
Abstract
Growing awareness of the societal consequences of datafication in recent years has given rise to a new form of civil society engagement called data activism. This article examines the discourse surrounding data activism on the social media platform Twitter. Through a mixed-methods approach combining computational analysis of Twitter content and close readings of Twitter profiles, we explore how new forms of civil society action related to data justice are articulated and linked to other forms of activism, conflicts and problems, and the actors involved in these articulations. Our analysis reveals a distinction between two articulatory patterns in the data activism discourse. The first involves grassroots actors, such as community organisations and individual citizens, who challenge existing power structures and advocate for social change. The second, on the other hand, is associated with academics, capitalists and policymakers who already hold positions of power and influence. This asymmetry is consistent with previous findings in data activism research. We encourage future research to extend these patterns, using additional methods and case studies, to further refine and contextualise the understanding of data activism within the civil society realm.
Introduction and aim
The objective of this article is to analyse how the emerging forms of civil society action around issues of data justice – that is, the beginnings of a potential data justice movement – discursively articulate missions and visions set in relation to other forms of activism, political contention and political issues, as well as to map what kinds of actors are engaged in these articulations.
The growing awareness in recent years of the social, political and ethical consequences of a datafied society has given rise to new forms of civil society engagement. Phenomena such as mass surveillance (Cinnamon, 2017; Couldry and Powell, 2014; Ruppert et al., 2017; Zuboff, 2019; 2015), economic, sexist and racial discrimination inscribed in automated decision-making systems (Eubanks, 2017; O’Neil, 2016), and propaganda bots used for manipulating public opinion (Benkler et al., 2018; Bennett and Livingston, 2020; Hagen et al., 2022) are just some of the examples of societal challenges that have paved the way for a seemingly new form of data activism. Data activism can be loosely defined as emergent sociotechnical practices aimed at addressing and mitigating problematic implications following datafication and algorithmic automation (Beraldo and Milan, 2019; Milan, 2017; Milan & van der Velden, 2016; Lehtiniemi and Haapoja, 2020; Lehtiniemi and Ruckenstein, 2019; Treré and Bonini, 2022).
Previous scholarship on social movements and civil society action has emphasised the importance of emerging movements and campaigns of taking control of the narrative and actively framing the issues around which they want to mobilise. Formulating the problem at stake, devising the methods to mitigate it and generally setting the agenda and owning the issue, are key elements of social movement action. These elements are what will allow movements to potentially gain support, shape public opinion and ultimately achieve their goals. This is especially the case when movements are new, as the need is then particularly pressing to establish legitimacy and gain traction. Movement scholars Benford and Snow (2000) have written about the importance of ‘collective action frames’ for mobilisation. They argue that social movements do not arise automatically from certain structural conditions or pre-existing ideologies. Rather, social movement actors must work as ‘signifying agents actively engaged in the production and maintenance of meaning for constituents, antagonists, and bystanders’ (Benford and Snow, 2000: 613). This means that social movements have to actively shape the narratives and meanings that surround the issues they care about in order to mobilise others to join their cause. Making the connection to cultural studies theories on meaning-making, Snow and Benford argue that social movement action is deeply entwined with the politics of representation and signification (Hall, 1997).
In other words, the discursive construction by movement instigators of meaning around the issues, actors and areas of contention is crucial in shaping public opinion and determining the outcomes of political struggles. There are many different ways in which it is essential for an emerging movement to control the agenda: it allows them to prioritise their issues, ensuring these concerns are not buried among other matters in the public dialogue. When movements are in charge of the agenda, they can more effectively sway policy, ensuring that their issues are discussed in relevant arenas and exert pressure on citizens, corporations, policymakers and governments to take action. Controlling the agenda helps maintain focus on the main issues at hand, preventing the movement from becoming scattered or losing its potential. It also fosters unity among participants, aligning everyone's efforts towards shared objectives.
As stated at the beginning of this article, our study analyses how emerging civil society initiatives in this area are formulating their objectives and visions in relation to other activist efforts, political disputes and issues. Additionally, it seeks to identify the key players who are driving these discussions. We analyse this by combining a discourse perspective with computational text and network analyses of a dataset of tweets that address issues relating to data activism.
More concretely, the aim of the study is twofold: First, it aims to enhance the understanding of how data activism is discursively constructed by analysing which articulations of data activism take shape on Twitter (RQ1). Second, we ask which actors partake in this articulatory process (RQ2). The ambition is to scrutinise which actors contribute to the articulatory process of data activism and whether some positions are more prominent than others. Based on the results, we discuss the implications of the variegated influence of different types of actors on the formation of data activism as a phenomenon of social and political significance.
Contextualising and conceptualising data activism
To set the stage, we will first contextualise the phenomenon of data activism. As stated in the introduction, data activism can be conceived as a wide range of social and political practices that can aim to critically address, interrogate, as well as leverage societal implications that arise from datafication and algorithmic automation (Beraldo and Milan, 2019; Lehtiniemi and Haapoja, 2020; Lehtiniemi and Ruckenstein, 2019; Milan, 2017; Treré and Bonini, 2022). While other terms may be used to refer to the same phenomenon, such as data politics (Ruppert et al., 2017), computational politics (Tufekci, 2014) and algorithmic activism (Maly, 2019; Treré and Bonini, 2022), we consider data activism to be the most comprehensive concept and therefore use it as the umbrella term in this study.
One concept that foregrounds how the implications of datafication, algorithmic automation and similar societal transformations can give rise to activism is that of data justice. In their conceptual review, Dencik and Sanchez-Monedero (2022: 2) demonstrate how the notion of data justice ‘has been used to pave the way for a shift in the understanding of what is at stake with datafication beyond digital rights’. Questions related to data justice have been addressed across different research areas, such as that of working life (Johnson, 2016; Katzenbach and Ulbricht, 2019), public administration (Kaun, 2022), law (Heeks and Renken, 2018) and social movements. In the context of social movements, for example, the concept of data justice has been linked to challenges faced by social justice activists (Dencik et al., 2016; 2019), particularly in relation to large-scale data surveillance (Lyon, 2014; Raley, 2013). At the same time, the concept of data justice also invites discussion about how data and software can support social justice agendas, such as making abusive and discriminatory practices by state or corporate power visible to the public (Mattoni, 2020), or facilitating humanitarian efforts in developing countries (Gutierrez, 2018; Livingston, 2016).
