
Abstract
In this review, I analyse how ‘behaviour-based personalisation’ in insurance – that is, insurers’ increased interest in tracking and manipulating insureds’ behaviour with, for instance, wearable devices – has been approached in recent social scientific literature. In the review, I focus on two streams of literature, critical data studies and the sociology of insurance, discussing the new (i.e. health and life) insurance schemes that utilise sensor-generated and digital data. The aim of this review is to compare these two approaches and to analyse what kinds of understandings, methodologies and theoretical perspectives they apply to so-called ‘behaviour-based insurance’. The critical data studies literature emphasises the exploitative aspects of these new technologies and mobilises behaviour-based insurance to exemplify the negative outcomes of digital health. Scholars from the field of the sociology of insurance empirically analyse the practices of behavioural-based personalisation and study how regulating and ‘doing’ insurance affect attempts to personalise it. I highlight the importance of approaching insurance as a specific financial technology and argue that more research is needed to understand the practices of developing behaviour-based insurance schemes and the insureds’ experiences.
This article is a part of special theme on Insurance Personalization. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/collections/personalizationofinsurance
Introduction
The idea of using wearable technology and (big) data analytics in insurance has gained increasing attention in the latter half of the 2010s. Even large insurers, such as John Hancock, have explored the possibilities of incorporating self-tracked data – for example, data generated by activity wristbands and smart watches – into their policies (Sullivan, 2018). Actors from insurance and tech sectors see these kinds of ‘insurtech’ solutions as disruptors in the insurance market. Some argue that they transform insurance transactions, and perhaps the whole business, from impersonal to more personalised (McFall and Moor, 2018). In the insurers’ and tech companies’ visions, self-tracked data can be looped back to customers to ‘nudge’ their actions (see Thaler and Sunstein, 2009). More specifically, policies aim to manipulate customers’ behaviour and increase customer engagement by incentivising safe and healthy habits (Falkous and Callaway, 2018). Furthermore, the data could be used in risk calculations and predictive underwriting to offer ‘tailor-made and therefore particularly profitable policies’ (Wiegard et al., 2019: 64). These kinds of solutions that aim at both product and price personalisation (McFall and Moor, 2018) are examples of behaviour-based personalisation in insurance – a process where ‘markets and services are increasingly focused on the behaviour and lifestyle of actors’ (Meyers, 2018: 117).
Behaviour-based personalisation, specifically in the case of health and life insurance policies, can be seen as part of the larger hype around digital health. The expectation is that new digital technologies and extensive data sourcing will enable personalised medicine and lead to better health outcomes and cost efficiencies (Swan, 2012). For instance, wearable devices may help users to gain control of their health and generate savings in health care costs (Swan, 2012). Thus, their implementation in different institutional settings, such as insurance and healthcare, has gained significant interest (Becher, 2016; Lupton, 2016; McCrea and Farrell, 2018). The field of digital health, or ‘mHealth’, has been extensively analysed and criticised by social scientists, who focus on ‘datafication’: ‘the conversion of qualitative aspects of life into quantified data’ (Ruckenstein and Schüll, 2017: 262). Researchers have analysed the emergence of new kinds of data assemblages (Hogle, 2016) and mundane engagements with ‘data doubles’ (Ruckenstein, 2014). They have also discussed inequalities within digitised health, highlighting the asymmetric relations between the ‘data rich’ (e.g., corporations, institutions and governments) and ‘data poor’ (individuals) and the negative feedback loops that algorithmic systems can create (Andrejevic, 2014; O’Neil, 2016; Van Dijck, 2014).
Behaviour-based personalisation in insurance (or so-called ‘behaviour-based insurance’) has also been subject to such research. In particular, critical data studies and the sociology of insurance have discussed these new policies. First, the critical data studies literature highlights the exploitative aspects of behaviour-based insurance. Most of these studies consider the amalgam of insurance and self-tracking technologies as a dystopian version of the ‘wearable dream’ embodying the dark side of the ‘metric culture’: dataveillance, discrimination and exclusion (Ajana, 2017; Christophersen et al., 2015; Lupton, 2016). These oftentimes Foucauldian-inspired studies conduct little empirical analysis on existing behaviour-based insurance policies, but they employ them to represent the negative aspects of datafication. Second, scholars from the field of the sociology of insurance highlight the importance of approaching insurance as a special context for developing personalised solutions. With its practices of risk pooling and underwriting, ‘insurance as we know it’ (Meyers, 2018) is both a collectivising and an individualising technique (Ewald, 1991). A similar dynamic is at play with personalisation – alongside individualising practices, it constitutes a relation between a person and a reference group (Moor and Lury, 2018). Thus, the insurance studies examine how personalisation changes the practices of risk selection and pricing, or if it changes them at all, and whether the logic of algorithmic personalisation (Lury and Day, 2019) can be combined with statistical conceptions of risk (McFall, 2019). These studies employ perspectives from science and technology studies (STS) and engage in empirical analysis.
In this review, I map the social scientific research analysing the use of wearables and digital data in (private health and life) insurance. I aim to compare the literature streams I introduced above and propose possible directions for future research. I begin by presenting the methodological tools I used for the analysis and my literature selection process. Then, I discuss the critical data studies literature and analyse what kinds of understandings, methodologies and theoretical approaches its contributors take towards behaviour-based insurance. After this, I review research from the sociology of insurance to highlight how a deeper understanding of insurance technology could help to illustrate the limits and possibilities of behaviour-based personalisation. Finally, I conclude by arguing that even though STS-inspired insurance studies enable more precise and constructive criticism, further empirical analysis on insurance providers’ practices of developing behaviour-based policies and on users’ experiences is needed.
