
Abstract
Temporality is an important aspect of political discourse. Politicians and policymakers attempt to construct the past and the future to gain power, legitimize their policies, claim success for themselves and blame others. To make computational analysis of temporality more accessible, we develop a new methodology using a semisupervised machine-learning algorithm called Latent Semantic Scaling. Only with a set of common verbs in the past perfect and future tense as seed words, the algorithm estimates the temporality of all other words. We demonstrate that it can identify temporal orientation of English and German sentences from election manifestos around 60–70% accurately, which is comparable to the results from a recent study based on supervised machine-learning algorithms. We also apply it to Twitter posts by German political parties to reveal temporal orientation of policy issues.
Introduction
Temporality lies at the heart of modern politics because politicians and policymakers attempt to construct the past and the future to gain power, legitimize their policies, claim success for themselves and blame others (Mansbridge, 2003; Mayhew, 2004). This makes political discourse full of temporal references. For example, the Intergovernmental Panel on Climate Change (IPCC) reports often describe future rises in sea levels using noun phrases in order to make compelling cases for environmental policies; Tony Blair emphasized the difference between his New Labour movement and “old” Labour movements to gain support from both inside and outside of the party (Randall, 2009); Despite the importance of temporality in political discourses, only few studies have been conducted at scale using computational tools. A notable exception is Müller (2021), who applied supervised machine-learning algorithms to identify temporal orientation of election manifestos in English and German languages. Yet, these algorithms require thousands of manually labelled sentences, restricting corpora that researchers can analyze.
Aiming to make temporality analysis more accessible, we developed a new semisupervised technique using Latent Semantic Scaling (LSS), which only requires an unlabeled corpus and a set of seed words for training the algorithm. The technique, named semantic temporality analysis, is only given common verbs as “weak” supervision, but it is capable of automatically identifying broader expressions that relate to temporal orientation of texts.
In the following sections, first, we clarify the temporality of texts from the linguistic perspective; we then apply our semisupervised algorithm to English and German party manifestos to show that LSS can produce results comparable to support-vector machines used in the recent study (Müller, 2021). We will also demonstrate the usefulness of our method by revealing temporal orientation of Twitter posts by German political parties about various policy issues.
Temporal orientation of texts
Politician scientists have positioned parties and politicians in spatial models based on their ideological orientation to explain competition between them (Stokes, 1963). Similarly, we locate political actors based on their temporal orientation because time is a one-dimensional space in which all the events with varying duration are placed (Klein, 1994). 1 The temporal orientation of texts that we wish to measure is the position of a speech or document relative to the event it refers to on the timeline: a text is retrospective if it is generated after the occurrences of events; it is prospective if it is before the occurrences of events. This distinction is central to political discourse since retrospective statements relate to criticism and legitimization of past or current actions, while prospective statements relate to demand for or proposition of future policies (Dunmire, 2008).
Expressions for time reference
In English and German, temporal orientation can be expressed using a diverse set of words and phrases including tense, aspect, lexical aspect (or Aktionsarten), adjectives and adverbs (Evans, 2013; Klein, 2008). The tense of verbs (future/present/past) indicates whether the time of the topic (or event) is earlier, later than, or simultaneous to the time of the speech (or writing). The aspect of verbs (simple/progressive/perfect) indicates events are ongoing or completed from the speaker’s (or writer’s) viewpoint. While many verbs must be inflected to express temporality, verbs with lexical aspect (e.g., “create,” “generate,” “solve”) are inherently temporal as they imply changes in the state of things. Verbs often used in spatial analogy of time have lexical aspect too (e.g., “approach” and “leave”). 2 Adjectives (e.g., “old,” “early,” “new,” “next,” “forthcoming”) indicate temporality because they modify nouns. Adverbs give temporal orientation to sentences as simple adverbs (e.g., “soon,” “already,” “now,” “then,” “first”), morphologically compounded (e.g., “recently,” “thereafter,” “yesterday,” “tonight”), or syntactically compounded (e.g., “at Christmas,” “last spring,” “next year”).
