
Abstract
This article develops a method for investigating the consequences of algorithmic systems according to the documents that specify their design constrains. As opposed to reverse engineering algorithms to identify how their logic operates, the article proposes to design or "forward engineer" algorithmic systems in order to theorize how their consequences are informed by design constraints: the specific problems, use cases, and presuppositions that they respond to. This demands a departure from algorithmic reformism, which responds to concerns about the consequences of algorithmic systems by proposing to make algorithms more transparent or less biased. Instead, by investigating algorithmic systems according to documents that specify their design constraints, we identify how the consequences of algorithms are presupposed by the problems that they propose to solve, the types of solutions that they enlist to solve these problems, and the systems of authority that these solutions depend on. To accomplish this, this article develops a methodological framework for researching the process of designing algorithmic systems. In doing so, it proposes to move beyond reforming the technical implementation details of algorithms in order to address the design problems and constraints that underlie them.
Keywords
Introduction
Theoretical traditions in critical algorithm studies (Gillespie and Seaver, 2016) are indispensable for conceptualizing algorithms as belonging to algorithmic systems: assemblages of multiple algorithms, databases, and interfaces that interact, as well as social practices that people develop to interact with them. Yet, this conceptualization of algorithms remains difficult to translate into concrete methods for auditing algorithms, or negotiating how existing algorithmic systems should operate in practice. Instead, the methods of algorithm evaluation and criticism that have become most popular among algorithm auditors and policy advisors are those that concern the logic of algorithms, their statistical biases, and material opacities (Mehrotra et al., 2017; Mittelstadt, 2016), as opposed to their dependencies on broader technical infrastructures and social demands. By attempting to analyze algorithm logic in order to isolate their social harms, these methods overlook how algorithm design constraints, motivations, and applications inform algorithm design and contribute to certain consequences in the first place.
Without addressing these factors, methods for correcting algorithmic bias and opacity amount to what I call algorithmic reformism, whereby calculated evaluations and critiques of algorithm logic motivate its redesign without changing the underlying problems and design requirements that it is supposed to satisfy. This enables algorithm designers to signal that an algorithm's problems have been addressed and resolved, when in fact the very problems and questions that algorithms are designed to solve remain unaccounted for. It is therefore unsurprising that algorithmic reformism is an increasingly common response to the grievances raised by the users and subjects of algorithms, who flag the consequences of algorithms as problematic according to their negative experiences with them. What the reform of algorithm logic puts at stake is our ability to apprehend, address, and critique the problems that algorithmic systems presuppose by design.
To address this, I propose the method of forward engineering, through which we design an algorithmic system according to design constraints in order to identify the objectives, problems, and solutions that these constraints prefigure (Figure 1). Forward engineering provides an alternative to reverse engineering, which analyzes algorithm logic to determine its biases, to represent it more transparently, and to install oversight and accountability measures. In contrast, forward engineering begins by identifying how algorithm design documents establish an algorithmic frame, or a problem space that an algorithmic solution should solve. Then, by designing an algorithmic system that satisfies this problem space, we analyze design compromises and consequences revealed through the design process. This method is informed by a Research Through Design methodology (see Stappers and Giaccardi, 2017), which follows from the insight that the process of devising and articulating an artifact (e.g., a product, a service, an artwork, an algorithm) reveals aspects of this artifact that it does not immediately reveal on its own. By forward engineering an algorithmic system from constraints specified in an algorithmic frame, we learn how these constraints reveal consequences that they do not make explicit.

Forward Engineering. Algorithm design constraints provide an algorithmic frame that specifies what an algorithmic system should do. Through forward engineering, we design an algorithmic system that satisfies the specifications of the algorithmic frame, while identifying design implications and design flexibilities that emerge through the design process.
This demands an analysis of not only design constraints, but also the interdependencies and indeterminacies that they reveal during the design process (Figure 1). On the one hand, we identify design implications: how design constraints interact with one another to inform the design of an algorithmic system and its consequences, no matter how its logic is implemented or reformed. Design implications – technical limitations, dependencies, and design compromises – are not made explicit by algorithmic frames, but rather emerge in the process of forward engineering them. On the other hand, we identify design flexibilities: how an algorithmic frame omits certain design constraints, providing for an algorithmic solution that is flexible by design. Design flexibilities are important to identify because they raise questions of authority: who is granted the authority to adjust algorithm parameters, to interpret their outputs, or even to reform the algorithms. Forward engineering addresses how algorithmic systems are designed with these constraints and flexibilities in mind, and how these considerations inform the social consequences, functionalities, and dependencies that algorithmic systems have irrespective of their implementation.
In order to identify design implications and flexibilities, I propose three dimensions of algorithm design that shift our theoretical focus away from whether the design of algorithms is satisfactory, and toward interrogating how design constraints inform this design in the first place (Figure 2). First, I substitute an analysis of algorithmic bias for one of the algorithmic domain, or the problem space specified by algorithm design constraints. While algorithmic bias attends to how an algorithm solves a given problem by depending on partial information, an algorithmic domain addresses how this problem is itself partial before an algorithm is even designed to solve it. Second, instead of aiming for algorithmic transparency, I propose to investigate algorithmic semiotics, or the interfaces, diagrams, statistical representations, and rhetoric that algorithmic systems depend on in order to achieve the goals specified in an algorithmic frame. An attention to algorithmic semiotics reveals that algorithmic systems are not simply designed to automate tasks or to make interventions in material reality; a critical aspect of designing algorithmic systems is to ensure that they appear epistemically valid, logically coherent, and justifiable, irrespective of their material effects. Third, I propose a theory of algorithmic authority instead of algorithmic accountability, in order to identify the kinds of access, privilege, and responsibility that algorithm design constraints attribute to certain individuals. Rather than deciding who should hold algorithms accountable, we must examine how configurations of algorithmic authority already dictate who has permission to interact with algorithms, granting certain liberties to some.

