
Abstract
Dyadic data from the United Nations High Commissioner for Refugees (UNHCR) on the size of the global refugee population are widely used. However, for a large fraction of the refugee population, these data provide no information about refugees’ country of origin, which contributes to a high nominal rate of unreported values in the data. In this article, I demonstrate that two imputation approaches outperform the current standard approach, which assumes that all unreported values are zero. The first approach interpolates the unreported values, while the second predicts them based on trends observed in other dyads. Drawing on different types of information, the two approaches’ performance is similar. Replicating a published study on the effect of refugee crises on international war and peace, I demonstrate how both approaches strengthen the author’s findings and help to minimize the risk of a null finding.
The United Nations High Commissioner for Refugees’ annual dyadic data on the stock of refugees have been widely quoted in the media and used in various studies in political science (e.g. Barthel and Neumayer, 2015; Bermeo and Leblang, 2015; Salehyan and Gleditsch, 2006). Unfortunately, the UNHCR reports annual refugee counts for a host-origin country dyad only when there is at least one refugee. On the one hand, the unreported value could be a zero, suggesting that not a single individual has fled from the country of origin to the host country. On the other hand, even in the post Cold War years, about 7% of the entire refugee population are uncategorized in the sense that the data provide no information about their country of origin. This suggests that at least some of the unreported values are not true zeros.
Analysts using the UNHCR dyadic data regularly acknowledge this problem but assume that the refugee counts are zero in all unreported years. This approach leads to two problems: descriptively, the dynamic of the refugee counts is distorted, which makes the time series seemingly more volatile than it is; and, due the introduced measurement, studies which use hese data to construct explanatory variables are at risk of biased estimates (Carroll et al., 2006). For example, in a simple bivariate linear regression model with classical measurement error, coefficient estimates are biased toward zero (Spearman, 1904).
In this article, I demonstrate that interpolating a dyad’s unreported values based on observed years of the same dyad, as well as predicting a dyad’s unreported values based on observed values in other dyads, outperforms the current standard approach of assuming that the unreported refugee counts are zero. The linear interpolation approach imputes unreported values based on the straight line that connects the two observed values which enclose the unreported values. The least-squares (LS) prediction approach capitalizes on the least absolute shrinkage and selection operator (LASSO) to predict the observed values of a dyad from a linear combination of a subset of all other dyads. After fitting, the unreported values are filled in, based on an out-of-sample prediction.
I compare the imputation accuracy of the standard approach (which is always to impute zero), the interpolation approach, and the LS prediction approach. When comparing observed and imputed values across 500 simulated dyadic datasets, I find that both approaches considerably improve the imputation accuracy relative to the standard approach, cutting, for example, the root-mean-square error (RMSE) in half. Interestingly, while both draw on different sources of information, their performance is quite similar. When applied to the actual dyadic data I find that the interpolation approach over-predicts the annual global refugee population relative to the LS prediction approach to a certain degree.
Lastly, I demonstrate that the choice of imputation method is consequential for typical political science studies. Replicating a study that uses the UNHCR total refugee count (Salehyan, 2008), I show that the author’s estimates exhibit a downward bias, which is consistent with the notion that the measurement error in explanatory variables tends to attenuate coefficient estimates of regressions, increasing the risk of a null finding. To aid future studies, an imputed dataset—the World Refugee Dataset (WRD)—is made available (Marbach, 2018). While empirical research typically uses these dyadic data, the imputed data can also be easily aggregated to a monadic dataset.
This article considers the imputation of a dataset for a single indicator. An alternative strategy would be, of course, to only impute the values once the final dataset for a particular regression analysis has been assembled (e.g. using the approach of Honaker and King (2010)). However, often, users are not only interested in using the UNHCR data as an independent or dependent variable in a regression analysis directly, but also (a) to describe the size of (regional) refugee stocks, and (b) to construct variables for a regression analysis that requires a complete dataset (e.g. ratios).
The UNHCR refugee data is not the only incomplete dyadic time-series regularly used in political science. For example, even trade flow data—relying on two reporting entities instead of only one as in the case of UNHCR data—is far from complete. The current practice with this data is to use interpolation (Barbieri et al., 2009). Future research might evaluate how well the LS prediction approach works with this data.