Methodology
To find the relevant literature discussing behaviour-based insurance policies, I conducted searches in the Social Science Database (ProQuest) and Sociology Source Ultimate (Ebsco) using the following search commands: self-tracking, life-logging, ‘quantified self’, self-tracking AND insurance, wearables AND insurance, ‘wearable devices’ AND insurance, ‘wearable technology’ AND insurance, ‘quantified self’ AND insurance, datafication AND health and datafication AND insurance.
These searches resulted in a corpus of 503 potential articles. Based on abstracts, I excluded articles that were obviously not related to the research topic, book reviews, short commentaries and letters to the editor. This resulted in 291 articles for the full-text phase. After reading the full text, I excluded all the articles that did not discuss insurance. I then combined the results from the two databases and removed duplicates, leaving me with 58 articles. I snowball-sampled 34 additional articles with reference tracking. This yielded 92 articles for thematic analysis. Thematic inquiry led me to exclude 19 papers due to differences in theoretical approaches and thematic discussions, including 11 (public) health, health ethics and psychology papers; seven computer science papers; and one law paper. The final selection comprises 73 articles.
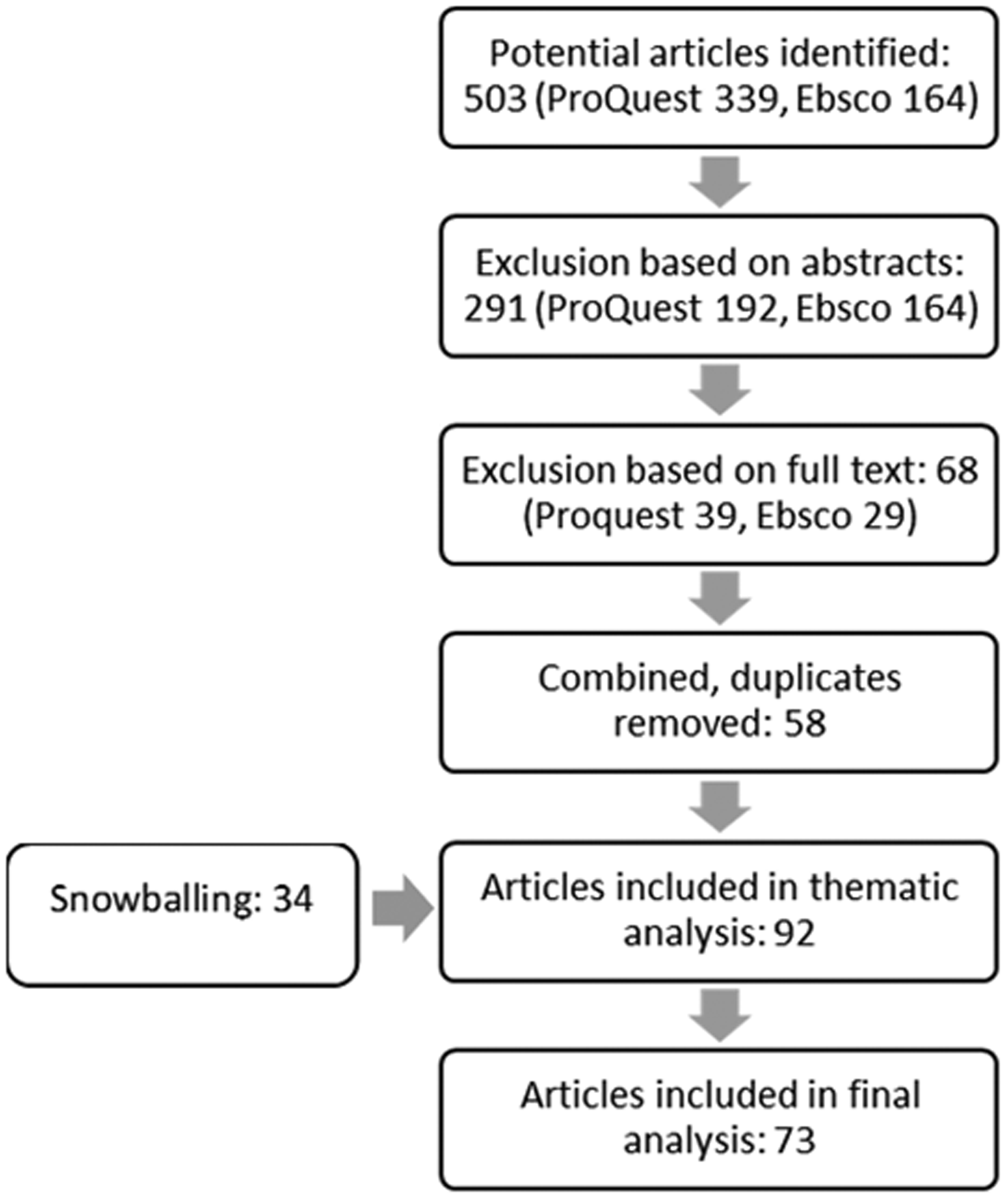
Behaviour-based insurance is closely related to questions of digital health; thus, I used Ruckenstein and Schüll’s (2017) classification of different literature clusters that study the datafication of health as a methodological tool. This helped me to recognise the various themes discussed in the articles and identify their main theoretical and methodological approaches. Most of the articles (55 papers) seemed to represent what Ruckenstein and Schüll (2017) call the ‘datafied power approach’, what is also called ‘critical data studies’ (Iliadis and Russo, 2016) or ‘critical digital health studies’ (Lupton, 2014). Many of these papers were Foucauldian-inspired, employing the concepts of biopolitics and neoliberal subjectification (Foucault, 1986, 1991) and concentrating on the matters of responsibilisation, surveillance and exploitation. Some of them, however, also drew from neo-Marxist critical social theory, discussing neoliberalism, unwaged labour and surveillance capitalism. I review these papers in the first part of the analysis.
