
Abstract
Following the release of large language models in the late 2010s, the backers of this new type of artificial intelligence (AI) publicly affirmed that the technology is controversial and harmful to society. This situation sets contemporary AI apart from 20th-century controversies about technnoscience, such as nuclear power and genetically modified (GM) foods, and disrupts established assumptions concerning public controversies as occasions for technological democracy. In particular, it challenges the idea that such controversies enable inclusion and collective processes of problem definition (‘problematisation’) across societal domains. In this paper, we show how social research can contribute to addressing this challenge of AI controversies by adopting a distinctive methodology of controversy analysis: controversy elicitation. This approach actively selects, qualifies and evaluates controversies in terms of their capacity to problematise AI across the science and non-science binary. We describe our implementation of this approach in a participatory study of recent AI controversies, conducted through consultation with UK experts in AI and society. Combining an online questionnaire, social media analysis and a participatory workshop, our study suggests that civil society actors have developed distinctive strategies of problematisation that counter the strategic affirmation of AI’s controversiality by its proponents and which centre on the public mobilisation of AI-related incidents: demonstrations of bias, accidents and walkouts. Crucially, this emphasis on ‘AI frictions’ does not result in the fragmentation of AI controversies, but rather enables the articulation of AI as a ‘super-controversy’: the explication of connections between technical propositions, situated troubles and structural problems in society (discrimination, inequalities and corporate power).
Keywords
This article is a part of special theme on Analysing Artificial Intelligence Controversies. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/collections/analysingartificialintelligencecontroversies
Introduction
In March 2023, the San Francisco-based start-up OpenAI released their latest large language model (LLM) Generative Pre-Trained Transformer 4 (GPT-4) to their subscribers, including an accompanying document warning about the potential negative consequences of this technology, 1 which led to a wave of media articles highlighting the real dangers of this ‘controversial’ technology for society. 2 In previous years, OpenAI had issued similar statements: in February 2019, the company initially opted against releasing the GPT-2 model (despite ultimately making it available several months later), due to ‘concerns about LLMs being used to generate deceptive, biased, or abusive language at scale’. 3 Similar concerns were made public in May 2023 by the Chief Economist of OpenAI’s parent company Microsoft, who went on record to state that ‘I am confident that AI will be used by bad actors, and yes it will cause real damage’. 4 Such affirmations of the dangers, harms and costs to society of this new wave of so-called generative AI by their developers and backers can be called ‘disruptive’ in their own right, as they break with unwritten conventions that have underpinned public communications about controversial science and innovation in the last few decades: in notable controversies about technoscience in the 20th century, concerning nuclear power, climate change, and genetically modified (GM) food, the companies involved consistently denied, refuted, deflected or severely qualified claims advanced by civil society actors about the harms and risks that their products created for society. What is the significance of the seemingly irresponsible affirmations by AI developers and backers of the disruptions, risks and harms that are created by their innovations, and what are the implications of this for the role and status of public controversies about contemporary AI?
One of the striking features of recent corporate ‘warnings’ about the dangers that AI poses for society is that they echo similar warnings that have been made by AI critics during the last 5 years. When Geoff Hinton, the ‘Godfather’ of AI went public with his concerns about AI in May 2023, and cited these as a reason to end his employment at Google, it was pointed out by many, in newspaper editorials and on Twitter, that he had in 2018 failed to show support when the computer scientist Timnit Gebru and others on Google’s Ethics team, were fired or left the same company citing closely related concerns, namely that Google’s LLMs present a source of significant harm to society. 5 In this regard, Hinton’s actions can be interpreted as a discursive strategy of appropriation—a way of disarming the criticisms of AI voiced by actors in society by adopting a modified version of those criticisms as one’s own, and mobilising one’s own authority as a credible spokesperson of science and business to occupy the channel of ‘public concern’ with AI, to the exclusion of out-group critics. 6 Indeed, this public communications strategy can be understood as reflective of wider, institutionalised relations between industry and state, in which Silicon Valley tech-company lobbyists seem assured that their ‘confidence’ that AI will cause widespread societal harm will not be sufficient cause for the state to restrict its development in ways that are adverse to their interests (McGoey, 2021). However, even if the affirmations of AI’s harmfulness for society by its developers and backers have featured more prominently in English-language media than similar assessments by industry outsiders in recent years (Dandurand et al., 2022), this does not necessarily mean that ‘AI controversy’ can be reduced to these industry assertions. To examine this, what is needed is a broad empirical investigation of the ‘problematisations’ of AI that have emerged from public debates about AI across the divide between ‘AI insiders’ affiliated with big tech companies and their civil society critics.
To this end, we have worked with UK-based experts in ‘AI and society’ to identify, qualify and evaluate the most important and possibly overlooked controversies about AI in the last 10 years, as seen from the UK. We asked: which public controversies about AI during this period achieved its problematisation, and how was this done? To answer our question, we adopted a critical methodology of controversy elicitation. To prevent our AI controversy analysis from merely reproducing the strategic corporate discourse about future risk and harm, we used techniques of controversy mapping to selectively identify AI controversies with the potential capacity to articulate problems with AI across the divides between industry and civil society, or more minimally put, between science and non-science. We implemented this approach in a mixed methods research design, which combined online consultation with Twitter analysis and a participatory design workshop with AI and Society experts from across domains. As we will discuss, this approach led us to identify two distinctive features of recent controversies about AI: (1) Many significant AI controversies involve the mobilisation of what we call ‘AI frictions’: concrete incidents such as erroneous arrests based on incorrect facial recognition intelligence, technical demonstrations of bias in operational algorithms such as in recruitment, and walk outs by outraged tech company employees. (2) This proliferation of AI frictions, however, does not entail the fragmentation of AI controversy, but rather provides occasions for the articulation of AI as a ‘super-controversy’: in AI controversies, any individual dispute is inexorably chained to a variety of other (overt and latent) problematics in and across research and innovation communities, government and public sector and wider societies. We argue that AI frictions enable a distinctive mode of problematising AI across science and non-science, one that links technological propositions with experienced harms and structural problematics in the areas of social justice, knowledge politics and political economy.
How to uncover the capacity of AI controversies for problematisation across the science/non-science binary?
