
Abstract
In this paper, we explore the methodologies underpinning two participatory research collaborations with Australian non-profit organisations that aimed to build data capability and social benefit in data use. We suggest that studying and intervening in data practices in situ, that is, in organisational data settings expands opportunities for improving the social value of data. These situated and collaborative approaches not only address the ‘expertise lag’ for non-profits but also help to realign the potential social value of organisational data use. We explore the relationship between data literacy, data expertise and data capability to test the idea that collaborative work with non-profit organisations can be a practical step towards addressing data equity and generating data-driven social outcomes. Rather than adopting approaches to data literacy that focus on individuals – or ideal ‘data citizens’ – we target the organisation-wide data settings, goals and practices of the non-profit sector. We conclude that participatory methods can embed social value-generating data capability where it can be sustained at an organisational level, aligning with community needs to promote collaborative data action.
Introduction
The ‘big data divide’ describes the uneven production, control and benefit derived from the flow of data through increasingly automated systems (McCarthy, 2016). It reminds us of the need to study the sites and settings in which data are generated and used alongside their impact on data subjects. Critical data scholars have detailed the role of corporate interests in shaping those uses and outcomes through ‘extractive’ data practices and systems designed for commercial gain (Andrejevic, 2014; Sadowski, 2019). Less attention has been paid to applied methods for understanding and improving data practices in civil society and community sector settings and the potential for building data capability in these settings as a way of improving data equity. Non-profit organisations (also referred to in various global contexts as not-for-profit, non-governmental organisations/NGOs, community sector, third sector or civil society) are uniquely placed to explore data opportunities and challenges, and consider how to build data awareness, skills and expertise for wider social benefit (Fotopoulou, 2020; Williams, 2020; Data Justice Lab, 2021).
In this paper, we explore the methodologies underpinning two participatory research collaborations with Australian non-profit organisations. The aim of the work is to develop and test participatory design or co-design methods that can help researchers and non-profit organisations collaborate to address issues of data equity. Although this must ultimately involve data subjects – those who are the subjects of data collection and analysis – in this paper, we focus on participatory research with non-profit staff members with varying data skills as a space for improving data practices and issues of equitable data access, use and outcomes. We argue that studying and intervening in data practices in situ, that is, in organisational data settings, and developing data capability can address the ‘expertise lag’ (Bassett, 2015) for non-profits while helping to reconfigure data practices and realign the outcomes of organisational data use to address data equity (Jagadish et al., 2021). Building on existing notions of situated data literacy and expertise, we position data capability in organisational contexts, as a more holistic (rather than individual) set of infrastructures, practices, competencies and goals. Non-profit organisations face significant challenges in using limited resources to build data capability, but they are also well placed to connect with community needs and generate social value by using, sharing and innovating with data. We do not assume that improved data capability will automatically deliver social value but see the expansion of non-profit data capability as a key battleground in addressing data equity.
Although these broader outcomes may be aspirational, our paper contributes specifically to the growing range of methods used to study data practices in situ and as they affect the operation of data in everyday and organisational contexts (Bates et al., 2016; Kennedy, 2016; Tkatcz et al., 2021) and establishes a set of participatory research strategies for building data capability with the potential to achieve greater public confidence and trust in data use (e.g. Ada Lovelace Institute, 2021; Data Justice Lab, 2021). Although big data or the data that flows through organisational and logistical processes can seem void of context, all data are local, embedded in socio-technical, cultural and organisational settings (Loukissas, 2019). Therefore, engaging directly with non-profit sector organisations, offers practical methods that can help to widen the scope of who benefits from, and is able to participate in, the digital and data economy, and points to the innovative role that the sector might play in shaping the use and social benefit of data. These methods can contribute to interdisciplinary studies of data practices across a range of fields including applied data science, human–computer interaction, science and technology studies and digital humanities.
The methodology has been developed through two collaborative non-profit sector data projects delivered in 2020 and 2021 with 20 organisations and 28 participants based primarily in Melbourne, Australia, in the context of extended pandemic-related lockdowns and fast-tracked digital-first service provision. We draw on interviews undertaken throughout the projects to examine the way participatory methods can be used to investigate and build effective and responsible data capability in these data settings and explore why and how non-profit organisations are looking to build data capability.
We begin by defining elements of data capability as a space for affecting data equity in practice through non-profit organisational data settings. We then review the participatory methods that have sought to critically engage with everyday digital and data practices with community organisations. This review highlights key transferable elements to derive an approach that focuses on (a) mapping and understanding data practices in situ, (b) producing data analysis outputs collaboratively, and (c) building data capability and data equity within diverse data settings. The second half of the paper details two case study projects drawing on these approaches. Analysis of participant interviews then shows the effectiveness of methods that target local and specific needs and practices of individuals within organisational data settings relative to their social mission, to create spaces and conditions for collaborative data action. The conclusion draws together insights from the case studies that show opportunities for working with non-profits to build data capability and addressing data equity through participatory methods.
Why study data capabilities in the non-profit sector?