The second-largest group (18 papers) resembled what Ruckenstein and Schüll (2017) termed ‘living with data’ or ‘data-human mediations’, as these papers were empirical and/or they employed theoretical insights from STS. This group included STS-inspired insurance studies that discussed behaviour-based insurance and applicable empirical studies concentrating on self-tracking practices. Here, I also included two review papers with no obvious theoretical emphasis. I discuss these studies in the second part of the analysis. Overall, there was not a clear difference between the two approaches in terms of the journals in which the articles were published. Many of the critical data studies articles appeared in Surveillance & Society, but other than that, papers from both clusters were published in journals such as New Media & Society, Big Data & Society and Philosophy and Technology.
Critical data studies and the sociology of insurance are not completely separated, as both streams of literature are inspired by Foucauldian research traditions (and some of the critical data studies scholars, too, draw from STS perspectives). Many earlier sociological studies of insurance employed governmentality perspectives to study insurance as way of governing society (Castel, 1991; Dean, 1999; Defert, 1991; Ewald, 1991). Later, these neo-Foucauldian approaches were used to explore the themes of responsibilisation and exclusion and the ways in which the insurance industry worked by embracing risk (Baker and Simon, 2002; Ericson and Doyle, 2004; Ericson et al., 2003). More recently, this tradition has been continued in the pragmatist stream of literature, employing insights from STS and contributing to the field of the sociology of markets (Callon et al., 2007). These studies approach insurance as a form of knowledge production and follow the various human and non-human actors participating in doing insurance (McFall, 2014; Van Hoyweghen, 2007). In this review, I focus more on these newer STS-inspired insurance studies, as behaviour-based personalisation is analysed using these perspectives. However, I discuss some of the classical neo-Foucauldian insurance studies in the second part of the analysis to highlight the importance of understanding insurance as a particular financial technique.
Insurance in critical data studies
Here, I analyse how the critical data studies literature approaches behaviour-based insurance. First, I discuss the different themes that are apparent in the body of research I examined. Even though many of the themes are intertwined, I have categorised them into three sections to ensure analytical clarity: (1) dataveillance and privacy issues; (2) responsibilisation, discrimination and exclusion; and (3) prosumption, unwaged labour and surveillance capitalism. Second, I discuss the theoretical and methodological approaches utilised in the literature and situate them in the larger field of the datafication of health and healthy citizenship.
Dataveillance and privacy issues
A recurring theme in the literature is that digital technologies enable novel ways of surveillance – or ‘dataveillance’. Instead of being ‘watched from above’, the datafication of new spheres of life submits people to the continuous and distributed monitoring of their behaviour (Van Dijck, 2014). Behaviour-based insurance is used as an example of this kind of logic. Insurance companies, alongside other institutions utilising data, are discussed as constantly tracking peoples’ digital traces (e.g., Hardey, 2019: 1002; Lanzing, 2019: 563; Lupton, 2016; Lupton and Michael, 2017: 255; Maalsen and Sadowski, 2019: 121; Phillips, 2015: 58; Sanders and Sheptycki, 2017: 5; Zuboff, 2019). Thus, insurance is seen as a part of a larger trend in which people are being monitored and externally incentivised, pushed or even coerced to engage in self-tracking in both public and private institutional contexts such as higher education, healthcare and the penal system (e.g., Elias and Gill, 2018; Lupton, 2014, 2016; Rich and Miah, 2017: 91). These institutions taking part in digitised health surveillance are seen as comprising the ‘public health surveillant assemblage’ that reinforces normative understandings of health and disciplines people who do not conform to them (Sanders, 2017: 44).
The critical research raises questions considering data privacy and users’ possibilities to manage their data flow. According to the literature, in the current ‘data-sharing culture’, users of self-tracking devices have little control over the movements of their data (Ajana, 2017: 9–11; Crawford et al., 2015: 490). Scholars fear that aggregated data, such as social media data, medical records and data from health apps, could be sold to third parties such as insurers, resulting in privacy issues and exploitative practices (Cinnamon, 2017: 614; Crawford et al., 2015: 490; Harkens, 2018: 22; Lanzing, 2016: 13; Lupton, 2015b: 448; Smith and Vonthethoff, 2017: 8). Ajana (2017: 11) argues that in societies where health services are increasingly being privatised, ensuring data privacy is crucial to preventing ‘a total transfer of power from individuals and communities to organisations and industries, such as insurance and pharmaceutical companies’. However, because the insurance industry’s right to collect data is often seen as a basic requirement for its operations, the effect of, for instance, the EU’s General Data Protection Regulation (GDPR) could be limited because it only regulates data use, not collection (Couldry and Yu, 2018: 4474). Thus, protections based on traditional notions of ‘privacy’ (such as informed consent) might not be enough to address this continuous tracking (Couldry and Yu, 2018: 4486).
