
Abstract
The availability of big data has significantly influenced the possibilities and methodological choices for conducting large-scale behavioural and social science research. In the context of qualitative data analysis, a major challenge is that conventional methods require intensive manual labour and are often impractical to apply to large datasets. One effective way to address this issue is by integrating emerging computational methods to overcome scalability limitations. However, a critical concern for researchers is the trustworthiness of results when machine learning and natural language processing tools are used to analyse such data. We argue that confidence in the credibility and robustness of results depends on adopting a ’human-in-the-loop’ methodology that is able to provide researchers with control over the analytical process, while retaining the benefits of using machine learning and natural language processing. With this in mind, we propose a novel methodological framework for computational grounded theory that supports the analysis of large qualitative datasets, while maintaining the rigour of established grounded theory methodologies. To illustrate the framework’s value, we present the results of testing it on a dataset collected from Reddit in a study aimed at understanding tutors’ experiences in the gig economy.
Keywords
Introduction and background
Recent advances in machine learning (ML) and natural language processing (NLP) models have significantly enhanced their performance in tasks such as question-answering and text summarisation. Sometimes, these models even outperform humans (Devlin et al., 2018; He et al., 2020). This, coupled with the proliferation of big data facilitated by the widespread adoption of digital technologies, has led to an abundance of digital traces that can be collected from various sources and analysed to gain insights into human behaviour (Lazer et al., 2009; Salganik, 2019). It enables researchers to investigate new phenomena and reach a new or wider range of research subjects (Agarwal and Dhar, 2014; Johnson et al., 2019). Yet, while advanced ML and NLP are superior for some tasks, human researchers possess qualities such as socially embedded sense-making, reasoning and contextual awareness (Legg and Hutter, 2007) that isolated and individual models trained solely on tokenised input cannot fully replace. Although recent developments have improved context handling, they still fall short of capturing the nuanced understanding inherent to human cognition (Wang et al., 2024). Therefore, there is a need to combine the strengths of both so they complement one another when analysing large qualitative datasets (Herrmann, 2020; Peeters et al., 2021).
Qualitative research methods such as grounded theory (GT) (Glaser and Strauss, 1967) are widely used in the humanities and social sciences. Hand-coding is central to these methods, which involve systematic data segregation, annotation, grouping and linking. The goal is to examine unstructured text to identify patterns and acquire a thorough understanding of the data (Chen et al., 2018; Rietz and Maedche, 2020). However, since such a procedure requires considerable manual labour and hours of dedicated effort, analysing big datasets reliably can be extremely laborious, if not impossible (Crowston et al., 2012; Müller et al., 2016). To address this, some researchers use strategies such as subsampling (Attard and Coulson, 2012; Kazmer et al., 2014), but this may fail to take advantage of the richness of the full dataset as a substantial portion of it will remain unexplored (Chen et al., 2018; Jiang et al., 2021). This limitation has prompted researchers to examine ways of using computational techniques to help minimise human coding efforts. According to Baumer et al. (2017), two researchers independently applied topic modelling (TM) and GT to the same dataset and compared their results. They found that many GT codes were well-represented in TM results; however, the latter had a lower level of abstraction, comparable to middle-level GT codes. Therefore, they concluded that these approaches work most effectively when combined. Similarly, Bakharia (2019), Crowston et al. (2012) and Ruis and Lee (2021) argue that while TM may automate parts of the coding process, more work is needed to acquire a deeper qualitative insight into the social phenomena under study. The effort to achieve this has given rise to what is known as computational grounded theory (CGT). Researchers suggest it is a promising methodology, but some reservations remain (Gorra, 2019; Procter, 2022).
Several attempts have been made to develop CGT frameworks, with the most prominent being proposed by Nelson (2020) and subsequently quite widely adopted (Ojo and Rizun, 2021; Williams and Greenhalgh, 2022). The framework has three steps that start by detecting patterns in the data using structural TM (STM). The highest-weighted (top-N) terms (i.e. words) per topic are used to examine the model to determine if it produces semantically coherent topics. Then pattern refinement, where the researcher returns to the classified data to add interpretation through qualitative deep reading of the documents in each TM topic. Finally, the pattern confirmation step, which includes deciding which computational techniques are most suitable for verifying patterns found in the data against the complete dataset. Odacioglu et al. (2022) propose a four-step CGT framework, started by applying latent Dirichlet allocation (LDA) TM, followed by expert coding where topics are labelled based on associated terms and rated their relevance to the study. The researchers also engage in applying the codes and writing analytical memos. The third step, focus coding, involves understanding codes, identifying patterns and seeking similarities between them by reading the associated top-N documents. Then, after constantly comparing codes and discovering links, categories are formed. The final step is theory building, which entails aggregating core categories into one higher-level theme that forms a theory.
Mangiò et al.’s (2023) framework started with experts assigning topic labels to STM topics based on examining the top-N terms and on the qualitative interpretation of the top-N documents per topic. They further evaluated the performance of the model by having two researchers manually review a sample of documents for each topic to assess the model. Then, following extensive discussions, they grouped the topics into more comprehensive higher-level categories based on content similarity. The researchers then utilised the STM for validation that enabled them to analyse how topics changed over time and compare these changes with real-world events. Furthermore, two authors ‘internally validated’ topics by manually coding a sample of documents per topic, ensuring that the model discriminated correctly. In the final step, an interpretative GT analysis of the topics is conducted. A hand-picked sample of the most representative top-N documents is independently hand-coded in three separate stages, including coding the raw data from topics, secondly, they arrange the resulting codes from first to second-order codes, which helps to provide more theoretical insights and in the final coding step a further aggregation of concepts is identified and classified into overarching categories.
While these earlier frameworks have clearly attempted to apply GT principles when utilising text mining techniques, some have oversimplified the process by over-relying on the computational tools results for theory development. Yu’s (2019) framework is an example, which started with applying LDA and then labelling the topics based on reading the top-N terms. They viewed LDA topical terms as open coding, and LDA topic labels as axial coding. The LDAvis tool (Sievert and Shirley, 2014) was then used to visualise LDA topics and they found that topics comprised three independent areas based on the topics’ relationships; therefore, they considered these areas as different categories. By further abstracting and summarising the topical terms contained in these categories, selective codes were obtained, each corresponding to a category.
