
Abstract
A crucial challenge for personalized health is the handling of individuals’ data and specifically the protection of their privacy. Secure storage of personal health data is of paramount importance to convince citizens to collect personal health data. In this survey experiment, we test individuals’ willingness to produce and store personal health data, based on different storage options and whether this data is presented as common good or private good. In this paper, we focus on the nonmedical context with two means to self-produce data: connected devices that record physical activity and genetic tests that appraise risks of diseases. We use data from a survey experiment fielded in Switzerland in March 2020 and perform regression analyses on a representative sample of Swiss citizens in the French- and German-speaking cantons. Our analysis shows that respondents are more likely to use both apps and tests when their data is framed as a private good to be stored by individuals themselves. Our results demonstrate that concerns regarding the privacy of personal heath data storage trumps any other variable when it comes to the willingness to use personalized health technologies. Individuals prefer a data storage format where they retain control over the data. Ultimately, this study presents results susceptible to inform decision-makers in designing privacy in personalized health initiatives.
Introduction
Personalized health is based on the massive integration of biomedical and social data into research, to determine how individuals’ physical and social environments, genetic endowments and behaviors influence their health (Barazzetti et al., 2021). This data helps to customize preventive and therapeutic interventions to the individual genetic and clinical characteristics of each patient (Minvielle et al., 2014).
Personal health data can cover a wide range of forms of data, from diagnoses recorded by physician in a patient's record to simple metrics about the individual, for instance their weight. A large amount of personal health data is produced in the medical context and often involves that medical institutions have access to this data, which raises privacy concerns (Baumann et al., 2018; De Pietro and Francetic, 2018; Platt and Kardia, 2015). However, a host of health data may be created and stored outside of the medical context: individuals can self-produce data via apps that record, for instance physical activity (Seifert et al., 2018; Seifert and Van-delanotte, 2021) or elect to undergo blood or genetic tests to appraise their risks to develop a cancer (Nakagomi et al., 2016) or other diseases (Ries et al., 2010). In this study, we look beyond precision medicine focused on sick patients and zoom-in on the prevention-oriented dimension of personalized health (Khoury et al., 2016).
We ask: what are individuals’ preferences regarding how they want to store the personal health data they opt to produce? We analyze two voluntary methods of data generation which cover the non-medical dimensions of personalized health: self-performed genetic tests to send to a laboratory (Phillips et al., 2018) that can be used to create personalized plans for health prevention and connected technologies that monitor physical activity (Allen and Christie, 2016) such as health trackers and apps. A central issue regarding any new technology is acceptability (McCartney et al., 2011; Leonard et al., 2017). To successfully apply new technologies and get citizens to use them, we need to know under which conditions such usage becomes more likely. In the context of personalized health, the usage of such technologies is also important for the common good, because the availability of individuals’ health data might not only improve their personal health, but can in addition provide the basis for research aiming at providing new diagnostic and treatments.
A crucial challenge for the future of personalized health is thus the handling of individuals’ data and specifically the protection of their privacy (Ostherr et al., 2017; Vayena et al., 2018; Blasimme et al., 2019). For instance, privacy protection is important because personalized health bears the risk of discrimination among individuals based on genetic profiles (Feldman, 2012; Lee, 2015; Phillips et al., 2014), as well as because powerful economic interests are likely to take advantage of citizens’ cognitive biases and weak data protection legislation to access to personal health data (Boyd and Hargittai, 2010; Brown, 2016).
Previous research (Whiddett et al., 2006; Laurie, 2011; Caenazzo et al., 2015; Patil et al., 2016; Persaud and Bonham, 2018; Buhler et al., 2019; Trein and Wagner, 2021) has shown that individuals are not willing to have their personal information shared beyond the purpose of clinical care and prefer to be consulted before their information is released. Yet, recent studies demonstrate broad public support for the use of health data for the purpose of research (Garrison et al., 2016; Stockdale et al., 2018; Braunack-Mayer et al., 2021). Furthermore, information about who benefits from data and the option to withdraw access to data increases the likelihood of data sharing (Milne et al., 2021).
