
Abstract
Sentiment analysis is one of the most widely used text analysis methods in social science. Recent advancements with large language models have made it more accurate and accessible than ever, allowing researchers to classify text with only a plain English prompt. However, “sentiment” entails a wide variety of concepts depending on the domain and tools used. It has been used to mean emotion, opinions, market movements, or simply a general “good-bad” dimension. This raises a question: What exactly are language models doing when prompted to label documents by sentiment? This paper first overviews how sentiment is defined across different contexts, highlighting that it is a confounded measurement construct that entails multiple concepts, particularly emotional valence and opinion, without disentangling them. I then test three language models across two data sets with prompts requesting sentiment, valence, and stance classification. I find that language models generally understand sentiment in terms of emotional valence rather than opinion. I find that classification generally improves when researchers more precisely specify their dimension, but that even when classification metrics are similar the different prompts are biased in different ways. I conclude by encouraging researchers to move beyond sentiment when feasible and use more precise measurement constructs.
Introduction
Sentiment analysis is perhaps the most widely used technique in text analysis. With the proliferation of transformer language models and zero-shot classification (i.e., classification without supervised training), many political and social scientists have turned to large language models (LLMs) as accessible and high-performance sentiment classifiers (e.g., Rathje et al., 2023; Tornberg, 2023; Weber and Reichardt, 2023). One challenge with this, however, is that “sentiment” entails a wide variety of concepts depending on the domain and tools used. This raises a question: If researchers do not have a consistent definition of sentiment, how do LLMs used for sentiment classification understand it? This brief paper answers this question and spells out the implications for researchers. I first provide a brief overview of sentiment analysis and how it is understood across different domains, tools, and contexts. I then test how generative LLMs understand the concept relative to the more well-specified concepts of stance (i.e., opinion) and emotional valence. Finally, I provide recommendations on how researchers should or should not leverage LLMs for sentiment analysis.
Textbooks and literature reviews on sentiment analysis often define sentiment in terms of “opinions, sentiments, and emotions in text” (Liu, 2010), or “the computational treatment of opinion, sentiment, and subjectivity in text” (Pang and Lee, 2008). Indeed, the literature is awash with references to sentiment as opinion, emotion, and other dimensions of text (e.g., Baccianella et al., 2010; Hutto and Gilbert, 2014; Mehboob et al., 2020; Wankhade et al., 2022). Those familiar with survey research might characterize these definitions as “double barreled”—they are trying to measure two or more things at once. In the language of statistical inference, sentiment is a “confounded” measure—it encapsulates multiple concepts simultaneously and it is difficult to determine what each concept is contributing to the measure.
I am not the first to call attention to sentiment’s confoundedness. As several other researchers in political and computer science have pointed out, emotions and opinions are distinct concepts that need not align (Aldayel and Magdy, 2019; AlDayel and Magdy, 2021; Bestvater and Monroe, 2022). The widely regarded SemEval series of annual workshops has similarly taken care to distinguish between emotion (which they call sentiment) and opinion (which they call stance) (Mohammad et al., 2016; Rosenthal et al., 2017).
More broadly, however, such care is not always taken when using sentiment as a measurement instrument. The commonly used sentiment dictionary Vader, for example, explicitly aligns itself with emotional analysis as a “valence aware dictionary” and then describes itself as an “opinion mining” tool (Hutto and Gilbert, 2014). SentiWordNet similarly positions itself as a tool for “sentiment classification and opinion mining” (Baccianella et al., 2010). Other dictionaries, like the popular Linguistic Inquiry and Word Count, avoid any mention of opinion classification and focus entirely on emotional dimensions (Pennebaker et al., 2001). Others still define sentiment in domain specific terms such as “consumer sentiment” or what direction the economy is expected to move (Sousa et al., 2019; Yang et al., 2020). Finally, several tools evade the question altogether and define sentiment in terms of an undefined positive and negative dimension (e.g., Rinker, 2017; Young and Soroka, 2012). This approach reduces sentiment to an ambiguous factor that that correlates with numerous dimensions of interest yet lacks the precision ideal for scientific inquiry.
