
Abstract
The size and variation in both meaning-making and populations that characterize much contemporary text data demand research processes that support both discovery, interpretation and measurement. We assess one dominant strategy within the social sciences that takes a computer-led approach to text analysis. The approach is coined computational grounded theory. This strategy, we argue, relies on a set of unwarranted assumptions, namely, that unsupervised models return natural clusters of meaning, that the researcher can understand text with limited immersion and that indirect validation is sufficient for ensuring unbiased and precise measurement. In response to this criticism, we develop a framework that is computer assisted. We argue that our reformulation of computational grounded theory better aligns with the principles within grounded theory, anthropological theory generation and ethnography.
Keywords
This article is a part of special theme on Machine Anthropology. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/collections/machineanthropology
Introduction
With the digitization of many practices textual and pictorial communication is becoming an ever more prominent part of social interaction and communication in contemporary societies. With the rise of social media, we now have communication on culture, politics and social issues from a large part of the population instead of merely elite actors. While the increase in the population and practices that produce text is an important new data resource for the social sciences, it also poses additional challenges. We know that different populations speak and write differently, we know that text takes on different meanings in different contexts. In many data sets we have little prior knowledge of which populations and practices produced the texts. Furthermore, the size of the text corpus makes it impossible to read manually. This puts large demands on text analysis methodology that needs to ensure discovery of categories within the data, the grounding of the interpretations, correct classification of content, efficient and valid scaling of the classification, and it needs to ensure good and unbiased measurement of the categories. In this article we seek to contribute to the development of such a methodology by stressing a computer-assisted, as opposed to what we argue is a computer-led, approach to interpretation and classification of text. Our critique of current approaches and our proposed solution only considers the task of interpreting and classifying documents and not other types of investigation, such as the inference of sentiment or the structural analysis of symbols.
Two approaches to computational text analysis are commonly juxtaposed in an attempt to overcome the tasks identified above: a supervised approach and an unsupervised approach (Grimmer and Stewart, 2013; Evans and Aceves, 2016; Nelson et al., 2018; DiMaggio, 2015). In the supervised approach, common within computer science, machine learning models learn from humanly annotated text. Here the human coder is the ground truth that automated classification is trained on and evaluated against. In other words, supervised approaches rely on manual coding. The practices of coding and quantifying text have been criticised within the social science for a number of pitfalls: 1) coding assumes that categories are known while they are mostly not 2) that human coders are biased and unreliable (Nelson, 2020; Lee and Martin, 2015; DiMaggio et al., 2013), 3) and that coding hides away the most vital part of working with text material, namely, accounting for and justifying the final interpretation of documents (Biernacki, 2012). Partly for these reasons, unsupervised machine learning methods have been much more popular in the social sciences. Unsupervised methods for text classification, especially topic models, have been praised for aligning with dominant assumptions within cultural sociology and qualitative inquiry: Inductively deriving categories from the data, allowing for the polysemy of words and the heteroglossia of documents, assuming the relationality of meaning (DiMaggio et al., 2013; Nelson, 2020). This has also led authors to claim that there is a strong relationship between grounded theory (GT) and unsupervised procedures (Nelson, 2020; Baumer et al., 2017). This relationship between unsupervised procedures and GT is a potentially fruitful starting place for thinking about machine anthropology. This is because GT shares many concerns with different aspects of anthropology, namely, developing theory from systematic qualitative inquiry(as opposed to only testing theories), dissatisfaction with overly abstract and generalizing theories being forced upon data, and a commitment to understanding and taking local knowledge and categories into account when developing one’s analysis.
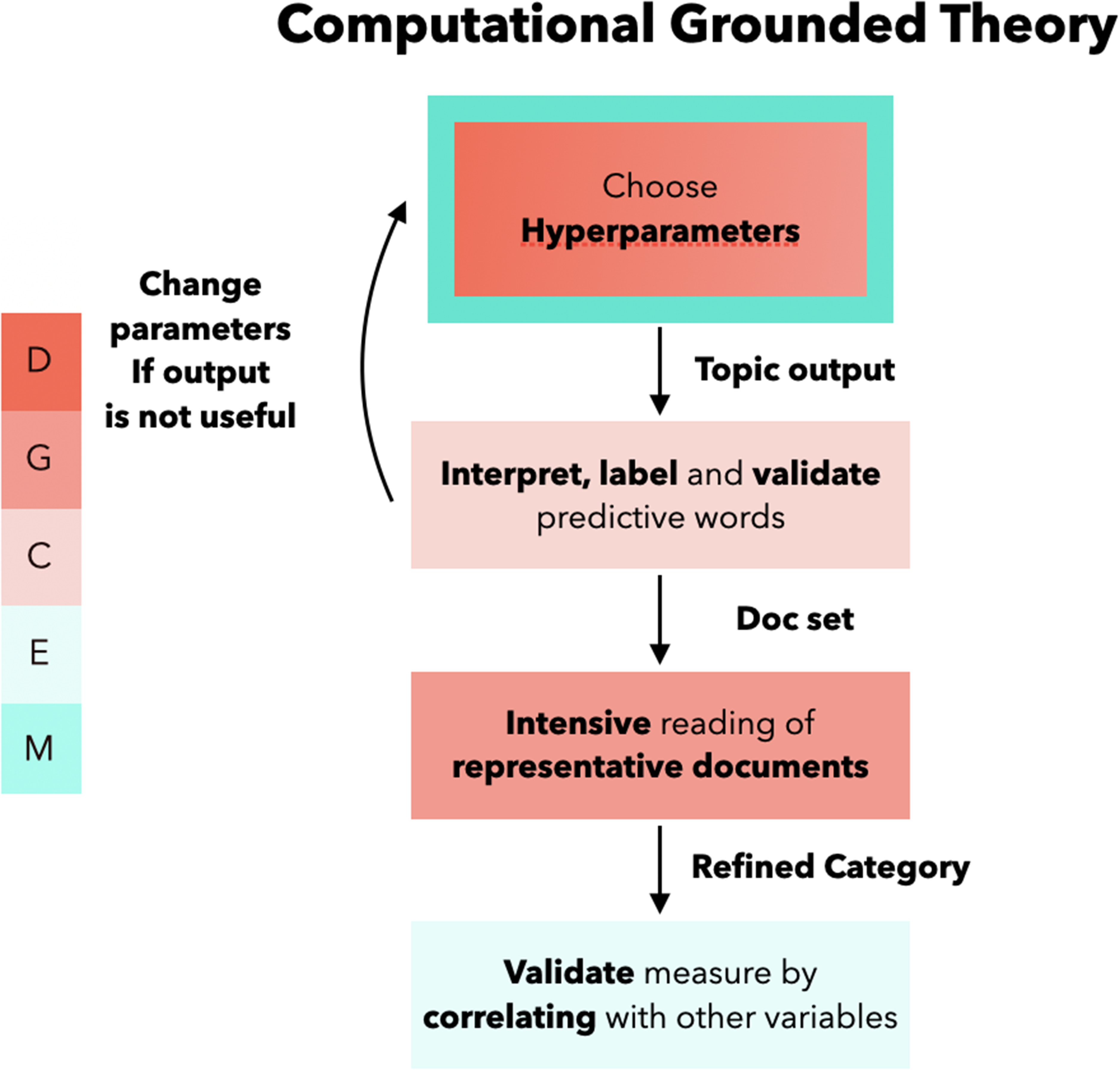
This is a illustration of the workflow of computational grounded theory. The different colors indicate what more general task is being handled at the different stages of the research process. D stands for Discovery; G for grounding; C for Classification; E for evaluation and validation of measurement.