Responsibilisation, discrimination and exclusion
The critical research asserts that behaviour-based insurance is a way of making the insured more accountable for their everyday actions and health. The policies are considered to be a neoliberal technique that promotes the responsible and productive entrepreneurial self, and they are contested for their lack of attention to the social, cultural and political aspects of health behaviour and digital technology use (Ajana, 2017: 4; Charitsis, 2016: 52; Fotopoulou and O’Riordan, 2017; Lupton, 2015a; Welhausen, 2018). Several studies employ US-based workplace wellness programmes, usually created by health insurers, as a descriptive example of the tendency to increase people’s responsibility for their own health and to normalise certain kinds of bodies and lifestyles (Crawford et al., 2015: 494–495; Elman, 2018: 3766–3767; Harkens, 2018: 22; Hull and Pasquale, 2018; Sanders, 2017: 44). By incentivising ‘healthy’ behaviour, users are trained not only to produce data for the companies to utilise but to produce the right kinds of data to prove that they are mastering their own well-being (Charitsis, 2016: 52, 2019: 140). However, it is suggested that the incentivisation of ‘healthy’ behaviour only draws attention away from the fact that insurers (and employers) have little real concern for customers’ health and a great interest in using their data for profit (Gidaris, 2019: 137; Hull and Pasquale, 2018: 191).
In addition to responsibilisation, behaviour-based insurance policies are seen to tamper with their users’ autonomy. For instance, the (financial) incentives and ‘nudges’ that insurance-related workplace wellness programmes offer are regarded as a violation of people’s decisional privacy and deliberative autonomy, as they interfere with users’ freedom to make their own decisions (Lanzing, 2019: 558; Owens and Cribb, 2019: 33). Moreover, people may have little room to opt out of wellness schemes, even though the rhetoric of ‘choice’ is often employed (Gabriels and Coeckelbergh, 2019: 126; Lupton, 2016: 113). For instance, people who refuse to self-track might be considered as inadequate employees, or they might face higher premiums (Lupton, 2017: 4). Thus, policies might result in ‘unforeseen challenges’ such as discrimination against and the exclusion of employees who do not want to engage with them (Christophersen et al., 2015: 291–292; Hull and Pasquale, 2018; Maturo and Setiffi, 2015: 489).
Furthermore, new insurance schemes are believed to have the potential to differentiate between customers and personalise premiums. The continuous streams of personal data could allow them to calculate more accurate, or even personal, premiums with real-time rate adjustments (Zuboff, 2019: 214). This kind of personalised pricing might affect conceptions of reciprocity and solidarity, as individualised risk assessment and pricing ‘make possible discriminations that were not detectable previously’ (König, 2017: 4–5). Consequently, behaviour-based insurance policies could create troublesome feedback loops, produce new categories of difference and reinforce existing inequalities (Ajana, 2017: 13; Cinnamon, 2017: 616; O’Neil, 2016: 167). For instance, policies may exclude people with disabilities, as wearable devices only track specific parameters of exercise, such as steps (Elman, 2018: 3766–3767). Therefore, people with ‘bad’ risks, such as illnesses, or people with less resources–who are most in need of insurance – may ultimately not be able to access or pay for policies (Lupton, 2014: 615–616, 2016: 113; Nissenbaum and Patterson, 2016: 89; O’Neil, 2016: 167).
Prosumption, unwaged labour and surveillance capitalism
Finally, critical researchers discuss the ways in which insurers use the data generated by new digital technologies to yield larger profits. This exploitation of customers’ data is discussed in terms of prosumption, (digital) unwaged labour and surveillance capitalism (Charitsis, 2016, 2019; Gidaris, 2019; Zuboff, 2019). For instance, it is seen that when users engage in self-tracking practices and allow their data to be collected, in a way, they are working for the companies (Gidaris, 2019: 135–136; Till, 2014: 448–451). However, even if people are given services in return for their data, they only receive a fragment of the value attributed to this work (Crawford et al., 2015: 490; Sadowski, 2019: 8). This kind of ‘prosumption’ that combines both production and consumption is seen as exploitative, as the customers are not necessarily aware of the labour they are performing, and they are not adequately compensated for it (Gidaris, 2019: 135; Ritzer and Jurgenson, 2010). Furthermore, in the case of workplace wellness programmes, policies transform employees’ leisure time and exercise into a form of unwaged labour, the purpose of which is to lower costs and enhance work performance (Till, 2014). The work day is extended through these wearable devices and activity goals, allowing employers and insurers to make extra profit (Charitsis, 2016: 52–53; Gidaris, 2019: 135–136; Hull and Pasquale, 2018: 201).
Researchers also discuss generating revenue through monitoring, predicting and modifying people’s behaviour in terms of ‘surveillance capitalism’ (Gidaris, 2019; Zuboff, 2015, 2019). In her book, The Age of Surveillance Capitalism (2019), Zuboff uses auto insurance policies utilising telematics devices as an example of this logic. She maintains that the continuous streams of data the tracking devices generate could allow insurance companies to reduce uncertainty and focus on predicting and managing individual risks (Zuboff, 2019: 214). According to Zuboff (2019: 218), the insurers’ aim is to create ‘guaranteed outcomes’ through two operations: (1) looping the data back to the drivers and (2) using it for predictive calculations. The enhanced predictability and personalised calculations of risk might then generate a ‘behavioural surplus’, as premiums could ‘rise and fall from millisecond by millisecond’, creating cost savings and efficiencies (Zuboff, 2019: 214, 217). Zuboff (2015: 85–86, 2019) sees surveillance capitalism as an exploitative and parasitic economic logic that threatens human nature, market democracy and individuals’ sovereignty. She argues that people are mostly unaware of the control and surveillance pointed towards them (Zuboff, 2019: 218).
