
Abstract
Age verification is currently gaining traction among some western democracies as a means to restrict minors’ access to online pornography. In this article we consider the ramifications of applying age estimation software to this task. We analyse a public dataset of 10,139 facial images processed through a commonly used high-performance convolutional neural network approach and find significant inconsistencies in classification performance. Notably, the software demonstrates racial bias, with highest accuracy for the Caucasian category and lowest accuracy for the African category. It also displays age and gender bias, with lower accuracy for young males compared to young females. In addition to underwhelming technical performance, we argue that the concept of employing automated processes to restrict access to pornography is not only problematic but fundamentally misconceived. The systems being proposed to automate age verification create greater user data privacy risks and divert resourcing that could be spent on strategies that are proven to support healthy sexual development. Ultimately, mandatory age verification systems create barriers to post-pubescent young people seeking information about sex online. Our study concludes that the underlying problem with age verification, therefore, is not only technical but more profoundly political: even if the system can be made to work, it should not be.
Keywords
Age verification is gaining traction among western democracies as a proposed solution to restrict minors’ access to online pornography. In August 2021, Australia's eSafety Commissioner issued a call for evidence ‘seeking insights into effective age verification techniques’ to prevent people under the age of 18 from accessing sexually explicit materials (SEM) online (eSafety Commissioner, 2021). In doing so, Australia became the latest country to explore age verification for this purpose, following similar moves in Europe and the United Kingdom. The Australian Government's roadmap for mandatory age verification (the ‘AV Roadmap’) attracted significant rebuke from a range of stakeholders, particularly privacy activists. The roadmap formed part of the Government's response to a report entitled Protecting the Age of Innocence (Standing Committee on Social Policy and Legal Affairs, 2020), which followed on from a 2016 Inquiry into harm being done to Australian children through access to pornography on the internet (Senate Standing Committees on Environment and Communication, 2016). By August 2023, the eSafety Commission announced that the age assurance market was immature with significant gaps, citing feasibility and technical concerns, and recommending media literacy and education (2023a).
In this article we consider the ramifications of applying automated decision-making to the task of restricting pornographic access to minors. To do so, we draw together researchers from multiple disciplines, including media studies, cultural studies, education and computer science. While machine learning is regularly used to control access to SEM online, such as through pornography and nudity classifiers, media and education studies insist that the best way to support healthy sexual development in a digital context is through increased education to support sexual and media literacies. The article is therefore divided into two key parts: the could versus the should of age verification. In the first instance, we consider whether accurate and reliable age verification is actually possible. While there are numerous machine learning approaches to age verification, we focus on age estimation, analysing a dataset of 10,139 images processed through a commonly used state-of-the-art convolutional neural network (CNN) approach. We report on the accuracy of age estimation classifications via age bracket, gender and race, and examine the ways in which classifiers zone in on particular image segments and introduce discriminatory bias. In the second instance, we consider whether age verification is actually desirable. We discuss age verification in light of current debates on privacy, feasibility, pornography regulation and healthy sexual development.
We argue that the concept of employing automated processes to manage access to pornography is not only problematic but fundamentally misconceived. First, current state-of-the-art facial recognition technology is only accurate up to a certain level, and studies suggest that this is unlikely to improve. Existing age estimation software is not even close to being able to reliably distinguish between people who are under and over eighteen years old (the legal age for purchasing pornography in Australia). While it remains a common refrain in computer science that such systems simply require better training data, more sophisticated algorithms or other incremental improvement, our meta-analysis indicates that age estimation solutions from facial scans cannot ever be expected to achieve acceptable levels of accuracy. Second, the systems being proposed to automate age verification are unworkable. They pose onerous requirements on platforms of disparate sizes and scales and divert resourcing that could be spent on strategies that are proven to support healthy sexual development. Even if they could be made to work, and even if they were not open to circumvention and gaming by users, they require the gathering, storage and sharing of extensive personal data which is susceptible to serious privacy violations. Finally – and most profoundly – a mandatory age verification system will create barriers to post-pubescent young adults seeking information about sex online. Research shows that in order to support healthy sexual development we need to ensure that comprehensive, age-appropriate sex education is available to give young people the information about sex that they are interested in (including information about pleasure) (Kantor and Lindberg, 2020). It is not simply that age verification doesn’t support this aim; the problem is that age verification actually works against this outcome. The underlying problem with age verification, therefore, is not a technical but a political one: even if the system can be made to work, it should not.
Constructing pornography as a problem
Cultural historians have demonstrated that the concept of pornography has been understood differently at various periods in history (Hunt, 1996). For example, in pre-revolutionary France, “pornography” described a genre of revolutionary political literature (Darnton, 1996). The literary historian Walter Kendrick argues that the category of pornography in the modern sense was invented in the nineteenth century in part as a response to the discovery of explicit illustrations in Pompeii as a way to control which sectors of society would be allowed to access such material (Kendrick, 1996) and debates about pornography can be used by powerful groups in society to control access to material that threatens to be disruptive to existing social structures.
Current debates about pornography took on their modern form in the early 1970s, when the US President's Commission on Obscenity and Pornography significantly changed the ways in which pornography was researched and discussed (McKee et al., 2022). The Commission commissioned dozens of reports from social scientists about the effects of pornography. Before the Commission there was little academic publishing on this topic; after the Commission a flood of material began and has not stopped. Before the Commission most of the arguments – in public debate and also in what academic research existed – leaned heavily on religious discourses of morality and statements gathered from authority figures like police, priests and politicians. By contrast, the Commission introduced an era of social scientific research that gathered empirical data from pornography consumers. Before the Commission the “effects” of pornography consumption that dominated public debate were those of moral decline. After the Commission there was more explicit focus on whether pornography damaged healthy sexual development. In short, pornography emerged at this point as a “social issue” (Wilson, 1973).
