
Abstract
We collect and analyze a corpus of more than 300,000 political emails sent during the 2020 US election cycle. These emails were sent by over 3000 political campaigns and organizations including federal and state level candidates as well as Political Action Committees. We find that in this corpus, manipulative tactics—techniques using some level of deception or clickbait—are the norm, not the exception. We measure six specific tactics senders use to nudge recipients to open emails. Three of these tactics—“dark patterns”—actively deceive recipients through the email user interface, for example, by formatting “from:” fields so that they create the false impression the message is a continuation of an ongoing conversation. The median active sender uses such tactics 5% of the time. The other three tactics, like sensationalistic clickbait—used by the median active sender 37% of the time—are not directly deceptive, but instead, exploit recipients’ curiosity gap and impose pressure to open emails. This can further expose recipients to deception in the email body, such as misleading claims of matching donations. Furthermore, by collecting emails from different locations in the US, we show that senders refine these tactics through A/B testing. Finally, we document disclosures of email addresses between senders in violation of privacy policies and recipients’ expectations. Cumulatively, these tactics undermine voters’ autonomy and welfare, exacting a particularly acute cost for those with low digital literacy. We offer the complete corpus of emails at https://electionemails2020.org for journalists and academics, which we hope will support future work.
Keywords
Introduction
Political campaigns use a variety of digital media for mobilizing potential voters and raising funds (Denton et al., 2019; Marland and Mathews, 2017). Email is a particularly important medium: it is a major driver of grassroots fundraising and requires little campaign infrastructure to operate (Magleby et al., 2018). Emails can also be tailored rapidly in response to news (Magleby et al., 2018) and campaign staffers rate them as more representative of campaign strategy than either television advertisements or media coverage (Hassell and Oeltjenbruns, 2016). Yet, due to their semi-private nature (Kang et al., 2018; Marland and Mathews, 2017), campaign emails are difficult to observe at scale and have consequently only either been analyzed in limited scope (e.g., the presidential candidates) or in limited size (e.g., a few thousand emails at most) (Williams and Trammell, 2005; Hassell and Oeltjenbruns, 2016; Hassell, 2011; Kang et al., 2018; Albert, 2020; Karpf, 2010).
While not heavily studied in the academic literature, political emails have received scrutiny from journalists motivated by bringing transparency and accountability to the conduct of elected officials and political campaigns. Particularly in the 2020 election cycle in the US, there has been a spate of anecdotal reports of manipulative tactics such as misleading subject lines and deceptive fundraising techniques—including nonexistent deadlines and false claims of donation matching—tricking recipients, especially older adults (Goldmacher, 2021a), into recurring donations (Levinthal, 2018; Choma, 2019; Ruperon, 2017; Mak, 2019; Bykowicz, 2019; Goldmacher, 2021b). These tactics are reminiscent of manipulative interfaces or “dark patterns” in the commercial sphere (Brignull, 2018; Gray et al., 2018). Dark pattern user interfaces subvert user decision-making and deny users autonomy over their decisions, often by exploiting cognitive vulnerabilities. 1 A growing body of academic research from the human–computer interaction (HCI), privacy, and psychology communities has shown that dark patterns are rife on e-commerce websites (Mathur et al., 2019), mobile applications (Di Geronimo et al., 2020; Gunawan et al., 2021), and privacy notice-and-choice user interfaces on websites (Nouwens et al., 2020; Utz et al., 2019). This awareness has led to calls for reform and regulation of such interfaces in digital markets (Warner and Fischer, 2019; Narayanan et al., 2020; Mathur et al., 2021).
Expanding upon prior qualitative journalism, we undertake the process of collecting an expansive dataset of political emails from the 2020 US election. Studying political emails at scale and from entities across the US political sphere required overcoming several challenges that social and political scientists, and journalists have faced. Using semi-automated machine learning techniques, we characterize and measure various manipulative tactics at scale. We use the conceptual framework developed for studying commercial dark patterns to study political communication. Like a consumer who is curious about a company’s products but uncertain about committing to a purchase, political campaigns must address people who are motivated enough to subscribe to the campaign’s email list but may not be committed enough to donate money. This might push campaigns toward tactics that manipulate people to unwittingly open emails, stay engaged, and donate.
We begin by describing how we collected a corpus of over 300,000 political emails from the 2020 US election cycle and showing that they are primarily about political events, issues, and fundraising. Next, we identify six manipulative tactics in email subject lines. These tactics range from those that openly deceive recipients (e.g., through dark pattern user interfaces in the subject line or survey requests in the email body) to those that, while not openly deceptive, create a curiosity gap or impose pressure on recipients to click and interact with the email (e.g., through urgency, sensationalism, and forward referencing clickbait in the subject line). 2 Our analysis shows that 37% of the median sender’s emails use a clickbait subject line, 5% use a dark pattern user interface tactic, and 42% use at least one tactic of either type. We then document instances of A/B testing, finding that senders often test and vary the manipulative tactics we identify—suggesting that these tactics are intentionally tuned via user testing. Next, we turn to how senders approach recipient fatigue from fundraising solicitations, and how emails pivot away from the subject line to fundraising. Finally, we show that nearly 322 senders disclose recipients’ email addresses with other entities but about three-quarters of these did not inform recipients about this practice.