Analytical dimensions that motivate forward engineering and reverse engineering. In forward engineering, we produce an algorithmic system according to design constraints to investigate how the constraints inform the design process and product. During this process we attend to three dimensions of algorithm design: algorithmic domain, semiotics, and authority. In reverse engineering, we identify a black boxed algorithm in an algorithmic system and use statistical techniques to analyze its underlying logic. This enables us to identify algorithmic bias, and to achieve algorithmic transparency and accountability.
The primary contribution of forward engineering is to confront appeals to algorithmic reformism, which I examine in the context of law enforcement data analysis. I investigate law enforcement data analysis because it has become increasingly subject to algorithmic reformism, whereby algorithm auditors and designers propose to correct the bias or opacity of law enforcement algorithms, without addressing the design goals, underlying theoretical motivations, and regimes of authority that these systems presuppose by design. Accordingly this article examines how these theoretical motivations include criminological theories like “broken windows policing” which have been historically critiqued for licensing the over-policing of poor and marginalized communities (see for example Fagan and Davies, 2000), and which nonetheless continue to motivate the designs of contemporary algorithmic systems in law enforcement. Through forward engineering, I address these design presuppositions, theoretical assumptions, and the problems they motivate, which together inform the implementation of algorithmic solutions, and which remain unchanged by algorithmic reformism. Moreover, that the public is generally restricted from access to law enforcement data analysis systems makes them appropriate for a study that concerns issues of algorithmic transparency and accountability. To this end, forward engineering provides a method for reading publicly accessible documentation to infer the consequences of algorithmic systems, without needing to know specifically what algorithm logic is being used.
To begin, this article explains how the concepts of algorithmic bias, transparency, and accountability motivate appeals to reverse engineering. The article then describes how reverse engineering is used in practice to analyze a law enforcement data analysis system called PredPol (PredPol, 2018), and it addresses some benefits and limitations of this approach, one of which is a tendency toward algorithmic reformism. In the following section, the article introduces the method of forward engineering along with its key methodological concepts, I describe how approaches in Research Through Design and critical algorithm studies inform the method, and I apply the method to analyzing PredPol. This prepares us to address methodological distinctions between reverse engineering and forward engineering. The article then concludes with opportunities and challenges that forward engineering poses for critical algorithm pedagogy and critique.
Reverse engineering
In academic research, literature, and journalism, much of the discourse that attends to the social consequences of algorithms concerns the notion of “algorithmic bias,” which addresses how the decision-making logic of algorithms and their consequences are statistically partial to certain individuals, populations, or entities (Hajian et al., 2016). The prevailing response to algorithmic bias has been an appeal to detecting and correcting for algorithmic bias. This has motivated the development of methods for “reverse engineering” algorithms (Diakopoulos, 2014), whereby statistical models or simulations of existing algorithms are developed to infer whether these algorithms exhibit a bias toward certain entities.
Reverse engineering can concern multiple kinds of algorithmic bias. An algorithm may treat a certain data variable as more significant than another, which exhibits a “technical bias” toward this variable; otherwise, the deployment of an algorithm in a particular social context may result in an “emergent bias” that was not explicitly accounted for in the algorithm's design (Friedman and Nissenbaum, 1996). Algorithmic bias may also concern how an algorithm inherits the biases of its input data (Feinberg, 2017), which has been popularized by the phrase 'garbage in, garbage out.' For example, if a certain population is underrepresented or overrepresented in input data, then the consequences that result from an algorithm's use of this input data will be partial toward or against this population.
In turn, concerns of algorithmic bias have motivated the conceptualization of “algorithmic transparency” (Diakopolous and Koliska, 2017), which argues that if the logic of algorithms were made transparent, then their biases and logical discrepancies could be more readily identified and corrected for (Pasquale, 2015; Burrell, 2016). Faced with the challenges proposed by notions of algorithmic bias and opacity, “algorithmic accountability” (Diakopoulos, 2015, 2016) proposes to hold algorithm developers accountable for the consequences of algorithms. This mainly entails the development of tools for detecting algorithmic bias or ensuring algorithmic transparency, so as to enable “algorithmic auditing” (Mittelstadt, 2016; Mehrotra et al., 2017), or to supplement the decision-making criteria of algorithms with human oversight (Neyland, 2016; Shneiderman, 2016), as in a system of checks and balances.
Reverse engineering can be applied to reveal an algorithm's biases, to make its logic more transparent, or to motivate the installation of accountability mechanisms. In any case, reverse engineering analyzes an algorithm's logic, such as which data variables it ingests, or which machine learning methods it utilizes, in order to identify its consequences. Such an inquiry motivates us to implement a new algorithm that does not exhibit the same consequences, or to critique those who designed the algorithm and demand that they be held accountable for the algorithm's design and effects.
Reverse engineering in practice
Here I describe how reverse engineering is applied in practice to PredPol (Predictive Policing), a law enforcement data analysis system developed for use by the Los Angeles Police Department (LAPD). PredPol uses an algorithmic model called ETAS (Epidemic Type Aftershock Sequence) to convert historical crime data into a geographic probability distribution that indicates where law enforcement interventions should be staged to apprehend and prevent crimes (Mohler et al., 2011). Kristian Lum and William Isaac reverse engineer the ETAS model and demonstrate the algorithm's disproportionate impact on historically over-policed communities (Lum and Isaac, 2016). What makes their approach an instance of reverse engineering is that the authors investigate how a particular algorithm operates (ETAS), and attend to the social consequences that can be expected to arise from using this algorithm's logic in practice.
Reverse engineering requires that Lum and Isaac examine the documentation that specifies how ETAS should be configured to predict crimes for PredPol, and then reproduce and implement the algorithm themselves. For want of the crime data that PredPol uses in practice, Lum and Isaac generate synthetic data that simulates the locations of drug use throughout Oakland. They run their implementation of ETAS on the synthetic data to reverse engineer how the model would predict crimes in practice, revealing that the algorithm is biased toward placing hotspots in locations that have already been policed. The authors conclude that this bias results in a feedback loop: places where crimes have already been documented are most likely to be designated as hotspots, which encourages police to find more crimes there, further increasing the likelihood of hotspots being placed there again.
