
Abstract
We expect Big Data methods to contribute to research with results that are not inferior to those attained in other ways but possibly better, or hard or impossible to generate in other ways. Those who apply these methods may also aspire to augment the arsenal of research methods, offer surrogates for existing research designs, and re-orient research. Moreover, we can critically examine the institutional, societal and political effects of the Big Data methods and the conditions for the solid institutionalization of these methods in social and political research. To reach its primary objective, this article elaborates conclusions on how Big Data methods, not only by means of their ‘social life’ but also by their ‘political life’, may influence the institutionalization of social and political research. To reach its secondary objective, the article re-examines a study of budgetary legislation in 13 countries carried out by means of Big Data methods to draw conclusions concerning the augmentation of the arsenal of research methods, the surrogation of existing research designs, and the re-orientation of research.
Keywords
Introduction
We expect Big Data methods to contribute to research with results that are not inferior to those attained in other ways but are possibly better, or hard or impossible to generate in other ways. Those who apply these methods may also aspire to use them to augment the available arsenal of research methods, offer surrogates for existing research designs, and re-orient research (Edwards et al., 2013). Moreover, we can critically examine the direct and indirect societal and political effects and conditions of the institutionalization of Big Data methods (Law and Ruppert, 2013).
The primary objective of this article is to elaborate conclusions on how Big Data methods, not only by means of their ‘social life’ (Law and Ruppert, 2013) but also their ‘political life’ (a notion that will be explained in the next section), influence the institutionalization of social research with special reference to political research. To support its pursuit of its primary objective, the article also pursues a secondary objective, comprised of the re-examination of a study of budgetary legislation in 13 countries carried out by means of Big Data methods. The purpose of this re-examination is to elaborate conclusions on the augmentation of the arsenal of research methods, the surrogation of existing research designs, and the re-orientation of research.
The following two sections elaborate the theoretical rationale of this article and reproduce the research hypotheses of the study that the article re-examines. The subsequent section and Appendix 1 introduce the Big Data methods and the research material of the re-examined study. Utilizing the re-examined study as a context, this article examines in its next two sections two methods of Big Data analysis, comprising a method of unsupervised latent trait scaling and a method of topic modeling. The purpose of the last section is to summarize the contributions of this article.
The theoretical rationale of this article
In important respects this article leans on neo-institutional analysis with no fewer than seven to twelve present-day orientations (Lowndes and Roberts, 2013; Peters, 2010). Making its pick from among this multitude, the article follows authors starting from Berger and Luckmann but principally comprising John W Meyer and his colleagues and followers (see Powell and Colyvas, 2008). Berger and Luckmann (1991) understood institutionalization to take place by means of habituation and resulting taken-for-grantedness (p. 72): ‘Institutionalization occurs whenever there is reciprocal typification of habitualized actions by types of actors. Put differently, any such typification is an institution.’
This article shares the assumption that not only human beings but also artifacts and therefore also Big Data methods and Big Data itself play active roles in research and other institutionalized action (generally see, for instance, Cecez-Kecmanovic et al., 2014; D’Adderio, 2011; Latour, 2005). The article fixes its attention to institutionalization related to Big Data methods in an analogous although not identical way to Law and Ruppert (2013), who elaborate the examination of the ‘social life’ of methods by means of characterizing what they call the relevant ‘patterned teleological arrangements’. Moreover, this article agrees with boyd and Crawford (2012) that mythologies of institutionalization in Big Data contexts need study, and therefore pays attention to the examination of ‘rationalized myths’ of Big Data, which rather than fulfilling common explicit promises to contribute to rationality support institutional legitimation (Meyer and Rowan, 1977).
This article not only seeks to examine the habitually institutionalized social life of Big Data methods but also the ‘political life’ of disruptions and radical transformations related to these methods. The article shares the understanding of politics of Pocock (1975: 156) as the ‘art of dealing with the contingent event,… with pure, uncontrolled, and unlegitimated contingency’, and also fixes its attention to the role of performativity (Austin, 1975) that catalyzes the disruptions and transformations indicated. We find analogous arguments on performativity in political theory (Skinner, 2009), science and technology studies (D’Adderio, 2008, 2011; Latour, 2005), and organization research (D’Adderio, 2014; Deroy and Clegg, 2015; Maguire and Hardy, 2009). The authors indicated locate disruptive, radical institutional change in situations in which contentious actors, finding that unprecedented opportunities have opened up, mobilize performatives by means of which these actors may successfully de-legitimate the incumbent actors and those performatives that have helped entitle the latter actors to their positions.