We close by discussing the implications of our work and the way our data collection can support future research, including broader descriptive and comparative questions about how campaigns and organizations communicate with their constituents, and on the events leading up to the 2020 USelection and in its aftermath. We also hope that our analysis will spur research that revisits digital campaigning in light of how a campaign or organization may abuse the affordances of the communication medium, as commercial enterprises similarly do (Brignull, 2018), to their advantage when competing for voter attention. Our entire corpus of emails is available to browse online at https://electionemails2020.org and we have released all the necessary data collection and analysis code on GitHub at https://github.com/citp/election-emails.
Assembling a corpus of 300K political emails
We introduce a carefully crafted corpus of 300K political campaign emails from over 3000 political campaigns and organizations in the 2020 election cycle in the US. We describe our data collection considerations in this section.
Generating a list of candidates and organizations
Our target population includes all candidates in prominent federal and state races as well as political organizations such as Political Action Committees (PACs) and political parties active in the 2020 US election cycle. A key characteristic of this population is that it is constantly changing. Candidates announce and end their candidacies, and organizations enter the fray at different points in the election cycle.
To ensure broad and up-to-date coverage, we combined three regularly-updated sources of information about political entities: candidates from Ballotpedia, PACs from OpenSecrets, and other political groups from manual search engine results. We purchased a list from Ballotpedia—updated weekly—of candidates running for election in 2020 at the federal and state levels. We gathered a list of active PACs and other groups from OpenSecrets. We discovered and compiled a list of political and Hill committees for political parties at the federal and state level based on the fact that their names conform to a standard pattern (e.g., “Young <Democrats/Republicans> of America” or “<Democractic/Republican> Legislative Campaign Committee”).
We then associated each entity with its website, if one existed. If Ballotpedia recorded a website, or if one was recorded in the Federal Election Commission (FEC) filings, we used that information. Otherwise we queried search engines based on the entity’s name and office and ranked the results based on a number of heuristics that we developed by observing common patterns in the URLs and names of such websites (e.g., “<last name> for Congress”). We manually verified each website that was detected with our automatic procedure and added in the correct one if it was not originally found.
Automated email signups and data archival using a bot
Collecting emails is not a straightforward process and requires interacting with a complex sociotechnical system. For example, when users sign up, their email addresses are often sold or disclosed to other entities. Even the opening of emails is tracked both by the sender (through link clicking and images) and by a complex network of third parties who observe the recipients’ interactions through cookies (Englehardt et al., 2018a). As a consequence of this tracking, users may receive varying subsequent emails.
Based on these considerations, we carefully automated the process of finding and filling out email subscription forms on these websites by creating a bot using Englehardt et al.’s open-source code (Englehardt et al., 2018a, 2018b). The bot runs on OpenWPM (Englehardt et al., 2018a), a Selenium-based web automation framework that enables examining the privacy practices of websites.
Upon visiting a political entity’s website, our bot used a variety of heuristics to discover an email signup form (Supplemental information 1.1). It filled all of these forms with details about a fictional recipient—email address, first and last name, fictional phone number, ZIP code etc. To disentangle the web of email address sharing, the bot generated a unique email address for each form. We chose the same unisex first name (Alex) and last name (Brown) for all our fictional recipients. Our fictional phone number had a valid area code but a random—and invalid—exchange code and line number. We picked an in-district ZIP code for the federal candidates, a state ZIP code for the state candidates, and the same state (Florida) ZIP code for all political entities and organizations. The bot also dismissed any obscuring popup or modal dialog first so that it could interact with the email signup form.
To standardize our treatment of emails, the bot opened each received email exactly once immediately after receipt, did not click on any links in the emails (excluding a link in the welcome email confirming we wanted to receive further emails), took a screenshot of the email, and saved any potential jar of cookies for each recipient.
In order to capture geographic targeting and A/B testing among the 24 prominent 2020 presidential candidates, we signed up for each of their lists with 50 unique email addresses (using a ZIP code from each US state).
Since our list of campaigns and organizations grew over time, we executed the website discovery and automated subscription steps in seven waves in December 2019 (12/02, 12/03, 12/10, 12/15), Jan 2020 (01/16, 01/27), and May 2020 (05/25). Supplemental information 1.1 contains details our signup steps and email interaction procedure.
