
Abstract
To better understand the COVID-19 pandemic, public health researchers turned to “big mobility data”—location data collected from mobile devices by companies engaged in surveillance capitalism. Publishing formerly private big mobility datasets, firms trumpeted their efforts to “fight” COVID-19 and researchers highlighted the potential of big mobility data to improve infectious disease models tracking the pandemic. However, these collaborations are defined by asymmetries in information, access, and power. The release of data is characterized by a lack of obligation on the part of the data provider towards public health goals, particularly those committed to a community-based, participatory model. There is a lack of appropriate reciprocities between data company, data subject, researcher, and community. People are de-centered, surveillance is de-linked from action while the agendas of public health and surveillance capitalism grow closer. This article argues that the current use of big mobility data in the COVID-19 pandemic represents a poor approach with respect to community and person-centered frameworks.
Keywords
Introduction
The SARS-CoV-2 virus emerged and infected people in contact to form pandemic. In response, researchers tracked pandemic through space via devices as people as data. The description of the movement of people between and within geospatial units as measured by “human mobility data” became one of the most widely used ways to inform infectious disease models and describe the expected spread and impact of the COVID-19 pandemic. Formerly locked behind private company paywalls, but released in response to the pandemic, the public availability of aggregated big mobility datasets incited a surge of publications using big mobility data for public health research (Becker et al., 2021; Grantz et al., 2020; Oliver et al., 2020). The current article describes the practices and circumstances which culminated in a central tendency towards these big mobility data during COVID-19 pandemic, turns a critical eye to their use, and discusses considerations critical to ensuring public health stakeholders remain attuned to using this data towards a grounded “social good” (Poom et al., 2020). This “social good” is assumed to be aligned with equity-based, participatory practices in public health such as community-based participatory research or participatory action research—practices which aim (and have been shown) to improve research transparency, effectiveness and dissemination through diverse, local stakeholder engagement and empowerment (Brett et al., 2014; Halladay et al., 2017; Newman et al., 2011; Wallerstein and Duran, 2010). It is this article's contention that the current use of big mobility data in the COVID-19 response represents a poor approach with respect to community and person-centered frameworks, raising questions about whether the hype of big mobility “data for good” matches its ultimate impact.
In the convoluted chain of big mobility data (re)production, people provide data describing their location, their daily practices, and their interactions with others. They are made into a data subject (Thatcher, 2016; Vayena and Madoff, 2019; Vayena et al., 2015). When examined in aggregate, as is the norm, their social groups, households, and larger communities become subject in turn. Their data is collected, processed (producing meaning, reproducing other meanings) and privacy-preserved (reducing meaning) by a company that then produces a “data product”. A surveillance data asset of value that may be analyzed internally, sold as part of a data analytics package, sold to contractual third party, or provided to a researcher or public health official (whether for a fee or, as discussed here, pro bono due to crisis) (Zuboff, 2015). Does this process of collection-transfiguration-provision align with the stated goals of public health? The public health researcher or public health official should be most concerned about the people and their reciprocal communities, particularly during a pandemic where the critical risk processes may occur at the level of the household, bedroom, local bar, hospital, or nursing home (Gilmore et al., 2020). Without meaningful participation, input or consent, the process of abstraction from person to data to company surveillance asset to model, de-centers people and communities from the COVID-19 pandemic response by the fundamental nature of its construction. Linnet Taylor notes that “research often treats data production as a flat, homogenous process that is not influenced by place—while also hailing Big Data as unprecedently granular and rich” (Dalton et al., 2016). The focus on how people's embodied COVID-19 risk and lived life patterns were described through impersonalized datasets acknowledges the “fundamental spatiality” of COVID-19, and the potential uses of big mobility data, while questioning the further routinization of surveillance capitalism in public health (Poom et al., 2020).
This article contains five main sections: (1) the backdrop of big mobility data and its specific attraction to public health researchers for COVID-19 is briefly reviewed, (2) the specific practices, narratives, and claims of data release are discussed in relation to a “place-based public health,” (3) the ethical uncertainty of big mobility data and public health surveillance is detailed, (4) exemplar models at two geospatial levels are used to illustrate the promise and challenges of using big mobility data, and (5) it is argued that the uncritical use of big mobility data muddle the link between public health surveillance and public health action via the de-centering of people and communities.
This article has limitations. Big mobility data is a capacious data category encompassing diverse data types (Chen et al., 2016). Six specific mobility datasets from six organizations have been selected as the focal point of analysis due to their heavy use in the COVID-19 public health literature and affiliation with surveillance capitalism (see Table 1). They range from data collected from a single company's userbase (Meta, Google, Apple) to datasets incorporating an amalgam of data sources (SafeGraph, Unacast, Maryland Transportation Institute and Center for Advanced Transportation Technology [CATT]) (Apple, 2020; Blumberg, 2020; Google; Jin and McGorman, 2020; Liu et al., 2020; Unacast, 2020b). This paper is particularly interested in the interface between private mobility data aggregators and academic-public public health actors and how their interactions produced a certain type of COVID-19 knowledge. Similarly, its scope is limited primarily to North America and the European Union, however, the companies and their relations are multi-national so, at times, discussion drifts between national boundaries and traditional geospatial demarcations. It centers on big data analytics versus technology-assisted active surveillance (e.g., app-based contact tracing, quarantine enforcement) by virtue of its use of COVID-19 models as the “outcomes” of private-academic-public partnership. However, these surveillance strategies are considered in a limited capacity when considering public perceptions on using location data to respond to COVID-19. Poom et al., writing from early in the pandemic asks, “How can we use mobile Big Data for social good, while also protecting society from social harm?” (Poom et al., 2020). This article asks, how can big mobility data be used, if at all, for community-engaged public health research which centers stakeholders as partners and encourages emancipatory change? What sort of public health knowledge is created? Writing from within an extended pandemic, this article attempts to answer with an analysis of the construction, claims, and impact of these big mobility datasets through their use in COVID-19 models.
