
Abstract
Despite the number of problems that can occur when core model assumptions are violated, nearly all quantitative political science research relies on inflexible regression models that require a linear relationship between dependent and independent variables for valid inference. We argue that nonparametric statistical learning methods like random forests are capable of combining the benefits of interpretability and flexibility. Recent work has shown that under suitable regularity conditions, averaging over predictions made by subsampled random forests produces asymptotically normal predictions. After estimating the variance, this property can be exploited to produce hypothesis tests and confidence intervals analogous to those produced within a parametric framework. We demonstrated the utility of this approach by replicating an important study on the determinants of civil war onset and show that subtle nonlinear relationships are uncovered, providing a new perspective on these ongoing research questions.
Introduction
Most quantitative political science relies on parametric statistical models that require strict model assumptions for valid inference, usually that the dependent variable is linearly related to the independent variables. 1 Obtaining unbiased coefficient estimates in a linear model requires specifying the exact correct model form, including any possible interaction or higher-order polynomial terms. Uncertainty about the correct functional form provides researchers wide latitude in testing interactions and higher-order polynomials, which can sometimes create multiple-testing issues. In addition, subtle nonlinear relationships – even if they are monotonic and not curvilinear – between the response and a predictor can severely bias coefficient estimates (including flipping the sign) for variables that do have a linear relationship, as was shown in Achen (2005) over a decade ago. Despite these potential issues and the existence of flexible statistical and machine learning alternatives, applied political science research continues to rely almost exclusively on classical approaches in order to perform inference. This reliance on more rigid tools is likely due to the perceived lack of interpretability and conventional variance estimates that available within a more flexible learning context.
In this paper, we argue that nonparametric ensemble methods – random forests (Breiman, 2001) in particular – can naturally accommodate nonlinearity in the data. We demonstrate that recent theoretical and methodological developments allow for some degree of interpretability including the use of null hypothesis significance testing via the production of conventional variance estimates. There has been a substantial amount of work in recent years that has demonstrated useful and desirable statistical properties of random forests when individual trees (or, more generally, base learners) are built with subsamples of the training data. Scornet et al. (2015) demonstrated that random forests are consistent whenever the underlying regression function is additive. Wager et al. (2014) applied the infinitesimal jackknife estimate of variance derived in Efron (2014) in order to estimate the variance of random forest predictions. Mentch and Hooker (2016) demonstrated that predictions from subsampled random forests can be viewed as infinite-order forms of classical U-statistics and as a result, are asymptotically normal under certain regularity conditions. Here the authors provided a general set of conditions noting that any type of base learner (tree) that satisfies those technical conditions can be used. Peng et al. (2019) improved this result, weakening the necessary conditions somewhat and allowing larger subsamples to be used. Wager and Athey (2017) advocated for a particular class of base learners that conform to honesty and regularity conditions, meaning that trees are constructed on different data than that used to produce the estimates in the terminal nodes, and also that splits in the tree allow for a certain minimal percentage of observations to fall on each side. As most of these conditions are rather technical, in the following sections, we will use the phrase “suitably constructed base learners” to refer in general to any tree or other base learner that obeys the necessary conditions for asymptotic normality as put forth in the previous works just described.
Ultimately, these results provide a means by which the uncertainty in random forest predictions may be formally quantified. Variance estimates for the predictions made by subsampled random forests share the desirable properties of conventional variance estimates for linear models. These variance estimates can be used in a standard testing framework to evaluate hypotheses about the predictive significance of a variable. Though this more flexible approach comes with an increased computational cost, we stress that the perception that one must give up flexibility in the choice of model in order to interpret results and conduct inference is quickly becoming an outdated notion.
Since random forests are a nonparametric method, there is no testing of the significance of a particular term-specific parameter as is the case in standard parametric models like linear regression. Instead, the predictions themselves take the place of these conventional parameters. While testing whether a variable makes a significant contribution to predicting an outcome is not the conventional approach utilized in political science research, we argue that it is in line with fundamental scientific principles. Indeed, though perhaps more subtle, even within a traditional linear model context, terms are only deemed “significant” when their inclusion in the model creates a more accurate fit than could be expected by random chance. Since real-world data generating processes may deviate substantially from the assumptions of linear models, the prime justification of using linear models has been their interpretability. Our goal here is to demonstrate that recent developments are beginning to allow for an analogous means by which the same inferential questions can be asked and answered in flexible machine learning contexts.