Corpus coverage
Our target population of campaigns and organizations active in the 2020 election cycle includes 16,082 candidates in federal and state races, PACs, Super PACs, political parties, and other political organizations. Among these, we discovered a website for 9640, the bot submitted a form on 7010, and we ultimately received emails from 3091 (Figure 1). This discrepancy is a consequence of several factors. First, only about 60% of the candidates and organizations in our corpus had an active website. Of the ones that had a website, we used a manually validated random sample to estimate that our bot submitted a form with 86% success when a mailing list form existed (details in Supplemental information 1.2). The fact that we received an email from about 32% of candidates and organizations with a website reflects that many candidates and organizations with websites did not have active email campaigns on their website. The vast majority of those who don’t are state candidates many of whom may not be in competitive races or may not be using their website to bolster their email list.

Funnel diagram showing the number of the entities remaining through the various steps of our corpus collection process.
Our coverage of prominent candidates is substantially higher than the baseline: of the 23 candidates who participated in the democratic presidential debates, our corpus includes all 19 candidates who were still in the race when we started our data collection in December of 2019. It includes 90.0% (63/70) of federal candidates who spent more than 10 million dollars according to FEC filings. Of the seven federal candidates who spent more than 10 million dollars but did not send us any emails, one was a presidential candidate who had suspended their campaign before we began our data collection while another was a less prominent presidential candidate whose website did not contain a mailing list signup form. Similarly, it includes 45.2% (71/157) organizations who spent more than 10 million dollars according to FEC filings. Of the 86 organizations that spent more than 10 million dollars but did not send us any emails, 14 had no website, 15 had a website but not mailing list, and 32 were not under the scope of our target organizations.
Our coverage also includes a diversity of electoral races: 91.2% of federal races and 48.7% of state races have at least one candidate who has sent us emails. Overall, our corpus constitutes emails from more prominent and active candidates and organizations. Given that managing an email list consumes financial resources, these are more likely to have adopted the email medium.
While our corpus continued to accrue emails in 2021 and beyond (now totalling

Distribution of the volume of emails over time.
Breakdown of the entities in our corpus showing the size of each subpopulation, the number that we attempted to interact with, and the number from which we received emails. Senders differ greatly in how often they send emails: the median federal candidate sent an email every 2 weeks whereas the 95th percentile candidate sent 13 emails every week. PACs and organizations are more active; the median Hybrid PAC sent an email every week and the 95th percentile Hybrid PAC sent 15 emails every week.

We note that while we attempt to cover all federal and state candidates up for election as well as political organizations such as PACs, we do not cover city-level races or non-profits such as 501(c)(3)s. Further, we only observe emails that result from signing up on websites. It is possible that emails sent to lists acquired through other means—data brokers, in-person fundraisers, rallies—have substantially different content. Donors may also receive tailored content, which we do not observe. Finally, since we signed up using an in-district/in-state ZIP code for the entities in our dataset, our corpus primarily reflects in-district/in-state email communication. We are unable to observe any variation in content that might emerge as a result of choosing alternate in-district/in-state ZIP codes or out-district/out-state ZIP codes. Given the increasing nationalization of politics (Hopkins, 2018: e.g.), future data collection could expand the multiple signups that we use for presidential candidates to capture geographical targeting among all representatives.
These limitations aside, our coverage compares favorably to another public resource, the “Archive of Political Emails” at https://politicalemails.org. 3 Supplemental information 1.2 compares our coverage to theirs on senders within the scope of our collection efforts. Supplemental information 1.3 discusses the ethical considerations we made in our study.
The content of political emails
To provide a systematic overview of the contents of our political email corpus, we used a structural topic model (Roberts et al., 2016, 2019; Schwemmer, 2021) to inductively discover topics. Each email in the model is represented as a mixture over topics, and each topic is represented as a mixture over words.
To prepare the emails for topic modeling, we took two steps to prevent sender-specific terms from dominating the output: masking the name of the sender (candidate or organization) and removing all non-textual content (e.g., HTML tags), greetings, footers, and other text repeated across emails by the same sender. Additionally, we removed emails not containing any body texts and took standard steps such as lemmatization, identification of collocations terms, and removal of stopwords.
We selected and validated a model with 70 topics that best fit our research goals. Two authors inductively labeled and grouped the 70 topics into six high-level categories (Figure 3). The topic categories with the highest proportions are “political campaigns, actors and events,” “political issues,” and “fundraising.” Topics in the “political campaigns, actors and events” category include, for example, presidential candidate and former president Donald Trump, as well as the presidential candidate and current president Joe Biden. Prominent “political issues” include healthcare, the “Black Lives Matter” movement, and the Coronavirus pandemic. The “fundraising” category corresponds to explicit fundraising and donation requests. The proportion for fundraising is a conservative estimate, as many of the email footers that we removed during preprocessing also contained fundraising requests. Supplemental information 2.1 and 2.2 contain details about our topic model as well as trends in particular topics by sender type and over time.