Taken together, these different research approaches to data justice are united by their ambition to make the risks and potential of digital transformation a matter of social justice (Taylor, 2017). This is partly by highlighting, from their respective perspectives, how the large-scale collection and analysis of big data today can both be exploited in ways that fuel power asymmetries between those who control data and those who do not (Brunton and Nissenbaum, 2015; Lyon, 2014; Zuboff, 2019;2015) and by highlighting how data can be used to promote social justice (Gutierrez, 2018; Livingston, 2016; Mattoni, 2020). Thus, by adding the notion of data justice to our contextualisation, data activism can be understood to encompass a set of social and political practices that aim to critically engage with and interrogate the societal implications that result from datafication and algorithmic automation, as well as to leverage these implications based on a social justice agenda.
Previous research on data activism
Although the study of social engagement with the implications of technological transformations of society has a long history (Tilly, 1995), we approach data activism as a contemporary research phenomenon. To set a date, research on data activism had its breakthrough around the year 2013, following the revelation of the so-called Snowden leaks and public discussions about problems of mass data surveillance and digital privacy in the wake of this event (Fidler, 2015; Lyon, 2014). Since then, the research focus has broadened in scope.
From the perspective of ideal types, existing research has argued for two prominent forms of data activism. While one is characterised by attempts to reactively limit the negative consequences of datafication, the other seeks ways to proactively use data as an empowering force for civil society (Beraldo and Milan, 2019; Milan and van der Velden, 2016: 6). On this basis, Milan and van der Velden (2016) distinguish between (1) reactive data activism on the one hand and (2) proactive data activism on the other hand. This proposed dichotomy illustrates how civil society action against datafication and algorithmic automation can take a variety of forms and directions. While capturing all variations of data activism is almost impossible, this typology can still serve as a useful reference point.
First, reactive data activism refers to activist practices that seek to counter ‘the exploitative forces inherent in processes of datafication’ (Lehtiniemi and Ruckenstein, 2019: 2). For example, several studies, particularly in the field of critical data studies (Dalton et al., 2016), have considered how bias and discrimination can be inscribed in these processes in ways that can perpetuate social, economic and racial injustices (Eubanks, 2017; Noble, 2018; O'Neil, 2016; Taylor, 2017). Reactive data activism might therefore take the form of initiatives that seek to shed light on these issues. Reactive data activists could also be involved in the development of alternative technological infrastructures to limit and resist mass data collection (Beraldo and Milan, 2019: 6). An illustrative example is the case of CryptoParties, which include ‘events where people meet to share their knowledge or to learn about encrypting online communication and digital media technologies or safe internet browsing’ (Kannengiesser, 2020: i).
In contrast, proactive data activism broadly encompasses activism that aims to use the affordances of data to enable social change (Beraldo and Milan, 2019; Milan and van der Velden, 2016). Data-enabled activists can employ a wide repertoire of strategies to harness datafication for the benefit of civil society (Gutierrez, 2018; Horgan and Dourish, 2018; Livingston, 2016; Milan and Gutierrez, 2018; 2015; Ricker et al., 2020). An obvious example is the so-called open data initiatives, which can manifest themselves in different forms. One such form is the use of public government data to make discriminatory government policies visible and accountable (American Civil Liberties Union, 2024). Another can be seen in grassroots anti-corruption efforts, where datafication has proven useful in documenting and exposing illegal activities of governments or other corrupt authorities (Mattoni, 2020). In addition, proactive data activism can also aim to ‘create alternative digital public spheres for equal participation and transform the relationship between citizens and automated data collection’ (Milan and Gutierrez, 2018: 3 italicisation added by us). An illustrative example of this proactive approach is the development of geospatial tools, enabled by software and data infrastructures, by and for indigenous communities to address and protect their rights and concerns (Kidd, 2019).
As data and algorithms now permeate more and more areas of society worldwide, the scope of both reactive and proactive data activist practices extends beyond the examples outlined here. Again, it is crucial to emphasise that data activism is highly contextual and can encompass a spectrum of actions, from individual acts to collective efforts, driven by different motivations. While some initiatives may openly declare their collective identity and goals, others may simply seek to create a digital sanctuary – a space free from external influence or surveillance (Guberek et al., 2018; Vannini et al., 2020) – without necessarily identifying as data activists or aligning themselves with any particular stance on data.
The motivation of this article to map the landscape of data activism is rooted in the observation that its contemporary vocabulary seems to be the construct of only certain types of voices, such as those from academia (Beraldo and Milan, 2019; Kannengiesser, 2020; Lehtiniemi and Haapoja, 2020; Lehtiniemi and Ruckenstein, 2019; Lehtiniemi and Haapoja, 2020; Mattoni, 2020; Milan, 2017; Milan and Gutierrez, 2018; 2015; Milan and van der Velden, 2016; Treré and Bonini, 2022), policymakers (European Commission, 2021; United Nations, 2022) and westernised, often male-dominated tech communities (Aouragh et al., 2015; Dencik et al., 2016). Despite scholars arguing that data activism today is undergoing a shift from being an ‘expert niche’ towards becoming an issue of ‘concerned citizens’ (Milan and van der Velden, 2016: 2), this assertion is yet to be backed up by empirical evidence.