We note that variables with strong predictive power may not be statistically significant when included in a linear model if their relationship to the dependent variable is nonlinear and that nonlinearity is not taken into account in the model specification. To demonstrate the utility of our approach, we replicated Fearon and Laitin’s (2003) (FL) central model, testing whether gross domestic product (GDP) or fractionalization is more important for explaining civil war onset. FL’s work has led many scholars to debate the relevance of ethnolinguistic fractionalization (ELF) and religious fractionalization on civil war onset after they contradicted the conventional wisdom by presenting models where there was no statistically significant effect of these variables. Our tests showed that both ELF and religious fractionalization are statistically significant when tested individually. 2 We suggest that one reason for this difference is the nonlinear nature of the relationship between fractionalization and conflict onset.
Our main contribution in this article is to show that random forests can be used for inference, and to demonstrate that hypothesis testing using random forests can produce results analogous to the hypothesis tests typically conducted with simpler parametric models. The implication is that the perceived gap between the interpretability and inferential utility of linear parametric models and nonlinear nonparametric models is smaller than most presume.
A statistical context for random forests
We now begin to define the random forest procedure with more mathematical formality. Suppose we have data of the form
Now consider a new location (set of feature values)

where
In order to perform statistical inference on the predictions from a random forest, we must be able to say something about the distribution of
While some work has been done to investigate more computationally friendly approaches (see Sexton and Laake (2009) for one such popular example), recent results have provided a more direct approach. In particular, Mentch and Hooker (2016) showed that for suitable base learners, so long as the subsample size k grows slow relative to the training set size n, random forest predictions are asymptotically normal with mean

where
Confidence intervals for random forest predictions
Given this central limit theorem and feasible methods for estimating the variance, pointwise confidence intervals for random forest predictions may be readily constructed by simply estimating the parameters associated with the distribution and pulling out the desired quantiles. Importantly, we pause here for a moment to stress that such confidence intervals are valid for and centered at the expected prediction from a random forest and not necessarily the true value of the underlying regression function. In general, in order to guarantee probable coverage of the true value, stronger conditions on the base learners are needed; see Wager and Athey (2017) and Peng et al. (2019) for more details. For more general classes of base learners, if we consider the generic regression setup whereby
At first glance, this fact may seem disappointing and even appear to make such intervals prohibitive to practical usage, at least without strong conditions on the base learners. Note however that while perhaps more subtle, similar restrictions exist even with simple and more traditional statistical models. Consider, for example, the linear model whereby we assume a relationship of the form

For low dimensional problems (
Hypothesis testing with random forests
In addition to providing confidence intervals for predictions, Mentch and Hooker (2016) also provided a means by which formal hypothesis tests for feature significance can be carried out. Following the previous notation, assume that we have a total of p features

as the difference in predictions between the two forests in order to form
Due to the inherent volatility of tree-based estimators, the authors note that this procedure may sometimes produce a high number of false positives depending on the structure of the data. That is, because trees in random forests are typically grown to near maximum depth, even noise features (with no true relationship to the response) can alter predictions enough to be considered significant. As a robust practical workaround to remove this susceptibility, Mentch and Hooker (2016) recommend using a permuted version of
These procedures naturally extend to more general hypothesis tests. To test whether a group of features is significant, each feature in that group can simply be removed or permuted in the reduced random forest. Furthermore, in follow-up work, Mentch and Hooker (2017) showed that when the set of test points
Replication
In the previous section, we discussed the fact that for suitably constructed base learners, predictions from random forests follow an asymptotically normal distribution. This allows for confidence intervals to accompany predictions and also allows us to conduct hypothesis tests for whether an independent variable contributes significantly to the prediction of the dependent variable. This has important implications for political science research. If the linear or otherwise model-specific assumptions in standard parametric models are violated, then both the coefficient estimates and confidence intervals are biased. Random forests make no such model-specific assumptions about the functional form. This section uses random forests to make inferences and conduct significance tests by replicating FL’s seminal paper on civil conflict.