Nelson (2020) most clearly articulates the methodological framework behind the use of unsupervised methods and qualitative inquiry, coining it computational grounded theory. She details three steps: pattern discovery, pattern refinement and pattern confirmation. Key to computational grounded theory is that patterns are located by the computational model and not the human coder, i.e, it is computationally led to ensure against the biased and constrained researcher. The researcher can then judge the usefulness of the categories returned by the model given substantive interests and read paradigmatic text to gain an in-depth understanding of the category and refine the interpretation. Lastly, Nelsons argues, in line with many others, that pattern confirmation can be done by correlating the model’s measure of the category with some other variables that indicate the same category. In its present form, computational grounded theory relies on the assumption that, 1) unsupervised models locates the relevant clusters of meaning within a corpus 2) the researcher can learn from minimal immersion, and lastly 3) the best way of validating a classification is through indirect validation.
In this article we assess the plausibility of each of these assumptions and reformulate the framework of computational grounded theory on the basis of this assessment. Regarding pattern discovery, we demonstrate that Latent Dirichlet Allocation (LDA) topic models are, in many cases, unable to discover known planted topics. Using a simple simulation design, we show how the model not only enforces a specific number of topics, but also a uniform size distribution (i.e., the proportion of topics are equal). This property of the model helps explain well known problems with topic models including: instability across model runs, and fused and duplicate topics. These results cast doubt on the ability of LDA topic models to locate the relevant clusters of meaning in a text corpus. We further demonstrate that Hierarchical Stochastic Block Models approach to modeling topics is able to discover topics when dealing with unbalanced classes. Our second argument is more principled. We argue that we cannot assume to know how word patterns map onto meaning and, therefore, can’t trust unsupervised models to locate patterns of meanings within text. This has the consequence that we can’t let discovery be computer led. Furthermore, the idea that the human researcher can read only the paradigmatic text retrieved by the model in order to provide a holistic and interpretatively valid account goes against much qualitative research that argues that there is a substantial phase of learning where the researcher comes to terms with how signs are used and what they refer to theoretically within a specific field site. This means that the researcher’s ability to read and understand correctly can’t be assumed, but must be ensured and accounted for. Lastly, we present evidence that we can’t rely on indirect validation because it does not ensure precise or bias free measurement. Our critique of computational grounded theory leads us to a reformulation which, instead of being computer led is computer assisted. We develop the central steps in a research framework we call computer assisted learning and measurement (CALM) that go from discovery, to grounding, classification, validations and, finally, measurement.
The article starts by clarifying the relationship between GT and strands of anthropology. The following section runs through and assesses the different aspects of computational grounded theory, moving from discovery to measurement. In the following section we will introduce our own framework and develop what we call computer assisted text analysis, again moving through the various steps of the analysis. The paper then discusses the reproducibility, credibility and analytical limits of the CALM framework. Lastly, we end with a conclusion.
Grounded theory and anthropology
In this section we introduce some of the central ideas behind grounded theory(GT) and clarify its similarities and differences to parts of anthropology. In particular, we’ll argue that GT and anthropology share 1) a commitment to theory generation from systematic qualitative inquiry, 2) a critical view of overly general and detached theories based on logical deduction and finally 3) a commitment to understanding the point of view of those that they study.
In the formulation of Glaser and Strauss (2009), GT is an approach to generating theory that focuses on emergent theory generated from data analysis, as opposed to theory generated from logical deduction from prior assumptions. The latter, according to Glaser and Strauss, leads to too many opportunistic uses of theory that do not fit the data (Glaser and Strauss, 2009, 6). As an alternative to theoretical deduction, Glaser and Strauss argue that theory should be “systematically worked out in relation to the data during the course of research. Generating a theory involves a process of research.” (Glaser and Strauss, 2009, 6). A central part of GT is theoretical sampling, where cases are chosen with respect to developing the category or hypotheses of interest. The goal is not empirical generalization, but rather theoretical saturation (Small, 2009). Hence, theoretical sampling concerns selecting what cases to compare for a specific theoretical propose(Glaser and Strauss, 2009, 47). Three points of comparison are vital to control according to Glaser and Strauss: populations, conceptual level and degree of similarity. Importantly, this is not because one has to compare things that are alike, but rather because theory development is dependent upon how one compares across these three parameters. The method used is the constant comparative method which analyzes each instance of category with prior instances in order to get at its defining features, central properties and relations to others categories. Typically, the constant comparative method relies on open coding of instances working towards an integrated theory. In this manner, GT combines the systematic coding procedure of more traditional quantitative content analysis, typically aimed at theory testing, with qualitative work aimed at developing theory, the latter is typically done without any systematic data analysis (Glaser, 1965).