The advantage of reverse engineering in this case is that it concretely demonstrates how an algorithm is biased in a realistic context. Lum and Isaac use geographic maps of hotspots, like PredPol does, to demonstrate how this bias might affect Oakland geography and corresponding demographics. Reverse engineering also enables the authors to posit that their findings are generalizable to other algorithms that work similarly to the ETAS model, which they identify as those that predict future crimes without adjusting for the disproportionate abundance of crime data in certain areas. This mitigates the need to repeat reverse engineering if the proprietors of PredPol design a new algorithm in the place of ETAS, provided that the new algorithm design does not take this critique into account.
Lum and Isaac's use of reverse engineering establishes a critique of the ETAS model that demonstrates a significant consequence of its logic. The proprietors of PredPol can now choose to implement an algorithm in the place of the ETAS model that addresses this critique. In fact, this is a change that is now underway, as the LAPD's “Precision Policing” initiative proposes to use new heuristics to adjust for the disproportionate presence of police in certain areas (Bratton, 2018), while there are no plans in place to retire the remainder of the PredPol infrastructure. Because Lum and Isaac's critique is no longer applicable to this new regime, we will need to apply reverse engineering again to the new scenario. This creates a pattern that I call algorithmic reformism, where a calculated critique of a particular algorithm such as ETAS motivates changing the algorithm's implementation details, while its underlying design constraints and motivations remain the same. Through this iterative process, the designs of algorithmic systems become less epistemically suspect, but more resistant to critique.
Here I argue that the biases of the ETAS model, although they appear to be specific to the algorithm, serve specific design constraints, and that any other algorithm implemented to satisfy the design constraints specified for PredPol would share similar consequences. Whereas reverse engineering aims to reproduce and analyze a particular algorithm like ETAS, it does not venture to interrogate the design constraints and problems that inform the choice of this algorithm, as well as how the algorithm is configured to satisfy these design constraints in the first place. Therefore, we cannot depend on reverse engineering alone to address consequences of algorithmic systems, insofar as these consequences are implicated in the constraints that motivate algorithm design. Instead, we must interrogate these design constraints themselves, and how they reveal certain consequences through the design process.
Forward engineering
How we design an algorithmic system depends on what we set out to achieve, as well as the problems and questions we presuppose can be solved by an algorithmic system. Algorithmic reformism elides this principle by proposing new algorithmic solutions to satisfy the same design problems, neglecting to acknowledge how design problems implicate consequences irrespective of their particular algorithmic solutions. Therefore, to guide an inquiry into algorithm design problems, I first propose the concept of algorithmic frames: the constraints, problems, and use cases that algorithms are designed to fulfill irrespective of their implementation (Figure 1). As opposed to revealing how algorithmic systems have been implemented by reverse engineering them, we identify how certain design constraints and problems inform these implementations in the first place.
The notion of an algorithmic frame finds precedents in existing research that examines how design presuppositions inform the logic of algorithms. For example, Yanni Loukissas investigates how a popular library of natural language processing algorithms depends on a history of unique design assumptions to classify the syntax of human speech, which he demonstrates by using the algorithms in practice (Loukissas, 2019). Os Keyes conducts a content analysis of automatic gender recognition (AGR) and human–computer interaction (HCI) research that aims to classify gender, demonstrating how the design assumptions of AGR algorithms prefigure the way that HCI research accounts for gender (Keyes, 2018). Both of these projects inspect algorithmic frames as their object of research, explaining the design of algorithms according to ontologies, partial objectives, and social biases that they presuppose.
Provided an algorithmic frame, a developer devises an algorithmic system by identifying a set of algorithms, data sources, and implementation details that can be articulated together to solve the problem specified. This process reveals design consequences and compromises that are not explicit in the algorithmic frame but rather emerge through the design process. Moreover, the design process involves more than just designing algorithm logic and data; as I will show, it also requires designing visual, interactive, and statistical conventions as well as configurations of authority that enable algorithms to be used as intended by design. In order to address these considerations, I propose the method of forward engineering (Figure 1). Forward engineering analyzes the consequences of algorithm design problems, irrespective of the algorithmic solutions that are implemented to solve them. While I follow from the methods that Loukissas and Keyes use to examine algorithm design constraints and assumptions, through forward engineering we are concerned with investigating consequences of these constraints that emerge through the design process – the object of research is the design process itself.
In particular, through the design process forward engineering identifies how relationships between design constraints lead to design implications: technical limitations, dependencies, and design compromises that are not made explicit by algorithmic frames but emerge in the process of forward engineering them (Figure 1). Through designing algorithmic solutions we also identify where the design constraints of algorithmic frames are insufficient or undetermined, providing for design flexibilities that defer decisions to the discretion of designers or certain users. In order to identify these design implications and flexibilities, we design an algorithmic solution according to design constraints specified in an algorithmic frame.
Research through design
Research Through Design involves both theoretical and practical components, both of which can inform one another: we can evaluate an existing theory by designing an artifact that reflects its principles, or we can design an artifact to theorize about its design process (Stappers and Giaccardi, 2017). In order to investigate the algorithm design process, I enlist Research Through Design in the sense that research can be produced by designing under the constraints of design requirements and stated objectives as they are already specified. Notably, imaginary media studies (Parikka, 2013) and critical making (Ratto, 2011) construct the components of existing media technologies together to research how technical constraints inform the design process and the artifacts that result. By comparing an imagined media technology to a real one, imaginary media studies reveals aspects of the latter that are normally taken for granted, tacit, or inconspicuous. Adversarial design (DiSalvo, 2012) operates similarly by emphasizing this antagonism between imagined and really existing artifacts. It concerns the creation of artifacts that, both in the process of their production and their use, reveal attributes of why certain artifacts are produced, by whom, and for what purposes.