Data literacy has been defined as the set of competencies and contexts associated with reading, working with and analysing data (D’lgnazio and Bhargava, 2015). Part of the difficulty, however, is that data literacies, along with expertise (Bassett, 2015), are also sites of struggle, built around the contextual knowledge and diverse experiences that shape relationships with data and its analysis. We use the term data capability to account for this broader context and wish to avoid evaluative terms like ‘data maturity’. Data capability describes the mix of skills and competencies, experience, expertise and resources needed to collect and use digital data in specific contexts. As we explain below, in contrast to individual data expertise and literacies, we position data capability as collective and collaborative, situated in organisational or community data settings. In data science, ‘capability’ can have a double meaning, relating both to personal attributes or abilities, and technical components such as software, hardware and database systems – a combination of tangible and intangible elements that underpin the creation and use of data (Gupta and George, 2016). We retain this double sense to account for the interrelated human, social and technical dimensions of data capability. Who works with data, how and to what ends – these are fundamental questions for delivering data equity, addressing the data divide and ensuring social benefit in data use.
Given their social value mission, non-profit organisations are an important site for developing data capability. Data activism has played a well-documented role for civil society organisations and actors, in the ‘use, mobilization and creation of datasets for social causes’ and to disrupt harmful corporate and state uses of big data (Kazansky et al., 2019; see also Reile, 2020). In a more operational sense, non-profits are increasingly looking to data-driven systems and analysis to streamline operations in the management of volunteers, track and understand patterns in donations or the impact of outreach activities, help to monitor public sentiment and events or develop predictive capabilities to aid decision-making and inform support provision (e.g. Brudney et al., 2017). Although much of this could be considered a replication of private sector ‘business insights’ and ‘customer relationships management’, there is a growing sense that more can be achieved using non-profit sector data than efficiency and operational management. However, compared to the private and public sectors, non-profits are considered to lack crucial resources and expertise (Infoxchange, 2020).
Larger non-profits in Australia delivering community health or disability support, for instance, employ thousands of staff as well as volunteers, with 1.3 million people employed sector-wide and 3.7 million volunteers (Australian Charities and Not-for-Profits Commission, 2018). Although non-profit organisations themselves face challenges in developing digital and data capability (Infoxchange, 2020), they operate at the social frontline, addressing social problems and disadvantage. Like other developed countries, the sector in Australia is characterised by instability and uncertainty (Barraket, 2008). Organisations often compete for government funds under networked and distributed funding models or through scarce philanthropic or individual donors. Data innovation has been driven by funding requirements tied to outcome measurement, as has been the case in Europe and the UK (Chiu, 2019) as well as North America (Lalande, 2018). But these are also everyday data settings (Loukissas, 2019; Kennedy, 2016) that constitute ordinary ‘information ecologies’, where people are encountering data systems and ‘struggling to figure out how to use their tools more efficaciously’ (Nardi and O’Day, 1999: 142). Gurstein’s (2011) critique of open data as a solution to the data divide drew an important distinction between access to data and ‘support for effective data use’, a critique that remains highly relevant for the non-profit sector.
The need to build data capability across the sector has taken on a political urgency, with various data literacy programs often seen as an answer. But there is little evidence as to what works, or research detailing steps for building data literacy and expertise, how organisations and groups can build data capability and ultimately how these will lead to improved data equity. Following scholars such as Kennedy (2016), and Bassett (2015), we argue that new forms of data literacy and expertise can be found and fostered in the contested space between the ‘new epistemologies’ (Kitchin, 2014) associated with big data – that is, the new ways of knowing the world associated with data analysis and insights – and the ‘alternative epistemologies’ (Milan and Van der Velden, 2016) – or inclusive, intersectional and equitable knowledge that activist and human-centred data practices might enable (Kazansky et al., 2019). In other words, building ‘critical’ data literacy among non-profits can improve service delivery, efficiencies and impact reporting, but it can also widen the scope of data equity and inclusion through community-oriented data practice (Fotopoulou, 2020). The first step is to rethink the goals and applied contexts of data capability.
Defining data literacy beyond individual competencies
As more domains of social life are transformed into computable data, the ability to understand and use data becomes essential for citizens, organisations and governments alike. Frank et al. (2016) argue that a data literate citizen should have the ability to find, select, understand, interpret, evaluate and manipulate data in the context of the internet with confidence, and to appreciate the value of data. To their definition of data literacies as the ‘the ability to read, work with, analyse and argue with data’, D’lgnazio and Bhargava note important sensitivities in the era of big data including the need to understand algorithmic manipulations, and ability to weigh up consequences of data handling for already marginalised people (2015: 2). These are rarely the sole remit of individuals acting alone with or in relation to data.
Our approach foregrounds the way data collection, use, literacy and expertise are situated. By connecting the notion of ‘situated literacies’ (Barton et al., 2000) to data and its uses, we emphasise the need to understand transformations in the communicative and relational contexts through which data is produced and becomes operational. In the 1990s and early 2000s, social and applied linguists developed new approaches to the concepts and methodologies associated with literacy to better account for different cultural and everyday contexts. Part of the ‘new literacy’ movement (Street, 1997; Barton, 1994), these scholars widened notions of literacy from a supposed set of individual competencies and cognitive processes to understand its plural forms in specific social contexts and cultural milieus. Rather than being properties belonging to individuals, literacies develop in the relations between people, within groups and communities, and in historical, cultural and institutional contexts. By applying this to the way we talk about, read, create, analyse and use data for decision making, we see an opportunity to study and address the data settings often ignored by dominant tech industry and critical data studies voices.