In this study, we use a survey experiment to analyze Swiss residents’ willingness to produce and store personal health data as the dependent variable. We probe the expectation that privacy concerns are crucial to explain why individuals report that they are willing to take a genetic test or use connected technologies. We randomly expose individuals to different storage conditions which differ in the degree according to which respondents retain control over their health data. In other words, we framed the question so to indicate that genetic data is stored as public good for one group and private good for the other. Our main research expectations are that private storage increases individuals’ willingness, so does framing genetic data as private good, which our study confirms.
Method: Cross-sectional, survey experiment
The data set for our analysis was generated from an online survey that was fielded in March 2020 in Switzerland as part of a larger project on health policy and genetic data. Switzerland provides a relevant context as the country has a health care system, which puts the responsibility for health care on individuals, for example regarding co-payments for treatments (DePietro et al., 2015; De Pietro and Francetic, 2018). In other words, Switzerland is a “consumerdriven” healthcare system (Okma and Crivelli, 2013) and as such, citizens’ willingness to use personalized health technologies is highly relevant.
The data in this paper consists of a sample (N = 1000) of the Swiss population, which is representative according to the following categories: men and women are distributed equally and the participants, aged between 25 and 65 years, are evenly distributed into four age groups. Two thirds (67%) of the sample is comprised of Swiss Germans and the remaining 33% are from Switzerland's French-speaking region. The data does not take into account the Italian- and the Romansh-speaking regions, representing 8% and less than 1% of the population respectively (Deruelle et al., 2022).
The main goal of the survey was to find out about how individuals are willing to share their health data. Therefore, we used a simple survey experiment. In the survey, after briefly explaining what is meant by health apps and genetic tests, we asked respondents how likely would it be for them to use health related apps (question A1) or to take a genetic test (question A2). After that we randomly framed individuals into two equal-sized groups while controlling for the gender, age and language region distributions. One group (common good framing – CG) received the following framing: “Some consider that personal health data is a common good and should be used to improve public health.” Then we asked them how likely would it be for them to use apps (question B1 . 1) or take genetic tests (question B1 . 2) if their data were stored by public authorities, such as a biobank. The other group (private good framing – PG) was provided with a different framing: “Some consider that personal data are private and should be used exclusively to improve the health of the individuals to whom they belong.” Again, this group was asked how likely it is they would use an app (question B2 . 1) or test (question B2 . 2) if they were to store their health data privately, for example in a “datasafe” or on a secure server.
We illustrate the survey setup in Figure 1.

Operationalization of data sharing in the survey.
Our analysis proceeds in two steps. For the first step, we analyze the role of storage conditions and framing data as common good or private good and whether citizens are more likely to use health apps and conduct a genetic test if they could store the data themselves or if it is stored by public authority. The experimental aspect of this research allows us to present respondents with storage options that are coherent with a normative view that articulates the nature of the data and what forms of data sharing are acceptable solutions. As such framing is coherent with storage options: there is no cross-comparison of framing vs. storage option possible. Ultimately the survey experiment is concerned with comparing response before and after framing. This part of the analysis uses descriptive statistics of the different variables (see Figure 2).

Levels of willingness to use apps and make tests along the framing.
For the second step, we conduct multivariate regression analysis to examine whether the results of the framing remains statistically significant when controlling for alternative explanations: variables based on the social background of respondents as well as their political background and their health history. This empirical strategy allows to test for the robustness of our findings. Our socioeconomic variables include the gender, age, citizenship, education level, professional status, subjective wealth, marital status, language region, and subjective health. The goal is to investigate whether there are disparities between those who anticipate potential health problems in the near future and those who do not (age variable), those who can afford to invest in alternative storage solutions that match their preferences and those who do not (wealth variable), those who have a better understanding of privacy and storage issues than others (education) and finally whether there are cultural disparities between the German- and French-speaking respondents in Switzerland.