The rationale of this article also pushes it to examine chances to augment the arsenal of existing methods, offer surrogates for known research designs, and more generally re-orient research (see Edwards et al., 2013). A common motivation to use Big Data methods is to try to reap economies of scale in managing large datasets, data dredging, and implementing research designs. Moreover, Big Data methods may lead researchers to transcend boundaries between research fields and re-orient research in other ways (Ruppert, 2013).
The hypotheses proposed in the study that this article re-examines
Big Data methods can be used either in exploratory analysis (O’Neil and Schutt, 2013) or explanatory research, the latter being the case in the study that this article re-examines. The empirical subject matter of the study indicated comprised a ubiquitous trite practice, namely government budgeting. However, the objectives of the study that this article re-examines had pushed it away from entrenched research on budgetary governance (de Haan et al., 2013; Hallerberg et al., 2007) or adaptations of generic research on public sector reform adapted to examine government budgeting (see, for instance, Hyndman et al., 2013). Instead, the study indicated examined historical legal traditions as possible influences on government budgeting.
The study that this article re-examines started with observations that despite indications that legal traditions are dead (Lindahl and Schadewitz, 2013; Pargendler, 2012), research acknowledging these traditions continues (Ma, 2012; Painter and Peters, 2010). Moreover, heterogeneity between national systems of government budgeting despite decades of global harmonization called for explanation (International Monetary Fund (IMF), 2013; Jones et al., 2013; Lienert, 2013; OECD, 2005; Wanna et al., 2010). The indicated study proposed hypotheses that legal system traditions indeed explain differences in government budgetary legislation according to entrenched historical, social, cultural, and political divisions in common law with British origins, Napoleonic civil law first codified in France, civil law of the German type, and Nordic law resembling German law in many respects (Glenn, 2010; Zweigert and Kötz, 1998). The study that this article re-examines approached differences between the legal systems taking the less common inroad of examining differences in legal language (Brake and Katzenstein, 2013; Kischel, 2009).
The first three hypotheses proposed in the study that this article re-examines were tested by means of a Big Data method of unsupervised latent trait scaling. The first two of these three hypotheses were: Hypothesis 1: A grand division into common law legal systems and civil law legal systems explains differences in government budgetary legislation. Hypothesis 2: Within countries of civil law traditions, finer divisions into Napoleonic, German and Nordic legal systems explain differences in government budgetary legislation. Hypothesis 3: The older the budgetary legislation is in a civil law country, the wider its differences from budgetary legislation in common law countries. Hypothesis 4: Divisions into legal system traditions explain divisions into topics in government budgetary legislation. Hypothesis 5: Divisions within government budgetary legislation according to different topics explain differences in the vocabularies of these topics in the legislation indicated.
Research methods and the research material in the study that this article re-examines
Methods
The foremost methods of the study that this article re-examines comprised a method of unsupervised latent trait scaling and a method of topic modeling. A brief background characterization follows, and Appendix 1 gives more details.
Latent trait scaling first appeared in social research of the political science variety in the shape of supervised latent scaling (Laver et al., 2002), which requires the researcher first to feed a ‘seed text’ and next utilize machine learning algorithms to do the scaling. Later, unsupervised scaling evolved (Proksch and Slapin, 2008), using machine learning algorithms throughout the research process. First and foremost, both two scaling methods have been applied to examine ideological polarization in politics by means of using such Big Data textual materials as parliamentary speeches, political statements of government ministers, or political party programs (Lowe and Benoit, 2013).
Topic modeling found its way into social research at about the same time as unsupervised latent trait scaling evolved within the political science variety of this research (Grimmer and Stewart, 2013). Rather than within political science research (Clark and Lauderdale, 2010), this method has found applications in sociological research (see, for instance, DiMaggio et al., 2013; Fligstein et al., 2014; Levy and Franklin, 2013).
Research material
The text material of the study that this article re-examines.
