
Abstract
Archiving data is a crucial practice, as it ensures reproducibility of research and aligns with the FAIR principles (Findable, Accessible, Interoperable, and Reusable). To facilitate data sharing, it is essential to understand the legal conditions, especially in the form of policies, at the time of data collection. However, these policies can be difficult to locate, change over time, and may even disappear as new policies are introduced. Terms of Service are a common form of such policies. With the growing use of Twitter/X data in the social sciences, and the restriction of access to the data by the platform itself, investigating ways of sharing of this data has become even more important, and having Terms of Service at hand to check the legal conditions at the time of data collection is a crucial task. To illustrate this use case, we compiled a complete collection of Twitter/X's conditions for sharing data from 2006 until 2023. Using both qualitative and quantitative approaches, we analyse how data sharing conditions have changed. We find that while the Terms of Service become increasingly longer and more complicated, their restrictiveness varies over time. However, our analysis further shows that sharing of full tweet objects both in retrospect and in the future is not usually covered and thus affecting the reproducibility of research as rehydration of tweets is no longer feasible.
Introduction
In 2006, Twitter introduced its Application Programming Interface (API) to facilitate programmatic interaction with Twitter content for developers. This also provided researchers with easier access to full-text tweets and adjacent metadata (see Pfeffer et al., 2018, 2023, on different APIs for Twitter/X data access). While the initial interest in Twitter data came from the fields of computational or data science, recent years have seen a rapid growth in the use of this data for the analysis of trends, behaviours, and interactions within societies in social science research. Preserving tweets fosters transparency and accountability, also providing a valuable resource for journalists and the general public. Additionally, the development of the platform and its content itself may become a valuable topic of sociological research.
However, from the outset, both researchers and archives have faced legal hurdles and uncertainties when collecting, analysing, and sharing Twitter/X data, which persist until today. On the one hand, the relationship between (social media) companies and researchers is governed by laws such as data protection acts. On the other hand, social media platforms’ Terms of Service (ToS) play a crucial role in shaping this relationship. We address this issue in three ways. First, we discuss how social media companies’ (in this case Twitter/X's) practices to restrict free access to their data may impact the FAIRness and the reproducibility of academic research. In this context, we describe the (legal) challenges researchers and archives face in making collected social media data accessible. Second, we give a short overview of changes in the practices of sharing Twitter/X data over the past 15 years. The final and most extensive focus is on the introduction of a comprehensive collection of Twitter/X's conditions for sharing Twitter/X data from 2006 to 2023. Using different methodological approaches, we analyse how these conditions have changed and how this results in different levels of restrictions put on researchers. Based on these insights, we use an example scenario to illustrate how the legal situation of researchers seeking to share a specific Twitter/X dataset has changed over time.
Twitter/X research in the social sciences
A 2020 bibliometric study of Twitter-related academic papers identified over 19,000 papers published between 2006 and April 2020, with the most relevant sources stemming from communication and computer science, followed by (albeit with some distance) social sciences and informational science sources (Yu and Muñoz-Justicia, 2020: 7). The top 40 topics identified by Karami et al.'s (Karami et al., 2020: 67703) automated analysis of more than 18,000 publication and conference abstracts published in the same time span include a considerable number of topics relevant to research in the social, political and economic sciences. 1 In their analysis of a random sample of 75 out of 1644 sociology-indexed journals, Murthy (2024: 179) identified seven predominant subject areas, with the topics ‘social movements, politics, policy, and activism (44 articles)’ and ‘health (27 articles)’ at the top of that list. The large amount of current data helps in understanding public opinion, social movements, cultural shifts, and the impact of events on different communities (e.g. the COVID-19 pandemic), such as studying attitudes, election behaviour, and online effects of filter bubbles and echo chambers (Dimitrov, 2023).
Tweets by public figures, government agencies and organizations have taken a prominent role in this regard. Official statements made on Twitter/X during crises can be relevant for studying decision-making processes and communication strategies. Politicians use Twitter/X to amplify their partisan message, but some also use it as a substitute channel to circumvent party constraints (Castanho Silva and Proksch, 2022). Others respond to important events such as large protests that are not discussed in channels like parliamentary debates (Schürmann et al., 2025). Unlike newspapers, social media make it possible to publish content (seemingly) without the interference of gatekeepers (Stier et al., 2018), and digital platforms like Twitter/X have thus increased the capacity of various kinds of actors to shape the political agenda (Gilardi et al., 2022). In such settings, policy or business decisions affecting the platform itself can have a significant and lasting effect, as illustrated by Elon Musk's acquisition of Twitter: ‘Elon Musk's transformation of Twitter into X has been coupled with increased polarization, higher levels of disinformation, and issues of information integrity more broadly’ (Murthy, 2024: 183).
While the studies cited above show that social media data and specifically Twitter/X data have a huge potential for studying all kinds of human behaviour, they carry a significant risk for biases and methodological pitfalls. These may result, among other things, from issues with the validity and representativeness of the data as well as from methodological design choices. Tufekci (2014: 506) argues that the ‘preponderance of Twitter studies is mostly due to availability of data, tools and ease of analysis. Very large data sets, millions or billions of points, are available from this source’. In particular, the representativeness of the data must always be discussed: on the one hand, this is the case when conclusions about the entire population are drawn from the Twitter/X population. On the other hand, several studies have shown that the use of different APIs and collection techniques can influence the representativeness and accuracy of the data (Salvatore et al., 2021).
