
Abstract
FAIR data, that is, Findable, Accessible, Interoperable, and Reusable data, and Big Data intersect across issues related to data storage, access, and processing. The solution-oriented FAIR principles serve an integral role in improving Big Data; yet to date, the implementation of FAIR in multiple sectors has been fragmented. We conducted an exploratory analysis to identify incentives and barriers in creating FAIR data in the medical sector using digital concept mapping, a systematic mixed methods approach. Thirty-eight principal investigators (PIs) were recruited from North America, Europe, and Oceania. Our analysis revealed five clusters rated according to perceived relevance: ‘Efficiency and collaboration’ (rating 7.23), ‘Privacy and security’ (rating 7.18), ‘Data management standards’ (rating 7.16), ‘Organization of services’ (rating 6.98), and ‘Ownership’ (rating 6.28). All five clusters scored relatively high and within a narrow range (i.e., 6.28–7.69), implying that each cluster likely influences researchers’ decision-making processes. PIs harbor a positive view of FAIR data sharing, as exemplified by participants highly prioritizing ‘Efficiency and collaboration’. However, the other four clusters received only modestly lower ratings and largely contained barriers to FAIR data sharing. When viewed collectively, the benefits of efficiency and collaboration may not be sufficient in propelling FAIR data sharing. Arguably, until more of these reported barriers are addressed, widespread support of FAIR data will not translate into widespread practice. This research lays the preliminary foundation for conducting targeted large-scale research into FAIR data practices in the medical research community.
Introduction
Good data management and stewardship have long been recognized as a cornerstone in scientific research, encouraging ‘long-term care’ to facilitate efficient data sharing and analysis (Jacobsen et al., 2020). Data sharing stimulates positive changes in public health strategies, allows for more cost-effective research, and promotes scientific integrity (Lutomski et al., 2013). The FAIR principles were formulated to guide researchers to make their data more Findable, Accessible, Interoperable, and Reusable, thereby propelling data sharing (Wilkinson et al., 2016). The FAIR principles have been endorsed by a wide variety of stakeholders, resulting in large European infrastructure initiatives (Budroni et al., 2019). FAIR metrics (de Miranda Azevedo and Dumontier, 2020; Wilkinson et al., 2018; Wilkinson et al., 2019), FAIR infrastructure (Weigel T et al., 2020), FAIR tools (Thompson et al., 2020), and ultimately a domain-independent FAIRification workflow (Jacobsen et al., 2020) were developed to aid the process of FAIRification. However, data sharing is often driven by individual researchers who have reported facing technical, motivational, economic, political, legal, and ethical hurdles (van Panhuis et al., 2014). Lack of resources and the perceived threat over data proprietorship appear to outweigh the benefits of data FAIRification (Piwowar et al., 2007; Roche et al., 2014; van Panhuis et al., 2014). Still, these perceived barriers have been predominantly based on non-empirical data.
Albeit limited, the empirical research to date has revealed marked differences in data-sharing perceptions across scientific disciplines (Chawinga and Zinn, 2019; Tenopir et al., 2011; Tenopir et al., 2020). Disconcertingly, medical researchers lagged behind their research contemporaries in their willingness to share data, their satisfaction with tools for preparing metadata, and institutional support for sustainable access to data (Tenopir et al., 2011). Reported willingness to use secondary data was also notably lower (Tenopir et al., 2011), further suggesting that medical researchers struggle with adherence to the FAIR principles. The divergence from other scientific disciplines is a critical observation and underscores the need to discern whether medical researchers encounter unique barriers not adequately captured in previous survey studies.
To improve FAIRification and data sharing in the medical research community, incentives and barriers must be systematically identified and addressed with FAIR end-users. However, since previous survey data may have missed critical themes and issues pertinent to the medical research community, performing qualitative research is an essential preliminary step. Such fundamental work can guide the formulation of future appropriate surveys and the development of local institutional policies. It can also serve as a basis for identifying changes in perception and attitudes toward FAIR data sharing over time. Therefore, we performed an international mixed-methods study to explore senior principal investigators’ (PIs’) perceptions of data sharing and applying the FAIR guiding principles in medical research.