In summary, the limitations in these frameworks include the absence of an initial stage of data exploration, which is critical given the amount and complexity of the data a social scientist will deal with in big data research. Additionally, there were no measures taken to externally verify the validity of the TM models’ results. Aside from this, and more importantly, certain frameworks failed to apply some of GT’s core principles, which is critical when claiming to utilise the methodology (Birks et al., 2013). These include not appropriately implementing the constant comparison analyses method, and lack of in-depth engagement with the data, as well as inadequately addressing the procedures for coding and grouping codes to arrive at higher-level conceptual categories that will lead to the emergence of the theory. Finally, within all the existing frameworks, there is a noticeable absence of applying theoretical sampling in big data research, a crucial step to fill in the gaps in the discovered core categories and contribute to the quality of analysis. In Table 1, a summary of the discussed CGT frameworks is presented.
Summary of the discussed CGT frameworks.
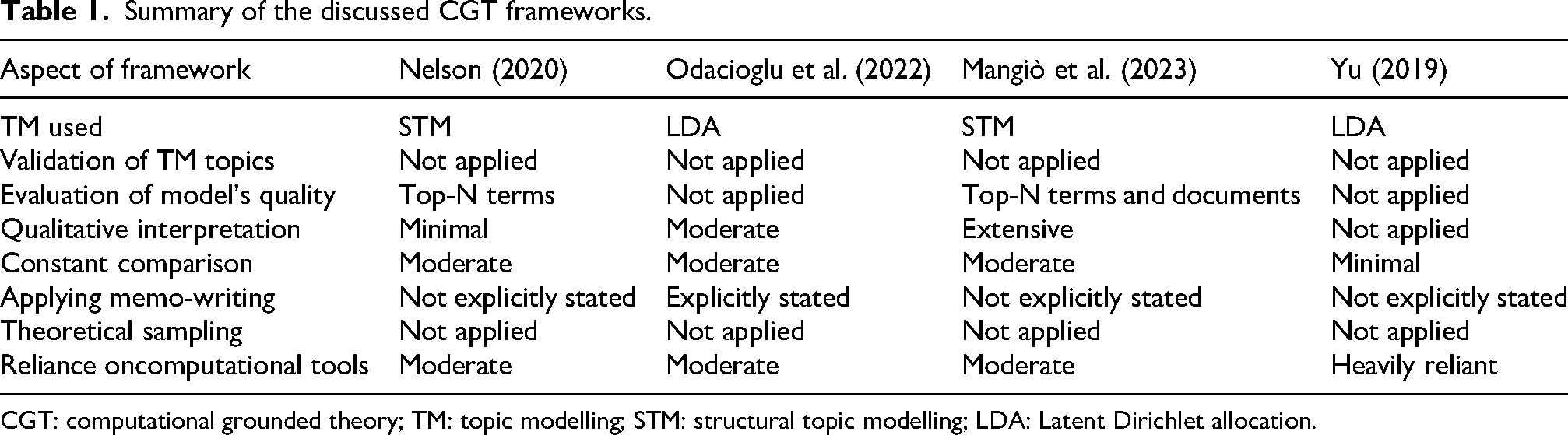
CGT: computational grounded theory; TM: topic modelling; STM: structural topic modelling; LDA: Latent Dirichlet allocation.
Grounded theory
GT is an inductive methodology for analysing qualitative data, which was originally developed by Glaser and Strauss (1967). It was introduced to address a limitation on existing methods of social research, at that time, which primarily focused on theory verification, while the initial step of discovering relevant concepts and hypotheses inductively from data is usually overlooked. GT is ‘simply a set of integrated conceptual hypotheses systematically generated to produce an inductive theory about a substantive area’ (Glaser and Holton, 2004: 3). This theory reveals the main concern of the research subjects and how they resolve it, that is, their behavioural response. It is called ‘grounded’ because it is grounded in the data: the research subjects’ own explanations or interpretations (Corbin and Strauss, 1990).
The analysis begins with open coding in which the researcher codes the data line-by-line, trying to conceptualise the patterns they find, since ‘the essential relationship between data and theory is a conceptual code’ (Glaser and Holton, 2004: 12). Initial codes are comparative and provisional (Charmaz, 2006) and it is only through constant comparison – the process of comparing incidents (i.e. the empirical data, the indicators of a category or code) with incidents, incidents with codes, and codes with codes – categories followed by higher-level categories start to appear (Charmaz, 2006). A category represents a group of related codes that share common characteristics or patterns. These codes (or sub-patterns) consider the ‘properties’ or ‘dimensions’ of that category (Glaser, 2002). Writing analytical memos is another continuous process to elevate data to concepts and an important component of quality (Glaser and Holton, 2004). As the constant comparison continues, core categories begin to emerge. A core category is considered central and may represent the main concern; frequently appears in the data and is meaningfully related to other categories (Glaser and Strauss, 1967). Then, selective coding, which entitled limiting subsequent data collection and coding to variables related only to core categories (Glaser and Holton, 2004).
As the analysis progresses, the researcher begins to identify gaps for which theoretical sampling is required to saturate the emerging core categories and provide the remaining necessary insights; here they must make decisions about which sources of data will meet the analytical needs (Birks and Mills, 2015). Only core categories with the most explanatory power should be saturated (Glaser and Strauss, 1967). Then, the final stage of theoretical coding begins, which is defined by Glaser (1978) as conceptualising ‘how the substantive codes may relate to each other as hypotheses to be integrated into a theory’ (p. 72).
Enhancing trustworthiness in CGT research
As big data provides new opportunities for social research, establishing trust in the research tools and methodology and thus in the results is of paramount importance. Some conventional researchers have raised concerns about the trustworthiness of ML models in conducting qualitative analyses (Drouhard et al., 2017; Eickhoff and Neuss, 2017; Gao et al., 2023; Jiang et al., 2021), and the credibility of results due to an over-reliance on computational tools (Dellermann et al., 2019; Nguyen et al., 2021; Ramage et al., 2009). This can be attributed to some weak examples of utilising these tools to explain and build theories about human behaviour without grounding them in social scientific foundations and accepting the results without proper validation. Therefore, we argue that when proposing frameworks to automate GT for big data analysis, trust can first be established by assuring social scientists that the core principles of their well-established methodology are applied and taken into account to maintain its rigour.