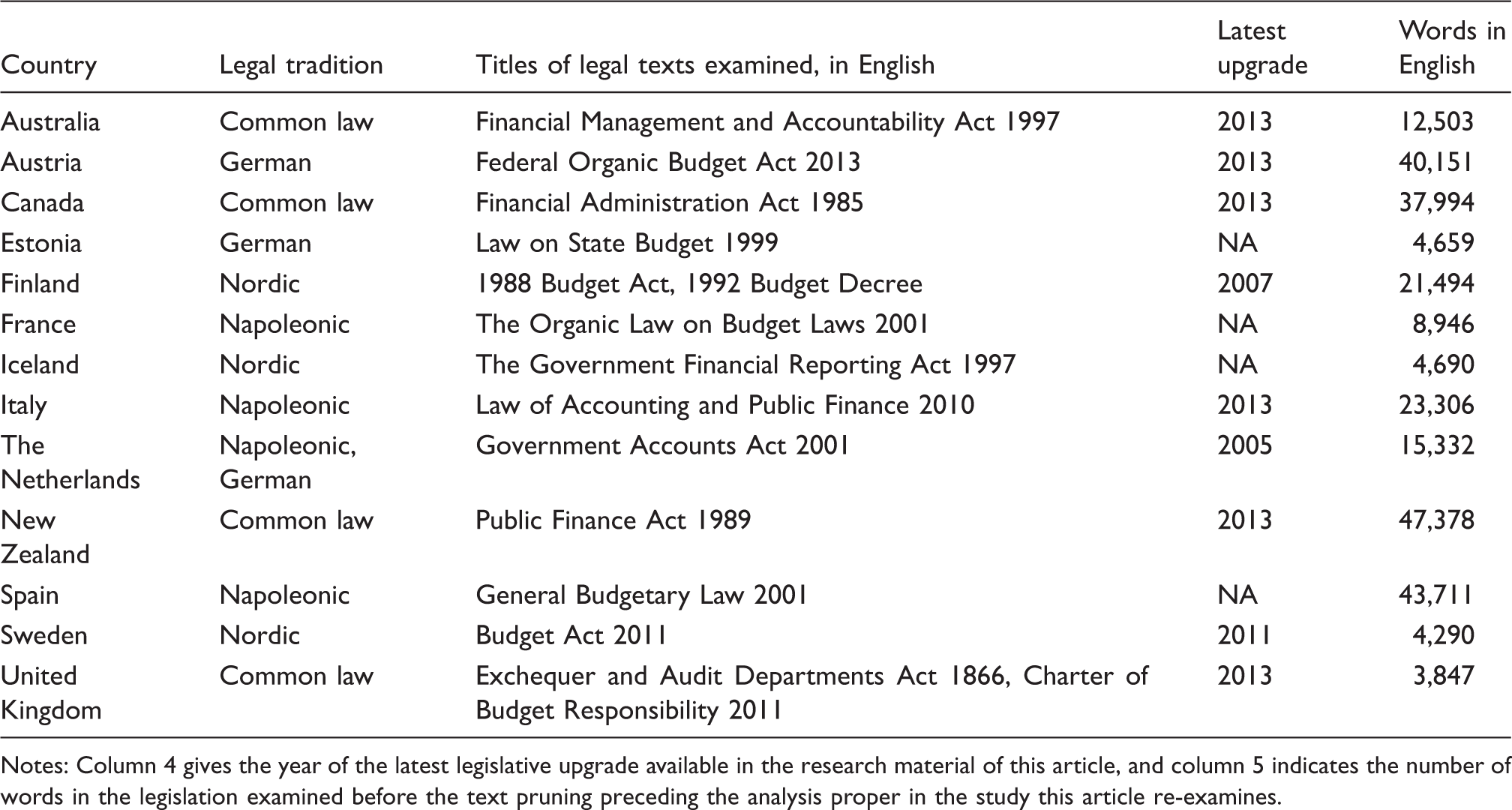
Notes: Column 4 gives the year of the latest legislative upgrade available in the research material of this article, and column 5 indicates the number of words in the legislation examined before the text pruning preceding the analysis proper in the study this article re-examines.
Most of the materials were derived from a World Bank (2013) website with legal texts in English or English translation. Two texts derived were from governmental websites, in English translation (Austria, 2013) or in Italian (Italy, 2013), of which the latter was translated into English. Applying a common and allowable practice of Big Data research for the UK and Finland, two separate legal documents were merged into a single text.