Reproducibility of social media research and the (Findable, Accessible, Interoperable, and Reusable) FAIR criteria
A movement parallel to the rise of Twitter/X research has been the push for Open Science and more open data in general. Fuelled by what came to be termed the ‘replication crisis’ (see e.g. Freese and Peterson, 2017; Frias-Navarro et al., 2020), the call for openness is often expressed as a call for making data ‘FAIR’ (Wilkinson et al., 2016). The FAIR principles specify that data should be Findable, Accessible, Interoperable, and Reusable. ‘Findable’ refers to readily discovering the metadata and data, typically with a unique identifier. ‘Accessible’ means data are retrievable via an open and accessible protocol. ‘Interoperable’ means the (meta)data can be exchanged. And finally, ‘Reusable’ includes features such as a detailed description and provenance. These calls for open and FAIR data militate toward more formal data sharing, often via data archives and repositories.
There are numerous arguments as to why archiving any research data is valuable. In scientific research, the ability to replicate and reproduce studies is crucial for validating findings. Sharing data enables other researchers to replicate studies, reproduce and verify results, and build on existing research (see Breuer and Haim, 2024, for a definition of replication and related terms). This transparency fosters more robust and reliable scientific knowledge. Furthermore, it saves time and resources, as often more than one research question can be answered with the same dataset. Thus, in the case of Twitter/X and similar platforms, shared datasets enable faster research and reduce the computing power needed for scraping and pre-processing. Data archives that have a long history of curating traditional forms of social science data, such as surveys, now recognize the importance and value of new forms of data, like Twitter/X, and their preservation (Dimitrov, 2023; Hemphill et al., 2021). However, they depend on both researchers being willing to share data as well as social media companies to allow access to their data. The latter is ultimately under the companies’ control, both in the technical and in the legal sense. In consequence, the ability to replicate research findings based on data from social media platforms depends on the regulatory and technological frameworks implemented by the respective companies.
Twitter/X was exceptional in permitting API access to its data. However, this changed in 2023 when API access became paid only, which endangered or ended 60% of research projects in progress at that time, according to a recent survey (Brown et al., 2023). This change in access ushered in a new era for researchers that some started to call the ‘Post-API age’ (Tromble, 2021), where API access to new data is often no longer possible, and published datasets containing only IDs representing Twitter/X content – making up 66% of the analysed DataCite-registered datasets – are practically rendered useless for most purposes. However, even before the changes in API-access, the replication and reproduction of results were compromised by the intransparency of sampling strategies employed by the different APIs (Assenmacher et al., 2022; Pfeffer et al., 2023) as well as by ‘tweet mortality’. The latter refers to the removal of posts and accounts from the platform, for example, for violating the Terms of Use or simply because users decided to remove content themselves. It is here that Twitter/X regulations for sharing data come into play, as these mostly allow for the sharing of post and user account IDs, then to be ‘rehydrated’ again via one of the available APIs in a process which downloads all posts or profiles still available on the platform.
It is important to note that the restriction of data access is not necessarily an intentional act to prevent research, and users can have many reasons for wanting to exercise control over their data (Puschmann and Burgess, 2013). However, Fiesler and Proferes (2018) find in a survey that ‘few users were previously aware that their public tweets could be used by researchers, and the majority felt that researchers should not be able to use tweets without consent’. While the practice of sharing IDs rather than full posts is an important means to protect both users and the commercial interests of Twitter/X, ensuring that content which is removed is no longer accessible to third parties, the resulting mortality of posts and accounts is at odds with the scientific principle of reproducibility. The issue particularly affects data collected with a focus on ‘harmful’ content such as hate speech. As Mamo et al. (2023: 08) observe, ‘tweet datasets self-sanitize’ as ‘harmful tweets, noise and spam’ are removed. Küpfer (2024: 493) points out that such ‘nonrandom removal patterns’ disproportionately affect disciplines such as political science, which often focus on sensitive subjects affected by removal of content, which may lead to significantly different findings in attempted reproduction (Knöpfle and Schatto-Eckrodt, 2024; Küpfer, 2024).
The Twitter/X regulations for sharing platform content, therefore, pose a dilemma for researchers and data archives. First, the suspension of free access to the Twitter/X API means that published research results can no longer be reproduced without substantial financial commitment (before even considering the added problems stemming from tweet/post mortality). Data reuse, too, is out of the question. Second, a considerable number of datasets with full tweet objects exists in public repositories, which most likely do not meet the requirements of the Twitter/X regulations. For example, because they were published without permission from Twitter/X or exceed the number of tweet objects permitted to be shared per user per day. Furthermore, they cannot satisfy Twitter/X's requirement that the published datasets may only contain content that was not deleted from the platform as stipulated in the company's terms. This extends to researchers who now ponder publishing full tweet objects collected in the past and have to take changed API accessibility into account. This illustrates the key role of the legal conditions under which data are collected.