Furthermore, trustworthiness, defined as confidence in the quality of a research study, including its methods, data and interpretation (Connelly, 2016), is vital for ensuring credibility (Lincoln, 1985; Nguyen et al., 2021; Shenton, 2004). Here, trust in computational methods must be assessed rather than assumed, given that high statistical performance in validating and evaluating ML models does not necessarily imply that their results are interpretable or practically effective (Chang et al., 2009; Grimmer and King, 2011). Thus, many approaches have been proposed to incorporate human validation and evaluation (Chang et al., 2009; Doogan and Buntine, 2021; Elangovan et al., 2024; Mimno et al., 2011; Ying et al., 2022; Zhang et al., 2025). Within the context of CGT, it is important to ensure that the incorporated techniques effectively replicate the role of the researcher in big data analysis. We argue that when using TM to automate the coding process, researchers should externally validate these topics to ensure the model’s ability to detect reliable patterns in the data, thereby the reliability of the automated coding process. Researchers then play an important role in evaluating the quality of the chosen models’ outputs. As Grimmer et al. (2021) argues, rather than fully relying on fitting statistics, it is important to obtain feedback from human researchers about the quality of the generated topics.
Additionally, the use of computational models in CGT can significantly contribute to fostering trust in the resulting GT by enhancing objectivity and reducing human bias (Shenton, 2004). This approach aligns with the concept of ‘mechanical objectivity’ as described by Porter and Haggerty (1997) and Daston and Galison (2021), emphasising reliance on machines and the trust in numbers to produce unbiased results. At the same time, trust in the developed GT is further reinforced by preserving the researcher’s role in qualitatively interpreting the model’s outputs to derive meaningful theoretical insights. This also reflects Daston and Galison’s (2021) notion of ‘trained judgment’ where objectivity arises from the interplay between mechanical processes and human expertise (Benbouzid, 2023). Personal biases in the interpretation stage can be further mitigated by adhering to the constant comparison process (Glaser and Strauss, 1967), central to conventional GT. Preserving the researcher’s interpretative role ensures that automation does not diminish the value of qualitative insights but instead enhances both trust and the researcher’s ability to engage with big datasets. This is particularly important for elevating the conceptual depth of codes generated by TM and for facilitating the development of higher-level core categories – crucial steps in constructing a GT.
This active researcher engagement for achieving this balance is commonly referred to as the ‘human-in-the-loop’ (HITL) approach. In this approach, computational tools are used to support the analysis, while the researcher retains an active role throughout the process (Kim and Pardo, 2018). Adopting HITL enables social scientists to address issues of trust and credibility when using ML methods by allowing them to intervene in validating, evaluating, and interpreting computationally generated results. This also ensures that researchers maintain a sense of closeness and control over their qualitative analyses, which might otherwise be lost in fully automated processes (Jiang et al., 2021).
Thus, this article introduces a novel methodological framework for CGT that incorporates the HITL approach and addresses the limitations of existing CGT frameworks to enhance trust. Unlike researchers who emphasise algorithmic failure and ‘data friction’ as a means to inspire creative insights and identify significant cases for interpretation (Madsen et al., 2023; Munk et al., 2022; Rettberg, 2022), our framework takes a different stance. The primary objective is to ensure that the CGT framework and its associated techniques, can automate key aspects of the traditional methodology, making it scalable and suitable for big data contexts without compromising the foundational principles of GT.
Methodology
Computational grounded theory: A new approach
CGT frameworks were developed as a way of dealing with large volumes of data when conducting a qualitative analysis. However, preserving the fundamental principles of traditional GT to the greatest extent possible is essential to claim to have followed the methodology (Birks et al., 2013). Our three-phase framework (see Figure 1) strives to achieve this goal. Using specific computational tools enabled us to implement and facilitate the application of other GT principles to big data research, beyond the coding process that is the main focus of existing frameworks.
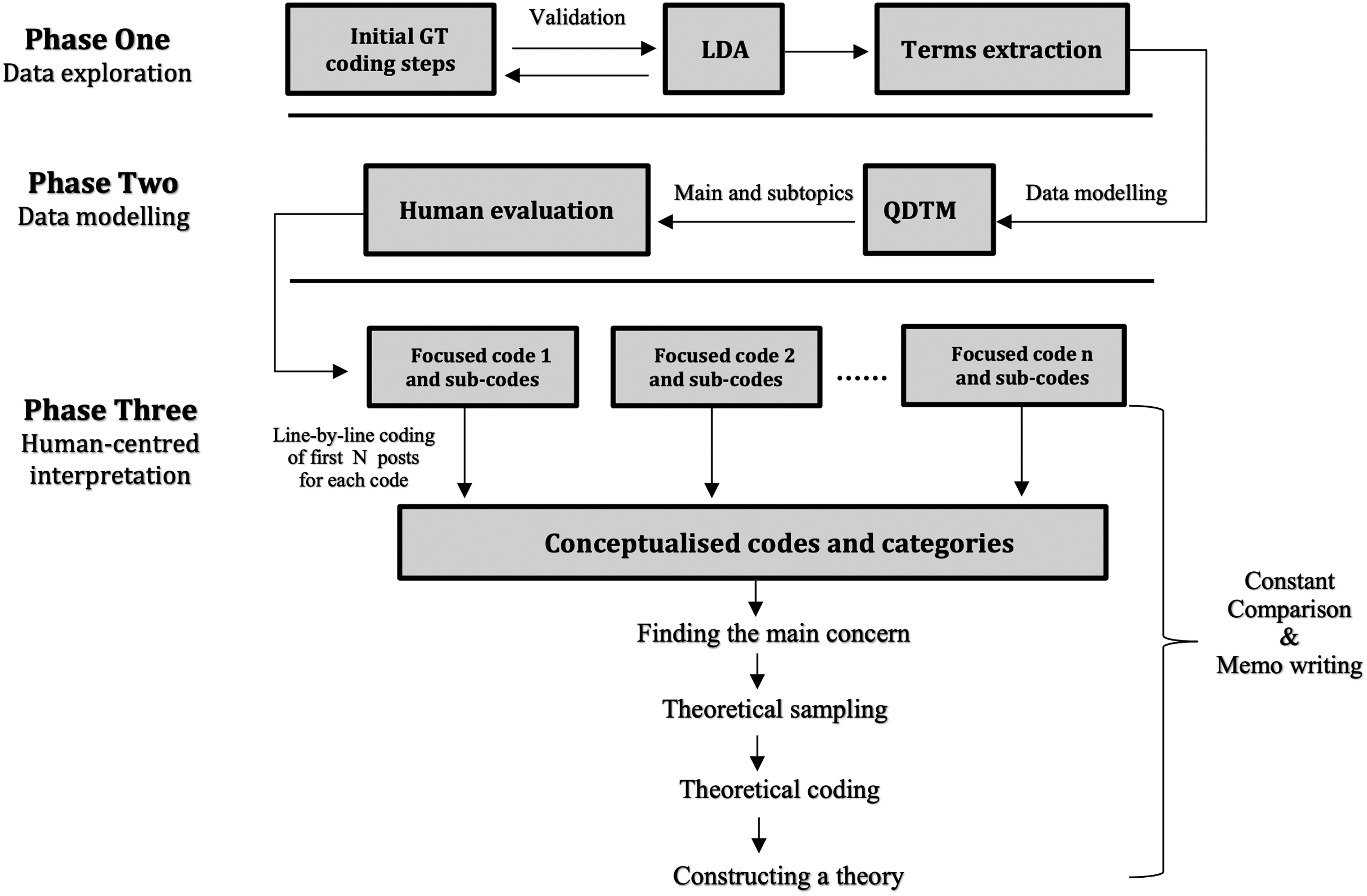
The HITL computational grounded theory (CGT) framework chart.
