
Abstract
This study investigates how the terminology used to describe algorithmic systems—specifically “algorithm” versus “chatbot”—influences user preferences, behavior, and the dynamics of human–artificial intelligence (AI) decision support. Additionally, it examines whether the objectivity of the task moderates this effect. Across two preregistered studies, participants consistently preferred the term “algorithm” over “chatbot” and were more likely to follow advice labeled as coming from an “algorithm” than from a “chatbot,” regardless of task objectivity. In the first study, 115 participants indicated their preference for either human advice or various AI system terms across two tasks: predicting stock prices (objective) and measuring romantic attraction (subjective). In the second study, 568 participants were randomly assigned to one of several AI system terms and tasks, assessing their preference and advice-taking, the latter measured by the Weight of Advice. The findings reveal that terminology significantly impacts user preference, behavior, and trust in algorithmically generated outputs, illustrating the broader implications for human cognitive and emotional responses in algorithmically supported decision-making contexts. These results underscore the importance of language in shaping human–AI interactions and provide practical guidance for organizations aiming to foster AI adoption through careful choice of terminology. They also extend research on algorithm aversion and human–AI interaction by offering behavioral evidence for critical data studies, showing that algorithmic labels influence trust and compliance beyond system performance.
Introduction
The rapid development of artificial intelligence (AI) is reshaping how humans interact with technology. Among the most significant advancements is the rise of generative AI systems, such as chatbots and large language models like ChatGPT. These systems are increasingly applied across various domains, including healthcare, customer service, and creative industries (Bigman and Gray, 2018; Jovanovic et al., 2020; Rapp et al., 2021). This growing reliance on AI has generated both excitement and concern, particularly regarding its influence on human behavior, decision-making, and cognitive processes.
A critical aspect of this transformation is the evolving nature of human–AI interaction. Interactions with AI systems are now a significant research focus due to their potential to enhance productivity, creativity, and efficiency. However, the success of AI implementation depends significantly on user adoption, which is often hindered by algorithm aversion—the tendency to distrust or avoid using algorithms after seeing them err, even when they outperform human judgment (Dietvorst et al., 2015). Understanding the factors that drive aversion or foster appreciation of AI systems is essential to promoting their effective use across diverse domains.
The terminology used to describe AI systems plays a pivotal role in shaping user perceptions and behaviors. Research has shown that terms such as “algorithm,” “artificial intelligence,” and “chatbot” elicit distinct user reactions, which significantly impact trust and engagement (Langer and Landers, 2021). For example, “algorithm” often conveys precision and objectivity, making it more suitable for tasks perceived as technical or data-driven, such as financial forecasting (Jussupow et al., 2020). Conversely, “chatbot” implies a conversational, human-like interaction but may undermine trust when applied to critical or technical tasks. These terminological distinctions are more than semantic; they influence user interactions, potentially affecting comfort, trust, and reliance (Candrian and Scherer, 2024).
If terminology influences user interactions with AI systems, it could also shape research outcomes, emphasizing the need for careful terminological selection in experimental design. Existing studies shed light on the role of terminology in algorithm aversion and suggest its potential to influence experimental findings. Moreover, the variety of terms employed in prior research (Langer and Landers, 2021) underscores the critical impact that terminology may have on future studies and their results.
Labels such as “chatbot,” “algorithm,” or “AI” may evoke different expectations, mental models, and trust levels, even when system performance is identical (Candrian and Scherer, 2024; Chacon and Larrain, 2026; Langer et al., 2022). Our study extends this research by examining how subtle intra-algorithmic labels, not just human versus machine comparisons, influence user preference and behavior.
Therefore, our first research question is: Does terminology influence the use or preference for AI systems? To address this, we study how the terminology used to describe AI systems affects user preferences and behaviors in human–AI decision support contexts, where AI is positioned as an advisory tool rather than a collaborative partner. Specifically, we focus on the terms “algorithm” and “chatbot,” which are prominently featured in discussions surrounding algorithm aversion and generative AI technologies. Both terms, “algorithm” and “chatbot,” may be used interchangeably because a chatbot is typically powered by an underlying algorithm. As a result, practitioners may use either term when discussing the technology. For example, in a customer service context, someone might say: “We developed an algorithm/chatbot to answer FAQs.”
Additionally, terminology's ability to evoke different characteristics and levels of trust (Langer et al., 2022) invites further inquiry into its interaction with other factors associated with algorithm aversion. Among these factors, the nature of the task—whether objective or subjective—may best reflect the perceived characteristics of a system, which leads to a second research question: How does terminology interact with the nature of the task to influence user preferences and behavior? The study seeks to answer the question by examining whether the task's objectivity moderates the relationship between terminology and user trust or engagement.
This research contributes to a deeper understanding of human–AI interactions by investigating these dynamics, shedding light on cognitive and behavioral shifts as humans increasingly use AI technologies. Ultimately, it aims to inform the design of AI systems that better align with user expectations and foster effective human–AI partnerships. Along these lines, Shin (2024) provides a comprehensive framework for how human–algorithm interaction—shaped by system design and perceived transparency—can influence user trust and susceptibility to misinformation. This reinforces the relevance of examining not only how users behave in response to AI systems but also how they interpret these systems within broader sociotechnical contexts.
Although our research draws from cognitive and social psychology—particularly work on algorithm aversion and advice-taking—it directly contributes to broader debates in critical data/algorithm studies (CDS) and digital society (Dalton et al., 2016; Kitchin, 2014). We treat terminology itself as part of the sociotechnical infrastructure through which algorithmic systems acquire legitimacy and shape user conduct. The CDS shows that algorithms do cultural and organizational work by configuring visibility, authority, and accountability (Boyd and Crawford, 2012; Gillespie, 2014; Nick, 2017). Our work demonstrates that merely calling the same system an “algorithm,” rather than a “chatbot,” measurably increases preference and compliance (advice-taking), identifying a discursive channel of algorithmic power that operates independently of performance. In CDS terms, labels are not neutral descriptors; they perform governance by calibrating trust, consent, and reliance in everyday encounters with algorithmically mediated systems.
Across two experimental studies, we examine how AI system terminology affects user preference and advice-taking, focusing on the terms “algorithm” and “chatbot.” We further test whether task objectivity moderates these effects. We situate this work within the context of prior research on algorithm aversion, chatbot design, and the psychological effects of labeling AI systems.
Related literature
Algorithm aversion
An algorithm can be defined as a set of rules to be followed in order to solve a problem (Lee, 2018), whereas algorithm aversion refers to the reluctance to use algorithms despite their superior performance compared to human counterparts, especially after users observe algorithmic errors (Dietvorst et al., 2015). This aversion is driven by various factors of special interest to this research, such as user and algorithm characteristics (Mahmud et al., 2022).