A legal assessment of collecting social media data
Researchers can access social media data using screen or web scraping techniques, or they use an API, which usually entails agreeing to ToS. Many companies try to prevent researchers from simply scraping content off their websites. The terms ‘web scraping’ and ‘screen scraping’ are sometimes used interchangeably, despite several differences (Dogucu and Çetinkaya-Rundel, 2021; Mitchell, 2024; Naumann, 2009; Stanley, n.d.). From a legal perspective, a key aspect concerning the practice of scraping is that visiting a website does not normally entail an act of active agreement, like clicking a checkbox, to ToS or other rules, even though companies often claim otherwise (Luscombe et al., 2022). Accordingly, several high-level court cases ruled that the re-use of data visible on-screen was legal. For example, in the United States, the Court of Appeals for the Ninth Circuit ruled in 2022 that scraping was legal in the case of hiQ Labs, Inc. versus LinkedIn Corp, deciding in favour of hiQ who had accessed information about the LinkedIn users from behind the platform's login. In Europe, a similar decision was reached in 2015 by the Court of Justice of the European Union in the case of Ryanair versus PR Aviation BV. PR Aviation BV had scraped flight information of the airlines to include them in a service portal. The CJEU rejected Ryanair's claim that the company held copyright to the data (Fontana, 2025: 201–203).
However, these rulings do not imply that screen or web scraping is legal per se. While scraping itself is not necessarily illegal in the United States or the European Union, the scraped content might be copyright protected, might contain personal data, or the scraping activities could technically impair the scraped web services. In these cases, copyright acts, data protection regulations, or criminal laws apply. These laws might exist on different administrative levels, like the California Consumer Privacy Act (CCPA) on the state level in the US, or the GDPR on a supranational level with national extensions in the European Union. 2 Remaining legal voids are then filled by court cases like the ones mentioned above, which tackle individual aspects of scraping.
The EU directive on copyright and related rights in the digital single market
In light of these uncertainties, the European Union passed Directive 2019/790 on copyright and related rights in the Digital Single Market (CDSM) (Rosati, 2018). The CDSM was intended to harmonize the legal situation of scraping and to come up with a basis for what is called ‘text and data mining’ (TDM). Article 2 no. 2 of the CDSM defines TDM as ‘any automated analytical technique aimed at analysing text and data in digital form in order to generate information which includes but is not limited to patterns, trends and correlations’. This is seen by some as an ‘overly broad definition’, because the directive not only regulates TDM itself ‘but all forms of modern data-driven digital analytics that rely on “training”’ (Margoni and Kretschmer, 2022: 686). The CDSM also defines and includes two areas of application for TDM: in scientific research (Art. 3) and by the general public (Art. 4), including private companies.
A challenge in applying the CDSM is that it needs to be transposed into national laws. This process provides EU member states with the opportunity to keep national regulations if they do not contradict the directive. Since some of the members only transposed the directive in 2023 or 2024, there is no general overview of the TDM regulations in all jurisdictions. André (2023) offers an overview of the transposition results in France, Germany, Ireland, the Netherlands, and Spain. Each of these countries had transposed the directive by 2022, but the resulting legislation has notable differences. For example, while the CDSM only talks about TDM for the purposes of scientific research by research organisations and cultural heritage institutions, Germany also includes individual researchers, and Ireland even extends it to members of the general public if they undertake research. Furthermore, elements covered in the CDSM for TDM include ‘works and other subject matter’. This is interpreted to mean ‘digital works’ in France, ‘digital and digitized works’ in Germany, and ‘works of literature, science or art’ in the Netherlands. A third area of differences emerges concerning rights holders’ right to object to TDM for scientific purposes. The CDSM does not provide for this kind of objection, and all countries but Spain follow that lead. The Spanish legislation does not distinguish between scientific and general TDM and thus seems to open a door for objecting to any type of mining, including for purposes of research. This short overview shows that the idea of one cross-national legal basis for TDM, at least in the EU, has failed so far. It remains to be seen if and how, for example, courts tackle this heterogeneity in cases of dispute.
In Germany, the CSDM was transposed into the German Copyright Act (UrhG 1965, 2021). Here, scraping is explicitly permitted and, in accordance with the CDSM, the act allows for the ‘reproduction’ of scraped information (in the sense of making copies available) via libraries and archives. In the German legal interpretation, screen scraping does not depend on or constitute a contractual agreement with the website provider (Vogel and Hilgendorf, 2020). This is an important detail when it comes to companies pointing to their ToS as binding agreements. Nonetheless, data protection, copyright and other laws may apply.
API-access and ToS: Challenges and consequences for research
The situation of researchers changes the moment they use an API to access web data rather than applying TDM techniques, as this usually entails actively agreeing to ToS. ToS are the legal terms that set forth the nature, scope, and limits of a service and the rules that the service's users must agree to follow (Merriam-Webster Dictionary, n.d.). A legally binding contract is only closed by means of pro-active consent, such as clicking a checkbox on a website (‘click wrap’), thus signalling agreement. In this case, the agreeing party becomes subject to the contractual conditions (Brehm and Lee, 2015; Vogel and Hilgendorf, 2020). Researchers collecting data by API might enter into such a contract, and if they do, the platform ToS may have an impact on the use and re-use of the data. This is the first challenge when facing ToS.
A second challenge is the findability and comprehensibility of platforms’ ToS. While, for example, German law obliges companies in Germany to have one single set of ToS (‘Allgemeine Geschäftsbedingungen’ or ‘AGB’), visible and without hidden conditions, social media platforms often present users – and thus also researchers – with multiple interrelated documents. Venturini et al. (2016), for example, found an average of five such documents when looking at various platforms. In the case of Twitter/X, these terms were laid out in different types of documents over time (see Table 1). Initially, all conditions for the (re-)use of Twitter content were contained in the platform's ToS. Between 2010 and 2014, the API terms covered the redistribution of tweets. From 2014 onward, conditions for tweet redistribution were laid down in the Twitter/X Developer Policy. The Developer Policies are incorporated into the respective Developer Agreement, along with, for example, the Twitter Rules and the API Restricted Use Rules.