There are many similarities between GT and anthropology in their approach to theory generation. Both GT and many strands of anthropology see overly general and abstract theories as highly problematic. While anthropology, more than GT, has done so for ethical and political reasons, both stress the analytical problems with ill fitted abstract theories. This concern is a central motivator for anthropology’s strong tradition for developing theories from their field work, as opposed to merely testing theories. Radicalized in the ontological turn (Holbraad and Pedersen, 2017), anthropology takes the ethnographic field site as the source of their analytical categories rather than merely their object. In this process no prior ontological assumptions are sacred. Rather, generating new, often radical, conceptualizations in dialog with ones material is often seen as the goal. From this perspective it is clear that GT and parts of anthropology are similar in their ambition to generate theory from qualitative inquiry.
Symbolic interactionism’s influence on GT and its dictum that people act towards things on the basis of the meaning they attribute to them makes GT committed to understanding meaning-making within their data in order to develop theories that fit the social situation studied. This is, of course, one of the essential tasks of fieldwork, namely to understand the “natives point of view” (Malinowski, 2002). In some formulations, this is the main task of anthropology (sometimes called cultural translation). By most it is seen as a requirement for an ethnography that the ethnographer understands and to some extent lives up to the requirements to interaction in their field site, before any analytical statements are made (Lichterman, 2017).
Below we will compare computational to non-computational grounded theory especially regarding the phase of discovery and interpretation of categories. However, computational grounded theory and the wider use of topic models in the social science also uses topic models as a measurement device. The output of such models is used as either the independent or dependent variable in regression analysis (Evans and Aceves, 2016). Therefore, we also evaluate computational grounded theory as a strategy for producing precise and unbiased measurement.
The logic of computational grounded theory
In this section we run through the three different steps of computationally grounded theory (CGT): discovery of patterns, interpretations and grounding of the patterns and pattern validation.
Discovery
When confronted with large text data, researchers have the challenge of discovering what categories are in the data and interpreting large amounts of text. A central claim in CGT is that this dual challenge can be solved by making discovery computationally led. According to Nelson, the computational model’s task in pattern discovery is to reduce the messy, complicated text into a simpler and more interpretable list or network of words (Nelson, 2020, 7). This allows for relevant categories to emerge from the data that the researchers, due to their own preconceptions or the complexity of the text, had not considered. This prevents the researchers from introducing their own biases into the material. The simpler representations are then interpreted and categorized in a fashion similar to normal content analysis, but, Nelson argues, this process is “fully and immediately reproducible” (Nelson, 2020, 13), unlike human-coded text. In sum, computational pattern discovery that uses actual frequencies of the (co-)occurrence of words to locate ideas or concepts in the data constitutes, according to Nelson, a more “reproducible and scientifically valid grounded theory” (Nelson, 2020, 13). In CGT, the task of constant comparison from grounded theory aimed at discovering new categories from the data is done by an algorithm that takes word distribution across documents as input in order to detect patterns. Two important assumptions are made when using topic models, such as the Latent Dirichlet Allocation (LDA) topic models, for discovery. The first assumption is that the model returns actual clusters of co-occurring words. The second assumption is that patterns in co-occurring words map onto meaning. We will discuss each assumption in turn.
A typical imaginary used to justify the use of topic models is that they cluster words together based on their co-occurrence in text (DiMaggio et al., 2013). The co-occurrence thesis is common in quantitative text models(in linguistics its typically referred to as the distributional hypothesis). Often the linguist Robert Firth is quoted for saying that “words shall be known for the company they keep” (Firth, 1957, 11). This is taken to mean that words should be understood through the words that they co-occur with and not in isolation. The place of this co-occurrence can either be in a sentence, in a document or other ways of defining the location of words. The trust we have in the model is that it will cluster words that co-occur and separate words that do not co-occur. In the following, we look more closely at the LDA model and under what condition we might expect it to return clusters of co-occurring words and under which condition we might suspect this not to happen, before we seek further evidence through a set of simulations.
LDA assumes that documents consist of multiple (K) topics, and can be represented as a multinomial probability distribution over topics
To understand the behavior of LDA it is instructive to look at the formula for computing the weights of the collapsed Gibbs sampler used for optimizing the LDA model i.e., for locating the latent topics. Here optimization is done by iteratively sampling the topic assignment of each word in a given document. Across documents each word has a distribution of topic assignments, but in the individual document the topic is “hard” assigned to each word. The topic assignment of a given word in a document (
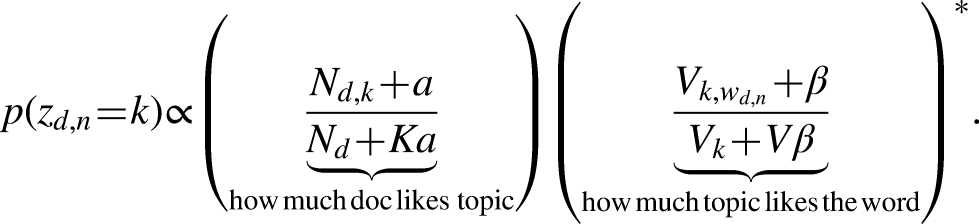
This formula is taken from
The important detail is the normalizing term (
We argue that the trade-off between co-occurrence and the penalty on large topics leads to two well-known issues reported by researchers: duplicate and fused topics (also known as hodge-podge or junk). In the first case the topic model has multiple very similar distributed topics. This is the result of one large topics (
To underline this point we provide a visual proof of the behavior. By designing a simulation with known topics we challenge the LDA model to locate them under two different scenarios: One with perfectly balanced classes, and one with a dominant topic 25 times bigger than the others. Next we visualize both the document term matrix as well as the resulting topic outputs from LDA using heatmaps to make both the scenario and behavior of the algorithm fully transparent. 1 In both scenarios each document draws words from 1 of 3 sets, each uniquely associated with 50 terms, and with a small random probability of words from the other topics. Document length is 200 words. In the first balanced scenario 100 documents are drawn from each set. In the unbalanced scenario, 100 documents are drawn from the first two sets, and 2500 documents are drawn from the last set. The results are displayed in Figure 2.