Recent scholarship has drawn attention to the appropriation of critical discourse about technology and society by the contemporary tech industry. Phan and colleagues (2022) describe how, when AI scientists at Google like Timnit Gebru publicly contested the company’s lack of commitment to addressing the societal harms and risks associated with the LLMs it was developing, the effect was not to endanger the company’s reputation. Instead, issues of risk and harm became ‘ethicised’ and corporatised: they were reframed by the company as concerns that could be dealt with via internal processes centred on values rather than regulation. Appropriation of the vocabulary of societal risks and harms of technology can also be discerned in contemporary scientific discourse on AI. For example, the computer scientist Percy Liang observed during his introduction to the ‘Foundation Models’ workshop at Stanford University in 2021: ‘what I am seeing today is the very beginning of a paradigm shift, [in the area of large language models] and I think this paradigm shift is going to have profound implications […] there will also be heavy social consequences that will result from each technological decision’. 7 Such affirmations that LLMs and indeed subsequent generative AI models create new societal risks and harms by AI proponents point towards a radicalisation of a recent argument by Geiger and colleagues which states that in contemporary capitalist societies, controversy about science and technology increasingly serves as a valuation strategy: a way of opening up markets for new products and mobilising public concern to create a community of attention for said products (Geiger et al., 2014).
In Geiger et al.’s accounts, techno-scientific controversies are increasingly deployed towards promotional ends. In the last decade or so, controversy has acquired a ‘positive’ association with the tech industry's notion of disruption (Geiger, 2020), the Schumpeterian idea that innovation done well is destructive of existing societal arrangements and will challenge social conventions. An example of this is Google Glass, which was widely reported in the media as controversial because of the fundamental concerns with privacy and surveillance raised by these networked wearables equipped with Facial Recognition. Reviewing these controversies, the tech magazine WIRED concluded: ‘Google Glass wasn’t a failure… it raised crucial concerns’. 8 This affirmative understanding of controversy as valuation stands in tension with earlier framings of controversy in Science and Technology Studies (STS), which defined it as an enabling occasion for the democratisation of research and innovation (Callon et al., 2011). From this perspective, public disputes about techno-scientific innovations, like nuclear power and genetically modified foods, enable (1) the expansion of the range of actors and competencies involved in the definition of techno-scientific risks and harms (inclusion), and (2) a process of the collective articulation of complex problems at the intersection of science innovation and society which are partly uncertain and affect different groups in society in divergent ways (‘problematisation’). The strategic assertions of AIs controversiality by AI companies and scientists do not fit this picture at all. Instead of opening up the debate about the socio-technical problems posed by AI to outsiders, these statements reassert the authority of scientists and company insiders to define techno-scientific risks and harms. Instead of facilitating the problematisation of AI in the sense of surfacing its complexity, uncertainty and heterogeneous effects in society, these assertions present attempts to consolidate the definition of AI as objective reality, in line with Samuel Johnson's old empiricist dictum that if it hurts, it must be real (Patey, 1986; on this point also see Kak and Meyers West, 2023).
In other words, the strategic use of AI's controversiality threatens the role of public controversy as a force of the democratisation of research and innovation, and risks to undermine its capacity for inclusion and problematisation. The reasons for this are surely complex. For one, artificial intelligence (AI) research has been marked since its inception by oversized, objectivist claims about its existential impact on humanity, claims which partly served as displays of scientific authority and prowess (Suchman, 2023) Yet, as Kling argued in Computerization and Controversy (1996), in earlier decades controversy about automation did provide important occasions for the collective definition of social problems in compute-intensive societies, enabling the articulation of ‘key value conflicts and social choices’ (Kling, 1996: xiv) concerning the future of work, surveillance, privacy and problems of bias, as a way to ‘articulate the different sides of key debates’ (xxi), and more generally, to foster a greater appreciation for ‘computerisation’s key social dimensions’ (xxii). Strikingly, many of the issues flagged by Kling and other contributors to this volume mirror today’s problems associated with AI. But where Kling could still claim—in 1996—that the societal issues raised by the computerisation of society ‘have not received due attention’ (xxii), today’s media seem flooded by statements to this effect. News media today endlessly circulate ‘explainers’ about why AI is controversial, as in the WIRED article on Google Glass above, and they are awash with reports of the societal harm that AI will or will not cause in the form of job losses and worker exploitation, discrimination by algorithm—as when UK students had their General Standard of Secondary Education (GSCE) marks downgraded by algorithmic rebalancing—and disinformation and deepfakes that will sabotage democratic elections. However, it seems to us this mass reporting on AI's harms to society does not qualify as a collective process of problem articulation. Recent studies of AI media discourse in France and Canada have shown that this discourse instead consolidates the binary that AI will either solve societal problems or cause epic harm (Crépel et al., 2021). And far from widening the range of voices involved in AI debates, the hyperbolic reports on AI benefits and risks that dominate the news media feature primarily scientists and industry representatives (Dandurand et al., 2022).
This situation not only has implications for our understanding of AI controversies as occasions for the democratisation of knowledge; it also has consequences for the methodology of controversy analysis. Since the early 20th century (Mannheim, 2015 (1936)), knowledge controversies have been valued as empirical occasions for exploring wider relations between science and society: whenever there is sustained disagreement in and about science—is light a wave or a particle? Is nuclear power safe?—the boundary between scientific insiders and outsiders is troubled, and new ways of framing the phenomenon in question become possible. Inspired by this insight, sociologists of science and technology developed the methodology of ‘controversy analysis’ from the 1970s onwards. Actor-network theorists defined controversies as opportunities for the empirical observation of science-society interactions: as controversies compel the actors involved to account for their positions in the dispute, they are led to make their relations explicit and, thus, describable by social researchers (Latour, 2005). This approach provided the basis for online controversy mapping, an approach that uses techniques of data analysis and visualisation to create representations of issues that are publicly contested in digital media (Rogers and Marres, 2000; Venturini and Munk, 2021). However, in the case of AI, assertions of controversiality do not seem to have the illuminating empirical effect that controversy analysis used to rely on: corporate and expert discourse about ‘AI risks’ has the effect of rendering civil society critiques of AI less visible and push debates about the political and economic interests of the tech industry into the background (Stark et al., 2021). Assertions of AI’s controversiality by its proponents exhibit features of a ‘pseudo-event’ (Parks, 2021): an orchestrated publicity moment where ‘nothing happens’, an artificial rather than an empirical occasion. There is no lack of expert contestation and societal debates about AI, but as long as we ‘merely observe’ the unfolding of AI controversies in popular and scientific media, as controversy mapping said we should do, we are most likely to capture strategic—not expansive and problematising—assertions of AIs controversiality.