A datafied power approach to insurance
The arguments made about behaviour-based insurance seem to comply with the general arguments in the critical data studies literature. In line with what Ruckenstein and Schüll (2017: 263–265) call the ‘datafied power approach’, insurance is discussed through issues such as dataveillance, exploitation of personal health data and objectification of bodies. In many cases, the research is Foucauldian-inspired, employing the concepts of biopolitics and neoliberal subjectification (Foucault, 1986, 1991). Some scholars seem to draw from neo-Marxist perspectives, discussing issues such as commodification of personal data and unpaid digital labour. Only a few studies analyse empirical data, but in those cases, new insurance schemes are not at the centre of the analysis. Usually, insurance is discussed along with other institutions utilising personal data and behaviour-based policies are given as examples of the possible negative outcomes of datafication and the self-tracking trend. Some articles borrow empirical examples from media texts, such as articles published in Forbes (Olson, 2014; Olson and Tilley, 2014), to highlight the recent developments in and possibilities of behaviour-based personalisation in insurance (e.g., Charitsis, 2016; Fotopoulou and O’Riordan, 2017; Lupton, 2015a, 2016; McEwen, 2018). Generally, the literature is not empirically well informed about Big-Data-enabled personalisation in insurance. The focus is predominantly on the US, context where the Affordable Care Act (ACA) (2010) has encouraged the use of preventive measures and health technologies in insurance and health care (Hull and Pasquale, 2018). This might lead to biased assumptions about Big-Data-enabled personalisation in insurance, as scholars overlook cases outside the US, where the markets and legal frameworks might be different.
The datafied power approach has been criticised for its lack of empirical attention to the different agencies and goals at play (Ruckenstein and Schüll, 2017: 265). It has also been challenged for being speculative, for configuring the users of wearable devices in unrealistic ways and for ignoring the users’ everyday experiences (Sharon, 2017: 116). Because of its strong emphasis on the exploitative aspects of datafication, the datafied power approach rarely considers cases of ‘noncompliance, appropriation and existential possibility’ (Ruckenstein and Schüll, 2017: 265). This is problematic, as it might reinforce traditional ideas of certain values, such as understandings of individual autonomy as a lack of constraint, while it disregards practices and modes of reasoning that do resist the dominant order (Sharon, 2015: 296, 2017: 106). From an STS perspective, overlooking the viewpoints of the actors involved could make the critique alienating, as it enables critics to occupy a position in which they are always right (Latour, 2004: 239–240). To avoid this, it could be useful to conduct analyses with a ‘realist attitude’ and to consider the historical situatedness, complexity and diversity of the research objects (Latour, 2004: 231). Hence, an STS- or practice-based approach to self-tracking and behaviour-based insurance could help researchers to study users’ experiences, formulate alternative questions and consider how values are enacted in specific practices (Sharon, 2017: 108, 116).
Insights from the sociology of insurance
In this section, I discuss how different aspects of insurance technology limit and enable the creation of behaviour-based insurance policies. Although I am focusing on the insurance and self-tracking literature that utilises STS approaches and engages in empirical analysis, I also discuss select classic neo-Foucauldian insurance studies in the first part of my analysis to achieve a precise understanding of what ‘insurance as we know it’ is and how insurance functions – or used to function. Thus, I begin by discussing how the basic mechanisms of insurance conflict with the idea of personalised risks and premiums. Second, I analyse how regulation affect the scope of insurers’ actions. Third, I demonstrate how the outcome of behaviour-based insurance depends on the practices of doing insurance.
Understanding insurance
‘Insurance as we know it’ is a collective mechanism for mitigating risk. Insurance standardises uncertain harmful events, assigns monetary value to them and distributes payment responsibility (Ericson et al., 2003: 5–6; Ewald, 1991: 201–205). In actuarial calculations, statistical methods are used to objectify uncertainty to predictable risks (Ewald, 1991: 201–202; Knights and Vurdubakis, 1993: 730). Insurance only tackles the ‘insurable risks’ enacted in these calculations – that is, calculable harmful events that cause financial losses and occur randomly in a pool of people (Ewald, 1991: 201; Insurable Risk, 2018). Consequently, risks can only be calculated on a population level and are always collective (Ewald, 1990: 146). Following this, insurance is a collective mechanism in which a group of people facing the same risk covers the occurrence of that risk for the ‘pool as a whole’ (Lehtonen and Liukko, 2015: 158). Because of this, all insurance schemes entail a practical form of solidarity (Lehtonen and Liukko, 2011: 33).
Both the insurance and the tech industry’s visions and critical commentaries of these prospects presume a move from this collective model to more personalised enactments of risk, as they believe that behavioural data can override the reliance on traditional group classifications (Becher, 2016; Zuboff, 2019). However, as the concept of risk is inherently collective, it is questionable whether ‘individual risks’ can exist, or whether determining risk at an individual level is anything else but guesswork (McFall and Moor, 2018: 198). Consequently, self-tracked data could perhaps be used in risk calculations, but it should be embedded into the insurance infrastructure to produce meaningful outcomes (McFall, 2019: 55). Thus, using digital data would likely align with the underwriting practices already taking place in insurance.
In a way, individualisation is nothing new in insurance, as ‘insurance as we know it’ both creates collectives and distinguishes members by their probability of risk (Dean, 1999: 30; Ewald, 1991: 203). In the underwriting process, a specific probability is determined for every member of the collective using calculative devices such as health questionnaires (Van Hoyweghen, 2007, 2014). The premiums, however, do not vary according to individual qualities, but instead they rely on specific group characteristics (McFall, 2019: 54). Thus, even though insurance individualises risk, it is individualisation that is relative to the other members of the collective (Ewald, 1991: 203).