HITL ensures the broader social and contextual validity of the topics discovered using unsupervised TM models. The involvement of the researcher in ongoing interaction with the results generated by computational tools enhances the reliability of the analysis. The framework also provides a detailed description of how to conduct a human-centred interpretation of the computationally produced results effectively. This will further ensure adherence to GT principles, which will lead to an improved theoretical understanding of the substantive field of study and enhance the trustworthiness of the results.
Phase one: Data exploration
In this phase, the researcher begins by familiarising themselves with their dataset. Given that in big data research researchers do not collect the data by engaging directly with the research subjects, gaining an understanding of the data, its structure and complexity is crucial. While Goni et al. (2022) suggest reading subsets of data for this purpose, we propose coding a random subset of the data using GT’s initial coding steps. This will result in a list of codes with precise descriptions of the content of each one. These resulting codes should be utilised to validate the patterns that will be explored computationally using unsupervised ML methods (i.e. ones that learn without training data) when exploring a larger volume of data in the next step. This systematic approach is important to provide a valuable method for validation. Even though the original GT methodology encourages coming to the data with a ‘blank slate’, that is not bringing any assumptions about the data into the coding process, here in CGT we mainly depend on ML models to code the data, which necessitates ensuring that these substitute for human researchers effectively and appropriately. Notably, previous frameworks such as Nelson (2020) and Odacioglu et al. (2022) did not incorporate this step.
Next, using LDA TM (see Figure 1), the entire dataset is explored to identify the main patterns. Upon applying LDA, each topic should be represented by a list of the top-20 terms and top-N documents (N is decided by the researcher based on the nature of their data). To label topics, we emphasise the necessity of reading topical documents, since close reading can provide better qualitative insights into the topic’s content (Brookes and McEnery, 2019). A similar approach is taken by Mangiò et al. (2023) and Nelson (2020) while others only used topical terms to label topics, which was proven to not reflect topic content accurately. Following this, HITL validation is crucial to ensure that the TM output effectively replaces human reading and judgments on a large dataset, avoiding the blind use of unsupervised and black-boxed ML algorithms (DiMaggio, 2015; Grimmer and Stewart, 2013; Korenčić et al., 2018). Thus, a concurrent validation (Boussalis and Coan, 2016) is used, where the researcher compares LDA topics with the generated GT codes. Due to LDA scalability and the size of the data included in this step, new topics might be discovered, which is to be expected and should not impact the validity of the analysis. Here, a high level of alignment between GT and LDA results will ensure validity. The similarity between the two methods is what enable validation, as both are exploratory, data-driven and iterative (Muller et al., 2016). Then, the resulting GT codes from step one and the LDA topics will both be considered, this includes not only the topics that overlap but also those unique to either GT or LDA, which is essential to fully leverage the power of ML models in uncovering patterns in big data.
One of the advantages offered by LDA is the availability of terms associated with each identified topic, which is an important resource that our framework utilises. In the term extraction step, the researcher refines and curates the set of terms for each of the previously labelled LDA topics that will form the basis for the data modelling phase. In essence, the term extraction step serves as a critical link between topic identification and modelling. For topics identified in GT and LDA, or only in LDA, the top-20 terms were selected. Any terms that are deemed irrelevant to the topic being discussed should be excluded from the list based on the researcher’s understanding of the topic. This process ensures that the terms associated with each topic reflect the topic content. Secondly, terms should be proposed for topics that appeared only in GT.
Phase two: Data modelling
After identifying and validating the main topics of discussion, the query-driven topic model (QDTM) (Fang et al., 2021) is used. It is a semi-supervised TM approach designed to return topics relevant to queries input by the researcher in a tree-like structure. Here, the researcher inputs the terms extracted from the previous step, a set of query terms for each topic, into the model. QDTM then employs term expansion techniques – frequency-based extraction, KL-divergence-based extraction (KLD), and the relevance model with word embeddings – on the input queries, producing a set of concept terms to enhance topic modelling. These techniques focus on retrieval and relation rather than generation in identifying terms. Then, terms are fed into a framework based on a variation of a Hierarchical Dirichlet process (HDP) to form main topics and a second layer of subtopics, which is considered an effective way to organise and navigate large-scale data (Dumais and Chen, 2000; Johnson, 1967). Furthermore, the HDP is a nonparametric Bayesian model that automatically infers the number of topics in a corpus (Teh et al., 2004).