The conceptual understanding of data activism beyond these seemingly top-down communities has not been thoroughly explored. This includes examining the extent to which data activism has spread to bottom-up actors, including those outside academia, the state and the market (Beraldo and Milan, 2019), such as non-governmental organisations, grassroots communities and ordinary people. Based on the assumption that how and by whom a phenomenon is framed and highlighted in the debate determines its social significance (Lindgren and Holmström, 2020), scrutinising the contemporary discourse of data activism is important. This insight leads us to our previously stated research questions about how data activism is discursively articulated in the empirical field (RQ1) and by whom (RQ2).
Analytical framework, data and methods
Key concepts
In line with Laclau and Mouffe's (1985) discourse theory, a discourse broadly refers to a particular way of talking about a phenomenon (i.e., assigning meaning to a phenomenon from a particular perspective). From a constructionist perspective, discourses are powerful because they shape the phenomenon they purport to describe (Parker and Camicia, 2009) and influence how it acquires social meaning (Lindgren and Holmström, 2020). A key concept for our analysis is that of discursive articulation. As defined by Laclau and Mouffe (1985: 13), articulations occur ‘between different struggles and subject positions’. An articulation is ‘any practice that establishes a relation between elements in such a way that their identity is modified as a result of the articulatory practice’ (Laclau and Mouffe, 1985: 105). In other words, when different concepts – for example, data justice and gender equality – are articulated together, the resulting discourse has an impact on the socio-political meaning of both concepts. Laclau and Mouffe's concept of equivalence is also relevant in this context, as it refers to how different grievances, which may arise from different economic, political and cultural contexts, converge into broader collective narratives or movements.
In our empirical analysis of tweets, we operationalise articulations and equivalences in terms of the co-occurrence of hashtags on the platform. On Twitter, as on other social media platforms, the co-occurrence of hashtags can play a crucial role in processes of articulation and the creation of chains of equivalence. For example, the co-occurrence of hashtags such as #BlackInAI and #WomenInSTEM in the same tweet highlights the interconnectedness of racial and gender discrimination in relation to technology. Establishing this equivalence between struggles can draw attention to the intersectional challenges faced by black women in these fields, and this dual focus emphasises the need for intersectional approaches to diversity and inclusion. By using both hashtags, activists can show solidarity across different but related causes, drawing on shared experiences of systemic bias, exclusionary practices and underrepresentation. In relation to this equivalence, the common enemy becomes the structures that perpetuate inequality. For Laclau and Mouffe, equivalence emerges when particular claims transcend their particularity. The practice of articulation is about linking different struggles or demands under a common banner or identity, thereby giving them a more collective and abstract meaning. The importance of equivalence here is that it arises when different demands or struggles are seen as equivalent in the sense that they share a common antagonist. For example, individual struggles of different social movements may be construed as related or equivalent because they all oppose the same oppressive system. Laclau and Mouffe argue that such equivalence can encourage the formation of broader political boundaries or identities. This resonates with what Dencik and colleagues (2019: 181) write about the need to transform data justice from ‘a special interest “issue” to a core dimension of social, political, cultural, ecological and economic justice’.
For the purposes of this article, the conceptual apparatus of articulation and equivalence provides a framework for analysing and understanding the multifaceted discourse of data activism on Twitter. At a higher level of abstraction, Laclau and Mouffe's framework highlights the role of discursive practices in shaping the political landscape more broadly.
Empirical setting
As outlined above, this article analyses articulations of data activism in the shape of hashtag co-occurrences in the empirical setting of Twitter. Choosing Twitter is essentially due to its prominent role as an online space for civil society communication and mobilisation (Aouragh et al., 2015; Bucher and Helmond, 2017; Lindgren, 2013; Rambukkana, 2015). Twitter is, thus, a valuable entry point for our study as a space for communication and articulation of public discourse. 1
Hashtags, moreover, have proven to be important in facilitating such articulations. Rambukkana (2015: 3) theorises hashtags as ‘nodes in the becoming of distributed discussions’, generative of hashtag publics. These publics invite any user ‘to participate in conversations beyond their own social networks’ (Rambukkana, 2015: 30; see also Eriksson Krutrök and Lindgren, 2018: 3). A similar way of thinking about hashtags is in terms of ‘folksonomy’, a form of collaborative tagging system that is ‘non-hierarchical and inclusive’ – rather than ‘hierarchical and exclusive’ (Golder and Huberman, 2005: 199). Conceived in this way, hashtags allow all platform users to participate collectively as agenda-setters, organising, classifying and conceptualising whatever phenomenon is at play (Mathes, 2004; Vander Wal, 2007). It is on this basis that the choice of Twitter as the platform for the study and hashtags as the unit of analysis should be understood.
Sampling
Data collection and sampling took place in three steps. First, there was an initial step of collecting tweets. For this primary data collection, we used the version 2.0 API provided by Twitter with Academic Access. A comprehensive historical extraction of full tweet objects was performed using the filtering term #datajustice. This gave us a dataset of 13,066 tweets from the first use of the hashtag by a single activist in February 2012 to the last use on 26 January 2023, with the data collection ending on 31 January 2023.
Secondly, following the initial data collection, we compiled a list of all the different hashtags (1822 in total) that co-occurred with #datajustice throughout the time frame. This inventory, arranged in descending order of frequency of co-occurrence, was then subjected to qualitative evaluation to assess the potential relevance of these hashtags for extending our study. Thus, we used a snowballing technique (Åkerlund, 2021), where the co-occurrence patterns of a particular hashtag could lead us to other related hashtags. In addition, a strategic sampling strategy was used, whereby hashtags were selected from this list based on our qualitative judgement of their importance and relevance to ongoing debates about data justice and activism. This process resulted in a list of 93 hashtags.
Third, with this list of hashtags in hand, we returned to the Twitter API to collect all tweets using any of these 93 hashtags, regardless of their association with #datajustice in particular. In the end, our data consisted of tweets containing any of the 94 selected hashtags (#datajustice plus 93 others). This final dataset consisted of 401,369 tweets posted between 09 December 2008, when the CEO of the UK-based Good Things Foundation (goodthingsfoundation.org) posted using the hashtag #digitalinclusion, and 31 January 2023, the last day of our data collection.