The diversity of temporal references suggests that we cannot rely only on tense and aspect of verbs despite their ubiquity. In fact, there are many references to the future without verbs in the future tense in election manifestos as shown below. “Moving ahead” in Example 1 is a spatial analogy of future actions; “address” in Example 2 is in the present tense but its lexical aspect implies future actions. Example 1. “We are moving ahead with ‘open skies’ agreements to expand opportunities for commercial aviation” (Democratic Party, United States, 2012) Example 2. “To be a truly reconciled nation, it is crucial that we address the issues of sovereignty and treaties” (Australian Greens, 2016).
Similarly, there are references to the future, the present and the past in manifestos only using adjectives and adverbs. The two adjectives, “forthcoming” and “next,” as part of noun phrases in Example 3 make the sentence clearly about the future, while the adverb, “already,” in Example 4 shows sentence is about the past and the present. Example 3. “The forthcoming renegotiation of the common agricultural policy provides the next Irish government with a real opportunity to deal with the problems” (Progressive Democrats, Ireland, 1997) Example 4. “Many are already struggling to cope with rising sea levels, flooding, drought and extreme weather” (Green Party of England and Wales, 2015).
Further, we can distinguish between three types of time reference: deictic, anaphoric and calendic (Klein, 1994). Deictic reference is relative to the time of speech (or writing) and usually achieved using tense of verbs; anaphoric reference is relative to time points in earlier sentences and often achieved using adverbs (e.g., “then” or “later”); calendic reference is absolute on time and achieved by mentioning names or dates of events (e.g., “Black Monday”, “September 11th”).
Computational approaches to time
Computer scientists have developed tools to identify time and duration of events in texts based on part-of-speech (POS) and named-entity taggers (Chang and Manning, 2012; Strötgen and Gertz, 2010). They have also attempted to improve the ability of these rule-based systems by collecting a greater number of temporal features using WordNet (Hasanuzzaman et al., 2016). In more recent studies, they have employed supervised machine-learning algorithms such as regularized logistic regression, support vector machines (SVM), decision tree classifiers, or neural networks (Huang et al., 2018; Kamila et al., 2017; Park et al., 2017; Schwartz et al., 2015). Müller (2021) also employed SVM and a neural network to identify temporal orientation of election manifestos, and concluded that SVM has the best balance between the accuracy and computational efficiency. His SVM models achieved F1 scores between 0.55 and 0.82 in classifying sentences from manifestos in English and German.
The machine learning-based approaches appear more capable than the rule-based approaches in capturing diverse temporal features, but these supervised algorithms can be prohibitively expensive as they demand large manually-labelled corpora for training. 3 However, the LSS can reduce the cost of training models dramatically because it only requires a small set of seed words for training (Watanabe, 2020). LSS can recognize the diverse temporal features because it employs the word embedding technique to assign temporality scores to all the documents in a corpus without manual labels. Although these scores do not necessarily correspond to their positions on the timeline, they can identify texts about the future in binary classification.
Algorithm of semantic temporality analysis
LSS has been developed to estimate the polarity of texts (e.g., sentiment), but it can estimate the temporality of texts too with small modifications because time is only another dimension with polar ends. Changes are (1) a smaller number of word vectors that we yield from latent semantic analysis; and (2) artificial columns in document-term matrix to record co-occurrences of seed words in the same sentence. 4
Defining temporal seed words
Users of LSS usually select seed words that have opposite lexical content to identify polarity of texts (e.g., “good” or “bad” for sentiment analysis), but our seed words only have grammatical functions. We use a set of common verbs in the past tense and the future tense such as “will give,” “going to give,” or “have given” as seed words to identify temporal orientation of texts relative to the time of speech (i.e., deictic reference). Our temporal seed words consist of combinations of an auxiliary verb and a main verb. We choose the simple future tense for prospectiveness but the past perfect tense for the retrospectiveness because verb forms are less ambiguous in the past perfect tense than in the simple past tense.
