
Abstract
As the use of automated social media analysis tools surges, concerns over accuracy of analytics have increased. Some tentative evidence suggests that sarcasm alone could account for as much as a 50% drop in accuracy when automatically detecting sentiment. This paper assesses and outlines the prevalence of sarcastic and ironic language within social media posts. Several past studies proposed models for automatic sarcasm and irony detection for sentiment analysis; however, these approaches result in models trained on training data of highly questionable quality, with little qualitative appreciation of the underlying data. To understand the issues and scale of the problem, we are the first to conduct and present results of a focused manual semantic annotation analysis of two datasets of Twitter messages (in total 4334 tweets), associated with; (i) hashtags commonly employed in automated sarcasm and irony detection approaches, and (ii) tweets relating to 25 distinct events, including, scandals, product releases, cultural events, accidents, terror incidents, etc. We also highlight the contextualised use of multi-word hashtags in the communication of humour, sarcasm and irony, pointing out that many sentiment analysis tools simply fail to recognise such hashtag-based expressions. Our findings also offer indicative evidence regarding the quality of training data used for automated machine learning models in sarcasm, irony and sentiment detection. Worryingly only 15% of tweets labelled as sarcastic were truly sarcastic. We highlight the need for future research studies to rethink their approach to data preparation and a more careful interpretation of sentiment analysis.
Introduction
Sentiment analysis has seen significant and widespread applications in various domains ranging from national security and crisis response (Cheong and Lee, 2011; Kumar et al., 2011; Sykora et al., 2013), brand management (Pang and Lee, 2008), business intelligence (Fan and Gordon, 2014; Goonetilleke et al., 2014), public health (Gruebner et al., 2016; Kuehn, 2015) and more broadly across our daily lives (Ilieva and McPhearson, 2018). Indeed, sentiment analysis is a popular and recurring element in social media studies with automated analytics (Ravi and Ravi, 2015). In this context it refers to computational techniques that allow the detection of valence, activation, as well as other emotions in sparse-text commonly encountered on social media at scale. Given its popularity and these numerous applications, a substantial effort by the information retrieval (IR) and natural language processing (NLP) communities has been dedicated to developing techniques, algorithms and approaches to detect affect more accurately in social media messages (Pang and Lee, 2008; Ravi and Ravi, 2015). Due to the prevalence of conducting sentiment analysis on large unstructured user generated content, accurate detection poses a challenge (Phan et al., 2020). Nevertheless, limitations on text length imposed by most social media and microblogging services such as Twitter arguably do nothing to discourage creative language use such as sarcasm and irony which allow strong sentiments to be expressed effectively (Ghosh et al., 2015).
Traditional NLP tools do not consider how words can be used playfully (ibid.). Hence, figurative language use on social media and especially the use of sarcasm and irony, in witty and inventive ways, pose significant challenges to these approaches. There have been efforts to automatically detect such language use in order to help improve overall sentiment analysis accuracy. Despite some relatively successful attempts in automated sarcasm and irony detection (Bamman and Smith, 2015; Joshi et al., 2016a), there is a distinct gap in the understanding of data quality used in training datasets that unfortunately can significantly impact supervised or semi-supervised 1 machine learning (ML) models, which are most often used in developing these kinds of approaches (e.g., Bamman and Smith, 2015; Khattri et al., 2015; Rajadesingan et al., 2015). Another issue is the qualitative appreciation of semantic characteristics of the individual social media messages which are little understood. Hence, the primary contribution of this paper is a manual semantic analysis of over 4000 Twitter messages (1820 of which relate to 25 different topics and events, ranging from cultural events, product releases, accidents, scandals to terror incidents), providing a much needed qualitative survey of sarcastic and ironic language use on Twitter. This is in addition to the presented literature, and while our review is not systematic, crucial links are drawn with existing research efforts in computational approaches for sarcasm and irony detection. For an exhaustive systematic review of specific machine learning models and feature sets, we direct readers to Sarsam et al. (2020). One of our resulting conclusions is that prior work in this area may have falsely attributed and relied on very low quality training, validation and testing datasets 2 with automated language models. It is hoped that this paper provides a much needed re-assessment and acts as a catalyst to stimulate substantive academic discussion in this area.
The remainder of this paper is organised as follows. The next section introduces background and relevant theory on sarcasm and irony as well as an overview of automated approaches for their detection, and a brief introduction to sentiment analysis. The subsequent section presents the manual semantic annotation analysis of two Twitter datasets, establishing the prevalence of sarcastic and ironic expressions on Twitter; not previously reported across such a varied dataset. The penultimate section provides a discussion and reflections on findings, issues and suggestions for potential future direction of research. The paper is finally concluded with conclusions.