Overview of assigned topic categories for political emails. The majority of content is related to political campaigns, political actors, and political events as well as political issues. More than 20% of content is related to explicit fundraising.
The topic categories illustrate that while the political emails in our corpus attempt to inform recipients about political issues and events, they primarily solicit funds and donations. In practice, we observe that other topics are often a motivation for fundraising and we discuss this below in the section on approaches to fundraising fatigue. We now turn our attention to the tactics senders use to get recipients to open their emails.
Manipulative tactics in political emails
As in the case of commercial dark patterns (Mathur et al., 2021), we observe a relatively small number of manipulative tactics that are used repeatedly across emails. We present four studies. Our first analysis concerns email subject lines, which we know that political campaigns attempt to carefully optimize (Denton et al., 2019; Magleby et al., 2018). Next, we examine A/B testing by presidential candidates and confirm that subject lines are heavily tested frequently in ways that align with the manipulative tactics we identify. We interpret this as suggestive evidence that the use of manipulative tactics is intentional and explicitly optimized. Third, we turn to the bodies of emails. In an exploratory manual investigation of email bodies, we observed a greater diversity of tactics as well as more barriers to automated analysis due to the presence of markup and images. We limited the analysis to one question we considered especially important: how senders attempt to overcome “fundraising fatigue.” Finally, we analyze how senders disclose email addresses to other political entities without the consent of the recipients.
Before proceeding, we address our use of the term “manipulative”—which is more common in the HCI literature on dark patterns than in political communication—to describe the tactics we document below. The phrase reflects our normative position that these tactics pose individual and collective harms. Even relatively benign tactics that encourage users to open an email exist in the context where many of those same emails contain more explicit deception in the email body. Our analysis of the email bodies as well as journalists have documented serious harms from political emails in the 2020 campaign including tricking recipients into recurring donations through default nudges (Goldmacher, 2021a, 2021b). Additional research has shown how confusing, but not necessarily deceptive, dark patterns in user interfaces can dramatically shape user behavior to their detriment (Luguri and Strahilevitz, 2021). We do not claim that any persuasive tactic used by campaigns is inherently manipulative. Rather we focus on these tactics because they are not primarily about engaging with political argument—they are consistently about pivoting to raising money. Readers might reasonably disagree that each tactic we discuss is manipulative, but we argue that the broader picture is more about manipulation than informing or persuading voters.
Manipulative ways to nudge recipients to open emails
Given that the typical open rate for political emails is reportedly only about 20% (Chaffey, 2020; Pearlman, 2012), the sender’s first challenge is to convince the recipient to open the email. We found two primary ways in which senders attempt to manipulate recipients into opening emails: by employing various types of clickbait and by exploiting the email user interface. We discuss these manipulative tactics below and provide our detailed codebook of tactics in Supplemental information 3.1. Figure 4 displays two annotated example emails that showcase several manipulative tactics, including five of the six tactics described in the section below. We also refer to email “from:” fields and subject lines below. The from field of an email indicates the identity of the sender to the recipient whereas the subject line contains the email subject. Figure 5 illustrates the from fields and subject lines in an email box.

Examples of two emails in our corpus (cropped for space) that show many of the manipulate tactics we identify. Additional tactics appear in the bodies of the emails, such as the donations counter in the email on the left which decreases randomly once the email has been opened in order to prompt the user to feel a sense of urgency. We do not undertake a comprehensive analysis of such dark patterns in the email bodies.

An illustration of our email inbox showing the “from:” fields on the left and the subject lines on the right, along with various manipulative tactics such as the Obscured name (“YOUR URGENT RESP.”) and Sensationalism clickbait tactic (Pelosi called you a WHAT?). The screenshot reflects the inbox from a randomly selected time period, in this case from March 2020.
Clickbait and dark patterns in email from fields and subject lines
Clickbait resists a universal definition but broadly speaking it exploits cognitive vulnerabilities to encourage users to interact with content. We identified three specific types of clickbait:
While clickbait manipulates recipients through framing and presentation of text, dark patterns exploit the user interface to manipulate users (Mathur et al., 2021). The email user interface defines a set of conventions for how users expect to receive information. The dark patterns we highlight below exploit these conventions to create false implications:
Prevalence of the manipulative tactics in our corpus
To identify instances of these six manipulative tactics, we used a combination of machine learning and regular expressions. The two tactics we detected using regular expressions were “Ongoing thread” and “Re: / Fwd:” (Supplemental information 3.1).