Nevertheless, the standard LSS cannot recognize combinations of an auxiliary verb and a main verb because a document-feature matrix (DFM) records their occurrences separately (i.e., bag-of-words representation). Therefore, we engineer special features for temporal seed words based on their occurrences in the same sentence (i.e. skip-grams).
5
For example, “The economy has weak regulations.” (Text 1) does not receive any special feature because “has” alone does not make the sentence in the past perfect tense; “Has the economy given rise to inequality?” (Text 5) receives “given/past” because the cooccurrence of “has” and “given” constitutes the past perfect tense (Figure 1). We added the newly created columns to the DFM and removed the original seed words from it. Illustration of how columns for temporal seed words are constructed. The table on the left is the original DFM; the table on the right records the frequency of temporality seed words.
Computing temporality scores
Once columns for seed words are created, we can compute temporality scores in the same way as polarity scores. LSS performs singular-vector-decomposition (SVD) of a DFM to estimate the semantic proximity of words by reducing its dimension in a similar way to factor analysis. The number of singular vectors is usually around 200–300 for complex constructs, but we set the number to 100 for temporality scores to capture more basic semantic relationships. SVD is first applied to a document-term matrix


We compute the temporality score of a text

Evaluation of semantic temporality analysis
We define texts that mention the past or the present as retrospective and those that mention the future as prospective for the following reasons: (1) retrospective texts should be about events that have happened already, while prospective texts should be about events that haven’t happened yet; (2) even if a language has three tense forms (i.e., past, present and future), the present tense does not necessarily indicate concurrency to generated the texts (Klein, 1994). 6 This distinction is also consistent with the earlier study by Müller (2021).
We analyze election manifestos in English and German because various studies have been conducted using the texts in terms of the salience of policy issues and the ideological positions of actors (Dolezal et al., 2014; Gabel and Huber, 2000; König et al., 2017). For all those dimensions, the temporality of texts has important implications (Mayhew, 2004). We apply our technique to existing data that contains labelled and unlabeled sentences from election manifestos sampled from English-speaking countries (UK, Ireland, US, Canada, Australia, and New Zealand,) and German-speaking countries (Germany, Austria, and Switzerland). 7