Methods
Study design
We conducted digital group concept mapping, which is a mixed-methods approach combining qualitative data collection with quantitative analysis processes and tools (Kane and Trochim, 2007; Trochim, 1989). It allowed international PIs to explore their perceptions of data sharing and applying the FAIR principles in a time-efficient and structured way (Kane and Trochim, 2007; Trochim, 1989). A key tenet of group concept mapping is that participants not only generate qualitative data but also analyze it thematically and assign priority scores. This makes it a measurable, non-directive alternative to, for example, thematic analysis. Typically, group concept mapping aims for ≥10 participants to enable meaningful cluster and rating analysis. Per the Regional Ethics Committee CMO Arnhem-Nijmegen (the Netherlands), this study did not fall within the remit of the Dutch Medical Research with Human Subjects Law (Wet Medisch-wetenschappelijk Onderzoek met mensen, WMO; Reference number 2020-6652). Digital informed consent was acquired before participation.
Participants
We invited 38 senior international PIs using convenience sampling and snowballing, starting with the professional network of our principal investigator (MJMB). This technique was partly chosen to recruit participants willing to commit to the considerable time investment demanded by concept mapping. Invitations were sent until at least 10 PI's agreed to participate. Invitees were approached based on their varied research backgrounds (ranging from cell research to epidemiological research), research settings (e.g., university and hospital), and their experience with collecting or obtaining large datasets that would be of interest to other (inter)national researchers.
Procedure
Concept mapping includes seven structured steps: (1) define participants; (2) formulate the seeding statement; (3) brainstorm: generate statements; (4) sort statements; (5) rate statements; (6) analyze statements; and (7) interpret concept map (Kane and Trochim, 2007; Trochim, 1989). Steps 3 to 6 were performed digitally using concept mapping software (Group WisdomTM, Concept Systems Incorporated). The participants performed steps 3 to 5, whereas the researchers (LR and MJMB) performed steps 1, 2, 6, and 7. Participants were informed of each step by email, which contained a link to the concept mapping platform and personal log-in details.
All participants were asked to brainstorm individually for ten minutes using the following seeding statement: ‘thinking as broadly as you can, generate statements on perceptions (e.g., barriers/worries/fears/advantages/facilitators) that researchers have related to data sharing and applying the FAIR principles (Findable, Accessible, Interoperable, and Reusable) in daily scientific practice’. Each participant was subsequently provided with all unique verbatim statements generated by the participants and asked to sort these statements according to theme, based on personal judgment, and label each category. There was no limit to the number of categories that could be generated. Finally, each participant was asked to rate the statements on a scale from 1 to 10, using the following question: ‘How relevant is this statement when a principal investigator is considering to share scientific data or apply the FAIR principles in daily scientific practice?’ Several demographic characteristics were also collected (age, gender, occupation, country of employment, and experience with data sharing).
Data analysis and interpretation
The concept mapping software uses multidimensional scaling and cluster analysis to identify patterns in participants’ sorted and rated data, which are graphically represented by two-dimensional cluster rating concept maps. The overall fit of the concept map is described by a stress value, which compares the obtained concept map to the dissimilarity matrix that served as input (Kane and Trochim, 2007). A stress value between 0.21 and 0.37 represents sufficient fit; a lower value within this interval is considered the most optimal (Kane and Trochim, 2007). Participant data were included for analysis if at least 105 statements were categorized and at least one statement was rated based on the required settings of the concept mapping platform. Additionally, participants’ sort data were evaluated to determine whether meaningful groups were formed. For example, sorting all statements into two categories called ‘perceptions’ and ‘other’ would not be considered meaningful for analysis.