Background, prior work and theory
Irony and sarcasm are subtle figures of speech that can be traced back to ancient Greece, even preceding the philosopher Socrates, who used irony to illustrate his views (Lee and Katz, 1998). Smith (n.d.) draws upon definitions and explanations given by socio-psycholinguists such as Fowler (1965), Kreuz and Glucksberg (1989) and Gibbs (2000), to finally arrive at this definition; “Irony and sarcasm are used to portray meanings that differ from the literal meaning of an utterance; many times this can be an opposite or hyperbole”. Sarcasm unlike irony is an aggressive and often hostile type of humour (Norrick, 2003). Specifically, Norrick (ibid.) classified conversational humour into four types: (1) jokes, (2) anecdotes, (3) wordplay and (4) irony, while sarcasm and mockery do not fall under any of these four categories as they can be found across all four. The Oxford English Dictionary defines “irony” as “the funny or strange aspect of a situation that is very different from what you expect” and “sarcasm” as “a way of using words that are the opposite of what you mean in order to be unpleasant to somebody or to make fun of them” (OED, 2020). Although irony and sarcasm are very closely related, they are hence distinctly different, with sarcasm being a more aggressive form of humour.
Expressions of sarcasm and irony within social media posts pose major challenges to real-world applications of established sentiment analysis techniques. In their literature review on sentiment analysis, Ravi and Ravi (2015: 14) highlight that “ambiguity and vagueness have been considered as major issues […]” especially with regards to challenges of “sarcasm (mock[ing] or convey[ing] irony), rhetoric [and] metaphor”. Ghosh et al. (2015: 1) state that such language “allow[s] strongly-felt sentiments to be expressed effectively, memorably and concisely […]” although “NLP tools […] do not take account of how words can be used playfully and in original ways”. This is a significant issue for automated techniques and the accurate assessment of creative language use, which is prevalent across social media platforms. Although there is a genuine lack of studies reviewing the prevalence of the above issue, Maynard and Greenwood (2014) have tentatively suggested that sarcasm alone may possibly account for as much as a 50% drop in accuracy when detecting sentiment automatically. Unfortunately, they (ibid.) did not clearly evidence this claim and only considered 134 tweets with a #sarcasm hashtag dataset. As we will illustrate in ‘Prevalence of sarcasm and irony: A manual semantic analysis’ section, a drop in accuracy for sentiment analysis is due to human communication involving expressions where the author may mean to convey the opposite of what he/she is communicating, and effectively transforming the polarity of the detected sentiment.
Given the potential impact on sentiment analysis and related automated methods, work in this area deserves careful attention. In the field of sentiment analysis, this has not received the level of scrutiny one may expect; for instance, in their comprehensive sentiment analysis review, Ravi and Ravi (2015) only found four papers on the topic out of over 160 reviewed articles. Similarly, Yadollahi et al. (2017) do not mention sarcasm and irony at all, despite proposing a useful nuanced taxonomy for sentiment analysis tasks, they do not acknowledge the potential role of humour (such as sarcasm or irony) in sentiment analysis. In fact, studying public mass media, Puschmann and Powell (2018) show how the framing and public expectations around analytical capabilities of sentiment analysis are often misinterpreted and overly optimistic, (p.9) […] public perceptions of sentiment analysis attribute qualities and capabilities to sentiment analysis that diverge from how this method has been developed and refined in practice. […] This connects with a broader shift toward a perception of feeling as something to be computationally grasped.”
Sarcasm
The social context is crucial when interpreting sarcastic comments (Katz and Lee, 1993). Ducharme (1994) states that sarcasm promotes “group solidarity”, while Gibbs (2000) finds that sarcasm is used to “vent frustration”, a tool that Twitter is often used for. For instance, Kim et al. (2011) found that Twitter users bonded over expressing sympathy, worry and frustration. Consider the examples from trending British tweets about tax avoidance (see ‘Method’ section for dataset details) from early April 2016 in Table 1.
Example tweets on tax avoidance (i.e. from early April 2016).

Most psycholinguists agree that a sarcastic utterance typically has a target. Davidov et al. (2010) found that because of Twitter’s context-poor and unstructured nature, it is not always possible to easily identify the targets sarcastic comments are aimed at. In the above examples, the hashtags are an apparent indicator that leaves little doubt as to what/who the sarcastic tweet is aimed at. Text-based user generated content (UGC) is potentially quite limiting to sarcasm detection, at least compared to other modes of communication such as video or spoken language, where visual and acoustic cues significantly help distinguish such utterances, for instance speech features including speech rate, and other contextual cues including laughter (Cheang and Pell, 2009; Tepperman et al., 2006). With increasingly more multimedia-based social media content, there may arguably be some future potential in multi-modal ML approaches.
Riloff et al. (2013) were the first to attempt to leverage recognising contexts that contrast a positive sentiment with a negative activity or state to detect sarcasm in social media posts (e.g., “Great, how exciting that I have to see my dentist today … having my tooth taken out”). Their approach was based on the intuition around sarcasm that arises from the contrast between a positive sentiment referring to a negative situation, where the challenge is to recognise the stereotypically negative situations that are generally considered undesirable and unenjoyable. Of course, such situations are context sensitive and depend on a person's demographics and social network. Riloff et al. (2013) did not pursue the latter contexts, but they did propose a rule-based classifier looking for positive verb phrase followed by a negative situation with a custom set of learned phrases achieving a 0.7 precision score, although recall was extremely low – 0.09 – with a very poor overall F measure of 0.15. The final proposed system was an ensemble of this rule-based approach and an SVM (support vector machine) model combined, which achieved a respectable F score of 0.51 (precision 0.62, recall 0.44), showing that such an approach could have some success.