Selected mobility datasets.
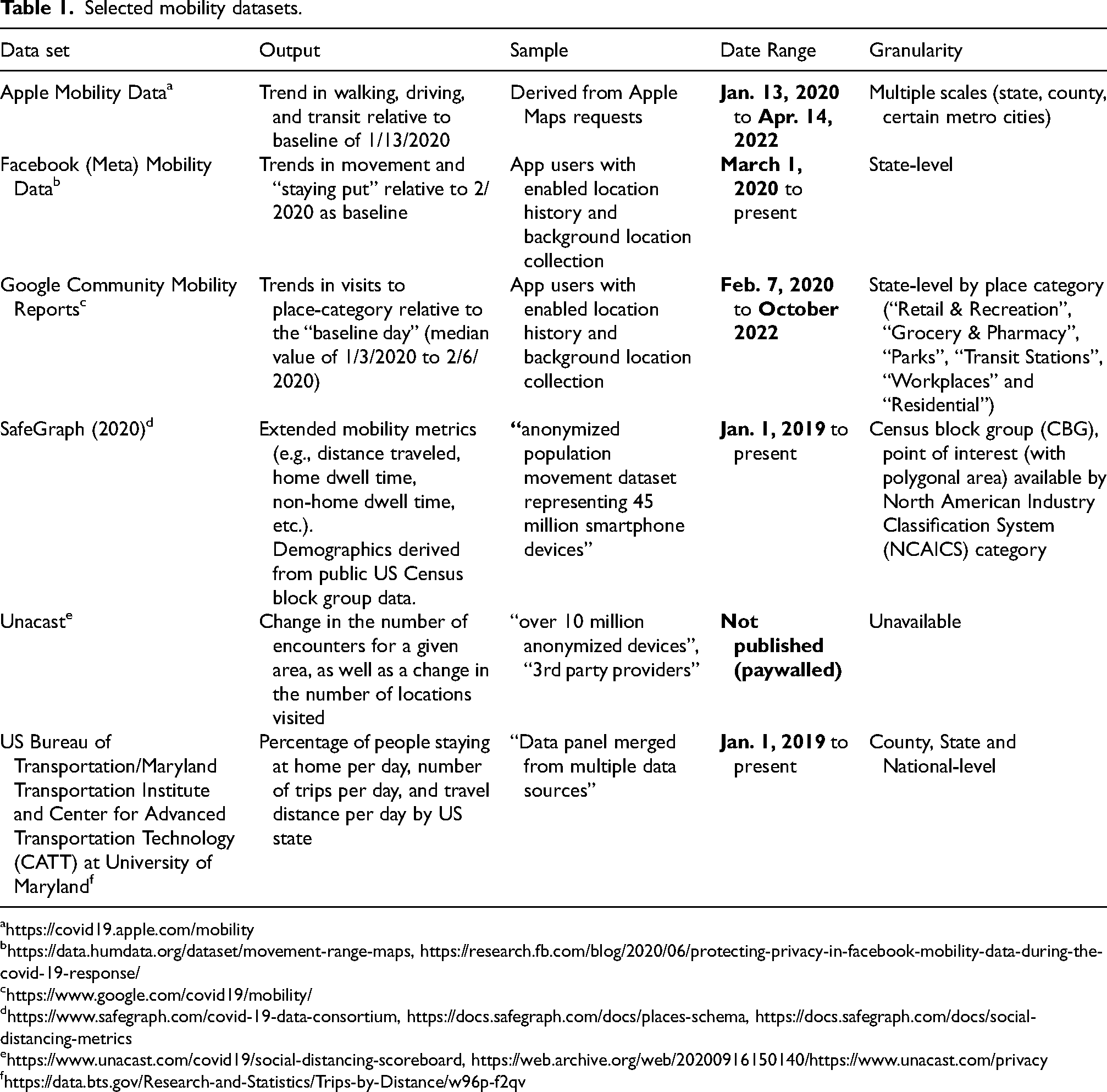
https://data.humdata.org/dataset/movement-range-maps, https://research.fb.com/blog/2020/06/protecting-privacy-in-facebook-mobility-data-during-the-covid-19-response/
https://www.safegraph.com/covid-19-data-consortium, https://docs.safegraph.com/docs/places-schema, https://docs.safegraph.com/docs/social-distancing-metrics
What is the utility of big mobility data for public health?
The current glut of COVID-19 data emerged from a very particular set of circumstances. Early in the pandemic, no data visualizations were available to monitor the COVID-19 case curve. Groups of journalists and private citizens collated statistical briefings from state health departments in Google Sheets (The COVID Tracking Project, 2020). An enterprising MIT student independently built a predictive model which would be quoted by the CDC and used by prominent public health researchers as a reference model to estimate “testing targets” for each US state (Gu, 2020; Jha et al., 2020). Although analyses were ongoing in more traditional government or academic spaces, these early efforts at data sharing manifested in decentralized channels. Pre-print servers assumed an outsized importance compared to the slower peer-reviewed journal. From this chaotic period, technology companies pivoted to publish their own datasets and analyses, often under the banner of “data for good.” The “data for good” moniker, a term with unclear origin but likely popularized by Meta's (then Facebook) 2017 Data for Good program, would become the common banner of mobility data for COVID-19 mitigation (McGorman, 2020). Of near-unique value was the release of private big mobility datasets. While previously used in infectious disease research to describe the spread of malaria, dengue and cholera or in disaster response after events such as earthquakes, never was the promise and hype of big mobility data for public health greater than in addressing the COVID-19 pandemic (Bansal et al., 2016; Finger et al., 2016; Wesolowski et al., 2012, 2015).