A cluster rating map was created displaying clusters with statements similar in thematic content. Additionally, the software calculated the average priority rating of statements within each cluster, which was graphically depicted by assigning layers to each cluster, with more layers representing higher priority of the statements within that cluster. Clusters were labeled by the software-based word pattern analysis of the participants’ data. To obtain the concept map which best fit the data, the minimum (4) and maximum (15) number of clusters able to describe the data were explored, that is, the most general and specific content analysis, respectively. This minimum and maximum were dictated by the software a priori to enable meaningful analyses. Less than four clusters would likely become thematically too broad, whereas >15 clusters would likely become too specific. Therefore, we started with a cluster rating map containing 15 clusters, with a researcher (LR) evaluating the content of each cluster for percentage of thematic congruity. Next, the number of clusters was reduced one at a time until the data were represented by four clusters. For every cluster map, the percentage of thematic congruity per cluster was calculated (LR). If the thematic content of statements within one cluster was relatively homogeneous, but not adequately represented by the label, a new label was manually assigned. The final concept map was based on the number of clusters that resulted in the highest percentage of thematic congruity. Consensus meetings were held in case of ambiguity (LR and MJMB). Given our chosen analysis, we predominately provided descriptive statistics. However, we evaluated whether the country of occupation (categorized as EU vs. non-EU) affected participants’ perspectives using pattern match and Pearson correlation coefficients. In line with accepted standards, the strength of the correlation coefficient was classified as: <0.5 low, 0.5–0.7 moderate, 0.7–0.9 high, and 0.9–1.0 very high (Feinstein, 1987).
Results
Participant characteristics
We assigned 21 of the 38 participants to the brainstorm task (response rate 55.3%); 18 participants finished this task and were assigned to the sorting and rating task. One participant chose not to participate in this second task. Reported reasons for study dropout were lack of time (n = 3) and complexity of the task (n = 1). The data from three participants were excluded from the sorting task due to insufficient quality, that is, data sorted in two non-descriptive categories. Thus, the final concept map contains sorting data from 14 participants and rating data from 17 participants. PIs were professionally active in 10 different countries: Australia (n = 1), Canada (n = 1), Denmark (n = 2), Italy (n = 3), New Zealand (n = 1), Norway (n = 1), Spain (n = 3), Sweden (n = 3), United Kingdom (n = 1), and United States (n = 2). The median age of participants was 61 years (range: 37–73 years). Most were women (n = 11), worked in the EU (n = 10), and had previously shared data both nationally and internationally (n = 12, Table 1).
Characteristics of participating principal investigators.

Participants that met the concept mapping software threshold criterion of having sorted at least 105 statements in meaningful categories.
Participants that met the concept mapping software threshold criterion of having rated at least one statement.
Personal characteristics of the participants who completed the short online questionnaire before the sorting and rating tasks (n = 17).
Brainstorm: Generate statements
A total of 111 unique statements were generated in response to the seeding statement. Supplementary 1 provides an overview of all clusters and statements, including the average priority ratings.