There are several aspects of existing work on data literacies that help to engage context and relationships and push the concept beyond individual competencies. Firstly, recent work identifies the critical dimension of big data literacies. As Fotopoulou (2020) points out, there has been a disproportionate emphasis on technical skills and competences at the expense of the social dimensions of citizen and organisational data practices. Missing has been a critical dimension that attends to the social contexts and consequences of big data, the ethical implications of data-driven decision-making for vulnerable groups, and data processing and governance (Carmi and Yates, 2020). And an important additional motivation to build critical big data literacies is to support meaningful public participation in the oversight and regulation of automated decision systems (Lewis and Stoyanovich, 2021).
Secondly, data literacies are ‘socio-technical’, and technical ecosystems play an important role in situating data literacy. As Gray et al. (2018) argue, a ‘data infrastructure literacy’ describes the knowledge and understanding of how data and systems infrastructures might align or misalign with various interests, outlooks and public concerns. Data infrastructure refers to the ‘shifting relations of databases, software, standards, classification systems, procedures, committees, processes, coordinates, user interface components and many other elements which are involved in the making and use of data’ (Gray et al., 2018: 3). Platform metrics, for example, provide public legibility for the display of social data, and these are a key dimension of personal everyday entanglements with data through social platforms (McCosker, 2017; Pangrazio and Selwyn, 2019). Data infrastructure and platform literacies are also tied to the outcome of algorithm-driven recommendations, sorting, ranking, classification and personalisation (Gran et al., 2020). In this sense, data skills are implicated in wider socio-political (regulation and governance) and corporate (business models and monetisation) aspects of data systems, requiring understanding of how data infrastructures or data-driven platforms are configured to produce, transform and circulate data.
A third move is to disrupt and widen the concept of expertise as a descriptor for those who can, and cannot, work with data. Expertise has always been contested, but in the context of data practices, needs further unpacking. Drawing on theoretical accounts of expertise in the sociology of scientific knowledge, Bassett et al. (2015) consider the way ‘expertise is not a given, stable category’, and in the context of uneven digital transformations across European civil society organisations and citizenry, ‘expertise itself is generally up for grabs in new ways’ (Bassett et al., 2015: 337). Usually, expertise ‘demands and is defined by high-level tacit ability that draws on laid down knowledge’ (Bassett, 2015: 555). This often involves claims to ‘mastery’ and authority, and associated relations of power and subordination. However, Bassett et al. dismiss simple divisions between lay and specialist digital technology use and knowledge, as this division ‘cultivates digital expertise for the purposes of industry, whilst refusing to make it a demand for everyday life’ (2015: 337).
Although the concept of data literacy remains contested, it is useful for grounding and understanding data practices in their communicative settings, in relation to data's representational (communicative) and functional (computational) status (Poirier, 2021). Theoretical and practical work on data literacy generally seeks to improve individual competencies and critical awareness (D’Ignazio and Bhargava, 2015; Frank et al., 2016) as an aspect of contemporary ‘data citizenship’ (Carmi and Yates, 2020) and shifting big data practices. However, it is not always clear where or how this work should take place, and burgeoning corporate data literacy programs (e.g. software company Qlik's online ‘Data Literacy Program’; Qlik, 2020) raise the question of ‘data literacy to what ends’?
Acknowledging different kinds of data expertise is also about recognising that local data knowledge – for instance, the domain knowledge of frontline workers in disability care or social work about their data subjects and data generation in the field – can sit alongside and inform specialist knowledge developed through formal accreditation. We do not pit data expertise and literacy against each other as Bassett does (2015). Rather, these are two sides of the same coin. Both are sites of struggle and opportunity and respond to the collective realities of digital and data transformations. The notion of situated data literacies can better account for this contextual variation in needs, knowledge and application. It points to the relationality of data capability and signals the kind of participatory approaches that are needed to affect and improve non-profit organisations’ data practices.
Participatory methods for building data capability
In this section, we draw together existing participatory methods suited to mapping and understanding data practices and building data capability through collective, purposeful data projects and activities. Participatory design (PD) or co-design methods aim to place research practice within specific settings and draw on local knowledge, experience and domain expertise. They have been used widely to address public health issues, for example, especially where there is a need to integrate education and social action to address health disparities (Minkler and Wallerstein, 2011). Mostly these methods are used to include local community members, ‘ordinary people’, consumers or end-users in service or product design processes (Costanza-Chock, 2020). Participation is used to build public ‘buy-in’ or develop trust, for instance, in product design (Sanders and Stappers, 2008), technology and systems development (Schuler and Namioka, 1993) or service provision. Participatory methods emphasise iterative processes of reflection and action achieved with those most affected by the work, drawing on their knowledge and perspectives (Cornwall and Jewkes, 1995). Following approaches to PD that embed the work within organisational contexts (Lodato and DiSalvo, 2018), our data capability building projects we focus on PD with non-profit staff members with varying data experience and expertise but extensive domain expertise and knowledge.