In CGT, this hierarchically structured TM is particularly helpful in ensuring the effective application of GT principles and maximises the researcher’s ability to extract the full analytical value from large datasets. First, since researchers will be provided with groups of related main and sub-topics together; this will greatly support the intermediate coding steps (Birks and Mills, 2015) and allow for more effective application of the ongoing process of constant comparison during analysis. It will also enable inductive reasoning and a focused examination of related documents (Fang et al., 2021). Second, in traditional GT research settings, it is the researcher’s responsibility to revisit the field and collect specific data when encountering a code or category they do not fully comprehend. In the proposed framework, QDTM automates or partially automates the saturation process. In most cases, only terms automatically generated by LDA are used, with no additional terms added to reduce human bias. Thus, the input queries are expanded into a comprehensive keyword list, making the output topics more relevant. The term expansion techniques employed are highly valuable as they re-examine the complete dataset and identify various variations and dimensions within each main topic (Carlsen and Ralund, 2022). By revisiting the corpus to capture overlooked aspects – such as low-frequency terms or niche topics – that were not initially captured due to their infrequent occurrence or any other factors, QDTM presents the researcher with enough variations and cases for each main topic. This will significantly reduce the necessity for researchers to engage in ‘extensive’ theoretical sampling to saturate their understanding of the identified codes or categories. Despite that, there may still be instances where such sampling might be necessary. Finally, it is critical that the number of sub-topics is automatically determined; in real-world large datasets topics are not evenly distributed, some are more frequent and have a wider range of variation than others. This feature might help researchers gain insights regarding the main concerns of research subjects and the core categories, since one of the indicators is its frequency of occurrence in the data (Glaser and Strauss, 1967).
These distinctive features of QDTM go beyond automating the coding process in large datasets. Instead, they actively support the application of other core principles of GT in big data research, making it a more suitable choice compared to single-layered TM models used in existing CGT frameworks.
Human evaluation of QDTM topics
The aim of this step is to ensure that the QDTM is capable of generating high-quality topics. This is critical as it will enhance the researcher’s ability to interpret these topics more efficiently and confidently at a later stage in the framework. To perform the evaluation tasks reliably, two or more annotators must independently annotate the data (Pustejovsky and Stubbs, 2012). This step further demonstrates the active involvement of the HITL in our framework and how this can contribute to increased trust in the final results. We emphasise the importance of evaluating topics’ intrinsic semantic quality. This is typically assessed using statistical measures, such as perplexity, however, negative correlations between these measures and human judgments of topic quality have been observed (Chang et al., 2009). Hence, we turn to HITL evaluation as an alternative – and superior – method. Typically, tasks for human evaluators (annotators) might include examining the quality of top-N terms for each topic (Mimno et al., 2011), or to identify the intruder within these terms (Chang et al., 2009). However, despite the popularity of measuring coherence based on topical terms, this approach is criticised for only partially reflecting topic content and quality (Brookes and McEnery, 2019; Grimmer and King, 2011; Korenčić et al., 2018).
In our framework, human evaluation is used to assess QDTM results, which is primarily based on topic documents. However, a list of terms per topic is provided to be used in specific cases. To effectively evaluate and annotate the QDTM’s topics, four distinct tasks should be undertaken. Firstly, rate the quality ’coherence’ of each topic, then identify the issues with lower quality topics, and then label the topics. Furthermore, since topics are hierarchically classified, this will only partly reflect output quality (Belyy et al., 2018; Koltcov et al., 2021), the relationship between main and subtopics should also evaluated. This step will enhance the researcher’s ability to interpret these topics more efficiently and confidently at a later stage. In Supplemental Appendix A, the complete annotation guidelines are presented.
Phase three: Human-centred interpretation
This final phase of the proposed CGT framework is dedicated to the in-depth, interpretative analysis of the topics produced by the QDTM. Based on the human evaluation conducted in the previous phase, the researcher will be presented with N groups of related topics, each representing a main topic and a number of subtopics. In the framework, the main topics are considered ‘focused codes’, while the subtopics are considered ‘sub-codes’ (see Figure 1). The labels produced by the annotators for each code are considered initial labels.
The interpretative analysis is started by coding the representative documents for each topic line-by-line. This process of ‘hand coding’ enables researchers to ‘zoom in’ on the studied phenomena for appropriate theoretical interpretations (Aranda et al., 2021; Mangiò et al., 2023) and will increase confidence that nothing has been overlooked (Glaser and Strauss, 1967; Glaser and Holton, 2004). As instructed by GT’s originators, hand-coding is vital to stimulating ideas, writing analytical memos, and properly applying comparative analysis to create higher-level categories. Here, since computational tools are used to classify the data and then the annotators to evaluate the resulting topics (codes), researchers are required to do their own coding. A similar approach is taken by Mangiò et al. (2023), whereas by Nelson (2020) and Odacioglu et al. (2022), interpretations are added to the analysis through a simple reading of the documents.
At this point, the size of documents will influence the plausible number of documents that can be manually coded and analysed (Amaya et al., 2021). Researchers should try to achieve a balance between the need for thorough analysis to draw meaningful insights and the practical constraints in terms of the resources and time available for manual analysis.
The analysis begins by coding the top-N posts of the first focused code. Constant comparison is applied here by comparing incidents in data against the code label and with each other. During this process, more sub-codes might be created and the researcher should raise the conceptual level of annotators’ labels since they are descriptive of topic content. After analysing the first focused code, the same process is applied to the first sub-code from the same group. The resulting codes should then be compared; the researcher should look for patterns, links, or any relationship between the focused code and the sub-code. This may reveal that one code (whether focused or sub-code) is part of the other or create a higher-level category that connects them. Here, the researcher should allow the analysis to take its course and ensure that the memos are written on a regular basis. Similar processes is applied for each of the following sub-codes until the analysis of the first group is completed. The researcher then moves on to the next group, until all are analysed.
The resulting codes and categories from each group are then compared to find relationships and to construct higher-level categories. At this point, the core categories and the main concern of the subjects under study should be determined and confirmed. Then, the researcher should engage in theoretical sampling to saturate gaps found in core categories (see next section). At this stage, the theoretical coding step commences, which is the process of defining possible relationships between the developed fully saturated core categories. Glaser (1978) explains that ‘Theoretical codes implicitly conceptualise how the substantive codes will relate to each other as interrelated multivariate hypotheses in accounting for resolving the main concern’ (p. 163). As opposed to the coding in the previous steps, which is data-driven, here we deal with ideas and perspectives which will help the researcher integrate categories and data into a theory.