The confounded nature of sentiment has resulted in the widespread use of sentiment analysis in cases where it is unclear how valid the measurement approach is. Social scientists have used emotion identification to measure opinion change (Matalon et al., 2021), applied sentiment analysis without explicitly defining what they are measuring (Osmundsen et al., 2021), and in one case used a model trained to classify product review sentiment on a one to five star scale for analyzing civility on social media (Avalle et al., 2024). A recent review by Rathje et al. (2023) published in PNAS simply defined sentiment as “positivity versus negativity.”
Due to recent advancements in LLMs, many have proposed generative AI as a way for robust sentiment classification without training a supervised classifier (Rathje et al., 2023; Tornberg, 2023; Weber and Reichardt, 2023). These models are attractive tools because they provide state-of-the-art performance without training a supervised classifier and are highly accessible because of their low technical barrier to entry. The models work by users providing a plain text description of the text analysis task, and then the model executes the task based on the description. However, the ambiguous nature of sentiment outlined above raises an important question: How do large language models understand the task of “sentiment analysis” when prompted to do it? If the model’s understanding of sentiment is not consistent with the researcher’s, they may not be measuring what they think they are. Further, if sentiment is a confounded measurement, would text analysis improve if we disambiguate the term and measure more precise concepts?
Disambiguating sentiment
The goal of this paper is not to make an argument for how researchers should define sentiment.
Sentiment has long been defined as an emotion and/or opinion in academic and common parlance. This only becomes a problem when its double-barreled definition encroaches on measurement tools. Rather, the argument of this paper is that researchers would be better served if they did not use the term at all and precisely defined the dimension of sentiment they are interested in when using language models for annotation. As outlined above, sentiment is primarily defined in terms of two distinct concepts: stance or opinion, and emotional valence. To define both, I refer to the broader literature on text analysis.
Biber and Finegan (1988) define stance in linguistics as a person’s “attitudes, feelings, judgments, or commitment” to a proposition. More recently, AlDayel and Magdy (2021) operationalize this for classification as a “textual entailment” task based on human judgment. That is, a document entails a stance if a human reading the document would infer that the author is expressing agreement with a proposition. Thus, stance is the opinion dimension of sentiment and necessarily includes some targeted proposition or object which the stance is about.
Valence, on the other hand, originates from two dimensional models of emotion in the psychology literature. In these models, emotions are mapped onto a two-dimensional space consisting of affect (the positivity or negativity of an emotion) and arousal (the intensity of an emotion) (Barrett and Russell, 1999). Early tools used for sentiment analysis, such as the Linguistic Inquiry and Word Count dictionary, were developed in the field of psychology and are explicitly aimed at measuring emotional valence (Tausczik and Pennebaker, 2010). “Sentiment” was not even mentioned in early versions of the dictionary and is now explicitly defined in terms of emotion (Boyd et al., 2022; Pennebaker et al., 2001). Thus, while stance is the opinion about a proposition or target, valence is the positivity or negativity of emotions expressed in a text.
Stance, sentiment, and valence labels often do not align.

With an understanding of why current definitions of sentiment are problematic, how researchers should disambiguate the concept, and the potential ways in which not doing so can result in different labels, the question at hand remains: How do language models understand the task of sentiment analysis—in terms of stance or valence? Given its ubiquity, sentiment analysis will continue to be widely used. Language models are already a commonly used tool for the task. Researchers should therefore be informed about what exactly is being measured under such conditions.
Data and methods
I examine this question with a straightforward approach that compares the labels an LLM produces when I prompt it for stance, valence, and sentiment classification. The three prompts are presented in Listings 1–3. The sentiment prompt in Listing 1 is ideal for probing the model’s understanding of sentiment because it does not define sentiment or how it could be identified within the text. I then adapt this prompt to label stance and valence in Listings 2 and 3, respectively. In the stance prompt, I specify that the model is to identify the opinion expressed with respect to a particular target, and the valence prompt specifies that the model is to identify the emotions expressed.