Finally, we stress the importance and role of the test and training sets in conducting the aforementioned hypothesis tests. Unlike traditional linear models, the significance tests are conducted on held-out test data – a subsample of the original dataset not used to train the model. This reduces concerns about overfitting in the trained model but also means that results can sometimes depend on the particular test locations chosen. To mitigate this effect, large test sets can be used in conjunction with more efficient procedures as in Coleman et al. (2019). Alternatively, tests can be performed across multiple train–test splits and results combined to form a more robust procedure. Meinshausen et al. (2009) provided one such means of combining results, and more efficient and general procedures are currently being developed in the statistics and machine learning community.
Civil conflict onset
One of FL’s more notable arguments is that the share of mountainous terrain is an important predictor of civil conflict onset, while markers of ethnic and religious fractionalization are not significant predictors. Using random forests with the accompanying variance estimates on their dataset suggests one reason why these results were produced: the marginal relationship between both ELF and religious fractionalization on civil conflict onset appears to be highly nonlinear.
We examined the data using the methods already outlined. We present the marginal relationship between the dependent variable and an independent variable using predicted probability plots – the change in the predicted probability of the dependent variable taking on a particular value while holding all other variables at their mean – in Figure 1 for all continuous covariates in FL’s main models. 3 For all predicted probability plots, the variance estimates of the predictions from our random forests model are included.
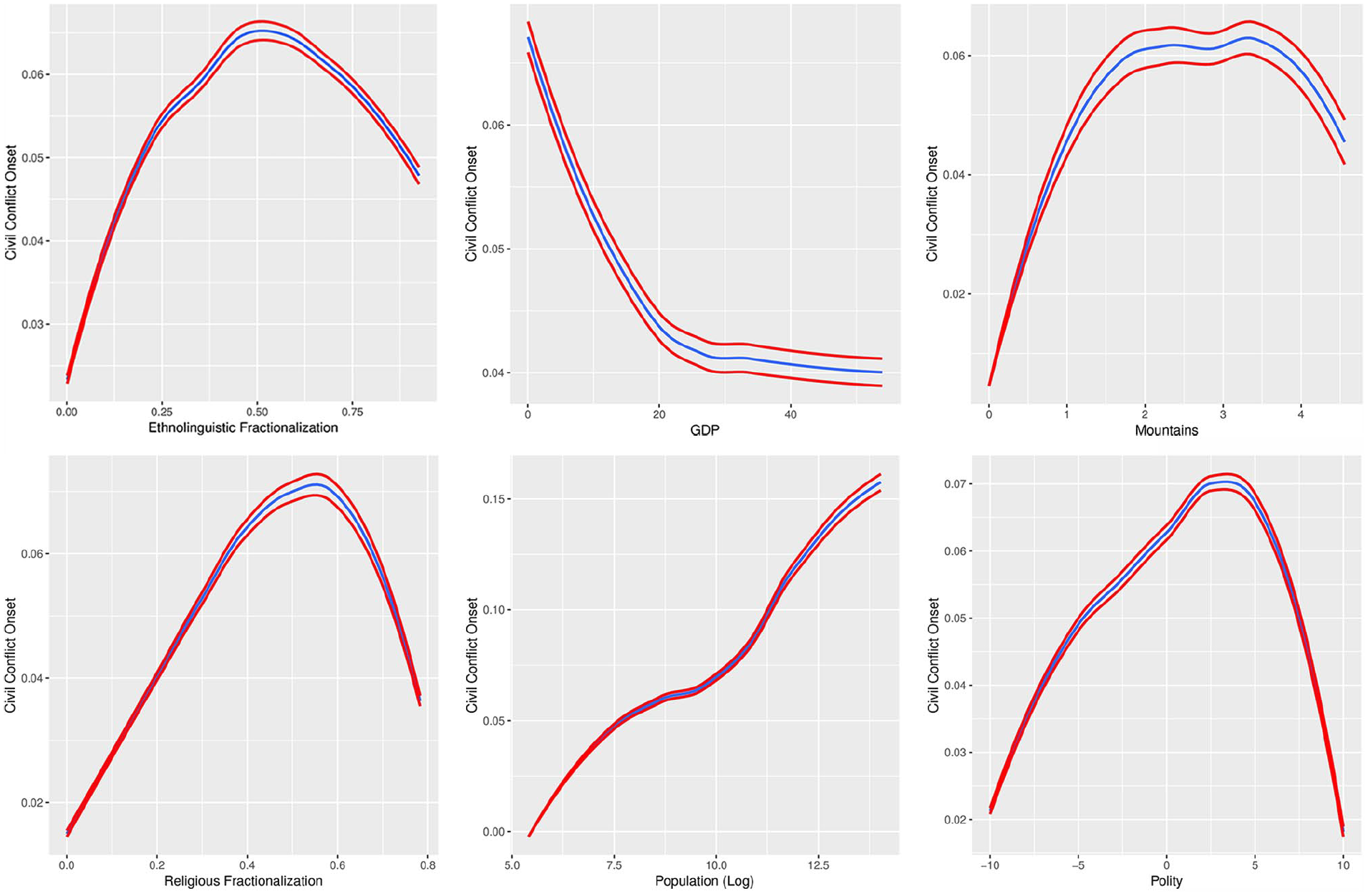
Marginal effects of a change in an independent variable on the likelihood of civil conflict onset. The blue lines represent the LOESS smoothing estimate of those predictions, while the red lines represent LOESS smoothed 95% confidence intervals for those predictions.