We trained LSS with the temporality seed words on unlabeled English (n = 252,229) and German (n = 132,129) sentences with minimal feature selection.
8
Figures 2 and 3 show that words with large negative or positive temporality scores are much more diverse than common time-related words found in the “Time” category of the LIWC 2001 dictionary. Although the distribution of scores is skewed towards the past in English, many words received intuitively correct temporality scores in both languages. LSS uses all these diverse features to determine temporality of texts. Temporality scores of English words. The horizontal axis is the estimated temporality of words, while the vertical axis is their frequency in the corpus. Words found in the “Time” category of LIWC 2001 are highlighted. Retrospective “history,” “historically” and “past” are on the left-hand side, while prospective “continue,” “start” and “young” are on the right-hand side. Temporality scores of German words. The horizontal axis is the estimated temporality of words, while the vertical axis is their frequency in the corpus. Words found in the “Time” category of LIWC 2001 are highlighted. Retrospective “geschichte” (history), “historischen” (historic), “seit” (since), “mittlerweile” (by now) and “nachdem” (after) are on the left-hand side, while prospective “zukünftige” (future), “künftig” (coming), “endlich” (finally) and “fristen” (deadlines) are on the right-hand side.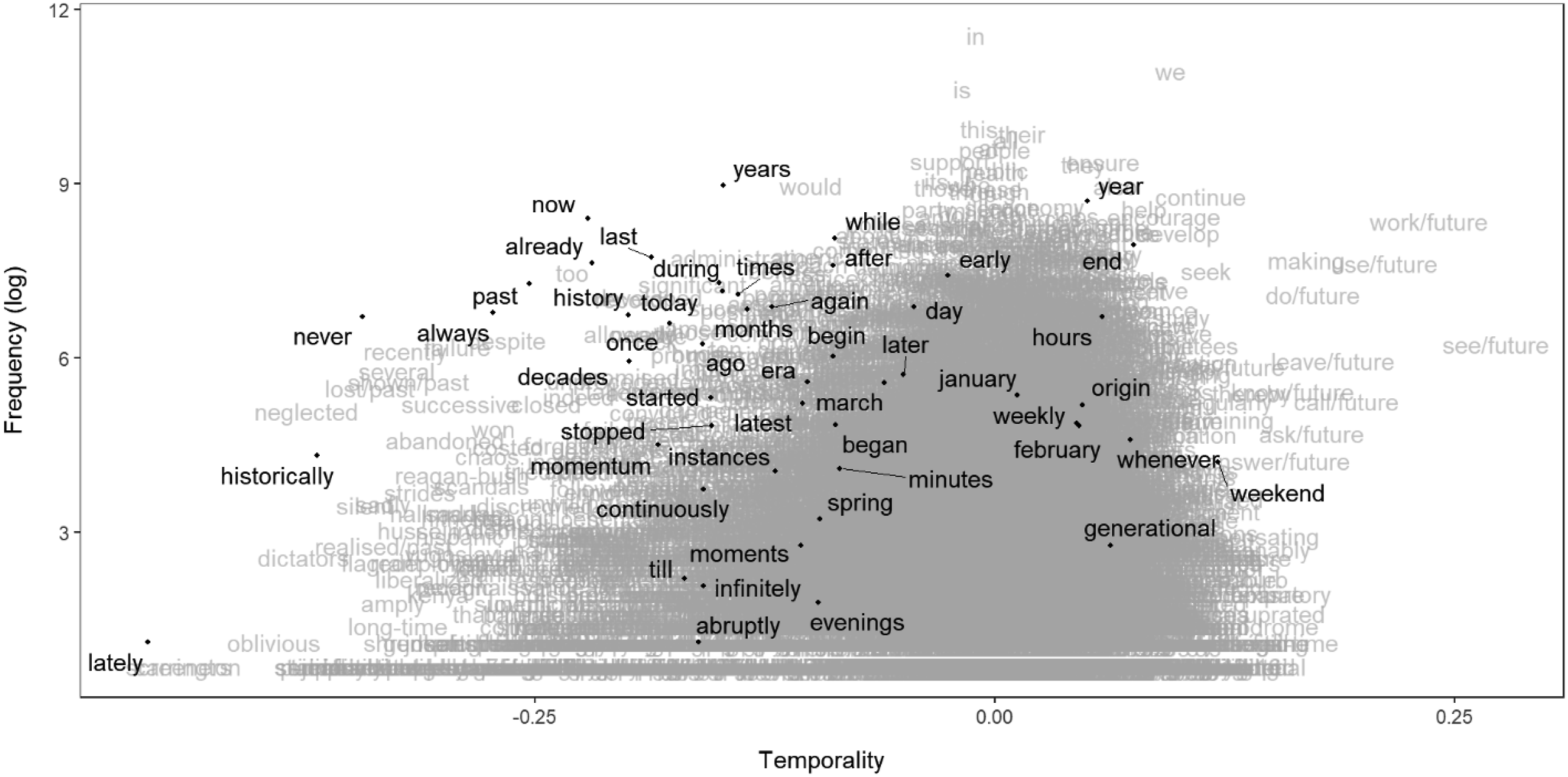

We predicted the temporality of labelled sentences in English (n = 5858) and German (n = 12,084) separately to evaluate the accuracy of the temporality scores of texts that we computed. 9 The labels of sentences are given by human coders based on the substantive temporarily regardless of the grammatical tense (Müller, 2021). Among all sentences 60% and 51% are labeled as “future” in English and German respectively. Although LSS can only determine if texts are retrospective or prospective with the current method, we present accuracy for all the available labels for the sake of transparency.
The upper plots in Figure 4 show that the proportion of sentences that are about the future increases as the temporality score rises. In English, when 0 < t ≤ 1.0, the proportion of “future” is around 0.7; when 1.0 < t, it exceeds 0.8 with the corresponding decrease in the number of “present” and “past” sentences. If we adopt the overall mean as the threshold 0 < t to distinguish between retrospective (“past” and “present”) and prospective (“future”), F1 scores is 0.70 (0.73 in precision and 0.67 in recall). In German, when 0 < t ≤ 1.0, the proportion of “future” is around 0.6; when 1.0 < t, it exceeds 0.7 with corroding decrease in other categories. If we adopt 0 < t as a threshold, F1 score is 0.63 (0.64 in precision and 0.61 in recall).