Examining augmentation, surrogation, and re-orientation in research by means of Big Data methods
Examining unsupervised latent trait scaling
The method of unsupervised latent trait scaling used in the study that this article re-examines (for technical details see Appendix 1) enables delivering estimating and testing results on what the developers of this method have named the fixed effects related to individual words (θ, theta), the fixed effects related to each different document included in the data (α, alpha), the word weights (β, beta), and the positions taken in the documents (ω, omega). The notion of ‘fixed effect’ is generic to many varieties of quantitative analysis, indicating that a variable is treated for the technical purposes of quantitative analysis as if it were non-random. All that is specific to estimating fixed effects by means of latent trait scaling derives from the character of this method as a Big Data method of textual analysis. The results obtained by means of using this method are typically uninteresting as concerns the fixed effects, the calculation of which therefore plays only a subordinate technical role to enable the calculation of the word weights and the positions taken in the documents. Moreover, the calculation of the fixed effects may essentially enhance the possibilities graphically to display the estimation of the word weights, the positions taken in the documents, or both the weights and the positions.
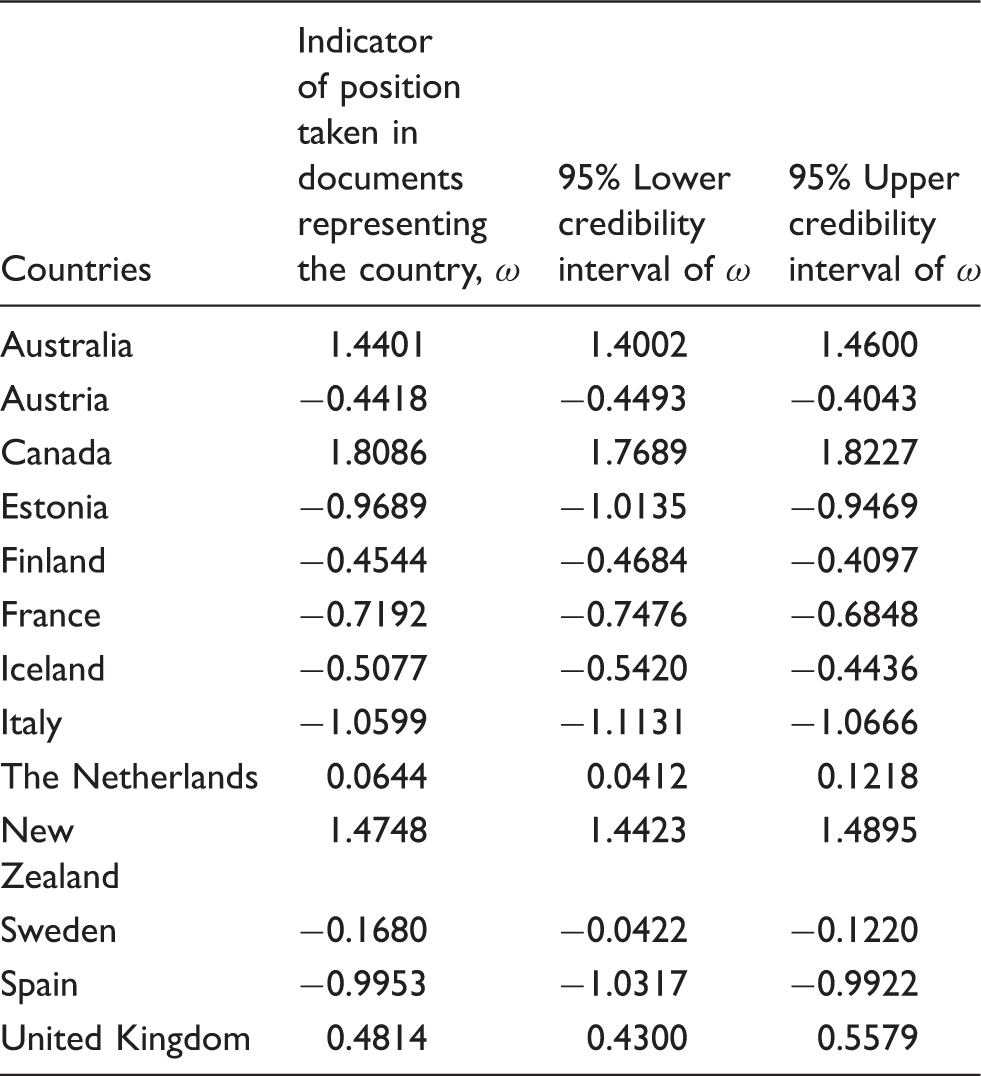
Words best discriminating between the documents examined and therefore between the countries from which these documents derive situated themselves at the extreme ends of β values, as is generally expected in applications of the unsupervised latent trait scaling method. This pinpoints an asset of this method: it emphasizes rare as opposed to frequent words discriminating between text documents. This very characteristic also eliminates the confounding effects of the different lengths of the texts examined. However, the assets of the unsupervised latent trait scaling examined must be weighed against its less outstanding characteristics, which included a graphical output plot with no fewer than 2992 different words according to their weights (β), or far too many either to present meaningfully or to make subject to a sensible substantive interpretation. In their turn, the α (alpha) fixed effects, related to documents and the countries behind these documents, are of no interest for the model interpretation, but the dimension they represent usefully takes visually apart the positions taken in the documents, or the important ω (omega) values (Figure 1).