Missing information in UNHCR data
The UNHCR collects data on the number of individuals who have fled from one territory (origin) to another territory (host). The nominal coverage period of the publicly available data on the UNHCR website is from 1951 to 2016 (UNHCR, 2017). These data take the form of annual, directed, dyadic count data that contain information about three distinct types of forcibly removed individuals—refugees, returned refugees and, since 2000, asylum-seekers (see supplemental materials section A for details). The upper panel of Figure 1 plots the annual counts of displaced persons by category. The most relevant category is the refugee counts since they are typically used in studies.

Total displaced-person population (upper panel) and annual proportion of the population reported in the residual dyad (lower panel) as reported by the UNHCR and excluding Palestinian refugees under United Nations Relief and Works Agency for Palestine Refugees in the Near East (UNRWA) mandate. The residual dyad reports the stock of refugees whose country of origin is unknown or unrecorded.
One important practical problem with these data is that the dataset only contains a dyad if there is at least one refugee to report. That means that there is no refugee count for all unlisted dyads in the dataset. This reporting practice means that conceptually, users of the data can not distinguish between dyads where there has not been a single refugee (true zero values) and dyads where the UNHCR was either unable to obtain information or decided not to report a count (missing values). Everyone using the dyadic data in a regression analysis necessarily has to decide how to impute the dyads that are left unreported. The standard approach is to impute a zero count (e.g. Barthel and Neumayer, 2015; Bermeo and Leblang, 2015; Echevarria and Gardeazabal, 2016; Salehyan, 2008; Salehyan and Gleditsch, 2006).
However, this standard approach ignores the fact that in each year and for each host country, the data also contains a residual dyad labeled “Various/unknown country of origin.” 1 In earlier years, the majority of the refugee population was reported in the residual dyad (see figure 1, lower panel 2 ), but even during the post Cold War era, on average, about 7% of the annual refugee population is reported in the residual dyad. While the UNHCR provides almost no information about how it collects its data or about the nature of the residual dyad, the existence of the residual dyad in the available dataset suggests that the refugee stock in at least some of the unreported dyads can not be zero. Therefore, the standard approach is unsatisfactory, in particular when it comes to more historical refugee counts.
Interpolation and LS prediction are two alternative strategies to impute the unreported counts. Based on either within-dyad information (interpolation) or information from other similar dyads (LS prediction), one allows at least some unreported counts to be larger than zero (but possibly some are predicted to be zero). Below I evaluate the performance of the two alternative approaches relative to the all-zero assumption using two complementary strategies. In the first evaluation, I compare the imputation performance across 500 simulated datasets. In the second, I compare the annual global refugee population estimates based on the imputed data with that of the raw data that also includes the residual dyad (benchmark estimates). The better imputation approach is expected to predict the benchmark estimates more accurately.
In principle, it would be desirable to conceive an imputation approach that actively uses the information about the size of the residual-dyad stock to improve imputation accuracy. However, this is challenging, since the imputation problem is not merely about distributing the residual-dyad stock across all unreported origin-host dyads. After all, each residual dyad also contains an unknown share of refugees that belong to a dyad for which the dataset reports a refugee count.
The previous paragraph points to a second problem with the UNHCR data. While the UNHCR collects information in host countries only and relies more often on its own data collection than on government reports (see SM-A for details), some reported refugee counts are most likely not entirely accurate (Crisp, 1999). While this manuscript focuses on imputing the unreported refugee counts—assuming that reported counts are accurate—future research might explore how the measurement accuracy of reported counts can be improved.
For the rest of the article, I focus on imputing the post-Cold War refugee counts (1989–2015), ignoring the Cold War period for which the rate of unreported values appears to be too high to obtain a sensible complete dataset. I supplement the UNHCR data with the annual counts of Palestinian refugees in the study period obtained from United Nations Relief and Works Agency for Palestine Refugees in the Near East (UNRWA) in personal communications. They are by definition excluded from the UNHCR data due to UNHCR’s limited mandate for Palestinian refugees. I also harmonize the territories in the UNHCR data, such that each dyad is made up of states as defined in the Correlates of War Project (Correlates of War Project, 2016) (for details, see SM-B).
Predicting unreported values
I consider interpolation and LS prediction as two simple but effective alternatives to the standard approach to imputing zero. The linear interpolation approach imputes unreported values based on the straight line that connects the two observed values which enclose the unreported values. When the unreported values are located at one end of a dyad’s time series, this approach imputes the last observed value. This approach is computationally quite inexpensive and capitalizes on the information from a single dyad.