To detect the remaining four tactics, we designed and built machine learning classifiers. We first used our codebook to calculate inter-rater agreement. Two researchers independently labeled 250 randomly sampled emails from our corpus for each of the four tactics, observing the subject lines and the from field. Cohen’s kappa (
One of the two researchers then coded a new random sample of 1% of the corpus (3174 emails), stratified by month, to build our classifiers. We trained support vector machine and random forest classifiers for each of these four tactics using this dataset. We extracted a variety of features for each tactic, including word n-grams, part-of-speech n-grams, dependency sn-grams, length, word count, sentiment, and other non-semantic features.
We split our coded sample of 3174 emails into three parts: a training set (2139), a calibration set (535), and a holdout set (500). We used the training set to perform 5-fold nested cross-validation to determine the best-performing classifier based on the classifier’s F1 scores. We then selected the best-performing classifier and retrained it on the entire training set using its best-performing hyperparameters from the cross-validation step. The best-performing classifier’s F1 score on the holdout set of 500 emails was 0.81 for forward referencing and sensationalism, 0.91 for urgency, and 0.94 for the obscured name pattern. We also tested whether the classifiers were calibrated on the holdout set. If they were not—meaning the predicted probabilities of the classifiers were not aligned with the true prevalence of these four manipulative tactics—we calibrated them on the calibration set. We provide additional details in Supplemental information 3.2, including the ROC and PR curves for each classifier.
We then scored the entire corpus of emails and aggregated them by “active” senders, i.e., those who sent at least 10 emails excluding “welcome” emails. This retained 1401 senders. Using the probabilities returned by our classifiers and regular expressions, we approximated the joint probability that any email contained at least one manipulative tactic (Supplemental information 3.3). The mean of each joint probability score across all the emails for a given sender represents the proportion of emails of the sender that contain at least one manipulative tactic. To derive corresponding proportions for each tactic type category—clickbait or dark patterns—we only considered the relevant tactics under that category.
We see that manipulative tactics are common (Figure 6). The median active sender used at least one manipulative tactic in 42% of their emails. In total, 10.7% of active senders employ them in over two-thirds of their emails and 8 out of 10 of those are organizations (organizations also send many more emails in total). The top senders in this group include prominent PACs and Super PACs like the Progressive Turnout Project, and the Democratic Conservation Alliance. The median value only shifts nominally to 41% when excluding all emails from senders that were a result of email address disclosures to other entities, as we describe in the section on email address disclosures below.

Histogram of senders showing the proportion of each sender’s emails that contain manipulative tactics, overall and broken down by type of manipulative tactic. Left (A): Any clickbait tactic. Left (B): Three types of clickbait tactics. Right (C): Any dark pattern user interface tactic. Right (D): Three types of dark pattern user interface tactics.
Splitting the tactics by tactic type, the median active sender used at least one clickbait tactic in 37% of their emails and at least one dark pattern user interface tactic in 5% of their emails (Figure 6). Figure 6B and D show that many senders use clickbait tactics with regularity but relatively fewer—still non-trivial—use outright deceptive patterns (”Ongoing thread” and ”Re: / Fwd:”). There are minor differences in likelihood of use of the manipulative tactics we describe by various sender attributes (candidates vs organization, party affiliation, and electoral race). Figures 8, 9, and 10 in Supplemental information 3.3 shows the cumulative distribution plots that illustrate these breakdowns.
A/B testing the use of manipulative ways to nudge recipients to open emails
Major email marketing services have easy built-in features for A/B testing—a randomized experiment conducted to learn user preferences. Our dataset allows us to investigate A/B testing patterns among the 24 prominent presidential candidates that we signed up for using 50 unique email addresses and distinct ZIP codes. A/B testing has become a central tool for many political organizations (Karpf, 2018). By studying what kinds of variables that campaigns are manipulating, we hope to better understand their intent and make inferences about the effectiveness of manipulative tactics.
We used text clustering to determine instances of A/B testing in the from field and the subject line—emails from the same sender are likely to contain similar content even if they vary in the from field or the subject line. We embedded each email into the vector space defined by Spacy’s en_core_web_sm model (Honnibal et al., 2020) and then clustered emails from each sender into “batches” using the HDBSCAN clustering algorithm (McInnes et al., 2017; Campello et al., 2013). We considered differences within these batches to be a result of A/B testing. Because our clustering is conservative, we used this as a lower bound for the amount of A/B testing that was actually performed in these emails.