Position estimates of countries in unsupervised latent trait scaling of the study that this article re-examines. Note: The x-axis indicates the estimates for each document’s (and country’s) position, ω (omega), and the y-axis indicates the fixed effects related to each document (and country), α (alpha).
As proposed in Hypothesis 1 of the study that this article re-examines, a grand division indeed prevails between countries with common law traditions and countries with civil law traditions. Hypothesis 2 could also be sustained, although the countries examined do not arrange themselves quite neatly into the Napoleonic, German, and Nordic variants of civil law. Certain countries sharing legal system traditions received resembling ω (omega) values, such as Spain and Italy, or Sweden and Finland, but there were exceptions such as Iceland more resembling Spain and Italy than the two other Nordic countries of Sweden and Finland. Moreover, Austria, one of the two representatives of the German tradition in the analysis, received a resembling ω (omega) value with Sweden and Finland. The Netherlands, with its Roman–Napoleonic–German legal characteristics (Glenn, 2010), comprised a unique case as could be expected. The fact that budgetary legislation was old at the time of the investigation both in Estonia and Iceland suggested the acceptance of Hypothesis 3 on differences between civil law countries with older as opposed to more recently reformed budgetary legislation.
Test results of unsupervised latent trait scaling in the study that this article re-examines.
Examining topic modeling
Characteristics of a three-topic model by words in the study that this article re-examines.

Note: The table indicates words in a descending order of probability that these words belong to a given topic. Only 30 words receiving the highest posterior probabilities in each topic are included in this table. Referring to the article text related to this table, the italicized words comprise examples of content words of budgetary governance in the first topic, words referring to institutionalization in the second topic, and accountability words in the third topic.
The topic modeling results (Table 3) allowed Hypothesis 4 to be sustained, revealing three topics: a joint topic of ‘German and Nordic law’, a topic of ‘common law’, and a topic of ‘Napoleonic law’. As is commonplace in topic modeling, many words appear in two or all three topics. However, some of these words only illustrate that the corpus comprised legal texts (for instance, ‘law’, ‘must’, ‘shall’, and ‘may’), or indicated references and cross-references common in legal texts (for instance, ‘section’, ‘article’, or ‘paragraph’).
Looking at words of substance that characterize certain topics rather than others, Hypothesis 5 on differences between the legal vocabularies of different legal systems could be sustained (Table 3). Words dealing with the contents of budgeting can be observed in the first topic of ‘German and Nordic law’, such as ‘budget’, ‘finance’, ‘financial’, ‘expenditure’ (both in the singular and the plural), ‘cash’, ‘assets’, and ‘provisions’. In the ‘common law’, topic words were found to characterize the institutionalization of budgetary governance with special reference to the key actors: ‘minister’, ‘crown’, ‘corporation’, ‘treasury’, ‘board’, ‘parliament’, ‘council’, and ‘governor’. Finally, words characterizing accountability received emphasis on the third, ‘Napoleonic’ topic: ‘accounts’, ‘accounting’, ‘report’, and ‘auditing’. Unfortunately, the relationships between different regimes of budgetary governance and different textual frames of budgetary legislation were too under-researched to receive an elaboration proper in the study that this article re-examines, and have to await future study.
Distribution of the three topics by countries in the study that this article re-examines.
