).
In addition, Table 6 shows the results of all of the experiments carried out.
F1-score of the seven trained models for each of the four outcome variables.

By grouping the F1-score metrics obtained for each group of variables in all the experiments carried out, the means and standard deviations shown in Table 7 were obtained. The group of variables with the best mean F1-score metric was the group with the best extrinsic variables. This group consisted of three extrinsic variables that most influenced the models according to a previously run feature selector.
Mean F1-score and standard desviation (SD) obtained according to the group of variables used in all experiments.
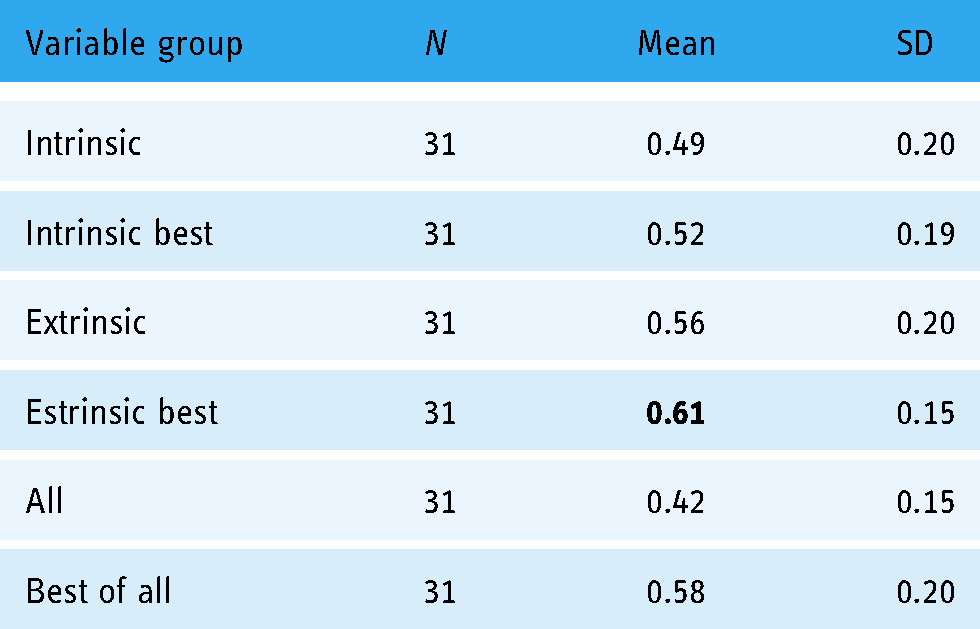
A two sample t-test was carried out to compare the F1-score in both the intrinsic and extrinsic variables.
There was a significant difference in F1-score between intrinsic (M = 0.49, SD = 0.20) and extrinsic (M = 0.56, SD = 0.20); t(30)
A two-sample t-test was carried out to compare the F1-score in both the intrinsic best and extrinsic best groups of variables.
There was a significant difference in the F1-score between the intrinsic best (M = 0.52, SD = 0.20) and the extrinsic best (M = 0.56, SD = 0.20); t(30)
Table 8 shows the data for the three models with the best results for each of the four predicted variables. From among these data, it is possible to see the type of model applied, the input variables used and the F1-score value obtained.
Three best models for each variable.

Ethical considerations
Approval for the study was obtained through the Ethics Committee of the University of Leon, Spain (code: ETICA-ULE-021-2018). All participants signed an informed consent form, in accordance with the Declaration of Helsinki (rev. 2013), and had the option to revoke their participation in the study at any time. Ethical regulations were respected as well as the Spanish Constitutional Law for the Protection of Data and for Biomedical Research in Human Participants.
Discussion and conclusions
Following the experiments detailed in the previous section, the results obtained are discussed, highlighting that extrinsic variables had the greatest influence on the four outcome variables analysed, that is, on the occurrence of postpartum urinary incontinence as well as on the frequency and intensity of UI and whether the source of this UI was due to biomechanical stress factors. Training the models with all intrinsic variables resulted in an average F1-score of 48.92% versus 55.65% using all extrinsic variables as input parameters of the models. Analysing the groups in which the three best intrinsic variables were selected, an average F1-score of 52.25% was obtained compared to a 61.35% success rate in the models using the three best extrinsic variables. The difference in both cases is statistically significant, so it is possible to determine that extrinsic variables have a greater influence on the occurrence, frequency and intensity of postpartum urinary incontinence.
These findings are consistent with previous research pointing to lifestyle-related and therefore modifiable risk factors such as obesity, 7 type of delivery, 17 or episiotomy. 18 These results, therefore, corroborate that postpartum urinary incontinence could be avoided if some lifestyle changes were made by the patients in their daily lives. It is especially relevant that the weight gained during pregnancy has shown significant results. Excessive weight gain during pregnancy increases the abdominal weight overload on the perineal musculature. This directly increases the pressure on these muscles. 19 But, in addition, the increased intra-abdominal pressure associated with overweight increases the mechanical load on this musculature indirectly. 20 The same physiological processes are probably responsible for the significant results found in relation to physical activity before and during pregnancy. Since the practice of physical activity would prevent excessive weight gain during pregnancy. 21 Furthermore, the inclusion in the model of all the activities practiced by the participating women supports the current recommendation on the importance of the intensity at which the exercise is carried out and not the particular discipline. 22 In parallel, the influence of the number of previous deliveries was also significant in the model generated. This phenomenon may be due to the fact that the accumulation of vaginal deliveries favors the degeneration of the muscular and fascial structures of support and continence.17,23 Conversely, counselling of the pregnant woman by different health professionals and attendance at childbirth preparation classes would favor the maintenance of self-care and behavioral patterns that are preventive and/or non-injurious to the perineum.24–26The group of intrinsic variables (or not under the full control of the pregnant woman) includes obstetric characteristics traditionally associated with increased risk of UI: gestational age at delivery and weight of the baby (two related variables), 5 the presence of perineal tear or episiotomy 27 and the duration of labour. 28 The only intrinsic variable included and currently agreed to have no influence on the development of postpartum UI is the use of analgesia during labour.29,30 In any case, our results do not question the possible structural impact of these events. Rather, they point to the lesser impact on the incidence of UI than the other group of variables analysed in this research. The main limitations of this study are the small sample size and that the dataset was obtained after a non-randomized controlled trial (level III of evidence). In addition, the amount of physical activity performed by the women participants was recorded through self-reported information rather than by objective quantitative methods such as pedometers or accelerometers. The authors recognize that these factors limit the generalizability of the results obtained. However, it opens up a line of research to carry out an intervention at a training level so that women implement a change of habits before or during pregnancy and confirm the findings found in our results.
Footnotes
Acknowledgements
We are grateful for the willingness of the participants in this study and the support provided by Lyu and Zaggy.
Contributorship
José Alberto Benítez-Andrades: Conceptualization, Data curation, Methodology, Software, Visualization, Validation, Writing-Original draft preparation. María-Teresa García-Ordás: Data curation, Writing-Original draft preparation. María Álvarez-González: Conceptualization, Supervision, Writing-Reviewing and Editing. Ana F. López Rodríguez: Conceptualization, Supervision, Writing-Reviewing and Editing. Raquel Leirós-Rodríguez: Data curation, Methodology, Software, Visualization, Validation, Writing-Reviewing and Editing.
Declaration of Conflicting Interests
The authors declare(s) that there is no conflict of interest.
Ethical approval
Approval for the study was obtained through the Ethics Committee of the University of Leon, Spain (code: ETICA-ULE-021-2018).
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Guarantor
José Alberto Benítez-Andrades.