Twitter/X terms and time span in effect.

ToS: Terms of Service; API: application programming interface.
Onward sharing and archiving of the data are regulated by the conditions that researchers agreed to when the data were collected. Thus, if the ToS or Developer Terms changed subsequently to the data collection and the researchers did not agree to those changes, it is possible that the initial contractual conditions for the individual project have not changed. However, this has up until now never been decided in court, adding to the insecurity around publishing full-text tweets. In the case of longitudinal data, multiple legal conditions may apply. Both the researcher collecting the data and any repository accepting the data must have all this information. Therefore, a third challenge lies in changes to the ToS over time. In the case of Twitter/X older records like the ToS or the Developer Policies are not easy to find. Typically, when new terms come into effect, they simply replace the older terms, which are removed. If a researcher did not save the terms that were in place when they collected the data, this can lead to a situation of legal uncertainty that most of the time results in data not being shared and thus research results not being reproducible.
Several disputes between Twitter and large-scale users of tweet data show that the company regularly reacted to such conflicts by restricting access to its data rather than settling access or re-distribution in court. One example is Twitter's confrontation with the British company DataSift over the commercial use of tweets in 2015. The company accessed tweets via Twitter's so-called ‘fire hose’ API to perform real-time social media analyses for third parties. Twitter announced that it would discontinue direct access to its data via third-party APIs, including for companies such as DataSift, after settling a dispute with this company outside of court. Future access was thus only to be provided via Twitter itself or via its new partner Gnip (Lunden, 2015). In 2016, the collection and misuse of large amounts of social media data by the British company Cambridge Analytica Ltd also led to stricter guidelines for the use of Twitter's API and data access. There was no court case that followed the Cambridge Analytica scandal (Mak, 2018) either. Clearview AI is a third example of a company violating Twitter's ToS. Twitter approached Clearview AI with a cease-and-desist letter for unlawful scraping in 2020. Again, there was no legal dispute in court, but the result of an out-of-court settlement was that Clearview had to cease its scraping activities ( The New York Times (online), 2020 ).
A final issue is the possible violation of laws by making full-text tweets or similar platform content available. As mentioned earlier, even if the act of scraping is considered legal, data protection, copyright, and other laws may still apply. For example, in 2022, the Belgian Data Protection Authority (DPA) fined the Non-Governmental Organisation EU DesinfoLab for violating the General Data Protection Regulation (GDPR). EU Desinfolab had conducted a study of Twitter messages data from 55,000 Twitter accounts concerning the so-called Benalla affair and had to pay EUR 2,700, because the Belgian DPA argued that publicly available personal data also falls within the scope of the GDPR (Foitzik, 2022). The above examples of legal issues involving tweets show that a certain risk is associated with the publication of full-text tweets.
Current data sharing practices
After describing the impact of ToS on data sharing from a theoretical perspective, we look at how Twitter data is shared by researchers in practice. A request to the DataCite API on 7 February 2025, to identify registered datasets with ‘Twitter’ OR ‘Tweet’ OR ‘Tweets’ in the title AND the description returned about 4000 records with publication dates from 2011 to 2024. 3 While this number suggests a stark mismatch when compared with the number of Twitter/X-related publications identified by Karami et al. (2020) and Yu and Muñoz-Justicia (2020), further research into the data availability of published Twitter/X research is necessary. Approximately half of the DataCite-registered datasets were published from 2021 to 2024 (see Figure 1). Most of the datasets were published via one of 10 data sharing platforms (see Table 2). As Table 2 suggests, most datasets reside in repositories without a specific disciplinary or institutional focus, which allow for immediate publication of data without further review. In addition, one discipline-specific, one institutional, one publisher-specific and one national repository are present in the list. Furthermore, SOMAR – ICPSR's social media archive – has been available for archiving and sharing social media data since 2023. 4

Twitter datasets registered via DataCite, 2011–2024.
Top publishers of Twitter/X-related datasets (Source: DataCite).