Despite available evidence, various narratives have since been mobilised to justify increasing regulation and surveillance. From the earlier concerns with obscenity, indecency and offensiveness, dominant discourses of concern evolved. With the emergence of home video recorders, public debates focused on the fact that sexual material could now be consumed in domestic settings (Juffer, 1998). This concern grew with the emergence of the digital distribution for sexually explicit materials, and the language of ‘extreme pornography’ began to be used as a coded way to enforce heteronormative ideals of sexuality (Attwood and Smith, 2010). More recently, concerns have been articulated in terms of porn ‘addiction’ (Ley, Prause and Finn, 2014) and ‘public health’ crisis (Nelson and Rothman, 2020; Webber and Sullivan 2018). Researchers have argued that the evolving nature of these campaigns represent a series of linked moral panics which all have the same underlying concerns – sex-negativity, heteronormativity and crises over new technologies (McKee et al., 2022). Regulators’ constant focus on taboo sexualities has been described as a vicarious kink in itself (Khan, 2014), and pornography laws that are unjust and out-of-touch have been shown to invite civil disobedience (Stardust, 2024).
Age verification as biopolitical surveillance
Age verification is becoming increasingly popular among governments as a ‘silver bullet’ to allay public concerns about minors accessing pornography. In 2020, both Germany and France introduced age verification (Braun and Kayali, 2020; Burgess, 2022), and in 2022, the UK revived their attempt after abandoning it in 2019 ‘after years of technical troubles and concerns from privacy campaigners’ (Waterson, 2019). Despite governmental enthusiasm, a sustained ‘Resist AV’ campaign has been underway in the UK since 2016 (Backlash, 2 022).
Australia's ‘AV Roadmap’ was prompted by the Online Safety Act 2021, which requires the introduction of a restricted access scheme to prevent minors from accessing sexual material. Notably, the Act does not require a particular form of restricted access and does not require age estimation or automated content restriction. Despite this, the eSafety Commissioner actively considered numerous automated techniques for verifying the age of users. eSafety describe these as falling into two categories: age verification and age assurance. Age verification processes involve confirming the age of a user via external sources of information, such as drivers’ licenses, credit cards or passports, which can be uploaded or matched against government e-identity systems. Age assurance includes processes to establish the age of an individual, such as self-reported age (entering or selecting one's year of birth) and confirmation of age by another person (a parent or peer). Two examples that eSafety Commissioner offered as ‘age assurance’ would, we think, more accurately be described as ‘age estimation’, because they predict the age of individuals using automated decision-making. These include age estimation software using biometric information (such as facial recognition technology, digital fingerprinting or voice recognition) and behavioural profiling (that estimates the age of users based on various online signals, such as digital traces or gesture patterns).
Privacy, feasibility and accessibility concerns about mandatory age verification have been repeatedly raised by civil society. For example, concerns have been raised about access to pornography for marginalised people without drivers’ licenses, passports, proof of age, credit cards or other identity documents (Blake, 2018, 231). Stakeholders have also been concerned about the higher burden placed on smaller, low-income websites, including those providing niche and independent content, who may be unable to afford the costs of implementing age verification (Blake, 2018, 230). Niche and indie pornography sites are already disproportionately affected by regulatory frameworks that criminalise queer, feminist and kink content (Stardust, 2018), and often have difficulty finding billing, hosting or payment processing (Stardust et al., 2023). There are open questions about how age verification data would be saved, stored, accessed and shared, given that the systems are usually proprietary and privately implemented. This is especially the case where user profiles could be cross-checked across other government databases such as the electoral roll, risking the unnecessary aggregation of personally identifiable, sensitive information. There is a risk that users could have their browsing histories, sexual preferences and online behaviour recorded on databases that could be sold, shared, hacked or leaked with little regulatory oversight. Such sensitive records would also become highly valuable (and easily exploitable) targets for extortion, blackmail and identity theft. One of the techniques the eSafety Commissioner considered, ‘behavioural signalling’, requires accumulating multiple data points about users, such as GPS, cookie data, IP address, username, physical address and browsing history. Such data collection has been proven to introduce numerous privacy risks (Zhao et al., 2022). As Austin and Reed (1999) point out, minors often not only misinterpret online consent mechanisms that seek to nullify their rights over such data but are often incentivised by online actors (such as advertisers) to relinquish their data through online entertainment outlets.
We can understand the enthusiasm for age verification (biometric age estimation in particular) as part of a broader trend towards population-level surveillance. In 2019 Australia's former Minister for Home Affairs Peter Dutton proposed to ‘face-scan people watching porn’ (Butler, 2019). The same year, the federal government unsuccessfully proposed a facial recognition scheme via the Identity-Matching Services Bill 2019 and Passports Amendment Bill 2019, which would have authorized the Department of Home Affairs to maintain a centralised database of facial images from government-issued documents and use them for identity-matching services for other agencies and contractors without warrants. At the time, the Law Council of Australia expressed concern that the databases could be expanded to include charge and prison photos, and the bills were rejected by the bipartisan Parliamentary Joint Committee on Intelligence and Security, who commented that they were inconsistent with privacy and transparency principles (Seo, 2019). Both minors and pornography are easy targets for facial recognition technologies: O’Neill et al. found that the face of the child is used for the purposes of ‘justifying and legitimating the use of facial recognition technologies’ and ‘serves to obscure the political ramifications of the extension of facial recognition and of biometric surveillance tools more broadly’ (2021, n.p). It is within this context of biopolitical surveillance that we can situate the sustained push towards age verification for online pornography – and the interest in age estimation software in particular.
The politics and practices of estimating age
Despite advancements in machine learning, a preliminary review of age estimation algorithms concludes their lack of suitability for restricted access systems. The limited academic research on the efficacy and reliability of human age estimation algorithms paints a picture of “a very challenging task” (Akbari, Awais and Kittler, 2020). In their submission to the eSafety Commissioner, two of the authors presented a preliminary analysis of the CNN of Levi and Hassner (2015) as applied to the UTKFace dataset (Zhang, Song and Qi, 2021). In his analysis, Obeid found that individuals belonging to marginalised ethnic groups are systematically misrepresented by CNN techniques (Stardust et al., 2021), classified as both older and younger than their actual age. Related works of Ramanathan and Chellappa (2006) Hajizadeh and Ebrahimnezhad (2011) and Angeloni et al. (2019) yield success rates of 70%, 87%, and 83% respectively, which, in practice, mean that approximately one in every five subjects will be incorrectly classified as belonging to an age group that is not their own. More fundamentally, error margins in age estimation are often due to the underlying hard-coded assumptions upon which these analyses are based. That is to say, the indicators programmed into software often rely on stereotypical indicators of age, based on assumptions about how certain physical characteristics present.