Method
To answer the first research question, which articulations of data activism are taking shape on Twitter, we used network analysis with a focus on analysing the co-occurrence of hashtags in tweets. In line with Laclau and Mouffe's definition of articulation as the process by which different elements are combined to form political discourse, for the purposes of this study we identified hashtags as the key elements articulating data activism on Twitter. In other words, the network analysis of which hashtags tend to be used together in tweets is conceived as an analysis of the discursive connections and combinations made by those who tweet.
To create a map of data activism discourse based on this operationalisation of articulations, we processed all tweets in our dataset that contained more than one hashtag (n = 306,549/N = 401,469) and created a list of edges, each edge representing a connection between two hashtags. Weights were calculated for all edges (range 1–22,424) and only edges with weights ≥10 were retained for further analysis. The resulting graph (7508 nodes; 9567 edges) was visualised using Gephi (Bastian et al., 2009). Nodes were sized by betweenness centrality (Brandes, 2001) and coloured by modularity class (Blondel et al., 2008). The OpenOrd layout algorithm was used to optimise the analysis of clustering patterns in the discourse. This algorithm implements an edge-cutting phase that temporarily removes edges to allow clusters to form and then gradually reintroduces them, resulting in visual clarity for the clusters (Martin et al., 2011). The visualisation (Figure 1) and its underlying data were then approached from a qualitative perspective by reading and interpreting the top 30 hashtags based on betweenness scores, supported by close reading of tweets, web searches and other complementary forms of data collection and analysis to get a sense of the meanings of the hashtags in question. The results of this process are presented in the section on Articulations of data activism below.

Co-occurrence network of hashtags related to #datajustice.
To address the second research question, which actors are driving the different parts of the discourse, we worked through three methodological steps. The first step was to calculate an overall measure of influence for all user accounts in the dataset, based on their interactions. To do this, we again used network analysis to create a graph with all user accounts as nodes and their interactions, as tagged in the Twitter API, as edges. These include replies (direct responses to a particular tweet), retweets (the redistribution of another user's tweet) and quotes (retweeting with an added comment). We then used Gephi to calculate centrality scores for all user accounts. In this case, we chose the PageRank metric, a derivative of eigenvector centrality, for its ability to recursively evaluate influence and prominence (Page et al., 1999). PageRank considers not only the number of users an account interacts with but also the influence and prominence of the accounts it interacts with. Based on this metric, all users were assigned a certain level of overall importance across the networks of interaction in this discursive context.
The second step was to create lists, per discursive cluster (see Figure 1), of the most influential users shaping the discourse within that specific domain. We achieved this by extracting, for each cluster, the top 5% of frequently used hashtags in that cluster, then extracting lists of all user accounts interacting with any of these cluster-defining hashtags, and finally ranking these lists by PageRank. The point of this was to get ranked lists of influential (high PageRank) user accounts that were active in each particular cluster (engaging with its main hashtags), to enable further analysis of which types of user profiles are the dominant voices behind particular articulations of data activism.
Third, as a final step, the prominent actors behind each cluster of articulations were analysed using an ideal type approach, in the sense that a sub-sample of observations was extracted from the top of the lists generated in the previous step and manually coded into a set of types. In line with Stapley and colleagues’ (2022: 2) definition of a typology as ‘formed by grouping cases or participants into different types on the basis of their common features, taking into account how each unique individual represents a particular pattern of features’, a typology of actors was created based on the following process: A sub-sample of the top 50 most influential users – which we considered to be a manageable and sufficient number of units for the purposes of analysis – from each cluster was extracted and analysed through a qualitative reading of their Twitter profiles. The profiles were tagged with a set of keywords, resulting in a set of coded defining actor characteristics. These first-level codes were then abstracted based on a set of (inductively elaborated) variables, resulting in an overall typology of actor types. The results of this process are presented in the section on actors in data activism below.
Articulations of data activism
Figure 1 shows the resulting visualisation from the network analysis of co-occurring hashtags described above. The fact that the clusters are coloured by modularity class, as described above, means that each different colour represents a different group or category of hashtags within the data. Each node in Figure 1 represents a single hashtag, and their proximity and clustering are based on how often they occur together in tweets. In terms of the layout and positioning of the clusters, the interpretation of network plots such as this is that groups that are closer together tend to share common characteristics or themes, implying that the hashtags within these clusters are used more frequently together. As for the general positioning of clusters in the plot (left/right, top/bottom), this is derived from a force-directed layout algorithm that places similar hashtags closer together and dissimilar hashtags further apart, creating a spatial representation that improves readability but is not inherently meaningful in any geometric sense.
A first look at the visualised discourse reveals at least seven significant articulations of data activism. We heuristically label these as: privacy (green), data culture (orange), data policy (yellow), data governance (red), data inclusion (purple), data justice (turquoise) and data revolution (black). These labels are based on a qualitative assessment of the most commonly used hashtags within each cluster. Note that these labels are general abstractions, that is, the result of interpretation, and are by no means exhaustive or completely unambiguous. Nevertheless, we consider them to be workable descriptors of the articulations at hand. Therefore, in relation to the first research question, we present below the result of our analysis of these articulations.
Data protection
Looking at the network, a significant proportion of hashtags articulates data protection as an important issue, as shown by the formation of the green cluster in Figure 1. In terms of content, this articulation of data protection reflects a seemingly restrictive attitude towards datafication, with hashtags such as #datasecurity, #surveillancecapitalism and #dataprivacy among the most prominent. These, in combination with other notable hashtags such as #gdpr, also foreground a techno-legal focus that contrasts with the more socio-technical foci of some of the other articulations in the network. While the data protection cluster forms a fairly coherent articulation, there are some interesting overlaps in Figure 1, particularly with the data justice articulation (turquoise cluster), which is perhaps the most socio-technically oriented articulation of data activism in the network.