Supporting theoretical sampling
Theoretical sampling significantly improves the quality of the analysis by allowing researchers to collect additional selective data to fill in emerging categories and address questions raised during the analysis (Charmaz, 2012), and is an often-overlooked step in big data research. In conventional GT studies, it is typically performed by following up with participants, observing in new settings and so on. However, in big data research, returning to data collection is not always feasible, for example, when the complete dataset is collected before analysis begins (Birks et al., 2013). According to Glaser and Strauss (1967), theoretical sampling is open and flexible: ‘Theoretical sampling for saturation of a category allows a multi-faceted investigation, in which there are no limits to the techniques of data collection, the way they are used, or the types of data acquired’ (p. 65). Therefore, in the proposed CGT framework, we argue that theoretical sampling can be implemented in big data research by utilising different computational techniques on the same sufficiently large and rich dataset. For example, the research might use sentiment or time series analysis, depending on the questions raised during the analysis, to help them gain completely different but needed results. This means conducting a multi-method analysis of the same dataset, previously analysed using TM. Here, researchers have to determine the most suitable NLP technique based on their needs, meaning that sampling methods will vary across different studies. Therefore, as also asserted by Charmaz (2014), theoretical sampling is a strategy that researchers employ and adapt to fit their specific study needs, not a standard data collection method.
Case study
To illustrate the implementation and usefulness of the proposed framework, a case study of gig economy tutors was conducted, with the ultimate goal of developing a substantive theory that could help explain their experiences.
Global economy digitalisation is associated with the rise of the gig economy, in which long-term employment is replaced by one-off transactions based on performing single tasks. This non-standard work, mediated through online platforms, has permitted flexible work arrangements and links independent workers with customers globally. It provides greater job autonomy and expanded employment opportunities (Clark, 2021). Despite that, the shift from market for jobs to market for tasks has also resulted in the loss of protections and rights typically associated with long-term employment (Drahokoupil and Vandaele, 2021). It is linked with job insecurity, income instability and low wages. This leads workers to work longer hours to achieve their earnings goals (Clark, 2021; Duggan et al., 2022). Moreover, there is an ethical concern arising due to, for example, a lack of transparency in platform operations (Jarrahi and Sutherland, 2019), which may create power imbalances between workers and platforms (Koutsimpogiorgos et al., 2020).
The nature of tasks performed in the gig economy has a significant impact on the challenges encountered and the overall experience of workers. This case study examined the experiences of an under-studied group of workers, tutors, where one-to-one online educational sessions are conducted, making them distinctive from other common forms of gig work, for example, in food delivery, transportation services or isolated knowledge-work tasks.
Case study data
CGT frameworks are generalisable to any source of textual big data. In our case study, we collected data from Reddit for illustration purposes and to test the framework. We examined Reddit and identified 18 relevant subreddits (see Table 2) in which our target population shares their experiences and asks questions. Using the Reddit API Wrapper,
The subreddits included in the study, along with the number of posts.

Phase one
To apply the first step to the case study, given the fact that our dataset consists of 18 subreddits, two relatively small subreddits were randomly selected, namely GoGoKidTeach and Palfish. This selection resulted in about 160 posts. The analysis process started by coding the data line-by-line, and since GT is a comparative and iterative process, the resulting codes were compared to one another, leading to the development of higher-level codes that group related codes together. After employing this step to this subset of the data, a total of 15 codes were identified (see Table 3). Due to their abstract nature, two of these codes, namely ‘Sharing experiences and feelings’ and ‘Seeking and providing help and advice’ were excluded from the comparison with LDA in the next step. This decision was made because these are contextual and primarily reflect the underlying purpose of the posts, and LDA as a statistical model is not expected to model them, which is designed to identify more concrete and topic-based patterns, rather than abstract themes tied to emotional expressions or interpersonal interactions.
List of codes derived from the initial exploration step.

Regarding the LDA process, two models with 13 and 17 K-values were tested (Alqazlan et al., 2021). The methods used to determine the value of K is firstly by following the approach of Quinn et al. (2010) and Grimmer (2010) to empirically examine the performance of LDA models with a different number of topics. Then, due to its time-consuming nature, we used the Tmtoolkit 1 Python package to compute and evaluate several models in parallel using state-of-the-art theoretical approaches, and based on this 17 topics were eventually selected. Evaluating the quality of the topics and labelling them was performed by examining the top-5 documents.
For validation, by considering both LDA models (with 13 and 17 topics), it was found that they were collectively able to detect 12 topics that were identified by GT analysis. Yet, both models failed to model one topic – ‘Covid-19-related discussions’ – that was present in GT codes. Conversely, only one topic – ‘Bank transfers and transaction fees’ – was clearly modelled in both LDA models but did not appear in GT codes. Therefore, since the aim of this step was to validate and further explore the data, and only one new topic was found even after the number of topics was increased to 17, the aim of this step was fulfilled, and it was not necessary to examine further models. Here, the obtained codes and topics will both be considered, making the final output of this process 14 topics that will be taken into account in the next phase. In Supplemental Appendix B, the term extraction results needed for applying QDTM are presented.
Phase two
To run QDTM on the gig economy tutors dataset, the model was input with a list of terms for each of the 14 topics that were identified at the terms extraction step. Here, after applying the pre-processing steps and training the model, vocabularies with less than five document frequencies and sub-topics with very low prevalence (<0.2%) were excluded. Once we were satisfied with the resulting model, we removed duplicate posts that appeared in the top-10 posts of each topic, and identical subtopics within each topic based on lower prevalence. This resulted in 76 topics (i.e. 14 main topics and 62 subtopics), each represented as top-5 posts and top-10 terms for the next step.