Sort and rate statements
PIs sorted the statements into 5–13 categories (median = 9). Figure 1 shows the concept map which best fit the data; it contained five clusters with a stress value of 0.30. The clusters were labeled: Efficiency and collaboration, Privacy and security, Data management standards, Organization of services, and Ownership. All five clusters scored relatively high and within a narrow range (i.e., 6.28–7.69), which implies that each cluster is likely to influence researchers’ decision-making processes regarding FAIR data sharing. The cluster ‘Efficiency and collaboration’ received the highest average rating of 7.23, and includes statements such as: ‘Promotes alliances of researchers in the same field’, ‘Data sharing is essential for reproducibility in science’, and ‘Gain in efficiency and cost-effectiveness’. High prioritization of this demonstrates PIs’ positive intent. PIs then prioritized the clusters ‘Privacy and security’ (average rating 7.18) and ‘Data management standards’ (average rating 7.16) which contained PIs’ most pressing barriers. Cluster ‘Privacy and security’ refers to PIs concerns regarding individual data protection and contains statements such as ‘Individual data protection needs to be guaranteed’ and ‘There are legal issues with sharing these large, linked datasets with individual information’. Cluster ‘Data management standards’ underscores PIs need for tools and concrete guidance for every step of the FAIRification process. It includes statements such as: ‘Sharing data requires additional work to organize your own data in such a way they can be accessible for other researchers. The necessary resources (e.g., funding) to support this process are not easily available’ and ‘The provision of tools to make data description and formatting as easy as possible is essential’. PIs subsequently prioritized cluster ‘Organization of services’ (average rating 6.98) which contained barriers related to the unavailability of educational programs, data platforms, and (inter)national initiatives from funding agencies and other sources. Statements include ‘Education for principal investigators and their database administrators on FAIR principles and data sharing would incentivize’, ‘Develop registration and database search systems (similar to PubMed)’, and ‘An incentive is needed from research funding agencies to facilitate sharing databases’. Cluster ‘Ownership’ was rated least relevant to data sharing and FAIRification with an average rating of 6.28. The cluster contained statements such as: ‘Less acknowledgment and recognition of the researchers who generated the data (needed e.g., promotions)’ and ‘Problematic with some investors’ interests’.
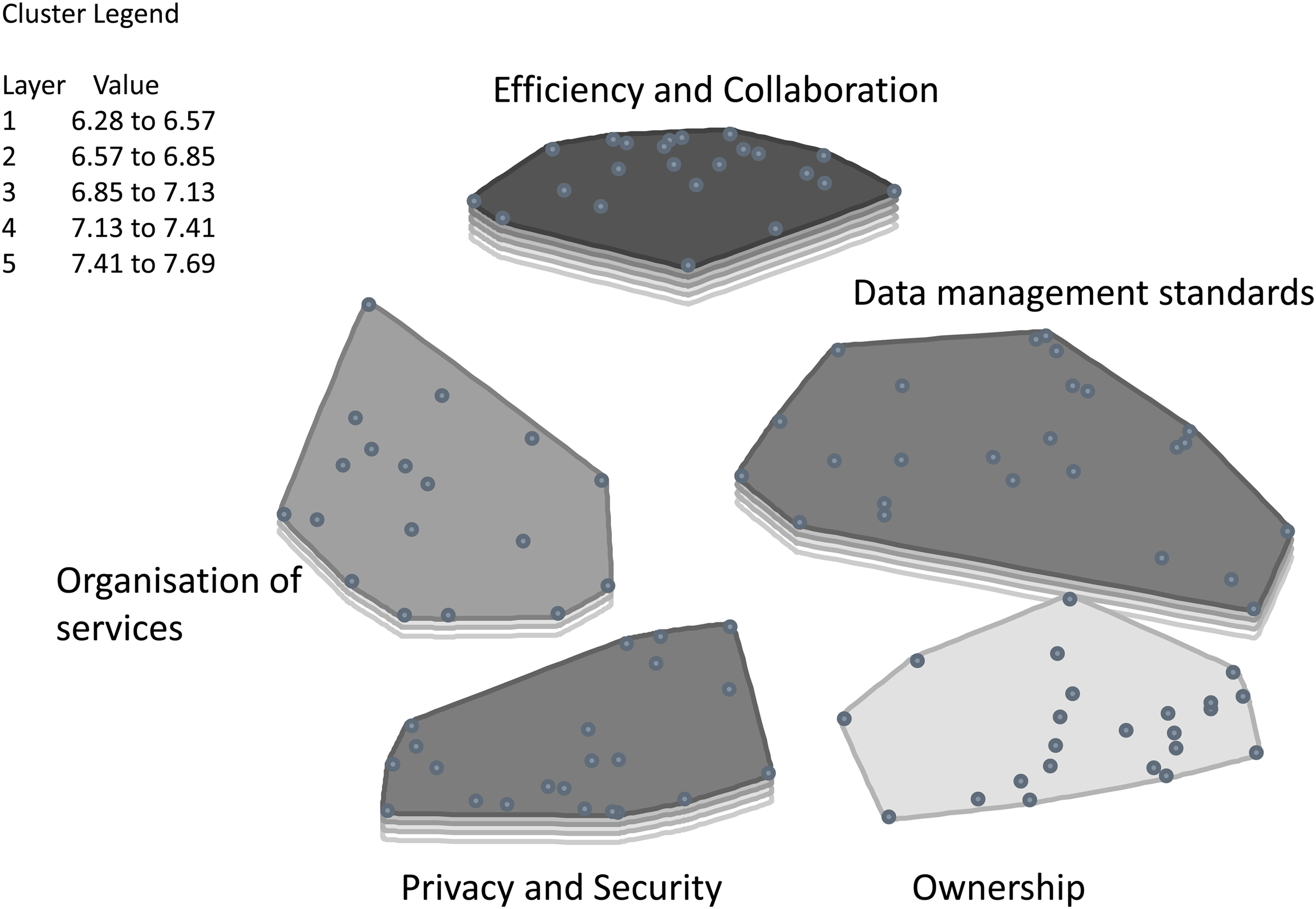
Cluster rating map.