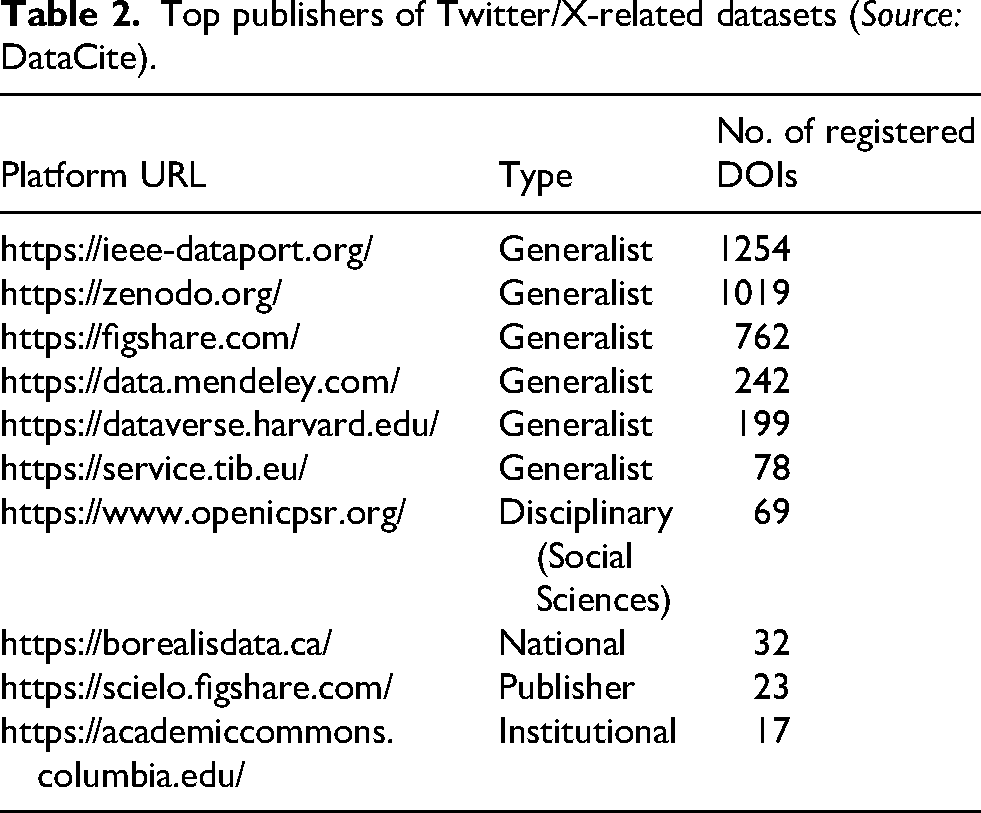
Based on the descriptions of the records harvested via the DataCite API, we were able to determine that two-thirds of the datasets contained only tweet IDs, whereas 17.5% included full tweet objects/posts. For the remaining records, the descriptions gave no indication of the kind of Twitter/X content published (Figure 1). This shows a clear tendency towards publishing only IDs. Of those datasets which published full objects, over 60 published more than 1,000,000 objects, with the largest published dataset of full tweets comprising 600 million objects and the largest dataset of published tweet IDs, including 1.5 billion IDs. An analysis of the subjects named in the metadata for each registered DOI shows that the 2020 spike in published datasets appears to be due to the significant number of COVID-19-related datasets. 5 However, it cannot be deduced from the data whether this increase is due primarily to a particular interest in this type of data, for example, to research topics such as the spread of misinformation during the pandemic, or to the reduced availability of other data, such as in-person interviews.
A corpus of Twitter/X's developer agreements and policies
Because an archive of former Twitter/X API Terms and Developer Policies is no longer available from the X website, we utilized the Internet Archive's Wayback Machine (https://web.archive.org/), a digital archive of over 866 billion web page snapshots covering more than 28 years, to collect the different versions of the documents relevant to harvesting and redistributing tweets since 2006. Entering a URL into the Wayback Machine will return complete snapshots taken of the respective page. These snapshots consist of the original HTML, including media, hyperlinks, and scripts. Site-internal hyperlinks are replaced with links to appropriate snapshots in the Wayback Machine. In addition to the captured original page content, each snapshot may contain additional scripts by the Wayback Machine.
To identify past versions of the documents with conditions for tweet redistribution, we began by checking the URLs for the Developer Agreements and Developer Policy in effect at the time of data collection (May–August 2024) in the Wayback Machine and browsed the results across the years. Using the ‘Last updated’ statement on the websites, we identified the different versions of these documents. In this manner, we were able to identify all Developer Terms versions between 2017 and today. To find earlier versions of relevant conditions, we then checked older snapshots of the Twitter website to identify relevant documents and their URLs. A limitation of the collection method is that snapshots of the relevant pages were not necessarily taken on the day of an update. Especially for early versions of the website, only a few snapshots are available. Therefore, it may be possible that changes that were only online for a short time were thus not recorded in the archive and could not be included in our dataset.
For each relevant document version discovered in this manner, we downloaded the HTML snapshot page using Python (see Methods Report for further details). The data publication consists of the .html files of the Wayback Machine snapshots, a CSV documenting information about each file, and an RDS corpus for computational analysis of the documents. In addition, the Python code used to download and prepare the .html files, as well as the R code to create the corpus from these files, are also published (Golland et al., 2025). To ensure the accuracy of our findings, we conducted a thorough re-examination of our HTML files. This included cross-checking our collection against versions listed in page archives where available, verifying the date of the policy, and the date of the website snapshot. Additionally, we reviewed other snapshots from the period when the policy was active to confirm the correctness of the snapshot. For Twitter/X ToS, an archive is still available on the X website (https://x.com/en/tos/previous). In the past, an archive of the API Terms existed (https://web.archive.org/web/20140423083640/https:/dev.twitter.com/terms/api-terms/archive), but it is no longer available on the X website. For both the API Terms and the ToS, we discovered more versions than those listed in the respective Twitter/X archive. This suggests that our collection possibly includes all main versions of the respective terms. For the more recent Developer Agreements, no such archive is available.
While the use of Twitter/X may be declining relative to other platforms such as TikTok, preserving a copy of the ToS that one has agreed to in the process of a research project is an important task regardless of the platform concerned. Using the current collection of documents, researchers who collected Twitter/X data at any time can access the ToS and Developer Terms that were likely in place during their project. However, the present collection does not claim completeness, and the authors assume no liability for the correctness of the terms, which were collected to the best of our abilities. We consider this dataset a starting point for similar data collections for scientifically relevant social media, intended to assist both researchers and archives in assessing the legal status of data collected from such platforms. While we consider this main benefit of the collection of ToS we present here, the collected documents can also be understood as text data in a narrower sense. To demonstrate the potential for analysis of such a collection, we apply qualitative and quantitative text analysis methods to analyse the changes of the ToS under investigation over time.
