
Abstract
Serious election forecasting has become a routine activity in most Western democracies, with various methodologies employed, for example, polls, models, prediction markets, and citizen forecasting. In the Netherlands, however, election forecasting has limited itself to the use of polls, mainly because other approaches are viewed as too complicated, given the great fragmentation of the Dutch party system. Here we challenge this view, offering the first structural forecasting model of legislative elections there. We find that a straightforward Political Economy equation managed an accurate forecast of the 2017 contest, clearly besting the efforts of the pollsters.
Introduction
Election forecasting has become a thriving discipline in the United States, as evident from the sheer number of competing models published in articles and symposia in the run up to presidential elections since 2004 (e.g., Campbell, 2004; Lewis-Beck and Stegmaier, 2014). While election forecasting based on statistical models originated in the US, the method has traveled to other advanced democracies (for an overview, see Lewis-Beck, 2005) as well as newer democracies (Lewis-Beck and Bélanger, 2012). The structural forecasting models that have been developed for these different contexts are generally based on the assumption that economic conditions affect the incumbent’s performance. Most models hence include an economic indicator as a key variable in predicting the incumbent’s vote and/or seat share. The accuracy of those forecasts varies from one model to another and from election to election. Overall, structural forecasting models perform quite well and give valuable insights regarding the importance of fundamentals for explaining elections and voting behavior (Wlezien and Erikson, 2004).
In contrast to public opinion polls that are published in the last weeks before Election Day, structural forecasts give a good sense of parties’ odds much earlier in the election season. Their lead time renders structural models extremely valuable for journalists and researchers, not to mention party strategists (Linzer, 2014). Poll aggregators acknowledge the value of structural models, and some of the most prominent poll aggregators integrate a historical model with information from public opinion polls (Linzer, 2013; Silver, 2016). Considerable evidence shows that combining polling information with a structural regression model offers more accurate predictions (Graefe et al., 2014; Rothschild, 2015). As a result, even in situations where rich and good polling data are available, it is worth developing models that predict election outcomes based on the fundamentals only.
While structural models have been formulated for almost every democracy in Western Europe 1 , no such models exist for the Dutch case. The highly proportional electoral system, the highly fragmented party system, and the recent surge in electoral volatility in the Netherlands (Mair, 2008) render the Netherlands a hard case for predicting elections by means of a structural model. It is improbable, however, that Dutch voters are completely unaffected by the fundamentals, as the large and varied set of countries for which models have previously been developed has led to the suggestion that ‘democratic electoral processes tend to obey very similar rules from one country to the other’ (Lewis-Beck and Bélanger, 2012: 768).
In this spirit, we have built a structural model that allows ex ante forecasting of the vote share the Prime Minister’s (PM’s) party obtains in legislative elections in the Netherlands. Applying this model to the 15 March 2017 elections we predicted that the party of incumbent Prime Minister Rutte, the People’s Party for Freedom and Democracy 2 (VVD) would obtain 22.3% of the votes. The party obtained 21.3% of the vote (Kiesraad, 2017). Our model had an error of 1.0 percentage point, a remarkably accurate forecast that clearly outperformed the polls.
Elections in the Netherlands
Legislative elections in the Netherlands are organized under a highly proportional electoral system. The 150 seats in Parliament are allocated proportionally and members of parliament are elected in a single electoral district, without a threshold (Farrell, 2011). Each party that has about 0.67% of the vote wins one or more seats in Parliament. Such a high level of proportionality 3 , at first sight, seems the perfect recipe for a highly fragmented party system and high levels of electoral volatility. However, as has been pointed out by Mair, it is only ‘when depillarization came into effect that the real effect of [the openness of the electoral system] kicked in’ (Mair, 2008: 235). In the 1950s and 1960s, citizens in the Netherlands identified strongly with particular societal ‘pillars’, such as the socialist or the religious pillar. Citizens, rather automatically, voted for the party that defended the interests of ‘their’ pillar. As these pillars have crumbled, however, so have loyalties to political parties (Andeweg and Irwin, 2014). As a result, the Dutch electoral context has basically evolved from one of the most stable systems in Europe to one of the most volatile electoral contexts (Mair, 2008). The traditional ‘pillar’-parties in particular have suffered from this trend towards depillarization. Combined, the liberal, socialist, and religious parties easily obtained 70% of the vote in the 1960s and 1970s. By contrast, on 15 March 2017, the liberal VVD, the socialist PvdA and the religious CDA together obtained less than 40% of the vote share. Increasingly, these traditional parties are challenged by non-mainstream parties from the left as well as from the right. The electoral success of these non-mainstream parties has fundamentally changed the party system and the party offer by creating additional viable parties that voters can choose from (Aarts and Thomassen, 2008).