Each of these three prompts is tested with three different language models: GPT-4o, Claude 3.5 Sonnet, and Llama-3 8B (OpenAI, 2023; Anthropic, 2024; AI@Meta, 2024). These three models represent two commonly used proprietary state-of-the-art models in GPT-4o and Sonnet 3.5, as well as a smaller, open-source model that can feasibly run on local hardware.


The data I use to test the prompts across the three models consists of two data sets: one with stance labels and a second with valence labels. The stance labeled data consists of 2390 tweets about politicians, hand labeled by two to three coders. The labels indicate whether the text expresses support, opposition, or no opinion towards the target politician. The sentiment data set is a random sample of 2000 tweets from the test set for task 4 of the 2017 SemEval challenge (Rosenthal et al., 2017). This data consists of tweets that have been labeled for positive, negative, or neutral sentiment with sentiment being explicitly defined as emotional valence. Each document was labeled by five annotators, and a final label was only accepted if three of the five annotators agreed. The data was sampled to have an equal distribution between sentiment classes.
To examine how the models understand sentiment, I conduct an “internal” test that compares the model’s sentiment labels to its own stance and valence labels and an “external” test that tests how well the prompts are able to re-capture human labels for stance and valence. For the internal test, I combine my two data sets and I compare how similar the set of stance and valence labels are to the set of labels generated from the sentiment prompt. The metric I use for this comparison is the Jaccard similarity score. Jaccard similarity is a measure of similarity between sets and is defined as the ratio of the intersection and the union of two sets. In simple terms, if a Venn diagram of two sets is made, it is the ratio between the shared portion of the diagram to the entire area of the diagram. A Jaccard similarity score of 1 for the set of documents labeled positive with the sentiment prompt and labeled positive with the valence prompt would imply that both prompts assigned a positive label to all of the same documents. This score provides a single, intuitive metric that allows me to evaluate if the sentiment labels are more similar to the stance or the valence labels.
For the external test, I use more conventional classification metric of accuracy to evaluate how well each prompt recovers human labels for stance and valence. I use accuracy because it has an intuitive interpretation, and because my testing set has near perfectly balanced classes, obviating the advantage of other metrics such as F1. This test provides more practical benchmarks for helping researchers understand how each prompt might impact their classification performance. I note, however, that while relative performance differences across prompts can be informative, readers should not interpret performance as a widely generalizable benchmark. Rather, the objective is to demonstrate how and why sentiment, stance, and valence prompts differ. Accordingly, the test set was sampled to have balance between classes. This is useful for identifying points of disagreement between the models but is rarely observed in practice.
Finally, to determine if performance metrics across prompts are significantly different than one another I use a two-sample permutation test to calculate a p-value that the difference is greater than zero. Where appropriate, I combine p-values across the models using Fisher’s method to test if the difference between prompts is jointly significant across the models.
Results
Internal test: label set similarity
I first compare similarity between a language model’s understanding of sentiment and its own definitions of stance and valence. To calculate the similarity between stance and valence labels with the sentiment labels, I first combine my two testing data sets so that I have a complete set for each label type. I then calculate the Jaccard similarity between the sets with bootstrap standard errors. Results are shown in Figure 1. Across all three models, the sentiment labels are more similar to the valence labels than the stance labels. Additionally, for each model the difference between the valence and stance similarity scores is highly significant at p < .01. When compared against their own understanding of stance and valence, language models generally understand sentiment in terms of valence. Jaccard similarity scores for valence and stance label sets with the sentiment label set. Bootstrapped standard errors are in parentheses. For each model, the sentiment label set is most similar to the valence label set.
