
Abstract
Enns et al. respond to recent work by Grant and Lebo and Lebo and Grant that raises a number of concerns with political scientists’ use of the general error correction model (GECM). While agreeing with the particular rules one should apply when using unit root data in the GECM, Enns et al. still advocate procedures that will lead researchers astray. Most especially, they fail to recognize the difficulty in interpreting the GECM’s “error correction coefficient.” Without being certain of the univariate properties of one’s data it is extremely difficult (or perhaps impossible) to know whether or not cointegration exists and error correction is occurring. We demonstrate the crucial differences for the GECM between having evidence of a unit root (from Dickey–Fuller tests) versus actually having a unit root. Looking at simulations and two applied examples we show how overblown findings of error correction await the uncareful researcher.
Introduction
In a recent symposium in Political Analysis Grant and Lebo (2016) and Lebo and Grant (2016) raise a number of concerns with use of the general error correction model (GECM). In response, Enns et al. (2016) have contributed “Don’t jettison the general error correction model just yet: A practical guide to avoiding spurious regression with the GECM.” Enns et al. are prolific users of the GECM; separately or in combination they have authored 18 publications that rely on the model, often relying on significant error correction coefficients to claim close relationships between political variables. In “Don’t jettison…” the authors narrow the gap of disagreement between themselves and Grant and Lebo. However, as they attempt to reconcile old findings with new insights, Enns et al. inadvertently make clear an essential point: using the GECM is more complicated in practice than researchers realize. Despite their extensive experience, Enns et al. are still misinterpreting the inferences provided by the error correction coefficient and as a result are overstating relationships between variables.
In this paper we explain where we agree with and diverge from Enns et al.. In short, there is agreement that: (a) with stationary data (I(0)) the GECM’s parameters have different meaning and the strong possibility of user error makes the model a poor choice; and (b) the GECM is more easily interpretable with all unit root (I(1)) and jointly cointegrated data so long as one uses the correct critical values. Many disagreements remain. In particular, despite the weaknesses of the Dickey and Fuller (1979) stationarity test, Enns et al. treat the test’s results as perfectly reliable for identifying unit roots. We show both the high frequency of the Dickey–Fuller (DF) test misclassifying series as unit roots and the consequences for using such series in the GECM. Further, Enns et al. advocate stretching the use of “unit root rules” into other data scenarios but ignore the possible consequences of doing so.
We also explore differences in our understanding of the data used in Kelly and Enns (2010) and Casillas et al. (2011). Enns et al. argue that the data and analyses in those papers and potentially many others fit neatly into the unit root rules category. We maintain that Enns et al. are likely misclassifying the series in those papers as unit roots which can lead to over-stated claims of error correction. We begin with the points of agreement between Enns et al. (2016) and Grant and Lebo (2016).
Points of agreement
The GECM can work when all the series contain unit roots and are jointly cointegrated
The GECM has several representations but the one most commonly used by political scientists is DeBoef and Keele’s (2008) Equation 5:
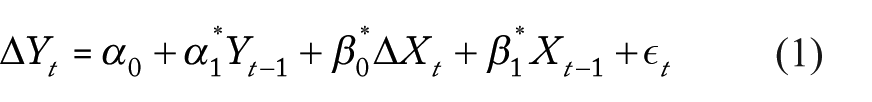
Enns et al. and Grant and Lebo agree with the literature in econometrics that when both
In particular, there is agreement that when both
functions as a test of cointegration between
The critical values for
When
This is progress. Grant and Lebo (2016) point out in their table 2 how frequently a researcher might mistakenly conclude error correction is present if she were to incorrectly use the normal distribution to evaluate
The GECM is possible but not recommended when all series are stationary
Enns et al. and Grant and Lebo agree on another key point: the GECM must be interpreted differently when all the data are stationary compared to when they all contain unit roots.
DeBoef and Keele (2008) and Keele et al. (2016) explain the equivalence of the GECM (Equation 1 above) to the autoregressive distributed lag (ADL) (Equation 2):
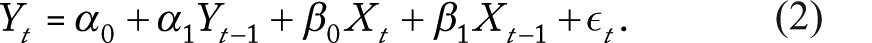
Stationary series require the “stationary rules” for Equation 1: (1)
We did not find these post-estimation calculations in any of our selected readings of the roughly 500 papers that cite DeBoef and Keele (2008). Instead, when data are claimed to be stationary, the value and significance of
Thus, Grant and Lebo do not say that the GECM cannot be used with stationary data, but argue (Grant and Lebo, 2016: 4): “…although the autoregressive distributed lag (ADL) model is algebraically equivalent to the GECM, the reorganization of parameters is not benign and easily leads to misinterpretation.” In other work Kelly, Enns, and Wohlfarth did not adapt their interpretation of the GECM while arguing data are stationary but, with “Don’t Jettison the GECM Just Yet,” the authors are now on board, saying (EKMW, p. 6): “Thus, we agree with Grant and Lebo that when the dependent variable is stationary, the parameterization of the GECM is more likely than the ADL to lead to errors of interpretation.”