Working in a highly structured and segmented electoral context, scholars of voting behavior in the Netherlands traditionally focused on explaining voting by means of socio-demographic characteristics. Relying on a ‘structured model of electoral competition’, the focus was on the effect of citizens’ religion or social class on their vote choices (Irwin and van Holsteyn, 1989). As this model started to lose its explanatory power, other issues have received more attention, such as the economy; it was expected that the waning of loyalties to the pillar parties would allow voters to hold the incumbent more accountable for economic conditions (Irwin and van Holsteyn, 2008; Middendorp and Kolkhuis Tanke, 1990). However, despite this assumption the literature on economic voting in the Netherlands is miniscule compared to research explaining the vote choice of Dutch voters by means of attitudes towards immigration, European Union integration, or populism (Aarts and Thomassen, 2008; Bélanger and Aarts, 2006; Schumacher and Rooduijn, 2013). These issues are important not only because some of the non-mainstream parties draw attention to them, but also because non-mainstream parties – especially when electorally successful – affect traditional parties’ agenda. When facing strong competition from non-mainstream parties, traditional parties shift towards more anti-immigrant and welfare chauvinist positions (Schumacher and van Kersbergen, 2016).
While attitudes towards immigrants and cultural attitudes more generally are without any doubt useful for explaining the – sometimes short-lived – success of single issue parties and fringe parties such as the List Pim Fortuyn (Bélanger and Aarts, 2006), we focus in this note on predicting the electoral result of the party of the incumbent Prime Minister. To do so, we argue that a focus on economic indicators holds the most promise. This emphasis on the economy falls in line with most approaches to forecasting electoral results by means of a structural model.
Some might argue that the highly proportional electoral system in the Netherlands is not favorable to economic voting, as coalition governments are thought to limit the clarity of responsibility for economic conditions (Powell and Whitten, 1993; but see Dassonneville and Lewis-Beck, 2017). However, previous work has offered some indications that incumbents in the Netherlands are rewarded under favorable economic conditions (Swank and Eisinga, 1999). In addition, a number of recent publications in the field of economic voting have indicated that in the context of multiparty systems, and when coalition governments are in office, the party of the Prime Minister tends to be credited and blamed for economic conditions (Debus et al., 2014; Williams et al., in press). For all these reasons, we are confident there is promise in developing a structural and economy-based forecasting model to predict the performance of the party of the Prime Minister in the Netherlands.
Forecasting in the Netherlands
No structural forecasting model has previously been developed for the Dutch case. Electoral predictions in the Netherlands are based solely on public opinion polls, which have a long tradition in the Netherlands. Those vote intention polls tend to perform fairly well for predicting the vote shares that different parties in the Netherlands receive. Furthermore, the highly proportional electoral system allows for straightforward prediction of parties’ seat shares as well. However, even though they generally predict the results quite accurately, vote intention polls have had a high error rate in a number of Dutch elections, such as the 1986 election (van der Eijk et al., 1986) or the rather exceptional 2002 election that took place 9 days after the assassination of Pim Fortuyn (van Holsteyn and Irwin, 2003).
Following trends and approaches used for other countries, Tom Louwerse has started aggregating vote intention polls in the Netherlands. 4 His model combines information from several polling houses (4 in 2012 and 6 in 2017) and the aggregate estimates give a good sense of overall trends in vote intentions for different parties in the Netherlands as well as the uncertainty of those vote intention polls. Given that vote intention polls are the only existing approach to forecasting elections in the Netherlands, we will benchmark our structural forecast against the estimates from the polls, and the aggregated polls in particular.
A fundamentals model
A standard approach to forecasting elections is to think of the vote (V) as a function of political and economic variables (cf. Equation 1) (Lewis-Beck, 2005). Many structural forecasts build on insights from the economic voting literature, with the basic assumption being that incumbents will be rewarded or punished for economic conditions (Key, 1966). It is hence straightforward to focus on forecasting the incumbent (or lead incumbent party) vote share by means of objective economic indicators, such as unemployment, inflation or gross domestic product (GDP) growth. The political variables that are added to predict the incumbent’s vote share vary more. In general, forecasting models include an indicator of the popularity of the government or the party whose vote share is predicted. Depending on data availability in a particular setting, this could be government approval rates, vote intention polls, party membership rates, or parties’ performance in previous or second-order elections (for different approaches to including political variables, see the papers in the special issue by Lewis-Beck and Bélanger, 2012). In addition, models regularly include political variables that allow taking into account some specifics of the context or regularities that observers of politics in a particular country have observed. For example, some US presidential election models include a dummy variable that identifies whether or not the incumbent president is running (Holbrook, 2008). Other models include a ‘time-for-change’ indicator to account for the fact that a party that has been in office for a long time (and several terms) tends to lose votes (Abramowitz, 2008; Lebo and Norpoth, 2007).