A comparison of the rating patterns of PIs working in EU member states (n = 10) versus non-EU member states (n = 7) showed very high correlation (Table 2, Figure 2, r = 0.93, 95% CI [0.81–0.97]). Both groups prioritized the cluster ‘Efficiency and collaboration’. The main difference was the modestly higher prioritization of the cluster ‘Privacy and security’ by PIs working in non-EU member states (7.75) compared with EU member states (6.79). The average ratings of non-EU member state PIs were considerably higher, showing less variation than those of PIs working in EU member states, though this may be an artifact of the study design.

Pattern match.
Pattern match results of average ratings by country of employment and age.

Note: Average relevance rating reflects the average rating attributed by the PIs to the statements within each clusters based on their relevance to a PIs decision-making process to share their data and apply the FAIR principles. A higher score indicates higher relevance.
Discussion
This study is a critical contribution to better understanding incentives and barriers in FAIR data sharing in the medical research community and meets prior calls to conduct focused research by discipline (Chawinga and Zinn, 2019). To the authors’ knowledge, group concept mapping has not been previously conducted to identify underlying themes and prioritizations. Thus, using this method, we were able to provide an unfettered insight into senior PIs perceptions and prioritizations which would have been obscured in standard questionnaire research. Exploratory qualitative work is essential for developing robust research tools for quantitative research. Whereas large-scale surveys with well-designed recruitment methods create generalizable results, preliminary qualitative research, such as our work, is the essential first step for guiding content suitability. Thus, our research findings would ideally be used as a basis for creating targeted surveys addressing issues in FAIRication and data sharing, specifically within the medical research community. Such surveys would allow for the in-depth analysis of demographic influences, potential confounding factors, and longitudinal monitoring of perceptions, which generally fall out of the scope of qualitative research. Given the heterogeneity within the domain of medical research, stratifying across subdisciplines (e.g., obstetrics and gynecology, geriatric medicine, and oncology) and career stage (e.g., early, mid-, and late-career researchers) would likely be of benefit.
Our research reveals that senior PIs harbor a positive view of FAIR data sharing, as exemplified by participants highly prioritizing the cluster ‘Efficiency and collaboration’. However, the other four identified clusters only received modestly lower ratings and largely contained barriers to the implementation of FAIR data sharing in current research practice. Thus, when viewing these clusters collectively, it raises the question whether the benefits of efficiency and collaboration alone are sufficient in propelling FAIR data sharing across the medical research community. Arguably, until at least some of these reported barriers are addressed, widespread support of FAIR data will not translate into widespread practice.