This is also progress. DeBoef and Keele (2008) advocate the GECM with stationary data – an early version of the paper was entitled “Not Just for Cointegration: Error Correction Models with Stationary Data.” 2 With all stationary series, they argue, one can estimate an error correction model (ECM) without discussing cointegration, long-run equilibria, or error correction rates. However, in addition to interpretation problems, other issues followed as well.
A key misreading of DeBoef and Keele is to conclude that the GECM is perfectly flexible so that series of any type can be analyzed together within it. 3 In particular, DeBoef and Keele’s (2008: 199) statement that “…as the ECM is useful for stationary and integrated data alike, analysts need not enter debates about unit roots and cointegration to discuss long-run equilibria and rates of reequilibration” has been repeatedly quoted but seldom understood. 4 The applied literature is peppered with statements such as: “In summary, the ECM is a very general model that is easy to implement and estimate, does not impose assumptions about cointegration, and can be applied to both stationary and nonstationary data” (Volscho and Kelly, 2012); “The ECM provides a conservative empirical test of our argument and a general model that is appropriate with both stationary and nonstationary data” (Casillas et al., 2011); and “While the use of an ECM is often motivated by the presence of a nonstationary time-series as a dependent variable, our application of this model is based on the fact that it is among the most general time-series models that imposes the fewest restrictions” (Kelly and Enns, 2010). Engle and Granger’s (1987) strict rules for cointegration were increasingly ignored as the GECM became the dominant technique in political science.
Enns et al.’s conclusion that “Although the ADL and GECM produce the same information (in different formats), the ADL is less likely to yield errors of interpretation when
Point of likely disagreement
On another point agreement is uncertain. Grant and Lebo posit that the univariate properties of all series in the GECM deserve attention; for example if all the independent variables are I(1) they must all be cointegrated with the dependent variable (DV). As opposed to Engle and Granger’s (1987) two-step ECM or Clarke and Lebo’s (2003) three-step fractional ECM, the GECM does not allow testing for cointegration or measuring error correction between
For example, the cointegration of unit root series
Points of disagreement
To review, all agree that a bivariate GECM estimates parameters
Our views deviate as we confront the stark choice about which rules to apply, especially with respect to the error correction coefficient. When should we switch from one set of rules to the other? Enns et al. claim that it is possible to unambiguously choose rules based on results from augmented Dickey–Fuller (ADF) tests: “If the ADF rejects the null of a unit root, we do not use the GECM to test for cointegration” (Enns et al., 2016: 4).
However, DF tests have a null hypothesis of a unit root so that positive evidence is required to classify the series as not I(1). As Enns et al. (2016: 4) admit “it is well known that ADF tests are underpowered against the alternative hypothesis of stationarity” meaning that many series incorrectly show evidence of a unit root. Indeed, the ADF test is sensitive to sample size, trends, and bounds. Fractionally integrated, near-integrated, autoregressive, and other stationary series often fail to reject the null in the ADF test. ADF tests can also be affected by trending, periodicity, and heteroskedasticity.
Falsely classifying series as I(1) means being too quick to favor the GECM over the ADL, to apply the wrong rules to the GECM, and to think that lower values of
Figures 1(a), 1(b), and 1(c) show these problems for the GECM. We generated 60,000 pairs of unrelated time series – 10,000 each for T = 50, T = 100, and T = 250 while varying

(a) With
For both Figures 1(a) and 1(b), each shape shows the average value of 1,000 ADF test statistics of
On the
The figures’ results should be striking, most especially for short time series. Unrelated series simulated as
Of course, the high rate of false negatives on the ADF test would not be as problematic if the ECM parameter testing for cointegration
Figure 1(c) shows this. Each cell reports the proportion of times that the ADF test fails to reject a false null hypothesis of a unit root and the ECM parameter is significant beyond MacKinnon CVs. For example, with series created as
To reiterate, not a single series in Figures 1(a), 1(b), or 1(c) contains a unit root. Thus, the GECM’s unit root rules should not be used for any of them.