Behavior of LDA with unbalanced classes. THe figure shows two document term matrices and the resulting LDA topic assignments of each term.
In the two document term matrices displayed in figure 2, we can see a clear separation of our planted ’topics’, and indeed in the balanced case, we see that each set is perfectly separated into 3 topics by LDA. One might expect that given even more empirical evidence for a specific cluster of co-occurring words, it would further help the model. However, when we add more documents drawn from set 3 - the unbalanced case - we see that LDA fails. As predicted by the tradeoff described above, we see a fusion of the two smaller sets (same number of terms, but the set is prevalent in more documents), and a duplication of set 3 into two separate topics having almost identical distributions over the vocabulary. These results are obviously critical to the use of topic models for measurement, but as we argue below also for discovery.
Unaware of the above problems, the main work of the researcher has been to locate the right number of topics (Nelson, 2020; DiMaggio et al., 2013). Scholars argue that one can find the appropriate number of clusters by reading the outputted list of words and from this judge the adequacy of the number of clusters. Nelson (2020) propose that the number of topics should be determined by minimizing the number of junk (fused topics) and duplicate topics determined only by qualitative inspections of words and optionally also documents. Too few clusters will return conglomerates of different topics, too many clusters will split single topics into multiple clusters - both of these scenarios can be detected by the researcher. This assumes that one can see when a topic is split in two and when two topics are combined into one. However, if the topics are different in size, as we expect, then the smaller of two topics clustered into a larger one will not necessarily have any of the most prevalent words in the displayed output. This means that the smaller topic can create unanticipated and systematic measurement error, but also that the researcher is left to conclude that the small and unobserved topic does not exist in the data. Using another simulation design we investigate this.
To demonstrate the problem of being mislead by the model we construct a corpus of almost 50 000 Facebook posts by politicians with 15 predefined categories of varying prevalence. Figure 3 reports on how often 15 planted categories are overlooked by the researcher inspecting LDA model outputs from multiple model runs. We distinguish between the researcher inspecting a quality topic with informative words from only one category (Accepted), to the researcher seeing informative words but in a low quality fused topic (Visible), and finally independent of quality inspections by the researcher, whether a model has at least one topic where a Cateogry is highly concentrated (Clustered) - i.e., that a significant part of the documents related to a given category has high topic loadings. The third distinction is important as evidence that the planted categories are discoverable by the model (i.e. have high quality). If given enough parameters (

Discovery across model runs to locate the optimal Model. A test data set was created by planting 15 categories. Running more than 100 000 models varying K and the number of topics, we report the probability that the model and researcher detect the category. Each figure displays the percentage of models detecting a category with varying detection criteria. To the right we define a model as having detected the category if the category is the dominant part of at least one topic, regardless of quality. Here we see that almost all models do indeed locate the planted topics. In the middle figure a category is detected if a predictive word from the category is present in the top 20 words ordered by the Frex score. To the left we include only accepted topics, i.e. topics not deemed as ’junk’ topics by the researcher. The criteria here is that predictive words from different categories should not be present in the top 20 words as ordered by the Frex score. The last one is the important one, as only accepted topics can be considered as being discovered. Here many categories are very often overlooked.
We see that several categories especially the smaller ones, are seldom found even by the model and the problem becomes even more pronounced if we look at how many models actually present quality topics that allow the researcher to make sense of them (i.e. without fusion). The results point to the problem of letting the model determine the universe of categories pertaining to a specific corpus. If researchers are led by the Topic Model output in understanding what politicians talk about and how, then they will be systematically biased towards the specific types of topics the model can locate as it interacts with the unbalanced distribution of true categories in the data, duplicating large topics and randomly fusing smaller topics.
The fact that we can’t uncritically trust the model output has further consequences for discovery. Scholars have argued that computational models “…can surprise, challenging presumptions or pre-existing theory, and lead the social analyst to abductively generate new theory by imagining what would be socially required for those patterns to exist” (Evans and Aceves, 2016, 23). However, given that we can’t trust the model output, other scholars have argued that, “Topic models must find what we know is there. Ultimately, a topic model’s trustworthiness must be determined by informed human judgments.” (Ramage et al., 2009, 4). If we differentiate between different degrees of discovery we might say that topic modeling, in the computationally led research procedure, only allows for weak discovery where we only find the categories we already know. This is a problem from the point of view of grounded theory, which is, precisely concerned with the development of novel categories from the data partly independent of assumptions and prior knowledge of the researcher.
If we can find better algorithms, is it then possible to rely on the co-occurrence assumption? The Hierarchical Stochastic Block Models (HSBM), a network-based approach to topic models, that provide the same multi-membership type clustering of words and documents as LDA, have been demonstrated to perform much better than LDA based topic models, even on data simulated from a Dirichlet distribution, while also addressing the issue of highly unequal topic sizes. Furthermore, HSBM does not require researchers’ input on number and size of topics as this is part of the model inference (Gerlach et al., 2018; Shi et al., 2019). In our simulation HSBM, is able to find clusters of varying sizes (see Figure 4) and it does not merge clusters with little or no overlap. While HSBM is a welcome improvement of unsupervised methods for locating topics in large text corpora, this does not necessarily imply that we should stick with the computationally led analytical strategy. This is at least partly because the models still rely on word features and word co-occurrences, and there is an unknown and uncertain relationship between word features and the meaning of a text.