In brief, big mobility data is data derived from network-connected devices and used to describe the movement and behavior of individuals with respect to geospatial boundaries (or other points of interest). Following the definition described by Vayena et al., big data is used “in the sense of very large, complex, and versatile sets of data that are constantly evolving in terms of format and velocity” (Vayena et al., 2015). It can be contrasted to small data which, in the mobility space, is collected through active solicitation through survey methods or small scale, limited time location tracking studies (Chen et al., 2016). It comes from many sources: mobile phone (via telecommunication company data), GPS (in-vehicle trip data or in-phone trip data), location-based service (smartphone apps that use location-based services to pinpoint location), Wi-Fi access point coordinates, Bluetooth connections, wearable devices, geo-tagged social media data, toll tags, public transportation smart cards or even bike share use (Sy et al., 2020; U.S. Department of Transportation, 2017; Xin et al., 2022).
Big mobility data is surveillance data. It is data collected at massive scale for the purposes of dataveillance, following the definition described by Rita Raley (citing Roger Clarke), to describe the movements and abstractly describe the life-ways of its subjects (Raley, 2017). Big mobility data is a product of surveillance capitalism. Zuboff defines surveillance capitalism as “as the unilateral claiming of private human experience as free raw material for translation into behavioral data.”(Zuboff, 2019). It is a system of extraction and commodification without appropriate reciprocities towards its source and target populations (users, customers, or otherwise). When using big mobility data, public health researchers and other actors are operating in the “behavioral futures markets” of surveillance capitalism, trading prediction products and participating in a dataveillance ecosystem. Under conditions of reciprocity and community-engagement, whether under principles of representative democracy or a more situated engagement, perhaps, this can be justified. This article will argue that these conditions were not met or, at least, not centered in the COVID-19 response. However, ultimately, this discussion and the considerations that follow accept the existence of surveillance capitalist datasets and the routine, longitudinal collection of behavior through personal devices. Following the lead of Poom et al. and Zuboff, this article aims to avoid reifying the “inevitability” of surveillance capitalism by problematizing the unprecedented use of its data. The rapid (in)digestion of big mobility data and its commercial entanglements into the COVID-19 response was not predestined. A more local, person and community-centered response is/was/will be possible.
As the reader may have already noticed, the scope, scale and velocity of big mobility data makes its discussion difficult. Discussion will center around the methods used by the six exemplar datasets previously mentioned. The central constructs of the mobility dataset are derived from global positioning system (GPS) coordinates and their convolutions. An essential data product to track a device's movement is the “origin-destination” pair. In most of these datasets, this represents the difference in the location of the tracked device at one point in time to its location at another point in time. More nuanced analysts then set a “nighttime home threshold” for time spent stationary. If a device stays stationary for time above this threshold, the location becomes the device's “home” location. In this way, the utility of the dataset becomes more clear. In addition to metrics of accumulation available from the “origin-destination” pair (e.g., distance traveled, mean daily distance traveled, etc.), one can now estimate mobility as one might live it (or so goes the claim). Proportion of time spent at home can be estimated—both at a single time point, in comparison between two periods of time (i.e., pre- and post-pandemic restrictions) and, as a panel, longitudinally. Essentially, the movement of network-connected devices act as a surrogate for human movement—from home to school, residence to residence, residence to business. Socio-demographics may then be derived to create “synthetic populations” from existing reference datasets at varying scales; for instance, at the macro- (e.g., US Census data) or micro-level (e.g., contact surveys, age mixing surveys) (Mistry et al., 2021). For instance, SafeGraph, one of the organizations discussed, uses US Census data to derive probabilistic demographics from its harvested mobility data (Squire, 2019a). When combined with infectious transmission modeling techniques, a synthetic population in motion is created, at-risk of infection, at-risk of death, often recovering but always, always moving.
For the public health researcher, the primary utility of geolocation mobility data lies in its putative ability to describe human mixing behavior (transmissible behavior) and, pragmatically, study aggregate human behavior in response to an intervention—here, for instance, the public response to physical distancing policies and associated public health interventions aimed at limiting mobility to reduce COVID-19 spread. Each device is assumed to represent an individual (even if reported in aggregate) and, thus, device location change and clustering (spatial or temporal) represents an estimate of an individual's movement and their physical proximity to other individuals. Additionally, higher quality data may be available at smaller geospatial units or even at the level of a “point of interest” (POI) (e.g., grocery store, sit-down restaurant, movie theater, etc.) (SafeGraph). Thus, these datasets claim to allow for an analysis of transmission dynamics to occur at flexible geospatial levels: from the continent to the “neighborhood” to the “point of interest”. The latter being most notable with its inference of not just trajectory but also activity, addressing the “trajectory rich but activity poor” problem (Gong et al., 2016). While lacking the rigor of manual contact tracing and individual–individual contact networks, mobility networks ostensibly allow for an evaluation of intervention effectiveness on a flexible scale with little direct resource investment. In the setting of an extended pandemic, with risk and burden entropically distributed across individual, community, and region (by time), such an approach, flattening the diversity of place to population-level risk and risk-relevant spatial inference, had significant appeal.