The characteristics of algorithms themselves also significantly influence user acceptance, highlighting the learning ability of algorithms moderate aversion (Berger et al., 2021; Chacon, Kausel et al., 2025). Transparency, mode of delivery, and accuracy are pivotal in diminishing the aversion felt by users (Mahmud et al., 2022). Another characteristic that may influence algorithm aversion is the level of autonomy in decision-making. Algorithms that operate autonomously and make decisions without human input (performative algorithms) are more likely to cause user aversion, especially when they fail or perform poorly (Jussupow et al., 2022). In contrast, advisory algorithms, which provide recommendations but leave the final decision to the user, tend to generate less aversion due to retained human control. Therefore, the balance between the algorithm's control and its effectiveness is crucial in mitigating user aversion (Jussupow et al., 2020).
While prior work on algorithm aversion has focused primarily on the contrast between human and algorithmic decision-makers, our study explores a different yet related dimension: the framing of algorithmic systems through terminology. We argue that even when users are interacting with AI rather than human agents, the label used to describe the AI (e.g., “algorithm” vs. “chatbot”) can activate different user expectations, levels of trust, and behavioral responses. This is consistent with Shin's (2024) broader argument that human–algorithm interactions are deeply shaped by how users construe AI intentions and interpret its communicative framing, particularly in situations of uncertainty and opacity. In this way, we extend the algorithm aversion literature beyond source comparison to investigate how intra-algorithmic terminology may influence the acceptance and use of algorithms.
Modern chatbots
Chatbots are intelligent conversational agents designed to simulate human dialogue, leveraging advancements in AI and natural language processing (NLP) (Bigman and Gray, 2018). Chatbots have been widely adopted across various industries, including customer service, healthcare, and e-commerce (Bigman and Gray, 2018; Go and Sundar, 2019). The integration of NLP enables chatbots to understand user intent and deliver relevant information, making them valuable tools in sectors like customer service (Luo et al., 2022). Additionally, many chatbots utilize anthropomorphic cues—such as human-like language, empathy, and social presence—which can enhance user engagement and compliance by creating a more human-like interaction (Bigman and Gray, 2018; Feine et al., 2019; Go and Sundar, 2019).
The CDS scholarship argues that classifications, interfaces, and labels are constitutive elements of algorithmic systems, not just wrappers (Bowker and Star, 2000; Pasquale, 2015). Labels mediate users’ “algorithmic imaginaries” (Gillespie, 2014; Nick, 2017) and the conditions under which systems become credible or contestable (Ananny and Crawford, 2018). Our focus on intra-algorithmic labels extends this line by showing that naming alone reconfigures perceived authority and appropriate deference, even when functionality and advice are held constant.
Terminology influence over algorithm preference and use
Terminology research has focused on how it affects user perceptions, algorithm characteristics, and tolerance for errors. However, to the best of our knowledge, little attention has been paid to the influence of terminology on the actual use and preference for algorithms. Existing studies suggest that terminology influences perceptions of system properties and valuations of automated decision-making (ADM) systems across different application contexts (Langer et al., 2022). Furthermore, comparisons between terms such as “AI” and “algorithm” reveal that people react more favorably to “AI” errors than to “algorithm” errors, suggesting that terminology can mitigate or exacerbate aversion (Candrian and Scherer, 2024). Although a broad range of terms has been examined in prior literature, the present study focuses specifically on the contrast between “algorithm” and “chatbot.” The other labels included in our design serve primarily as contextual benchmarks, but our central interest lies in these two widely used terms.
While most prior research on terminology has focused on perceived trust, competence, or system transparency, there is growing evidence that labels can directly influence user preferences. For example, Langer et al. (2022) suggested that users evaluate automated systems differently based solely on terminology. Similarly, Candrian and Scherer (2024) found that labels influence both interpretations of system failure and willingness to continue using the system. Teoh (2020) demonstrated that the names assigned to driving features (e.g., “Autopilot” vs. “Driving Assistant”) influenced perceived capabilities and driver behavior. Smale et al. (2024) reported that consumers preferred products labeled “smart” over “AI-powered,” despite functional equivalence. Additionally, Park et al. (2024) found that human-like labels increased chatbot preference and engagement.
These findings suggest that terminology activates mental models, expectations, and affective responses that shape user preferences, even when functionality remains constant. This is consistent with the AI debiasing literature, which emphasizes the role of framing and labeling in shaping trust and reliance (Shin, 2025). Terminology may also influence perceived usefulness and ease of use, key components of the Technology Acceptance Model (Davis, 1989), by framing systems as either competent tools or simplistic conversational agents. Based on this literature, we predict users will prefer the term “algorithm” over “chatbot” due to associations with objectivity, competence, and technical credibility.
Beyond psychological outcomes, terminology functions as a meaning-making device. From a sociolinguistic perspective, labels are not neutral descriptors; they act as signifiers that shape interpretation through cultural and contextual associations (Gee, 2014; Halliday, 1978). Communication theory likewise highlights how framing devices guide expectations, authority, and meaning (Entman, 1993; Tannen, 1993). Thus, terms such as “algorithm” and “chatbot” frame the interaction itself, invoking distinct scripts and assumptions.
Importantly, terminology also influences behavior. Prior studies have shown that framing affects advice-taking and compliance with system recommendations (Berger et al., 2021; Candrian and Scherer, 2024). For example, people were more likely to follow advice labeled as algorithmic than human (Logg et al., 2019), and less likely to engage with services labeled as chatbots, unless a failure occurred, in which case the label softened the negative response (Mozafari et al., 2022). Similarly, Park et al. (2024) found similar framing effects on compliance in mental health settings.
These patterns are consistent with the literature on framing effects (Keysar et al., 2012; Kim et al., 2022; Tversky and Kahneman, 1981), which posits that the presentation of information affects interpretation and response. Terminology acts as such a frame, shaping mental models of system reliability, competence, and human-likeness (Gentner and Stevens, 2014; Johnson-Laird, 1983). From a social cognition standpoint, users rely on cues such as labels to form rapid judgments about AI systems (Fiske and Taylor, 1991). Decades of cognitive psychology research have documented that exposure to a term can activate associated schemas and expectations, thereby shaping interpretation and behavior (Neely, 1991; Huete-Perez et al., 2025). Thus, exposure to terms such as ‘algorithm’ may activate schemas associated with analytical rigor, which not only shape interpretation but also influence behavior through rapid heuristic judgments—an important insight for understanding framing effects in human–AI decision-making.