Rajadesingan et al. (2015) exploits behavioural traits from a user’s past tweets, in addition to lexical and linguistic cues. In a similar approach, Khattri et al. (2015) also apply ideas from Riloff et al. (2013) and propose a classifier based on contrast-based identification and a historical tweet-based model that identifies if the sentiment expressed towards an entity in the target tweet agrees with sentiment expressed by the author towards that entity in the past. Comparing their approach against the same datasets that Riloff et al. (ibid.) used, Khattri et al. (2015) achieved an F score of 0.83 (precision 0.84, recall 0.81), which is a substantial improvement. Their work primarily shows that making use of text other than just the one believed to contain sarcasm, by leveraging historical text-based features within a supervised sarcasm detection framework, is a promising approach. Bamman and Smith (2015) also explore contextual features and point out that they may aid in accurately identifying sarcasm, providing a useful overview of some complex features, some of which were found to perform well in model training. However, it is questionable how efficient their approach would be in terms of running-time and memory footprint, as it likely would not perform well under real-time running requirements, or large volumes of data, hence making these features altogether impractical for larger 3 social media datasets. The authors (Bamman and Smith, 2015) point out that users with historically negative sentiments tend to have higher likelihoods of sarcasm use, and some features in their approach were also based around the intuition that sarcasm is more likely to take place between people who are more familiar with each other, hence taking into account past @mention messages exchanged between users. Interestingly, in subsequent analysis, the authors (ibid.) found that the strongest audience feature predictors of sarcasm were actually the absence of mutual mentions. It is worth noting that they (ibid.) used sarcasm hashtags to generate their seed dataset, which is a method that, as we show in ‘Prevalence of sarcasm and irony: A manual semantic analysis’ section in this paper, is rather problematic.
Parde and Nielsen (2018) have shown that using sarcastic tweets (the #sarcasm hashtag) and enriching training datasets with additional annotated Amazon product review data can slightly improve the performance of automated sarcasm detection, where the F score improvements reported are 0.58 to 0.59 for tweets and 0.74 to 0.78 for Amazon reviews. Amazon-based sarcasm detection is more accurate than detection on Twitter, primarily due to longer messages.
Irony
Although irony and sarcasm are distinct from each other (see section 2), what we observed from the computational research literature is that sarcasm and irony are occasionally bundled together and used interchangeably. The reasons for this may be varied, but include some conceptual misunderstandings, similar characteristics (e.g., frequent use of hyperbole), and hence similar automated detection approaches being applicable. Also, more pragmatic considerations may play a role, such as the challenge of human annotators consistently differentiating between irony and sarcasm, hence lack of example cases of irony and availability of labelled datasets for the usually “data hungry” computational machine learning methods. In this section, we provide a brief overview of some prior work that specifically dealt with irony detection.
Reyes et al. (2009) were among the first to discuss the importance and principles behind detecting irony in terse-text
4
in order to correctly assign fine-grained polarity levels. Sarmento et al. (2009) developed a model, also based on pattern detection to locate positive and negative sentiment in Portuguese newspapers – finding that the only problems arising in their system were due to the automatic misinterpretation of irony. Carvalho et al. (2009) created an automatic system for detecting irony relying on emoticons and special punctuation in online newspaper comments. Reyes and Rosso (2011) developed a model that represents irony in Amazon customer reviews by integrating “different linguistic layers” (i.e. from simple n-grams to affective content). They (ibid.) point out the importance of correctly identifying irony because of its use in expressing opinions but acknowledge the difficulty in finding a solution to detect it, admitting that it is unrealistic to rely on a single technique or algorithm. Hence, Reyes et al. (2013) propose a multidimensional model of “textual elements”, identifying four dimensions that are found in ironic tweets; those are:
Signatures: focuses on typographical elements, capitalisations or punctuation marks that imply opposition within a text (such as having the word “love” and the word “hate” within the same sentence). Unexpectedness: examines patterns such as “temporal imbalance” which mixes different tenses and contextual imbalance that locates inconsistencies in a text. Style: monitors recurring textual sequences. Emotional scenarios: the use of emoticons to display moods or emotions.