External test: stance classification
Figure 2 plots between each classification prompt and the human labels with bootstrapped standard errors. I use a two-sampled permutation test to calculate if the performance from the stance prompt is significantly greater than the sentiment prompt. In all cases, the stance prompt is significantly better at p < .05 with the Llama 3 model being the closest to insignificant at p = .01. This result is consistent with previous work from Bestvater and Monroe (2022), who emphasize the importance of distinguishing between emotional valence and stance. The difference between the sentiment and valence prompts, however, is not significantly different from zero either individually (GPT-4o: p = .19, Sonnet 3.5: p = .26, Llama 3: p = .85) or jointly (p = .39). Classification performance with bootstrapped standard errors for stance, sentiment, and valence prompts on stance labeled data. Using a prompt specifically for stance can provide a dramatic improvement over sentiment classification.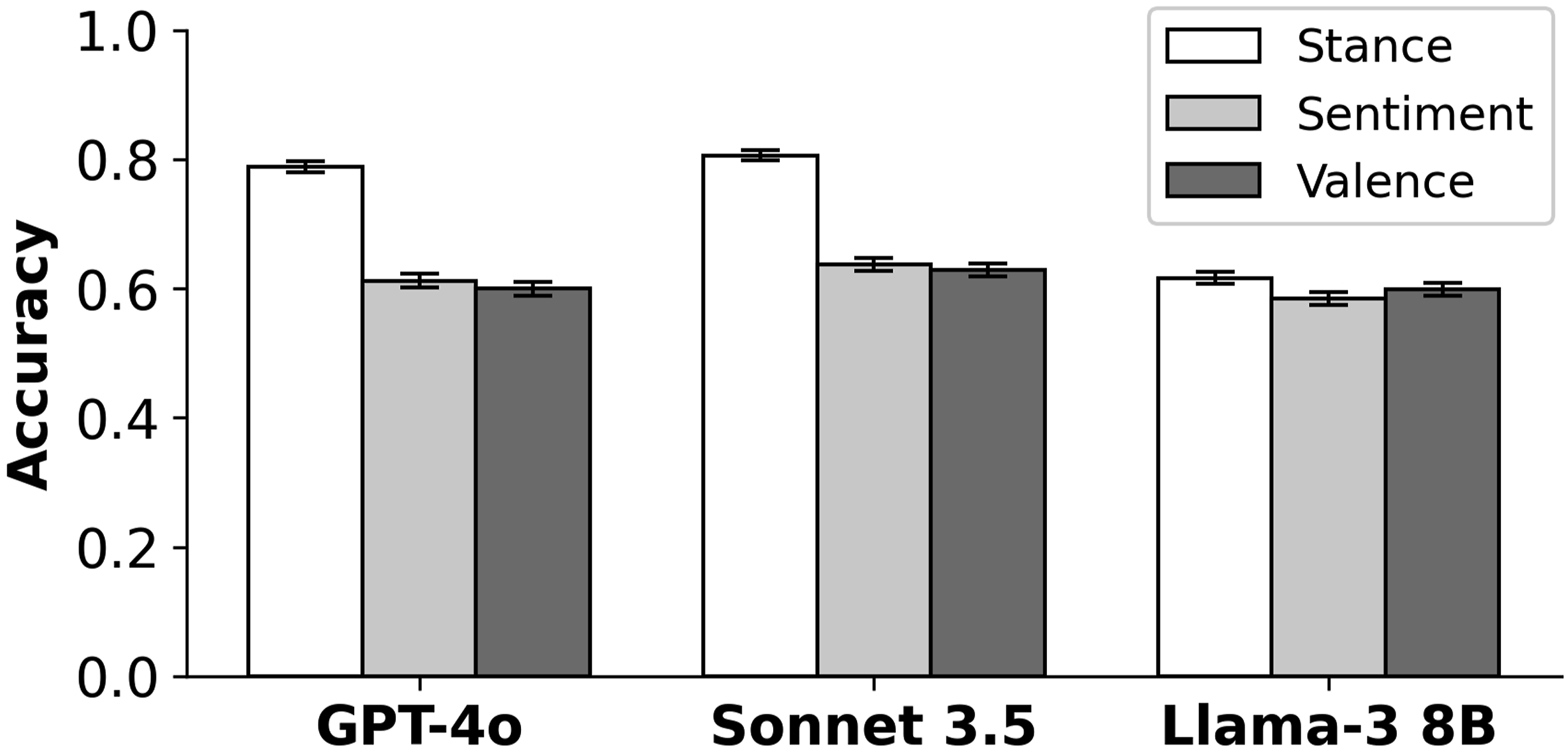
Notably, while the Jaccard similarity scores for Llama-3 showed greater alignment between sentiment and valence labels than sentiment and stance labels, the difference vanishes in the classification performance metric. The confusion matrices for the Llama-3 labels in Figure 3 illustrate why. While the errors for the stance prompt are largely concentrated on the neutral documents, the sentiment and valence prompt errors are more evenly distributed across the neutral and support documents. Even though the error rate across all three prompts is similar, the sentiment and valence prompts have