This approach echoes calls for a more place-based public health surveillance, one which moves beyond the use of case cluster detection (the detection of statistical anomaly) which uses “spatial aberrations in health to define places irrespective of contextual meaning” (Yiannakoulias, 2011). Essentially, a health surveillance which focuses on the attributes of a place (i.e., a physical space embedded with contextual meanings) rather than on the attributes of individuals in a certain space (even if ultimately the health attributes of a place are derived from individual health attributes). A more granular, expansive big mobility data apparatus—particularly those data linked with POIs would then seem to fulfill a more representative, more community centered approach. Place is a central identifier of community and thus big mobility data are describing a place and its members (MacQueen et al., 2001). For instance, SafeGraph (and Google through a less clear process) builds a contextual geography through the use of business POIs (really polygons of interest) and assignment of a North American Industry Classification System (NAICS) code—a classification of business establishments by type of economic activity (SafeGraph). One may then infer how long one spent at a park (good health activity), at a bar (bad health activity), or at grocery store or convenience store (ambiguous health activity). In the case of COVID-19, certain POIs (e.g., restaurant, bar) or types of POIs (e.g., indoor/outdoor, urban/rural) may be identified as associated with a particularly high infection risk—a method used by Chang et al. which will be discussed later (Chang et al., 2020). However, who does this context serve? Does it really describe a place and community the way the community would like to be described? Above all, this particular place-based public health surveillance requires new forms of data collection which describe place in the data terms of the surveillance capitalists. For the goal of syndromic surveillance (for instance, linking hospital use to an infectious disease outbreak) “frequency of door openings, volume of foot traffic and even quantity of garbage produced” would be collected (Yiannakoulias, 2011). “Environmental sound recognition technology” would be used to count “the frequency of noise producing disease symptoms—such as coughs, sneezes and sniffles” (Yiannakoulias, 2011). At transportation hubs, “the purchase of paper handkerchiefs, throat lozenges or lip-balm from kiosks in major public transit stations” tracked (Yiannakoulias, 2011). Who would be collecting this data? Under what terms? Such collection would require near total commitment to surveillance capitalist companies and a dataveillance defined by commercial standards, not under any reciprocal commitments to the people with a stake in their community.
One could imagine an alternative place-based public health that redresses inequities and limited participation in the creation of public health knowledge. Mitchell and Elwood write of the “emancipatory power of spatial thinking” in the context of a collaborative mapping project which centers community participants through a participatory action research approach (Mitchell and Elwood, 2012). As the authors describe, participants create an alternative future writing that, “mapping ‘our’ culture and ‘our’ history renders these events and processes more immediate, visceral, personal, and potentially alterable in terms of their seeming trajectory” (Mitchell and Elwood, 2012). Applied to public health and, more specifically, COVID-19, such a theoretical approach could address the implied “naturalness” of disease in certain communities, reduce spatial stigma and better link public health surveillance to public health action. When analyzed in collaboration (or at the very least consultation) with communities, “food deserts” are not a category of natural geography but rather an intersection of inequities and historical marginalization, COVID-19 “hotspots” are not anomalies but the result of complex spatio-socio-medical community needs, and fixing reduced access to health resources in spatially stigmatized places becomes political imperative rather than logistic inconvenience (Keene and Padilla, 2014; Reese et al., 2019).
It is unclear if big mobility data can be used for participatory research. Participatory research strategies center empowerment. Reflecting on a national survey on the collection and use of personal information, with subsequent structured interviews, Andrejevic notes, “Despite the persistent focus on privacy issues in both academic research and popular press coverage, privacy arguably takes a backseat to an underlying sense of powerlessness” (Andrejevic, 2014). Revealing information about yourself is undesirable but often allowable, however, being “kind of being forced or bribed to share your information,” as one participant aptly notes, is wholly unacceptable (Andrejevic, 2014). There is a lack of reciprocity resulting in big data divides between the aggregators of the data (the tech companies), the academic researchers (who may have access and capability but do not own the data) and the people and communities who originally produced this data (who have neither access, capability nor ownership). Big data allows for meaning to be made from a distance with little context necessary. One dataset can be linked to another dataset without ever having to involve a community or even engage with a human subject. Echoing Taylor's reminder of the dangers of “Land Rover” research, where an international development researcher takes an air-conditioned tour of a community and returns to an air-conditioned office to write a report, big mobility data research runs the risk of becoming API tourism research (Dalton et al., 2016). Where research about the real, lived health experiences of people and communities is only ever encountered through an ever more complex series of interfaces, interconnected datasets, and code divorced from embodied context. It brings surveillance capitalism as an “innovative institutional logic thrives on unexpected and illegible mechanisms of extraction and control that exile persons from their own behavior” to the world of public health research (Zuboff, 2015). In the COVID-19 response, participatory and community-based research strategies were not centered. Again, with emphasis, this approach was unprecedented but not inevitable.
Call and response: a data release narrative
The calls for big mobility data and its release occurred nearly in parallel. In March of 2020, established spatial researchers called for aggregated mobility data as a tool to “fight” COVID-19 by helping to “refine interventions by providing near real-time information about changes in patterns of human movement” (Buckee et al., 2020). The “real-time” nature of mobility datasets and their promise of a continuous data stream across the COVID-19 pandemic life-cycle foreshadowed its widespread adoption by academics and public health actors (Oliver et al., 2020). It promised the ability to refine, determine the impact and otherwise tune public health interventions—principally, social or physical distancing measures—within an analytically flexible time period and with an eye to when “the need to resume life again without risking a major resurgence” arose (Buckee et al., 2020).
The near universal scope and pragmatic use case of the data appealed to public decision-makers. The European Data Protection Board (EDPB) released an informal statement (and later a formal one) recommending the release of anonymized mobile location data while also referencing a provision where member states could “introduce legislative measures pursuing national security and public security” to use personal data (EDPB, 2020). Soon after the EDPB's statement, Europe's major telecommunications companies met with the European Commission of the EU to discuss handing over anonymized and aggregated mobility data from customer mobile phones (Scott et al., 2020). While, of course, not subject to the EDPB oversight, Israel would pass emergency spy powers to obtain individual-level, non-anonymized mobile location data from telecommunications companies shortly after (Altshuler and Hershkowitz, 2020; Tidy, 2020). The People's Republic of China similarly incorporated individual-level location data in their expansive COVID-19 surveillance program through relationships and data agreements with the leading three tech companies: Alibaba (through their Ant group), Baidu and Tencent (Buckley et al., 2022; Mozur et al., 2020; Qiang et al., 2020; Zhu and Smith, 2015). The details of the PRC's massive program are beyond the scope of this article but, notably, both Baidu and Tencent mobility data was used in significant COVID-19 model publications (Chinazzi et al., 2020; Kraemer et al., 2020; Li et al., 2020; Zhang et al., 2021). The specific nature of implementation varied widely by nation but there was a common assumption that 1) big mobility data will be useful and 2) the current emergency more than justified its use (Human Rights Watch, 2020). Collaboration between public health officials (the decision-makers) and private companies (the data aggregators) was deemed essential to describe the prognosis of pandemic and when restrictions were released. By hook or crook, partnerships were established, deepened, and renewed in pursuit of big mobile insights.