They (ibid.) found that hashtags were one way tweeters use in order to avoid being taken literally. They annotated tweets with the hashtag #irony and compared them to tweets that were not ironic. The Monge Elkan edit distance score was used to allow gaps of unmatched characters to minimise noise from misspellings, and it is worth pointing out that such measures of text similarity 5 are generally useful across sentiment analysis tasks. Barbieri and Saggion (2014) attempt to detect irony on Twitter using the same datasets that Reyes et al. (2013) prepared. They also measure word use frequency and apply supervised ML methods; their model included word frequency, style, adjective/adverb intensity and sentence structure. They also looked at sentiments, synonyms and ambiguities in order to “distinguish irony from as many different topics as possible” (ibid.: 66). The researchers only tested their model in controlled experiments using basic linguistic tools such as WordNet, 6 and acknowledge the primary problem of disambiguation of meaning is an open problem. Barbieri et al. (2014a) adopted the same technique they had tried in their previous work, this time adding parts of speech (POS) tagging 7 to increase accuracy, and most interestingly, they tackled the issue of ambiguity, concluding that the more meanings a word has, the more likely it is to be used ironically. Barbieri et al. (2014b) adapted their previous technique to Italian tweets using a Decision Tree classifier from machine learning to detect ironic tweets. They reported an F measure improvement of 0.11 over simple baselines. Barbieri et al. (2015) adapted their model to detect satire in Spanish tweets with comparable results. Buschmeier et al. (2014) used Davidov et al. (2010)’s method of monitoring the imbalance among the polarity of terms, with the addition of taking emoticons and interjections into account and applied their method on Amazon reviews after having five human annotators decide between ironic and non-ironic reviews. Their system achieved an F measure of 0.68. Hao and Veale (2010) proposed an algorithm for separating ironic from non-ironic similes, detecting common terms used in this ironic comparison. They found that web users often use figurative comparisons as a means to express ironic opinions. A set of example ironic tweets for the hashtag #GrandNational, which is an annual British horse racing event that has received some public criticism around animal welfare (see ‘Method’ section for dataset details), are shown in Table 2. In the next section, we present our focused manual semantic annotation analysis study of sarcasm and irony across two datasets.
Example tweets on trending hashtag #GrandNational (i.e. from early April 2016).

Prevalence of sarcasm and irony: A manual semantic analysis
Using sarcasm and irony hashtags as “gold” 8 labels for training sarcasm detection systems is a widely used method (e.g., Bamman and Smith, 2015; Khattri et al., 2015; Parde and Nielsen, 2018; Rajadesingan et al., 2015; Sarsam et al., 2020). Although distant supervision-based learning was found to work well for basic sentiment classification (Hogenboom et al., 2013; Pak and Paroubek, 2010), doubts about such approaches being used for sarcasm and irony detection have been raised some time ago by Davidov et al. (2010). Hashtag-based datasets especially for sarcasm and irony may result in a high proportion of noisy data. Besides, the issue has not received any attention in related literature, and our understanding of the prevalence of sarcasm and irony within various contexts on social media is lacking. To address this, we present the outcomes of a manual semantic analysis of 4334 Twitter messages associated with (i) hashtags commonly employed by the above-mentioned prior work and (ii) relating to a selection of 25 distinct events, from a dataset presented previously by Sykora et al. (2014).
Method
The manual semantic analysis was performed by a researcher with training in linguistics and discourse analysis. The task focused on the human expert deciding whether the intended meaning of a message was sarcastic or ironic, based on the surface text of the tweet, as well as identifying commonly used types of expressions within various contexts. This was a systematic process in line with closed coding content analysis approaches, as outlined in Thelwall (2013). A manual qualitative analysis of tweets allows for a deeper understanding of the shared material, particularly where the context is nuanced due to irony and general humour, as well as the use of out of vocabulary terms, slang, abbreviations, etc. The coding strictly focused on the surface level meaning of communicated message in the tweet. The reason for this is that we are interested in the use of humour and irony within the message content itself, as word/character-based models are primarily based on such features in automated detection approaches (e.g., Bamman and Smith, 2015; see ‘Background, prior work and theory’ section). To assure reliability, as is common practice in related literature (Mahoney et al., 2019), out of all tweets across the datasets i and ii described below, a uniform random sample of (480 tweets) was also coded by the second author, resulting in virtually perfect (99%) agreement with the linguistics/discourse expert.
The analysed data consisted of two separate datasets,
9
containing Twitter messages associated with;
A set of predefined hashtags often employed in training ML models (e.g., Riloff et al., 2013, etc.), specifically, analysing a random sample of a maximum 300 messages for each hashtag on data collected via the Twitter Search API, over a one-week time period (i.e. March-April 2016), with 2514 tweets in total, namely:
[1] - #sarcasm
[2] - #sarcastic
[3] - #not
[4] - #notsarcasm
[5] - #notsarcastic
[6] - #irony
[7] - #ironic
[8] - #joke
[9] - #humour
[10] - #funny
(ii) A random sample of 1820 tweets, sampled directly from a collection of 1,570,303 tweets retrieved via the Twitter Search API on 28 separate datasets relating to 25 unique events (65 random tweets from each of the 28 datasets were selected). An overview of this data and the dataset itself is discussed in more detail, including its emotional properties (derived using the EMOTIVE sentiment analysis system) within Sykora et al. (2014).
#Sarcasm, #irony and #joke hashtag use
The primary output from the manual analysis of the 10 hashtags (dataset i) from Twitter is presented in Table 3.
Overview of hashtags-based tweets often employed in training ML models.