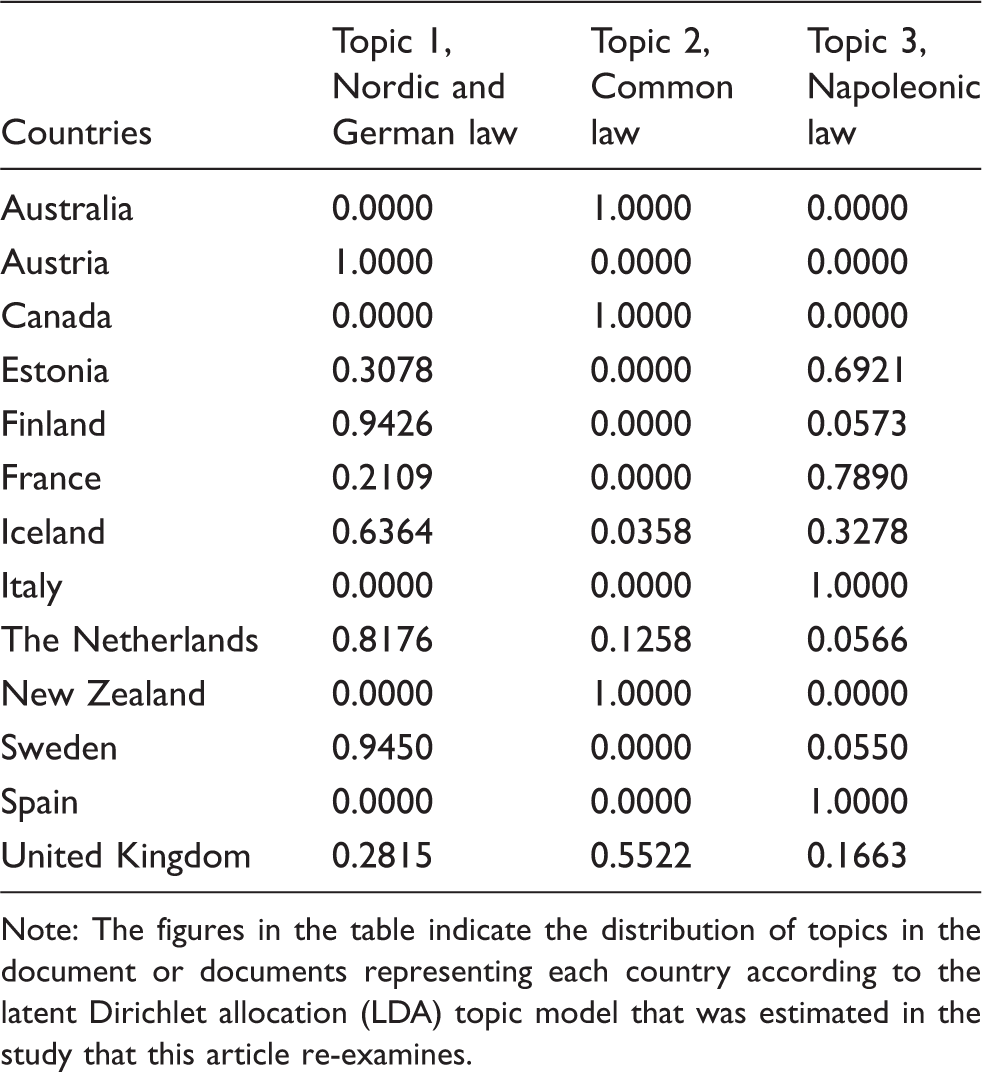
Note: The figures in the table indicate the distribution of topics in the document or documents representing each country according to the latent Dirichlet allocation (LDA) topic model that was estimated in the study that this article re-examines.
The countries in which only the second, ‘common law’ topic was present comprised Canada, New Zealand, and Australia, and this topic also predominated in the United Kingdom with a weight over half of the total. According to the estimation results, in Spain and Italy only the third, ‘Napoleonic law’ topic was present. France, in its turn, represented itself rather as a hybrid between the Napoleonic topic and the German-Nordic topic, possibly reflecting the historical influence of German legal traditions in northern France and the characteristics of the Code Napoleon as a hybrid between the law of southern France and northern France (Glenn, 2010).