Many of these indicators are highly variable. One process of age estimation is the analysis of facial wrinkles by Gabor filters, linear filters used for texture analysis (Batool and Chellappa, 2015; Hosseini et al., 2018). However, wrinkles are not determinative because they depend on a range of factors (such as sun exposure, oil production, smoking and facial expression) and can be easily undermined by facial cosmetics or injectables (Dantcheva et al., 2012). Another is the analysis of hairline distribution, which has been proven to negatively skew age estimations (Lanitis, 2002). Distributions of facial hair are also highly variable across different populations. For example, women with polycystic ovarian syndrome or hirsutism may display more facial hair due to high levels of androgen, and post-menopausal women may display more facial hair due to the reduction of oestrogen. The amount of head hair is also variable: while hair loss is influenced by genes, trans masculine people of different ages taking testosterone may experience hair recession because of the increased amount of Dihydrotestosterone (which targets hair follicles) in their bloodstream. Another process of age estimation is by determining craniofacial growth with age by distance ratios of facial features with respect to each other (for instance, the lengthening of a subject's jawline with respect to their upper lip). However, Farkas et al. (2005) survey this method and point out that such ratios vary with ethnicity. As CNN approaches (which are conventionally applied) do not acknowledge such contextualisations, they are also susceptible to misclassification by generalising that certain facial features belong to a certain age group.
These examples are reminiscent of human bias that has been documented when humans attempt to identify age. Breast size, for example, has been used as indicator of age among medical experts attempting to identify child sexual abuse material (CSAM), however this is a highly inaccurate indicator because breast development is so variable. In one study, paediatric endocrinologists in court misidentified adult women from legitimate pornographic sites as being under eighteen on the basis of their youthful appearance: they erred two-thirds of the time (Rosenbloom, 2013). Such assessments can have significant ramifications. In 2010, politician Fiona Patten reported that, in a training session with the Australian Classification Board, she was informed that small breast size could imply that models were underdeveloped and therefore underage, which could lead to publications and films being refused classification (effectively prohibited from import, export, sale and circulation). In 2021, Australian academics contacted US authorities because they “came across an OnlyFans account that was advertising on Twitter” which “was advertising a very young model who was male”. They requested an assessment from a forensic paediatrician, “who confirmed that the individual could be no older than 13 or 14, based on his physiological characteristics” and the page was taken down on both Twitter and OnlyFans (Cockburn, 2021). The reliability of both human and automated age verification therefore has significant consequences, not only on who can access online pornography, but who can participate in sexual media production.
Because age estimation by human beings is already unreliable, age estimation by algorithms is inevitably fraught. Indeed, it is generally the case that algorithms that seek to identify and categorise human characteristics such as gender, race, sexual orientation and age cannot reliably classify complex and intersecting identities. Facial recognition technology has high rates of error when purporting to recognise age and gender and has been proven to have significant racial bias (Guo and Mu, 2010). Existing facial recognition technologies are usually trained on data sets that are biased towards white faces with significant underrepresentation of non-white faces, which limits their applicability among the general population (Kärkkäinen and Joo, 2019). The Gender Shades study, which analysed IBM, Microsoft and Face++ facial recognition software, found that all classifiers performed better on male faces than female faces (8.1%-20.6% difference in error rate), all classifiers performed better on lighter faces than darker faces (11.8%-19.2% difference in error rate), and all classifiers performed worst on darker female faces (20.8%-34.7% error rate) (Buolamwini and Gebru 2018). Gender recognition systems have been developed without the consultation, collaboration or involvement of marginalized communities, and have been demonstrated to “misrepresent complex gender identities and undermine safety” (Scheuerman and Brubaker 2018). Furthermore, age estimation classifiers (such as the UTKFace dataset investigated here) work on the presumption that the metadata embedded in dataset images is true and accurate (despite categories of race and gender being social rather than biological constructs). This metadata is difficult to verify because users may report, express and articulate their gender, ethnicity and age differently across various contexts.
The trouble with age estimation as a gatekeeper to access online content is not only that the machines are inaccurate, but that they are using indicators to estimate something that is culturally and geographically variable. While ageing is a biological process, the concept of age is culturally constructed. Definitions of youth and adulthood vary markedly across the globe, as do stages of social and emotional maturity. As sociologists have noted, age is afforded different meanings across social and cultural contexts. Transitions from childhood to adolescence to adulthood are marked by different ‘coming of age’ rituals that sometimes have less to do with age and more to do with maturity, puberty, social connection, relationships and responsibilities. Within the field of sexual health, the thresholds between these classifications are highly contested, with varied definitions of who is considered an ‘adolescent’ or a ‘young person’ (United Nations, undated, p2). While Western societies are preoccupied with childhood innocence, positioning people as dependents in need of protection until the age of 18, in some contexts children may be heads of households regarded as having wisdom and responsibility. Even legal ages of access – to vote, to consent to sex, to drink alcohol, to enter premises, to marry, to view certain films – differ across jurisdictions. And yet facial recognition technologies are not assessing maturity or sexual development but making a rudimentary distinction between users over or under the age of eighteen.
Methods
While much previous work has revealed the inadequacy of age estimation algorithms through the lens of performance measurement (% accuracy, precision vs recall), less work has touched on exactly why these systems fail. Much of this is due to the epistemology of machine learning in this present moment which has tended towards focussing on algorithmic performance as the primary marker of quality, rather than how or why algorithms perform in a specific manner (Birhane et al., 2022). Thanks to a recent upswing in interest on explainability, however, there is a new focus upon unpacking the internal logics of machine learning systems for the purposes of algorithmic accountability. In this article, we focus specifically on biometric age estimation software as an approach considered by the eSafety Commissioner and explore their reliability and potential impacts by race and gender. Age estimation algorithms constitute any automated methods for determining the age of an individual. Such algorithms are prominently implemented as a sub-task of facial image analysis and have been studied extensively in machine learning research (Han et al., 2013). We consider CNNs, as a form of automated age estimation that is currently the subject of much interest, and as such would be likely candidates for consideration in any technical implementation of age verification. CNNs are machine learning solutions designed predominantly for classification problems, that are trained using a corpus of labelled data from a similar context to their intended domain of application.
