
Abstract
This special theme contextualizes, examines, and ultimately works to dispel the feelings of “sublime”—of awe and terror that overrides rational thought—that much of the contemporary public discourse on algorithms encourages. Employing critical, reflexive, and ethnographic techniques, these authors show that while algorithms can take on a multiplicity of different cultural meanings, they ultimately remain closely connected to the people who define and deploy them, and the institutions and power relations in which they are embedded. Building on a conversation we began at the Algorithms in Culture conference at U.C. Berkeley in December 2016, we collectively study algorithms as culture (Seaver, this special theme), fetish (Thomas et al.), imaginary (Christin), bureaucratic logic (Caplan and boyd), method of governance (Coletta and Kitchin; Lee; Geiger), mode of inquiry (Baumer), and mode of power (Kubler).
This article is a part of special theme on Algorithms in Culture. To see a full list of all articles in this special theme, please click here: http://journals.sagepub.com/page/bds/collections/algorithms-in-culture.
A growing number of scholars have noted a distinct algorithmic moment in the contemporary zeitgeist. With machine learning again in ascendancy amid ever-expanding practices to digitize not only all of the important records of our lives but an increasing quantity of our casual traces—mining them like archeologists at digital middens—it is indeed no wonder that the academy has also made an “algorithmic turn.” In response, universities are adding interdisciplinary programs in “data science,” and scholars across the sciences and humanities are weighing in on the promises and perils of algorithmic approaches to their work.
While it is true that algorithms—loosely defined as a set of rules to direct the behavior of machines or humans—are shaping infrastructures, practices, and daily lives around the world via their computerized instantiations, they are neither strictly digital nor strictly modern. The word “algorithm,” a Latinization of the name of ninth-century Persian mathematician and scholar al-Khwārizmī 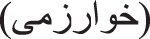 , in fact predates the digital computer by over a thousand years (Al-Daffa, 1977). For many of these years, “algorithm” was an obscure term associated with the algebraic manipulations for which al-Khwārizmī was best known, or a stand-in for the decimal number system more generally. This changed starting in the mid-20th century, when the emerging field of computer science adopted the term to refer to a specification for solving a particular kind of problem that could be implemented by a computer.
, in fact predates the digital computer by over a thousand years (Al-Daffa, 1977). For many of these years, “algorithm” was an obscure term associated with the algebraic manipulations for which al-Khwārizmī was best known, or a stand-in for the decimal number system more generally. This changed starting in the mid-20th century, when the emerging field of computer science adopted the term to refer to a specification for solving a particular kind of problem that could be implemented by a computer.
As computers spread and digital information systems replaced paper, there was a concomitant rise in the interest of algorithms as a social phenomenon (and concern). Some of the first algorithms that computer science students learn allow them to tackle fairly simple data organization and retrieval tasks—but these tend not to be the algorithms that capture social imaginations. Instead, those that are more complicated and difficult to understand—or those that have been intentionally black-boxed by their creators—are also those most prone to evoking in us feelings of a technological sublime in all its awe-inspiring, rationality-subsuming glory (Mosco, 2005; Nye, 1996). Media theorist describes the technological sublime as a feeling of “astonishment, awe, terror, and psychic distance”—feelings once reserved for natural wonders or intense spiritual experiences, but increasingly applied to technologies that are new and potentially transformatory, but also complex and poorly understood (Mosco, 2005: 23).
In the 1960s, for instance, alongside the heady transdisciplinary rubric of cybernetics, the first artificial intelligence algorithms sought not just to define rules for human–machine systems, but to govern them through far-reaching behaviorist feedback mechanisms, conjuring sublime worlds of automatically regulated harmony (Dupuy, 2009). Alongside this utopian dream developed a dystopian nightmare of a mechanized society in which individual agency was subsumed by coercive algorithmic control via institutions and governments. U.C. Berkeley students protested these kinds of visions, riffing on the text printed on computer punch-cards cards to make signs that read, “I am a UC student. Please don’t bend, fold, spindle, or mutilate me” (Lubar, 1992). Both aspects of this cybernetic sublime largely turned to disillusionment as these early algorithms failed to deliver on their utopian promises 1 —even as some of the dystopian fears of algorithmic control were quietly implemented by corporations and governments in the decades since.
A strikingly similar algorithmic sublime has been reinvigorated in the last few years with powerful new techniques enabled by massive datasets (demurely called “Big Data”), increased computing power, 2 and new techniques in machine learning—techniques that are difficult to understand, with potentially massive social ramifications—that take advantage of both. More mundane algorithms already do play a role in many aspects of our daily lives, from healthcare to creditworthiness to the management of utilities. But the ways that algorithms ignite the contemporary cultural imagination—much like those attached to cybernetic visions in decades past—makes them seem still in the realm of science fiction, harbingers of a revolutionary future of which we are forever on the cusp.