The non-profit sector is well versed in community engagement and co-design processes. However, we do not claim that these settings are without constraints (Lodato and DiSalvo, 2018) or that PD and co-design processes are the only answer to addressing data capability and data equity issues the sector faces. In the context of controversial expansion of the use of AI, for example, some have argued for caution in ‘participation-washing’ data-driven and automated systems design (Sloane et al., 2020). Effective participatory methods make intervention and community engagement less needed by growing capability and transferring ‘ownership’ over processes and outcomes. By drawing on participatory methods for developing data capability, our approach emphasises the co-learning and social learning aspects of participatory methods and the importance of working in localised data settings. Our informants and project participants and the research team learn collaboratively through data scoping and analysis. In working with non-profit organisations and their workforce, our approach aligns with participatory action research (PAR) methods that involve those who are directly affected by an issue in iterative collaborative research and learning activities (Kindon et al., 2008).
Lessons can be drawn from existing collaborative data projects that have applied participatory approaches and methods relevant to building data capability in non-profit settings. Methods for developing data literacy usually target individual ‘citizens’ through community data projects or as individualised literacy programs, rather than addressing the needs of non-profit organisations in their specific contexts. They gather people with a range of expertise to use data to develop ‘data hacks’ that might address social issues. Examples of ‘citizen data science’ approaches for improving data literacies might include open data jams, hackathons and workshops in public libraries (Frank et al., 2016). In these activities, groups of volunteer data scientists collectively engage in programming and data scoping or analysis efforts, suppling non-profit organisations with much-needed data science expertise and support data-driven decisions for civic issues (Pedersen and Caviglia, 2019).
Other community-based participatory methods include ‘data parties’ and ‘data walks’. ‘Data parties’ are participatory data analysis workshops that have been designed for leaders of non-profit organisations to discuss and identify suitable datasets (such as the community indicators survey data), develop better ways of interpreting data or sharing data with community partners, for instance (Franz, 2013; Rogers and Newhouse, 2018, Connell et al., 2020). Pioneered by the Urban Institute in the US, ‘Data walks’ involve participants rotating through data presentation stations where community data on, for example, education outcomes, employment, food security and mental health are displayed for participants to interpret, discuss and reflect on in small groups, to devise policies and strategies to transform services (Murray et al., 2015; Harrison et al., 2019). These are more about bringing data to communities and drawing on their insights and interpretations to improve organisational or research data analysis.
Targeting organisational contexts, collective actors and civil society data settings offers an important shift. For Fotopoulou (2020) there is value in building the competencies of the collective actors working in civil society data settings to address the ethics and societal impact of data. Her account of ‘datahubs’ describes participatory workshops that introduce representatives from civil society to data types and open data portals, storytelling with data and practical technical skills, such as data wrangling with Google Sheets, and creative visualisation with online infographic applications (Fotopoulou, 2020). In the absence of targeted development, open learning and public pedagogy approaches make resources available to improve public awareness and reflexivity about the social implications of data and algorithmic systems. Lewis and Stoyanovich (2021), for example, devised a series of comics to deepen public understanding of ethics in big data, algorithms and AI. Web-based tools may also assist with the building of data literacy (Sander 2020). In Sander's study, available resources include interactive guide, multimedia website, infographics, audio story, short video tutorials, documentary, recorded talk, video quiz, game, text-based information and other types of tools and resources. These tools can supplement workforce training gaps; however, as we show in our case studies below, they are not necessarily effective by themselves without participatory action and intervention.
From these applications of participatory methods for building data capability, we take a similar focus on non-profit data settings and emphasise: (1) hearing and being able to respond iteratively to local knowledge and specific contexts for data practices; (2) creative and translational processes that use visualisation, media and interfaces in creative ways to connect with diverse participants; and (3) collaboration and self-enabling data transformations are key to scaling data capability development across the non-profit sector. We draw on these key elements of participatory methods in designing our two case study projects, detailed in the remainder of this paper.
Two case studies: Situating and developing data literacy and collective data capability
We developed and applied a set of methods for understanding and addressing data capability gaps and needs through two linked research projects, in collaboration with 20 non-profit organisations and 28 participants. Participating organisations for project 1 were recruited through the research team's networks and through snowball processes in 2020. Project 2 participants were recruited via an invitation to a research workshop at a conference focusing on technologies for non-profit organisations run by Infoxchange (digital equality non-profit) in May 2021. There were no specific criteria for inclusion in either project, other than an expressed interest in building organisational and individual data capability.
The research design was informed by strategies gleaned from existing participatory methodologies, with the two projects taking an iterative and situated approach that builds capability through ongoing involvement in embedded data projects, generating and knowledge and capabilities and collaborative capacity within the organisations. Our evaluation and analysis of this approach is based on interviews with participants throughout the two projects, and through collaborative data exploration and co-design workshops. The project methods target the underlying data inclusion issues affecting non-profit organisations (whether small, medium or large), in their specific contexts to account for domain-specific, situated perspectives on data capability.