In our analysis, we examine data sourced from four distinct age groups relevant to debates about access to pornography: ages 0–12, 13–18, 19–25 and 26 + . We choose these groups for several reasons. Because regulators are concerned with under 18 access to pornography, and privacy activists are concerned about users over 18 being incorrectly blocked, we focus on groups on either side of this 18yo threshold. However, because the literature on healthy sexual development differentiates between the impacts of pornography on pre-pubescent and post-pubescent young people, we examine these groups separately (0–12yo, 13–18yo). Although puberty commences at different ages, we take 12yo as the average age of puberty onset in Australia. Further, ‘young people’ up to age 25 are a demographic who also have specific needs in relation to sexual development and education. We additionally explore each of these categories by race and gender, to identify the potential for compounding disadvantages and harms.
UTKFace dataset
To examine the accuracy of CNNs for age estimation, we classified facial portraits from the UTKFace dataset compiled by Zhang et al. (2017) using the pre-trained Deep EXpectation (DEX) CNN. The UTKFace comprises over 20,000 images of human faces, collected from publicly available online locations and provided at the discretion of dataset authors. Our sample consists of 10,139 images selected at random, which has enabled us to achieve statistical representativeness for most of our analysis. Each image is labelled at the time of the image's capture with the age of the subject, and their purported gender and race. Although we report on these classification categories below, we recognise that there are problems in how they have been articulated. For example, the racial categories provided by this dataset only include limited descriptors: ‘White’, ‘Black’, ‘Asian’, ‘Indian’, or ‘Other’ and the gender categories are limited to equally problematic binary options of ‘Male’ or ‘Female.’ These labels do not necessarily represent categories self-described by the individual subjects; rather they are usually inferred or imposed using publicly available metadata. As such, they risk erasing the experiences, histories, identities and cultural complexities of the subjects, and represent a broader problem for machine learning in grasping intersecting and fluid identities.
“Deep Expectation” method
We classified the UTKFace Dataset using the pre-trained Deep EXpectation (DEX) CNN of Rothe et al. (2015). Since its introduction, the DEX CNN has contributed to contemporary solutions to age estimation, achieving “state-of-the-art results” (Agbo-Ajala and Viriri, 2021), as supported by the surveys of Sundararajan and Woodard (2018), and Hassan et al. (2021). Paired with the well-adopted IMDB-WIKI dataset, the DEX model has been cemented as a key development in age estimation research.
The authors understand that technologies similar to DEX were considered in Australia. The Protecting the Age of Innocence report, from which the AV roadmap derives, discussed facial analysis technologies as a potential approach (Standing Committee on Social Policy and Legal Affairs, 2020). Among possible forms of image data, biometric photo IDs issued by government bodies were frequently mentioned as possible inputs: Australian Driver's Licenses, Proof of Age Cards, and Australian Passports all prescribe centrally positioning a subject's head and shoulder-line within a margin of an almost square-ratio boundary (Queensland Police Services, 2023) (Australian Government Department of Foreign Affairs And Trade, 2023). This matches the specification of the IMDB-WIKI training data used for the DEX model, with only the differences of restricted facial expressions, hair, and accessories – although the DEX model nonetheless anticipates cases that enforce these restrictions.
The Inquiry also heard from the Head of Age Verification at the British Board of Film Classification (BBFC) about their digital Age Verification Certificate (AVC); one of their providers for administering AVCs, Yoti Australia Pty Limited (2019), reported on the feasibility of implementing age verification in Australia. The Yoti Limited (2022) ‘age scan’ technology uses a neural network approach, positioning it within the same class of solutions as the DEX model, although with claims of stronger statistical accuracy for younger age groups. Despite this, they recognised increased error rates for older individuals, already introducing potentialities for ageism, as previously articulated by Stypińska (2021).
To this end, the technologies considered for the AV roadmap align with the class of solutions containing the DEX model, and image data similar to the data evaluated within this article. Here we apply the DEX CNN as implemented in the Keras Python deep learning API (Uchida, 2022), and trained using the IMDB-WIKI dataset (again provided by Rothe et al. (2015)). It works by analysing an image of a subject's face via an ensemble of 20 sub-CNNs to predict their age, within the range of 0–100 years old. As we are interested in the inferences made in estimating age, we focus specifically on this and disregard the DEX method's gender inferencing capabilities, which falls outside the scope of our research question.
The DEX method provides an inference as to a subject's age as a vector of 101 values, where these indexes (ranging between 0–100) correspond directly to the probability that the subject's age is said index. The predicted age is then determined as the dot product of this vector, with the discrete years for each age as a class given by the formula:

Facial image data pre-processing
Accurately testing the reliability of the age estimation model required ensuring that all facial images were consistently aligned. The DEX method pre-processes sample images by alignment, centring, and cropping (Rothe et al., 2015, 2.1). Alignments are achieved by rotation; we produced similar results by applying Gaspar and Garrod's method (2021), which not only rotates, but warps images to correctly display obscured faces. All images were required to centre the subject's face to include a 40% margin. For pre-processing, we applied the “DLIB” machine learning library (King, 2009), which detects the facial landmarks within images, cropping accordingly. A total of 9645 images from our corpus succeeded in all stages of the pre-processing, and those that failed this stage were removed from the input corpus Figure 1.

Example pre-process of image for age estimation.
Facial landmark detection and LIME explainability
After pre-processing, DLIB was further used to determine image segments that describe the subject's facial features meaningfully and consistently. This step allows us to later isolate which specific facial features the model is focusing on to estimate the subject's age Figure 2.