In this sense, “algorithm” and “chatbot” act not only as frames but also as semantic primes that cue distinct mental pathways—analytic competence in the former, conversational in the latter. A term such as “chatbot” may prime associations with scripted or limited tools, while “algorithm” evokes technical accuracy. These cognitive and affective heuristics, in turn, influence both attitudes and behavior toward the system. More broadly, different terms evoke different levels of trust and acceptance. For instance, “AI” may suggest a more anthropomorphized and competent system compared to “algorithm,” which might be perceived as more familiar (Langer and Landers, 2021). These perceptions are crucial in determining user trust and reliance on algorithmic systems, particularly in contexts where the system's perceived capabilities are critical. Moreover, it has been proposed that individuals might feel uneasy about terms such as “algorithm” or “artificial intelligence.” Nonetheless, they often appreciate the results of these systems, provided they are unaware of their algorithmic origins (Mariadassou et al., 2024). This suggests that aversion may stem from the terminology itself rather than the quality or functionality of the system's output, reinforcing the importance of how these systems are framed and communicated to users.
In this context, the term “chatbot” has gained prominence due to its widespread application across various domains (Rapp et al., 2021). Despite this prevalence, to the best of our knowledge, no previous research has examined how the term “chatbot” influences user perceptions compared to the term “algorithm.” Chatbots, often powered by probabilistic models based on NLP, may present challenges in terms of explainability and transparency because their complex and adaptive behaviors are less predictable, despite recent advancements in their capacity to engage with humans. In contrast, systems referred to as “algorithms” are typically perceived as deterministic and more transparent, potentially making them more understandable and trustworthy to users. This contrast raises the question of how “chatbots” are evaluated in comparison to “algorithms,” and whether one is preferred or more frequently used by individuals. Investigating these perceptions is crucial for designing technologies that users are willing to adopt and trust.
Building on the questions outlined above, this study employs a multistep analysis that focuses on the impact of terminology on user preference and usage. Specifically, we investigate whether “algorithm” or “chatbot” is more favorably received and whether this influences the likelihood of users following advice provided by these systems. Accordingly, we propose the following hypothesis: Hypothesis 1: Terminology influences both use and preference, reflecting intra-algorithm framing effects, such that (a) individuals prefer the term “algorithm” over “chatbot,” and (b) individuals are more likely to follow advice when it is referred to by the term “algorithm” rather than “chatbot.”
The moderating effects of task over algorithm use
Task characteristics are a crucial and extensively researched factor influencing algorithm aversion (Castelo et al., 2019). A task's complexity, importance, and context can significantly affect user aversion for algorithms (Mahmud et al., 2022). Algorithm aversion is present in at least 75% of tasks, as shown in a study by Kaufmann et al. (2023). This aversion is observed across a range of domains, such as finance and healthcare, and is particularly influenced by task type, user expertise, and feedback on algorithm performance. Furthermore, users rely more on algorithms for objective and quantifiable tasks, whereas tasks requiring moral judgments elicit aversion due to the algorithms’ perceived lack of human-like qualities (Bigman and Gray, 2018). Additionally, people's perceptions of fairness, trust, and emotional responses vary depending on whether decisions are made by humans or algorithms and the nature of the task (Lee, 2018; Starke et al., 2022).
Rational decision-making is typically preferred for tasks with clear, evaluable outcomes. In contrast, intuitive decision-making is favored for subjective and simpler tasks (Inbar et al., 2010). Trust in algorithms decreases for subjective tasks but increases when these tasks are framed as objective (Castelo et al., 2019). Moreover, the alignment between the agent and the task type influences user preferences, with human agents being favored for social tasks and nonhuman agents for analytical tasks (Hertz and Wiese, 2019). This is further supported when considering that algorithm aversion is more prevalent in subjective domains (Logg, 2017).
We examine the potential differences that terminology might generate across two tasks. We consider that the term “chatbot” may follow recent trends of anthropomorphizing technology and may elicit more human-like characteristics, as its interface is designed to assist and interact with users in a more personal and engaging manner, thus potentially performing better than an “algorithm” in subjective tasks. Therefore, we propose: Hypothesis 2: Terminology has differential effects depending on the task's objectivity, (a) the relationship between the chosen terminology and preference for an AI system will be moderated by task objectivity, with “algorithms” being preferred for tasks with high objectivity than “chatbots” and less preferred for tasks with lower objectivity, and (b) the relationship between the term and use will be moderated by task objectivity, with “algorithms” being used more for tasks with high objectivity than “chatbots” and less used for tasks with lower objectivity.
These hypotheses aim to investigate the impact of terminology on algorithm use and preference, particularly in tasks with varying degrees of objectivity.
Overview of studies
The primary objective of this research is to understand how terminology influences the preference for and use of algorithms and chatbots, compared to other terms, in tasks with varying perceived objectivity. The research was conducted through two experiments, and although our study's users do not interact directly with the AI, the setting reflects a common and realistic decision-support scenario where individuals evaluate or follow AI-generated advice.
The research will focus on the terms “algorithm” and “chatbot,” while also incorporating other commonly used terms from the literature, such as “artificial intelligence,” “automated system,” “expert system,” “robot,” and “statistical model” (Langer et al., 2022; Langer and Landers, 2021). The terms were selected to ensure both contextual relevance and alignment with previous research. Terms such as “automated system,” “robot,” and “statistical model” were drawn from Langer et al. (2022) while others, including “algorithm,” “chatbot,” “artificial intelligence,” and “expert system,” were chosen for their prevalent use in both research and real-world applications. Although several terms were included in our design, our empirical focus centered on “algorithm” versus “chatbot” for both theoretical and empirical reasons: the former suggests precision and formality, the latter informality and limited capability. This distinction, as supported by Langer and Landers (2021), enabled us to examine the most meaningful contrast while maintaining analytical clarity.
Two tasks were selected to represent subjective and objective scenarios. Specifically, the tasks presented to all participants involved measuring the romantic attraction a given person would feel for another (Logg et al., 2019) and predicting a future stock price (Chacon, Kausel et al., 2025; Önkal et al., 2009). Based on a study from Castelo et al. (2019), selecting a possible romantic partner is a subjective task, and predicting stocks is an objective task. This is further supported by Logg et al. (2019), who used a romantic task to represent a subjective decision-making context. The distinction between the two tasks follows Prahl and Van Swol's (2021) demonstrability continuum: Tasks such as stock predictions are considered objective, with verifiable answers, whereas romantic attraction tasks involve subjective judgment and do not have a single correct outcome. Schaap et al. (2024) reinforce this by showing that people perceive finance as more objective and better suited for algorithms than dating-related decisions.