Project 1 was a pilot, funded by Lord Mayor's Charitable Foundation, a philanthropic foundation that supports non-profit organisations to create positive social change. Project 2, funded by Australian Government research funding, is ongoing, with an expanding participant base, designed to map and build data capability in the non-profit sector over time. The projects apply participatory methods differently, but both were designed to assess, stage and scale-up data capability for the sector, ultimately aiming towards tools that can be effectively applied without researcher intervention. Table 1 provides an overview of the specific participatory methods used and the capability building strategies for each project, informed by the theoretical frames of situated and critical data literacy and expertise.
Data capability methods and strategies.
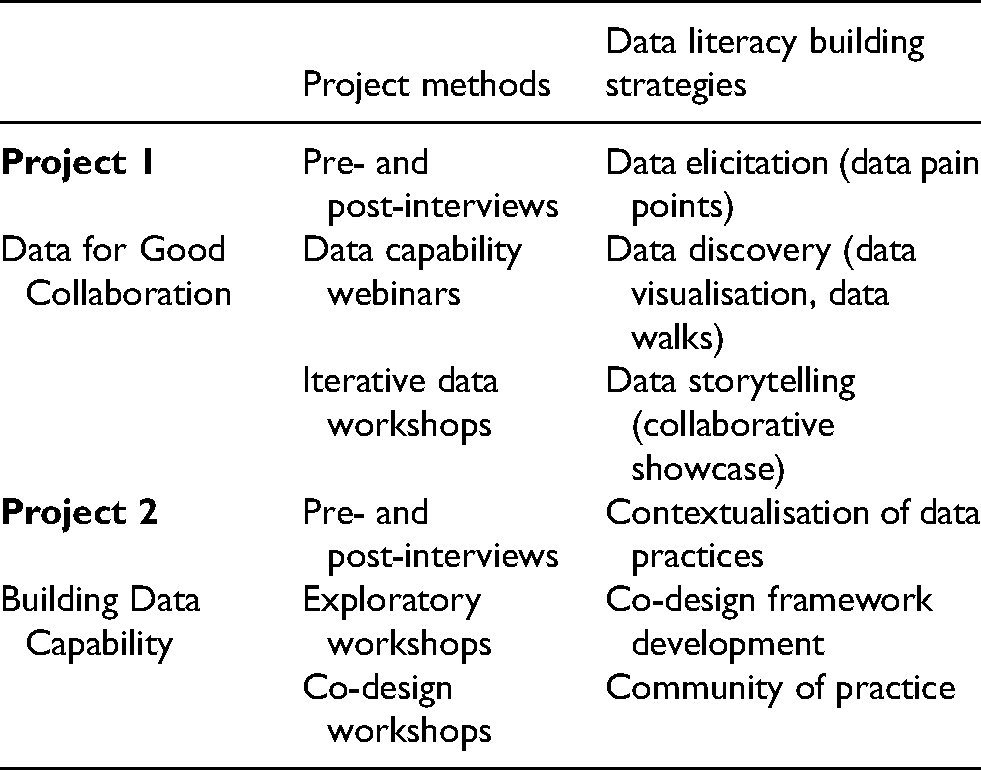
Project 1. Data for Good: Iterative and collaborative data exploration and analysis
The Data for Good project aimed to explore and build data analytics capability with three non-profit organisations (Albury et al., 2021). Our team worked collaboratively with Yooralla (Y), a large disability support organisation, Entertainment Assist (EA), a small organisation that delivers mental health support and training in the entertainment industry, and Good Cycles (GC) a small-to-medium social enterprise addressing youth unemployment and disadvantage, all based in Melbourne, Australia.
We worked with 13 individuals within the three organisations to collaboratively produce data analysis outputs. The project took place from 2020 to early 2021, and the interactive workshop-oriented methods set out for the project required modifications due to lengthy COVID-19 lockdowns in the city of Melbourne (Figure 1). This involved running workshops via Zoom, using a ‘virtual whiteboard’ (a live Google Doc) to gather input from participants and share data analysis and visualisation for group discussion. Interviews were likewise carried out via videoconferencing platforms.

Iterative data workshops: data elicitation, discovery and deliberation.
The project involved three main research activities: (a) an educational webinar series tailor made by the research team and attended by a group of participants from each organisation; (b) an iterative co-design workshop series involving data analysis and insights; (c) and pre-and post-project interviews. In between these interactive sessions, the research team conducted exploratory data analysis and investigated additional open data sources to offer new data insights for each organisation. As noted in Table 1, these research activities were designed strategically to build data capability collaboratively throughout the project, alongside the delivery of data analysis outputs. Partner organisations were responsible for identifying relevant internal datasets and ensuring these were de-identified according to the Australian Privacy Act Cth 1988, and in line with the team's institutional ethics requirements.
The educational webinar series was developed to familiarise participants with foundational concepts about data analytics and data collaboration relevant to the non-profit sector. Five webinars were pre-recorded by the research team, with supporting resources and recommended readings ensuring, for example, those core concepts were discussed and defined, and legal requirements relevant to the project noted. The webinar resources introduced data projects, explored data ethics and governance, outlined data collaborative methodologies and shared a technology toolkit. A final capstone webinar in February 2021 brought all project participants and the research team together to share project findings and insights. In this way, the webinars complemented the collaborative workshops (see Figure 1).