Facial landmark connotations. Note: The indices of the coordinates displayed in the diagram above correspond directly to those applied within the DLIB detection package, and are used to derive the following connotations: OBT (Outer Boundary Top); OBL (Outer Boundary Left); OBB (Outer Boundary Bottom); OBR (Outer Boundary Right); LEA (Left Eye Area); LE (Left Eye); LC (Left Cheek); N (Nose); UL (Upper Lip); M (Mouth); C (Chin); REA (Right Eye Area); RE (Right Eye); RC (Right Cheek). The area highlighted in light blue is also denoted as the F (Face) segment.
In addition to facial landmark detection, we also implemented the image module of the LIME explainability package (Ribeiro et al., 2016). LIME's image module creates a Boolean mask to reveal which specific image pixels detract from, or contribute to, the outcomes of the DEX model's inferences. This mask reveals the degree by which specific segments of an image contribute to its age estimation. Combining the facial landmark detection and LIME Boolean mask allowed us to further obtain the degree (as a percentage) by which specific facial segments contribute to the DEX model's inferences relating to the subject's age. An example is given in Figure 3.

Intersection of image segment defined by facial landmarks and image explanation. Note: The Boolean matrix is here conveyed by super-pixels of varying colour displayed in the LIME image explanation. Green super-pixels denote the value of ‘1’, whereas red super-pixels denote the value of ‘0’.
Finally, to summarise overall patterns of LIME image segment activation across the dataset of facial images, we summate the matrices of the corresponding Boolean masks in order to generate heatmaps, as are visualised in our results Figure 4.

Aggregation of LIME image explanations as Boolean masks to generate heatmap of image segment activations.
Statistical significance
As previously detailed, we contextualised all sample images by age ranges, binary gender norms, and given race categories. We attempted to achieve statistical significance for all combinations of categories by evaluating the central tendency of the inferences for the associated results. Specifically, we implemented D'Agostino’s and Stephens (1986) normality test on the age estimations associated with each of the combinations, and disregard instances where the null hypothesis could not be rejected for a confidence interval of 95%; the details are conveyed in Appendix A. In the results section that follows, all instances that fail to achieve central tendency for this test are disregarded.
Findings: age estimation accuracy
We found significant inconsistencies due to race in the DEX model's classifications, with higher classification accuracy for the ‘Caucasian’ category, and the lowest quality for the ‘African’ category. We also found that young males are more likely to be misclassified than young females, particularly in the 0–12 age bracket.
Figure 5 reveals the overall spread of confidence in the output classification for each age bracket, i.e., how accurate is the model across each category and age bracket. Figure 6 shows the frequencies of differences between estimated and ‘true’ ages, i.e., how far the model's estimates are from the ‘true’ ages of input subjects. In Figure 6 a positive value would indicate that the model output has classified the subject as older than their true age. In both figures, the common ‘overlap’ (i.e., the subsample shared by all distinct distributions) is discounted from all distinct distributions, which in turn contrasts relevant differences between them.

Age estimation accuracy from the DEX model.

Distributions of age estimation difference (model estimate – true value).
With respect to race, wider confidence intervals (flatter and shifted further to the left) for younger age brackets indicate reduced accuracy for younger subjects (with ages 0–18 most affected). Notably, the ‘Caucasian’ category in the 0–12 age range performs best within this sub-group, while the ‘Asian’ category performs poorest. As shown in Figure 6.a, subjects of all races within younger age ranges (0–18) are estimated as significantly older than their true ages, by up to 45 years. Alternatively, for the 26–100 age range, the majority of races stabilise to a misclassification error margin of ±20 years; this excludes the ‘African’ category, which observes frequent misclassification for subjects appearing younger, by sometimes as much as 40 years. In fact, the ‘African’ category demonstrates the worst age estimation accuracy in all applicable cases.
In line with past studies of racial bias in facial classification, the ‘Caucasian’ category ranks best, peaking above 90% accuracy for all age ranges. Where statistical significance is established, the ‘Asian’ and ‘Other’ racial categories demonstrate less accurate yet similar characteristics. Also, the Indian racial category frequently demonstrates the narrowest confidence intervals, which indicates the greatest certainty in deviation of age estimations.
With respect to gender, we observe in Figure 5.b that the model has higher accuracies in age estimation results for the 0–12, 13–18, and 19–25 age ranges of female subjects, with male subjects receiving better accuracy in the 26–100 age range. Somewhat consistent with the findings from racial categories, there is less certainty in age estimations for subjects within the 0–12 and 26–100 age ranges. As shown in Figure 6.b, in the 0–12 age range, male subjects are slightly more likely to be misclassified as being older than their true age. Whereas in the 26–100 age range, female subjects are more likely to be misclassified as younger.
Findings: image segment activations for age estimations
Moving beyond classification accuracy, we also examined how facial segments contributed to age estimations, and how this interacted with racial categorisations. A claimed innovation of the DEX model is that the model does not rely on explicit facial landmarks to infer age (avoiding potential discriminatory bias). However, using LIME explainability modules, we determined that the classifier consistently relies upon facial landmarks to undertake age estimations, irrespective of whether the result is right or wrong. This is substantiated by the consistent activation of facial segments (F segments) by the DEX model, as noted across all age ranges and races. One such example is visualised for the ‘Caucasian’ category of ages 0–12 in Figure 7.

Heatmap of image segment activations for ‘Caucasian’ racial category.
The DEX model's reliance on facial segments is most apparent within the 0–12 age range. Specifically, strong activations are observed for Left Eye Area (LEA) and Right Eye Area (REA) segments across race categories performing successful classifications. Thereafter in the 13–18 age range, this reliance weakens as other segments begin to influence results. The ‘Caucasian’ and ‘Other’ categories both observe stronger activation in Outer Boundary Top (OBT) and Outer Boundary Bottom (OBB) segments, and this is pronounced in the 19–25 age range, which demonstrates further activation in the Outer Boundary Left (OBL) and Outer Boundary Right (OBR) segments. In the 26–100 age range, the Face (F) segment is least relied upon to determine age classifications. Furthermore, there is significantly more activation of the OBT segment than anywhere else.