In documents representing six countries (Australia, Austria, Canada, Italy, New Zealand, and Spain) only one topic evolved, which was almost the case in Finland and Sweden. In Estonia, France, and Iceland a dominant topic and a minor topic could be found, and in the United Kingdom and the Netherlands the study that this article re-examines revealed a dominant topic and two minor topics.
Baseline comparisons concerning the Big Data methods that this article examines
Baseline comparisons have been carried out before between traditional methods and the unsupervised scaling method that the study that this article re-examines utilized (see, for instance, Grün and Hornik, 2013; Lowe and Benoit, 2013). The performative struggles between researchers using traditional methods (see, for instance, Biernacki, 2014; Budge, 2013) on the one hand, and researchers using Big Data methods (DiMaggio et al., 2013; Laver et al., 2002; Proksch and Slapin, 2008) on the other, also offer lessons for baseline comparisons.
The baseline comparisons in this article receive support from long-time researcher familiarity with both quantitative research and semiotic and rhetorical textual analysis. During the preparation of an international refereed article that went into press in 2014, extending a three-country study (Hyndman et al., 2013) to cover a fourth country, the laborious material collection, the tedious and error-prone manual coding and dissatisfaction with the analysis of word frequencies made methods of Big Data analysis attractive (for the methods actually chosen, see Appendix 1). Given this modest baseline, the study that this article examines, once completed, represented a substantial improvement.
While preparing the study indicated above, the path led to the best-evolved Big Data methods to examine ideological polarization, comprised of methods of latent trait scaling. An additional interest to learn what unsupervised rather than supervised scaling would deliver made the Wordfish program (Proksch and Slapin, 2009) the choice. The study that this article re-examines was driven towards topic modeling by two additional forces. The former of these comprised researcher familiarity with the classical rhetorical examination of (Aristotle, 2006) and the resulting curiosity to learn about the performance of a Big Data method that steps forward as an inheritor of the classical tradition. The latter driving force was a technical interest in using two methods of Big Data analysis as baselines in respect to each other in examining the same research material.
Conclusions and discussion
Augmentation, surrogation, and re-orientation of research
From among the two types of Big Data methods that this article has examined, latent trait scaling has evolved with the explicit purpose of augmenting (Edwards et al., 2013) earlier methods. The authors of both supervised latent trait scaling (Laver et al., 2002) and unsupervised latent scaling (Proksch and Slapin, 2008) have been critical towards the conventional methods applied in a minor international research project started in the mid-1980s to examine political preferences of parties since 1945 finally in more than 50 countries (MARPOR 2015). Although sensitizing MARPOR representatives towards vulnerability in their methods, the altercations have ended in stalemate (Budge, 2013; Volkens et al., 2013), and comparative examinations of the merits of the traditional and Big Data methods (see, for instance, Lowe and Benoit, 2013) have failed to resolve the fundamental disputes.
Big Data methods of topic modeling originate from within hybrids of computer science and statistics rather than from within social research. Topic modeling explicitly augments traditional latent variable modeling initiated with Karl R Pearson’s principal component analysis at the beginning of the 20th century and continued with such methods as LL Thurstone’s factor analysis in the 1930s (Blei, 2014; Grimmer and Stewart, 2013). However, researchers with classical humanist inclinations may want to critically consider how much topic modeling actually augments the 2500-year rhetorical tradition of examining topics or other procedures of classical humanist textual interpretation (see, for instance, Biernacki, 2014).
The results of this article suggest agreement with Edwards et al. (2013) that Big Data methods may not easily provide surrogates for conventional research designs of social research despite the fact that such advances are not ruled out (see, for instance, Hale et al., 2014; Nickerson and Rogers, 2014). In the study that this article has re-examined, the research design was cross-sectional and comparative by modest default rather than by explicit design. A possible future step forward would lead to longitudinal Big Data research of texts of budgetary legislation in a number of countries (for analogous examples of longitudinal Big Data analysis, see, for instance, DiMaggio et al., 2013; Grimmer, 2010; Proksch and Slapin, 2008).