We found that the occurrence of A/B testing varies substantially by the sender and by email component. Among senders, the median and mean percents of email “batches” with A/B testing detected is: 5.2% and 27.0% on the subject, 3.0% and 8.4% on the email body, and 0.3% and 2.8% on the from field. The fact that a majority of experimentation happens in the subject line suggests that manipulation may be particularly prevalent and particularly effective in subject lines. We also found tests conducted that specifically targeted five of the six manipulative tactics we documented (all except “Ongoing thread”). In fact, within A/B tested emails where the subject or from fields changed, a median and mean of 54.1% and 47.7% of batches experienced direct experimentation with the presence and absence of one of these five tactics. We report examples for each (each batch of subject lines corresponds to exactly identical email bodies):
A/B testing allows senders to test how to craft emails in a way that increases measures such as open rates anddonations, and decreases measures such as unsubscription requests. The presence of A/B testing of manipulative tactics indicates that campaigns are aware of these tactics, and that there are in fact parameters to tune when deciding how to deploy them effectively (Narayanan et al., 2020).
Approaches to fundraising fatigue
Our topic model demonstrates that explicit fundraising is one of the main goals of campaign emails. In a sample of 200 emails, we further verified that the majority (140) contained donation requests—even after excluding content footers which often contain such requests as well. Because senders run the risk of desensitizing recipients with persistent fundraising solicitations (Bykowicz, 2019), we examine how senders attempt to overcome possible fundraising fatigue. Many of these techniques are not as amenable to automated analysis and so we use a series of smaller, manual studies and indirect automated tests.
The pivot-to-fundraising pattern
A common tactic is to mention a topical hook in the subject line and begin the email discussing that topic before pivoting to a donation request. Supplemental information 3.4 shows an example of an email that pivots from a topical hook into a fundraising ask. We quantified this “pivot-to-fundraising” pattern and measured the extent to which sentences in various locations in an email relate to its subject line as well as the extent to which they are explicitly about fundraising.
To measure semantic similarity between the email body content and the subject line, we used the Universal Sentence Encoder (Cer et al., 2018) model. This model embeds each sentence into a vector space that captures its semantic meaning. In this space, the cosine similarity score between any two sentences represents their semantic similarity. Using this similarity score, we measure how related a sentence in the body of an email is to its subject compared to a different subject from the same sender (details in Supplemental information 3.3).
To determine if sentences are fundraising asks, one author labeled 400 randomly selected sentences from the emails in our corpus, creating a 300-100 train-test split (the base rate of positive examples is 14%). We then trained a logistic regression model to predict whether a sentence is a fundraising ask, and observed a test accuracy of 96%, with a false negative rate (FNR) of 25% and false positive rate (FPR) of 0%.
As we see in Figure 7, emails do not stick to the topic of their subject lines; in fact, toward the end of an email, sentences are no more related to its subject line compared to a random subject line from the same sender. Meanwhile, fundraising-related content rises in probability in the first half of emails and stays high in the second half.
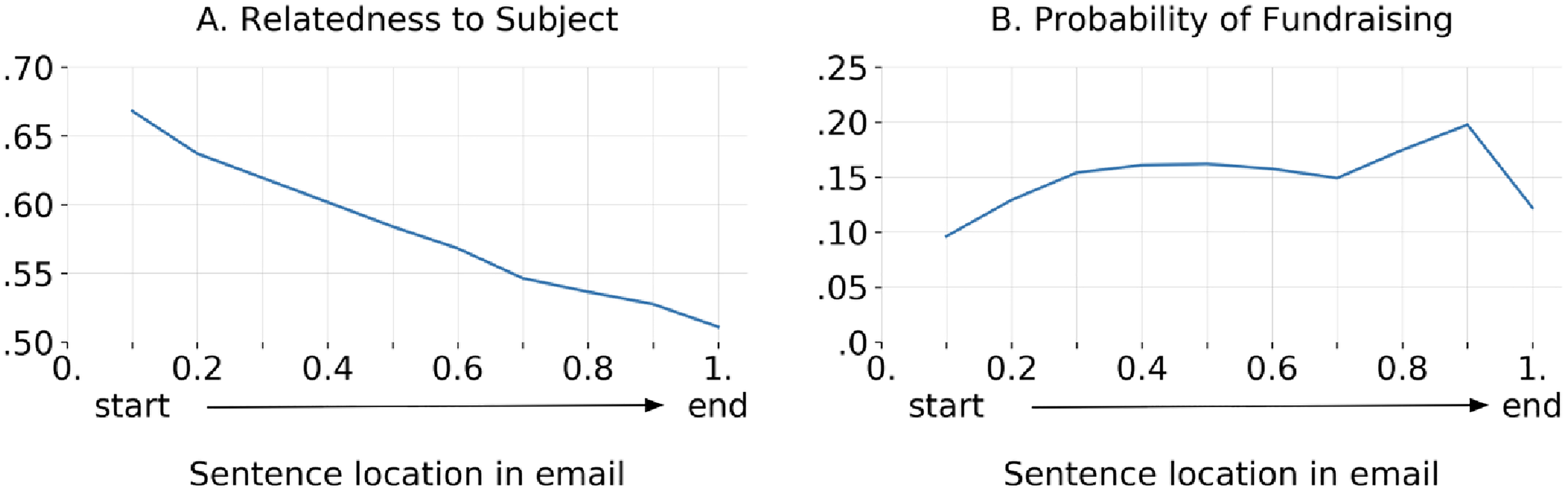
Aggregate trends in the progression of emails, illustrating how emails start by discussing the topic of their subject lines but pivot to fundraising requests. Left (A): emails descend in relevance to the subject line, calculated as the probability that the sentence is more similar to the subject of the email it came from, rather than the subject of a different email. The baseline probability is 0.5. Right (B): emails increase in probability of being classified as a fundraising ask. The drop in the end is explained by email footers that were not removed, such as “Paid for by CAMPAIGN.”