10
Still, Enns et al.’s favored ADF test will incorrectly conclude that many are I(1). In fact, with short series the ADF test gives us false negatives a majority of the time and even 15% of the time when series are complete white noise, that is,
Enns et al. do not confront these problems. Instead, they force non-unit root data into the “all unit root” case and rely on the error correction parameter
If we could identify with certainty I(1) series we could know when to apply the unit root rules but, as Enns et al. correctly point out, “It may be that with short time series, we cannot draw firm conclusions about the time series properties of variables” (Enns et al., 2016: 9). Given that, Enns et al. should not choose rules based on a weak test and should not focus on a parameter whose interpretability gets muddier as data deviate from exactly I(1). Doing so gambles with inferences since if the data are not truly I(1) then
Elsewhere, Enns et al. are explicit about extending the unit root rules to data that are not I(1). In their Case 4, Enns et al. apply them to near-integrated data – where
But the unit root rules are not exactly correct when
Thus, when do we switch from one set of rules to the other? There is no magic threshold as a series goes from
Enns et al. oversimplify again when they use unit root rules for fractionally integrated (FI) series where
This seems disingenuous. Neither Grant and Lebo (2016), Ericsson and MacKinnon (2002), nor any other source we know of has argued that MacKinnon CVs are appropriate except with exact I(1) data. Enns et al. provide no justification for expanding when these values should be used – to NI data, FI data, or any other type. Yes, Enns et al.’s advice prevents some spurious findings but that does not mean that these are the correct critical values. As Grant and Lebo’s (2016) figure 4 shows,
In sum, many series that do not have unit roots will test as though they do. Also, neither fractionally integrated nor near-integrated series have unit roots and thus do not work for the CVs set out in Ericsson and MacKinnon (2002).
16
Treating such series as I(1) in the GECM means
The GECM in practice when we are too quick to find unit roots
Next we consider the practical implications of squeezing non-unit root data into the unit root case for the GECM. To begin, recall Murray (1994)’s story that a unit root variable is like a drunk out for a walk – the next step is random but his current location is the sum of the steps taken thus far. Cointegration is akin to the drunk taking a leashed dog along for the walk. The two may be on random walks but are tethered so that any distance between them is eventually closed (error correction) and in the long run tends to zero.
What data do economists study for error correction? The textbook example in Stock and Watson (2011) uses one-year and three-month treasury bill rates set by the federal reserve, shown in Figure 2. These are unit roots; unless the US Federal Reserve decides to change them – a shock in the error term – interest rates at time

Stock and Watson’s (2011) cointegration example: three-month and one-year T-bill rates, error correction rate = 52%.