The annotation criteria for the dataset from Table 3 to be considered as ironic, sarcastic or humorous were strictly focused on the communicated message and the associated semantics, including any additional hashtags, other than the indicative hashtag used for the collection (e.g., #sarcasm, #ironic), which was purposefully ignored. #notsarcasm and #notsarcastic both have less than 300 tweets as the terms were not prevalent and not as many results were returned through the Twitter search API. From the table, it is evident that the proportion of actually sarcastic expressions in the sarcasm-related category was a low percentage of only 14.89% of the messages. To unpack the characteristics of these tweets further, a brief qualitative discussion of each category of messages; sarcastic, ironic and humorous from Table 3, to illustrate their use (all taken from the dataset i), follows below.
Consider the example message from the dataset;
RT @__user__: Free #healthcare? This man Bernie Sanders is a communist, just like Canadians. #FeelTheBern #DemDebate __url__
#Trying to be a #GoodWomen in a #World where #BadB's get all the #credit … #Not Made for this #World!! #Jesus
Example tweets collated using the #not hashtag as a distant learning sarcasm indicator.
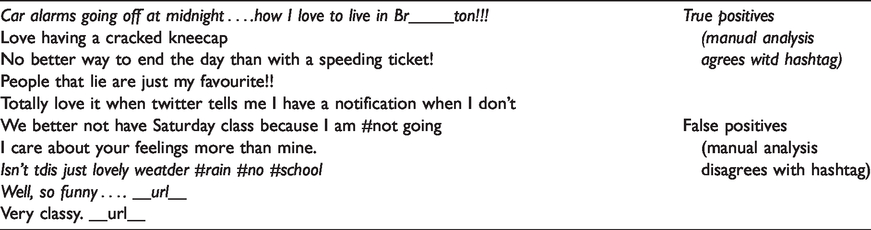
Irony was considerably more prevalent with its associated hashtag, than sarcasm (i.e. 28% vs. 14.89% in Table 3). Several examples of typical ironic expressions are illustrated with tweets presented in Table 5. However, the high proportion of actual ironic tweets is partly due to a trending topic in the dataset with a high proportion of retweets, example tweet below;
Example tweets collated using the #ironic and #irony hashtags as indicators of irony.

RT @__user__: Flight 787 of Royal Brunei lands in Jeddah, piloted by an elite crew who are not allowed to drive there. #Irony __url__
Table 3 also shows statistics for #irony-related tweets once messages regarding the Flight 787 were ignored, which still contained a high prevalence of ironic tweets (34% for #irony). However, in the dataset of tweets based on the #ironic hashtag, this Flight 787 message did not take hold at all, and the sample contained a fairly well-balanced random collection of topics, which still showed a high proportion of 24% actual ironic tweets, compared to an average of 14.89% actual sarcastic tweets for #sarcasm, #sarcastic and #not (i.e. right column in Table 3).
For comparison, we conducted the same study on humorous tweets collected via the #joke, #humour and #funny hashtags, it is apparent that a significant high proportion of tweets include links, without the surface text of the message itself being funny. Overall only 4 tweets were genuine attempts at jokes (i.e. Table 6) out of all 900 of tweets (i.e. the research associate was liberal in annotating this category as content that only remotely resembled an attempt at a humorous expression/joke would be counted as such).
Example tweets collated using the #joke, #humour and #funny hashtags as indicators of humour.

The interesting characteristic of this particular category of the dataset (i.e. tweets collected from #joke, #humour and #funny) is that out of 900 tweets in total 720 contain url links (80%). This highlights the observation that in particular with humorous Twitter content, analysing the surface text of tweets is going to miss substantial context. Techniques that analyse embedded media, including url links with potentially media and rich context, are hence needed to deal with such expressions. In contrast, out of the 900 tweets associated with #sarcasm, #sarcastic and #not, 374 tweets (41.56%) contained url links. For the 600 tweets on #irony and #ironic, this was 297 (49.50%), and out of the 114 tweets for #notsarcasm and #notsarcastic only 16 (14.04%) contained a url link to an external resource, while on average these tweets were found to contain sarcastic content more often than the other hashtags (i.e. Table 3).
Event-related tweets
We conducted the analysis of dataset (ii) which consisted of 1820 Twitter messages on a broad range of heterogeneous, randomly chosen topics; some trending in the United Kingdom and others trending internationally. The aim was to provide an indicative overview of the prevalence of sarcastic, ironic and general humorous messages within fairly “standard” social media use, across wide range and types of topics and events in the English language. In previous work, Riloff et al. (2013) reported that out of 1600 random tweets obtained from the streaming Twitter API that did not contain a sarcasm hashtag, only 29 (1.8%) were judged to be sarcastic by their human expert annotator. In our random event-based approach, we found an even lower proportion of such expressions. Out of 1820 tweets, only 20 (1.09%) were either sarcastic or ironic, with sarcasm expressions in 14 and irony in only 6 distinct messages. There were only 28 tweets containing other types of humorous content.