Concerning racial categories, the trend continues with ‘Caucasian’ and ‘Other’ categories. For the ‘Caucasian’ category, the DEX model relies significantly on F segments. This reliance weakens in the 13–18 age range, where the F segment contributes to both accurate and inaccurate classifications. As a result, the OBB segment overtakes it as most contributing to accurate classifications. In the 19–25 age range, the F segment is much less related to classifications of any kind; rather in this age range, the OBL and OBB are influential upon accurate classifications. This finally adjusts to the OBR, OBL, and OBB segments within the 26–100 age range, where the F segment is least influential.
A visualisation of the image segment activations for accurate age estimations of both the ‘Caucasian’ and ‘Other’ racial categories (as aggregated for all subjects within each group) are provided in Figure 8.
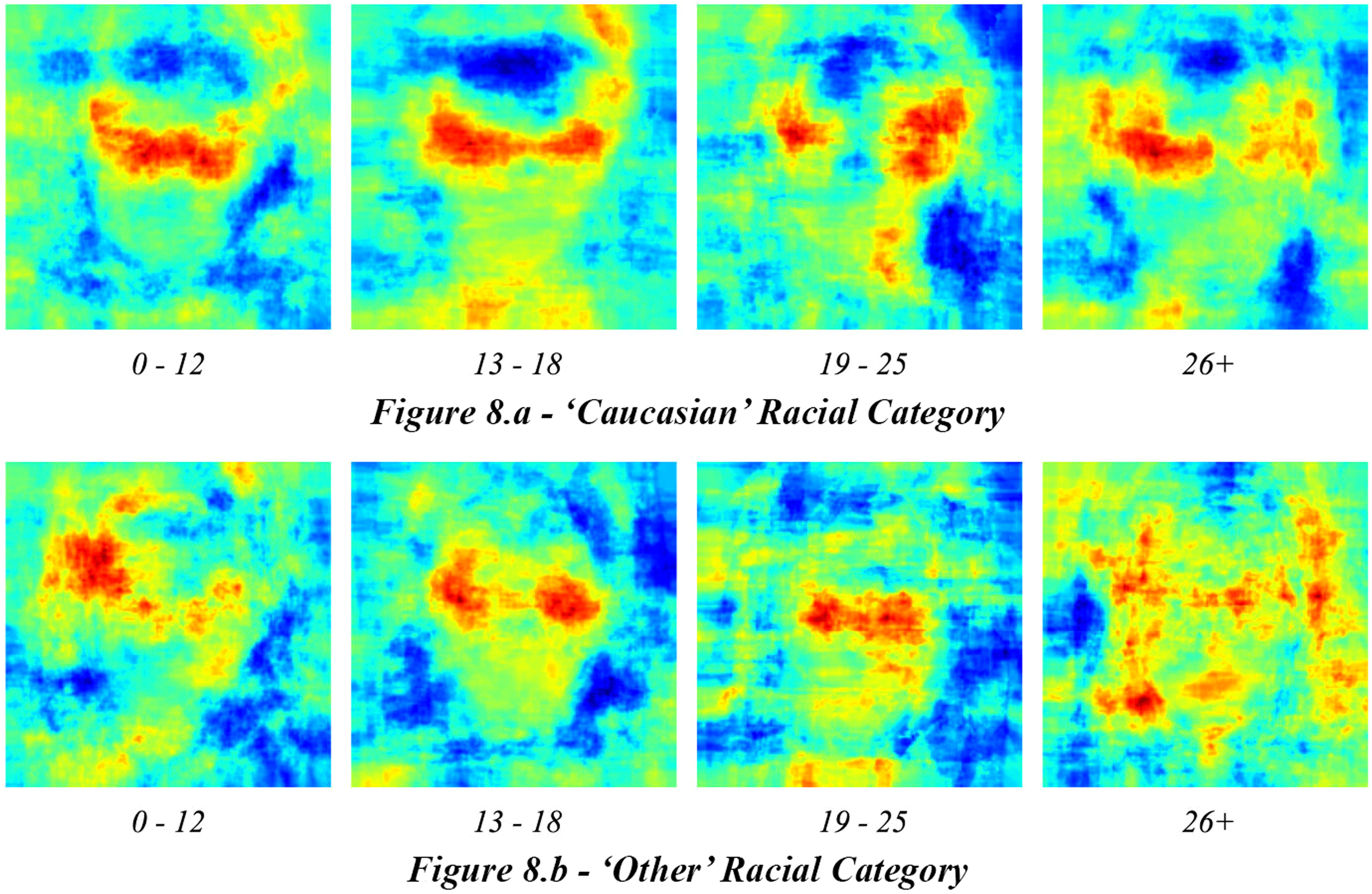
Heatmaps of image segment activations that contribute to accurate age estimations.
For all other racial categories, statistical significance cannot be established for the age ranges of 13–25. Irrespective of this, the age ranges of 0–12 and 26–100 coincide with the trend that older subject age results in more inaccurate determinations of age. Except for the `African’ racial category, for which the DEX model does not rely primarily upon facial landmarks for all age ranges. The complete set of results that correspond to the image segment activations for age estimations are detailed in Appendix C.
Discussion: racial bias and facial landmarks
Our analysis indicates that using automated decision-making to estimate age is fraught for several reasons. The most prominent finding consistently reinforced in our analysis has been the frequent failure among the ‘African’ racial category. This is demonstrated in estimation accuracies, where said subjects scored consistently worse than other racial categories. While statistical significance could not be established for all age ranges, subjects aged 26 and over were generally misclassified as younger, sometimes by as much as 40 years. We perceive that the failure is due to the model's inability to generalise progressions of age in ‘African’ faces; supported by image segment activations, which exhibited high noise and trended to right and bottom outer boundaries of the image.
Whereas `Indian’ and `Asian’ racial categories had more stable age estimations, the `Caucasian’ racial category generally performed better. The `Other’ racial category outperformed all alternatives in age estimation accuracies. This racial category aggregates subjects including but not limited to Hispanic, Latino, and Middle Eastern descent. We interpret that the improved performance may be due to the larger variations of facial features (as a result of aggregating differing races) present in the ‘Other’ training data, enabling it to generalise with greater insight.