a more similar pattern of errors than the stance prompt. The implication is that even though distinctions might not manifest in holistic classification performance metrics, sentiment and stance prompts can result in very different label sets, and thus different results in downstream analysis. Thus, even if classification performance metrics are similar, researchers should take care to prompt language models for the concept they are trying to measure in rather than relying on proximate constructs. Even though stance, sentiment, and valence prompts have comparable accuracy in recovering stance labels when using the Llama-3 8B model, the distribution of errors for the stance prompt is distinct from the sentiment and valence prompts. Thus, difference that may not manifest in overall performance metrics can still lead to different results in downstream analysis.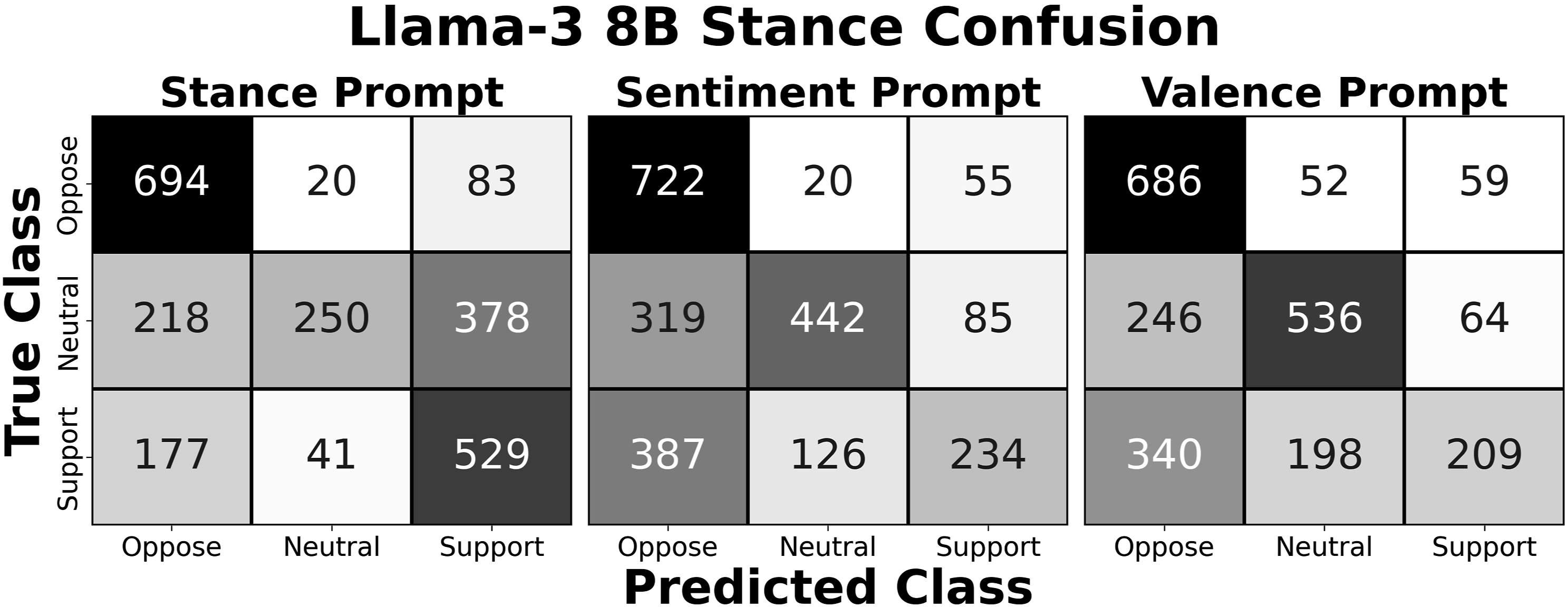
External test: valence classification
Finally, I assess whether the valence or sentiment prompt better recovers the valence labels in the SemEval-2017 data set. If the confoundedness of “sentiment” in the social science literature has spilled over into LLMs, we might expect that the sentiment prompt performs worse than the valence prompt on recapturing human labels for emotional valence. However, the results shown in Figure 4 demonstrate no discernible difference in classification performance between the prompts either for the individual models (GPT-4o: p = .27, Sonnet 3.5: p = .37, Llama 3: p = .23) or jointly (p = .27). Classification performance with bootstrap standard errors on valence labeled documents for sentiment and valence prompts.