Another look at Kelly and Enns (2010)
Enns et al. (2016) defend Kelly and Enns’s (2010) results so long as the unit root rules are applied. Kelly and Enns’s (2010) table 1 model 4 shows the GECM results with Welfare Attitudes as the DV and Policy Liberlism and the Gini index as independent variables. With just T = 33 it is unsurprising that ADF tests on all three variables fail to reject the null of a unit root. 17 Thus, the data surpass Enns et al. threshold to apply the unit root rules. 18
Figure 3 shows these series. The solid line plots

Kelly and Enns’s (2010) data in their table 1 model 4; Kelly and Enns, and Enns et al. claim that the error correction rate is 55%.
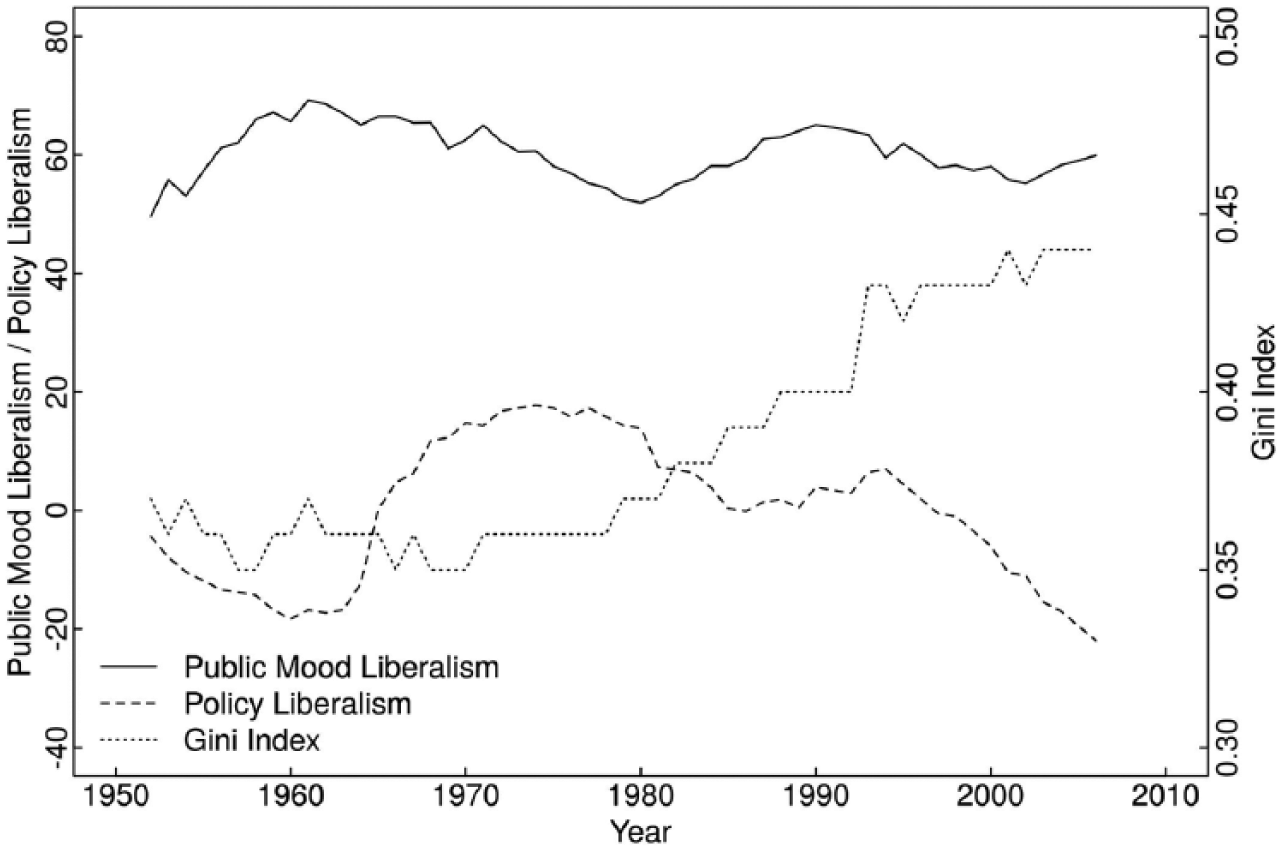
Elsewhere, Enns et al. (2016: 4) specifically defend models in Kelly and Enns (2010) and say “Yet, looking at Kelly and Enns’ most parsimonious analysis (Table 1, column 2) we find clear evidence of cointegration.” The three series are graphed in Figure 4 with Public Mood Liberalism (the solid line) as the DV. It is possible that cointegration is hard to see when more than two series are involved but making the comparison between Kelly and Enns’s data and the classic example in Figure 2 it seems more likely that the error correction rate is overstated by Kelly and Enns – Figure 4 does not look like a drunk and her dog(s).
Data from Kelly and Enns’s (2010) table 1 model 2 - relationships are not apparent.
Also, compare Kelly and Enns’s (2010) models 1 and 2 in their table 1 which show the same error correction rate (
Another look at Casillas et al. (2011)
Next, we look at Enns et al.’s defense of Casillas et al. (2011). Casillas et al. use three DVs: Salient Reviews, Non-Salient Reviews, and All Reviews decided in a liberal direction at the US Supreme Court. Enns et al. say:
“We agree with Grant and Lebo that Casillas, Enns, and Wohlfarth were wrong to interpret the
What Enns et al. miss, however, is that the differences between Salient Reviews on the one hand and All Reviews and Non-Salient Reviews on the other are ones of degree, not category. These variables are computed anew each year based on the Court’s decisions, making them very unlikely to contain unit roots. However, with T = 45, ADF tests have extremely low power in confirming that.
Enns et al. stand by Casillas et al.’s estimates for All Reviews “The significant long-run impact of mood on the Court suggests that public opinion also has an effect that is distributed over future time periods. The error correction rate of 0.83 indicates the speed at which this long-term effect takes place. We expect that 83% of the long-run impact of public mood will influence the Court at term
This seemingly incontrovertible conclusion (

Casillas et al.’s (2011) data for their table 1, error correction rate claimed to be 83%.
It is impossible to know the extent to which a negative coefficient on
To demonstrate, Figure 6 begins with data from Grant and Lebo’s (2016) simulations of fractionally integrated data and shows decreasing values of

Casillas et al.’s (2011) error correction model (ECM) estimates are where they would be if no error correction was occurring.