Behavior of HSBM under unbalanced classes. Here we test HSBM with a 100:1 imbalance. The correspondence between the document term matrix above, and the topics below in figure 4.b shows that it is unaffected by the class imbalance. Furthermore HSBM locates the topics unambiguously compared to LDA in the balanced scenario.
If we return to the famous Robert Firth quote, it is important to note that for Firth the proper understand of an utterance was based on what he called the context of the situation. Context of the situation was originally proposed by Malinowski in order to simultaneously broaden the scope of the relevant context and stress that the situation should always be accounted for in the analyses of linguistic expressions. For Malinowski the broader context was both the culture and environment: the “general condition under which a language is spoken” (Malinowski, 1994, 6). The situation captures the occasion, the prior events, the aim and function of the statement that gives the statement its meaning (Malinowski, 1994, 6). Firth’s versions of the context of situation is similar with a focus on the persons and personalities, the verbal and non-verbal actions, relevant objects and the effect of the verbal actions (Firth, 1957, 9). From this point of view, it is clear that there are other relations then words relations that should be accounted for before inferring the meaning of documents. Therefore, we can’t trust or assume that computational models locate the relevant and adequate categories and their boundaries. While words or their co-occurrence do not necessarily define the meaning of a statement, they might be effective indicators of their meaning. However, the relation between word pattern and meaning can’t be assumed but has to be proven in every given case, because the relations between word distributions and meaning are likely to change when the corpus changes.
Interpretation and refinement
In the pattern refinement step, the researcher perform what Nelson calls a computationally guided deep reading. This step is supposed to 1) confirm the plausibility, 2) add interpretation and 3) possibly modify the patterns in order to provide a holistic reading. Thus, we move from mainly discovering categories to interpreting them. According to Nelson, there are two problems the computational guidance is supposed to solve: the natural limits to scaling deep reading and the biased nature of our reading. Both of these concerns are handled by algorithms that identify texts “that are representative of a particular theme” and that can “calculate the relative prevalence of that category” (Nelson, 2020, 24). A careful application of these algorithms enables the researcher to “read and interpret any amount of text without the burden of reading the full text”(Nelson, 2020, 26). Furthermore, both the researcher and the research community “can trust that when a quote is chosen as an example of something, it is not an outlier but is indeed representative of some theme in the text” (Nelson, 2020, 26). From reading the most prevalent words and documents, the researcher then labels the topic as being about something specific and, based on the reading of the paradigmatic cases, writes an analysis of the topic. Here, saturation is ensured by the model, that has ’read’ the entire corpus and now presents the paradigmatic exemplar to human analysts. Instead of the human having to read through extensive number of cases, as is common in grounded theory, the computer has done so. In other words, while human analysts read and interpret, it is the computer that leads the selection of documents, and guarantees the robustness of the pattern and the representativeness of the documents. This assumes that the model has correctly measured and delimited a topic and that the meaning of words used in a particular text match on to the meanings that the words take on in the other texts. Furthermore, it assumes that the reader is able to identify and analyze the categories without substantial exposure.
Even if we assume that the model has found a relevant category and delimited it properly (which we demonstrated above is highly unlikely), we can’t assume that the documents that are estimated to contain a lot of given a topic are paradigmatic or representative of a larger topic. It might be that the document contains many of the words pertaining to a topic, but that does not entail that it represents the meaning of a given topic in other documents. A paradigmatic case is a case that supports learning, and most clearly illustrates, develops and explicates the logic active in many other cases. Locating a paradigmatic case then only makes sense in context of having analysed many other cases which all support taking a given text as the exemplar best able to illustrate the logic of the wider set of cases. This support is not merely word counts but actually meaning-making. Reading a limited set of documents might then make the analysts severely misunderstand the wider logic revealed by a specific case.
A second problem is that CGT procedures do not demand that the researcher becomes familiar with the field of study. The idea that we can read very little text and get the model to read the rest fails to recognize that the reader herself has to become qualified to interpret meaning-making in the field. While it has been argued that CGT does not replace the competent analysts, the process of gaining familiarity with the field is always external to the proposed research design. Like ethnographers, researchers have to trial and error in order to test their interpretations and come to terms with both what people actually mean and why the researcher’s initial interpretation may have been wrong. Reading a few documents does not support the qualification of the human reader. Even if the researcher is a domain expert, the corpus will have certain specificities that have to be learned and accounted for. Furthermore, given that the ambition is theory development the domain expert can’t, by definition, rely on prior knowledge but has to learn anew - something which requires intensive and extensive reading. In grounded theory, the sampling procedure is controlled by the researcher in order to test, develop and further theorize in close relation to the data at hand.
Validation and Measurement
We now turn from discovery and interpretation of patterns to their validation and measurement. How do we validate the topic model before we use it as measurement? In most applied research only inspection of top words and documents, a version of face validity, is used. In the more programmatic statements(Grimmer and Steward 2013; Nelson 2020), author argue for indirect validation strategies, such as concurrent validity and/or predictive validity. Firstly, it is assumed that face validity and indirect validation measure are sufficient secondly that direct validation is not possible. Here we will present some evidence that challenges these assumption(for a full test of Topic Models for measurement see Ralund et al. 2018).
The inspection of top words (most prevalent words in a topic) and documents is the way in which a topic is taken to be meaningful. It is assumed that if these top words and document are clearly about a given topic then the model has discovered a valid topic that can be used for measurement. This assumes that the top words and documents are representative of the wider distribution. However, we have no guarantee that top words represent the meaning of unobserved words and documents, both due to the risk of unobserved fusion, and the simple fact that one is inspecting a non-random and very biased sample of the topic-word distribution. There is certain tension between interpretation and validation. If one takes into account more than the top 10 or 20 words the topic is hard to interpret, yet labeling a topic based on the top words gives little certainty of the precision of the classification.