Edwards et al. (2013) indicate that the re-orientation of research by means of Big Data methods may start from where their mere augmentation of conventional methods stops. The empirical results on government budgetary legislation in the study that this article has re-examined suggest that latent trait scaling has potential in empirical research over and above the study of the ideological dimensions of politics (Laver et al., 2002; Lowe and Benoit, 2013; Proksch and Slapin, 2008). More specifically, in the study indicated, a specific method of unsupervised latent trait scaling was used to discern latent traits of legal traditions in government budgetary legislation in 13 countries by means of examining the texts of this legislation. Big Data research has been evolving within legal research proper (see, for instance, Hildebrandt, 2012; Surden, 2014), but the study that this article has examined indicates re-orientation within political science research on government budgeting and legal policy-making rather than legal studies.
The foremost contribution of the topic modeling application in the study that this article has re-examined was confined to social research of the political science variety. This is possibly a contribution in itself, as topic modeling has been applied within political science research comparatively rarely thus far (but, see, for instance, Clark and Lauderdale, 2010), whereas it has been substantially more common within sociological research (DiMaggio et al., 2013; Fligstein et al., 2014; Levy and Franklin, 2013; more generally, see also Bail, 2014).
The social and political life of Big Data methods influencing the institutionalization of research
As indicated at the beginning, as its foremost objective this article examines the ‘social life’ and the ‘political life’ of Big Data methods as influences on the institutionalization of research. The social structures, the organization and the identity of Big Data research, and its researchers within the social and political sciences were still weak rather than entrenched in most countries and most research fields in the mid-2010s. At the same time, mainstreaming of Big Data methods was still advancing within statistics proper rather than having been fully accomplished (see, for instance, EMC, 2015). Genuine innovations in social and political research concerning Big Data methods have been relatively few thus far although not nonexistent (see, however, Grimmer and Stewart, 2013; Laver et al., 2002; Proksch and Slapin, 2008). However, the Big Data activism of distinguished social and political scientists (see, for instance, DiMaggio et al., 2013; Fligstein et al., 2014; Laver et al., 2002) may be changing the situation.
According to one scenario, social and political research utilizing Big Data methods will institutionalize itself, that is, it will become habitual and taken-for-granted in social and political research. However, should this institutionalization take place, it would also generate its ‘rationalized myths’ (Meyer and Rowan, 1977) with the exaggeration of the merits and contributions of these methods and formal rather than substantive commitment to them. We would also witness not only the enhancement of the rationality of the core analytic processes of research by means of the Big Data methods, but also the strengthening of the external legitimation of institutions of research by the same means.
For a social researcher in political science, particularly interesting characteristics of the political life of the Big Data methods include the performative roles that these methods and their applications may play in disrupting the achieved institutionalization of research and, possibly, in catalyzing institutional transformations. This article has indicated two specific performative struggles. The first one of these struggles has revolved around a long-term international project examining ideological political polarization (MARPOR, 2015), and has been waged between those who defend traditional methods (Budge, 2013; Volkens et al., 2013) on the one hand, and those who apply Big Data methods (Laver et al., 2002; Proksch and Slapin, 2008) on the other. As indicated above, proposals of appeasement (Lowe and Benoit, 2013) have reaped little success so far. The other performative struggle, which to this date has been milder, has been waged between those who apply Big Data methods including topic modeling (DiMaggio et al., 2013; Fligstein et al., 2014) on the one hand, and those who prioritize methods derived from classical humanistic traditions (Biernacki, 2014) on the other.
In the mid-2010s, time has generally been working to the advantage of those social and political researchers who apply or promote Big Data methods, as observations accumulate that in many countries public sector and private sector funding authorities have placed heavy emphasis upon Big Data research projects. Exhibiting a ‘vivid awareness of the relationship between personal experience and the wider society’ better known as ‘sociological imagination’ (Mills, 1959: 3), these developments have lately become keenly acute not only for numerous global colleagues but also for the research team from among whose products this article is one. Observations of opportunities intermingle with experiences of smaller or larger moments of success in attracting external research funding and having refereed article manuscripts accepted in international journals, winning variable success in mainstreaming Big Data research and related teaching in academia, and disappointments insofar as funding applications or article manuscripts receive rejections. What else do the current characteristics of the ‘political life’ of Big Data methods and its researchers represent than politics in the very sense of Pocock (1975: 156) as the ‘art of dealing with the contingent event… with pure, uncontrolled, and unlegitimated contingency’?
Footnotes
Declaration of conflicting interests
The author declares that there is no conflict of interest.
Funding
This study was supported by Koneen Säätiö/Kone Foundation, Helsinki, Finland, project grant.