The release of data came in a torrent. First to surface, on March 23rd, 2020, Unacast—a self-described “location data platform” based in New York, New York and Oslo, Norway—released a “Social Distancing Scoreboard” of United States state-level changes in mobility with an associated “Data for Good” portal for academic researchers (Unacast, Unacast, 2020b). Their data sources are not publicly available. On April 3rd, Google would release “Google Community Reports”—reports on percent changes in mobility at state-level and place category-level (e.g., park, retail and recreation, groceries, etc.) relative to an antecedent baseline day (the median value from the 5-week period Jan 3 – Feb 6, 2020) (Fitzpatrick and Karen DeSalvo, 2020). Data was limited to users with “location history enabled” in profile settings and anonymized using a process publicly described in a pre-print server paper (Aktay et al., 2020). On April 6th, Meta would follow with the release of a mobility dataset with trends in movement and “staying put” relative to February 2020 values (Jin and McGorman, 2020). This data set was similarly limited to users with “location history enabled” and anonymized using non-specified differential privacy techniques (The Gov Lab et al., 2021). Notably, Meta further refined its COVID-19 data products in partnership with the academic group, the “COVID-19 Mobility Data Network,” and also expanded into surveys, preventative health and “social connectedness” datasets. Apple rounded out the massive tech companies with a release of “mobility trends” based on Apple Maps trips and direction requests (Apple, 2020).
The smaller companies responded with an emphasis on technical expertise. On April 13th, Camber Systems, also in conjunction with the “COVID-19 Mobility Data Network,” released a data dashboard product with nuanced estimates such as “Uncorrelated Shannon entropy” and “Radius of Gyration” (Camber, 2020). Notably, they argue for the inherent inclusivity of location data. The sources and sampling of their data are not disclosed. On April 14th, SafeGraph, one of the major drivers of private-academic partnerships of the pandemic, released four dashboards (“Social Distancing”, “Shelter in Place”, Weekly Foot Traffic Patterns” and “Consumer Foot Traffic”) accompanied by a “Data Consortium” portal (with responsive support) for academics (Blumberg, 2020; SafeGraph, 2021). The SafeGraph datasets were more sensitive than the previous releases, capturing mobility patterns to the census block group and providing information on spatial-temporal variables such as “dwell time” or “trip of X length” in addition to assigning activity to POIs coded to North American Industry Classification System (NAICS) standards. Other companies, such as Cuebiq and Descartes Labs would release data mainly through smaller curated academic partnerships (Livaccari, 2020; Warren and Skillman, 2020). Finally, on May 19th, 2020, the first explicitly public dataset was released by the US Bureau of Transportation Statistics in partnership with the Maryland Transportation Institute and Center for Advanced Transportation Technology (CATT) at the University of Maryland. Unique to this project, the group promised “transparent evaluation” and “open-source algorithms”, although with the significant caveat that these would be provided at a later date (Liu et al., 2020; U.S. Department of Transportation, 2017).
The data was released as the severity and human toll of the pandemic was actualized. Public health stakeholders and data companies joined under the promise and claims of these big surveillance data. Their connection to COVID-19 public health action was not yet clear.
Ethical chaos: public health surveillance and big mobility data
Research and public health surveillance are mutually constitutive practices. There is no formal demarcation between research, surveillance and practice, creating a rich interface where owners of private data engage with public health researchers who engage with diverse stakeholders in public health “activity” (WHO, 2017). This complexity challenges public health ethical considerations which are primarily derived from competing positions (in the Western tradition) including utilitarianism, liberalism, communitarianism, solidarity-based approaches, and more praxis focused principles (Dawson and Jennings, 2012; Roberts and Reich, 2002; Upshur, 2002). Furthermore, the volume, variety, velocity of big data further challenges these conceptions and requires additional layering of ethical considerations specific to this data type (Stewart, 2021). The result is that current guidelines do not, cannot, adequately address the rapidly changing research/practice dynamics of big mobility data, particularly for something as entropic as a pandemic. Amid such entanglements, guidelines rely heavily on self-regulation by companies and researchers.
The crux of regulatory uncertainty may stem from a historical reliance on human subjects research as the ethical basis from which research is conducted. Metcalf and Crawford elegantly describe the conundrum of big data: It moves ethical inquiry away from traditional harms such as physical pain or a shortened lifespan to less tangible concepts such as information privacy impact and data discrimination. It may involve the traditional concept of a human subject as an individual, or it may affect a much wider distributed grouping or classification of people. It fundamentally changes our understanding of research data to be (at least in theory) infinitely connectable, indefinitely repurposable, continuously updatable and easily removed from the context of collection. (Metcalf and Crawford, 2016)
Big data research is secondary research “about humans that is not human-subjects research” (Metcalf and Crawford, 2016). It is not interventional in the traditional sense, uses publicly available datasets not collected for research purposes and, thus, is exempted from ethical board review. Quoting Ioannidis (2013), they call this the “‘oxymoron of research that is not research’, when research is considered simultaneously powerfully insightful about human lives, but inconsequential when accounting for potential harms” (Ioannidis, 2013; Metcalf and Crawford, 2016). How does one create guidelines for data that is made most meaningful in its linkage and thus continuously re-transfigured?