All supplementary materials are stored on an OSF project and are available at: https://osf.io/gwv6n. The OSF project includes surveys, code, data, sample size calculation using G*Power, and preregistration for each study.
Study 1
Sample and procedure
The first study involved 115 undergraduate students from a midsized university. Seventy percent of participants identified as male, with an average age of 24 (SD = 4). Participation was voluntary, and students were incentivized to complete the survey with course credits, regardless of their responses. The study was conducted online. Two attention checks were included: the first attention check allowed participants to continue with the experiment, but only after a warning was given. Participants who failed either of these checks were excluded, resulting in a final sample of 113 participants.
This study utilized a two-factor within-subjects design, with one factor being the term used to name the system and the other being the task. Participants were exposed to seven different terms across two distinct tasks with varying levels of objectivity. They were asked to indicate their preference for either a human performing the task or the corresponding term (e.g., “algorithm,” “chatbot”), using a scale from 1 to 7, where 1 indicated a complete preference for a human, and 7 indicated a complete preference for the term.
This experiment drew partial inspiration from the third experiment conducted by Longoni et al. (2019). The similarity lies in the structure of the questions posed to participants. Longoni and colleagues asked participants to express their preference between a human provider and an AI provider. In contrast, our experiment expanded this approach by asking participants to state their preference between a human provider and several specific terms. The order of the terms shown was randomized to avoid potential biases. Participants were required to express their preference on a scale from 1 to 7 for each term in various scenarios, with 1 indicating a strong preference for the human provider and 7 indicating a strong preference for the term.
Participants were presented with two tasks to assess their decision-making and preferences in different contexts. The first task involved a participant measuring the romantic attraction a given person might feel for another person, a subjective decision-making task, while the second task required predicting a future stock price, which represents a more objective task. Attention checks and demographic questions were included to ensure data quality and gather participant characteristics.
Variables
Several variables were used to test the different hypotheses. The first variable is preference, the dependent variable of this experiment. It is a Likert scale variable ranging from 1 to 7, where 1 indicates a complete preference for a human performing the task, and 7 indicates a complete preference for the term (e.g., “algorithm,” “chatbot,” etc.). This scale was based on a study from Longoni et al. (2019).
The second variable is term, a categorical independent variable that indicates the terminology used to describe the system that provides the advice. It has seven possible values, not only focusing on “algorithm” and “chatbot” but also including other common terms (i.e., “artificial intelligence,” “automated system,” “expert system,” “robot,” “statistical model”) to make a more comprehensive study of differences brought by terminology.
The third variable is task, an independent binary variable representing one of two possible tasks. The tasks presented to all participants involved measuring the romantic attraction a given person would feel for another and predicting a future stock price. The choice of tasks intentionally highlighted the differing levels of objectivity and examined how term preferences might shift across these contexts. Attention checks and demographic questions were included to ensure data quality and to gather participant characteristics.
Analytical strategy
In this study, we tested different hypotheses through several procedures. First, a mixed-effects regression was performed with preference as the dependent variable and six dummy encoded variables representing term as the main independent variables. This analysis allows us to test Hypothesis 1.a. Afterward, we conducted a mixed-effects regression with preference as the dependent variable and task, six dummy encoded variables representing term, and their interaction as the main independent variables to test Hypothesis 2.a. Finally, a mixed-effects regression was performed by splitting the data between tasks to more directly visualize possible differences in preference for terms within each task. All tests used “algorithm” as the term reference level and financial task as the task reference level. This study only measured preference, not use; therefore, no hypotheses or conclusions about usage were tested.
Results and discussion
The results of the three analyses are presented in Table 1. In model (1), we report the results of the first mixed-effects regression, where preference is the dependent variable and six dummy variables representing term are the independent variables. Model (2) shows the second mixed-effects regression, which includes preference as the dependent variable and both task and six dummy variables representing term as independent variables; interaction results are displayed in the lower rows of the table. The results of model (2) can be visualized in Figure 1, which displays the distribution of the predicted preference over both tasks. Lastly, models (3) and (4) present the regressions performed separately for each task, with model (3) showing the results for the financial task and model (4) for the romantic task.

Dot plots of predicted preference distribution for the financial task (left panel) and the romantic task (right panel).
Mixed-effects regression results on the impact of terms and task on preference in Study 1.
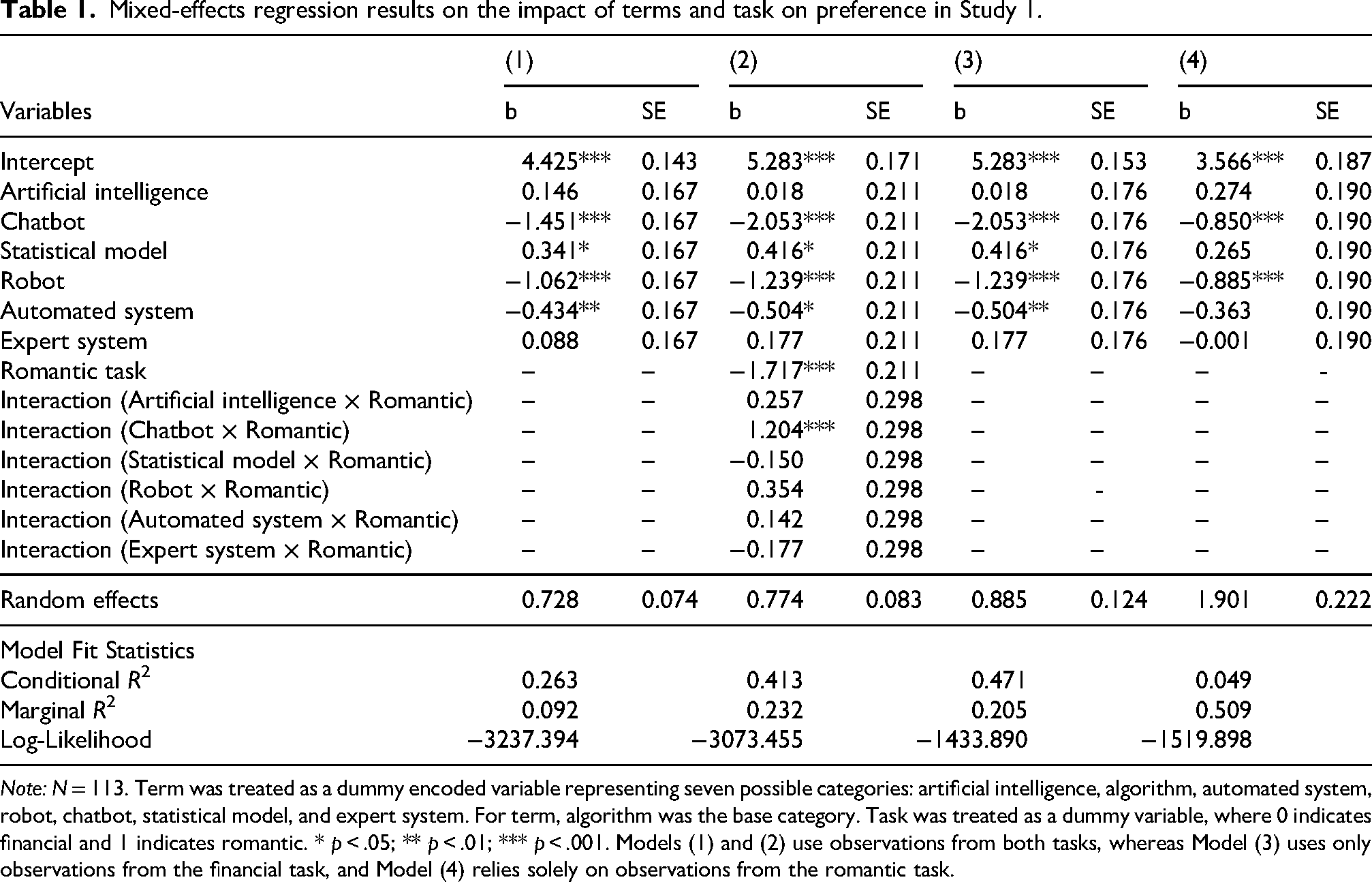
Note: N = 113. Term was treated as a dummy encoded variable representing seven possible categories: artificial intelligence, algorithm, automated system, robot, chatbot, statistical model, and expert system. For term, algorithm was the base category. Task was treated as a dummy variable, where 0 indicates financial and 1 indicates romantic. * p < .05; ** p < .01; *** p < .001. Models (1) and (2) use observations from both tasks, whereas Model (3) uses only observations from the financial task, and Model (4) relies solely on observations from the romantic task.