Given the significantly smaller proportion of such language-use, this is in stark contrast to dataset (i) with messages where a sarcasm or irony hashtag was included (i.e. Table 3), pointing to some relative usefulness of the #hashtag heuristic with this type of content being more likely. Table 7 presents an overview of all the 28 different datasets with the count of distinct tweets with sarcastic, ironic and humorous language highlighted in the three right-most columns. The emotional variables associated with tweets from this events dataset (i.e. Sykora et al., 2014) allow us to tentatively explore potential associations with humour, sarcasm and irony. Spearman’s rho correlation over all the 28 datasets highlights a potential yet weak relationship between (absolute) emotionality of tweets and the likelihood of humorous content (rho = 0.131). This would be consistent with Rajadesingan et al. (2015) who found that there was a higher probability of users using sarcasm when they were in an emotionally charged “mood”. Sarcasm was potentially positively correlated with irony (rho = 0.278) and humour (rho = 0.284), while humour was, as expected, negatively correlated to irony (rho = −0.234). However, none of these correlations were actually significant at p (two-tailed) < .05; keeping in mind recent concerns around drawing premature conclusions from non-statistically significant p-values (Amrhein et al., 2019), these results are at most indicative of potential associations and need to be interpreted cautiously.
Overview of the analysed datasets, with frequency information on sarcasm, irony and humour over a random sample of 65 tweets for each event, and the related event description.
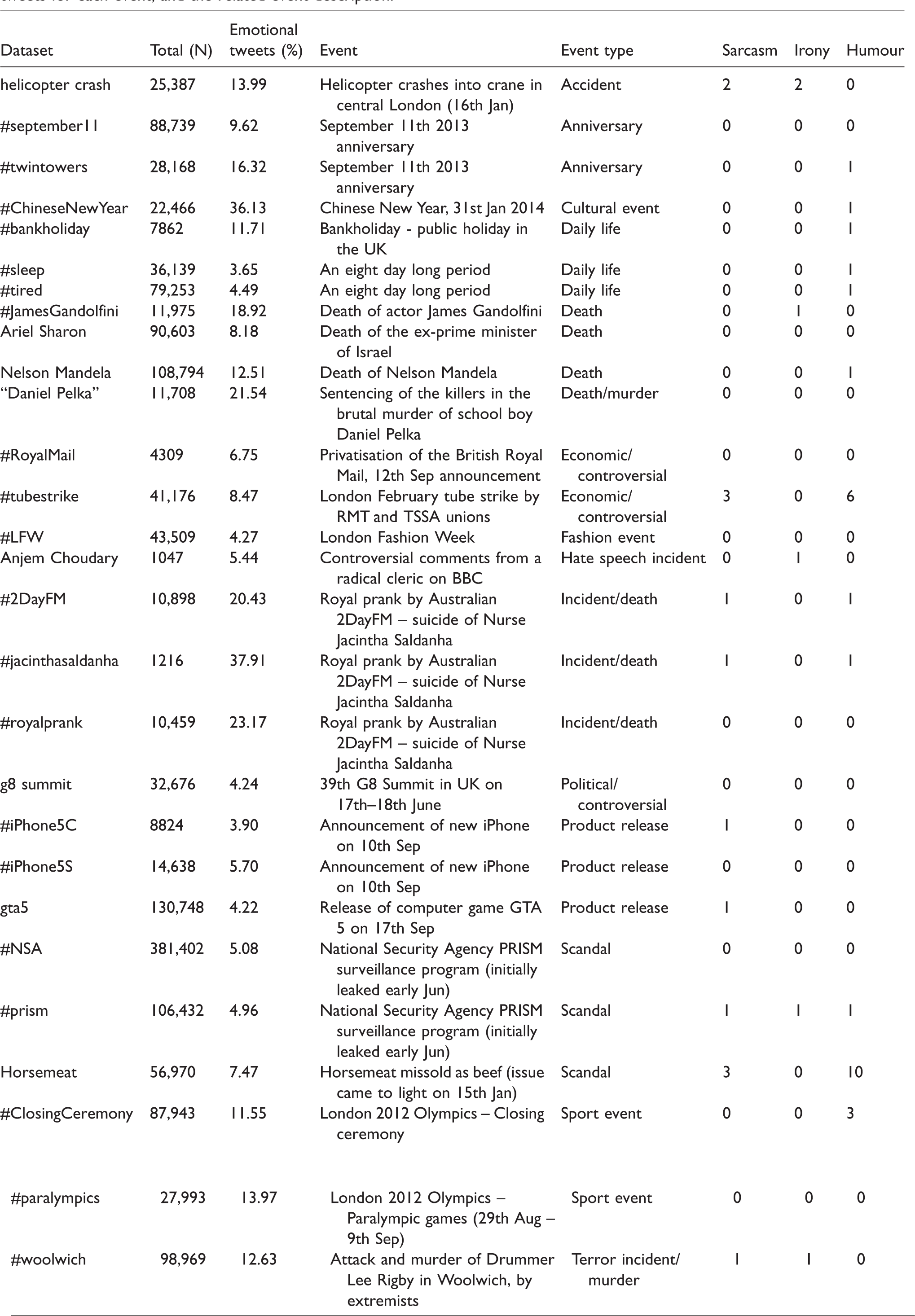
Several important observations can be drawn from results in Table 7. For instance that #horsemeat and #tubestrike both contained a high proportion of humorous language, 10 (15.38%) and 6 (9.23%), respectively. These are by far more prevalent than even tweets tagged with a hashtag implying humorous language from dataset (i), which indicates that certain events evoke humorous content much more frequently. As was highlighted in ‘Prevalence of sarcasm and irony: A manual semantic analysis’ section, a widely accepted theory of humour proposes that it is a tool used for coping, and both these events were particularly significant in that they (potentially) affected a large population in a (likely) negative way. Both these events also had the highest proportion of sarcastic tweets in their respective samples of tweets. The results also indicate that events centred around deaths of well-known individuals and the tragic murder of Daniel Pelka contained no sarcasm nor irony, except for one ironic message associated with #JamesGandolfini, “Why is it that nice things are never spoken of when the person is alive, but only after their death? #JamesGandolfini”. Hence, it is possible that depending on the nature of events, there may be scope for identifying likely types and styles of irony, sarcasm and/or humour. However, further investigation over larger corpora of events and topics on social media would indeed be needed to validate such a hypothesis.