In estimating age, we found that the DEX model's accuracy is highly variable. For example, for subjects of the 0–18 range, the performance is particularly weak; younger subjects have been generally estimated as older, in some cases up to 45 years, while subjects aged 26 and over produce error margins of up to ± 20 years. In terms of gender, trends were only slight, and again contextualised by age range: within the 0–25 age range, female subjects had their ages more accurately estimated than males - the reverse was then observed within the 26 and over age range, where ‘males’ had more accurate estimations than ‘females’.
A long-standing feature of ML-based age estimation technologies has been the reliance upon facial landmarks to determine a person's age. The DEX model is introduced as an alternative ‘facial landmark agnostic’ approach. However, our analysis reveals that despite these claims, DEX still relied upon facial landmarks. We speculate that this may be a result of emergent model complexity, where the model independently anticipates and forms dependencies on specific facial features it perceives to be beneficial to age estimation. We found that the model frequently observes the subject's left and right cheeks, mouth, and chin image segments to infer its predictions.
Overall, our results convey that facial segments of an image consistently affect the DEX model's determinations. This is true for both successful and unsuccessful age estimations, implying that there exist instances where it is not possible to ascertain the subject's age from their face. These results beg the more fundamental question: is it correct to assume that an image of a subject's face can be used to accurately determine their age? Given that facial features – such as brow shape or lip curvature – can be visually inhibited, ethnically variant, cosmetically adjusted, or not necessarily correspond to the subject's age, it is incorrect to assume that an image of a subject's face can be used to accurately determine their age.
Supporting healthy sexual development
We must always remember that what can be described as an “error” in classification is, in each case, a human being attempting to access representations of sexuality. The implications of mistakenly refusing access to that material can be significant for each of those humans, as well as being a notable error in a CNN approach. The various disciplinary approaches represented by the authors show us that not only is accurate age estimation impractical – more than this; it is undesirable. To put the point at its simplest: from the perspective of sex education, the issue of how to ensure that young people aren’t harmed by unwanted encounters with pornography is best managed not by restricted access, but by education. Even if used as a preliminary screening tool alongside human oversight, age estimation software still presents significant privacy concerns and diverts resources that could be invested in evidence-based solutions.
Sex education research insists that the best approach to supporting healthy sexual development for young people is to ‘talk soon, talk often’ with them about sex (Walsh, 2011). This includes talking to them about pornography. Pornography is not a monolithic, homogenous category. Particularly in an age of digital production, pornography includes multiple genres, philosophical approaches and content that is generally more diverse than mainstream media (Comella and Tarrant, 2015; Taormino et al., 2013). Like other forms of media, pornography spans the gamut of genres from documentary to comedy, horror and romance. The eSafety Commission's approach presumes that pornography is ‘violent and extreme’, despite research demonstrating that ‘violence’ in pornography is often measured in ways that conflates violence with consensual kink (McKee, 2015). It further makes assumptions about what ‘real’ and ‘fake’ bodies look like, even though the construction of reality and authenticity are highly blurred in any curated media production, including pornography (Stardust, 2019) and follows outdated narratives about objectification that fail to recognise the difference between sex and sexism (Paasonen et al., 2020).
This approach is also problematic because it ignores the research on how people actually use pornography (Byron et al., 2021). Research on young adults’ consumption of pornography highlights that they are media literate, critical consumers, and can distinguish between real and simulated content (Buckingham et al., 2005). Many young people view pornography as a lower-risk alternative to real-life experimentation with sex (Smith et al., 2014). Sexual and explicit media can also play a role in affirming desires, bodies and practices of young people, particularly sexual minorities who are underrepresented in traditional media (Litsou et al., 2020). Explicit content can be “a source of knowledge, a resource for intimate practices, a site for identity construction, and an occasion for performing gender and sexuality” for young adults (Attwood, 2005, p.65).
One domain of healthy sexual development is open communication with trusted adults about sex (McKee et al., 2010). Taking an educational rather than censorious approach limits the risk that young people will be upset if they accidentally stumble across SEM, where the research shows that “blurry notions of harm [from pornography, notions that they hear from the media] bother young people more than the actual pornographic content they encounter” (see Spišák, 2016). As Spišák demonstrates, if parents get angry or upset at young people when they stumble across SEM, that is more damaging than the sight of the material itself. Parents therefore need to understand their own sexual values – for example, if they disapprove of sex outside of long-term, committed, loving relationships – and be having conversations with young people about how their values differ from the representations encountered in pornography. Open communication limits the risk of harm – but perversely, censorship regimes contribute to harm by making it clear to young people that they should be embarrassed if they do stumble across material, and should keep it a secret. Green et al.'s work on “national contexts for the risk of harm being done to children by access to online sexual content” demonstrates that not only does the meaning of “harm” differ in different cultural contexts, but also that young people think about “harm” in very different ways from their parents (Green et al., 2020).
In this context, the ideas of ‘protection’ and ‘innocence’ are at least misleading, and deliberately obfuscatory. The ‘innocent’ children referred to in the Protecting the Age of Innocence include sixteen and seventeen-year-old people who, in most states and territories, can legally consent to sex. A historical consideration of the language of ‘protection’ in governmental legislation shows that it has commonly been used to sugar coat legislation that controlled groups of people – women, children and Indigenous peoples (see Baron, 1981; Egan and Hawkes, 2009; Nettelbeck, 2012). There is something particularly perverse in using the language of protecting people from themselves. Post-pubescent adolescents and young adults want to know more about sex. Restricting access aims to protect them from their own – common and healthy – interest in learning more about sex.
And still, restricted access systems are unlikely to stop young people from accessing SEM: UK research suggests that teenagers can easily avoid age verification (Yar, 2019) and may get around age checks using the dark web or by using third-party technologies to modify their images, impersonate others or assume a false identity, putting them at greater risk of encountering child abuse images (Blake 2018). Restricting access only contributes to a culture of shame about sex that is distinctly unhealthy (Wilson et al., 2012). We must not ‘protect’ young adults from learning about sex. Rather, we must support them to do so in healthy ways. In the eSafety Commission's own research, young people report wanting agency over whether, when and where they view online pornography, and “expressed their right to safe, autonomous sexual development and exploration” (2023b, 6). Young people were concerned that age assurance was of limited efficacy and had privacy and security issues, and viewed education (including porn literacy and sex/relationship education) as the most helpful tool (2023c).