How, then, to analyse public controversies about AI under these conditions? In this context, we propose, the task of controversy analysis is not to ‘describe’ the positions and relations of actors involved in AI controversies, but rather to undertake an active search for problematisations that AI controversy may still be giving rise to today. That is, our hypothesis is that AI controversies today continue to provide opportunities for the democratisation of science and innovation, by expanding the range of actors involved in AI debates beyond a narrow range of insiders and for the shared articulation of complex problems. However, such problematisations seem today in many cases crowded out in public discourse by promotional deployments of AI's controversiality, which use the language of AI harms and risks to consolidate the authority of techno-science and the reality of AI. We ask: how to uncover controversy’s capacity for the problematisation of science and technology, in a context in which predominant debates about the benefits, risks and harms of contemporary AI seem focused on the consolidation of AI as an objective reality? If, generally speaking, promissory and eschatological framings of AI appear to dominate media discourse, how can we identify AI discourses that enable articulation and contestation of what is problematic about AI across industry, science, media and society?
Methodology: From the observation to the elicitation of AI controversies
It was clear to us, then, that if we wished to attend to societal processes of the problematisation of AI, we would need to diverge from predominant approaches in controversy mapping. Contemporary AI controversies do not fit the model of a generative empirical occasion: prominent media and expert debates about AI cannot be relied upon—in and of themselves—to bring to the surface qualifications of the societal consequences of AI or to make explicit actors’ relations and interests. The usual research strategy of controversy mapping, which is to query online media for controversy terms such as ‘Nuclear waste’ or ‘GM foods’, and then to document the positions that actors take on the issue on Web pages and in social media, does not work in this case (see also Munk et al., this volume). Indeed, Twitter data that we collected using the query ‘AI’ between December 2018 and March 2021—which came to 36 million tweets—seemed to us unsuitable for controversy mapping: on initial exploration this data set appeared to contain lots of publicity and little debate. If we were to use this data to create a ‘controversy map’, there was a real risk our analysis would merely end up reproducing solutionist and doomsaying claims about AI—and their associated authority and reality effects—without surfacing articulations of AI as a collective problem. To locate the latter, we decided, it was necessary to shift from the description to the elicitation of AI controversy. Declining to adopt the empiricist posture of patiently tracing contestations about AI wherever they emerge, we instead decided to draw on design research methodology to devise strategies to actively elicit a distinctive type of controversy about AI: controversies with the capacity to problematise AI across the science-non-science divide.
9
Design researcher Donato Ricci offered this helpful summary of this methodological re-orientation of controversy mapping: If we [typically] spend a great deal of time to seek the sources, detail the protocols and produce visual manipulation[s] to identify “
To structure this process of controversy elicitation, we adopted the following three-step research design: first, we actively configure a context for AI controversy elicitation, by inviting a specific community of experts to assist us in the identification of relevant controversies. As it is our objective to surface problematisations of AI across science and non-science, we decided to consult UK-based ‘AI and society’ experts. In a second step, we qualify AI controversies: we define the type of topics and incidents that the consultation surfaced and the problematisations of AI they entail. Next, we analysed selected AI controversies using social media methods and follow-up interviews, to assess the extent to which they generated problematisations, facilitated contestation and compelled exchange between heterogeneous actors. In the third and last step, that of evaluating AI controversies, we invited UK-based AI and society experts into a design-led workshop, where we worked together to create novel diagnoses of selected AI controversies and their capacities for problematisation.
Convening an extended expert community in the UK: What are the most important and possibly overlooked controversies about AI in the last 10 years?
To initiate our analysis of AI controversies, we began, as is customary in controversy mapping, with a ‘query’ (Rogers, 2017). However, our initial query did not involve selecting and submitting a set of keywords to an online platform API, such as Twitter's, but rather took the form of an invitation email that we sent to 250 UK-based experts in ‘AI and society’. Our decision to focus on this community was in part informed by (1) our role in the international Shaping AI consortium, a project in which we had taken on the task of mapping research controversies about AI for the period 2012–2022 beginning with the UK, and (2) by the notable presence of civil society organisations active in this issue area in the country. 10 We thus began by selecting actors with demonstrable expertise in AI and society, which we did by identifying speakers and registered participants at academic and professional events on the broad topic of AI and society in the UK between 2021 and 2022, and which included academic, industry and civil society conferences and workshops. 11 In so doing, we followed the STS assumption alluded to above, that the capacity of controversy about technoscience to surface emergent definitions of harm and risk is in part a consequence of inclusion, an effect of the involvement of a wider range of actors in the debate about uncertain and problematic science and innovation. In line with this assumption, we adopt a broad definition of ‘experts in AI and society’, whom, following Funtowicz and Ravetz (1991), we define as members of an ‘extended peer community’ and includes all ‘those with a stake in an issue who are committed to genuine debate’ (Funtowicz and Ravetz, 1991: 170).
Our respondents included civil society advocates and activists (Amnesty, EDRi, Article 19), civil servants from AI-related government units (Information Commissioner’s Office, Centre for Data Ethics and Innovation, NHSX), academics with backgrounds in digital humanities, social science and computer science and industry (AstraZeneca, DeepMind), the arts (Serpentine Galleries; Ambient Information Systems) and journalism (BBC, TechCrunch). That is also to say, our research design did not specifically target institutional outsiders, but rather focused on actors who are involved in the articulation of AI harms, risks and benefits in ways that cut across the science/non-science binary. To counter-act authority effects, our consultation explicitly encouraged respondent to give their own perspective on what makes AI controversial asking: (1) ‘What in your view are the most important, and possibly overlooked, controversies about AI in the last 10 years’ (italics ours)? To enable us to explore their answers further, we added another question: (2) What are notable moments, publications and/or individuals associated with the controversies mentioned? To get at underreported issues associated with AI, we asked: ‘Are there other controversies or problems in and with AI research that you believe should be considered as part of our study?’ The first round of the consultation was sent out in November 2021 and completed by 53 experts.
We identified three different types of responses to our consultation, which broadly correspond to the three questions we asked. A first set identifies (1) ‘controversial topics’, broad areas in which controversial AI developments take place, such as ‘Algorithmic decision-making’, ‘AI warfare’ and ‘Environmental costs’ (see Figure 1). A second set of responses mentions specific sites, incidents, events and objects of contestation, concrete instances in which AI caused disruption, trouble and, in several cases, demonstrable harm in society (Amazon’s biased hiring tool; data transfers without consent between the Royal Free Hospital and DeepMind; the persecution of Uighurs in China). We named these latter instances (2) ‘frictions’. Building on Meunier et al.’s ((2021); see also Shaffer Shane, 2023) work on ‘algorithmic trouble’, we use the term ‘AI friction’ to denote instances of AI-related harms occurring in specific environments in society (roads, hospitals and schools), as distinct from more abstract and de-localised societal risks. In a third and last set of cases, respondents offered (3) problematisations of AI, which we loosely defined as answers to the question ‘what is the problem with AI?’; and more specifically, we understand as attempts to articulate underlying contestations, difficulties and suffering associated with AI that arise at the limit of discourse (Barry, 2021) and which it may be challenging to name (two examples from our consultation: ‘The claim that AI exists today’; ‘Deploying non-transparent systems to make decisions that directly affect people’s lives’).