Like both imaginary media studies and adversarial design, research-creation encourages the exploratory creation and production of an artifact under specified constraints (Chapman and Sawchuk, 2012). But instead of posing an antagonism between imaginary and really existing media artifacts, research creation seeks out qualitative resemblances among them, documenting their structural or aesthetic affinities. Meanwhile, feral computing (Fuller and Matos, 2011) acknowledges that certain consequences of designed technologies are unpredictable insofar as they interact with human users, external factors, or other systems, and encourages their development for the sake of investigating this. This informs my conceptualization of design flexibilities: how the omission of certain design constraints affords algorithmic systems, their designers, or their users certain freedoms of action by design.
These methods derive research through design because they interrogate how the process of designing computational systems generates certain problems, compromises, and flexibilities, each of which informs the computational product that results. Likewise, we forward engineer algorithmic frames to investigate the consequences that design constraints exhibit during the design process. This fundamentally changes our conceptualization of algorithmic bias, transparency, and accountability. No longer concerned with opening the black boxes of algorithmic systems to reform their logic, these concepts must be made adequate to an investigation of the design process itself (Figure 2).
Algorithmic domain
Whereas algorithmic bias identifies how algorithms are partial to certain objects and variables that they operate upon, an algorithmic domain identifies how the language, concepts, and problem space of algorithmic frames present partial ways of designing, developing, and applying algorithmic systems in the first place. This is to say that an algorithmic system is partial before it exhibits any statistical biases. To this end, we identify how an algorithmic frame establishes an algorithmic domain, like a problem space or a field of assumptions, in which an algorithmic solution should operate. Investigating algorithmic domains enables us to identify how the designs of algorithmic systems, and thus their partiality, are delimited by design requirements, objectives, and problems posed in advance of their implementation.
Such partiality is evidenced, for example, in the classification of individuals into discrete gender categories that exclude non-binary and transgender parameters of representation (Keyes, 2018; Hoffmann, 2019). These schemes of classification are provided by algorithmic domains that conceptualize gender according to presupposed categories. Moreover, an algorithmic frame expresses not just a partiality toward certain ontologies of objects and subjects, but also a partial mode of organizing these objects and subjects. This is especially relevant to the context of law enforcement, where criminological theories motivate the design of information systems that sort and rank individuals according to data collected about them, namely in order to calculate their disposition to criminality. Through forward engineering, we interpret such theories as design constraints that inform the design of particular algorithmic solutions. We then devise algorithms that respond to such design constraints, examining how their logic satisfies these constraints, and to what ends. To investigate an algorithmic domain is to identify how design problems and presuppositions confer to particular design solutions.
An algorithmic domain specifies the needs or agendas that motivate the design of an algorithmic system, and it often provides use cases to illustrate how the system can be used to satisfy these needs. An algorithmic domain may also specify statistical, sociological, or criminological theories that motivate an algorithmic system's design, along with key entities, subjects, and phenomena that it should account for. In doing so an algorithmic domain delimits the discourses and epistemic criteria that are adequate to reflecting on algorithmic systems. For example, an algorithmic frame may identify the correction of algorithmic bias as critical to an algorithm's proper implementation, and provide specifications for how to evaluate bias (see for example, Uchida and Swatt, 2013). The design of an algorithmic frame thus involves selecting not only which data variables should be represented by an algorithmic system, but also, by virtue of establishing this domain, which data variables should be prioritized for circumspection and critique. For this reason, we must acknowledge that algorithmic frames do not only provide design specifications for processing data; they also provide specifications for how this data processing should be apprehended and understood.
Algorithmic semiotics
Algorithmic transparency conceptualizes algorithm logic as enclosed and obscured by the walls of a 'black box' (Figure 3), which must be reverse engineered so that the consequences of algorithm logic can be revealed. This discourse elides the fact that the consequences of algorithms cannot be discovered by attending to their logic alone; to the contrary, the consequences of algorithms depend on how they disclose themselves to the world, through interfaces, visualizations, diagrams, and automated events. Through algorithmic semiotics, algorithmic systems present algorithm logic as percepts – e.g., vibrating your phone because your account is out of funds, displaying a message that an algorithm has classified data with 99% accuracy, or locking a door – which make the logic of algorithms affective. I call these mechanisms semiotic because they depend on conventions for translating the logic of algorithms into apprehensible percepts. What is more is that the process of designing algorithmic systems involves designing and composing these conventions such that the consequences of algorithms appear epistemically valid, logically coherent, and consistent with the goals set forth in an algorithmic frame.