For this initial model, designed to forecast Dutch legislative election results, we focus on predicting the vote share of the party of the Prime Minister. This focus allows us to build on theories of economic voting. We build a parsimonious model that explains the PM’s party’s vote share 5 by means of three indicators. As an economic indicator, we include GDP growth in the year before the election year. 6 We include GDP since it is generally thought of as the most ‘global’ economic indicator (Norpoth et al., 1991). Unlike what holds for unemployment rates, GDP growth should affect the PM’s party’s vote share irrespective of the ideological position of this party (Dassonneville and Lewis-Beck, 2013). As a first political indicator, we include the PM’s party’s vote share in the previous legislative elections (for the previous vote choice as a predictor, see also Lebo and Norpoth, 2007). On the one hand, this choice is driven by the lack of longitudinal data on government approval in the Netherlands. On the other hand, given the gradual process of depillarization in the Netherlands, controlling for the previous vote share is a very effective way of taking into account the gradual decline of the traditional parties (VVD, CDA and PvdA), which are the parties that have held the position of Prime Minister in the Netherlands. We include a second political indicator as well, which is the number of months the Prime Minister has been in office, in order to capture the ‘cost of ruling’ in terms of vote loss that usually occurs (Lebo and Norpoth, 2007; Norpoth and Gschwend, 2010). Our model to forecast the vote share of the PM’s party in the Netherlands hence takes the following form:
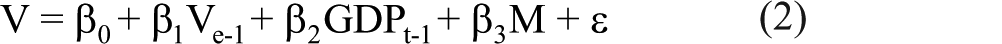
where V is the vote share of the party of the Prime Minister, Ve-1 is the vote share the party of the Prime Minister obtained in the previous legislative election, GDPt-1 is the GDP growth rate (weighted by the election month) in the year before the election and M is the number of months the Prime Minister has been in office (uninterruptedly). It is important to note that this model scores well on the sine qua non of a forecasting model – lead time. It offers a forecast from data gathered the year before the election contest itself. 7
Estimating this model for the 19 Dutch legislative elections that took place between 1952 and 2012 by means of an ordinary least squares regression, we obtain the following estimates listed in Table 1.
Regression model explaining the vote share of the Prime Minister’s (PM’s) party in the Netherlands, legislative elections between 1952 and 2012.

Notes: Unstandardized coefficients and standard errors (in parentheses) are reported. Significance levels: *p < 0.05; **p < 0.01; ***p < 0.001 (one-tailed). The χ2 value of the Durbin’s alternative test for autocorrelation was 0.354, with a p-value of 0.552, thus supporting the null hypothesis of no serial correlation (note that because a lagged dependent variable is included in the model, we do not report a traditional Durbin–Watson statistic).
The fit statistics of this model are encouraging, with a fairly high explanatory power and a root-mean-square error that is not too high. Furthermore, the predictor variables that are included in this model all have the expected sign and achieve significance. We find that when the party of the Prime Minister obtained a higher vote share in the previous election, it will also obtain more votes in the election that we explain. Furthermore, the effect of GDP growth offers indications of a mechanism of economic voting. The coefficient suggests that for each additional percentage point in GDP growth, the party of the Prime Minister wins an additional 1.3% of the vote share. Finally, the ‘months in office’ variable is negative and significant, indicating that the longer the Prime Minister has been in office, the fewer votes his or her party will obtain.
According to this model, the vote share of the Prime Minister can be predicted by means of the following equation:

Diagnostics
This election forecasting model, as is customary in such structural equations, bases itself on an estimation on a very small sample size (19 elections between 1952 and 2012). As regressions on such small sample sizes can be rather unstable, it is of foremost importance to apply various diagnostics to the model and to carefully assess its predictive power. In what follows, we validate the accuracy of the model in a number of ways.
In Table 2, we present the within-sample predictions of the model, which are derived from Equation 3. For each of the 19 elections in our sample, we present the model prediction, the actual vote share and the prediction error. As evident from the forecasts in Table 2, the model predicts the PM’s party’s vote share fairly well. On average, the model has an absolute error of 3.7 percentage points. It is also clear that the model performance varies quite strongly from one election to another: for some elections (e.g., the 1981 elections) the forecast is extremely precise while in other instances (e.g., the 1956, the 1971 and the 2012 elections) the model’s prediction has an error of 7 percentage points or more.