The human evaluation task was conducted by three experienced journalists. The reason for choosing this group is because they had taken part in similar annotation tasks before, which helped to significantly reduce the training time. Moreover, as journalists are generally well-acquainted with many different subjects, making it easier for them to understand the data. In total, each annotator spent about 15 h working to complete the annotation work. They followed guidelines developed by the research group through several rounds of revision and testing (see Supplemental Appendix A). Overall, the annotation was conducted in two stages; first, two main topics and their subtopics were annotated (12 topics total), and the second was with the remaining 12 topics and subtopics (64 topics total). The inter-annotator agreement (IAA) was calculated for each one. Four tasks were required: evaluating topic quality, identifying issues with topics, labelling topics and evaluating relationships between main topics and subtopics. Finally, the criteria for exclusion of topics is that main or subtopics are found to be incoherent, subtopics that are unrelated to their main topics, and topics where all three annotators disagreed on one or more tasks.
To measure the IAA of human evaluation of topics, Fleiss’ kappa (Fleiss, 1971) was used (see Table 4). According to Landis and Koch (1977), all obtained scores are considered ‘fair agreement’. However, we found that in 97% of the annotations, at least two of the three annotators agreed on all tasks. This indicated that the results are acceptable (Feinstein and Cicchetti, 1990), and it was not necessary to take further steps to increase agreement. Moreover, task dependency may have contributed strongly to the obtained results, as disagreements in task one will usually result in disagreements in tasks two and four. For final annotation decisions, we used a simple majority voting method, and in cases of complete disagreement among the annotators (only seven annotations, see Table 4), these topics were excluded. The final category counts after resolving disagreements are given in Table 5. Based on our exclusion criteria, 21 topics (27%) out of 76 were excluded. Therefore, a total of 55 topics will be considered in the next phase of the analysis. Of these, 14 were main topics and 41 were subtopics.
Inter-annotator agreement (IAA) results.

Final categories counts after resolving disagreement.

Commencement of phase three analysis
Following the quality evaluation of the QDTM results, it was necessary to determine the length of posts to decide how many posts it would be feasible to include in the analysis. Across 55 topics, statistics of the top 10 posts revealed a minimum length of 11 tokens, an average of 165 tokens, and only 13 posts exceeded 512 tokens. Based on these, it was determined that hand-coding of 550 posts would be a manageable task. We started the analysis by examining groups of related topics, and manually coding the top-10 posts for each code in the first group. Then, we proceeded to analyse the next group, continuing this process until all 14 groups were examined. Subsequently, after identifying the specific category that necessitated theoretical sampling, we integrated the newly identified data into the coding process and compared it with other data within that category.
During the analysis, a category ‘Redditing’ emerged, where tutors create their supportive network on Reddit; novices seek help and experts provide assistance. Yet, a question arose regarding whether novices truly benefited from this interaction. As a result, more empirical evidence is needed, which requires theoretical sampling. Here, a sentiment analysis model was identified to be useful in answering this question. The model distilbert-base-uncased-go-emotions-student 2 was pre-trained (Wolf et al., 2020) on the GoEmotions dataset (Demszky et al., 2020). This benchmark dataset contains 58K comments was manually annotated for 27 emotions. The generalisability of the data across domains was tested via different transfer learning experiments. After applying the model, we purposely selected ‘Gratitude’ and ‘Realization’ emotions (see Figure 2) for further analysis. Then, we randomly sampled 50 posts assigned to each emotion (see Table 6). Our analysis revealed that the data met our needs, leading to the creation of a new code, ‘Realising’ as a result of tutors’ Redditing behaviour.

The frequencies of emotions in our dataset. The bars in red are the two emotions selected for theoretical sampling. Gratitude represents about 7.70% and realization represents about 7.00% of the data.
Random samples from the data assigned to ‘Gratitude’ and ‘Realization’ emotions.

Table 3 in Supplemental Appendix C shows the resulting focused codes and sub-codes after line-by-line coding for each group of topics. Then, we compared codes and categories resulting from the analysis of all groups to identify relations and construct higher-level core categories, see Table 4 in Supplemental Appendix C. Quotations from the data to support each of these core categories and corresponding codes can be found in Supplemental Appendix D.
Following this, the final set of fully saturated core categories was organised based on patterns of connectivity in the theoretical coding step which greatly aids in the development of our GT. The section below presents the final product of the HITL CGT framework.
The GT of tutors’ experiences in the gig economy
The analysis revealed a grounded theory of tutors’ experiences in the gig economy. The theory proposes that the underlying main concern underpinning most of tutors’ discussions is ‘staying financially afloat’ when working within ‘under-structured organisations’ these are tutoring platforms. Tutors face significant ‘financial uncertainty’ due to job insecurity, income instability, fluctuating demand, inadequate payments as well as difficult-to-attain incentives. Tutors’ ability to stay financially afloat is also challenged by and arises from opaque and often error-laden ‘technological systems’. The technological systems contributes to payment instability when they incorrectly mark tutors as absent and penalise tutors when technical issues prevent task completion. Tutors’ income is also directly affected when they encounter issues arising from the booking system in events of overlapping classes, students’ no-shows, and cancellations. The vague and often unfair rating system that evaluates tutor performance and influences students’ hiring choices adds to concerns of payment instability. The tutors, however, are largely impotent when trying to address inaccuracies and malfunctions, since the tutoring platforms often fail to comply with the policies they set and lack effective communication channels in an apparent abuse of power. This category and its corresponding codes are among the most frequently discussed topics (see Table 3 in Supplemental Appendix C, topics 3, 4, 5, 6, 7, 8, 9 and 13).
The inherent ambiguity in platform work, including unclear decision-making processes and poorly defined rules and procedures, results in a state of ‘confusion’ among tutors. This code was found frequently in most of the 14 topics, as shown in Table 3 in Supplemental Appendix C and later raised to a category in Table 4 in Supplemental Appendix C. This confusion has a profound impact on how tutors act to resolve their concerns, as does their level of competency in navigating the technological systems. Platform work ‘experts’ are those who have dedicated substantial time and effort to ‘understand’ the job and the system. While ‘novices’, who may or may not be task experts but are not familiar with platform work, need more time to reduce their confusion and establish themselves on the platform, especially as the technologies employed do not operate in their favour. Furthermore, tutors’ ‘financial structure’ will hugely affect the possibility of pursuing this job full-time: for example, only those with financial support or living in low-cost countries find it worthwhile to absorb the impact of uncertain payments. For the majority, achieving earning goals will negatively impact a tutor’s work-life balance and job enjoyment (see topic 10, Table 3 in Supplemental Appendix C). The necessity for them to generate income is what drives them to ‘continue tutoring’ and adapt to challenges.