The public health ethics literature is similarly ambivalent. The “WHO Guidelines on Ethical Issues in Public Health Surveillance”, a publication of the World Health Organization's Global Health Ethics Team, synthesizes core ethical considerations and provide guidelines for public health surveillance (WHO, 2017). The considerations are common good (“a public good … unable to be subdivided into private benefits because they are fundamentally shared”), equity (“morally problematic inequality”, with health as a central concern), respect for persons (sometimes framed as “reciprocity” or “autonomy”) and good governance (noted as a “political demand” and not a principle as such) (WHO, 2017). However, the resulting guidelines do not make reference to the use of private big data or clearly detail ethical considerations for its use. In general, a reading of the WHO guidelines would seem open to the use of big mobility data for the purposes of COVID-19 mitigation during a public health emergency. Specifically, they urge the timely sharing of data, in Guideline 15, stating, “During a public health emergency, it is imperative that all parties involved in surveillance share data in a timely fashion” (WHO, 2017). And no other guidelines, including Guideline 9 which concerns the protection of vulnerable groups, read specific enough to capture the situation. Commenting on the “shifting boundaries of surveillance,” the question of big data for public health is left open stating, “it is unclear whether the private sector has an obligation to share those data [big data] with public health or government officials” and calls for additional work on “privacy and anonymity, the integration of public and private data sets and issues of data validity and reliability” (WHO, 2017).
Current guidance exhorts data stakeholders to conform to best practice and earn the right to self-regulation. Fundamentally, this means treating big data research as human subjects data even if it is not regulated as such. For instance, in “Ten Simple Rules for Big Data Research,” they must “Acknowledge that data are people and can do harm” (Zook et al., 2017). The aggregator, researcher or public health stakeholder must acknowledge the person in the data, their entanglements and work to mitigate harm. Other approaches then address the researcher as steward, providing a parallel with the public health's preoccupation with good governance. “Practice ethical data sharing,” exhorts a researcher to acknowledge the reality that much big data (including mobility data) is “collected under mandatory terms of service rather than responsible research design overseen by university compliance officers” (Zook et al., 2017). The data is “accessible only after creation making it impossible to gain informed consent a priori … and contacting the human participants retroactively for permission is often forbidden by the owner of the data or is impossible to do at scale” (Zook et al., 2017). The researcher cannot assure the ethical collection of data as one would in a more traditional human subjects project. Nevertheless, this rule primarily makes clear that the researcher must rely on the data provider as their ethical surrogate—a potentially fraught situation. Again, reflecting the preoccupation with emergency, “Know when to break these rules,” concedes that in exceptional circumstances (as in a global health emergency like the COVID-19 pandemic) ethical rules must be flexible. Data collected without informed consent may need to be used and standards of privacy loosened. Still, they acknowledge that this practice is a “exceedingly slippery slope” and stakeholders must “be cautious that the ‘emergency’ is not simply a convenient justification” (Zook et al., 2017).
There is the question of whether the very emphasis on ethical considerations further removes affected communities from the conversation. When faced with the incompatibility of existing frameworks with respect to big data, Metcalf and Crawford (2016) propose a reading of research ethics “that emphasizes ethics regulations as a form of community assent which enables self-regulation” (Metcalf and Crawford, 2016). Alternatively, Anat Matar proposes a much bolder argument where the very act of “abstract moral discussion is a weapon in the hands of the powerful … and it is necessary to commit not only to concreteness but, primarily to real involvement that is caught up in praxis” (Matar, 2022). The rhetoric that ethical considerations can be applied universally to big data or public health surveillance without situated engagement by people with real involvement (here, with their behavior represented and their community affected) would ring false. There is no ethics without basic political action. For the purposes of this argument, I propose community-based participatory models of research as a partial solution to both. Rather than clarifying guidelines, mandate review by community advisory boards, empowered to make real change to proposed research plans (Halladay et al., 2017; Newman et al., 2011). Recruit participant-researchers from affected communities to encourage inclusive and collaborative engagement. In all action, center “a collaborative, partnership approach to research that equitably involves community members, organizational representatives, and researchers in all aspects of the research process” (Grayson et al., 2020).
Data (role) models
With their release into the semi-public domain, infectious disease epidemiologists (and other academic researchers) quickly began incorporating mobility data into their models with little formative research or community input. Two illustrative models which link mobility with risk of infection at different geospatial scales are discussed. This section is intentionally technical to illustrate the methods used by each study and the conclusions they generate.
(Inter)national-level
Using Google “Community Mobility Reports” (CMR), Sulyok et al. examined whether an association existed between mobility and case incidence at a national and “continent” scale using cross-correlation analyses (Sulyok and Walker, 2020). Data from February 15, 2020 to June 19, 2020 was analyzed. Three predictive models were then constructed, two using CMR data and one without, and their performance compared to actual case incidence for the period of June 19, 2020 to September 13, 2020. Each model was compared to a standard reference and then each model was compared to the others.
The authors found a notable negative correlation between the location categories of “retail and recreation,” “grocery and pharmacy,” “workplace,” and “transit” and case incidence for countries of the Global North while a weaker or even positive correlation was observed for countries across South America, in Eastern Europe and India. An inverse correlation was observed for the location categories of “parks” and “residential” which the authors hypothesize is the result of an “increase of time spent close to habitation” (Sulyok and Walker, 2020). The analyses were particularly concerned with between-continent comparisons and found various differences for each category between continent.