Frequency of occurrence of AI controversy topics in the UK expert consultation (Autumn 2021).
Especially striking in our results was the prominence of the aforementioned ‘AI frictions’ among the responses. While our consultation asked respondents to identify ‘controversial developments’ and ‘controversies’ in and about AI, a significant number (41 out of 53 respondents) identified concrete incidents involving AI in society: traffic accidents involving automated vehicles, the use of racially biased facial recognition by the South Wales and Metropolitan police, the downgrading of GCSE marks by algorithms during the UK ‘exams fiasco’. It suggests that in the area of AI and society, ‘controversy’—in the sense of the staging of public disagreement about a specific knowledge proposition—may not be the main form of contestation of AI, with the emphasis placed, instead, on the demonstration of concrete instances of AI-related harm to specific groups and institutions in society (students, BAME, the National Health Service (NHS)). Also striking, we found, is the comprehensive range of societal domains identified in the responses, which ranged from law enforcement, health, transport, the welfare state, education, media, democracy, the economy (including recruitment and work) and sports. This broad range of application domains—which is nearly coterminous with society—has been identified as a sociological feature of digital innovation (Lupton, 2014), but here it emerges as a feature of public controversy about a digital ‘object’, AI. This feature, too, stands in contrast to techno-scientific controversies of earlier decades, which tended to be limited to specific societal domains (GM foods connect across agriculture, health and economy; nuclear technology associates environment, energy, human rights and the military).
Our initial consultation results suggested to us that AI may qualify today as a super-controversy: AI controversies do not only take the form of public contestation of specific techno-scientific propositions, but arise from the linkage of specific instances of harm and risk arising in society with technical propositions and wider, structural concerns. However, it is important to note that the consultation also surfaced several knowledge controversies in the more familiar sense of the term, that is, public contestation of expert claims. The most frequently mentioned controversial development was facial recognition, a topic which gave rise to public disagreements in the UK from 2018 onwards as civil society and academic experts asserted that facial recognition systems in use by the Metropolitan Police fail to meet accuracy standards, while the Metropolitan Police released an evaluation report which concluded that its facial recognition systems are accurate and not racially biased. 12 Mentions of other notable topics in the consultation, such as tracking and targeting, data and corporate research culture, equally include references to expert disagreement as in the case of the legality of data transfers without consent between the NHS and DeepMind, and to debates about controversial research papers like the Stochastic Parrots article by Bender, Gebru et al. discussed below.
Next, we made a distinction between controversy topics in terms of the degree to which they elicited detailed problematisations in the consultation, as opposed to only being indicated as a keyword, such as ‘surveillance’. What stood out here for us is that, while some respondents focus on specific problems (‘pseudonymisation not fit for purpose’; lack of consent for the online scraping of personal images by AI companies), many others specify AI's controversiality in relation to wider, structural problems such as racism, privatisation of the public sector, scientific integrity and lack of trust. Facial recognition is associated with the unlawful use of technology in the public sector, as well as ‘bad science’ and persistent racial and gender biases. Problematisations associated with ‘corporate research culture’ included references to toxic working environments in corporate AI research leading to the suppression of independent research. All these problematisations foreground power dynamics, and many refer to entrenched societal inequalities. However, it proved difficult to categorise problematisations, and we therefore left these aside for the time being.
To pursue the exploration of AI as a ‘super-controversy’, we proceeded to delineate AI controversies by identifying couplings of (1) frictions and (2) controversial topics from among the consultation responses.
13
We thus adopt a relational, data-driven approach to analysing AI ‘controversy couplings’ (Costas et al., 2021) and define the empirical object of our study as AI’s controversiality: we deliberately leave open the question of the form and formats that AI controversies take on in the empirical settings in which we investigate them, making this a question rather than an assumption in our research. To select AI controversy couplings for further analysis from the many couplings identified through our consultation, we relied on the criterion of ‘research intensity’. As Question 2 of the consultation asked respondents to provide links to publications relevant to the controversy in question, we adopt a simple frequency count of associated research publications—in which we included investigative journalism, as well as civil society reports—as a way to identify AI friction-topic couplings for further research (see Figure 2). Also taking into consideration the spread of controversy friction-topic couplings across different expert communities and societal domains, we selected the following five controversies for further analysis:
Correctional Offender Management Profiling for Alternative Sanctions (COMPAS): a controversy about algorithmic discrimination in judicial systems sparked by the ProPublica (Angwin et al., 2016) report ‘Machine Bias’. NHS + DeepMind: a controversy about data sharing between UK public sector hospitals and big tech sparked by the Powles and Hodson (2017) paper on Google DeepMind research in the Royal Free. Facial recognition (Gaydar): a controversy about the use of machine learning-based image analysis to predict sexual orientation sparked by Wang and Kosinski (2018). LLMs (Stochastic Parrots): A controversy about bias in large neural network models for encoding and generating text, sparked by Bender et al. (2021) ‘On the Dangers of Stochastic Parrots’. Deep learning (DL) as a solution for AI: a controversy about the capacity of DL—the use of trained multilayer neural networks with large numbers of weight parameters—to sustain the claims of artificial intelligence research (Marcus, 2018).