Figure 6 also includes
In all, Enns et al.’s (2016: 2) statement: “…we reconsider two of the articles that Grant and Lebo critiqued (CEW, K&E [Casillas et al. and Kelly and Enns]) and we demonstrate that a correct understanding of the GECM indicates that the methods and findings of these two articles are sound,” could only be true if the weakest relationship among our Figures 2, 3, 4, and 5 is Figure 2’s textbook example of cointegration. Enns et al’s blanket statement also misdirects from the fact that they only defend those papers’ least outrageous findings.
In fact, Casillas et al. (2011) misinterpret
In practice, if you are using the unit root rules in the GECM, you can only easily interpret
Further thoughts on simulations and replications
Enns et al. (2016: 2) say: “Although our conclusions differ greatly from Grant and Lebo’s recommendations, we do not expect our findings to be controversial. Most of our evidence comes directly from Grant and Lebo’s own simulations.” This statement deserves more attention than there is space for here but the essential point is that Enns et al.’s widespread promotion of MacKinnon CVs is an easy way to reduce Type I error rates in simulations or in practice but these are not the right CVs except when data truly have a unit root. When
The properties of the series Enns et al use – in Kelly and Enns, Casillas et al., and elsewhere – do not match the properties of the data they simulate. The consequences of being wrong are to get nonsense results, for example, insisting that 97% of the disequilibrium between Supreme Court decisions and public mood is corrected in two years.
Also, Enns et al. cast doubt when they say Grant and Lebo misused the GECM by replacing the independent variables of published work with shark attacks, tornado fatalities, other nonsense series, and simulated data. Enns et al. are correct that in Grant and Lebo’s replications they did not follow their own advice to set aside regression results where there is no evidence of cointegration. But, of course, that was precisely the point: Grant and Lebo are demonstrating the mistakes made when GECM results are misinterpreted as was done by Kelly and Enns, Casillas et al., and the many published GECM studies.
That is, Grant and Lebo show that if one mimics the methods and interpretation of papers like Casillas et al. (2011) the independent variables do not really matter in terms of getting significant results on the error correction parameter. 24 Enns et al. are correct, for instance, that Grant and Lebo’s table 10 replication of Casillas et al. would not show shark attacks and beef consumption to be related to Supreme Court decisions if Grant and Lebo had improved upon Casillas et al.’s methods. Nevertheless, it is notable that with both Kelly and Enns’s (2010) and Ura and Ellis’s (2012) data, some relationships – Grant and Lebo’s table 13 (Republican Mood) and Grant and Lebo’s table E.13 model 3, respectively – between the DVs and variables such as Onion Acreage are strong enough to surpass MacKinnon CVs and conclude cointegration exists. Since the data are unlikely to have unit roots, MacKinnon CVs still are not enough to prevent spurious findings of error correction.
Conclusion
We show that using the unit root rules with series that simply pass the DF test is not enough to avoid overstating findings of error correction. Especially with short time series it is too easy to fail to reject the DF null of non-stationarity and then misunderstand the error correction coefficient. This is a principal reason why the applied literature is replete with incorrect GECM findings and why Grant and Lebo recommend against using the model except in ideal circumstances.
Enns et al.’s “Don’t Jettison the GECM” tries to clarify how to correctly interpret the ECM coefficient but inadvertently shows that while the GECM is viewed as flexible and easy to use it is, in fact, inflexible and extremely easy to misuse. Enns et al. agree that the GECM can work when data are unit roots, cointegrated, and special critical values are used but fail to realize they cannot simply extend those rules to non-unit root data and obtain reliable conclusions.
Indeed, Enns et al. advocate applying the unit root rules to data they know to not have unit roots – autoregressive and fractionally integrated – as well as other series that merely show evidence of a unit root. Moreover, they make their decisions based on the much maligned DF test. Although they say (Enns et al., 2016: 2): “Most of our evidence comes directly from Grant and Lebo’s own simulations” Enns et al. do so while roughly doubling the CVs without proving the practice is correct. Many spurious findings are eliminated this way but MacKinnon CVs and the unit root rules are not enough to overcome the interpretation problems on
Grant and Lebo (2016: 27) say: “Error correction between variables is a very close relationship that should be obvious in a simple glance at the data.” The graphs of data we provide here should make it clear that Enns et al.’s claims to have found long run equilibria between political time series in Kelly and Enns (2010) and Casillas et al. (2011) come from the misuse of the method, not the data. Finding long run equilibria across decades of data makes for a story that is interesting but that hinges on a parameter that is often inscrutable. If researchers insist on employing the GECM with data that may not be unit roots they need to focus on the model’s other parameters.
Footnotes
Declaration of Conflicting Interest
The authors declare that there is no conflict of interest.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Notes
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.