These results provide a use case for Google CMR data but flatten the tremendous diversity of a place and its people to such an extent that meaning becomes nebulous. The target population is ostensibly an entire country's, or even continent's people, but the sample population represents “all devices with location history opt-in moving between Google-defined place category” (Sulyok and Walker, 2020). Neither the device(s)-person or place-category is well-defined or, perhaps, even able to be defined (at least for the researcher). The assignment of place category is an unclear process within the Google organizational structure with almost certainly large variation between country and continent and there is no public validation between the subset of devices (and their users) with location history opt-in and a more traditional population dataset (e.g., census). Opportunities for misclassification abound. As policy, the results could be interpreted as the need for more sweeping stringent mobility restrictions creating what Cash and Patel call “the subversion of global health,” where decreased mobility (in a vacuum) becomes critical to any COVID-19 response regardless of context (Cash and Patel, 2020). This leaves the many individuals working in the informal economy (estimates of 2 billion worldwide) who must move to live or those reliant on non-COVID-19 health or social services at extreme risk. Similarly, given the scale of the analysis, it is unclear what community engagement would look like or what the requisite research-action would be. It reifies the idea of a “one-size-fits-all” response to COVID-19 across people, places, nations, and continents defined by the scope of Google's reach.
Neighborhood-level
Using SafeGraph data, Chang et al. constructed a dynamic mobility network between census block groups (CBGs) and point of interests (POIs) for 10 large metro areas in order to model COVID-19 transmission dynamics (Chang et al., 2020) . They used a dataset provided by SafeGraph and the period from March 1 to May 2, 2020 was assessed. Providing insight into the type of data SafeGraph collects, the network was built using a panel of network-connected devices which represents “the hourly movements of 98 million people from neighborhoods (or census block groups) to points of interest such as restaurants and religious establishments connecting 56,945 census block groups to 552,758 points of interest with 5.4 billion hourly edges” (Chang et al., 2020). They then overlaid a susceptible-exposed-infected-recovered (SEIR) model (“each CBG having its own set of SEIR compartments”) onto each mobility network and calibrated using published case counts. Transmission dynamics were described and various re-opening scenarios analyzed by CBG demographic composition (white/non-white, income level), industry category, reduced occupancy, and variations in urban mobility reduction.
The model predicts higher infection rates among “disadvantaged racial and socioeconomic groups … solely as the result of differences in mobility”—suggesting that, in the early period of the US epidemic at least, disadvantaged groups were not been able to reduce mobility as sharply as other groups (Chang et al., 2020). The model also suggests that “superspreader” POIs may be accounting for the majority of infections. Full reopening would result in additional risk for individuals who live in low income CBGs. The article then grades industry POIs by level of risk (highest to lowest). Full service restaurants and religious organizations had the largest predicted impact on infections due to reopening and department stores/new car dealerships/convenience stores had the lowest.
As opposed to the other highlighted papers, the scale and specificity at which the authors make their conclusions provides a hypothetical “link to action” in community. However, despite the tremendous amount of attention it received, it is unclear if its potential was realized (Altmetric, 2022). This is where a community input and engagement is most critical. By incorporating the community earlier in the process, an implementation and dissemination plan could have been embedded into the study and enacted on its completion.
Sets of problems and challenges for health action
Two major sets of problems, highlighted by the previously selected examples, loom when considering the use of these private (or public-private) datasets for the purposes of public health. One is a mostly scientific set of concerns centered on the accuracy of the dataset and its validity with respect to making inferences about the target population. The second posits that the gap between the researcher, data provider and data subject de-centers people and their communities from the COVID-19 response, severing the established link of surveillance with action. The researcher is gated by the data provider from critical individual and contextual information about the data subject (and by extension their person), while the data provider (with access) strengthens their position. These sets are mutually entangled.
Access to key information on sample composition is limited as part of the proprietary data science workflow. Many firms, particularly the smaller firms engaged in mobility data as a sole enterprise (e.g., SafeGraph, Unacast) do not disclose what apps or external organizations provide them data (SafeGraph). No other information is provided on those “Partners” found on their privacy pages, if any are listed (Unacast, 2020a). For their part, the larger firms (e.g., Google, Meta) do not provide what subset of users meet the conditions (e.g., “location history opt-in”) to be included in the dataset. SafeGraph does notably provide a detailed analysis on the correlation of their sample with respect to the US Census and includes an additional tutorial on how to test their data with other subpopulations (Squire, 2019b). Still, such limitations present challenges to epidemiologists interested in using the data to make inferences with respect to spread. While ongoing methodological innovations (such as defining “no-bias” conditions when comparing mobility between demographic groups) may improve validity, the inherent proprietary restrictions remain (Garber et al., 2022).
There is a fundamental mismatch between the promise of the data and the reality of its creation and use. Using the previous vocabulary, this can be conceptualized as a big data divide between companies and public health actors. The claim says that this data is directly helping “fight” COVID-19. Ostensibly, it is then preventing infection, disability and death in people. Researchers stated it and companies certainly did—with ringing press releases to “spearhead” data collaboratives, to “track and combat” COVID-19 or, with a shrug, “we’ve heard from public health officials that the same type of aggregated, anonymized insights we use in products … could be helpful as they make critical decisions to combat COVID-19” (Buckee et al., 2020; Google; Jin and McGorman, 2020; Livaccari, 2020). However, data was critically gated from public health officials by design. Poom et al. describe this problem of dataset deployment as “exploratory rather than operational” (Poom et al., 2020). The data is aggregated and anonymized in-house (often opaquely, often with unpublished methods) by the parent company. Demographic data (if any) is imputed from US census data. Individual-level data, the kind most helpful to a targeted public health response, is fully unavailable. While it is understandable to limit its release given privacy concerns, in the time of a deadly pandemic, why is it amenable to use individual-data for business purposes but not public health purposes? This is not an argument for the public release of individual data but the question must be asked as to why commercial rights are privileged. Poom continues, “in a very real sense, application of mobile Big Data … was limited to insiders rather than officials or citizens seeking to identify hot spots or conduct contact tracing” (Poom et al., 2020). Researchers and public health officials would take what they could get on data acts of charity—and make do as well as they could. Firms reaffirm their right to not release data and choose under what specific circumstances it can be used.