Given the conceptual contrast and consistent response divergence between “algorithm” and “chatbot,” our analysis focused on these two terms to test our primary hypotheses. The results for model (1) show that “algorithm” had a significantly higher preference over “chatbot” (b = −1.451, p < .001), strongly supporting Hypothesis 1.a. Additionally, “algorithm” was significantly preferred over “automated system” (b = −0.434, p = .009) and “robot” (b = −1.062, p < .001). Conversely, “statistical model” was preferred over “algorithm” (b = 0.341, p = .041).
The results for model (2) show a significant interaction between “chatbot” and the “romantic” task (b = 1.204, p < .001), showing that the difference in preference for “chatbot” versus “algorithm” varies by task. However, “algorithm” was preferred over “chatbot” in both the financial task (b = −2.053, p < .001) and the romantic task (b = −0.850, p < .001). These results do not support Hypothesis 2.a.
Models (3) and (4) provide further insights into the preference for “algorithm” compared to other terms, besides “chatbot,” within each task. In model (3), “statistical model” was preferred over “algorithm” (b = 0.416, p = .018), while “algorithm” was preferred over “automated system” (b = −0.504, p = .004) and “robot” (b = −1.239, p < .001). In model (4), “algorithm” was also preferred more than “robot” (b = −0.885, p < .001).
Throughout Study 1, participants showed a consistent preference for “algorithm” over “chatbot.” This supports Hypothesis 1.a and provides support for determining that terms can have a significant impact on preference. Finally, the results of all models are robust after controlling for age and gender. To further study preference and actual use, Study 2 was conducted with a larger sample.
Study 2
Sample and procedure
The second study recruited 568 participants from Prolific, focusing on native English speakers with high prior performance ratings on the platform. The participants had an average age of 36.3 years (SD = 13) and a diverse range of occupations. The experiment was conducted online, and participants were rewarded with a monetary payment upon completion. Two attention checks were included: the first attention check allowed participants to continue with the experiment, but only after a warning was given. Participants who failed both attention checks were excluded, which resulted in a final number of 553 participants. Furthermore, a measure of tech affinity was added (Langer et al., 2022). This allowed us to control the results based on familiarity with technology (Tully et al., 2025).
Participants were randomly assigned to one of five terms and one of two tasks. While Study 1 included seven terms, Study 2 used a reduced set of five to improve clarity, power, and reduce cognitive load. “Automated system” and “expert system” were excluded based on a combination of factors such as the conceptual distinctiveness of each term, their limited variation in user preferences in Study 1, and the need to reduce cognitive and analytical complexity in the between-subjects design of Study 2. In contrast, we retain the term “artificial intelligence” due to its high salience in public discourse and relevance in the human–machine interaction literature. This streamlined set of labels also sharpened our focus on the core comparison between “algorithm” and “chatbot,” which remains central to our theoretical and empirical contribution.
The tasks remained identical to those in the earlier experiment. Participants were asked to answer two questions. First, they had to indicate their preference for a human or the assigned terms to perform the task. This question was similar to that in Study 1. However, only the assigned term was used to ask for participant preference. Considering this, the question posed by Longoni et al. (2019) was similar.
As a second question, they were required to make a prediction related to their assigned task. After making an initial prediction, participants received advice from the assigned term and submitted their final prediction. The recommendation was the same among all participants of the same task, only the term was different. This experiment was similar to that of Chacon, Kausel et al. (2025). This framework allowed us to compare differences elicited solely by changes in terms and to compare differences between tasks. Both questions were asked twice to all participants, and analyses were performed using the average result between them.
This study employed a two-factor between-subjects design with task and term as independent variables. Demographic variables were also collected, and two attention checks were included to ensure response quality. Responses were excluded if participants failed both attention checks.
Variables
Several variables were used to test the different hypotheses. The first variable is preference. This is the first dependent variable and is a Likert scale variable ranging from 1 to 7, where 1 indicates a complete preference for a human performing the task, and 7 indicates a complete preference for the term. This variable was asked twice, and the average of both responses was used for analysis.
The second variable is Weight of Advice (WOA). The use of advice was assessed using this WOA measure, which has been utilized in previous studies (Chacon, Reyes et al., 2025; Logg et al., 2019). The WOA works as a proxy for behavioral inclination rather than actual sustained usage or reliance, but is sufficient to provide evidence on the difference in use caused by terminology.
1
This variable corresponds to a dependent variable that measures the extent to which a person takes advice from the corresponding term:
The initial estimate corresponds to the participant's initial prediction. Advice is the value recommended by the term. The revised estimate is the participant's final value. When advice and the initial estimate were equal, the value was discarded. Values closer to 1 represent higher advice-taking. Conversely, values closer to 0 represent less advice-taking. WOA values higher than 1 or lower than 0 were discarded to perform the analysis, which resulted in 438 observations for WOA.