While performance metrics are not discernibly different, the Jaccard similarity in Figure 1 indicates that the label sets are not exactly the same. Figure 5 plots the confusion matrix between the sentiment and valence classes. I observe that disagreement between the two labels is concentrated among observations with neutral valence classes. This provides further evidence of the examples highlighted in Table 1. News or factual reporting that is absent emotional cues may be classified as positive or negative when using a sentiment prompt based on whether the events reported are generally positive or negative. This is not inherently wrong, researchers may want either classification. However, researchers should clearly define their measurement when prompting the model rather than letting the model’s concept of sentiment determine if a particular document is classified for emotions, stance, or general goodness or badness. Disagreement between sentiment and valence labels is concentrated among documents with neutral valence across all three models. A sentiment prompt will often assign a positive or negative label when valence is neutral based on whether the events discussed in a document are generally good or bad.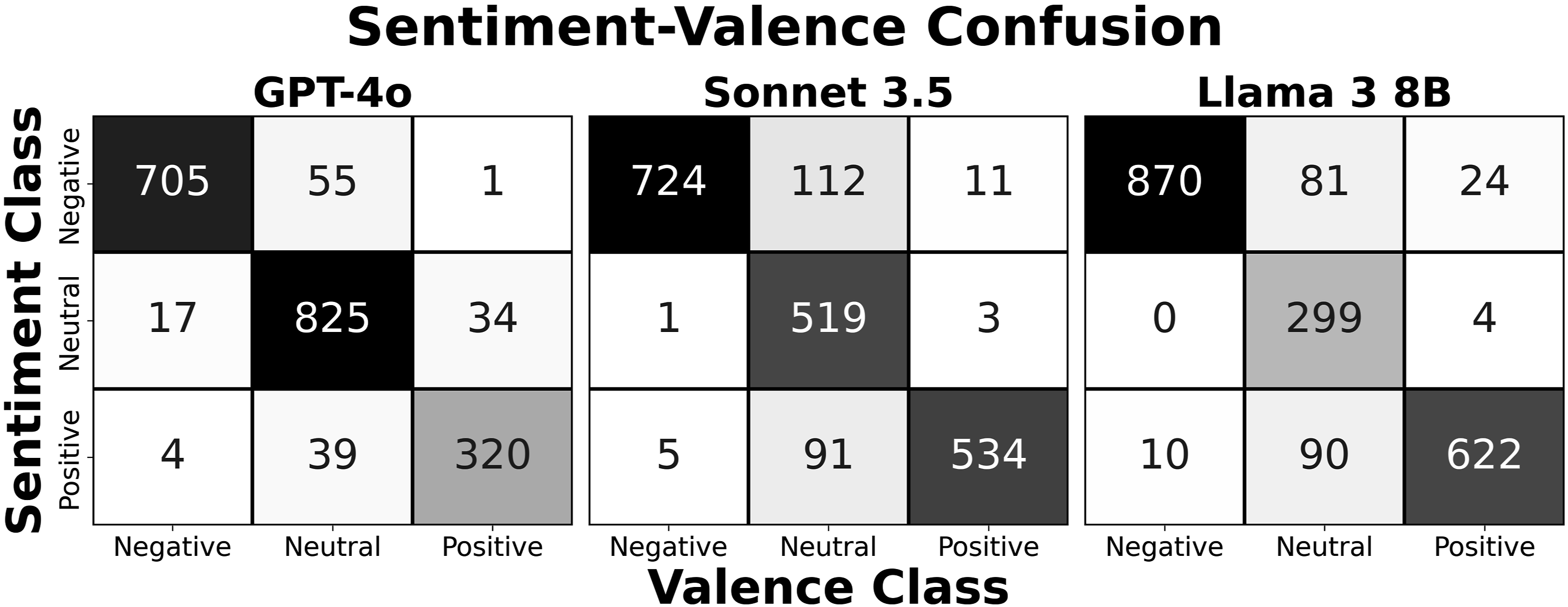
Discussion
This paper provided a brief overview of how sentiment is widely used to measure multiple constructs at once and then demonstrated how LLMs understand the concept. Throughout the literature, researchers define sentiment in terms of emotions, opinions, market movement, a general good-bad dimension, and more. Many of the available tools purport to measure these things simultaneously, and researchers sometimes do not explicitly define what they are measuring in their work. Given the semantic promiscuity of sentiment, it remained an open question how generative LLMs understood sentiment analysis and what exactly they do when prompted to classify the sentiment of a document.
The results presented demonstrate that LLMs interpret sentiment primarily, but not exclusively, as emotional valence. I demonstrated that prompting language models for sentiment or emotional valence returns a similar set of labels as measured by Jaccard similarity scores and classifies documents with similar levels of performance. Where sentiment and valence labels disagree, it tends to be instances where valence is neutral and sentiment assigns a label based on a vague good-bad assessment of the document’s contents. Sentiment and stance prompts show much more significant divergence. When researchers are trying to measure opinion, prompting for opinion rather than sentiment potentially offers a significant increase in classification accuracy. Even when classification accuracy is similar, however, I demonstrated that stance and sentiment prompts generated appreciably different sets of labels.