The underwriting process is not a straightforward technical measure. Studies using STS approaches suggest that alongside actuarial calculations, insurers consider other things, such as marketing and customer relations, when determining premiums (Van Hoyweghen, 2014: 338–339). Thus, underwriting is not an exact science but the outcome of several combined factors (McFall, 2019: 54; Van Hoyweghen, 2014: 346–347). Similar logic is at play in the behaviour-based insurance policies currently on the market. For instance, the Vitality franchise of Discovery Ltd rewards its customers with bonuses, gift cards and promotional deals if they reach high enough activity levels (McFall and Moor, 2018: 206; Vitality Corporate Services Limited, 2019). Offering bonuses, however, is not the same as using behavioural data to determine and price individual risk; thus, the Vitality scheme resembles a retailer loyalty programme more than a new way of calculating risk (McFall, 2019: 70; McFall and Moor, 2018: 198).
Furthermore, it is unclear whether insurance based on ‘individual risks’ would be operational – or whether it would be considered insurance at all (McFall, 2019: 70). Insurance technology spreads risk among a pool of insureds who ‘join their resources to face future uncertainties’ (Lehtonen and Liukko, 2015: 157). This spreading of risk is vital, as it ensures profitability for the insurance company and constitutes insurance as an efficient form of security for the customers (Lehtonen and Liukko, 2015: 157–158). It differentiates insurance from personal savings and has been used to distinguish insurance from gambling (Lehtonen and Liukko, 2015: 157; O’Malley, 2004: 109–110). For (behaviour-based) insurance to be secure or profitable without risk spreading, companies’ operational models must be renewed. Interestingly, many visionaries of behavioural-based personalisation are not insurers, but they are ‘interested actors’ such as tech and consultancy firms (Meyers and Van Hoyweghen, 2018: 128). Therefore, a radical shift in practices seems unlikely, as the insurance business is famously inert to change and is cautious of reputation risks (McFall and Moor, 2018: 198).
The critical analyses, however, rightly point to the limits of insurance solidarity. As people with similar characteristics are pooled together and increasingly detailed risk classifications are conducted, someone is always left out (Lehtonen and Liukko, 2011: 39, 2015: 165). Thus, insurance creates exclusion alongside inclusion (Lehtonen and Liukko, 2015: 156). The neo-Foucauldian insurance studies have examined the topic of exclusion extensively and suggest that insurance generates ‘gated communities of risk’ by skimming off the most profitable populations, favouring ‘responsible’ people and using ‘redlining’ tactics to exclude certain underprivileged areas deemed high risk from their schemes (Baker, 2002: 39; Ericson et al., 2003: 227–229). This could ‘unpool’ some of the risk that insurers carry and exclude the poor and high-risk individuals while encouraging the fortunate and wealthy to have even more insurance (Ericson et al., 2000: 534–537; French and Kneale, 2009: 1030–1032; Heimer, 2002: 117). These kinds of exclusionary measures are sometimes understood as practical responses to tackle the problems of moral hazard and adverse selection. However, neo-Foucauldian scholars point out that insurance is not a neutral technology but a means of distributing responsibility and a site for constituting moral subjects (Baker, 2002; Dean, 1999; Heimer, 2002; Knights and Vurdubakis, 1993; O’Malley, 2002).
Critical data studies researchers align with these analyses, arguing that the refusal to track or the inability to conform to health ideals could lead to discrimination and exclusion from insurance (e.g., Lupton, 2016; Zuboff, 2019). However, empirical evidence on existing behaviour-based insurance policies does not entirely support this conclusion, as policies are still in the pilot stage, and their use of self-tracked data is limited (McFall, 2019: 70–71; Meyers, 2018). Instead, policies create inclusion and exclusion by trying to attract young and health-conscious customers to constitute ‘healthy’ pools (McFall and Moor, 2018: 206). This, again, is more of a marketing method than a feature of insurance technology. Still, as classifications and risk assessment are at the core of insurance, behaviour-based personalisation could lead to further discrimination (McFall and Moor, 2018: 205). Similar fears were expressed in the 1990s and 2000s during the debate on the use of genetic information in insurance (Wauters and Van Hoyweghen, 2016). In the end, many of the scenarios turned out to be exaggerated, as a lack scientific progress, public opposition and new legislation hindered insurers’ use of genomic data (Thomas, 2012; Wauters and Van Hoyweghen, 2016). Given the existing evidence, it is too early to evaluate whether insurers will take up behaviour-based personalisation and whether they can make it work (McFall and Moor, 2018: 205).
Legal frameworks
The insurance industry is a highly regulated field, with legislation targeting the practices of risk selection and underwriting (Meyers, 2018: 119). Insurers can only use ‘relevant and reliable’ data in risk calculations. Further, the use of protected attributes, such as religion, sexual orientation and ethnicity, is prohibited by anti-discrimination laws (McFall, 2019: 71; Meyers, 2018: 120). The demand for such protections stems from the question of solidarity: Who is seen as eligible for insurance, and what kinds of risks are seen as worth insuring (e.g., Lehtonen and Liukko, 2011; Van Hoyweghen et al., 2007)? Because insurance is generally understood to be an instrument of solidarity instead of discrimination (Prainsack and Van Hoyweghen, 2020), and access to healthcare is defined as a fundamental right (European Union, 2012; WHO, 2017), insurers’ attempts to narrow the risk pool have been met with critical scrutiny. In recent years, anti-discrimination regulations have been enacted on both the national and supranational level forbidding the use of genomic data (Van Hoyweghen, 2007), pre-existing conditions (Hull and Pasquale, 2018; McFall, 2019) and gender (Rebert and Van Hoyweghen, 2015).