The LS prediction approach actively uses information contained in other dyads. The general idea is to find the linear combination of other dyads that best predicts the observed values of the target dyad, and then use this combination to predict the unobserved values. Let

Since typically, there are more dyads (predictors) than observations, I use the LASSO for regularization. By augmenting the LS objective function with a penalty term (as defined in equation 1), the LASSO effectively selects the subset of dyads whose linear combination predicts the observed value of the target dyad and shrinks all other coefficients to zero (Tibshirani, 1996). Following the literature, I choose a regularization parameter
I make two adjustments to the LS predictions that are motivated by qualitative inspections of the imputation results in earlier pilot analyses. First, I reset predicted values smaller than zero to the natural limit of zero. Second, in instances of extrapolation—that is, for unreported values at the two ends of a count series—I reset the predictive values to the last observed value if the predicted values exceed the last observed value. The latter adjustment seems warranted against the background of UNHCR data collection practices. We would expect that larger counts have a higher reporting probability than smaller ones. It is beyond the scope of this article to explore if and how these two adjustments can be directly integrated into the LS objective function.
Comparing imputation accuracy
To evaluate how well these alternative approaches perform relative to the assumption that all unreported values are zero, I subset the data to contain the 260 dyads for which all values are reported. I then generate 500 copies of this dataset, replacing some reported values with missing values. To create realistic missing-data patterns, I randomly sample missing-data patterns observed in other dyads. Next, I impute the unreported values with the standard and the two alternative approaches. I summarize the difference between imputed and observed values for each dataset using the RMSE and its complement, the median-absolute error (MAE). In addition, I report the Pearson correlation coefficient
Table 1 summarizes the mean and the standard deviation for each evaluation metric across the 500 datasets. Both interpolation and the LS prediction approach considerably improve upon the all-zero imputation approach. While the RMSE decreases by 49% (LS prediction) and 51% (interpolation), the MAE decreases by 39% (LS prediction) and 36% (interpolation). The performance of the interpolation approach and the LS prediction approach are quite similar in this evaluation. Interpolation outperforms the LS prediction approach to a certain extent when it comes to the RMSE and the correlation coefficient but not when it comes to the MAE. Since MAE is least sensitive to the variance of the error distribution (the difference between observed and imputed values) these results suggest that the LS prediction approach minimizes the average error at the cost of higher variability.
Evaluating three approaches of imputing total refugee counts. Each row reports the mean and standard deviation of the three out-of-sample imputation accuracy metrics that are estimated based on 500 simulated datasets. Since the all-zero imputation approach imputes the same value, the correlation coefficient is undefined.

Next, I apply the LS approach to all host-country dyads with at least three observed and distinct values. 4 See supplemental materials Figure SM-SI-2 which illustrates the imputation results for four selected origin countries.
To systematically evaluate the overall plausibility of the imputed dyadic dataset, I aggregate the imputed dyadic data to obtain estimates of the annual global refugee population. I compare these aggregate estimates with the benchmark estimates from the raw data that also include the residual dyad. A perfectly imputed dataset would result in counts of the global refugee population that are at most identical to the benchmark estimates and in particular, they should not exceed the benchmark estimates.
Figure 2 confirms that both approaches work well. While the estimates from the LS prediction and interpolation approach are not perfectly aligned with the benchmark estimates, they are much closer compared to the estimates imputed with all-zero assumption. The MAE for the scaled counts that are based on the imputed dataset is about 0.15 (interpolation) and 0.17 (LS prediction), while it is about 0.37 for the counts that are based on the all-zero assumption. However, it is noteworthy that interpolation overshoots more often than the LS prediction approach (see in particular the estimates for 1991 in Figure 2). Hence, one may regard the LS imputed data as the more conservative imputation.