Under the hood, even cutting-edge deep machine learning algorithms and the Big Data on which they depend are, if not fully understandable, at least partially interrogatable. Methods like backpropagation and visualization techniques can help researchers understand what an algorithm “sees,” and a growing number of scholars are taking seriously the effects of implicit (and explicit) biases, exclusions, and unpredictability in both data sets and data models. The growing popularity and rigor of conferences such as FATML/FAT* (Fairness, Accountability, and Transparency, either in Machine Learning specifically or in technical systems more generally) attest to a growing recognition of the responsibilities that some in the field feel toward building (and teaching) ethical systems.
Alongside these technical advancements, the burgeoning field of “algorithm studies” has been working to dispel the algorithmic sublime by attending closely to the grounded material implications of algorithms, with more and more critical social scientists with strong technical skills assessing the rhetoric and the realities of algorithms (see e.g., Gillespie and Seaver, 2016). Applying many of the same methods and theories that have enabled social scientists and humanists to understand processes of scientific inquiry and technological development for nearly 50 years, this work explores the sociotechnical implications of algorithms in politics, media, science, organizations, culture, and the construction of the self.
However, sublimes can be stubborn. On one side, some researchers in engineering and computer science still see themselves as engaged in “basic research” that need not attend to ethics (e.g., Hutson, 2018). Some instead “discover” the importance of this area, ignoring decades of scholarship from across the social sciences and humanities that have closely scrutinized the social implications of technology. On the other side, current public discourse about algorithms tends to reinforce claims that despite the often-extensive human tuning that goes into these systems, even partial transparency and interpretability are impossible. In the middle, scholars who actually are engaging with these questions either tend to be ignored in these broader discourses (e.g., O’Neil, 2017), or a few succumb to the pressure to sensationalize their research for public consumption, which unfortunately often involves shallow and incomplete interpretations that can lead technologists to think that social scientists do not really understand them after all. The result is a widespread impression that many algorithms are “black boxes” with little hope for supervision or regulation—and that (despite ample evidence to the contrary) academia has been woefully remiss in neglecting to interrogate the implications of this algorithmic turn.
This special theme works against this mythology. Adding to the growing field of algorithm studies, the papers here consider algorithms as an object of cultural inquiry from a social scientific and humanistic perspective. We explore the sociotechnical implications of the development, deployment, and resistance of algorithms across various social worlds (Becker, 1982). Moreover, we examine how algorithms are not only embedded in these cultures, but are what Seaver in this special theme calls “of cultures”: they are co-constituted by the same cultural processes and take on a multiplicity of different cultural meanings. In short, these authors collectively find that algorithms have everything to do with the people who define and deploy them, and the institutions and power relations in which they are embedded.
We began this conversation at a conference on Algorithms in Culture hosted by the Center for Science, Technology, Medicine and Society and the Berkeley Institute of Data Science at the University of California, Berkeley in December 2016. 3 Our explorations were motivated by a number of wide-ranging questions. How broadly might we usefully define algorithms, for instance? Why has there been an explosion of discourse about “algorithms” in popular culture in the last decade? Are contemporary algorithms a necessarily computational phenomenon, or might we learn something from their algebraic history? What kinds of work are done to make algorithms computable, and what are their material effects? What does it mean to study algorithms as culture (Seaver, this special theme), fetish (Thomas et al.), imaginary (Christin), bureaucratic logic (Caplan and boyd), method of governance (Coletta and Kitchin; Lee; Geiger), mode of inquiry (Baumer), or mode of power (Kubler)? And in what ways can our methods and theories for answering these questions contribute back to computer science, data science, and Big Data initiatives?
In this special theme, Seaver compellingly makes the case that there is no one stable definition of algorithms: they are “multiples—unstable objects that are enacted through the varied practices that people use to engage with them.” Each author in this special theme grapples with this multiplicity, largely drawing on reflexive ethnographic methods (e.g., Burawoy, 1998) to richly account for how algorithms play out in the “mangle of practice” (Pickering, 1993). As such, these scholars also avoid casting the companies that often create these algorithms as monoliths with unified moral visions. While critiques of the hegemonic ideologies that circulate within the technology industry are important, it is equally important to grapple with the complex and heterogeneous practices on the ground: trade-offs, conflicts, even acts of resistance.
Christin describes some of these heterogeneous practices based on ethnographic work with a news agency governed by web analytics and a criminal court using algorithms to understand recidivism risks of potential parolees. She finds that algorithms are co-opted as symbolic resources in both of these communities, and that both draw on “algorithmic imaginaries” to make sense of what these algorithms are doing—though each has distinct practices based on their institutional context. Christin notes that there are differences between the intended and actual effects of algorithms, which she terms “decoupling.” Participants then take up various strategies of “buffering”—acts of resistance such as foot-dragging, gaming, or open critique—to reclaim agency and expertise within algorithmically mediated work environments.