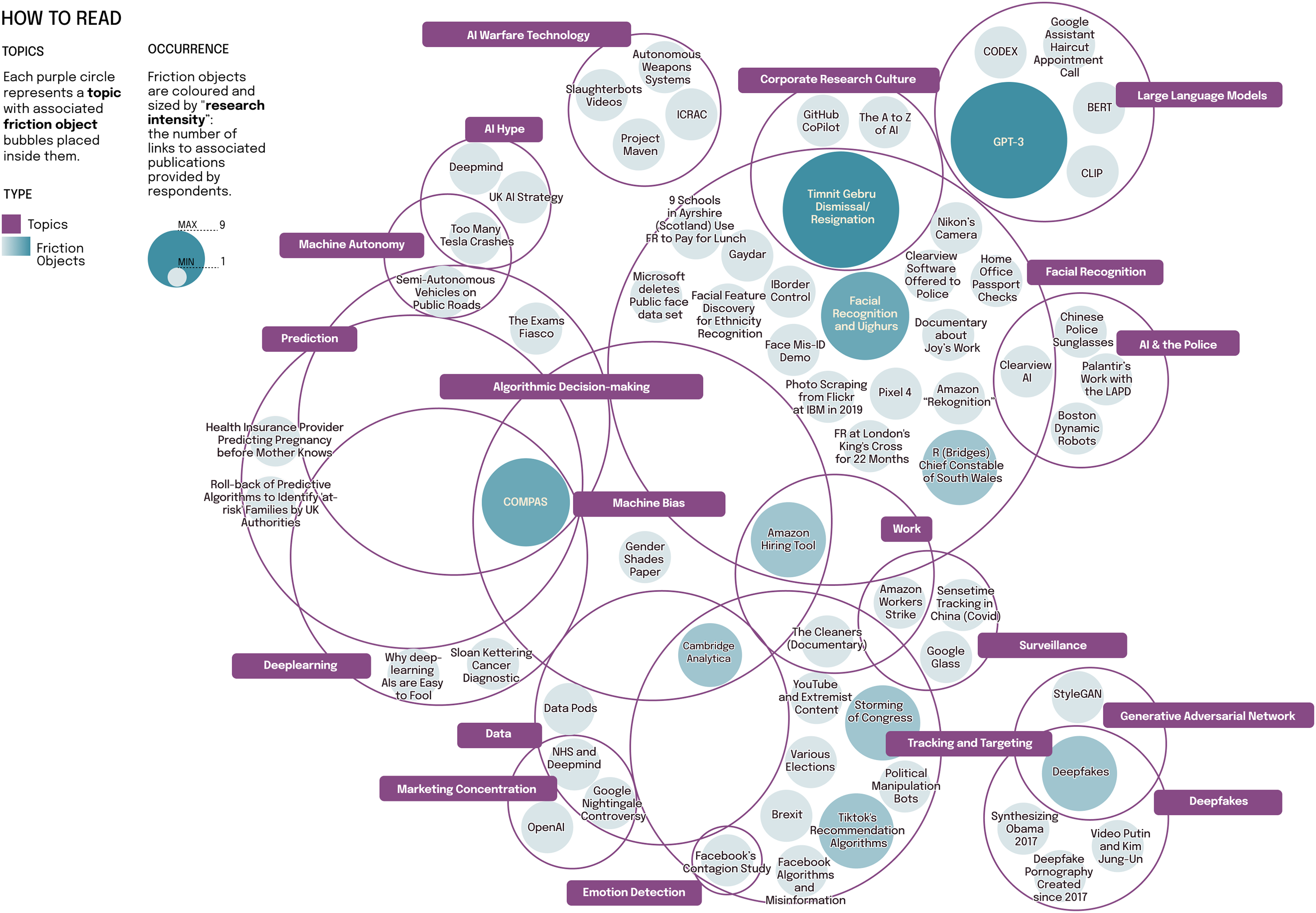
Friction-topic couplings identified in the expert consultation ‘what is controversial about AI?’ Autumn 2021.
AI and society controversies on Twitter: Levels of disagreement, actor composition, forms of engagement
Having identified these five controversies, our next step was to analyse whether and how these controversies enabled the problematisation of AI across the science/non-science binary. Follow-up interviews with participants in the online consultation offered some indication of the relevance of this focus. In relation to the controversial collaboration between the NHS Hospital the Royal Free (London) and Google subsidiary DeepMind, one respondent noted: ‘I think that's what happened with the NHS thing… [i]t sort of broke out of the confines of people who were interested in AI and privacy into something which had more general currency’ (Interview 14EH); another noted that ‘[T]he Google DeepMind Royal Free thing applies to my university. And I've spoken with people at my university here and I speak to people at DeepMind, basically, they don't see what the fuss was about… [s]o there's a really interesting… important point about who actually does learn lessons from this stuff’ (Interview 22JS). To ensure we captured the unfolding of AI controversies across societal domains, we decided to conduct the next step of our controversy analysis with Twitter data. Not only is Twitter a tried and tested setting for controversy mapping (Burgess and Matamoros-Fernández, 2016; Madsen and Munk, 2019), but at the time we conducted this research it was still a notable site of intersection between academic, journalist, activist and industry debates. Our interviewees confirmed this understanding of Twitter as a prominent forum for tech controversies during the relevant period (2012–2022), alongside discussion forum and instant messaging platform Reddit and Discord. They referred to Twitter as a site that ‘has enough experts, it’s open, [and] general’ (Interview 12SL); ‘[i]t gives you a feel for an issue’ (Interview 14EH), although we were also reminded that ‘there’s a huge amount of virtue signalling in terms of what you argue with people about [on Twitter]’ (Interview 13CR).
We created tailored Twitter data sets for each of our five controversies, by designing Twitter API queries to capture discussions about the controversial publications identified through the consultation (see Figure 3). 14 Next, to make sure our data sets were pertinent to our selected AI controversies, we manually classified ‘conversations’ in the datasets as in scope or out of scope. 15 That is also to say, at this stage of our research, we chose as our unit of analysis the ‘conversation’ as defined by the Twitter API: strings of replies generated by a single tweet, which can be visualised as a descending, inverted ‘tree’ structure of replies from a given ‘origin tweet’ (Nishi et al., 2016). The guiding concern in our Twitter analysis remained with the generative capacity of AI controversies, as outlined in Section 2: to what extent do the papers in question enable the problematisation of AI on Twitter through sustained disagreement about determinate propositions among actors from diverse backgrounds (science and non-science)? We asked: what problem definitions in relation to AI are surfaced through exchanges within extended expert communities on Twitter? To what extent do these exchanges involve heterogeneous actors, cutting across science and non-science? To answer these questions, we analysed conversations in four dimensions: topics, levels of disagreement, forms of engagement and actor composition.

Twitter data collection for five AI research controversies.
We begin by coding conversations for controversy topics, which first of all reveal significant shared concern across all controversies with ethics, knowledge and social justice. 16 Other frequent themes are political economy as well as data and data protection (see Figure 4). Speaking generally, this topic distribution is not dissimilar from our consultation findings. On Twitter, too, the impacts of AI deployments on disadvantaged communities featured as an especially prominent topic, as did the corporate ownership of AI infrastructures and related barriers to the evaluation and regulation of AI in society. Data featured prominently both in debates about rights (privacy) and regulations (including GDPR) as did epistemic challenges of reliability and transparency of data processing within AI-based infrastructures. Epistemic concerns about the quality of outputs of AI systems, and lack of adherence to standards of scientific rigour in AI research also featured in many conversations, topicalising scientific quality. All controversies, finally, gave rise to society and justice debates, which define harmful impacts of AI on society in terms of discrimination, entrenched privilege, racism and societal inequality.

Most frequent themes across the five Twitter controversies.