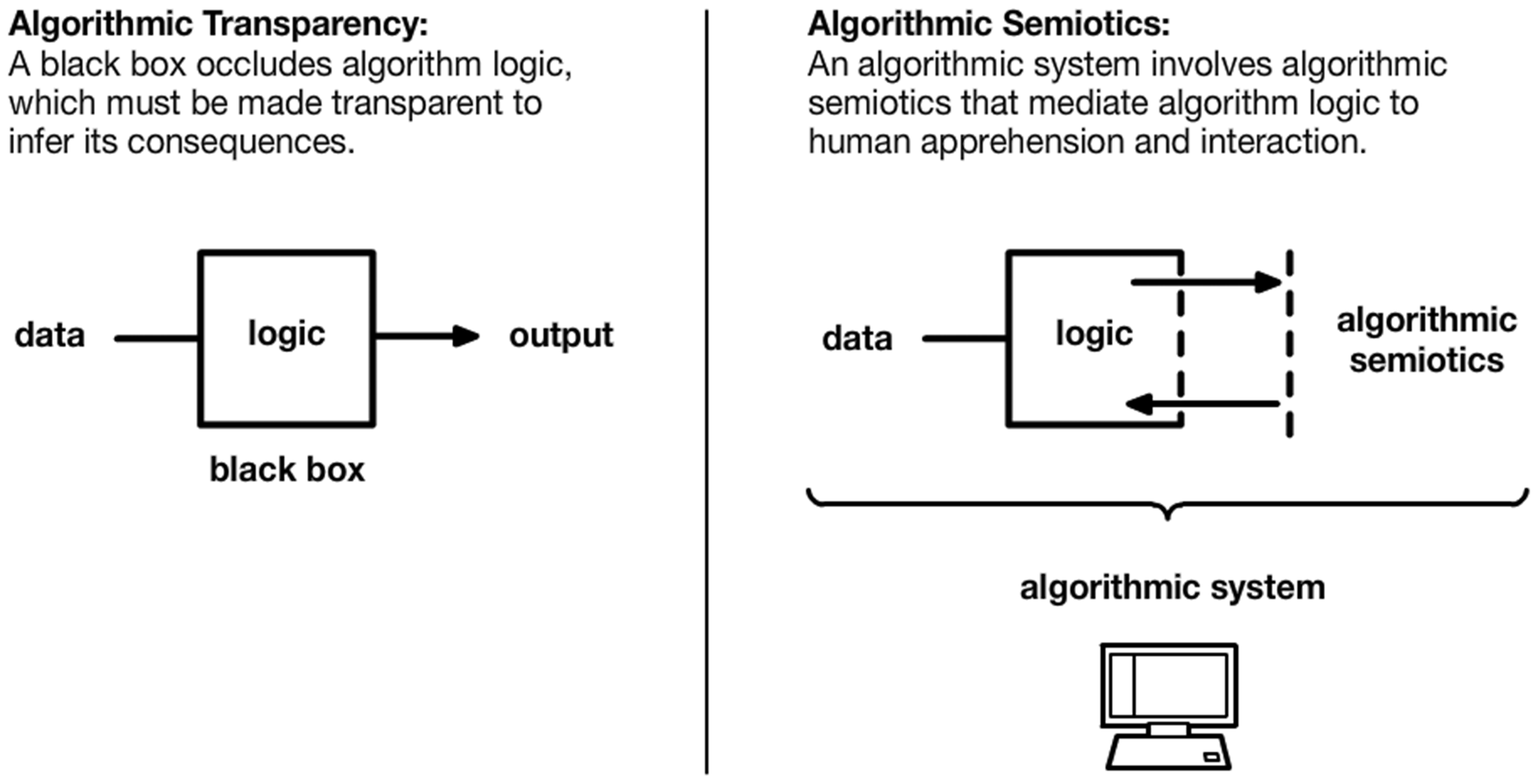
Algorithmic Transparency and Algorithmic Semiotics. Algorithmic transparency posits a black box that occludes algorithm logic. Algorithmic semiotics posits designed conventions that mediate this logic for human apprehension and interaction.
Algorithmic semiotics include graphical and interaction conventions designed by User Interface (UI) Designers and User Experience (UX) Designers, but also those designed by algorithm developers who assign meaningful labels to dimensions of data or algorithm outputs, like 'heart rate' or 'user ID,' in order to indicate their use. Moreover, algorithmic semiotics account for the metaphors, explanations, and rhetoric that demonstrate to people how algorithms should be understood and used, often in order to encourage their positive reception and to justify their deployment. Christian Sandvig demonstrates, for example, how algorithms are explained with diagrams or cartoons in order to indicate how they work, or to advertise their functionalities (Sandvig, 2013). In this way, algorithmic semiotics do not simply make algorithms apprehensible, but are designed to make algorithms apprehensible in particular ways, to certain ends.
The design of algorithmic semiotics can be likened to a practice of rhetoric and persuasion that concerns how algorithmic systems appear to people and are experienced by them, which are appearances and experiences designed in accordance with the constraints specified by an algorithmic frame. For example, Louise Amoore and Agnieszka Leszczynski examine how the probabilistic calculations of algorithms are mediated by geographic maps that influence how people perceive the calculations and act upon them (Amoore, 2011; Leszczynski, 2016). Here the assignment of forward engineering is to identify the design constraints and goals that motivate the presentation of these probabilities on geographic maps in the first place. Such maps do not simply represent these probabilities; they are algorithmic semiotics designed to mediate them in a particular way, consistent with goals and use cases set forth in an algorithmic frame.
Insofar as an algorithm is designed by people or to affect people, I argue that algorithms cannot have effects without depending on algorithmic semiotics, which mediate between algorithm logic and human apprehension. Algorithmic semiotics demonstrate that the logic of an algorithmic system can never be simply transparent or opaque, because it is always mediated by algorithmic semiotics; e.g., a programming language, a diagram, a visualization, an interface, or a physical action. We cannot depend on algorithmic transparency to infer the consequences of an algorithmic system by isolating and analyzing its logic, since this logic is always entangled with semiotics that mediate this logic and bear their own consequences (see Reigeluth, 2017). Moreover, this mediation is not arbitrary, but constrained by design. Every algorithmic frame either specifies algorithmic semiotics that it requires to operate – systems for interfacing, visualizing, comprehending, and analyzing algorithmic systems that extend beyond the data processing logic of algorithms – or it poses problems that constrain how these semiotics should be designed. Through forward engineering, we concern ourselves with how design constraints motivate the design of particular semiotics for mediating algorithm logic. This analysis of algorithmic semiotics demonstrates that we cannot simply analyze algorithm logic without also analyzing how this logic is designed and intended to be perceived by people in practice. Nor can we remove these mediating semiotics to make the consequences of algorithms transparent, as to do so would change their very consequences, and even raise additional ethical and social concerns (Ananny and Crawford, 2018).
Algorithmic authority
Appeals to algorithmic accountability (Diakopoulos, 2015, 2016) tend to follow from algorithmic mistakes, mishaps, or blunders that draw the reliability or epistemic legitimacy of algorithms into question once they are already deployed in practice. Algorithmic accountability thus intends to account for algorithmic discrepancies when they emerge in particular circumstances, but it does not venture to attribute these discrepancies to concrete design principles and assumptions that might reproduce them in the future. Therefore algorithmic accountability wants to hold algorithm developers accountable for the systems that they have constructed, but less so for the systems that they are actively developing. Moreover, while algorithmic accountability attributes an authority to reform to algorithm developers and an authority to contest to algorithm subjects, it does not sufficiently interrogate the conventions that establish and maintain this division of authority.