In Figure 5 we use the same artificially constructed corpus with 15 known categories. Here we look at the relation between perceived quality of the top words and the actual match of the topic to the planted categories. On the vertical axis we have the precision of the topic classification weighted by topic-document probability and on the horizontal axis, the percentage of top words that are indicative of a given category. While a higher percentage of matches does improve the precision of the classification, there is still high variation. With 0.9 top words matched to a topic you might still end up with classification that has a 0.60 precision (even as low as 0.20), that is, 4 out of 10 documents will be classified wrongly. While the quality of top words is obviously correlated with quality of classification, the figure also shows that word inspection is no guarantee for good measurement.

The figure shows the efficacy of the quality inspections from the two different representation schemes. The widely used FREX scores (red) as defined by Airoldi and Bischof (2016) and the most probable words (blue).
What about other forms of indirect validation, such as concurrent validity and predictive validity? It is important to note that normally these types of indirect validation are used when you have two indicator variables of the same theoretical construct and you want certainty that the indicator variable is measuring the theoretical construct you claim. But this assumes that the indicator variable itself is properly measured, i.e. has no systematic measurement error. We can’t use indirect validation to ensure against measurement error.
The obvious solution to this problem is to validate the measure directly by coding a random sample from a given topic and see how often the model is right or wrong in its classification. It is standard procedure in supervised machine learning to test the models performance against a test set. While some might argue that the topic is a latent feature that can’t be directly validated, it can be validated once the researcher has labeled it a specific topic.
Summing up on our run through of computational grounded theory we believe that some aspects of the methods makes it less in line with concerns and ambitions within anthropology. LDA topic models can only support weak discovery of categories what the researcher already knows. This goes against, for example, anthropology’s commitment to producing novel theories and novel conceptualizations from fieldwork. Likewise, the idea of minimal immersion does not ensure that the researcher understands the point of view of those studied. Lastly, the assumption that co-occurring words is an appropriate level of analysis goes against anthropological theories of meaning, such as Malinowski idea of the context of the situation. Below we will present a framework that combines computational models and in-depth reading in ways that seek to allow for strong discovery, support the constant comparative method, and to qualify the human reader and provide good measurement.
From computer-led to computer-assisted learning and measurement
In this section we will take the consequences of the above critique and argue for a computer-assisted approach to text analysis. First, we will reformulate the relationship between computational text analysis and in-depth text analysis, and try to clarify how the different modes of analysis complement one another. Then we will present the outline of a methodological framework that moves from 1) discovery; through 2) interpretation; and on to 3) classification and measurement.
Given the issues raised above, how should we think of the relation between the qualitative and the computational when working with large scale text data? What does it mean to move from computer-led to computer-assisted analysis of text data? First of all, it means that the justification for a given interpretation and/or classification of text comes down to the qualified human reader rather than a computational model. This is done by demonstrating that the researcher understands how signs are used within a specific community (or context) and how a given interpretation adds to, or is in line with theoretical interests of an community of inquiry. Part of this work relies on an overview of what is going on within a field and partly on saturation, namely having seen enough cases containing enough variation, to arrive at a robust understanding and theory of the focal phenomena.
Gaining both an overview and reaching saturation is typically a challenge. Getting an overview is difficult given the large heterogeneity in what a corpus is about and the high variations in size that different categories typically have. Reaching saturation around any given category is difficult because the category will very likely be very rare in the data. Hence, locating these cases can’t be achieved through random sampling. The cases of interest typically do not have a known location. This means that they can’t be found by looking somewhere specific. Even within each category, the researcher needs to gain an overview and saturated understanding of each relevant subcategory: here again we, are likely to observe high variation in size between the different sub-categories. Also, we do not simply want to learn from cases but also to measure their prevalence or relations to other variables. To accomplish this, we need to classify large amounts of texts.
An important constraint on our framework is that it starts from the premise that we do not know how words, word relations or the context of the situation in any general sense map on to meaning making. All we can hope for is that certain features (word, word-relations, author, audience, recipient, time and place) might work as effective indexes of certain meanings, as opposed to being necessarily related to them. Thereby, we take account of the contextuality of meaning that both Malinowski and Firth highlighted with the idea of the context of situation, but we do not seek to address how situational elements in general relates to meaning. The meaning bearing unite is the sentence in context, yet precisely what elements of this context that are relevant to the meaning of a sentence is something learned within the specific setting that one is analyzing. This happens through manual reading of text and actively seeking out relevant contextual elements. Mainly through this type of reading can one gain a robust idea of whether a sentence is of a certain general type and what we might learn from it.
This means that manual reading and classification is the practice through which discoveries are made, interpretations are grounded and proper classification is ensured. The analysis undertaken by a qualified reader is the “ground truth”. The computational models ensure that the human reader finds enough cases with enough variation to allow saturation. Furthermore, it can enable the scaling of the classification made by researcher. Our framework is quite conservative in its division of labour between the machine and the anthropologist.
Figure 6 is a simple version of the CALM workflow. It goes from initial discovery, grounding interpretation, classification, validation and measurement. Like the computer-led workflow, there are various stages where one moves back and forth. Below we will detail these steps and try to explicate the logic.

The CALM workflow.
Discovery
In the CALM framework the goal of discovery is two-fold. First, computer-assisted discovery might propose a relevant partition and categories by clustering certain words. These clusters might support, supplement or challenge categories the researcher already has from prior qualitative work, domain knowledge or theory. Second, computer-assisted discovery provides the researcher with words that can be used as an initial search set, seeds that can be used in order to find instances relevant to further develop one’s interpretations of a given category.