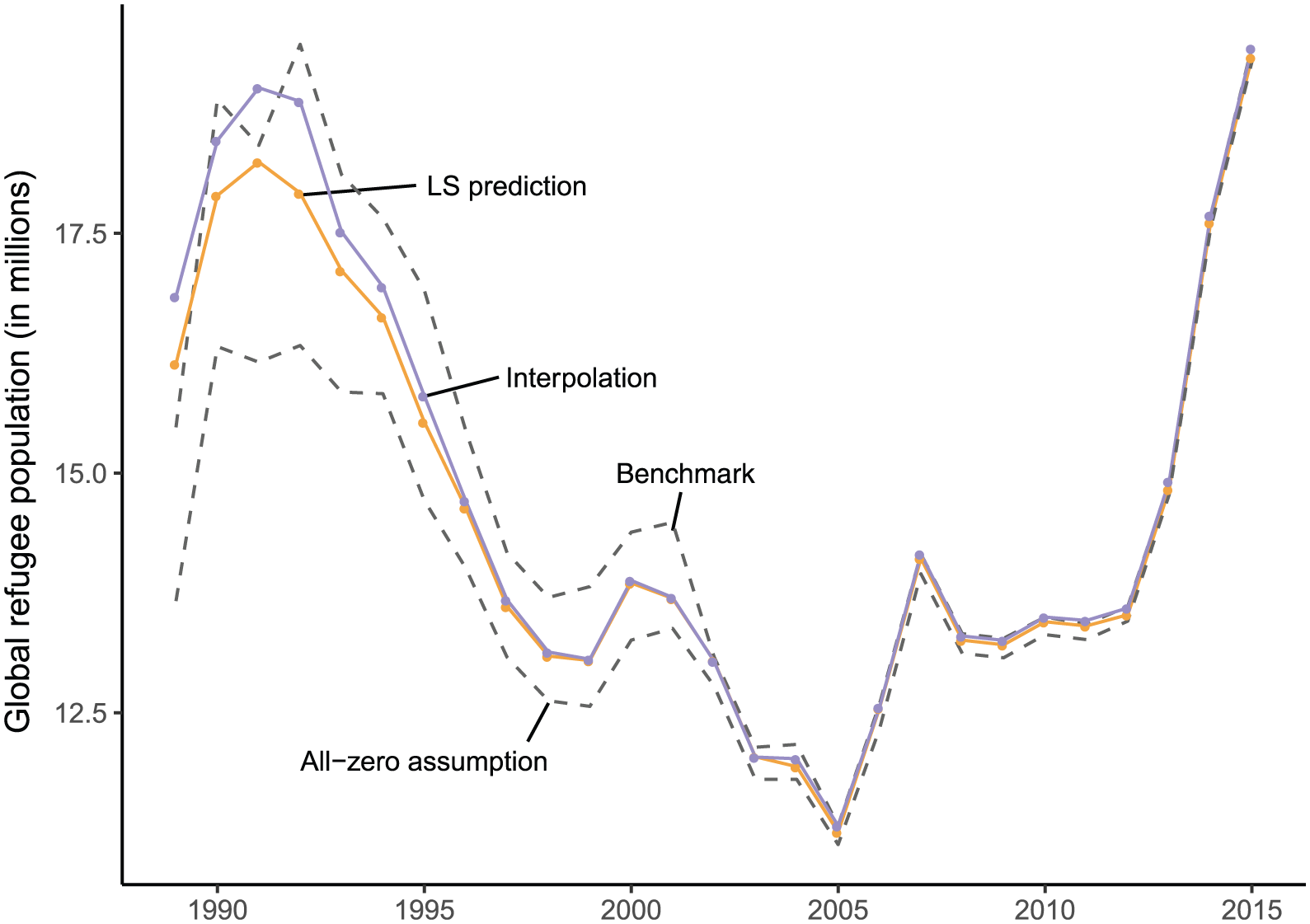
Comparison of estimates for the total global refugee population, excluding those in and from micro-states. The benchmark estimates are calculated based on the raw data and include the residual-dyad stock not attributable to any particular origin country. The other estimates are based on imputed data which include only refugee stocks attributable to specific countries of origin.
Both approaches have one drawback that they share with the standard approach of imputing zeros: They do not provide users with a measure of imputation uncertainty that could be used to proliferate into subsequent regression estimates similar to how multiple imputation uncertainty is typically proliferated. While interpolation is deterministic, one could in principle construct prediction intervals for the LS predictions. However, there is little agreement in the literature as to how to calculate valid standard errors or prediction intervals for the LASSO estimator in general (Hastie et al., 2009). The best users can do for now is to run their analyses based on both interpolated data and data imputed based on the LS prediction approach, and evaluate how sensitive their substantive conclusions are to the imputation method.