We next tried to establish the degree of controversiality of the identified topics, which we did by coding all in-scope conversations for the level of disagreement, and then assigning these codes to the topics addressed in these conversations (see Figure 5). 17 Perhaps unsurprisingly, our analysis shows that there is a general trend towards disagreement: topics in all controversies tend to be placed towards the more contentious rather than non-contentious end of the spectrum. We note that the level of disagreement is correlated with the volume of tweets produced on a certain topic: In COMPAS, the three largest topics by volume—bias, prediction and racism—tend to appear in conversations with higher levels of contention. To further qualify the controversiality of topics, we considered the ‘levels of engagement’ for each conversation: the degree to which conversations elicited long and/or wide threads of replies on Twitter (more about this below). We found that contentious topics do not automatically correspond to a high level of engagement. It is true that in COMPAS, Parrots and DL as a solution for AI, the top topics by engagement tend to lean towards higher levels of contestation. However, we found the highest level of disagreement for science-related topics that belong to the theme of knowledge (light green in the visualisation), and secondly, in topics relating to society and justice (in black), political economy (in blue) and bias (in orange).
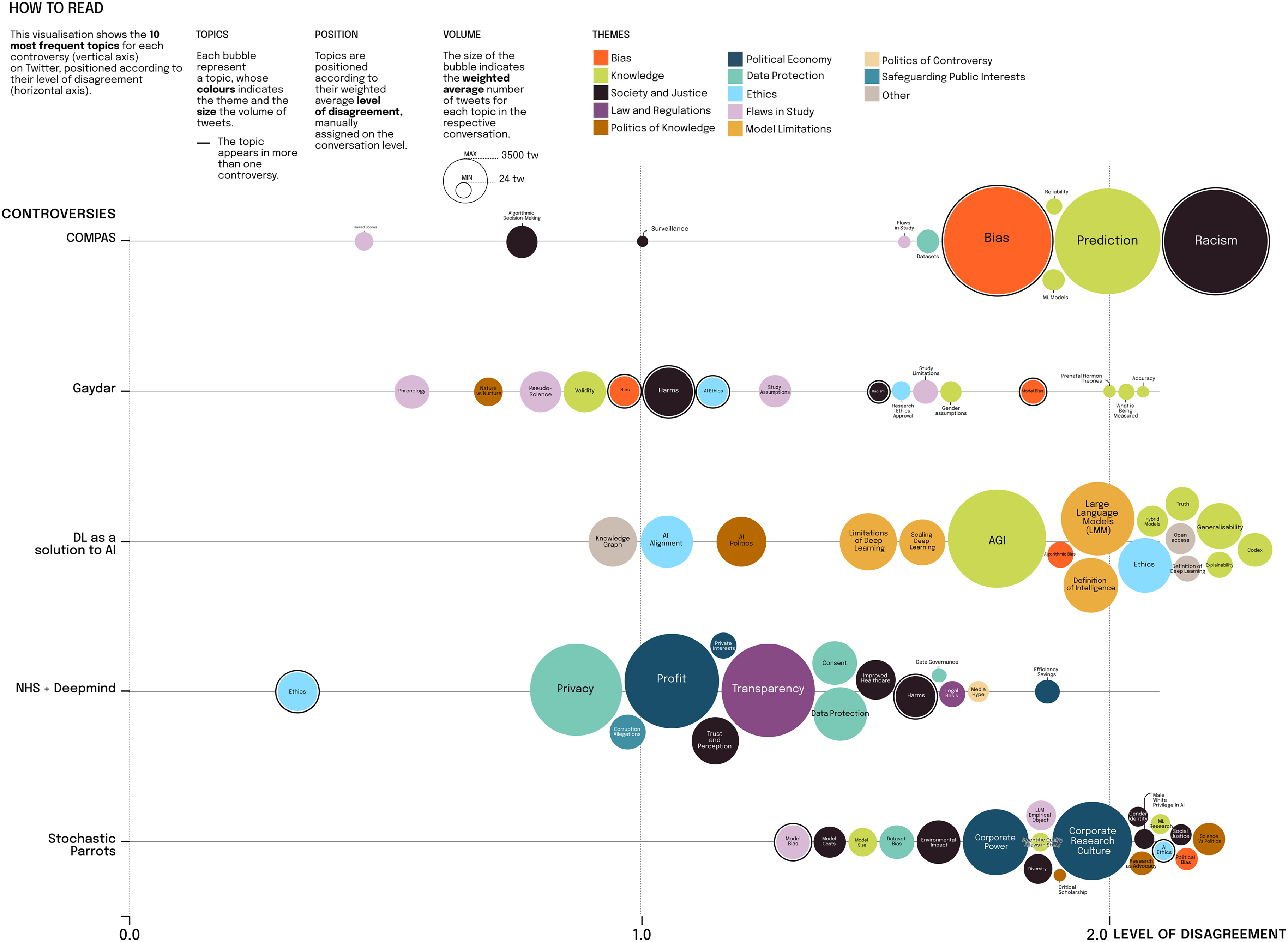
Distribution of the most frequent topics per controversy according to their level of disagreement.
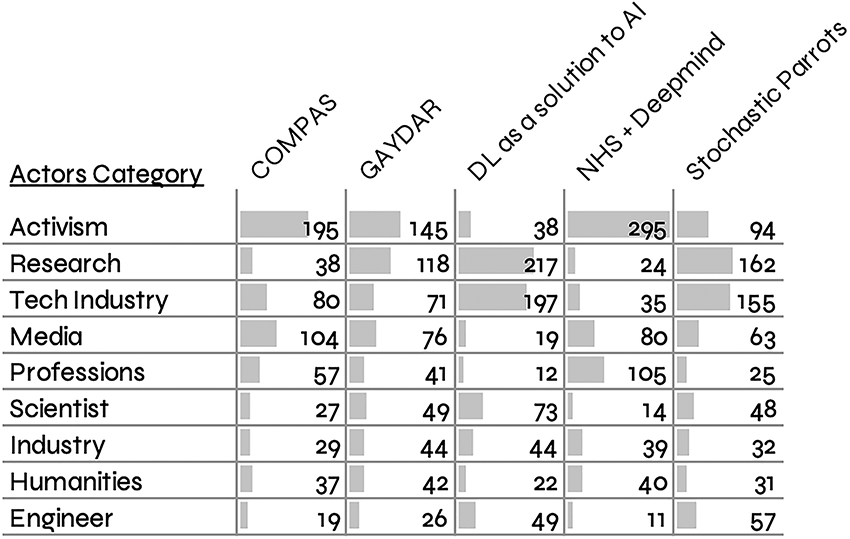
Next, we examined the extent to which our AI controversies on Twitter facilitated interaction among heterogenous actors, that is, exchanges across the science/non-science binary. To this end, we categorised the Twitter accounts contributing to each controversy using basic occupational categories (see Table 1). 18 We found that only a very small number of Twitter accounts appear in more than one controversy, suggesting that our five controversies mobilised different Twitter ‘communities’, which is noteworthy in the light of the high topic similarity between AI controversies on Twitter in Figure 4. Considering the size of actor categories across controversies, we can see that some controversies lean more towards the ‘activist/media side’, such as COMPAS, and others more towards ‘scientific/research’, such as DL as a solution for AI, and some are hybrid, such as the Parrots and Gaydar controversies which bring together researchers and activists. NHS/DeepMind is the one controversy where professions (health) are prominent (see Table 2), and policymakers are relatively absent in all the Twitter controversies. As such, these findings demonstrate a truism from the sociology of knowledge, which states that the content of a controversy aligns with actors’ positions in society (Barnes, 1977), more about which below.