We found that senior PIs working in medical research face unique challenges compared to other scientific disciplines regarding privacy. The emergence of the ‘Privacy’ cluster confirms that Tenopir et al. (2020) rightly postulated that medical researchers are less willing to share data because they work with human participants. Senior PIs reflected that medical data are subject to a high level of scrutiny in the public domain and stringent legal restrictions, often to the detriment of FAIR data sharing. For instance, the General Data Protection Regulation (GDPR), which went into effect in all EU Member States on May 25, 2018 (Bentzen and Hostmaelingen, 2019; Official Journal of the European Union L 119/1, 2016), harmonized EU data protection law, in part, to facilitate data sharing between countries (Vlahou et al., 2021). In contrast, however, its strict standards have led to widespread unease (Peloquin et al., 2020), with researchers becoming more reluctant to share data due to fear of potential GDPR violations and sanctions (Vlahou et al., 2021). Our research revealed that senior PIs working in non-EU member states were particularly concerned about privacy, which may reflect a cultural difference in scientific norms or the wide-reaching influence of the GDPR. To illustrate the limitations of GDPR identifiability standards, a recent statistical modeling exercise demonstrated that it could correctly re-identify 99.98% of Americans based on 15 demographic attributes in any de-identified dataset (Rocher et al., 2019). Although it was only a theoretical exercise, it underscores international concerns regarding anonymity and de-identification requirements in the wake of GDPR.
Our research further echoes concerns that the GDPR creates conflict between regulation and research ethics (Vlahou et al., 2021). Restrictions linked to informed consent requirements have led to delays in data sharing or even prohibited it, both within and outside the EU borders (Vlahou et al., 2021). To overcome these difficulties, some researchers have advocated amending the GDPR to facilitate data sharing (Peloquin et al., 2020; Vlahou et al., 2021). Our findings reveal that such policy initiatives are necessary to help researchers navigate the legal terrain surrounding FAIR data sharing.
Disconcertingly, senior PIs reported that they lack comprehensive knowledge of FAIR data management skills (e.g., the implementation of metadata schemes and data models). To date, the FAIRification process seemingly remains a specialist skill out of the repertoire of many research professionals. An international consortium has recently published a teaching and training handbook for academic institutions (Engelhardt et al., 2022), and hopefully, such efforts will bridge the gap for younger generation researchers. Whereas senior PIs agreed that education and training would be useful, currently there are too few incentives to gain it. Many research institutes neither formally acknowledge nor give professional credit for data FAIRification, as evidenced by senior PIs stating that this is currently undervalued within their own research institutes.
Substantial work has been undertaken to mitigate barriers in the FAIRification process (de Miranda Azevedo and Dumontier, 2020; Jacobsen et al., 2020; Kaliyaperumal et al., 2022; Thompson et al., 2020; Weigel et al., 2020; Wilkinson et al., 2018; Wilkinson et al., 2019) Some institutions, for example, have established dedicated data steward personnel to facilitate data stewardship tasks. A data steward refers to a specialist with expertise in data management, and in the medical research community, they are often skilled in FAIR principles. Based on our findings, we would purport that investment into data stewardship is the necessary pathway forward to overcome barriers in FAIR data sharing. The current lack of data stewardship is problematic since the operationalization of FAIR itself can be challenging. Tenopir et al. (2011), for example, previously hypothesized that the definition of metadata was unclear for many researchers. We have empirically shown that this lack of clarity exists, persists, and not only pertains to metadata but FAIR concepts in general. Interoperability is perhaps one of the most challenging concepts within FAIR, and it may be erroneously viewed as simply the use of established questionnaires. However, true interoperability is more demanding and requires specialist knowledge of ontologies and data models to create structured data which would support machine readability. The need for such expertise further underlies the important role of data stewards in facilitating future FAIR research.
Even when equipped with appropriate knowledge, carrying out FAIR data in practice is hindered. Senior PIs stated that funding agencies allocate an insufficient proportion of the research budget to data management, underestimating the extensive work involved in FAIRifying data. This challenge mirrors public health professionals working with routinely collected data (e.g., disease surveillance data or program monitoring) who also feel ill-equipped to address FAIR data issues partly due to lack of economic resources (van Panhuis et al., 2014). Yet, it also suggests that permanent funding and personnel, which is often the case in many public health organizations, is not sufficient in achieving FAIR data sharing. In fact, it only highlights the heightened disadvantage of the medical research community which regularly faces loss of skills due to transient staff funded under short-term grant awards.