As opposed to the dichotomous model of algorithmic accountability, we should be concerned with algorithmic authority: the way in which the people that design, use, relate to, or are affected by algorithmic systems interact with one another, and how they are afforded the ability to articulate their wants or needs according to certain conventions of interaction provided by algorithmic systems. Notably, Brian Jordan Jefferson addresses how law enforcement data analysis systems are entangled with regimes of access and decision-making that structure who interacts with data and how (Jefferson, 2017). With the concept of an algorithmic frame, I argue further that such configurations of authority are prefigured by design.
Algorithmic authority accounts for the existence of different accountability models. It pluralizes algorithmic accountability by acknowledging the existence of particular design conventions and technological mechanisms that algorithmic systems deploy to configure their subjects in relation to one another. Instead of demanding that algorithm developers be held accountable, we ask: In this particular case, why are algorithm developers authorized to reform algorithmic systems, and how do algorithmic frames justify this authority? Furthermore, we investigate how algorithmic systems are deployed in the service of particular configurations of authority. These configurations of authority may preexist the design of an algorithmic system, but it falls on an algorithmic frame to specify a particular configuration of responsibility and access that an algorithmic system should abide to.
Forward engineering in practice
To demonstrate forward engineering in practice, I apply the method to analyzing PredPol and compare it to the reverse engineering approach employed by Lum and Isaac (Lum and Isaac, 2016). To accomplish this, I analyze PredPol's public documentation and promotional materials, white papers documenting the system's algorithmic implementation details, a patent specifying the system's information architecture (Mohler, 2015), as well as documents disclosed in response to Public Records Act (PRA) and Freedom of Information Act (FOIA) requests.
To ascertain PredPol's algorithmic domain, I first identify the high-level problem that the documents propose for the algorithmic system to solve, as well as the needs and sociological theories that it states motivate its design. The documents specify that the purpose of PredPol is to optimize the geographic allocation of police resources according to historical crime data, by providing “forward-looking recommendations as to where and when additional crimes could occur” (PredPol, 2018). The documents also specify that PredPol must assist law enforcement in its objective to apprehend and deter crime. To accomplish this, they appeal to criminological theories like “broken windows policing,” which argue that crime in one location is evidence that crime will likely occur there again (PredPol, 2014). Therefore, the algorithmic domain requires that I design an algorithmic solution which highlights locations for law enforcement interventions according to geographical crime data, and which presupposes that crime reoccurs in the same places. Note that I do not implement the ETAS algorithm, because this is but one possible solution for satisfying these constraints. Whereas reverse engineering analyzes a particular algorithmic solution, the purpose of forward engineering is to investigate how design constraints and problems motivate algorithmic solutions to be designed to certain ends, and to identify the implications for design that arise in the process.
Historically, appeals to broken windows theory have licensed law enforcement interventions in locations that are comparatively poor and underprivileged, following from the logic that misdemeanor crimes like vandalism, evidenced by broken infrastructure, are indicators of a regional disposition to criminality (Fagan and Davies, 2000). In this way adherents of broken windows policing claim to discriminate on the basis of such misdemeanor crimes alone, while denying that this regime of discrimination necessarily contributes to the over-policing of poor and minority communities (Bratton, 2018). For PredPol, an appeal to this theory justifies the implementation of a predictive model that does not aim to identify substantive causal links between crimes, but rather interprets every crime at a given location as a generic indicator that another crime will recur nearby. However, PredPol's algorithmic frame imposes a constraint on this generalizing logic by requiring users to choose a crime classification (e.g., auto theft, burglary) for analysis each time that they run the predictive model (Mohler, 2015). This indicates a first
Like Lum and Isaac (Lum and Isaac, 2016), I generate synthetic crime data according to the design specifications: fundamentally, each data point must have geographic coordinates and a timestamp. The difference is that whereas reverse Lum and Isaac simulate how PredPol would analyze drug crime data in practice, and therefore design all of their data to belong to the same classification of drug crime, I follow the algorithmic frame to design the data points with different crime classifications in order to investigate the implications of this design constraint. This consequently raises a substantial
The documents further specify that locations for allocating police resources according to historical crime data are called “hotspots,” which designate 500 × 500 ft squares. In order to satisfy this constraint, the output of my algorithm needs to take the form of this grid, even though the specified input is point-based location data. This consequently reveals a second
I next need to implement logic for determining which regions in the grid should be declared as hotspots, given the synthetic data. I follow from the sociological theories that the system presupposes in the algorithmic domain: crime in one location is evidence that crime will likely occur there again. This reveals another

Algorithmic system forward engineered from PredPol's algorithmic frame.