The correlation between the two dependent variables, preference and WOA, was modest but significant, with a Pearson correlation of 0.305 and a Spearman correlation of 0.281 (both p < .001), indicating a consistent but partial relationship between stated preference and behavioral reliance on the assigned term's recommendation.
The third variable is term, an independent categorical variable with five values: “artificial intelligence,” “algorithm,” “robot,” “chatbot,” and “statistical model.” Each participant was randomly assigned one of these terms.
The fourth variable is task, an independent binary variable representing one of two possible tasks: romantic or financial. Each participant was randomly assigned to one of these tasks. The study also included demographic data, such as age and gender.
Analytical strategy
This study followed a similar approach to Study 1 but employed a two-factor between-subjects design, utilizing ordinary least squares (OLS) regression instead of a mixed-effects regression. The first analysis used two OLS regressions to test hypotheses 1.a and 1.b. The first regression used preference as the dependent variable and term as the independent variable, and the second regression had WOA as the dependent variable and four dummy variables representing term as the independent variables.
The second analysis involves interaction effects. Two OLS regressions were conducted to check for potential interactions. The first was between preference as a dependent variable, and four dummy variables representing term and task as the independent variables. The second used WOA as the dependent variable and four dummy variables representing term and task as independent variables. These analyses tested hypotheses 2.a and 2.b.
The third and final analysis was a task-specific analysis. Separate OLS regressions were performed for each task to visualize differences between terms within each task. All tests used “algorithm” as the term reference level and financial task as the task reference level.
Results and discussion
The results for both preference and WOA follow the same structure and are each presented in separate tables. Table 2 presents the results for preference, and Table 3 presents the results for WOA; both tables share the same structure. In Table 2, model (1) reports the results of the first OLS regression, where preference is the dependent variable and four dummy variables representing term are the independent variables. Model (2) shows the second OLS regression, which includes preference as the dependent variable and both task and four dummy variables representing term as independent variables; interaction results are displayed in the lower rows of the table. Lastly, the regressions performed separately by task are presented in models (3) and (4). Model (3) shows the regression with preference as the dependent variable and four dummy variables representing term as the independent variables, considering only values for the financial task. Model (4) presents the same regression but only for the romantic task. This structure is repeated in Table 3, but with WOA as the dependent variable. The distribution of predicted preference and WOA values across different tasks for all terms is visualized in Figure 2.
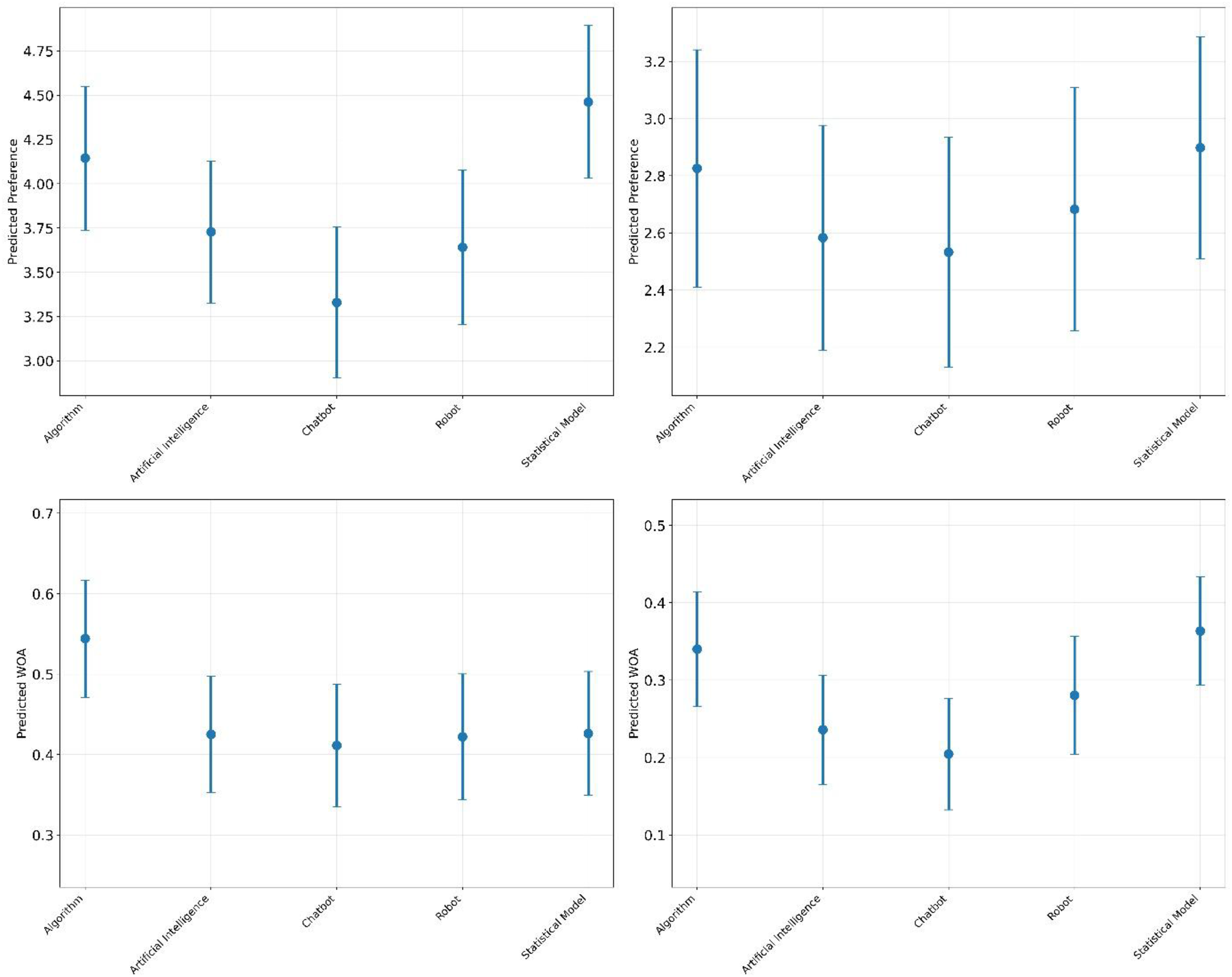
Distribution of predicted preference (upper row) and WOA (lower row) for the financial task (left column) and romantic task (right column) across different terms in study 2.
Regression results on the impact of terms and task on preference in Study 2.