We have largely focused on possible legal reforms, integration/incentivization of FAIR data training, and structural support (namely in the form of data stewards) as the necessary steps to facilitate FAIR data. Notably, other initiatives may be viewed equally, or perhaps even more, important. A recent systematic review found that the most common incentives for data sharing include co-authorship, embargo periods, data journals/publications, altmetrics, data sharing badges, and data advertisements; each carries its own inherent advantages and disadvantages (Devriendt et al., 2021). Yet, none of these incentives seem to be universally adopted, and their uptake varies in practice (Devriendt et al., 2021). Heightened focus should be given to such incentives, or combination thereof, when creating FAIR data frameworks. Moreover, evolving beyond the historical dependence on first and last authorship and identifying new indicators for professional recognition may further stimulate FAIR data (Devriendt et al., 2022a). Bridging such research findings to implementation in the medical research community requires clear policies with actionable objectives.
It would be remiss not to acknowledge the efforts of numerous individual journal publishers and funding organizations requiring FAIR data sharing as a prerequisite for funding and publication. However, the lack of harmonization between frameworks can result in disjointed and sometimes conflicting implementation (Chawinga and Zinn, 2019). Moreover, in many cases, data are stored outside of a repository, hindering external access (Federer et al., 2018). Repercussions in the case of noncompliance for data sharing are often non-existent because many funding bodies simply lack robust monitoring systems (Devriendt et al., 2022b). Whereas it is out of the scope of this article to provide a comprehensive overview of initiatives directed toward FAIR implementation, these recent studies would suggest that further policy research and development is needed in this area.
Further bolstering the argument for unified policies is the intrinsic link between FAIR data and Big Data. In broad terms, both concepts intersect across issues of data storage, access, and processing (Gvishiani et al., 2021). However, the former refers to solution-oriented guidelines directly related to data management and data sharing whereas the latter typically refers to rapid large-scale data processing and generation (Gvishiani et al., 2021). Data FAIRification undoubtedly plays a pivotal role in improving Big Data. Therefore, encouraging the adoption of these principles across multiple sectors as a general policy would be to the benefit of research and society.
Our study has several potential weaknesses. Firstly, convenience and snowball sampling were used to recruit participants, which was initiated from the research network of our PI (MJMB). Although a widely used and accepted recruitment technique in qualitative research, it is subject to selection bias. For example, if our PI largely collaborates with other researchers engaged in data sharing from other high-resource countries, the prominence of the cluster, ‘Efficiency and collaboration’ may have been overemphasized. Since these sampling techniques largely inhibit the thorough analysis of demographic characteristics, additional qualitative research within specific subgroups may be of benefit (e.g., senior PIs with less experience in data sharing or from low-resource countries). Secondly, the sample size may be regarded as small, particularly in comparison to survey research. We did, however, exceed the minimal threshold recommended for concept mapping. Still, to identify persistent themes, additional similar qualitative studies could be undertaken in other settings and/or within specific medical subdisciplines, with the ultimate goal of a meta-synthesis of results. This could potentially be achieved through approaching department heads of research universities, medical research institutions, and/or other key stakeholders. Thirdly, the data analysis was performed by one researcher (LR); however, to promote objectivity, the thematic content of each cluster for the most general to the most specific content analysis was systematically assessed as previously described in the Methods section. Lastly, concept mapping software is vulnerable to the quality of the participant data, particularly when participants’ categorization of statements is averaged. Speculatively, participants who generated relatively few categories negatively influenced the analysis resulting in grouped statements somewhat dissimilar in content, although participant outliers were removed. Despite these limitations, our exploratory analysis demonstrates the benefit of concept mapping to guide survey creation by revealing themes not previously captured in other studies.