Now that I have implemented an algorithm to designate hotspots, the design constraints require me to design algorithmic semiotics to present these hotspots to human apprehension and interaction, to indicate precisely where law enforcement should intervene in geographic space. Given that I am constrained by having converted point-based crime data into a grid-based probability distribution, I encode geographic space as a gridded heatmap, with darker squares indicating a higher local likelihood of future crimes, with hotspots outlined. Then, following the requirements of the algorithmic frame, I overlay this heatmap on a geographic map (Mohler, 2015). This effectively reveals a
The superposition of hotspots and geographies is an increasingly common approach to representing crime data that warrants specific attention. Fundamentally the semiotics of crime maps evince what media scholar Aurora Wallace (2009) describes as an “aesthetic of danger” that portrays particular geographies and communities as threatening, reinforcing popular convictions about the spatiotemporal dynamics of criminality and its regional distribution. Wallace draws particular attention to the degree of control afforded to crime mapping systems to depict certain areas as dangerous, and as permanently marked by past events that are less contemporaneous than the crime maps suggest. In the case of PredPol, what makes the presentation of geography and hotspots significant in this way is another feature provided by the algorithmic frame: users can not only select the range and kind of data that the algorithm considers to calculate hotspots, but they can also select hotspots manually from any point on the map (PredPol, 2014). This engenders a key
From the purview of algorithmic accountability, we might appeal to holding users accountable for selecting fair or appropriate hotspots, perhaps by limiting the flexibility that they have when choosing hotspots, or rendering their choices more transparently. However, by forward engineering the algorithmic frame, we find that PredPol is designed precisely in order to balance the use of a scientifically verified hotspot selection algorithm (that is to say, one that is informed by peer-reviewed theories and methods) with the unbounded decisions of human users. To request algorithmic accountability or transparency here is to miss the point: PredPol's algorithmic frame seeks an algorithmic solution that licenses the unbounded discretion of law enforcement analysts with a bounded algorithmic protocol. These two processes of hotspot selection are not mutually exclusive but paralleled, and this parallelism informs how the algorithmic system operates and appears. It provides for a distribution of authority which effectively ensures that no single algorithm or person is definitively responsible for hotspot selection: neither the developers who implement PredPol, the users who adjust its parameters in practice, the PredPol algorithms, nor the law enforcement officers dispatched to the hotspot locations.
Reverse and forward engineering: Methodological distinctions
Having forward engineered PredPol's algorithmic frame, I now discuss methodological distinctions between forward engineering and reverse engineering. First, reverse engineering is concerned with evaluating a specific algorithm's logic, in this case the ETAS model (Lum and Isaac, 2016). Reverse engineering identifies whether the algorithm exhibits any epistemic fallacies, like unexpected biases, classification errors, or feedback loops, which motivates the design of better algorithms that do not exhibit the same fallacies. In contrast, forward engineering does not analyze whether an algorithm's logic is faulty or epistemically valid, but how design constraints motivate certain algorithm logic. By forward engineering PredPol's algorithmic frame, we find that the algorithmic feedback loop revealed by Lum and Isaac is itself a design requirement, even before it is the fault of a particular algorithmic solution: the sociological theories that underpin PredPol's design themselves presuppose that crime patterns should exhibit a feedback phenomenon. Thus for forward engineering, if the algorithm we design for PredPol has deleterious consequences, it is not because the algorithm has been designed improperly but precisely because it has been designed according to design constraints which implicate these very consequences.
This is significant in the context of law enforcement because criminological theories and policing initiatives have been historically designed to police poor and minority communities (see for example Hawkins and Thomas, 2013). If we locate the cause of disproportionate over-policing in particular algorithmic solutions and datasets, we may neglect to interrogate the historical legacy of theoretical assumptions that motivate these solutions in the first place. For its part, forward engineering identifies PredPol as an algorithmic system that operationalizes the logic of broken windows theory and enlists the semiotics of cartographic hotspots to represent criminality geographically. In turn, this necessitates that we acknowledge existing research and literature that addresses the motivations and practical implications of broken windows theory (for example Fagan and Davies, 2000) as well as the function of cartographic conventions in establishing certain conceptualizations of criminality (for example Kindynis, 2014). Algorithmic systems designed according to these conventions are subject to their same critiques; for this reason, forward engineering provides a method for identifying the function of these conventions in the process of designing algorithmic systems.
Second, while reverse engineering conceptualizes an algorithm as a logical process that must be analyzed or revealed, forward engineering conceptualizes algorithm logic as a component of a broader algorithmic system. For forward engineering, the consequences of algorithms are not limited to their logic, but to configurations of semiotics and authority that this logic depends on in order to work as intended by design. In the case of PredPol, forward engineering can clearly acknowledge a series of consequences that reverse engineering does not. First, hotspots do not represent definitive crime predictions so much as they are instances of algorithmic semiotics that have an argumentative effect: a hotspot is not an indication of a planned action but a representation of geography according to algorithmic criteria. The algorithmic frame depends on algorithmic semiotics to represent historical crime data in way that is conducive to deciding how to allocate location-based law enforcement interventions. In turn, PredPol's algorithmic frame specifies a configuration of algorithmic authority that lets users choose hotspots manually, distributing authority across the PredPol algorithms and users without leaving any one agent definitively responsible for hotspot selection.
Further, PredPol has an algorithmic domain that motivates its solutions to operationalize and justify criminological theories like broken windows policing. Whereas reverse engineering can critique an algorithm like ETAS for incidentally or inadvertently actualizing the logic of broken windows policing, forward engineering views this algorithm as a solution intentionally designed to actualize this logic. In other words, over-policing of certain communities in PredPol isn't a bug; it's a feature. Here we cannot be concerned exclusively with how to design an algorithm that does not over-police certain communities because we must address the design constraints that prefigure this algorithm's design in the first place. Other algorithmic solutions might be developed but altogether to the same effects, insofar as their design remains informed by the design principles of broken windows theory.
Third we should consider the cases to which reverse and forward engineering can be applied. Both methods concern analyzing algorithmic systems provided partial information about them. Both methods are applicable to analyzing PredPol because information about the system's design constraints and its current algorithm are both publicly accessible. However, reverse engineering is impossible if we both do have access to using an algorithmic system and we do not know what algorithm it uses. Moreover, reverse engineering may be intractable once algorithms are implemented in practice (Gillespie, 2014), and some of the epistemic claims of reverse engineering to reveal algorithmic bias are dubious (Green et al., 2010). On the other hand, forward engineering is impossible if we do not have access to documents specifying the system's design constraints. However, I argue that this is seldom the case as public messaging and documentation about algorithmic systems is continually released to justify their impact, whether to people that will be affected by them or to people that want to deploy them. Moreover, FOIA and PRA requests are frequently granted access to algorithm design constraints, but not to algorithm source code and logic. Whereas the public is generally restricted from accessing the algorithm logic of law enforcement data analysis systems, forward engineering enables investigations of algorithmic systems that can be conducted through public messaging and documentation alone.