Data culture
A closer analysis of the orange cluster reveals an articulation focused on data as culture. The most prominent hashtags that define this articulation, such as #hacktivism, #hackathon, #art and #code, in their own ways evoke associations with open-source culture (e.g., Baack, 2015) and ways of engaging creatively or artistically with data as a cultural activity. While there are indeed other articulatory influences, such as more data protection-oriented hashtags such as #stalkerstate and #snowden, the cultural and seemingly proactive vocabulary remains central.
Data policy and governance
The yellow cluster shows an articulation held together by a focus on data policy. The most prominent hashtags in this articulation reflect a rather formal tonality, such as #digitalagenda, #eu and #websummit, all of which can be associated with a vocabulary that is commonly found at a formal policy level. Furthermore, a look at the red cluster reveals a clear and consistent articulation around data as a governance issue. Key shared hashtags include #democracy, #civictech and #citizenassembly, all of which can be linked to discussions about how to use digital technology to strengthen democratic processes. In the research literature, this discussion is ‘variously grouped under labels such as e-governance, online deliberation, open government and civic technology’ (Kreiss, 2015, p. i).
Data inclusion
A close reading of the hashtags in the purple cluster reveals an articulation linked by a common focus on data as an issue beyond mere technology, but rather one of inclusion (cf. the data protection articulation). This articulation of data inclusion emphasises social justice and, by extension, the transcendent nature of data. This is illustrated, for example, by the relative centrality of hashtags related to justice and equality, such as #digitalinequality, #digitaldivide, #digitalexclusion and #digitalrights. In this sense, the articulation of data inclusion shares a number of similarities with the articulation of data justice (see below). The difference is one of tonality, with the former being more formal and the latter somewhat more radical.
Data justice
The turquoise cluster reflects ways in which data is explicitly articulated as an issue of justice. The most prominent hashtags here contain either the word data or algorithm, combined with various references to justice and equality, or the lack thereof (such as #datajustice, #databias, #data4blacklives, #decentralizeddata, #algorithmbias and #algorithmsofoppression). The common denominator that unites the articulation of data justice is a seemingly more radical tonality and perspective that stands in contrast to the data inclusion articulation discussed above. Moreover, the data justice articulation is the only one to include hashtags that refer to ‘algorithms’. Looking at the shape and position of the turquoise cluster in Figure 1, we see a diverse pattern in which data justice articulations appear both as a fairly distinct sub-cluster in the periphery, and, interestingly, as integrated and overlapping with other articulations. We interpret this as indicative of how datafication today cuts across multiple domains of society, with economic, cultural and political implications in whatever domain it is situated, and partly converging with other social movement issues. This is in line with what Dencik and Sanchez-Monedero (2022: 8) argue when they write that ‘data justice as a way to inform mobilisation’ should be understood as a ‘system-level critique’ with a focus on how ‘datafication features in ongoing negotiations of social relations and power dynamics within society’ (Dencik and Sanchez-Monedero, 2022: 8).
Data revolution
Less central, but quite coherent, is an articulation we have chosen to label ‘data revolution’, illustrated by the black cluster in Figure 1. The hashtags that make up this articulation reflect, on the one hand, similarities with other more socio-technical and social justice–oriented articulations (e.g., data inclusion/data justice). However, the cluster is also distinct, not only because it reflects a more radical tonality (including, e.g., hashtags such as #datarevolution and #dataforchange) but also by the fact that explicit mentions of forms of the word activism seem to be prominent among the top hashtags here, in contrast to the other articulations. This more explicit, activist nature of this articulation is also evident in hashtag variants that relate to – and thus establish equivalence with – other and broader social justice issues such as gender and race (e.g., #queerdata, #blackindata, etc.).
The discursive landscape of data activism
Returning to our first research question about the articulations of data activism, the discursive landscape (Figure 1) reveals what appears to be a quite diverse repertoire of data-related issues, experiences and grievances. This is in the sense that the mapped articulations cover a diverse range of content, and that different articulations relate to each other in relatively complex ways. However, this is not to say that there are no patterns at all.
A general pattern is that, taken together, the articulations reflect a common focus on data in relation to some form of societal challenge – be it how to ensure privacy, how to prevent discrimination based on how data is used or how to make data work for the benefit of people. In line with previous research, our findings also suggest a distinction between what has been described as a more techno-legal set of articulations, as opposed to a more socio-technical set. While the former type of articulation reinforces the view that the social challenges associated with datafication can be mitigated through techno-legal measures such as ‘the use of encryption and policy advocacy around privacy and data protection’ (Dencik et al., 2016: 2), the latter consists of articulations that align implications with a structural social justice agenda. The techno-legal group would then include the clusters that situate data and datafication in the context of protection, policy, governance and inclusion, while the socio-technical group includes the clusters that articulate data as a matter of justice, in the context of culture and as a driver of revolution.
While this heuristic distinction serves as an easily applicable overview of general patterns found in the network, it also reinforces the ideal type tendency identified in previous data activism research. Moving towards a more descriptive perspective, it is essential to note that this distinction is far from clear-cut. This is particularly true in the sense that the two sets of articulations, far from being isolated from each other, have some interesting overlaps. This includes, for example, the pattern by which the data justice articulation branches out and engages with several other articulations. Our findings thus highlight the fact that the ideal type perspective that currently guides essential parts of data activism research, however useful, is based on ‘simplifications of a much more complex and entangled reality’ (Beraldo and Milan, 2019: 7). Nevertheless, the tendency to speak in terms of a simplified division between techno-legal and socio-technical perspectives has indeed been addressed and problematised by Dencik and colleagues (2016), among others.