We recognised early on that data literacy resources alone would not be enough to make a difference with the three organisations, or adequately address their specific context and situations. As noted in our review, there are extensive online resources for developing critical and operational data literacy (Sander, 2020; D’Ignazio and Bhargava, 2015), along with any number of open or paid online data science courses. However, post-interviews with participants reiterated that these were the least effective mode of capability development. Some did not feel they had the time to work through them alongside the co-design workshops and regular workload; and while some noted the benefit of links and additional materials, these were used mainly for checking legal and governance issues or exploring open datasets rather than for skill-building. Nonetheless, the webinars and other information were considered valuable as accessible information and learning resources and for ‘socialising’ data practices within the organisation. As one participant noted, the webinar support materials would be useful for ‘some directors of ours, however, that perhaps hadn't engaged with data in a business context before’ (Alex, EA).
The three-stage collaborative workshop series involved staff from each organisation working with members of the research team over a period of 3–6 months in an online workshop format. Several methodological strategies were used throughout the workshops. The workshops created space first for attention to local knowledge and context through an exploration of what we called data ‘pain points’ – referring to the existing challenges organisations faced in all aspects of working with their own organisational data and generating effective insights or demonstrating impact or innovating through collaboration and generative data projects. The first workshop took an elicitation approach, using prompts and a virtual whiteboard to establish these key challenges, and to identify and discuss datasets, and provide direction for analysis between workshop 1 and 2. As one participant enthusiastically reflected, ‘it was very much a discovery session the first one’, ‘trying to elicit an understanding’ of the organisations’ data needs and challenges (Imran, GC).
These processes of elicitation were important for working towards a shared language, or literacy, around data use and outcomes, in a way that is not simply imposed by the research team, helping to create buy-in through sensitivity to their organisational mission and community or clients’ needs. A common language emerged by collectively taking stock of how participants spoke about data, about its value and how they worked with it. For example, one group wanted to better understand and do more with the data collected in response to service incidents logged by its frontline disability workforce and clients, and to look for patterns in that data over time. Defining incidents as data, and rethinking how incidents were categorised helped to establish some new approaches to analysis and insights that could better pinpoint ways of understanding these incidents and aligning training with them more directly. Another group had large datasets tracking the bike trips and activities of their trainees and wanted to better show the carbon footprint savings that work accrued over time. Linking city governance categories of carbon savings to the trip and activity data renewed value in the data captured for those activities.
Building on the ‘data walk’ methods pioneered by the Urban Institute (Murray et al., 2015), the second workshop involved each group exploring and responding to the detailed display of initial data analysis and visualisation. Because participants had varied roles in their organisation, with different levels of technical or strategic involvement in data collection and analysis, a range of different responses were elicited through the first two stages. The iterative process and involvement along with the way related to our discovery strategy, and this resonated strongly with participants: The really useful thing about the workshops is that we were discussing the interpretation of any of the data points as we went and discussing not just the interpretation but how would we group things, how would we classify things so that we can make it meaningful (Lindsey, GC).
By the time of workshop 3, the emphasis was on organisational context, sense-checking and application, with the strategy of data storytelling. Participants from the smallest organisation, working with minimal data noted the potential: ‘I was really heartened by the impact shift that could be measured and how that was conveyed through [data] presentation’ (Bonnie, EA); ‘really one of the key take-aways for me is that you don't often need much data, if you’re asking the right questions, to get some useful business insights.’ (Alex, EA). Part of the challenge of working towards those insights for these participants is ‘not knowing what you don't know’, and they saw collaboration as key to breaking down those uncertainties.
For all participants, but particularly the larger organisation, collaboration was a key theme and ambition of the iterative workshop and data walkthrough methods. Data collaboration was explicitly addressed in the workshops and in the webinar support materials in line with emerging approaches that seek to ‘match real life problems with relevant expertise and data’ (Susha et al., 2018: 1). Given the focus was on each organisation separately, the wider sense of data collaboration remained an aspirational part of the project. However, the participatory data capability building approach and methods highlighted different aspects of collaboration as a surprising finding, particularly in respect to bridging the ‘silos’ of internal organisational unit and role collaboration around data collection and use. For example, bringing people together from different parts of the organisation meant: ‘having a more collaborative approach within my own organisation rather than being quite siloed in the way that we look at our data’ (Ash, Y). One participant was explicit about the need to overcome these internal barriers to collaboration: [The project] connected the two teams like we haven't had yet. While it's a connection that seems really, like it would have happened already, it hadn't and I think that it's really great that we’ve now made that connection. (Stephanie, Y)
These processes and strategies align with many of the goals of the emerging participatory methods for building data capability. We saw the importance of responding explicitly to the specific contexts, local knowledges and roles of those working with data. In particular, the iterative process allowed input from people with different data roles and experiences. The translational processes involving the iterative use of data visualisation the methods, even where they had to shift to wholly online, enabled connection with diverse participants from each organisation. Feedback suggested that more work was needed to sustain and scale data capability development within these organisations, and more widely across the non-profit sector. This is the focus of the strategies adopted in Project 2.