The proliferation of anti-discrimination laws has given rise to the debate on the financial viability of the insurance industry and insurers’ ‘right to underwrite’ (Meyers and Van Hoyweghen, 2017: 16). Meyers and Van Hoyweghen (2017: 16) estimated that insurers’ interest in behaviour-based personalisation could be fuelled by the introduction of genetic non-discrimination acts (GNDAs) and the anticipation of stricter regulations. Constituting risk groups could become more difficult in the future, and insurers are highlighting the controllability of behaviour and discovering ways to attract ‘responsible’, young and healthy individuals (McFall, 2019: 68; Meyers and Van Hoyweghen, 2017: 16). Thus, while GNDAs have reconfigured insurance markets by protecting genetic ‘risk-havers’ from discrimination and by increasing the subsidising qualities of insurance, they have contributed to the idea that lifestyle ‘risk-takers’, such as smokers, should carry their own responsibility (Lehtonen and Liukko, 2011: 40; Van Hoyweghen, 2010: 441).
Critical researchers often discuss these individualising effects of Big-Data-enabled personalisation using US cases related to the ACA legislation. However, Liz McFall (2019: 70) argues that under current US regulations, it seems unlikely that the envisioned threats of behaviour-based personalisation would become a reality, as the ‘protections for pre-existing conditions, and the actuarial devices for reinsurance, risk assessment and risk corridors, purposefully prevent the use of any individual level data derived for pricing’. Thouvenin et al. (2019) assert that, due to strict anti-discrimination and other regulations, attempts to individualise (health or other) insurance contracts by running large-scale Big Data analytics are probably not commercially feasible in the US (and specific to this case, California). Thus, even though the ACA legislation encourages the adoption of wellness schemes and data-driven devices, it does not support their use in pricing and risk selection.
The US context, however, lacks strict data protection regulation, whereas in Europe, the EU’s GDPR constitutes the most important restriction for behaviour-based personalisation in insurance (Thouvenin et al., 2019). Still, critical voices suggest that the GDPR has its shortcomings. Marelli et al. (2020: 12–13) highlight four main issues raised in the debate: the inadequacy of traditional data protection principles to regulate Big Data practices, the vagueness of regulatory categories, the problems with the notice-and-consent model and the insufficiencies of controlling data processing operations. These issues highlight the need for renewed regulations that consider different stakeholders’ rights, values and interests. Intensified data collection could create a new kind of solidarity through the understanding that ‘we are all’ carriers of data and potentially subject to discrimination (Prainsack and Van Hoyweghen, 2020). This could lead to further demand for protections against behaviour-based personalisation (Prainsack and Van Hoyweghen, 2020). However, because individuals’, families’ and societies’ methods of coping with risks are largely tied to insurance mechanisms, a balance between market incentives and societal needs must be found (Blasimme et al., 2019: 7).
Doing insurance
Critical data studies researchers approach insurance as a black box or as a given entity. In contrast, insurance studies highlight the importance of studying the practices of doing (behaviour-based) insurance. For instance, the meanings and applications of the central concept of insurance, moral hazard and the understandings of morality and prudence have evolved alongside changes in the ideological and practical implications of insurance (Baker, 2000; Leaver, 2015; Quinn, 2008). Following these kinds of trajectories and taking a pragmatic stance calls for a richer and empirically rooted approach to insurance. The pragmatist perspectives are well-established in insurance studies, with Ewald (1999: 21) arguing that general insurance does not exist – rather, there are only insurance companies with different strategies for competition and acquiring information. These kinds of perspectives are prevalent, especially among insurance studies that use STS approaches. These studies focus on the effects of human and non-human actions and highlight that the outcomes of insurance depend on how it is assembled in different situations (e.g., Lehtonen, 2017; McFall, 2014; Meyers, 2018; Van Hoyweghen, 2007).
The insurance studies using STS approaches employ various empirical materials and ethnographic methods to analyse insurance practices and new insurance schemes. Meyers (2018) follows the emergence of behaviour-based personalisation and the creation of a ‘not-yet’ market by conducting participant observations in insurance conferences, interviewing insurance professionals, analysing reinsurers’ online platforms and following car insurance experiments. McFall (2019) uses the case of Oscar Health to study how conceptual, regulatory and infrastructural practices act as barriers to risk personalisation. The empirical evidence from these studies shows that there are many practical difficulties in creating a policy that utilises new means of tracking. Thus, the utopian – or the dystopian – idea of personalised insurance is not very easy to achieve. Instead of personalising risks, behaviour-based insurance policies seem to create future markets by personalising and promoting insurance companies (McFall, 2019; Meyers, 2018).
What is still lacking from both critical data studies and the sociology of insurance is a focus on the insureds’ experiences. Furthermore, although insurance studies have analysed the providers’ perspectives through expert interviews, documents, blog posts and business conferences (McFall, 2019; Meyers, 2018), more research is needed on the insurance providers’ practices of developing behaviour-based policies. The user perspective has been studied in what Ruckenstein and Schüll (2017) call the ‘living with data’ approach to self-tracking practices and the datafication of health. Even though these studies have not focused on insurance customers, some of their findings might be applicable in the insurance context. For instance, empirical evidence shows that people oftentimes abandon wearable devices, or their use becomes unengaged (Gorm and Shklovski, 2019; Kristensen and Ruckenstein, 2018; Rapp and Cena, 2016). In Schüll’s (2016: 323) ethnographic study, an informant affiliated with the UnitedHealth insurance company describes encountering this problem: Back upstairs at the Digital Health Summit, technology designers, doctors and government representatives continued to brainstorm on how to get personal data technology onto the wrists and into the pockets of more consumers. The accuracy and feasibility of monitoring, they reported, was good and getting better, and data scientists were continuing to refine analytic algorithms; the challenge when it came to self-tracking devices and programs was consistent use – ‘getting people to use the damn thing, so that it becomes part of their lifestyle’, as the Executive Vice President and Chief Medical Officer of the UnitedHealth insurance company put it.