Conclusion
Our analysis demonstrates that automated age estimation systems cannot be made to work in a reliable way that ensures accuracy, reliability or fairness. Machine learning approaches replicate human age estimation practices that are already problematic and biologically determinist. They rely on stereotypes about how highly divergent physical characteristics – hair, wrinkles, jawlines. Even when machine learning models are sold on a promise of being debiased and agnostic to specific facial features, our analysis shows that they continue to attend to specific physical characteristics in estimating age. The public datasets used to train and test these models themselves presume the truth of publicly available metadata as it is organised into rudimentary categories of race and binary categories of gender. In our analysis, a popular facial data set, albeit one which reproduces problematically limited demographic characterisations, revealed how a leading CNN skewed towards accuracy in ‘Caucasian’ faces. While classifiers can be tweaked to produce more true positives, it is a zero-sum game as doing so will inevitably increase the incidence of false negatives, and vice-versa. Because it is not possible to design an ML age classifier that affects all populations identically, software engineers are required to make decisions about what constitutes an acceptable rate of collateral damage – decisions that have significant trade-offs and implications.
However, the lack of reliability is not our fundamental disagreement with these technologies. Even if age estimation systems could be made to work, they should not be. This is a case study where automated decision-making is being misapplied to try to solve a social, cultural and educational problem rather than a technical one. Machine learning is often seen by governments as a panacea for complex policy areas. Instead of solving problems, machine learning systems often introduce further problems and distract from existing evidence-based policy options. When we say the problem is an educational one, we refer not only to comprehensive sex education and media literacy for adolescents. Rather, the hubris around age verification and the financial investment into making it feasible speaks to the need for porn literacy education among adults, including politicians. Porn literacy is developing as an important concept in research, deriving from earlier work on medial literacy (Smythe, 2018). Recent work has begun to think about “reading porn well” rather than taking an abstinence-based approach (Byron et al., 2021).
If our commitment is to supporting healthy sexual development in a digital context, focusing on automated processes is a distraction from the positive, practical, evidence-based steps that would make a difference. Relying on a rigid threshold of whether a user is under/over 18 erases fundamental differences between pre-pubescent children and post-pubescent adolescents, two groups that have very different needs and relationships to sex. Given that the biggest risk factor for pre-pubescents is the use of pornographic materials in the commission of sexual assault by adults on children (Langevin and Curnoe, 2004), governments must invest in community-led prevention and ensure that child protection services are funded at an appropriate level. Public health messaging must make it clear that the vast majority of child sexual abuse is perpetrated by someone already known to the victim, including close family members, and other authority figures such as teachers, coaches or priests (YWCA, 2017). On this point, governments must remove barriers to reporting such as the so-called ‘Seal of the Confessional’ which has been used by Catholic priests to conceal child sexual abuse. In terms of accidental exposure, the existence of parental familiarity with and use of ‘walled garden’ environments where pre-pubescents can safely play online is vitally important. As noted above, research shows that when young people accidentally stumble across forbidden material online, the biggest harm they face is fear of their parent/guardian's anger because the young person has (they worry) done the wrong thing (Spišák, 2016). Therefore, open communication between prepubescents and parents/guardians about sex is at the root of supporting healthy sexual development (Walsh, 2011).
By comparison, post-pubescents require legislated comprehensive, developmentally-appropriate sex education with a focus on providing the information they actually want about sex (Fine and McClelland, 2006). Young people consistently report they want to know more about pleasurable aspects of sex (Fisher et al., 2019, pp. 80–81). A comprehensive curriculum would teach students about pleasure as well as gender diversity and non-monogamy, in addition to human rights that have a significant effect upon health and wellbeing. LGBTIQA + health relies upon ‘the promotion of progressive sexuality education messages in classrooms addressing homophobia, sexual autonomy, sexual experimentation’ (Jones and Hillier, 2012). Given that a domain of healthy sexual development is ‘competence in mediated sexuality’ (McKee et al., 2010), it is also vitally important that young people receive appropriate training in porn literacy – knowing how to read porn well and make porn well (for example, selfies) (Byron et al., 2021). Sex education should also include sex-positive versions of porn literacy, developed with input from experts including sex educators, young people and pornography performers and producers (Stardust, 2016).
In practice, a restricted access scheme could include a simple yes/no question that asks users whether they are of age to consent in the jurisdiction in which they are accessing the content. Such an approach would serve the purpose of minimising prepubescent children, pubescent adolescents or young adults who do not know about the existence of SEM, from accidently accessing them. It also signals clearly to the consumer that a decision about consent to view material must be made, ensuring they will not ‘stumble’ across or be spammed by material they don’t want to see (Egan and Hawkes, 2009). But instead of opting for such an approach, governments are increasing their regulatory burdens by scaling up their investments in automation and data collection. This ought to raise suspicion. Instead of investing in consent education or porn literacy, significant resources, energy and time are being diverted towards fuelling biometric surveillance technologies – including nudity filters, pornography classifiers and CSAM detectors – which continue to raise serious privacy, accuracy and accountability issues. If machine learning is being pitched as the magic solution to human problems, we ought to pay greater attention to how the ‘problems’ are being articulated in the first place.
Supplemental Material
sj-docx-1-bds-10.1177_20539517241252129 - Supplemental material for Mandatory age verification for pornography access: Why it can't and won't ‘save the children’
Supplemental material, sj-docx-1-bds-10.1177_20539517241252129 for Mandatory age verification for pornography access: Why it can't and won't ‘save the children’ by Zahra Stardust, Abdul Obeid, Alan McKee and Daniel Angus in Big Data & Society
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Australian Research Council Centre of Excellence for Automated Decision-Making and Society [grant number CE200100005] and the Faculty of Arts and Social Sciences at the University of Sydney (personal research account).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.