Within-sample forecasts.

The within-sample predictions give us a good idea of the accuracy of the model and the extent to which it fits the data. Ultimately, however, we develop a structural model with the aim of doing out-of-sample forecasts – and, in particular, to predict the PM’s party vote share for the 2017 legislative elections. We therefore proceed with some out-of-sample forecasts based on the data from the 19 elections in our sample. Table 3 summarizes the results of the out-of-sample forecasts, in which we drop from the estimation the election for which the vote share is predicted (i.e., dropping one election at a time). For each of these out-of-sample (jackknife) estimates, the prediction is based on information from the 18 remaining elections. Each of these forecasts is compared to the actual result, which allows assessing the model’s actual forecasting potential.
Out-of-sample forecasts.

Not surprisingly, the out-of-sample forecasts have somewhat larger prediction errors. The mean absolute error for these 19 out-of-sample predictions is 4.6 percentage points. From the out-of-sample forecasts in Table 3, it is clear that the model’s precision fluctuates noticeably from one election to another. For some elections, the prediction is fairly or extremely close (e.g., the 1994 elections) while in other instances the forecasting error is substantial (e.g., 2002).
Forecast for the 2017 legislative elections
The ultimate test for a structural forecasting model, however, is a real-time step-ahead forecast. We have pursued such a test, and have applied the model to predict the vote share the party of the incumbent Prime Minister Mark Rutte (VVD) would obtain in the 2017 elections.
Using the estimates from Equation 3, and adding information on the party’s previous vote share, GDP growth and the number of months Rutte has been in office, our estimate for the result of the VVD in the 2017 elections was the following:

Our model, which we published before the polls closed on Election Day, predicted that the party of the incumbent Prime Minister would obtain 22.3% of the votes. This estimate was considerably higher than what the polls suggested. The estimates of the aggregated polls, published by Tom Louwerse on the eve of the elections, suggested the VVD would obtain about 17% of the votes [95% confidence interval: 16.5–17.9] (see Online Appendix).
The party’s actual election result in the 2017 legislative elections was 21.3%. As such, we can conclude that our structural forecast did remarkably well. Not only is the error of our model just 1.0 point, but the error of our structural model was also smaller than the error of polls that were published on the eve of the election. This is all the more noteworthy, as our model had a lead time of more than two months (that is, as soon as GDP growth rates for 2016 were published, a forecast could be made). Table A1 in the Online Appendix clarifies that our structural model beating the polls is not exceptional. In fact, for four out of the ten elections for which we have polling data, our structural model outperforms the polls.
Conclusion
While election forecasting has become a serious enterprise in most Western democracies, the Netherlands has remained something of an exception, where the extant scientific forecasting has relied on public opinion polling, to the virtual exclusion of other methodologies. A leading reason for a lone focus on polls has been the assumption that the party system is too complex and too fragmented to allow the prediction of election outcomes by other methods. However, we show that other approaches have value, namely the widely applied structural modeling approach. We offer a standard Political Economy model to explain, and predict, the aggregate electoral performance of the PM’s party, as a function of economic growth, previous success, and length of time in office. This parsimonious model, applied well in advance of the election contest itself, generally operates well, as the various statistical tests make clear. And, with regard to the 2017 contest in particular, it forecasts that result almost exactly (with just one percentage point of error), in stark contrast to the large error from the pre-election day polls (with an aggregate average error of over four points).
From this exercise, we have learned several things. First, despite the complexities of the changing political party system of the Netherlands, structural models can forecast elections well, even better sometimes than the polls. Second, with regard to the issues at play in the 2017 contest, the structural modeling results suggest that issues such as immigration and terrorism might have been overplayed, while the enduring, important issue of the economy might have been underplayed. Of course, the advantages of our structural model do not mean that it cannot be improved. For example, as an experiment, polling data could be blended with the substantive variables, in an approach labelled ‘synthetic’ modeling (Lewis-Beck and Dassonneville, 2015). Alternatively, experiments could take place with the addition (and subtraction) of other potential substantive variables. Such tests as these open up bright possibilities for the future of election forecasting in the Netherlands.
Footnotes
Acknowledgements
The authors thank two anonymous reviewers and the editor for comments on the manuscript of this paper.
Declaration of Conflicting Interest
The authors declare that there is no conflict of interest.
Funding
This work was funded by Canada Research Chairs [grant number 950-231173] and by Fonds de Recherche du Québec-Société et Culture [grant number 2017-NP-199028].
Notes
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.