From Figure 1, we see that GDP and population appear to have relationships to conflict onset that are at least monotonic and close enough to linear that we would expect such a signal to be captured in a standard linear model. The figure also suggests that a reasonable functional form for the effect of a country’s polity score is also specified in FL’s models, since the random forest output shows a roughly quadratic relationship.
When we turn to the marginal effects of ELF and religious fractionalization, a more complicated picture emerges. The plots for these variables show a curvilinear and nonmonotonic relationship. For both fractionalization measures, there is a positive and largely linear relationship when both variables are at the lower half of their range of values. When the variables take on values above
We now use the method described in “Hypothesis testing with random forests” to test whether ELF or religious fractionalization are statistically significant predictors of civil conflict onset. As already described, this is performed by constructing two large random forests built on proper subsamples of the training data – one where the variables we are interested in testing are randomly permuted, and one where the data are undisturbed – and comparing predicted values at various locations throughout the feature space. Extracting the variance estimates allows us to compute a p-value to determine whether the models constructed with these different training sets produce significantly different predictions. 4
The results of these hypothesis tests for the predictive significance of individual variables are presented in Table 1. The results show that several of the variables achieve marginal predictive significance at conventional (
P-values for marginal predictive significance for a number of predictors of civil conflict onset.

This random forest testing procedure is also capable of conducting joint significance tests for predictive importance. This is conducted in the same way as testing whether one variable is significant: we simply permute the values of the entire set of predictor variables we want to jointly test, and then compare random forest models trained on the original data with models trained on data where the values of those variables have been randomly permuted. This is an important follow-up step for variables that appear to have qualitatively similar marginal relationships to the response variable. Indeed, in an analogous fashion to linear models, when two highly correlated predictors are available, it is entirely possible that neither looks marginally important since the other can be used to uncover the same signal. We carried out this test for both religious fractionalization and ELF, since these variables have similar effects according to the predicted probability plots. The resulting p-value was 0.00003. We note that, quite importantly, a joint significance test for these same variables in a logit model produces a p-value of
Conclusion
Random forests are often considered the best off-the-shelf black box algorithm for making accurate predictions. They can readily accommodate missing values, nonlinear relationships, interactions, and a large numbers of covariates. A number of studies have used random forests to predict the onset of civil or interstate wars (Muchlinski et al., 2015). We have argued here that the superior predictive performance of random forests can be harnessed to examine the same kinds of relationships in the data that political scientists typically seek to uncover with conventional parametric models, including making inferences about the marginal effect of independent variables.
A nonparametric approach that retains the ability to conduct valid inference opens up a number of possibilities for political scientists. In addition, advances in plotting the results of random forests can enable researchers to present results about how variables interact without specifying the functional form (Goldstein et al., 2013). To ensure comparability, we chose to replicate a study that did not use fixed effects or clustered standard errors. Future research should explore how random forest models can incorporate dependence between observations. Predictions from random forest models have also been shown to be effective when used in multiple imputation for missing variables (Tang and Ishwaran, 2017). As our exploration of the relationship between ELF and religious fractionalization measures and civil conflict onset show, the full benefits of nonparametric methods in general and random forests in particular have yet to be utilized by political scientists.
Supplemental Material
Appendix – Supplemental material for Predictive inference with random forests: A new perspective on classical analyses
Supplemental material, Appendix for Predictive inference with random forests: A new perspective on classical analyses by Richard J. McAlexander and Lucas Mentch in Research & Politics
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental materials
Notes
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from the Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.