Note: N = 553. Term was treated as a dummy encoded variable representing five possible categories: artificial intelligence, algorithm, robot, chatbot, and statistical model. For term, algorithm was the base category. Task was treated as a dummy variable, where 0 indicates financial and 1 indicates romantic. * p < .05; ** p < .01; *** p < .001. Models (1) and (2) use observations from both tasks, whereas Model (3) uses only observations from the financial task, and Model (4) relies solely on observations from the romantic task.
Regression results on the impact of terms and task on WOA in Study 2.

Note: N = 553. Term was treated as a dummy encoded variable representing five possible categories: artificial intelligence, algorithm, robot, chatbot, and statistical model. For term, algorithm was the base category. Task was treated as a dummy variable, where 0 indicates financial and 1 indicates romantic. * p < .05; ** p < .01; *** p < .001. Models (1) and (2) use observations from both tasks, whereas Model (3) uses only observations from the financial task, and Model (4) relies solely on observations from the romantic task.
Regarding the preference dependent variable, the results of the first analysis in Table 2, model (1), revealed that “algorithm” was preferred over “chatbot” (b = −0.592, p = .009), supporting Hypothesis 1.a. The interaction effect in the second analysis, shown in Table 2, model (2), between “chatbot” and “algorithm” term and task with preference as the dependent variable, showed no significant difference (b = 0.522, p = .214), thus, it did not support Hypothesis 2.a. The final analysis, performed separately by task and presented in Table 2, models (3) and (4), provides specific results: “algorithm” was significantly preferred over “chatbot” in the financial task (b = −0.815, p = .010). However, in the romantic task, there was no significant difference in preference between “algorithm” and “chatbot” (b = −0.293, p = .298).
For the WOA dependent variable, the first analysis shown in Table 3, model (1), indicates that “algorithm” was significantly more used than the terms “chatbot” (b = −0.143, p < .001), “artificial intelligence” (b = −0.116, p = .003), and “robot” (b = −0.095, p = .019). These results support Hypothesis 1.b. In the second analysis, concerning the interaction between the “chatbot” and “algorithm” term and task, no significant effect was found, as shown in Table 3, model (2); therefore, they did not support Hypothesis 2 b. This finding is consistent with the results in Table 3, models (3) and (4), where “algorithm” was significantly more used than “chatbot” (b = −0.133, p = .059); and also “artificial intelligence” (b = −0.119, p = .040), “robot” (b = −0.122, p = .043), and “statistical model” (b = −0.118, p = 0.049). In the romantic task, “algorithm” was significantly more frequently used than “chatbot” (b = −0.136, p = .004), as well as “artificial intelligence” (b = −0.104, p = .026). These results further demonstrate that “algorithm” was more used than “chatbot” in both tasks; however, there was no significant difference between tasks.
Finally, these results are robust after controlling for age and gender. Furthermore, tech affinity showed a significant effect when used as a control variable over model (1) for preference, but the difference between “algorithm” and “chatbot” remained significant. The variable tech affinity showed no significance in all other models.
General discussion
The present research investigated the influence of terminology on user preference and behavior, specifically comparing the terms “algorithm” and “chatbot” and how these effects vary based on task objectivity. The studies tested whether individuals prefer one term over the other and whether terminology affects the likelihood of users following advice provided by these systems. We also explored whether task objectivity moderates these patterns. The results underscore the importance of terminology—particularly the contrast between “algorithm” and “chatbot”—in shaping user trust and behavior.
Two experiments were conducted to explore these questions. Study 1 involved 115 undergraduate students who were presented with two tasks: predicting stock prices (objective) and measuring romantic attraction (subjective). Participants indicated their preference between a human and various terms, including “algorithm” and “chatbot,” for performing each task. These two terms were of particular interest due to their theoretical and practical contrast in perceived technicality and formality. Study 2 involved 568 Prolific participants randomly assigned to one of five terms, again including algorithm and chatbot, and one of the two tasks. Participants expressed their preferences and engaged in a decision-making exercise where they received advice from the assigned term.
The results consistently supported Hypotheses 1.a and 1.b: individuals preferred the term “algorithm” over “chatbot,” and they were more likely to follow advice when it was referred to as an “algorithm.” However, Hypotheses 2a and 2b, which posited that task objectivity would moderate these effects, were not supported. The preference for “algorithm” over “chatbot” was consistent across both objective and subjective tasks, indicating that terminology influences user preference and behavior regardless of task type.
Theoretical contributions and implications
The findings contribute to the expanding literature on algorithm aversion (for a recent review, see Chacon and Kaufmann, 2025), particularly within human–AI interaction. While prior studies have explored how terminology influences user responses to system failures (Candrian and Scherer, 2024) and the attributes users ascribe to AI systems (Langer et al., 2022), this research introduces a new layer by demonstrating that the terminology used to describe generative AI systems has a significant impact on user preferences and behaviors during their interactions with these systems. Specifically, the findings reveal that “algorithm” is consistently preferred over “chatbot” across tasks with varying levels of objectivity, underscoring the importance of linguistic framing in deploying generative AI systems.
Our findings extend the concept of the framing effect (Keysar et al., 2012; Kim et al., 2022; Tversky and Kahneman, 1981) by demonstrating that differences in system terminology—such as labeling a system an “algorithm” versus a “chatbot”—can activate distinct mental models (Gentner and Stevens, 2014), influencing both preference and behavioral engagement. This indicates that users’ responses to AI are influenced not only by its functionality but also by the language used to present the system. This perspective aligns with sociolinguistic and framing perspectives, which suggest that terminology does not passively reflect meaning but actively constructs it through shared interpretive frameworks (Entman, 1993; Gee, 2014).
Interestingly, the present study hypothesized that task objectivity would moderate the effect of terminology, expecting greater acceptance of “algorithm” in objective tasks and more skepticism in subjective ones. However, preferences remained consistent across both task types. This null finding suggests that framing may override task context: “chatbot” likely carries negative connotations (Gnewuch et al., 2017), while “algorithm” may signal competence and neutrality (Logg et al., 2019), leading to stable preferences regardless of domain. Rather than depending on mere task characteristics, the influence of terminology appears to arise from enduring interpretive biases. This highlights the role of labels in steering trust and compliance with algorithmic systems, even when functionality remains constant.
Another explanation is that users, regardless of the task type, perceive AI as lacking emotional or intuitive judgment and thus prefer labels that sound more analytical (Sundar, 2020). This suggests that the framing effect reflects not just task-specific reasoning but deeper heuristics related to anthropomorphism and trust in AI (Waytz et al., 2014). These findings highlight how linguistic biases can persist even when task context should, in theory, shift user expectations, extending research on AI adoption and communication.