To operationalize political background variables, we ask participants whether it is the role of the state to provide social security, to reduce economic inequalities, to store and use data as well as to regulate the storage and sharing of data. Respondents’ views on the role of the state in health and welfare indicate whether individuals are supportive of state intervention in these areas. The first two background variables are respondents’ views on whether it is the role of the state to provide social security or to reduce economic inequalities. These two variables are useful to paint big strokes on the role of the state: if individuals are largely in favour of state involvement in these aspects but adverse to have their data stored by the state, this would indicate that this is more likely due to privacy concerns rather than political views on the role of the state. If individuals are adverse to both, it would mitigate our findings and indicate that political views are significant. We also analyzed two other background variables: the respondents’ views on whether it is the role of the state to store and use data and their views on whether it is the role of the state to regulate storage and sharing data. In contrast to the first two variables, if respondents say that it is indeed the role of the state and are willing to have their data stored by the state, this would indicate that political views and personal choice are coherent in explaining individuals’ willingness to use personalized health technology.
Finally, focusing on health specifically we look into individuals’ relationships with their own health. We survey their self-assessed health conditions and whether respondents have family antecedents of cancer. The role of those variables is to identify whether health-conscientious individuals are more likely to want to monitor their health using apps or genetic tests.
Results
For each question laid out in Figure 1, our statistics report the share (in percent) of those who responded “likely” or “very likely.” Our first results are depicted in Figure 2 and illustrate the impact of the framing. The three panels of the graph show the share of respondents that are willing to use apps and make tests, initially (before framing), and in both the common and private good framings (using a subsample of observations). In the second and third panels, we report the willingness to use apps and tests for the subsample before framing (results are in line with those of the whole sample given in the first panel) before indicating the results using the framing. First, we observe that individuals are much less likely to do genetic tests (49.7%) than to use apps (70.2%). Further, we find that those who received the information that data might be stored with the state (CG framing) are less likely to use apps (45.6%) and even less likely to conduct genetic tests (39.2%) compared to those who received the information that data should be stored with the individual (PG framing). In the latter case, the willingness to use is slightly lower for apps (66.8%) and slightly higher for tests (51.4%) when compared to the situation before framing.
In Table 1, we illustrate the respondents’ willingness to use health-related apps or to participate in genetic testing along the different control variables over the different framing setups. Again, and across the variables, we observe that individuals are much less likely to do genetic tests than to use apps. For example, both men and women are similarly likely to use apps (70.6 respectively 69.8%) but for both genders, the willingness to use tests is lower (51.2 respectively 48.2%).
Levels of willingness to use apps and make tests.