Conclusion
In this review, I have analysed how the recent social scientific literature from critical data studies and the sociology of insurance approach behaviour-based personalisation in insurance. These streams of literature represent distinct research projects with different premises and aims. On the one hand, the critical data studies research is oriented towards an overall theoretical analysis of the datafication of health. Here, insurance acts mainly as an extreme example of the undesired outcomes of this pervasive logic. On the other hand, STS-inspired insurance studies approach insurance as a specific technique and logic with its own preconditions. Thus, behaviour-based personalisation is first and foremost studied in relation to ‘insurance as we know it’ to see if and how the new technologies change existing insurance practices. In contrast to critical data studies, the overall effects of datafication are not the primary target of these analyses – instead, the focus is on empirically analysing existing insurance cases, practices and regulatory frameworks.
The critical data studies literature uses behaviour-based insurance to exemplify dataveillance, a process in which people are submitted to the constant monitoring of their data traces and pushed to adopt self-tracking practices (Lupton, 2016). Researchers assert that the prospect of using self-tracked data in risk calculations and premium personalisation is exploitative, as it could lead to the discrimination and exclusion of people who do not conform to certain health ideals, or who do not wish to partake in self-tracking (Lupton, 2017). Furthermore, the critical research perceives behaviour-based insurance as a case of surveillance capitalism, an economic logic allowing insurers to yield profits through monitoring, predicting and manipulating peoples’ behaviour (Gidaris, 2019; Zuboff, 2019). In contrast, insurance studies highlight several issues in building a functioning behaviour-based policy. First, risk and insurance are collective concepts – therefore, the idea of personalised premiums is at odds with the basic mechanisms of insurance. Second, the existing insurance legislation in the US and EU hinders the effective use of self-tracked data (McFall, 2019; Thouvenin et al., 2019). Third, the outcomes of behaviour-based personalisation are not deterministic, but they depend on the actors participating in doing insurance. Current behaviour-based insurance schemes are still mostly pilot policies that act as a form of marketing and that help insurers to prepare for the future market (McFall, 2019; Meyers, 2018). Thus, it seems that the dystopian imaginings invoked by the critical research, and the utopian visions of the industry, are not actualised.
It is evident that power and knowledge asymmetries allow insurers to structure the playing field and control many of the conditions of insurance relationships. Behaviour-based insurance could entail many of the problems the critical scholars discussed, such as discriminating against people with restricted mobility (e.g., Elman, 2018). Therefore, critical voices on insurance and new technologies are needed. However, by only highlighting the coercive and exploitative aspects of insurance relations, the critical data studies literature completely overlooks the basic usefulness of insurance. Furthermore, as the critical research rarely engages in empirical inquiry, it dismisses users’ experiences and cases of noncompliance. Thus, it might rely on the same understandings as the dominant Big Data enthusiastic discourses, ultimately taking insurers’ and tech companies’ visions on the ‘digital disruption’ seriously. Giving credit to these predictions could in fact re-enforce this possible future (e.g., Beckert, 2016).
To understand behaviour-based personalisation in insurance, it is crucial to approach insurance as a specific financial technique. STS-inspired insurance studies employ this kind of perspective and analyse the limits that insurance technology, practises and legislation place on new policies. This kind of empirical stance facilitates constructive criticism that does not rely on the dominant discourses. Thus, the solution is not to depoliticise the discussion but to examine how normalisation and exploitation appear in actual practice (Sharon, 2018: 21). In fact, insurance studies highlight that behaviour-based personalisation is already thoroughly political, as it is subject to strict regulation and legislation.
Neither critical data studies nor the sociology of insurance have discussed insurance providers’ practices of developing behaviour-based policies and users’ experiences in detail. Therefore, more empirical analysis focusing on these topics is needed. Thus far, insurance studies have explored the providers’ side through examining official documents, blog posts and business conferences, for example (McFall, 2019; Meyers, 2018). However, an in-depth empirical analysis on the design processes of new (health or life) policies is missing. Moreover, insurance customers are generally an under-researched area, with only a few studies examining the insureds’ experiences (e.g., Lehtonen, 2017). Therefore, research focusing on behaviour-based policy customers is needed to understand how the policies unfold in everyday life. Future studies could analyse how insurance companies aim to become involved in customers’ lives and ensure their engagement with their products. They could also investigate how customers negotiate their relationships with new policies. These kinds of approaches would provide an opportunity to empirically test claims from critical analyses. They would also highlight that there are many ways of doing insurance, and that the future of behaviour-based personalisation is open for alternative imaginings.
Footnotes
Acknowledgements
I am very grateful for the insightful and helpful comments that I received from the three anonymous reviewers and the co-editors of the Big Data & Society special issue ‘The personalisation of insurance: data, behaviour and innovation’. The first draft of this article was written during a research mobility in KU Leuven (autumn 2018) and discussed in ‘Risk and the Insurance Business in History’ – conference in Sevilla, Spain (11–14 June 2019). I would like to thank Ine Van Hoyweghen, Liz McFall, Gert Meyers, Hugo Jeanningros and Arjen van der Heide for their encouraging feedback and great discussions. Finally, I wish to thank Turo-Kimmo Lehtonen and Minna Ruckenstein for their comments and support throughout the writing process.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was supported by Academy of Finland (grant number 283447).