Lastly, forward engineering is designed specifically to account for algorithmic reformism. The outcome of reverse engineering is a critique of a particular algorithm's epistemic fallacies, which motivates the design or implementation of an improved algorithm. This tends toward algorithmic reformism, where in the case of the LAPD, algorithms are now being reformed to use heuristics that respond to critiques like Lum and Isaac's, while continuing to depend on the same criminological theories like broken windows policing (Bratton, 2018). These reformed heuristics are said to be “discriminating” but not “discriminatory,” because they use data about community orderliness to anticipate crimes, but they are not intentionally designed to have a disproportionate impact on certain races. From the vantage of forward engineering, however, we see that this is but a new rhetorical and semiotic solution to a design problem and design constraints that have remained the same. Moreover, whereas algorithmic bias concerns how algorithms are “discriminatory,” an algorithmic domain addresses the deleterious consequences of “discriminating” design problems to begin with. By investigating how algorithmic frames inform the design process, we acknowledge that this new solution will not fix the problems that the LAPD presupposes by design – we must confront the design problems and constraints themselves.
Meanwhile, new law enforcement data analysis systems like HunchLab (hunchlab.com) and CivicScape (civicscape.com) propose to account for algorithmic bias, transparency, and accountability with algorithm logic that is open source and user-controlled. Again, we need only return to the forward engineering of PredPol to find that many of the design constraints, implications, flexibilities, and consequences remain. Whereas reverse engineering can target the algorithms that each of these systems use and correct their epistemic fallacies, forward engineering can critique the regime of design problems and conventions that these systems share. As new law enforcement campaigns arise to reform the biases of algorithmic systems, it is imperative that we continue to confront the historically entrenched presuppositions that motivate these systems in the first place. Forward engineering provides a method for identifying these presuppositions in the design constraints specified by algorithmic frames, enabling us to relate work on the history, motivations, and contexts of these presuppositions to an analysis of the algorithm design process.
Conclusion
This article presented a method for analyzing the process of designing algorithmic systems according to design constraints. In doing so, it proposed the design dimensions of algorithmic domains, semiotics, and authority to investigate the consequences of algorithms beyond the scope of algorithmic bias, transparency, and accountability. Whereas these latter discourses continue to raise important concerns about the biases and opacity of algorithms, they contribute to algorithmic reformism insofar as they overlook how these consequences are informed by design constraints in the first place. Through forward engineering, we confront consequences of algorithmic systems that are presupposed by design problems, irrespective of the algorithmic solutions designed or reformed to solve them.
By shifting the scope of our analysis, we also stand to shift the scope of our interventions. As opposed to correcting for algorithmic bias, we can consider how design problems, objectives, and needs motivate algorithmic systems to be partial to certain people, populations, processes, and politics by design, as specified by algorithmic domains. The call for transparent algorithm logic can be met with an analysis of how design problems influence the configuration of semiotics that mediate this logic to people in order to influence how algorithms and their calculations are perceived. And programs of algorithmic accountability can shift to acknowledge that configurations of authority are implicated in the design of algorithmic systems, and that we must draw these designs themselves into question, not merely regulate their consequences. In each way, we depart from appeals to algorithmic reformism that propose to correct the logic of algorithms, and we confront the underlying design principles, motivations, and problems that algorithmic solutions are designed to satisfy.
This underscores the importance of a Research Through Design practice in both critically interrogating and intervening into the consequences of algorithmic systems. By forward engineering algorithmic frames, we demonstrate how the design requirements of algorithmic systems inform processes of designing them to certain ends, with particular consequences. This presents an opportunity to develop critical algorithm pedagogies that begin from algorithm design problems to teach about how algorithm design solutions respond to these problems and what kinds of flexibility developers have (and don't have) in negotiating them. Such pedagogies can accordingly draw from existing research and literature to address how certain discourses, values, practices, and available technologies inform the design of algorithmic frames in the first place. In the case of law enforcement data analysis, we must go beyond algorithm logic to ask why law enforcement presupposes certain problems for algorithms to solve, as well as how algorithms are designed not only to solve but also to justify these problems and their appeals to criminological theories like broken windows theory.
By laying this critical foundation, future research can better account for how modifying design problems, constraints, and objectives enables the production of alternative algorithmic systems. This is to investigate how changing algorithmic frames changes the kinds of algorithmic systems that result. In doing so, we can address the broader social and political systems that either support or preclude these changes to algorithm design constraints. What remains to be investigated to this end is how the process of specifying algorithm design constraints can be rendered more intelligibly and made more fundamentally participatory. This would be to provide for a space in which students and individuals affected by algorithmic systems can identify the conditions of production that beget algorithmic systems, extrapolate the consequences of these conditions, and devise constructive alternatives. As opposed to correcting for algorithmic bias and opacity, altogether at the discretion of algorithmic authorities, we must develop a critical literacy of the circumstances that inform the design of algorithmic systems. In doing so, we may find that the problematic implications of algorithms lie not with algorithms themselves, but with the conditions that motivate their design and deployment.
Footnotes
Acknowledgements
This research was inspired by the ongoing work at the Stop LAPD Spying Coalition. In addition to endeavoring to access, analyze, and publish documentation of algorithmic systems developed for the Los Angeles Police Department, members of the Stop LAPD Spying Coalition have invested their time, attention, and care into developing a critical understanding of algorithmic systems through facilitating conversations with Los Angeles communities and providing a space for me to publicly present my research. I would also like to thank Juan De la Hoz for listening to these ideas in their formative stages and asking for insightful points of clarification. Lastly I would like to thank my doctoral program supervisor Dr. Leah Lievrouw for her ongoing support in enabling me to pursue research projects that are practice-driven and informed by engagements with extra-academic audiences.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was supported by funding from the Graduate Summer Research Mentorship Award at the University of California Los Angeles.