10
The relationship between the threshold and the accuracy is summarized in the lower plots, in which the Area Under Curve (AUC) scores are 0.59 in English and 0.58 in German. Accuracy of temporality scores of English and German texts. In the upper plots, the x-axis is the temporality scores (t) binned by the standard deviation; the y-axis is the proportion of texts manually labeled as about the future (red), present (black) or past (green) in each bin. The integers above the x-axis show the number of sentences in the bins. The lower plots show the false positive and true positive rates in identifying texts about future with varying thresholds (i.e., ROC curves); circles on the curve indicates threshold being 0 < t.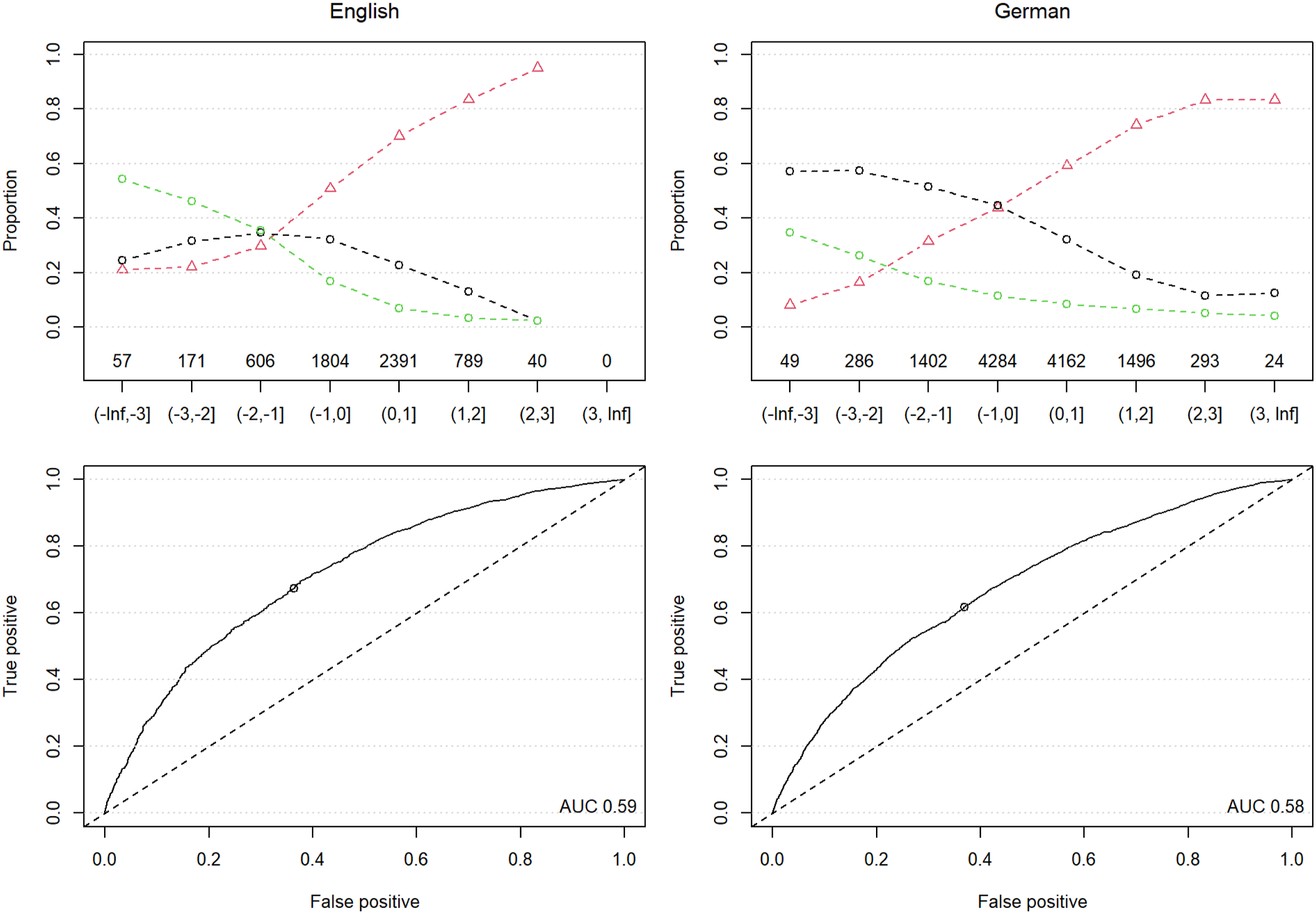
Use case: Analysis of tweets by german political parties
We apply semantic temporality analysis to the Twitter posts by political parties during the campaign period of the 2021 German federal elections to demonstrate its usefulness in political research. We trained LSS on unlabeled tweets (n = 1,038,831) with the temporal seed words and applied the model to identify temporality of its subset (n = 2043), which are manually labelled for policy areas. 11
Figure 5 shows that ‘education,’ ‘economy’ and ‘environment’ are the most prospective while the ‘domestic security,’ ‘foreign policy’ and ‘migration’ are the most retrospective. These results are intuitive because education, economy and environment are usually progressive agendas, while domestic security and migration are often conservative agendas; Germany foreign policy is oriented towards the status quo. We cannot present detailed analysis due to the lack of space, but it clearly shows that semantic temporality analysis has the potential to deepen our understanding of political completion. Average temporality scores of tweets. High temporality scores indicate policy areas are prospective. The vertical bars are the standard errors at the 95% confidence level. The integers above the x-axis are the number of tweets about the issues.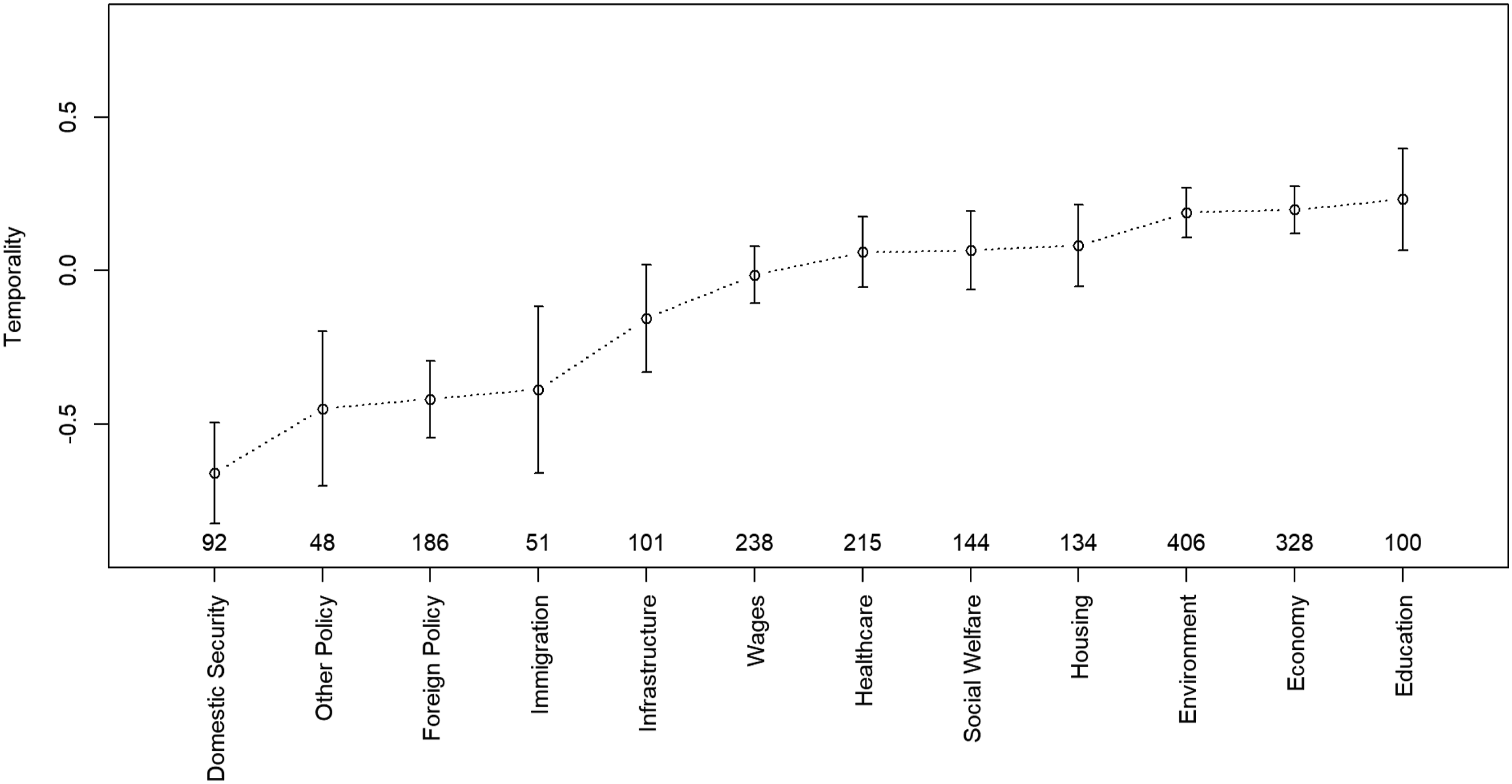