Correlates of refugee crises
To demonstrate that the imputation approach makes a difference, I replicated an analysis, published in the American Journal of Political Science, of how refugee stocks correlate with international war and peace (Salehyan, 2008). Salehyan studies whether large refugee stocks increase the chances of host and origin countries being caught in a military dispute with each other. His main finding is that dyad members that host (send) large numbers of refugees from (to) the other dyad member are more likely to initiate a militarized interstate dispute against the other dyad member.
The study uses a time-series cross-section probit analysis of militarized interstate disputes between the years 1955 and 2000. Restricting the analysis to politically relevant directed dyads, the dependent variable takes the value “1” if a country initiated an intrastate dispute against the other dyad member. The primary variable of interest is the size of the refugee population migrating from one dyad member to the other, and vice-versa. The author argues that both the size of the refugee population that leaves a dyad member, as well the size of the refugee population that enters the same dyad member, increase the probability that this dyad member will escalate a dispute. Acknowledging the all-zero assumption, the author uses the UNHCR data available at the time and supplements them with information on Palestinian refugees from the United States Committee for Refugees and Immigrants.
The replicated results for the main model appear in Table 2, column 1 (for the full table see Table SM SI-1). In the second column of Table 2, I dropped all dyads that either refer to the period before 1989 or those that include at least one micro-state. In the third column, I replaced the original refugee variable with the LS imputed version and in the fourth column I replaced it with the interpolated version. The point estimates increase for both approaches: For the LS prediction approach, coefficients increase by 17% and 39%, and for the interpolation approach coefficients increase by 22% and 26%. Encouragingly, the estimates in this application do not differ significantly between LS prediction and interpolation.
Probit coefficient estimates and cluster-robust standard errors (

Table SM SI-2 reports the average marginal effects for which the increase in percentage terms is similar in magnitude, which suggests that these changes are also substantively meaningful. For example, the all-zero imputation estimates suggest that an increase of 1000 refugees (about 6.9 on the log-scale) in the initiator increases the risk of a dispute by 1.1%. The estimate based on the LS prediction approach is 1.3% and thus about 19% higher.
While it is difficult to obtain formal results for how measurement error in covariates affects coefficients and marginal effects in non-linear models, the previous finding is consistent with the well-known result of the measurement error in simple linear regression models: measurement error in one variable attenuates the respective regression coefficient. 5 While none of the study’s substantive conclusions are affected, this might not always be the case. Using the all-zero assumption increases the risk for a null finding, especially for studies that investigate small effects and are of lower power to begin with.
Conclusion
The UNHCR provides a popular dataset of annual, global refugee counts. However, for a large proportion of the refugee population, the data provide no information about refugees’ country of origin which contributes to a high nominal rate of unreported values in the dyadic data. In this article, I demonstrated that using interpolation or LS prediction is superior to the current standard approach of assuming that all unreported values are zero. Both approaches improve upon current standard practice, leading to complete and more accurate data about the dynamic of the refugee counts for host-origin dyads and data that minimize the risk of null findings.
Future work might explore other approaches to improve the imputation accuracy. One direction would be to model the dynamics within each dyad and borrow information about these dynamics across dyads using a hierarchical model. This is challenging, though, due to three features of the data. First, the time series are typically short (at most 26 years for the post Cold War period). Second, the smaller the counts, the less smooth the time series. Third, the count distribution is highly skewed, which affects simulation-based inference algorithms negatively that are typical used to fit hierarchical models.
Another way to improve predictions would be to gather additional qualitative information to help distinguish between true zeros and missing values. This is particularly important for the Cold War years, for which the share of the refugee population reported in the residual is quite high. An effort should be made to survey the UNHCR archives, which appear to harbor an enormous wealth of information that is not included in the online database. Further information could be obtained from the United States Committee for Refugees and Immigrants and other non-governmental organizations.
Supplemental Material
sm_1 – Supplemental material for On imputing UNHCR data
Supplemental material, sm_1 for On imputing UNHCR data by Moritz Marbach in Research & Politics
Footnotes
Declaration of Conflicting Interest
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Supplemental materials
The replication files are available at https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi%3A10.7910%2FDVN%2FR8EJWA&version=DRAFT.
Notes
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from the Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.