Discussion
Based on the outcomes of our presented analysis we need to highlight two primary observations, some related issues, as well as limitations associated with our study’s method, and suggestions for future work. An intriguing qualitative observation around the role of multi-word hashtags, which has not been covered in prior research, is also discussion in detail within section ‘Multi-word hashtags in sarcasm and irony use’.
First from analysis of the hashtag marker-based dataset (i) we can conclude that the proportion of genuinely humorous, sarcastic and ironic surface-level content in such tweet messages is generally very low. Although semi-supervised learning has been applied with some success on large datasets across range of problems where labelled data were not readily available (Zhu and Goldberg, 2009); given our findings across commonly employed hashtag markers, this observation has implications for such automatic approaches. The assumption that linguistic features that are indicative of humorous, sarcastic and ironic messages can be leveraged when in reality this is hardly the case, is hence worrying. Social media messages, especially from strictly character restricted platforms such as Twitter, are of primary concern, given their often short sparse nature and lack of context. This is to some extent empirically illustrated in the work by Parde and Nielsen (2018), where sarcasm detection over Amazon reviews, compared to Twitter, is substantially more accurate due to the longer length of content and hence richer context available to the sarcasm detection model. Another implication stems from our observation of a very high proportion of url links (80%) seen among humorous tweets, as well as sarcastic (41.56%) and ironic tweets (49.50%). However, our study was strictly limited to the surface-level semantics of a tweet and we did not explore the linked url content. Therefore, little can be said with certainty regarding the url linked content, but it is indeed possible that at times all or part of the humorous, sarcastic or ironic message was embedded within such linked sources. Especially given the low frequency of surface-level humour in tweets and their relative high proportion of url links is intriguing. Despite this, the majority of current approaches in sentiment analysis and automated sarcasm/irony/humour detection still do not support non-textual modalities of data analysis, nor their linked textual content (Ravi and Ravi, 2015; Sarsam et al., 2020; Yadollahi et al., 2017). Studying such content in tandem, and techniques that analyse embedded media or potentially rich multi-modal and textual content from url links, referred to in tweets, would seem to be a worthwhile area of further future work.
The second set of observations based on our analysis of dataset (ii) confirms an exceedingly low proportion of sarcastic content, just over 1%, as previously reported by Riloff et al. (2013) across typical, large collections of topics on Twitter data. Although Riloff et al.’s (2013) dataset consisted of randomly collected tweets, and our own consisted of a random selection of mostly UK-based events, we confirm this result, and we additionally find that the prevalence of sarcasm, as well as irony and humour, can vary significantly across different types of events and topics. We report on events ranging from scandals, product releases, cultural events, to accidents and terror incidents. While most of the 28 datasets reported here, do not show any more than 1.5–2% of such language use, in line with Riloff et al. (ibid.); for some events, the prevalence of humour and sarcasm was found to be much higher, in range of 6–20%, for the London helicopter crash, tube strike and the Horsemeat scandal. What this likely means in practice is that most of the time, across large cross-topic datasets, sarcasm, irony and the use of humour may be much less of a concern as is generally thought (Puschmann and Powell, 2018); yet, the performance of sentiment analysis and related tools will strongly depend on the specific topic or event covered and discussed on Twitter. This is similar to findings from work by Ribeiro et al. (2016), who reported how performance of twenty-four state-of-the-art sentiment analysis tools is highly context sensitive, and varies significantly across different datasets, even when these are from the same social media platforms. A natural limitation of our study is the small size of the analysed dataset, while still larger than prior work; in future work, we plan to substantially extend the variety and number of events/datasets. The extent of the annotation effort could also be increased. This will allow to undertake a more substantial analysis across the types of events and topics to evaluate their nuanced characteristics that are likely to evoke more humour, sarcasm or irony on Twitter. Such bottom-up empirical research is important across social media platforms in order to further our understanding around the nature of discourse and properties of events and themes that are likely to elicit conversations with higher levels of humour, sarcasm or irony, and its implications for sentiment analysis being taken into account.