Tutors will ‘persist’ while working on tutoring platforms; it is the core category that is observed in nearly all topics and it illustrates the behaviour through which tutors addressed their main concern. They seek to establish a supportive network on Reddit and engage in ‘Redditting’ behaviour as a response to the absence of workplace and colleague support. Within Reddit, tutors play different roles based on their competency levels: novices are the help seekers who operate in a context of confusion; experts provide explanations and solutions based on their understanding of the platforms and the business models. Tutors ’resist’ challenges by empowering one another and forming bonds through the shared negative experiences and emotions. Tutors also persist in their efforts to ‘solve’ the problems they encounter. This may involve communicating with the platforms’ management despite their non-responsiveness, and educating students about the technology used on the platforms. To stay competitive, tutors develop interpersonal skills and use self-marketing by promoting their expertise and qualifications in their profiles. ‘Strategising’ is another form of tutors’ persistence. To mitigate income instability, tutors establish a base of regular students by maximising availability, working during peak hours and opening slots in advance. Teaching popular classes and being likeable are ways to raise popularity. Working mainly with loyal regular students and asking for high ratings are strategies for protecting reputation. ‘Multi-homing’, that is, working on multiple platforms simultaneously, is another strategy to combat an insufficient and unstable income.
With persistence, and dedicating time and effort, some tutors were able to resolve their main concern by ‘generating sufficient income’ and achieving their earning goals. Based on our theoretical sampling results, ‘Redditting’ has a significant impact on reducing tutors’ confusion and thus ‘realising’ and gaining a better understanding of unclear aspects of the platform. Lastly, tutors who possess clarity and understanding of the gig economy business model are divided into two types. The first accept the flaws of the business model, set realistic expectations and do not rely on this job as their main source of income. The second type refuses to tolerate poor working conditions and low pay, opting instead to leave the tutoring platform. They may employ leaving strategies such as ‘platform hopping’ in order to find better-paying platforms or they may switch to platforms that let them set their own prices. Alternatively they may simply choose to work as freelance online tutors who are not associated with any platform. This can be observed in Table 3, Supplemental Appendix C, topics 14, 12, and the sub-codes in topics 10 and 5.
Discussion and conclusions
This article proposes a novel framework for applying CGT, offering a practical solution for analysing large qualitative data using ML and NLP tools. The trustworthiness and credibility of the results is ensured by adopting a HITL approach, and the rigour of the GT methodology was maintained by adhering to all its fundamental principles. The case study results demonstrate the potential of this novel approach to CGT, as well as making an important contribution to gig economy research by focusing on an understudied group.
Our framework introduced a departure from the common practice in CGT frameworks of using single-layered TM for coding big datasets by employing a hierarchically structured TM, QDTM. The researcher begins by using LDA to identify the main topics of discussion. Then, to ensure codes and categories saturation, the QDTM with its terms expansion techniques, extends the discovered (and validated) main topics by revisiting the complete corpus to search for all relevant sub-topics, ensuring that no pertinent data or aspects are overlooked. Furthermore, the tree-like structure of QDTM topics presents the researcher with groups of related topics, which makes it easier to analyse and identify relationships between them, thus facilitating the application of GT’s constant comparison analysis. Additionally, QDTM’s capability to model topics using query terms elevates its superiority over other hierarchical TM models, offering researchers the flexibility to formulate missing topics from LDA.
Our framework has maintained a balanced approach, leveraging computational tools as supportive aids rather than replacements for human involvement. We contend that building trust in the credibility of CGT is ensured by the active inclusion of researchers. Within our framework, researchers are engaged in each step of the analysis, starting from the discovery of topics, validation, the modelling process, evaluation and ultimately the interpretation. Furthermore, the researcher adheres closely to GT’s core principles in the final phase of ‘zooming in’ on the phenomena under study to add interpretation and theoretical insights into the analysis. This helps to raise the conceptual level of the codes generated by QDTM and facilitates the construction of core categories. We argue that line-by-line coding of the data is what enables the discovery of research subjects’ main concern and helps to reveal how they address that, which are the key goals in any GT study.
Finally, while our research was carried out before large language models (LLMs) became available, our CGT framework is effectively NLP technology agnostic and hence as more powerful NLP tools become available, they can easily be accommodated within it.
Limitations
NLP researchers may find a limitation in the framework regarding the reproducibility of findings derived from manual interpretive line-by-line coding. Unlike quantitative studies, ensuring identical analysis by two qualitative researchers is challenging. Glaser (2007) argue that through constant comparison, personal input decreases and data become more objective. We argue that computational tools in the framework can reduce subjectivity and bias. Algorithms classify texts the same way by keeping the parameters the same. For instance, QDTM generates comparable topics and sub-topics if another researcher employs the same terms provided in Table 2, Supplemental Appendix B on the same dataset. Thus, the computational component can contribute to the reproducibility of the analysis.
With regards to validation, from a GT perspective, the theories produced are inherently grounded in the data and offer ‘a valid explanation’ of how research subjects address their concerns. Nevertheless, researchers should strive to maximise the validity of their analysis (Cohen et al., 2001). Our CGT framework ensured the validity of the quantitative analysis carried out in the first phase to identify the main topics. However, the final theory generated through the framework remains firmly situated within the qualitative realm and cannot be validated using common practices applied in quantitative and computational disciplines.
Finally, we acknowledge that the implementation of our framework may be time consuming. However, each step is indispensable for the proper application of core GT principles and to ensure trust, especially with large datasets. Overall, as noted by its originators (Glaser and Holton, 2004), GT’s inductive and iterative nature is complex and demands a great deal of time and effort.
Supplemental Material
sj-pdf-1-bds-10.1177_20539517251347598 - Supplemental material for A novel, human-in-the-loop computational grounded theory framework for big social data
Supplemental material, sj-pdf-1-bds-10.1177_20539517251347598 for A novel, human-in-the-loop computational grounded theory framework for big social data by Lama Alqazlan, Zheng Fang, Michael Castelle and Rob Procter in Big Data & Society
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental materials for this article are available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.