Project 2. Building data capability and collaboration in the non-profit sector
The second project – Building data capability and collaboration in the non-profit sector – aimed to assess the sector's capacity to apply data analytics and automated decision-making technologies (see Yao et al., 2021 for initial reporting and findings). Participatory methods were designed firstly to contextualise data practices, establishing more depth of information on the varied data settings, and secondly to co-design, test and evaluate a data capability and collaboration framework informed also by national and international data-use principles and best practices relevant to the sector. We adopted a participatory design that consists of three phases of research activities (see Figure 2). This project is ongoing (2021–2023) and emphasises the need for sector-wide mapping of data practices, within Australia, as well as globally.

Contextualisation and data capability framework co-design phases.
Phase 1 involved scoping discussions (through a research workshop) and interviews centred around organisational context and availability of data infrastructure, issues and challenges with data use, literacies and expertise, as well as goals and visions for applying data analytics and automated decision-making systems.
For the purposes of explaining the participatory methods and associated data capability-building strategies, we focus here on the first phase of initial discussions in relation to a workshop with 12 participants, and seven individual interviews. These discussions offered insights into why and how our participants sought to build their own and their organisations’ data capability – and where some of the challenges and hopes lay. This helps to confirm the key elements of our participatory data capability building approach and inform future research insights. Later phases of the project and associated activities focus on contextualising organisational data practices and capabilities, while working with participants to embed data capability building and collaboration practices in specific organisational contexts. Together, the research activities work to open pathways for improved internal organisational data practices and establish avenues for data collaboration and innovation across the sector in the form of communities of practice.
First-stage interviews with participants established interests and challenges in building data capability and collaborating across the sector to improve data management, use and outcomes. An important theme across all the organisations was developing data capability to enhance organisational ‘benchmarking’. Participants saw this as vital for understanding the potential of data and automation, and as a mode of data-driven collaboration in the sector. One participant had a set of benchmarking questions he wanted to be able to address by collaborating with others or by using open or public datasets: Because it's nice to know where else everyone else fits, especially not-for-profits. And how do we relate? Are we doing a good job or are we not? Are we on the IT curve? Where are we on the IT curve? What other options are available? Is there anything else that can be shared between not-for-profits, rather than just going our own way, developing our own systems? Are there any recommendations for technology, [or] for data analytics? (IT manager, Adult education)
Connecting with a larger group of non-profit sector data and technology professionals offered our participants a way of achieving some level of benchmarking, knowledge sharing and potential collaboration.
The research benefit in taking a participatory approach lies in the rich access to the data settings, and the insights revealed about the varied data competencies among participants with different organisational roles, as well as a shared willingness to find innovative ways to build data capability. This work is happening in the face of low resourcing, usually driven by one or two key and self-motivated people who have moved into a data management and analytics role. And it happens typically in contexts of uneven infrastructural systems and underutilised, inadequate or new technologies. One participant conveyed a sense of uneven and inconsistent data practices and pointed to the need for a whole of organisation approach: What's happened is the staff work across different sites. They’ve come up with their own way of capturing information, which doesn't necessarily adhere to the policy and guidelines that – again, we are at a very early stage of putting together these guidelines and policies in place that talks about information management and a governance structure as well. (Manager, data management and analytics, Youth support and advocacy service)
As with Project 1, the implied notion of data collaboration embedded in these discussions included both inter- and intra-organisational processes, systems and labour, as well as the potential use of external data sources, and the idea of developing wider data collaboration within the sector. Along with these lines, and as part of the attraction and benefit of participatory methods is the strong interest in being part of a kind of community of practice (Wenger, 1999) for capability development and updates. As one participant explained: ‘I’ve always had an interest in capability building in the sector, and I do really like that this framework is being developed’ (Data and digital manager, Youth support and advocacy service).
Many participants in our study reflected that they are in the early stages of developing data capability in their organisation, describing a range of challenges including lack of resourcing and skills, and incomplete, inadequate or fragmented data infrastructure, systems and tools. Each also recognised that norms and practices are still emerging. One participant saw this as a core rationale for developing sector-specific guidance that can address the specific needs and contexts of different non-profit organisations, especially as they differ from those of private enterprise and the public sector. Codifying or tailoring data capability advice and options would be of significant benefit, ‘whether it's in terms of frameworks or even if it's just a logical way of understanding some of these issues in a neat package’: Almost any guidance would be useful, and so it can be generic enough in a way to cover off on a lot of different types of organisations because there's really, from what I’ve looked at, there's certainly very little that I can see that feels codified and that could just be because it's such an emerging and changing space. (Data insights and learning manager, Rural and regional development service).
Working towards data transformation within the sector and in diverse organisational settings involves some level of codification, as this participant put it. That is, developing a shared language of data practice not driven by commercial imperatives but reflective of the social value and impact of civil society work, through collaboration and self-driven processes as a pathway for scaling data capability across the sector.