In conclusion, senior PIs feel ill-equipped, underfunded, and lacking sufficient support to create FAIR data. Until local and international structural changes are undertaken, achieving FAIR data in the broader medical research community will continue to be a fragmented endeavor. This research lays the foundation to conduct further research into motivational factors for FAIRication and direct future policies in the expansion of FAIR data.
Supplemental Material
sj-csv-1-bds-10.1177_20539517231171052 - Supplemental material for FAIR data sharing: An international perspective on why medical researchers are lagging behind
Supplemental material, sj-csv-1-bds-10.1177_20539517231171052 for FAIR data sharing: An international perspective on why medical researchers are lagging behind by Linda Rainey, Jennifer E Lutomski and Mireille JM Broeders in Big Data & Society
Footnotes
Acknowledgments
The authors acknowledge the considerable contribution and time investment of all the participating principal investigators without whom this research would not have been possible. The following participants consented to being acknowledged by name: Marta Román, Department of Epidemiology and Evaluation, IMIM (Hospital del Mar Medical Research Institute), Barcelona, Spain; Ellen O’Meara, Kaiser Permanente Washington Health Research Institute, Seattle, WA, United States of America; Sisse Njor, University Research Clinic for Cancer Screening, Department of Public Health Programmes, Randers Regional Hospital, Randers, Denmark; Montserrat Rué, University of Lleida, Lleida, Spain; Nehmat Houssami, University of Sydney, Sydney, Australia; Fredrik Strand, Department of Oncology-Pathology, Karolinska Institute, Stockholm, Sweden; Montserrat Garcia Closas, Division of Cancer Epidemiology and Genetics, National Cancer Institute, Rockville, MD, United States of America; and Per Hall, Department of Medical Epidemiology and Biostatistics, Karolinska Institutet, Stockholm, Sweden. The funder had no role in the study design; in the collection, analysis, and interpretation of data; in the writing of the report; and in the decision to submit the article for publication. All authors were independent from the funder. All authors had full access to the data in the study and can take responsibility for the integrity of the data and the accuracy of the data analysis.
Authors contribution and guarantor information
Concept and design were done by LR, JEL, and MJMB. Acquisition, analysis, or interpretation of data was done by LR and MJMB. Statistical analysis was done by LR. Drafting of the manuscript was done by LR, JEL, and MJMB. Reviewing and amending of manuscript were done by JEL, LR, and MJMB. All authors read and approved the final manuscript. The corresponding author attests that all listed authors meet authorship criteria and that no others meeting the criteria have been omitted.
Availability of data and materials
Competing interests
All authors have completed the ICMJE uniform disclosure form at ![]() and declare: all authors had financial support from the Dutch Cancer Society (KWF) for the submitted work; no financial relationships with any organizations that might have an interest in the submitted work in the previous three years; no other relationships or activities that could appear to have influenced the submitted work.
and declare: all authors had financial support from the Dutch Cancer Society (KWF) for the submitted work; no financial relationships with any organizations that might have an interest in the submitted work in the previous three years; no other relationships or activities that could appear to have influenced the submitted work.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the Dutch Cancer Society (KWF) under Grant 12522.
Licensing
The corresponding author has the right to grant on behalf of all authors and does grant on behalf of all authors, a worldwide license to the publishers and its licensees in perpetuity, in all forms, formats and media (whether known now or created in the future), to (i) publish, reproduce, distribute, display, and store the contribution, (ii) translate the contribution into other languages, create adaptations, reprints, include within collections and create summaries, extracts, and/or abstracts of the contribution, (iii) create any other derivative work(s) based on the contribution, (iv) to exploit all subsidiary rights in the contribution, (v) the inclusion of electronic links from the contribution to third party material wherever it may be located, and (vi) license any third party to do any or all of the above.
Transparency declaration
The lead author affirms that this manuscript is an honest, accurate, and transparent account of the study being reported; that no important aspects of the study have been omitted; and that any discrepancies from the study as planned have been explained.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.