While access to critical information is gated for researchers, public health participation in surveillance capitalism spaces accelerates the “routine” use of surveillance capitalist datasets, strengthening the position of the surveillance capitalists and deepening their ties to the claims of public health. Zuboff writes of “formal indifference”, users can do anything and say anything as long as it is done in a form amenable to data collection, and “extraction,” exchange devoid of reciprocity, as two main characteristics of surveillance capitalism (Zuboff, 2015). The act of good public health surveillance is anything but indifferent! It is “the monitoring of events in humans, linked to action”—a design that monitors so as to act (WHO, 2017). The cycle of public health surveillance must be reciprocal and interdependent with people and community. Ideally, through participatory models which directly empower a community to define their own best health (Gilmore et al., 2020; Wallerstein and Duran, 2010). The adaptation of big data towards purposes aimed at improving the people's health does not supplant the need for such “full cycle” reciprocity and engagement. But a fully “app-based” approach to public health surveillance, which can be expanded to a big data approach, risks linking public health to surveillance capitalism intrinsically. Users now expect that a public health application will collect and sell information to third parties but justify such actions to the “greater good” (Seberger and Patil, 2021). Through asymmetrical collaboration, the agendas of public health and surveillance capitalism are linked.
The largest big data divide, however, remains between the person and community present in the data. There is an intractable disconnect between the “ground truth” of people's embodied risk and their representation in processed data sets. Taylor, commenting on the use of mobility data by Western researchers in sub-Saharan Africa, writes of the “tension between data scientific skills and contextual understanding” and its corollary the “cultural and experiential gap between researcher and data subject” (Taylor, 2015). While this applies to data scientists (and data providers) more broadly, it is important to acknowledge the profound scalar leaps occurring between experiential data abstraction and researcher inference. In “A Cyborg Manifesto …”, writing on an “informatics of domination”, Haraway describes a world “subdivided by boundaries differentially permeable to information” (Haraway, 1991). I think this is a useful construct here. The individual, interpersonal, and community risk behaviors operate on situated registers in distinct but inherently interconnected assemblages. For instance, household transmission (“home”) has a significant role in the COVID-19 pandemic—the experiential scale of which is remarkably small, limited to family or close relations (Madewell et al., 2020). The act of collecting longitudinal location data from a panel of devices through a diverse set of unidentified third party sources linked by machine learning and then embedded in an infectious disease model with its own set of assumptions to capture many households experience crosses over many, many “boundaries”. Methodologically, the uncertain geographic context problem describes the challenge of addressing causation given the massive temporal and spatial uncertainty present (Kwan, 2012). Information, potentially critical information on persons and their connections, is lost along the way. The policies informed by those models (if solely informed) may be reductive, deny crucial experience or harm communities. Haraway posits that in an “informatics of domination,” “Human beings, like any other component or subsystem must be localized in a system architecture whose basic modes of operation are probabilistic, statistical.” (Haraway, 1991). If researchers must dabble in the construction of such an architecture through device samples, anonymization, and use of synthetic population in order to create public health knowledge, they must be explicit about the information that is differentially lost in the process. Data providers must assist in unmasking those differential barriers and closing the gap (to the degree possible) between data science and contextual understanding. It remains to be seen if this is possible. To begin, let us center the people and communities in the data.
Conclusion
The release of private mobility data into the public sphere between April and May of 2020 was the equivalent of a “data gold rush.” There was a tremendous drive, for emergency, to use this data in order to better understand the pandemic, its impact on people's movement, evaluate non-pharmaceutical interventions and exploit a unique data stream. As the most direct impacts of the COVID-19 pandemic, infection, death and disability, decrease, it is important to turn attention to the type of public health knowledge that flourished in its chaos. Namely, a way of understanding which privileges an abstract representation of people and community versus engaging them towards situated knowledge. One that acts through an impact pathway of exclusion. Taylor states that “the risks of data misuse in the context of mobile traces mainly stem from power and knowledge asymmetries between researchers and data subjects and between corporations and states” (Taylor, 2015). The entanglements of big mobility data for public health research, if nothing else, makes these asymmetries clear. We must redress these differentials and empower and engage the people locally before distance becomes norm.
The risk is not merely theoretical. In their 2020 publication “Pandemic fatigue: Reinvigorating the public to prevent COVID-19,” the World Health Organization (WHO) recommended four key strategies in policies, interventions and communication (“understand people,” “engage people as part of the solution,” “allow people to live their lives,” and “acknowledge and address the hardship people experience”) and five cross-cutting principles (“transparency,” “fairness,” “consistency,” “coordination,” and “predictability”) to address extended COVID-19 transmission (Europe, 2020). In strategy, engagement with people is indisputably the focus. In principle, clarity of approach is central. In the surveillance of people to action with people pathway, these strategies form the final connector. There is a misalignment between this people-centered, situated approach to action and the interventional claims, but distant reality, of big mobility data use. The obfuscation necessary to maintain proprietary information limits transparency which limits accuracy which leads to interpretation error and bias. The fundamental process of translating mobility data to inference removes experiential information at scale and privileges certain representation over others (the details of which are also obfuscated). The use of mobility data for public health links surveillance capitalist data to public health itself, presenting, perhaps insurmountable, conflicts with some of the core community-centered principles of the field. However, guided by an unflinching assertion that data are people, and used in conjunction with participatory research strategies, in settings acceptable to the community, it may provide insight into public health issues in infectious disease. But its asymmetries must never stray from mind.
Footnotes
Acknowledgments
There are so many people I have relied upon. In particular, I would like to thank Mark Lurie and Will Goedel for their assistance in the preparation of the original project and all of my classmates and STS and public health professors for helping refine the arguments presented. Finally, I would like to extend my thanks to the journal reviewers for their excellent feedback.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.