Quantitative text analysis of ToS documents
Various straightforward quantitative text analysis algorithms can be used to get an overview of the text corpus, gain an understanding of the dynamics over time and obtain clues for answering initial research questions. The change of document length over time is a first indicator to get an overview of the documents. Figure 2 shows that the document length (measured as the number of characters per document) has changed considerably over time. While the first documents contained only around 1000 words, this number has grown to over 12,000 words in the latest version contained in our dataset. Since studies find information overload as a significant negative predictor of reading ToS, this development can be interpreted as a decrease in the probability that these documents are or were read (Obar and Oeldorf-Hirsch, 2020). Assuming the average reading speed of an adult, reading the latest document would take about 45 min. The probability that the documents are completely read and understood decreases even further when looking at the change in readability. Using the common Flesch readability score (Flesch, 1948), Figure 3 shows that the average readability of the documents decreases and that all documents in the corpus rank between ‘difficult to read’ and ‘extremely difficult to read’.

Changes in document length.

Changes in readability.
A further insightful measure is the extent of document editing from version to version. By analysing the text similarity of a document with its previous version, it is possible to show how much text was changed beyond differences in length. Looking at the three groups of documents separately, the text data reveal an interesting pattern (see Figure 4). Most of the changes that were made affected only small parts of the documents. In most cases, over 90% previous documents were reused. However, there were always more radical changes to the documents across longer intervals. In future analyses, other indicators that could be used include sentiment analysis as well as topic model approaches. Our quantitative text analysis so far reveals that document length has increased while readability has decreased over time, leading to information overload and decreased reading comprehension. Despite minimal changes in most documents, larger revisions occurred across longer intervals.

Changes in text similarity.
Qualitative analysis of regulation changes
As the ToS evolved, regulations as to which Twitter/X content could be redistributed changed as well. While the quantitative analyses above are informative, they do not reveal the full picture of changes affecting what could be shared and for which purposes. Thus, in the following, we outline key qualitative parameters that changed based on the analysis of those passages in the Terms of Use, API Terms and Developer Policy, which directly referred to the redistribution of Twitter content.
Initially, Twitter operated with a very short set of ‘Terms of Service’ (see Figure 2). The focus was mainly on the platform users and the rules and conditions under which they could use Twitter. From 2006 to 2009, the ToS explicitly encouraged sharing of Twitter content on ‘outside websites’ under the condition that a link back to Twitter was provided. In 2009, with version 3 6 of the ToS, the condition was introduced that ‘you have to use the Twitter API if you want to reproduce, modify, create derivative works, distribute, sell, transfer, publicly display, publicly perform, transmit, or otherwise use the Content or Services’ (Twitter, 2009). For the first time, this version of the ToS contained a cross-reference to the evolving API rules. In addition, ‘crawling the Services’ was permitted as long as ‘in accordance with the provisions of the robots.txt file’, whereas ‘scraping the Services without the prior consent of Twitter [was] expressly prohibited’ (Twitter, 2009). A distinction of the terms ‘crawling’ versus ‘scraping’ was not provided as far as we were able to determine.
From 2010 on, the Terms of Use and the API Terms existed as separate documents, with the latter targeted at developers (see van der Mersch, 2016, for context). Accordingly, the API Terms had a strong focus on the conditions for applications that interacted with Twitter (e.g. by posting on behalf of users), or which could be used to display or embed Twitter content, for example, on websites (e.g. Twitter feed plugins or widgets). The API Terms centred on permitted means of sharing Twitter content and services for interaction and display, and on preventing competitors from recreating the ‘Twitter experience’. Thus, while there now was a restriction on distributing Twitter content, it was limited to sharing ‘to any third party for such party to develop additional products or services without prior written approval from Twitter’ (Twitter, 2010: I 4a, our emphasis). This scenario, just like the Terms in general, was not well-applicable to research scenarios involving the permanent storage of Twitter platform content and its sharing with third parties.
In 2011, version 7 of the API Terms abandoned the previous language and stated that the redistribution of Twitter content to third parties without permission was forbidden – regardless of the purpose. It is from that moment on that all sharing of Twitter content was possible only based on stated exceptions to this default rule. This entailed that any third-party APIs returning Twitter data were only allowed to return IDs (for tweets, users, and messages) and that sharing full Twitter content was only permitted in the form of a PDF or a spreadsheet, for example, providing a ‘save as’ functionality. Export of Twitter content to a ‘datastore as a service’ or ‘other cloud based’ service was explicitly forbidden (Twitter, 2011: I 4A). While again it is not clear what services this entails, it could well include the storage of Twitter content in repositories or data archives.