Discussion and conclusions
Data equity can be achieved in part at least by building data capability in the non-profit sector context, where organisations and individuals already seeking to generate social value outcomes. These data settings are important for understanding the evolving data divide shaping the way data are produced and used, and who benefits in the process. By cultivating data capability with non-profits, we can counter the often-misplaced priorities of private enterprise data applications and rethink data practices for social good outcomes. Our case study projects contribute to a methodological toolkit that can aid these processes and work towards new forms of ‘collaborative data action’ (cf. Williams, 2020), ideally involving self-sustaining communities of responsible data practice. In the Australian context, there are some promising signs but still a long way to go.
Through our two case study projects, we saw the potential in mobilising a range of participatory strategies, involving, firstly, hearing and responding iteratively to the specific needs and situations of organisations. Secondly, creative and translational processes that use data visualisation and interfaces effectively are essential for connecting with diverse participants with different kinds of data expertise. And thirdly, collaborative processes (both within organisation and intra-organisation) are needed to scale data capability development across the non-profit sector. This approach explicitly seeks forms of collaborative data action over competition, data as a social good rather than a proprietary resource to be extracted and exploited.
Taking a situated, participatory approach, we identified and further developed three key elements of current participatory approaches to building non-profit sector data literacy. Our case study projects employed several strategic approaches, as part of a set of participatory methods, to achieve these three elements. This involved creating spaces and techniques for iterative data elicitation to explore data pain points or challenges and identify relevant datasets, data discovery to gain responses to data visualisation using data walks, and helping the groups work towards context-aware data storytelling. Building on these methods, we also saw the need to contextualise non-profit data practices, through engagement with a broader set of organisations and situations, and by fostering a community of practice co-design to embed a data capability framework.
Typically, participatory data events – the data parties, data hubs, data walks and other data literacy building approaches – are flexible in the variety of activities as well as length and timing needed to best suit the participants and their needs for data-related skills. They can make data more accessible to non-data experts and empower communities to develop individualised interpretation of data and targeted solutions to local problems. Generally, they work to bring individuals and citizens together with organisations to develop data solutions or explore data insights.
As Williams (2020) argues, they are about community investment in the potential social value of data. However, at the heart of these approaches, there is often an ‘ideal’ data citizen in mind. Such approaches would be most effective when used with participants with shared interests, when the data can be visualised relatively easily, and when workshop participants are able to develop a shared language and clear understanding of what can be achieved collaboratively using data. However, by targeting the ideal data citizen, these techniques and methods sit outside of the organisational data settings where we argue more substantial change and collaborative data action can be achieved. By targeting data settings and the data goals and practices of the non-profit sector, our aim is to embed data capability where it can be sustained and be better aligned with community needs.
A recent report by Infoxchange, a digital solution provider supporting Australian non-profits, identifies improvements in six capability areas of digital technology within the sector: information technology, digital infrastructure and systems, social media presence, workforce skills and organisational culture and risk management (Infoxchange, 2020). Despite this, the report concludes that Australian non-profits are not yet prepared for advanced data analytics for automated futures. Although it would be unrealistic to assume that a single series of workshops or activities could be sufficient to train the workforce to perform advanced data analytics, participatory activities are crucial for enabling the non-profit sector to better engage in policy discussions and advocacy around big data while they experiment in expanding data analysis and begin to deploy automated systems.
Collaborative, participatory approaches can help to address data equity and inclusion in a way that complements more ‘top-down’ regulation or policy responses. Local discussions about open data and data sharing have sought community input, with the government inviting responses to the recent publication of the Data Sharing and Release Legislative Reforms Discussion Paper (Commonwealth of Australia, 2019). However, non-profit organisations have not been the target of capability-building policy and in our projects focus more on compliance than with innovation and cooperative data practices and data sharing.
An important goal of widening data literacy and participation is to include the subjects of organisational data practices where these are service users and clients. A high-level framework for doing this has been developed recently by Ada Lovelace Institute (2021), but this model of ‘participatory data stewardship’ also needs to be translated to actual sites and settings in response to local knowledge, expertise, needs and resources. Although our studies and interventions are limited to Australian non-profit data settings, these settings offer a useful space to consider digital and data transformation away from dominant European and US contexts. Comparative work is needed. The Australian non-profit sector provides a site for experimentation and innovation in data practices, outside of corporate sector competition and at an arms-length from direct government intervention. Nonetheless, comparative work across a wider range of settings globally including the global south will deepen knowledge about the global impact of the digital and data divide.
Finally, establishing key measures of data capability as indicators of data equity can be a longer-term goal of using participatory methods to understand the situated data literacies and overall data capability of non-profit organisations. Practical measures by data capability non-profits have emerged in the form of data maturity assessment tools (see Data.org in the USA, and Data Orchard in the UK). Our findings and similar work can contribute to widening the evidence base on the state of data capability in different national and local contexts. This in turn will help to map preparedness and pathways for responsible and effective use of automated decision-making systems built on those data practices. In this work, we are seeking to drive sustainable data capability in the non-profit sector to address data equity, to help inform how researchers can contribute to building wider circles of collaborative data action.
Footnotes
Acknowledgements
The authors wish to thank our additional research collaborators in the two case study projects: Amir Aryani, James Kelly, Julie Tucker, Sandun Silva and Jihoon Woo.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Lord Mayor’s Charitable Foundation, ARC Centre of Excellence for Automated Decision Making and Society (grant number CE200100005).