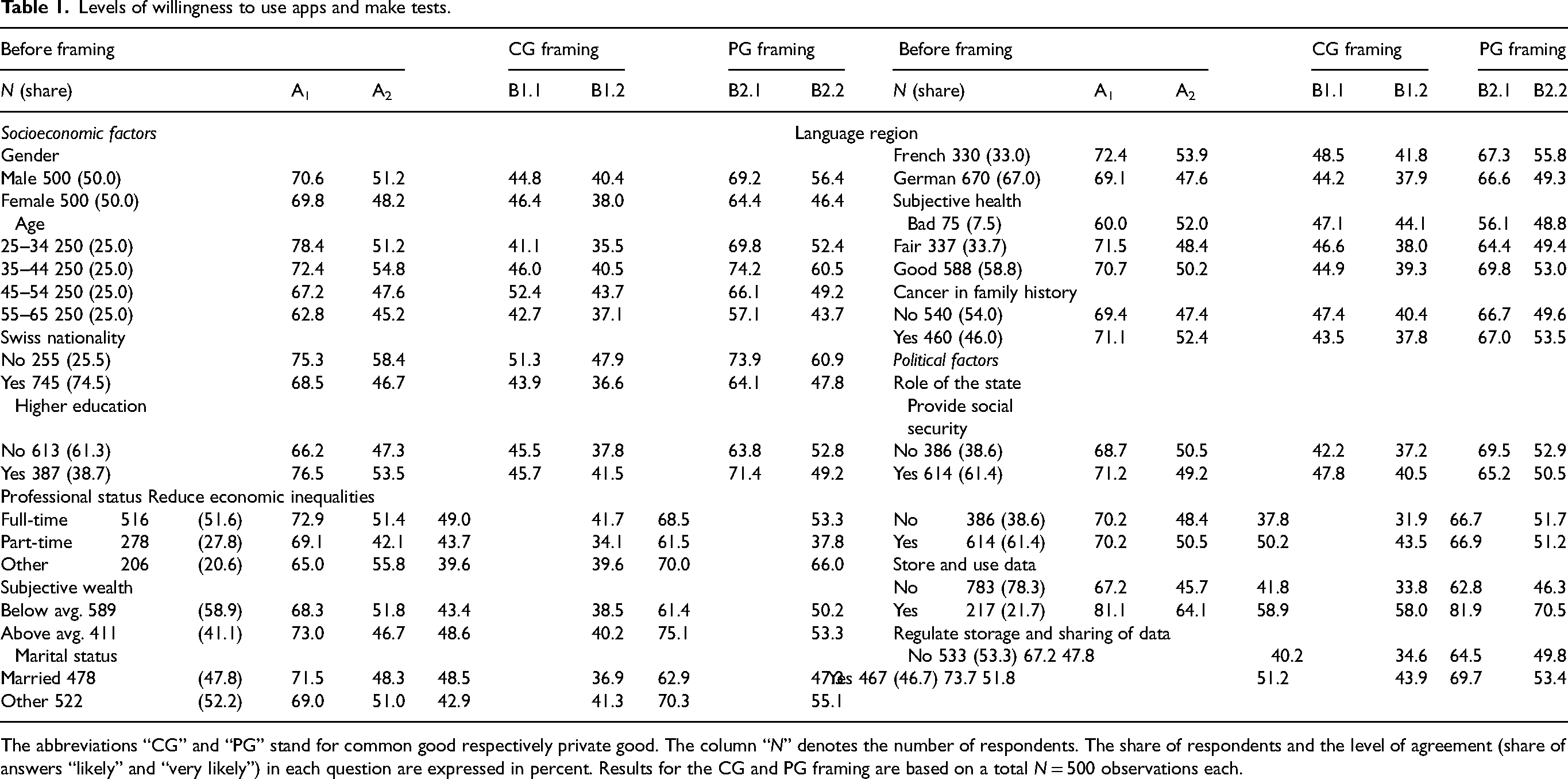
The abbreviations “CG” and “PG” stand for common good respectively private good. The column “N” denotes the number of respondents. The share of respondents and the level of agreement (share of answers “likely” and “very likely”) in each question are expressed in percent. Results for the CG and PG framing are based on a total N = 500 observations each.
Concerning political factors, we transformed the variables that measure the individual's level of usage in the four statements into binary measures (yes/no). In the original survey, the variables measure the statements on a five-point Likert scale, from “do not agree” to “fully agree”, allowing for an “undecided” category. To simplify the presentation of the results and our econometric analysis, we have coded both disagreement categories as well as the “undecided” category as a “no” since we aim to distinguish actual willingness. Indeed, we observe that the political factors seem to make a difference regarding the willingness to use apps and conduct tests. Those who feel that it is the role of the state to store and use data are more likely to use apps and tests regardless of the framing. Finally, let us note that we have also coded the variable regarding subjective health, combining the categories “bad” and “very bad” as well as “good” and “very good” into “bad” and “good” respectively. Further, we have changed the education level variable into a binary variable classifying individuals into those who at least have a high school diploma and those who have not.