There are also cross-cultural considerations. For instance, Joshi et al. (2016b) present early empirical work illustrating some differences between what various cultures consider to be sarcastic on social media. Sarcasm and irony detection in different cultural contexts and especially non-English languages have been quite rare, with only a few exceptions, such as work in Dutch by Liebrecht et al. (2013), Italian by Barbieri et al. (2014b) and Spanish, again by Barbieri et al.(2015). Due to the sensitive nuanced nature of language and culture specific differences in figurative language use, multi-lingual issues pose an interesting future research area, also echoed in Abulaish et al. (2020), especially when it comes to the use of humour, sarcasm and irony; and how these empirically differ across populations.
Multi-word hashtags in sarcasm and irony use
Multi-word hashtags, such as #suckedass (see section ‘#Sarcasm, #irony and #joke hashtag use’) pose a problem for sarcasm and irony detection. Zappavigna (2015), who has conducted one of the most detailed linguistic-based analyses of hashtag use on Twitter to date, suggests that the issue is that hashtags are not only used to help organise social streams by their topic, but have a more experiential and social function, such as “#soawesome”, “#Ihatemornings” “#ff” (i.e. follow Friday – used to mention accounts worth following). This poses issues in practice as the semantic context is not straightforward to interpret for most sentiment analysis and automated analytics tools. Generally, hashtags can be considered to be a form of metadata (i.e. data about data) embedded within the social media message and have meta-semantic value, effectively a sort of meta-commentary. They may also have a limited lifetime, such as for instance #ObamaCare, which relates to a health-care system reform by the ex-US president and remains short-lived only while public debate around this political issue remains. Interestingly new hashtags can sporadically evolve and emerge (Maity et al., 2015), such as #ObamacareWorks. Zappavigna (2015: 277) points out that [.] #ObamacareWorks while opportunistic is an example of meta-evaluation used to emphasize a particular political perspective and perhaps also to rhetorically imply that there is an ambient audience of microbloggers who agree with the point being made (and who might potentially search for or use this otherwise idiosyncratic tag).
Hard to believe summer is almost done. And school is right around the corner.
Yah no worries, just dump your load of mulch in the middle of the road
Future work
We believe that future research of automated tools may benefit from carefully considering such concerns, and a promising future direction may well be the development of semantic models in the form of knowledge bases. Hee et al. (2018) have specifically shown how introducing knowledge bases of common-sense, also known as general world-knowledge semantics, can significantly improve performance in detecting irony (in their case achieving a respectable F-measure of just over 0.7). Indeed, an error analysis of misclassifications for automated sarcasm detection by Parde and Nielsen (2018) highlights three particular issues and areas for future work; (i) introducing models of world or common-sense knowledge to help detect sarcasm/irony, (ii) better approaches to normalising text, such as splitting up compound hashtags into individual words, to ultimately improving performance of sentiment detection approaches by appropriately reversing the polarity of detected sentiment, and (iii) issues around evolving language and slang on social media pose a continued challenge. These three future research challenge areas directly relate to also addressing the multi-word hashtag issue we have pointed out above. The fourth (iv) challenge area will be how to effectively resolve the temporal sense associated with complex hashtags and expression over certain specific time periods and individuals/community of users, where the meaning behind certain language use may be very specific to certain social network of users, or individuals.
Conclusion
This paper reviews core approaches to automated detection, the issues and actual prevalence of humorous, sarcastic and ironic language use within social media posts, in order to further understand and help researchers interpret and potentially mitigate the effects on sentiment analysis techniques. The main contribution of this paper is observations from a substantial semantic analysis of over 4000 social media posts. Within our analysis, we also explore 25 events and topics, from a random sample of 1820 tweets, taken from a large 1.5 million tweet dataset collection, across a range of events including, scandals, product releases, cultural events, accidents and terror incidents. Our findings highlight the lack of genuine use of sarcasm, humour and irony with certain hashtag markers. For instance, hashtags like “#sarcasm” are not necessarily good indicators of sarcasm. Machine learning models for automated sarcasm and irony detection, as well as related performance of sentiment analysis tools are likely to be impacted by this observation, as these are often trained on training data of hence highly questionable quality and little qualitative appreciation of the underlying data. We further highlight the contextualised use of multi-word hashtags in the communication of general humour, while focusing specifically on sarcasm and irony. After reviewing the state of the art, we found that most sentiment analysis systems simply fail to recognise such hashtag-based expressions. A study that qualitatively investigates surface meaning of humour, sarcasm and irony use over a sizeable set of tweets was until now missing. We believe our findings are of importance to the research community for academics that use and apply, as well as develop, such tools.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.