Geiger’s ethnography of the infrastructure of Wikipedia provides another example of some of the decoupling and buffering that Christin describes, with an eye toward the kinds of tacit knowledges that can make the community particularly difficult for newcomers to navigate. He focuses on the specific interactions and workarounds that volunteer moderators (of which he is one) develop by working alongside a host of algorithmic “bots” on Wikipedia. Geiger discusses the implications these “bots” have for governance, gatekeeping, and newcomer socialization in communities like Wikipedia, which can come to rely quite heavily on these algorithmic mediators to function.
Like Geiger, Lee considers how people make sense of what algorithms do in the process of working alongside them—though she takes a different approach in exploring this question. Drawing on an experimental design where participants react to the same managerial decisions variously presented as coming from a human or from an algorithm, Lee considers how those who are subject to managerial control understand authority, fairness, and trust differently in these two cases, and with different kinds of tasks. Where humans were often seen as “authoritative,” algorithms could be at times efficient and objective, but also unfair and untrustworthy in decisions that seemed to rely on intuition—and algorithms, seen as dehumanizing, did not as reliably elicit the kind of positive emotional response that humans did.
The next several articles explore how algorithmic control has been playing out at scale, shaping the temporal rhythms of cities, bureaucratic norms and expectations across the technology industry, and the possible scope of state surveillance. Drawing on an ethnographic observation of a two Dublin city systems that feed into a “city dashboard”—one that manages traffic patterns in real time and another that monitors noise levels—Coletta and Kitchin examine how the rhythms of city life shift with the possibility of real-time data collection and processing. They discuss how these come to change, governance practices and even constitute new modes of “algorhythmic” governance.
The kinds of things that commonly-used algorithms make (more easily) possible, and the kinds of institutional logics that they come to embody in the process, have had impacts that go beyond just one company, Caplan and boyd argue. Using the example of Facebook to examine the spread of sensationalism, “Fake News,” and other forms of propaganda—web content that has proven to be fairly attention-grabbing and thus lucrative for online advertising—these authors demonstrate that the norms that algorithms enforce (such as catchy “clickbait” headlines, more extreme related article recommendations, and easy mechanisms for “going viral”) can end up homogenizing entire industries in their quest to optimize for the algorithm (and for profit). Because these algorithms have largely been written by private companies, they have lacked the oversight that a state institution would (ideally) have—oversight they might have to be subject to in the future if we want to regain the possibility for deliberative discourse.
On the other hand, Kubler provides a sobering example of how these algorithmic norms can be used even by ostensibly democratic states for ever-more-intrusive surveillance practices—especially when conditions in those systems also preclude sufficient oversight. Intervening in discussions of posthegemonic power and post-panoptic surveillance mechanisms, he examines how IBM’s “i2 Analyst’s Notebook” allows French law enforcement to quickly draw from massive databases of information in order to make associations, craft narratives around criminal and potential terrorist activity, and ultimately exercise power in ways specifically afforded by the information from these algorithms. This level of intrusion and surveillance, while enabled by algorithms, has been routinized by the repeated extensions of national states of emergency, and has precipitated shifts in state subjectivity.
How might we interrogate these systems? In addition to the ethnographic methods Seaver advocates and that most of the authors here enact, Baumer uses design-based interventions to more actively consider how people perceive algorithms and to explore the disconnects between these “lay” understandings and how algorithms are actually implemented. By using three human-centered design techniques—speculative design, participatory design, and theoretical framing—for algorithm studies, Baumer compellingly makes the case for shifting from focusing exclusively on performance to more human-centered metrics in evaluating algorithms. When discussions of algorithmic bias often assume that algorithms can solve the problems that algorithms create, such a reframing becomes especially important. At the same time, Baumer also highlights some of the challenges that arise from this translation-work, particularly the need for those involved to develop both technical and critical skills.
Thomas, Nafus, and Sherman take a broader view of the power we invest in algorithms. Drawing on theoretical engagement with Graeber and ethnographic research with the computer-vision and quantified-self worlds, they cast the kinds of “social contracts” that algorithms make possible as fetishistic, characterized by a faith in what algorithms can (or should be able to) do—in other words, a faith in algorithmic power and agency. The authors show that this lens can lay bare the priorities of those who hold this faith and those who are objects of algorithmic control, allowing those more critical of the algorithmic fetish to contest these priorities before algorithms stabilize “into full-fledged gods and demons.”
In sum, this special theme considers how algorithms are enacted, practiced, and contested, and provides tools for others doing the same. Together, we work to examine and dispel the algorithmic sublime that characterizes contemporary discourses on algorithms—not by simplistically collapsing the definition of algorithms, but considering the rich, multifaceted, and at times contradictory meanings that algorithms take on across many domains.