In our closer analysis of the clusters, we also found differences in attitudes towards datafication. Across all articulations, we found both proactive and reactive attitudes that do not seem to follow any particular logic or be dependent on any particular issue. With reference to the two types of data activism outlined earlier in this article, we coded proactive attitudes as those that emphasised the potential of data as a positive tool, and reactive attitudes as those that approached datafication in a less positive way, for example as a source of discrimination and exploitation. The most proactive articulations were found within three articulations (data revolution, data culture and data governance) which are quite unrelated apart from this similarity. We also found that the techno-legally oriented articulations were generally more reactive (negative towards datafication as such) than the socio-technically oriented ones, which were, on average, either more proactive or neutral.
Another tendency that problematises and complicates any simple division between techno-legal and socio-technical positions concerns tonality. While some articulations, for example, share a similar view of what the challenges of datafication are, they differ in their choice of words to address them. In our qualitative assessment, we found this perhaps most striking in the case of the data justice articulation, when compared to the data inclusion articulation. This is because, while the challenges addressed within the two different articulations (clusters) are essentially the same, the inclusion cluster seemed to reflect a more formal tonality than the justice cluster. Some examples to illustrate this contrast are #digitalinclusion (data inclusion) versus #decentralizeddata (data justice); ‘#digitalexclusion’ (data inclusion) versus ‘#algorithmsofoppression’ (data justice); or #digitalrights (data inclusion) versus #data4blacklives (data justice). In addition to this contrast, a further case could be made regarding the prefixes used within each articulation to address data challenges. This is particularly true for the data inclusion articulation, which reflects a consistent use of the word digital in different combinations, while the challenges addressed within the data justice articulation are conceptually addressed through the word data and also algorithm.
Actors in data activism
Figure 2 provides an overview of the types of actors involved in the articulations of data activism, based on two characteristics: affiliation (the sector in which the actor was identified) and interest (the interest the actor was identified to have in that sector). The labels of the columns represent the types identified within each characteristic, and the boxes show the occurrence of each type, calculated as a percentage.
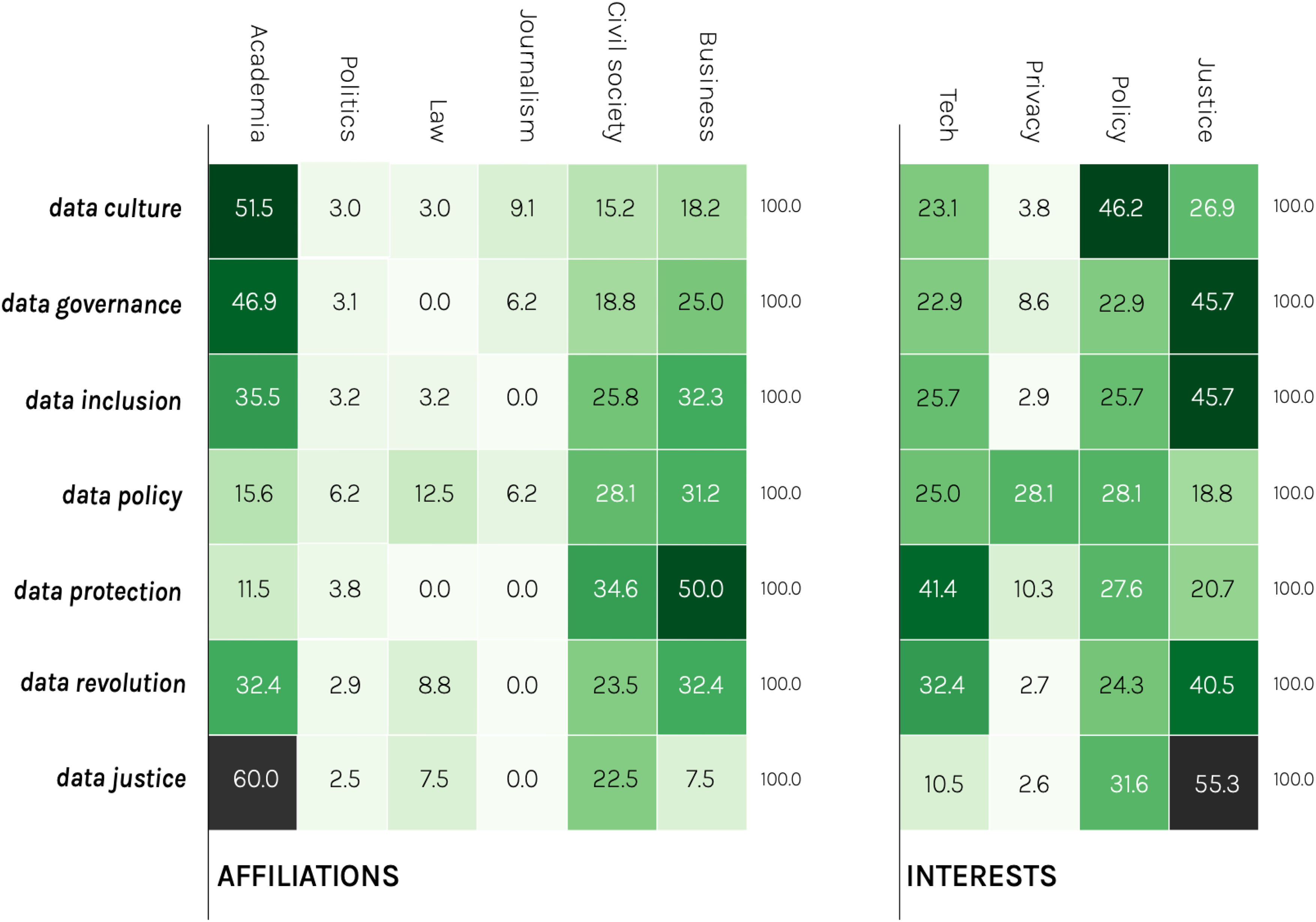
Heatmap showing percentages for user affiliations and interests within the clusters.