To understand deeper how the usage of apps and tests is linked to the different explanatory variables, we estimated different regression models. Specifically, we built four regression models using the binary answer variable (see above) for the likelihood to use an app or to conduct a test. We use logit models because they yield the lowest Akaike Information Criterion (AIC) values compared to models with a probit or a cloglog link function. As robustness tests, we also estimated variables, which does not yield different results. These findings are available upon request from the authors.
We estimate two models regarding the likelihood to use apps and two models concerning the usage of tests. In both cases, we estimate one reference model with the control variables only. Model 1 and 3 use as dependent variables the questions A1 respectively A2 from Figure 1 (Table 2). Models 2 and 4 use the questions questions B1 . 1 / B1 . 2 respectively B2 . 1 / B2 . 2 from Figure 1 as dependent variables (Table 2). In addition, we add to Models 2 and 4 an additional binary variable measuring PG (1) vs. CG framing (0). In addition to the regression coefficients, Table 2 also shows the marginal effects of variable, since the regression coefficients do not allow us to determine the size of the effects.
Regression results for the apps and tests usage.

All models are based on N = 1 000 observations. Significance levels: ∗ p < 0.05; ∗∗ p < 0.01; ∗∗∗ p < 0.001.
The main result of the analysis shows that those who received the private good framing are more likely to use health apps and do genetic tests compared to those who were exposed to the common good framing. In the second set of regression models (bottom line in models 2 and 4 in Table 2), a binary variable indicates if the respondent received the private good framing instead of the baseline common good framing (cf. Figure 1). The results show that such a framing significantly increases the likelihood to use apps and wearable devices by almost 24% and makes it almost 14% more likely that individuals do blood and genetic tests.
The analysis shows also that very few control variables are statistically significant (see Table 2). For example, the items measuring the respondents’ medical history do not seem to co-vary with the willingness to do tests, especially when we control for the private good framing variable.
Among the socio-economic variables yielding significant results, the following points are relevant. Regarding the use of apps, those reporting a subjective wealth above average are more likely to use apps once the framing is applied. However, as shown in Table 1, this is due mostly to the relationship between subjective wealth and app use in the private group framing. Indeed, while before framing 73% of the respondents with a wealth above average would use apps, they are only 48.6% once the public good framing is applied. This however rises up to 75% for the private good group. This shows a meaningful relationship between wealth and connected device usage, but only when individuals are presented with the private good framing – thus confirming the central result of this study. Moreover, those reporting to have a higher level of education are almost 9% more likely to use apps, but statistically significance is lower. Regarding the use of genetic tests, the reference model indicates that respondents with at least a high-school diploma and a family history of cancer are more likely to engage in tests compared to those who have a lower level of education and no cancer history in their family. Furthermore, Swiss citizens and those who only work part-time are less likely to take such tests.
Among political factors, we see that respondents who feel that it is the role of the state to store and use data are more than 16% more likely to report app usage and 15% more likely to conduct genetic tests. These results increase even further if we control for the effect of framing. This finding is not surprising because it implies that those who are anyways more willing to give away their data to public authorities are more likely to conduct tests, independently whether they received a CG or PG framing. One possible interpretation of this result is that these respondents have higher levels of trust in the government (something that we did not measure) and therefore are willing to share their data from health tests with the authorities.
Other political factors play a less important role: notably, those who support statements such as “it is the role of the state to provide social security” and “it is the role of the state to reduce economic inequalities” are not more or less likely to use health apps and provide genetic tests. Although the regression coefficients have an either positive or negative direction, their statistical significance is weak, and they point in different directions for two similar variables. This finding indicates that using health technologies is not very strongly related to political ideologies, such as the left and right political positions (Jensen, 2011).