The implication of these results is that prompting an LLM for sentiment classification can, at worst, introduce significant measurement error and, at best, presents an ambiguous measurement construct to readers. Instead, researchers should be specific to both language models and readers about what they are attempting to measure and avoid double-barreled constructs like sentiment.
Given the above, it is difficult to escape the conclusion that “sentiment analysis” is perhaps not the right framing for many text analysis tasks that previously fell under its umbrella. During the first wave of text analysis methods that counted word occurrences with dictionaries, it was difficult to be precise in measurement. Sentiment analysis was a useful approach for measuring many things because emotions can be credibly measured with word counts and correlate with many dimensions of interest. However, the landscape of text analysis has evolved significantly and, fortunately, allows researchers to be much more precise in what they measure. Models like BERT, GPT-4, Llama, and others are more capable of modeling document semantics and thus more able to make meaningful distinctions between opinion, emotion, and other dimensions of interest (Bestvater and Monroe, 2022; Devlin et al., 2018; OpenAI, 2023). Thus, researchers should strive to use methods that measure these directly rather than bundling them into the single construct of “sentiment.”
While this paper primarily focused on generative LLMs, it is important to note that such large and computationally demanding models are not necessary to disambiguate between dimensions of sentiment. Encoder models like BERT can also be used as either supervised or zero-shot classifiers to label emotions or opinions with comparable or superior accuracy while requiring much less computing resources (Burnham, 2024). Disambiguating sentiment into more precise measurement constructs is thus not a luxury locked behind high-power compute clusters or proprietary LLMs with metered APIs. Accordingly, I encourage a shift towards greater precision and clarity in text analysis. When feasible, researchers should explicitly define their dimensions of interest rather than employing the ambiguous umbrella of sentiment. While it is understandable that researchers may adopt the term sentiment for the sake of consistency with a broader body of literature, researchers would be well served to be more precise in the actual application of methods. This will enhance both the validity and reliability of research using text.
Footnotes
Acknowledgments
I would like to thank the two anonymous reviewers for their helpful and timely feedback.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from the Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.