Two years later, in 2013, version 13 of the API Terms mentions the provision of ‘downloadable datasets of Content’ (Twitter, 2013: I 4A). For the first time, the possibility to provide IDs for download is not only associated with offering an API but extended to other forms of redistribution: ‘If you provide downloadable datasets of Twitter Content or an API that returns Twitter Content, you may only return IDs (including tweet IDs and user IDs)’ (emphasis ours). At the same time, a limit is imposed for the export of Twitter content via ‘non-programmatic means’: ‘You may provide spreadsheet or PDF files or other export functionality […] for up to 100,000 public Tweets and/or User Objects per user per day’. An export of Twitter content to datastores or cloud-based services is still not permitted (Twitter, 2013: I 4A). The latter sentence was removed in 2014 when the second version of the Developer Policy came into effect. 7 At the same time, the limit to sharing full tweet objects was halved to 50,000 objects per user per day and a clause was added stating that ‘Any Content provided to third parties via non-automated file download remains subject to this Policy’ (Twitter, 2014b: I, 6b).
In June 2017, version 8 of the Developer Policy for the first time issues a restriction on the number of IDs that may be shared. It states: ‘You may not distribute more than 1,500,000 tweet IDs to any entity (inclusive of multiple individual users associated with a single entity) within any given 30 day period, without the express written permission of Twitter’ (Twitter, 2017a: I, F 2b). This suggests that individual users belonging, for example, to the same organization, may not download more than 1.5 million tweets between them in the 30-day period. The Policy also states that ‘You may not distribute tweet IDs for the purposes of (a) enabling any entity to store and analyse tweets for a period exceeding 30 days without the express written permission of Twitter’ (Twitter, 2017a: I, F 2b). This can be interpreted as a requirement to delete tweet IDs obtained from a third party after 30 days. Three months later, in September 2017, version 9 of the Developer Policy for the first time introduced an exception for academic and non-commercial research. For either the tweet ID limit and the adherence to the 30 days maximum storage period were removed (Twitter, 2017b: I, F 2.2). This exception remained valid until 2023 and version 15 of the Developer Policy, shortly after Twitter's rebranding as X.
Version 15 of the Policy maintains the 1.5 million IDs per month per entity rule but drastically lowers the number of full objects sharable to 500 per user per day. It includes an exception for academic research, but the sentence on academic non-commercial research is difficult to interpret due to its convoluted syntax: ‘Academic researchers are permitted to distribute Post IDs and/or User IDs solely for the purposes of non-commercial research on behalf of an academic institution, and that has been approved by X in writing, or peer review or validation of such research’ (X, 2023: ‘Content redistribution’). The Policy seems to state that IDs can be shared if the research was approved by Twitter or for the purpose of peer review or replication, but it is far from unequivocal. 8 Table 3 summarizes the developments outlined above. This suggests that many published Twitter/X datasets – especially those sharing more than 50,000 full tweet objects or 1.5 million tweet IDs – may not comply with the Twitter/X terms and policies. 9 The following fictional scenario further illustrates the regulations and their consequences for sharing content from Twitter/X.
Summary of regulations for archiving and sharing Twitter/X content.

Let us imagine, that researchers collect 1.5 million tweets via the Twitter API between 1 October 2013 and 28 February 2014, to study the use of health-related hashtags. They repeat the collection one year later, from October 2014 to February 2015, collecting an additional 1 million tweets from the API using the same query. In summer 2015 they submit a research paper based on the tweets to a journal, which asks them to (a) provide the corpus to the reviewers for peer review and to (b) publish it for replication purposes along with the article. What can be shared and how is governed by the regulations in place when the Twitter content was collected. The 2013 collection falls into a period where unlimited IDs and up to 100,000 tweets were allowed to be shared, but where no Twitter content could be exported to cloud-based storage. In consequence:
The researchers are allowed to share the tweet IDs for rehydration with the reviewers or provide them with packages of 100,000 full tweets over a period of 15 days. Publishing the collected content via a repository is likely not possible due to the restriction on cloud-based storage. Whether publishing the content as an appendix to the article on the journal website would be a solution to this problem would require further legal assessment.
The second set of tweets collected falls within a period where the storage of Twitter content in cloud-based services was permitted and where unlimited tweet IDs as well as 50,000 full tweet objects could be shared per user per day. Therefore:
The researchers can share this collection with reviewers in the form of tweet IDs for rehydration or as packages of 50,000 tweets each over 20 days. Publication of the tweet IDs via a repository is permitted.
This would have applied to all Twitter content collected up until October 2023 due to the provisions for academic, non-commercial research. Had the data been collected between October 2023 and February 2024, however, only the October 2023 data would fall under this exception. All data collected from November 2023 onwards fall under the new X regulations for academic, non-commercial research. No significant number of full tweet objects can be shared with reviewers anymore. While it is possible to share tweet IDs as needed, this practice is no longer feasible due to the cost associated with rehydrating the IDs.
A measure of restrictiveness
Another approach to analysing the Twitter/X terms is to look for a measure of restrictiveness. We analysed the overall open- or restrictiveness of the passages chosen for analysis. For this we considered not only the number of objects allowed to be redistributed to third parties, but also restrictions or exceptions made in the following dimensions: technology (e.g. mandatory use of the API or permission to redistribute content only in a specific format), time (e.g. redistribution of a given number of objects per user per day, or in a 30-day period), purpose of use (e.g. for non-commercial academic research only), object type (tweet IDs or full tweet objects), and permission (possibility to ask Twitter/X for permission to redistribute platform content in ways not standardly permitted by the terms/policies).