Overall, our findings underline the importance of data privacy when it comes to implementing practices of personalized health. Maintaining privacy over personal health data storage important when it comes to using health-related apps and tests: more so than beliefs about subjective health and a family history of cancer.
Conclusions
As per research expectations, this study shows that individuals are more likely to use personalized health technologies if their data are kept privately, rather than a common storage. This shows that privacy concerns are still important, which is in line with findings from the literature (Ostherr et al., 2017; Vayena et al., 2018; Jacobs and Popma, 2019). Other explanatory variables have a less clear effect, but this finding is not statistically significant. For instance, respondents with a degree in higher education are more likely to use those technologies. However, this increased likelihood disappears once we apply the framing. Nevertheless, ideological views should not be completely eschewed: indeed, those who believe that it is the role of the state to collect and store data are more likely to use personalized health technologies.
There are important differences between health apps and genetic tests. The likelihood for respondents to self-perform a direct-to-customer test is, regardless of the framing, lower than for health apps. It is also lower throughout all background variables. Previous findings on health data in Switzerland did not differentiate between means to produce health data (Pletscher et al., 2022). Genetic data is particularly sensitive a form of health data and individuals’ willingness to even elect to do a test may be mitigated by their knowledge and their worldview on genetic information and its use (Bearth and Siegrist, 2020; Clayton et al., 2018). Yet, attitudes towards genetic testing may not only be rooted in ethical considerations. Middleton et al. (2020) for instance show that in Switzerland most people are unfamiliar with genetic knowledge and do not differentiate those from other medical information. Willingness may also depend on costs (Ries et al., 2010).
While respondents are more likely to produce and store data in the private good group, our survey experiment shows that willingness to produce and store data is lower once the framing is applied, regardless of the framing that is applied. This is important for practitioners, as it shows somewhat of a paradox: as soon as respondents are contemplating that the data can be shared, they are less likely to want to produce it, yet, producing this data would improve the public good. Ultimately our results show the necessity to develop literacy on health data, digital platform and privacy. Potentially, this could include improving scientific literacy and educating on the personal and collective benefits of producing this data; however, our results show that respondents from the common good framing group were the least likely to produce and store data. More generally, our findings show also that personal health data is no different than other forms of personal data: mitigating data privacy concerns is of the utmost importance for a correct implementation of personalized health objectives. Therefore, in order to promote the production of personalized health, decision makers should create storage solutions that could emulate, for instance, the Swiss Electronic Health Record (Baumann et al., 2018; De Pietro and Francetic, 2018; Platt and Kardia, 2015) that allow citizens to give consent for the use of their data for the purpose of research.
Like any other research, our study comes with limitations. We lay out three limitations. The first one being the generalization of our findings. Switzerland is arguably at the forefront of the personalized health “turn,” and thus the debate regarding data privacy is particularly relevant, unlike in other national contexts in Europe or worldwide.
Second, the scope of our empirical analysis is limited as we could not include the Italian-speaking population of Switzerland. Finally, our study is limited to personalized health technologies (smartphone apps, wearable devices, do-it-yourself tests) where data generation is depending on the patients’ willingness to use them. Our results are therefore not relevant to personal health data generated as a result of a medical intervention.
This last limitation may inform the direction for future research. Further analysis of individuals’ preferences can be done by comparing the medical and the non-medical dimension of PH data generation. In the same vein, more storage and privacy options can be explored Considering that respondents’ willingness to use health technologies is significantly higher when the state is not involved. Future research could explore which private third-party citizens trust to handle their data, whereas private insurance, digital technology firms or cooperative biobanks. On the specificity of genetic testing, future research should explore whether ethical and cost-related considerations matter in the Swiss case or whether privacy concerns trump it all as one could expect from our findings. Finally, our results can inform how to design privacy for PH data outside of the medical context. And thus, it would be relevant for future research to further analyze how privacy and storage may affect whether individuals accept to share their data.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung, (grant number CRSII5 180350).