Note that only two characteristics are shown on the map. Other characteristics were also analysed, such as whether an actor was identified as an individual, group or institution, gender (where relevant and made explicit by the actors themselves) and whether the actor took a reactive or proactive stance towards datafication. These characteristics will be addressed in the following text where relevant. What follows is an analysis of the patterns that emerge from this map, presented as a summary of a number of key observations.
Overall, our findings reveal an eclectic mix of actor types based on their affiliations and interests. The fact that contentious experiences of data are far from isolated, but seem to involve actors from many different parts of society, is, on the one hand, a finding in itself. However, this diversity also makes any attempt to translate the findings into a clear typology challenging. This is not to say, however, that there are no patterns of significance.
At least three observations can be made about the affiliations of actors. First and foremost, actors affiliated with academia are among the most influential actors in the data activism discourse, alongside business. The distribution of these affiliations differs between the different articulations. For example, the majority of business-affiliated actors can be found in the data protection articulation, while actors from academia are particularly prominent in the data justice and data culture articulations. A second observation worth mentioning is that the representation of political actors is scarce. This is probably due to several factors, one possible reason being that data as a societal issue in its own right has not yet entered the broader political arena. Thirdly, actors who are explicitly associated with civil society, that is, who have explicitly described themselves in this way in their Twitter profile, are predominant but overall less prominent than academics and business.
Regarding the interests of the actors, at least two critical observations can be made. Firstly, on closer analysis of the data, we found that the majority of actors associated with business were also interested in technology. In addition, where the gender of the actors was identifiable, there was a tendency for the majority of those in business and interested in technology to be men. A reading of their profiles also generally indicated a more proactive attitude towards datafication. This contrasts with individuals associated with academia, where women, based on an assessment of their self-presentation, seemed to predominate. Furthermore, academics appeared to be more reactive or neutral than proactive. A second notable observation here is that the interest in justice is present, but appears to be primarily represented by actors in academia. Finally, our analysis of whether the actors were individuals, groups or institutions showed a relatively equal occurrence of groups and individuals, while the representation of institutional – primarily political – actors was close to zero.
Concluding discussion
The study presented in this article aimed to map the discursive landscape of data activism on Twitter by analysing how emerging civil society issues related to contentious experiences with data are articulated (RQ1) and by whom (RQ2). Our analysis of articulations started with a network analysis of Twitter hashtags related to data activism, including the meaning and co-use of these hashtags, followed by a close reading of a sub-sample of Twitter profiles to analyse the actors involved in these articulation patterns. The empirical aim was to gain insights into the dynamics of the data activism community on Twitter and to understand the patterns of discourse and influence within this community.
In conclusion, the analysis of how data activism is articulated (RQ1) reveals at least three notable patterns. Firstly, in line with previous research, there is a consistent emphasis across all articulations on societal implications of data that move beyond the technological realm to encompass related issues of ‘social justice, new forms of agency and political participation’ (Lehtiniemi and Ruckenstein, 2019: 1). Secondly the articulatory practices demonstrate a combination of proactive and reactive attitudes towards these implications (Milan and van der Velden, 2016). That is, there is a duality of attitudes towards data, with some focusing on its potential for societal benefit and others on its risks. Thirdly, two articulatory patterns emerge regarding actions suggested to mitigate perceived challenges with data: one tending towards a techno-legal perspective and the other having a more socio-technical orientation (Aouragh et al., 2015; Dencik et al., 2016). The former may be interpreted as suggesting that challenges can be addressed through technical and legal measures while maintaining the status quo, and the latter as highlighting issues of structural injustice inherent to the way contemporary technology is adopted by society to the extent that radical change is needed. Moreover, there is a difference in tonality between these patterns of suggested actions and solutions. The techno-legal perspective adopts a formal and moderate tone, while the socio-technical view takes a more radical and urgent approach. These tonal differences may suggest that they convey different problem descriptions and ideas for solutions, which may be influenced by the positions of the actors involved.
In terms of the actors involved in the data activism discourse on Twitter (RQ2), the analysis leads to two concluding observations. The first observation is that individuals from what has been referred to in passing earlier in this article as top-down communities are slightly overrepresented in all articulations, regardless of perspectives, attitudes and proposed solutions to the implications of data. Based on a close reading of how they present themselves on Twitter, these actors are largely academics, policymakers and individuals from business and technology, all of whom may be seen to occupy societal power positions to different extents. Furthermore, it was observed that academic actors were identified as slightly more prominent in addressing structural justice issues, while the majority of those calling for purely technological or legal solutions were identified as men in the business sector with an interest in technology. Secondly and relatedly, the study suggests that there is a comparatively limited representation of actors from politics, civil society and the grassroots, in the data activism discourse on Twitter, especially when compared to business and academic actors. It is important to remember that the sampled hashtags were snowballed from that of #datajustice and could thus be expected to be imbued with politicised and activist language use. From that perspective, it is (even more) surprising that civil society actors, not the least those with apparent political affiliations, were a minority. Along these lines, it is also crucial to acknowledge that not all Twitter users utilise hashtags. Our sampling strategy, while having apparent advantages as sampling by hashtags allows for focusing on specific topics and communities, may, therefore, also be limited to some extent as it might not fully capture the breadth and diversity of actors engaged in this space.
This landscape of articulations and actors raises important questions about what it means for emerging forms of activism that actors, who may already have capital and opportunities within the current state of affairs are potentially responsible for what Eyerman and Jamison (1991: 3) call cognitive praxis – ‘that which transforms groups of individuals into social movements, that which gives social movements their particular meaning or consciousness’. While one can imagine how a movement could potentially be strengthened by academics assuming ‘the articulating role of movement intellectuals’ (Eyerman and Jamison, 1991: 64), it seems less hopeful that corporate actors will occupy such positions. Corporate activism (Warren, 2021) may indeed, to some extent and in some contexts, help to move society in good directions while supporting the financial goals of capitalists (Lehtiniemi and Haapoja, 2020). Nevertheless, there is also reason to believe that corporate engagement in data justice issues is largely profit-driven and more cynical than authentic.