Beyond framing effects, terminology can also be understood through the lens of semantic priming. Cognitive psychology research shows that words automatically activate related concepts in memory, shaping expectations and judgments even before conscious interpretation occurs (Neely, 1991). For example, the term “algorithm” is likely to evoke associations with precision, data, and objectivity, whereas “chatbot” primes associations with informality, anthropomorphism, or superficiality. This perspective suggests that the mere choice of label may bias user responses at an automatic, associative level, not only through interpretive framing.
From a theoretical standpoint, these results have relevant implications for future research. First, they emphasize the importance of researchers carefully selecting the terminology used to describe AI systems, as these choices can directly impact study outcomes. The results of our studies may be explained by the characteristics elicited by the terminology or the transparency; therefore, aligning the terminology with the research objectives and the system's intended characteristics is essential to ensuring the validity and reliability of findings. Second, these insights are particularly relevant for organizations aiming to enhance human–AI interactions. The terminology used in system design and deployment plays an important role in fostering trust, engagement, and productivity, ultimately shaping the effectiveness of these partnerships.
Beyond these cognitive and communicative mechanisms, our findings also contribute to CDS. This field emphasizes that algorithms and data systems are not only technical artifacts but also cultural and organizational constructs that acquire legitimacy through discourse, classification, and labeling (Bowker and Star, 2000; Gillespie, 2014; Nick, 2017; Pasquale, 2015). By showing that simply naming an identical system “algorithm” rather than “chatbot” increases user preference and compliance, our results empirically demonstrate how labels function as performative elements of governance. In this sense, terminology is not a neutral wrapper but a constitutive part of algorithmic power: it configures visibility, credibility, and trust in ways that shape how humans interact with ADM systems. This insight complements CDS debates on algorithmic imaginaries, legitimacy, and accountability by grounding them in behavioral evidence from controlled experiments.
With the increasing prevalence of AI chatbots (Kim and Hur, 2024; Wang et al., 2024), an intriguing direction for future research lies in investigating user preferences and behaviors across a broader spectrum of the terminology used to describe AI chatbots. Expanding this line of inquiry could explore the nuanced effects of alternative labels (e.g., “virtual assistant,” “AI companion”) on user expectations, trust, and willingness to engage with these systems. Moreover, examining how these preferences evolve across different domains, such as education, customer service, or healthcare, could provide valuable insights for tailoring the design and deployment of generative AI technologies to specific contexts.
These findings extend work on algorithm aversion and advice-taking in psychology, while also offering insight into how language mediates human–AI interaction in sociotechnical systems. In this way, the study contributes to ongoing research in algorithmic accountability, AI framing, semantic priming, and user behavior within data-driven environments, thereby supporting interdisciplinary inquiry into how people interpret and respond to opaque, ADM systems.
Practical implications
The results have significant implications for designing and implementing algorithmic systems in various industries. Organizations aiming to promote user adoption of algorithmic systems should consider the terminology they use to describe these technologies. By opting for terms that users prefer, such as “algorithm,” companies can enhance user engagement and increase users’ likelihood of following system advice. For example, in financial services, presenting a recommendation system as an “algorithm” rather than a “chatbot” could lead to higher acceptance of automated investment advice. However, practitioners should be mindful that while terminology influences advice-taking, WOA does not equate to sustained system usage or long-term behavioral reliance; therefore, further monitoring of continued use is warranted.
Organizations should leverage the preference for “algorithm” by framing their algorithmic systems accordingly. Conversely, if a system is labeled as a “chatbot,” users might be less inclined to follow its recommendations, potentially undermining the system's effectiveness. These findings align with recent guidance in the AI design and policy literature, which emphasizes that promoting calibrated trust in algorithmic system requires not only technical accuracy but also thoughtful framing, explainability, and transparency in user communication (Shin, 2025).
Although task objectivity did not moderate the terminology effect in this study, understanding the role of tasks remains important in real-world applications. Organizations should still consider the nature of the tasks when deploying algorithmic systems. While terminology might have a consistent impact, tailoring the system's presentation and communication style to the task context can further enhance user experience and acceptance.
Limitations
One limitation of this research is the focus on only two tasks: predicting stock prices (objective) and measuring romantic attraction (subjective). These tasks were intentionally selected based on prior studies that differentiate between relatively objective forecasting scenarios and highly subjective interpersonal judgments (e.g., Castelo et al., 2019; Logg et al., 2019; Prahl and Van Swol, 2021; Schaap et al., 2024). However, we did not include a direct manipulation check to empirically confirm whether participants perceived these tasks as differing in objectivity. Incorporating such a measure in future studies could offer additional insights by capturing individual variation in task interpretation. Expanding the task set and validating perceived objectivity would further enrich our understanding of how task characteristics shape responses to algorithmic advice.
A further limitation of this study is that we did not assess participants’ mental models or prior interpretations of the terms used. No manipulation check was made to confirm how participants interpret terms such as “algorithm” versus “chatbot.” Individuals likely held varied understandings of labels, which may have influenced their preferences and behaviors. For example, the term “algorithm” might signal precision to some people but opacity to others, while “chatbot” may suggest either helpfulness or superficial automation. To further strengthen the contribution, a direct manipulation check, such as a semantic differential scale, could be added in further studies to capture better how participants construe AI-related terminology. As Shin (2024) argues, users construct representations of algorithmic systems through social cues, framing, and past experience—mental models that evolve rather than remain fixed. Future research should investigate how these models influence trust and usage, as well as how system design can support more accurate and calibrated expectations. It may also be useful to explore how individual traits—such as personality or cognitive style—moderate these effects.
Conclusion
This research found that the terminology used to describe algorithmic systems (e.g., generative AI systems)—specifically “algorithm” versus “chatbot”—significantly influences user preferences and behavior in human–AI interactions. Across two studies, participants consistently preferred the term “algorithm” over “chatbot” and were more likely to follow advice labeled as coming from an “algorithm,” regardless of whether the task was objective or subjective. This suggests that the influence of terminology is robust across various types of tasks, highlighting how language can impact the dynamics of interactions between humans and AI.
The findings underscore the crucial role of language in shaping human perceptions, engagement, and acceptance of algorithmic systems. Organizations should consider using preferred terms such as “algorithm” when introducing AI systems to foster trust and enhance user engagement, thereby maximizing the potential of AI–human partnerships. As humans increasingly interact with AI in both professional and personal contexts, carefully selecting terminology can facilitate more productive and positive interactions. Future research should examine a broader range of tasks and explore users’ mental models and preconceived notions about generative AI terminology to better understand the underlying mechanisms behind these effects and their implications for human adaptation and behavioral change in AI interactions.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: ANID/FONDECYT/Iniciación 11250210 and ANID/FONDECYT/Regular 1251286.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.