Discussion and conclusions
LSS can recognize various temporal features based solely on their semantic proximity to the temporal seed words. Our evaluation demonstrates that LSS can distinguish between retrospective and prospective texts between 60% and 70% correctly, which is comparable to the accuracy achieved using SVM in the earlier study (between 55% and 82%). This is surprisingly good considering the near-zero cost for training the LSS algorithm.
While temporality scores of German words are distributed symmetrically, English words are skewed towards the past. This suggests that these English verbs have greater strength as seed words for retrospectiveness than prospectiveness. It is presumably because the parties in the English-speaking countries rely on the future tense to make election manifestos more appealing, but those in German-speaking countries use the past perfect more carefully to refer to past achievements and collective memories as we can see in the lower number of sentences labeled as “future” in the German sentences (60% vs 51%).
Despite the skewed distribution of temporality scores of words, LSS identified temporality of texts more accurately in English than in German. F1 scores were the highest in identifying prospective English sentences, but they were much lower in identifying retrospective German sentences. Since this pattern is consistent with the earlier study, we believe that is caused by more complex tense forms of the language that makes temporal referencing, especially the past, less clear (Klein, 1994). 12
The result also highlights the advantage and disadvantage of the supervised and semisupervised algorithms: the former usually outperforms the latter but the later outprices the former when users can define target dimensions using seed words. For this, we engineered skip-gram seed words by combining an auxiliary verb and a main verb, both of which are otherwise too ambiguous as seed words. This technique allows researchers to define various dimensions more easily and expand the scope of text analysis with LSS.
Overall, we believe that our new approach to temporality of text is useful for various fields of political science that range from electoral studies, comparative politics, and political communication as demonstrated in the use case. However, there are remaining issues and questions that will open new avenues for exciting future research. First, tense-based temporality seed words worked well with both English and German languages, but such seed words are not available for Japanese, Arabic and Chinese, whose verbs have either fewer or no tense forms. 13 In analysis of such languages, we should use anaphoric or calendic expressions as seed words. Second, LSS produces continuous temporality scores, but they do not always correspond to the temporal distance of events mentioned in the texts. To make semantic temporality analysis more useful, we should assign large positive or negative scores to texts about events far in the future or the past.
Finally, we propose and urge researchers in politics and international relations to study temporal orientation of texts more using our cost-effective approach. If temporality analysis is combined with other analysis such as polarity analysis and topic classification, it will produce important information on how politicians and policymakers gain power or legitimacy through discourse.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.