In a seminal study of the phenomenon of data activism, Beraldo and Milan (2019: 9) concluded that it remains ‘an open question to what extent’, practices they refer to as, data activism ‘display a cohesive collective identity of their own and the capacity of action sustained over time, and whether it provides the much-needed counter-weight to the impending surveillance capitalism’. However, despite growing social awareness of the consequences of a datafied society and academic speculation about the emergence of civil society engagement – paving the way for data activism as a research phenomenon – our findings seem to suggest that there is still much progress to be made. This is not least in relation to the significant corporate and business presence uncovered in the study, which points to the risk that data activism is dominated by performative gestures and public relations optics rather than driving substantive change (Thimsen, 2022). Or, to put it more bluntly, that actors who can benefit from the logics inherent in surveillance capitalism (Cinnamon, 2017; Zuboff, 2019; 2015) may in fact have the greatest influence in shaping the public narrative of its inherent challenges.
To conceptualise this tendency, we find it adequate to speak in terms of a typology, of two general, and overarching, constructs of data activism derived from the analysis of articulations and actors. The first one outlines a bottom-up pattern where grassroots actors, such as community organisations or individual citizens, challenge existing power structures and advocate for social change. This approach is decentralised and potentially inclusive, empowering marginalised communities to participate in decision-making processes related to data governance and rights. Processes around articulations such as data justice and data revolution typify this pattern, involving actors affiliated with civil society and journalism. By contrast, the second construct represents a top-down pattern where actors higher in hierarchy or with more power, such as academics or business corporations, engage in articulating data justice issues. These actors shape the discourse in ways that may not reflect the concerns of marginalised communities most affected by data injustices, potentially overshadowing their experiences.
Our study highlights an overrepresentation of top-down actors driving data activism discourse, such as academics, corporations and policymakers, while bottom-up actors like grassroots activists and marginalised communities are underrepresented. As such our typology can be seen as an empirical confirmation of some tendencies identified in previous research, such as the gap between techno-legal (top-down) versus socio-technical forms (bottom-up) of data activism, as suggested by Dencik et al. (2016), or the alleged disconnect between a tech justice (top-down) stance on the one hand, and a social justice stance (bottom-up), as noted by Aouragh and colleagues (2015).
This imbalance risks neglecting the perspectives and needs of those most affected by data practices and technologies in the formulation of an emerging data justice movement. The voices and perspectives involved in the data activism discourse are crucial in determining which challenges are seen as most pressing, the preferred solutions to those challenges, and the practical steps to bring about change; it is therefore essential that the voices of those most affected by data injustices, such as power imbalances and discrimination, are represented over and above those who are unaffected and who may even benefit from maintaining the status quo.
Limitations and future research
Our study has limitations that point towards avenues for future research. First, it should be underlined that our typology, like other taxonomies referenced throughout the article, simplifies a complex reality (Stapley et al., 2022). We acknowledge the fluid boundaries and contested perspectives that do surround the typology. For instance, assigning academic actors as top-down may indeed be subject to debate, as parts of this (heterogeneous) category could align with the bottom-up strand in terms of loyalties. In fact, a subsequent discussion in data activism research regards the potential of a new form of ‘data-activist’ research, defined by Milan and van der Velden (2016) as a ‘type of co-generative inquiry and a way of conducting ‘engaged research’, that turns (research) data into points of interventions, supporting grassroot efforts’ (p. 8; Milan, 2014). This debate is all the more relevant given that, in our analysis, we found that interest in data justice is indeed present among actors in the academic world. Whereas the typological categories thus are neither clear-cut nor mutually exclusive, we argue that they offer a useful heuristic framework for future research.
Second, our choice of Twitter as the platform to study could indeed be questioned. This is due not only to the well-known debate about Twitter as a corporate platform that tends to favour elitist discourse (Mirchandani, 2012; Mustafaraj et al., 2011) but also because resisting such corporate platforms and instead developing their own communication infrastructures may, in fact, be the very mission of some data activists. While we contend that Twitter/X remains an accessible source for a first empirical glimpse of the data activism discourse, we encourage, at the same time, future research to explore the alternative locations in which data activism may take place, both online and offline.
Relatedly, the analysis focuses solely on a dataset that originates from a snowball sampling around a single hashtag, and it is also in English. Although this dataset is fairly comprehensive and central to articulations of contentious experiences with data, it also excludes some perspectives. In everyday political reality, besides the alternative platforms data activists may use, there are different dimensions to concepts such as ‘datafication’, ‘justice’, ‘activism’ and ‘civil society’, to name a few. An examination of alternative locations of data activism may also offer insights into different articulations of data justice as well as how they may vary across these locations.
In addition, while our study spans a considerable time frame the focus was not to analyse data activism in a way that accounts for events shaping its evolution and focus over time. Yet, this is indeed an avenue for future research. A more comprehensive understanding of data activism may well be achieved by following its emergence along a timeline. Therefore, we encourage future research to conduct longitudinal analyses to identify trends and events that have influenced the development of the data activism movement.
Finally, it must also be noted that data activism that is oriented towards addressing consequences of datafication (data-oriented activism) can, in several ways, be enabled by, and leveraged on, data practices (data-enabled data activism) (Beraldo and Milan, 2019), harnessed as part of new activist repertoires of collective action (Tilly, 1977), that are not only digital repertoires of contention (Earl and Kimport, 2011) but which potentially usher in an era of datafied activist repertoires. Future research should empirically explore how activists utilise data-driven technologies, beyond the dichotomy of ‘means vs. ends’ and investigate how data-enabled activism contributes to new repertoires of collective action (Beraldo and Milan, 2019: 9). By addressing these limitations and exploring the directions they suggest, future research should strive to deepen our understanding of data activism as an emerging movement and its evolving impact on society.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Swedish Research Council (VR) (grant number 2021-02815).