The particular clusters that a given model returns are supportive if are indicative of the same categories that our theory/prior work would lead you to expect. The clusters might also supplement our theoretical expectations by proposing new categories that we had not thought about. Lastly, the located clusters might challenge our theoretical expectations by redrawing the boundaries around a set of known categories. An important difference from a computer-led approach is that, in this phase, everything is taken to be at the most uncertain level of inference. The words that are clustered together by the model are conceived as a highly uncertain sign of a given category. Thus, the topics that the model does not find are not necessarily deemed to be irrelevant, and we do not necessarily respect the boundaries proposed by the model either.
Following the previous discussion, we use HSBM to discover initial search terms. After discovering interesting clusters, we now direct the search to extend and saturate our preliminary categories by retrieving similar terms. Here we use King et. al’s (2017) approach to keyword search, and Word2Vec to get a measure of similarity between words. Word2Vec is a word embedding model in which multidimensional vector representations of each word are tuned to solve the task of predicting neighboring words (Mikolov et al., 2013). Word2Vec has proven to be an effective way of expanding query sets and category dictionaries (Tulkens et al., 2016). Just as with HSBM, we use Word2Vec to find what we expect to be effective search terms, instead of relying on Word2vec to capture a certain cultural logic within a corpus (for this more ambitious and risky endeavor, see Kozlowski et al. (2019)). The task is similar to a snowball crawl, where one transverses a given area in a network in order to sample cases. In order not to get stuck in particularly non-productive areas of the embedded space we either purposefully alter the search term list or randomly recombine sub-samples of previously included relevant terms. This ensures a greater search coverage.
In this phase the researcher is analyzing on the level of words. Word and word relations can be effective in stimulating our imagination regarding the actual meaning making within each document. The mode of discovery is one that focuses on possibilities, where the theoretical imagination is sparked to life by patterns of words. The end product is a set of categories with a connected set of search terms. Each category can naturally have subcategories with connected subsets of search terms: none of which are taken to be empirically grounded yet.
Interpretation and grounding
In the interpretation and grounding step the researcher retrieves a document set by applying the search terms. The goal is first to judge the adequacy of the category, given the documents, and second, to read and learn from an extensive and varied set of documents relevant to a given category (qualifying the researcher). Third, to write an extensive analysis of the category. Fourth, to construct a coding scheme with a definition of the category, illustrated with exemplars and boundary cases, that can be used to classify content in a transparent, interpretatively valid and reliable manner. Lastly, it is also here that the researcher becomes certain of the most theoretically productive analysis given the data.
The search terms are meant to find the relevant instances to overcome the problem of rarity and, secondly, to ensure enough within-category variation to support theoretical saturation. The analyst can apply the constant comparative methods to the document set in order to develop defining features, its subdivision and continuums and analyze its relation to other categories (Glaser, 1965, 439). There is an important trade-off in the construction of the search terms. A too inclusive strategy will reproduce the problem of rare events, where too many irrelevant documents are retrieved - the problem of low precision. On the other hand, we have the problem of low recall, where the search set is too restrictive so that we miss many of the relevant instances of the phenomenon. Importantly here, recall and precision regards insuring saturation, not good measurement. A solution to this problem is iterative sampling where the search term lists are continually updated on the basis of developing the theory and hence, move from a more restrictive to a more inclusive search set, or going into depth with specific subcategories.
In this mode of reading, an important question is the organization and construction of the text data - similar to what is call unitarization in content analysis (Krippendorff, 2004). Our own work is primarily with Facebook data and some of the tricky issues with unitarization of documents are solved by the fact that Facebook itself is organized in relatively comprehensible and manageable units. Typically, posts in a group, a page or personal profile and with connected comments and comment-to-comments. Yet, there is still the question of how much context should surround each post and comment when the researcher is reading. This has to be determined partly by theoretical focus and partly by experience. While, as argued above, we are never sure what each encounter demands of us in terms of context tracing, for practical reasons it is worthwhile trying to organize one’s material in such a way that relevant context, on average, is displayed or easily accessible when reading.
This is the step that both ensures the interpretative accountability and validity of the text analysis and its theoretical relevance. This implies that it is not only coding and memo writing that are necessary, but also accounts of the development of one’s own interpretative journey in moving from one understanding to the next and documenting the events where one reached a new understanding of the meaning-making within the field. This is what Lichterman calls interpretative reflexivity (Lichterman, 2017). The step ends with both a qualitative analysis of a category, but also a more concise coding scheme that, in principle, can be used by others.
Classification and Validity
At this point in the analysis, we should have a qualified researcher, a developed understanding and analysis of a set of categories and an applicable and valid coding scheme. The next step is to apply this coding scheme to classify content in order to both train a machine learning model and test it.
At this stage the coding process is closed and no theoretical adjustments to the category are to be made. This does not mean that there is not any interpretation going on, but this is at the level of correctly applying the code to content rather than to correct the understanding of the category. Therefore, the prior qualification of the reader is important because there is still a lot of non-explicated knowledge that might be relevant for the application of the code. Ideally, the coding scheme is for externalizing, objectifying and making transparent the knowledge gained from in-depth reading. Yet, while coding previously involved research assistance in order to scale the classification, the advent of supervised machine learning allows the researcher to rely on much less coded data.
For training the machine learning model, the CALM framework relies on active learning procedures (for a social science example see Wiedemann (2019)) where the machine learning model uses model uncertainty in order to find the most informative cases to be coded. In traditional supervised machine learning, the training data is given to the model all at once, and hence, risks both a lot of redundant information about certain cases and lack knowledge of others. For example, in our own prior work we used nearly 9000 random sampled examples for training a model on a single category (with only approximately 900 positive cases) and 3000 for testing. Therefore, supervised machine learning has traditionally been seen as very expensive compared to unsupervised methods for classification. However, with the rise of active learning and transfer learning, the cost is radically declining.