Actor categories across controversies according to a zero-shot actor classification using a GPT-3.5-series model (see Footnote 18).
Main topics of disagreement, main actors and overall form of engagement in selected AI research controversies on Twitter.

Finally, the calculation of ‘levels of engagement’ for conversations enabled us to explore the extent to which AI controversies on Twitter enabled a widening of engagement with the issues at stake (inclusion) and the degree to which they instigated processes of problem articulation (problematisation). We took the ‘width’ of conversations—many different users replying—as an indication of the broadness of engagement, and ‘depth’—long reply chains—as a mark of sustained engagement in the articulation of issues. 19 We found that the COMPAS controversy on Twitter was comparatively inclusive, while the Stochastic Parrots controversy evinced the most sustained engagement, suggesting more active involvement in problem articulation as a collective process. We note that, according to this measure, inclusion is marked by a ‘reaction democracy’ (Gerbaudo, 2022) logic of bursty but brief engagement, while the longer shapes—sustained articulation—are associated with strong, arguably more elitist, participation from researchers in controversy. We visualised this finding by assigning an overall impressionistic shape to each controversy: controversies of which conversations on balance exhibit a high width have a broad appearance, whereas those with higher depth are characterised by extended length (Figure 6).

Forms of engagement: the ‘shapes’ of AI controversies on Twitter.
As to the overall findings of our Twitter analysis, we are especially struck by the strong emphasis on societal problems (racism, inequality) and political economy (market concentration, data appropriation) in the selected AI controversies, which aligns with the findings of our consultation. However, on Twitter, we also found a strong engagement with epistemic issues, in the form of concern with scientific integrity and the science/politics tension (research vs. advocacy) in AI research. The focus on these topics correlates with the social positions of participants in the controversy: epistemic concerns are topicalised in controversies with prominent participation of researchers, while controversies with strong activist engagement are more concerned with issues of regulation, ethics and justice (Table 2). While this alignment between discursive content and social position is something social studies of scientific controversy would lead us to expect (Barnes, 1977), a different aspect of AI and society controversies on Twitter does not align with this approach. Controversy analysts in STS have argued that techno-scientific controversies surface complexity and thereby disrupt received scientific and societal problem definitions (Callon et al., 2011). But AI and society controversies on Twitter rather seem to mobilise established scientific and societal issue frames (transparency, pseudo-science, racism, inequality). Should we conclude that AI and society controversies on Twitter consolidate entrenched problem definitions? In the conclusion, we will reflect on the significance of this for our understanding of AI and society as an area of super-controversy.
Materialising AI controversies: shaping controversies with design-led participatory methods
We cannot forget of course that Twitter analysis provides a highly partial perspective on AI controversies. Our Twitter research, just as our consultation, captured particular instances of controversy: for example, the COMPAS controversy on Twitter was dominated by reactions to a celebrity politician, AOC. 20 In reality the controversies in question unfolded across many different settings: for example, the COMPAS controversy served as an exemplary case study in policy communities (Selbst et al., 2019) while notable DL controversies were on display during the ‘AI Debates’ periodically held in Montreal in December of 2019, 2020 and 2022. The Stochastic Parrots controversy is arguably the only one of the five selected where Twitter served as the primary setting of controversy, but this one, too, has a far more complex topology: internal organisational processes at Google, including the firing of Timnit Gebru and walk-outs staged by Google staff are key events in this controversy. For this reason, we treat our Twitter analysis as providing an initial qualification of AI and society controversies in English-speaking contexts. In the next and last step of our analysis, we used our Twitter data mappings as a starting point for the evaluation of AI controversies during a participatory workshop with AI and society experts.
A central feature of our methodology of controversy elicitation is to mobilise the standpoints of a situated community of experts to activate a collective process of problem articulation, which is a key affordance of controversy. In a design-led collaborative workshop that we organised in March 2023 in London (Figure 7), we took this process of situated elicitation of controversy one step further by inviting 35 UK-based AI experts from science, government, industry, activism and the arts, many of whom were respondents to our initial consultation, to a design-led participatory workshop. Drawing loosely on methods of evaluative inquiry (Marres and de Rijcke, 2020), we designed a diagnostic exercise, in which we worked with participants to assess the five selected AI controversies in terms of inclusion and problematisation: the extent to which they offered opportunities for participation, made visible problems with contemporary AI, and enabled shifts in the balance of power within the wider domain of AI and society. During the workshop, the invited experts worked together in five small groups to evaluate the five controversies, supported by material props.

Shifting AI controversies: shaping and reshaping AI with experts in AI and society, Friends House London, 10 March 2023.
After having been introduced to the five controversies, participants worked with a diagnostic tool that we had designed specifically for this purpose—dubbed the ‘controversy shape shifter’—to determine the ‘shapes’ of the selected AI controversies. Asking participants to cut paper strips to different lengths that corresponded to values assigned to controversy parameters, we invited them to determine: the relevance of the issues addressed, the degree of participation, the location of the controversy (situatedness), and the allocation of responsibility for addressing the problem (power and solvability) (see Figures 8 and 9). We offered the participants an explicitly normative overall framing for this evaluative exercise, by asking them to tell us: is the controversy in question in good or in bad shape? To support their evaluations, we provided participants with controversy ‘dossiers’, which included a timeline of events, an actor list, key documents and the Twitter analysis for each controversy. On this basis, they determined the controversy’s ‘shape’ by assembling long and short strips of cardboard guided by the evaluative grid.

The evaluative grid composed of five parameters: relevance, situatedness, power, participation and solvability.

Shaping of the DL as solution for AI controversy by AI and society experts.
Participants were also encouraged to add notes to their shapes—annotating the cardboard with pens—summarising their evaluations based on either the dossiers provided or their own knowledge and experience.