To make these comparable across the different terms and policies, we assigned a restrictiveness score according to the following rules: Each relevant passage was assigned a score reflecting the open- or restrictiveness of the default. A higher score indicates more restrictiveness, with a score of 100 indicating that no redistribution whatsoever is allowed. For example, in versions 1 and 2 of the Terms of Use, the default was ‘sharing is allowed and encouraged’, resulting in a default score of 0 (no restrictions). Beginning with the API Terms v1, the default became more restrictive, adding more conditions and limitations to redistributing content to third parties – for example, by disallowing the redistribution of content to third parties for the development of products or services without written permission from Twitter/X. For each exception to the default described in the relevant passage, points were added or subtracted from the default score, depending on whether they enabled more or less redistribution. 10 The resulting scores are shown in Figure 5. The figure shows that the fewest restrictions were made between 2006 and 2009 (ToS) and between 2014 and 2017 (Developer Policy). The API Terms, in particular, were very restrictive regarding the redistribution of platform content.

Restrictiveness of redistribution regulations in ToS, API Terms, and Developer Policies.
Discussion
Our analysis of the Twitter/X ToS shows that sharing full tweet objects, whether collected in the past or recently, is largely not covered by past or current ToS. Consequently, there is no conclusive solution to making full-text tweets collected in projects accessible for reuse by other researchers yet. This result highlights that calls for open data and the FAIRness of research can only work when possible legal constraints are considered and resolved. This might be impossible in a case like Twitter, as the case of the Library of Congress shows. In 2017, the Library had to back away from its plan to make public tweets from the time between 2006 and 2017 available for re-use due to unresolved legal issues and technical difficulties (Osterberg, 2017). The current situation can only be resolved by legislative changes to overrule ToS in clearly defined cases and considering user rights to the protection of their data and intellectual property, as in the case of the Digital Services Act (European Parliament and the Council of the European Union, 2022). But the time it takes to install such regulations is time lost for research, for example, on current societal issues. Given the fact that API access for rehydration of tweets is no longer feasible due to high cost, researchers, academic publishers, and repositories are now faced with a situation in which it may no longer be possible to ensure reproducibility of research based on Twitter/X data. How should we respond to this situation?
Organizations running repositories – including the ones listed in Table 2 – should accept more responsibility to ensure that researchers do not publish data which may be in conflict with social media platform ToS or infringe on the platform users’ rights. In their own ToS, repositories usually shift all liability for the violation of third-party rights onto the data depositors, that is, the researchers. Our own experience suggests, however, that researchers are often not aware of what the ToS they agreed to mean in practice. As demonstrated above regarding the Twitter/X regulations, this could be the case because the ToS language is not easily applicable to research scenarios, or because the increasing length and complexity of those terms severely limit their understandability. Considering this, repositories should take more responsibility in educating researchers. At the same time, we recommend that they develop strategies and policies with the research community on how to resolve the dilemma between enabling reproducibility, compliance with platform terms, and protection of user rights to privacy and their intellectual property. These should be based on legal assessments and consider national laws and regulations potentially overriding the platform terms (e.g. in the case of Text and Data Mining following the EU CDSM directive).
Researchers working with Twitter/X and other platform data are recommended to take time to read and understand the terms and conditions they agree to when collecting data from these platforms via APIs. Often, repositories, particularly discipline-specific ones, will be happy to help if needed. In addition, researchers should consider the possibility of publishing derivatives of the full tweet objects – the options range from annotations of tweets and the frequency of certain terms, such as hashtags, to more complex text representations, such as document-feature matrices. In addition, the research community should explore possibilities of using synthetic data to address copyright and data protection concerns, as well as issues stemming from tweet mortality. 11
Conclusion
Social media data have become an important type of data for social science research on political communication, social behaviour, public opinion, agenda setting and so on. When researchers collect this kind of data, they might be restricted in their activities by legal constraints such as the social media platforms' ToS. If researchers have actively agreed to those terms, they have effectively closed a contract with the platform provider. ToS can therefore be an important impediment when it comes to using and sharing data. We present Twitter/X as an example for this use case of legal constraints and trace the development from an almost open sharing policy to very restrictive rules. The Twitter/X case also shows the conflicts that can emerge when researchers are encouraged to make data FAIR, which comes from commercial platforms and is therefore governed by ToS, and which, moreover, is collected without consent from the users. While discussions exist on the ‘FAIRification’ of sensitive data (see e.g. FAIR-Impact, 2024), these cannot resolve the methodical-ethical issues around consent.
The example of Twitter/X also exemplifies how platforms confront researchers and other users with terms that can change drastically over time. Having grown in length from less than a thousand to more than 12,000 words, the terms now also extend over several documents and have overall become less comprehensible. Court rulings and thus interpretations of the terms by judges would have the potential of shedding light on where the legal limits lie when it comes to ToS. However, Twitter/X has settled all cases outside of courts and thus has prevented judges from interpreting its rules. Finally, the company is not providing a comprehensive overview of the changes to its ToS, which makes it difficult for researchers to assess the legal situation at the time of data collection.
We therefore set up a collection of Twitter/X ToS to obtain insights into the changes of the terms and overcome the information gap when it comes to recovering the terms in place at a certain point in time. This collection covers all terms from 2006 until 2023 and was collected to the best of our abilities. The ToS also make for interesting data themselves when looking at reasons for changes. However, we only consider this collection to be a starting point. While Twitter has been an important source of data for many social sciences in the past years, it is by no means the only relevant online platform. In addition to the changing data access conditions of online platforms, the dynamic legal situation needs to be considered, which is also undergoing change, for example, in the European context, particularly as a result of the Digital Services Act (Turillazzi et al., 2023).
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.