Stratifying by party affiliation, office level, and incumbency, we see little difference in how different groups’ emails deviate from the subject as the email progresses. However, in terms of fundraising asks, we see differences, as shown in Supplemental information 3.3. Democrats seem to have a higher proportion of fundraising asks over Republicans, and Federal campaigns over State ones.
Deceptive claims and requests
We discovered several other tactics that use specific deceptive claims or requests. About 36,000 emails (11.5% of all emails) promise donation “matching,” usually by unspecified entities. Legal experts point out that although matching by wealthy individuals is common in philanthropy, it would be unlawful for political campaigns due to FEC individual contribution limits (Pathe, 2017). About 11,300 emails request the recipient to submit some type of survey. Once the user completes such a form, there is an overwhelming likelihood—88 out of a sample of 100 that we examined—that they will encounter a deceptive user interface that makes it appear as if a donation is necessary for the text or choices entered into the form to actually be submitted. A small subset of “survey” emails (189 of 11,399) went further to explicitly claim not to be about fundraising, with subject lines such as “NOT asking for money.” We inspected a sample of 10 and found that all of them did in fact ask for money within the survey. Finally, a substantial fraction of emails refer to an imminent fundraising deadline to urge a donation. Such pleas account for the end-of-month spikes in email volume (Figure 2), even though most campaigns file FEC reports quarterly.
Senders disclose recipients’ email addresses without their consent
Prior research suggests that political campaigns often collaborate by sharing or selling users’ email addresses (Box-Steffensmeier et al., 2020). We examine how often this occurs in our corpus, including cases where it explicitly violates the privacy policy of the sender. During sign-up, our bot generated a unique email address on each sender’s website, allowing us to match every email to a sign-up. We manually examined every email that was sent from a different domain name than the sign-up domain and, in each case, determined whether the difference in domain names was because the email had an unexpected sender. We did this by examining the domain’s ownership using a combination of online search, the website’s privacy policy, and by querying WHOIS, a central registry of domain ownership.
We observed a total of 741 instances of email address disclosures by 322 senders. Table 2 summarizes the campaigns and organizations who disclosed email address and the number of entities that received the email addresses. The entities receiving these emails address include 282 campaigns and 329 political organizations, but also 10 news websites. Our findings reveal that email address disclosure is more prevalent than previously reported for the 2016 election cycle (Box-Steffensmeier et al., 2020) and that it involves a wider variety of political and non-political entities beyond federal candidates and PACs.
Email address disclosures by senders in our corpus.

For each of the 322 entities that shared email addresses, we attempted to determine whether this fact was communicated to subscribers by examining campaign websites in August and December of 2020. The majority (133) had no privacy policy on their websites. Only about a quarter (77) mentioned that they disclosed email addresses in their privacy policies. Out of the remaining 112, 15 did not mention email address disclosures in their privacy policies, 16 falsely claimed they do not share any personal information with other entities, and 25 had mentions about email address disclosures that were too ambiguous to determine whether or not the sharing we observed was permitted.
Discussion
We present and analyze a corpus of over 300,000 political emails from the 2020 US election cycle. Our analysis demonstrates that political campaigns and organizations use clickbait in subject lines and manipulate elements of the email user interface to get readers to open emails. We provide the first systematic analysis of the quantity of these tactics, demonstrating that they are the norm among active email senders. We observe a striking convergence by thousands of senders to a small number of manipulative tactics, which has also been observed in the realm of commercial dark patterns (Mathur et al., 2019; Narayanan et al., 2020). We speculate that senders may be borrowing ideas from each other, that senders are exploiting a small set of cognitive biases in users, or that many senders may be using a common set of advertising and fundraising agencies that are responsible for manipulative tactics (Lee and Narayanswamy, 2019). We were unable to devise a scalable method to reliably identify the fundraising agencies responsible for individual email campaigns, and hence are unable to analyze the role of these intermediaries.