For the purposes of this paper, we want to highlight one important result of this process of shaping AI controversies. Many participant annotations drew attention to the fact that AI and society controversies operate on two levels at once. On the one hand, they uncover highly specific issues raised by AI systems (e.g., a flawed data sharing agreement between public sector and industry organisations; a problematic internal approval procedure for academic publication in the tech industry) but, on the other hand, they expose major structural problematics (the politicisation of science, abuse of power and inequality). While the COMPAS case, for example, focused on the racial bias of this scoring software and its underlying data against ethnic groups, the controversy equally exposed how the use of algorithmic systems in the public sector amplifies entrenched racial inequalities. The NHS + DeepMind case dealt with technical requirements on the legality of data sharing agreements (which were not adhered to in this case), but simultaneously flagged a major structural challenge of AI to both national and international public policy communities, namely the appropriation of public sector data by private companies, as well as growing Big Tech's control over the creation of public sector data infrastructures.
During the workshop, debates about DL as a solution for AI highlighted the role of everyday publics in the creation training datasets for neural networks through their digital participation. Also, what appears as a technical debate about the ‘architecture’ of predictive models turns out to have massive legal ramifications regarding the applicability of contemporary copyright law to data infrastructures in society. The Gaydar case's controversy about the use of neural networks to predict sexual orientation raised a major issue of societal harm by demonstrating that AI analytics could be used to expose people's vulnerabilities, but also highlighted that scientists seek to take advantage of specific ‘hype’ dynamics to attract attention to their publications. Finally, the Stochastic Parrots controversy was perhaps the most dense in its articulation of intersecting societal problematics, highlighting ecological impact (the energy cost of training LLMs), the marginalisation of ethical considerations in research debates, and the roles of women in corporate AI research. This suggests to us that AI and society controversies, while not necessarily unsettling established problem definitions in science and society, nevertheless articulate unsettling connections between technical applications of AI, experienced harms and structural societal problematics. These sometimes unexpected linkages found through the exploration of the selected controversies led us to characterise the topic of AI as an impressively generative ‘super-controversy’.
Conclusion
Our examination of AI and society controversies via an online expert consultation, Twitter analysis and an evaluative workshop has enabled the elicitation of AI controversies in the following ways. Our online consultation with UK-based experts suggests that recent controversies about AI and society not only consist of public disagreements about knowledge propositions (is AI accurate? How do we know it is safe?) but involve demonstrations of socio-technical frictions in society: occurrences, events and applications that instantiate the harm that AI does and could do in concrete places, with impacts on specific social groups, involving the products of specific companies. But the prominence of AI frictions does not mean that AI and society controversies are fragmented. Many of these frictions offer demonstrations of entrenched institutionalised discrimination against ethnic minorities and women amplified by the uptake of algorithmic systems in the public sector (COMPAS; the UK exams fiasco, the use of facial recognition by the police and in schools). Our Twitter analysis both consolidated and complicated this finding of the relative prominence of a situational demonstrational logic in recent English language AI and society controversies. On the one hand, social justice issues of racial/gendered inequality and entrenched privilege, as well as problems of political economy, such as the corporate ownership of the means of knowledge production, featured prominently among AI controversy topics identified on Twitter. But in this setting, the focus on societal friction in the problematisation of AI does not overshadow knowledge controversy: on Twitter we equally found AI to be the focus of contentious methodological and epistemological debates, with disagreements about rigour, scientific quality and the science/politics distinction being especially prominent.
We tentatively draw the following conclusions regarding the capacity of AI and society controversies to facilitate inclusion and problematisation across the science/nonscience binary. On the one hand, the AI knowledge controversies that we identified on Twitter demonstrate a degree of inclusion, in so far they mobilised experts across science, journalism, industry and activism on Twitter, However, representatives of affected communities did not feature prominently in them. It seems that it is especially through the type of controversy topics articulated in the controversies in question that the expert/non-expert boundary is crossed: these range from issues of social justice to scientific methodology, politics of knowledge, ethics and political economy. We note that classic societal—and indeed sociological—problems, such as societal inequality, and the demarcation between science and politics, play a central role in AI controversies, and arguably, are rendered publicly relevant through them (on this point, see also Roberge and Castelle, 2021). AI and society controversies topicalise classic themes from the sociology of knowledge—the social organisation of science, the role of underlying interests in the structure of knowledge, bias—and entrenched social problems: power differentials and privilege, discrimination and inequality. This contrasts sharply with the understanding of techno-scientific controversy as a force of problem articulation that shifts attention away from structural societal problematics such as class, race and gender (Latour, 2005) towards ‘single issues’, such as pollution or patient rights.
We therefore conclude that AI, despite the specificity of its techno-scientific arrangements and many of the associated problems, has acquired the status of a ‘super-controversy’ through AI and society disputes. Contrary to the expectation that public controversies about techno-science surface contingent problems, AI and society controversies instantiate and connect a range of structural concerns across epistemic, political, economic and ethical dimensions with AI. This could perhaps be observed most starkly in the Stochastic Parrots controversy, which actualised AI and society conflicts in the form of a located, personal experience of friction (‘Timnit Gebru fired’) and connected social justice arguments (white privilege) with technical debates about the meaning of ‘meaning’ (i.e., whether generative models ‘understand’ their outputs) and political economy (corporate control over knowledge production).
In such a super-controversy, problematisation does not just proceed through the creation of heterogeneous association between specific actors and entities, as actor-network theory suggested, but arises from the forging of connections between techno-scientific propositions (AI)-situated troubles and entrenched societal problems. The demonstration of AI frictions seems to play an enabling role in this. In this regard, their significance should not be understood solely in terms of the particularisation of AI-induced harm by associating these with specific persons, experiences, deployments and environments. Equally distinctive about AI frictions is their connective capacity: frictions demonstrate to wider publics how ‘AI’ as a complicated techno-scientific domain of application is, nevertheless, closely and intimately connected with society-wide phenomena, such as structural inequality. Through controversy, the firing of a single researcher can topicalise complicated connections between the political economy of knowledge production, social justice issues and epistemic issues of what constitutes scientific rigour. It is also to say that, in the face of the strategic affirmation of the controversiality of AI by its developers and backers, advocates and experts in AI and society have undertaken the problematisation of AI according to a different logic. We are tempted to call this logic ‘sociological’ insofar as it involves the demonstration of connections between specific technical propositions, contextual frictions and structural problems across social domains.
Footnotes
Acknowledgements
We would like to thank all the respondents to our online consultation ‘What makes AI controversial?’ as well as our interviewees and the participants in the ‘Shifting AI Controversies’ workshop, without whose expert contributions this research would not have been possible. We also thank our colleagues and students in the Centre for Interdisciplinary Methodologies at the University of Warwick who took on key roles to help realise the workshop. We are grateful to all Shaping AI teams for inspiring discussions.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the Economic and Social Research Council (Grant number ES/V013599/1).
Notes
References
 In
In