Transfer learning has dramatically changed the efficiency of the features used to solve classification tasks. Language models that have trained on huge amounts of text have been shown to enable what has been called few-shot learning, which means that the model only needs very few training examples in order to achieve high performance (Devlin et al., 2018). A second set of features is the extensive dictionaries developed in the prior steps. These are used as noisy labels, which means that they are assumed to contain a lot of noise and are only seen as indicative of category to the extent that they do not contradict the human label. These are efficient for giving the active learning loop a “warm start” to already start directing its efforts and sample positive cases even in highly unbalanced scenarios ( Wiedemann (2019) for the concept of least confidence sampling with bias towards the positive case).
The last aspect of classification is constructing the test set. While the training set becomes smaller due to more efficient models, the same is not the case with testing. As we have argued, automated text classification can be highly biased, and with the use of language models trained on huge data sets, we are opening up to the biases that are known to exist in these models. While a lot of these biases should be handled in training, this is not certain. Besides the biases from the language models, many other sources of bias might occur: word usage might differ across the population, making it easier for the model to correctly classify from some parts of the population, there might be more data from some time periods and from specific author populations. Again, this points to the importance of the test set and that it is large enough to analyze the performance across relevant units of analysis in order to ensure that one’s results are not driven by measurement error. This is also the Achilles heel of automated text classification, because estimating the performance of the model across the relevant variables quickly demands an unfeasible and very large test set, especially when the categories are rare (rarity increases sample size in order to ensure statistical power).
Discussion
In this section we discuss the CALM framework’s relation to the recent focus on abductive inference, a trend within both qualitative sociology and anthropology, the concerns with reproducibility and credibility central to computational grounded theory, and finally some notes on the limits of the CALM framework.
Given that grounded theory is about theory generation, what implications do recent criticisms and alternatives focusing on abduction do to our discussion? A stronger focus on existing theories and working with multiple theories, rather than assuming that theory will emerge from data analysis alone, fits our framework well. Precisely, when the idea of natural clusters is left behind and the search is led by the researcher, then it is possible to try out different theories and make risky abductive inferences. Abduction, to be effective, also depends upon robust evidence or else the surprising fact that should provoke creative theorizing can’t be trusted. From a substantive, and not methodological point of view, the most boring answer to a surprising fact is that it results from measurement error. While it is true that certain partitions returned by a given model might lead to creative hypothesis generation, abductive analysis as laid out by Tavory and Timmermans also relies on extensive empirical work following the initial abductive inference in order to arrive at a well constructed theoretical account (Timmermans and Tavory, 2012). CALM supports this through extensive sampling across different axes of variation.
One of the central concerns of computational grounded theory is reproducibility and the CALM procedure seems less reproducible. It is clear, that with extensive readings and a variety of search operations, it is a more complicated procedure than running a few topic models and varying the number of topics that should be returned. On the other hand, every search operation can be traced, documented and reproduced if the operations are coded in a programming language. Most importantly, reproducibility from a qualitative point of view is more about understanding the perspective and experiences that created a certain interpretation. Here, extensive quotes and explicit theoretical choices in the analysis of a category provide a more solid background than references to model output.
The shift to the researcher and the discrediting of the computational model also raises the question of credibility. The credibility of computational grounded theory, to a great extent relies on trusting the model, which we argue one should not. How then is the credibility of the qualitative analysis communicated and ensured. Again, we would partly appeal to classic qualitative strategies, such as demonstrating the capacity of the human reader through their display of sensitivity to subtle differences in meaning making and their ability to describe the specifics around their field site. Second, the extensive search in large text data sets makes it possible to ensure within-case generalization - something qualitative studies have been criticized for lacking. The logic being that, given the map of the corpus that the models provide and the places that have been visited by the researcher, there is good reasons to believe that all relevant parts of the corpus have been analysed.
CALM is meant to facilitate the direct interpretation and classification of text and not word level or structural (at least not in its quantitative sense) analysis of text. If one is interested in the mentioning of specific people or places, or specific slogans or symbols (as long as they are captured by a specific token), then CALM is not needed. Furthermore, CALM does not focus on the structural properties of documents or words. While, our framework uses network methods, such as HSBM, these are meant to support discovery of topics and not to provide network analytical statistics. Hence, something like the network centrality or betweenness centrality of a document or a symbol in a corpus is not the analytical focus of the framework.
Conclusion
In this article we argue against the computer-led version of computational grounded theory. We argue that this approach puts unwarranted trust in the model’s ability to locate the relevant categories in the data. First, we demonstrate that the LDA topic model, used extensively in the social sciences, can’t locate planted topics if classes are unbalanced, and instead produce duplicates and conglomerate clusters, a problem that cannot be fixed by simply inspecting top words, and instead warrants a deeper skepticism of the output. Second, we argue that we can’t assume to know how meaning maps on to word pattern; hence, we can’t rely on any given model to provide us with relevant categories in the data. Third, that computationally grounded theory’s idea that the model can locate the few representative documents fails to support the necessary qualification of the researcher through varied and saturated immersion into the corpus. Finally, we argue that the validation strategies used in contemporary social science, face validity and indirect validity, do not ensure against substantial measurement error.
As an alternative, we argue for a computationally assisted approaches that puts the researcher in charge of all operations, but uses the model’s ability to locate potentially useful patterns and word similarities. This approach builds extensive search term lists with the help of computational models and uses the lists to retrieve document sets that are read and analyzed in-depth using the constant comparative method. In line with grounded theory, the research process, in its discovery and interpretation phase is built up around theoretical sampling, where the researcher is constantly sampling in order to support theoretical saturation around a given category. The phase of interpretations support the qualification of the researcher and an extensive analysis of a given category, which is turned into a coding scheme used for classification. The classification step uses an active learning framework combined with transfer learning in order to effectively train a model to replicate the researcher’s classification. The costs saved in training the model are instead used to test the model and investigate differential biases across the variables of interest.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Hjalmar Bang Carlsen was funded by the H2020 European Research Council (Grant number: 834540) as part of the project ‘The Political Economy of Distraction in Digitized Denmark’ (DISTRACT).