A more detailed examination of manipulation in email bodies is an avenue for future work. As one example, in our manual exploration we frequently observed an attempt by senders to create an illusion of personalization wherein they inform recipients that they have been handpicked by candidates for surveys or raffles and that their response is specifically being solicited. While the potential for political manipulation through algorithmic personalization has raised much concern (Susser et al., 2020; Zuiderveen Borgesius et al., 2018), actual personalization may not be necessary for manipulation to be effective.
While our data do not allow for a direct examination of the effectiveness of these manipulative tactics, we studied presidential candidates and confirmed that they are using A/B testing. There is also abundant evidence from journalistic reporting that email tactics are subject to careful study (Lee and Narayanswamy, 2019). Both these observations suggest that the manipulative tactics might indeed be effective (Bykowicz, 2019; Montellaro and Journal, 2015) and thus pose a variety of harms to recipients.
Manipulative patterns diminish the autonomy of recipients and coercive donation practices can harm their financial welfare (Goldmacher, 2021a). When senders disclose email address to other entities—including some whose behavior contradicts their own privacy policies—recipients’ privacy is violated. In particular, those with low digital literacy (Hargittai, 2002)—which is closely proxied by age in the US (Hargittai et al., 2019)—are particularly at risk of being harmed (Goldmacher, 2021a). Indeed, the strong age moderation effects of exposure to digital political misinformation (Guess et al., 2019) suggest the same.
Beyond harm to the individual, the manipulative tactics also pose broader collective societal harms. The underling manipulative political discourse corrodes the ideal of a public sphere and of a participatory democracy (Habermas, 2015). It distorts political outcomes by advantaging those who are skilled at deploying technological tricks, triggering a race to the bottom. When voters realize they are being tricked, they lose trust in political communication and disengage. Yet, this may not lead to self-regulation: based on A/B tests, senders likely make a calculated assessment that the gains from such tactics outweigh the losses from unsubscription. The normalization of questionable tactics also poses a security risk, making it easier for scammers to imitate political candidates and organizations in order to steal money from would-be donors (Severns and Bland, 2018).
The potential for harm is particularly concerning because unlike social media platforms and online ad platforms that impose fact-checking and moderation policies on political speech, emails are unfiltered and unmoderated in part because there are few public records of them. This suggests a potential countermeasure, namely for email providers to analyze political emails to add warnings to the user interface or filter out some emails entirely. However, this might violate norms around the privacy of email content and also raises concerns about suppression of political speech by private actors; Gmail’s—and others (e.g., Outlook)—spam filtering has already been criticized along these lines (Jeffries and Yin, 2020; Iqbal et al., 2022).
Conclusion
We hope that our corpus will be useful for studying a wide array of traditional political science questions, including how candidates represent themselves to their would-be constituents, how and when campaigns go negative, and what tactics campaigns and organizations use to raise money and mobilize voters. In the context of the 2020 US election, our corpus could also be used to study emails preceding the Georgia run-off elections, emails questioning the integrity of the 2020 US presidential election, and various other more general post-election communication. Emails also provide a unique window into smaller campaigns that lack the funding necessary to purchase airtime and consequently do not appear in major datasets of television ads such as the Wesleyan Media Project. Further, as social media platforms like Facebook and Google have recently banned political advertising and fundraising, it has become more important for campaigns to use emails to rally their bases and raise money (Schneider, 2021).
Our collection of emails is available to browse online at https://electionemails2020.org, and with a full dataset available to academics and journalists by application, complementing other collections including the campaign emails at https://politicalemails.org and the https://dcinbox.com collection of official newsletters from congressional offices (Cormack, 2018). We have released our bot and all the relevant analysis code on GitHub at https://github.com/citp/election-emails. We hope that our corpus can shed some light on this previously under-explored, yet prevalent, form of political communication.
Supplemental Material
sj-pdf-1-bds-10.1177_20539517221145371 - Supplemental material for Manipulative tactics are the norm in political emails: Evidence from 300K emails from the 2020 US election cycle
Supplemental material, sj-pdf-1-bds-10.1177_20539517221145371 for Manipulative tactics are the norm in political emails: Evidence from 300K emails from the 2020 US election cycle by Arunesh Mathur, Angelina Wang, Carsten Schwemmer, Maia Hamin, Brandon M Stewart and Arvind Narayanan in Big Data & Society
Footnotes
Acknowledgements
We are grateful to Mihir Kshirsagar, Matthew Salganik, Andy Guess and Orestis Papakyriakopoulos for feedback on our paper. We also thank Justin Grimmer and Jonathan Mayer for advice at earlier stages of the project. We are also grateful to Ballotpedia and OpenSecrets for providing and making their data available to us. This project was funded in part by generous support from the Data Driven Social Science Initiative at Princeton University.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.