
Abstract
Political scientists interested in studying the political implications of citizens’ cognitive abilities often turn to readily available “intelligence ratings” in the American National Election Studies (ANES). These ratings are generally thought to represent respondents’ cognitive abilities, albeit imperfectly. I hypothesize that these ratings do not reflect more-objective tests of cognitive ability, and instead better capture considerations related to the political subject of the interviews and other contextual factors. In the 2012 ANES, which contained a cognitive ability test (“Wordsum”), I find that political engagement and demographic factors but not actual measurements of cognitive ability are associated with interviewer intelligence rating scores. In bivariate analyses, verbal intelligence and interviewer ratings are moderately correlated with one another, consistent with conventional wisdom. But this correlation is a spurious one, as the same is also true for political engagement, education, and household income. Further, in multivariate models, Wordsum scores were neither statistically nor substantively predictive of interviewer ratings. The results suggest that interviewer ratings are better understood as proxies for political engagement, not cognitive ability. I conclude by arguing that the growing importance of studying cognitive ability in political science makes it necessary to include more-objective verbal intelligence tests more frequently in public opinion surveys.
Introduction
Political scientists have become increasingly interested in the relationship between voters’ cognitive abilities and many political outcomes (e.g. Hillygus, 2005; Berinsky and Lenz, 2011; Makowsky and Miller, 2014; Wodtke, 2016). Interviewer ratings of respondent intelligence are arguably the most accessible measure of cognitive ability in political science research (Luskin, 1990), and have been employed as proxies for intelligence in both the recent past (e.g. Luskin, 1990; Holbrook, 1999; Hauser, 2000) and present day (e.g. Healy and Malhotra, 2014; Holbrook et al., 2014). Researchers are often careful to point out that these measures are imperfect. Yet, because they are at least thought to correlate moderately highly with more formal measurements of verbal intelligence (Gibson and Wenzel, 1988; Luskin, 1990), scholars nevertheless assume that the ratings are more-or-less valid indicators of a general intelligence construct.
Whether or not this assumption is a good one is an important question in the study of cognitive ability, as scholars continue to investigate its role in shaping citizens’ attitudes and behaviors. If interviewer ratings do not accurately reflect the construct they purport to measure, researchers will need to consider regularly including other items (such as more-formal tests of cognitive ability) on surveys such as the American National Election Studies (ANES) in the future.
In this research article, I cast doubt on the premise that interviewer ratings are even generally valid indicators of cognitive ability. Verbal intelligence tests, one form of cognitive ability that is highly-correlated with general intelligence (see Malhotra et al., 2007: for a comprehensive overview), show moderately high bivariate correlations with interviewer ratings. However, so do a wide range of other political and demographic variables. Multivariate models reveal that interviewer ratings are substantively and statistically unrelated to verbal intelligence. Instead, and in line with theoretical expectations, the results suggest that interviewer ratings of intelligence more strongly reflect individuals’ interest and knowledge about politics, as well as their income and educational background.
A growing scholarly interest in cognitive ability
Scholars have been interested in voters’ cognitive abilities and their relevance to politics for decades, and research using intelligence to predict various political outcomes continues to be well-studied. For example, cognitive ability is thought to play a role in shaping whether or not voters are knowledgable about politics and make use of abstract ideological concepts to guide their issue preferences (Luskin, 1987, 1990; Carpini and Keeter, 1993, 1996). It has also been hypothesized to increase citizens’ willingness to participate in politics (Brady et al., 1995; Hillygus, 2005; Berinsky and Lenz, 2011), promote tolerance toward social out-groups (Bobo and Licari, 1989; Deary et al., 2008; Wodtke, 2016), and reduce political attitude extremity (Makowsky and Miller, 2014). Scholars have also taken a recent interest in investigating whether or not highly intelligent individuals hold different symbolic and operational ideological orientations (Ellis and Stimson’s (2012) terminology) than those who are less intelligent (Carl, 2014, 2015a,b,c; Solon, 2014; Meisenberg, 2015), or if they are less likely to engage in partisan-motivated reasoning (Kahan et al., 2012, 2013; Mérola and Hitt, 2016).
Many of the above studies make use of ten-item Wordsum measurements (Thorndike, 1942; Thorndike and Gallup, 1944) available in surveys such as the General Social Survey (GSS) and 2012 ANES. Others rely on numeracy (quantitative reasoning) measurements or verbal and/or mathematical standardized test scores. Still others make use of interviewer intelligence ratings, whereby survey administrators score each respondent they interview face-to-face in terms of how intelligent they seem. Interviewer ratings have been used, often with some reservations, to show that cognitive ability is associated with higher levels of political sophistication (Luskin, 1990), the tendency to acquire political information over the course of campaigns (Holbrook, 1999), and (to some extent) participation in electoral politics (Hauser, 2000). The measurement has also been shown to be negatively related to quantitative “heaping” (i.e. rounding) response strategies on questions asking respondents to offer answers that span large numeric ranges (Holbrook et al., 2014).
Simply put, scholars employ measurements of cognitive ability in making sense of a wide range of political phenomena. Interviewer ratings of respondent intelligence are one strategy by which scholars can do this, and, unlike other measures of cognitive ability, have the benefit of being readily available in many cross-sections of the ANES.
Interviewer intelligence ratings
In the ANES, interviewer intelligence ratings are five-point scales based on survey administrators’ responses to the following question:
“How intelligent would you say the respondent is? Much above average, a little above average, average, a little blow average, or much below average?”
In practice, interviewer ratings are typically recorded at the conclusion of the survey by two different interviewers (one administering a pre-election interview, and another doing the same after the election). Scholars have long known that this method boasts high inter-rater and intra-rater reliability levels (Campbell et al., 1976). The measure is also thought to have some amount of construct validity, correlating moderately highly with Wordsum measures of verbal intelligence (Gibson and Wenzel, 1988). It is also thought to have some amount of predictive validity, as the measure tends to positively correlate with political knowledge and education (Luskin, 1990).
However, scholars have also held reservations about the validity of the rating measurement for some time. As Luskin (1990) points out, interviewers are “hardly expert judges” and their ratings may reflect “seepage from other variables:” such as respondents’ levels of political sophistication, income, or education. Demonstrative of this point, Leal and Hess (1999) found that interviewers across three nationally representative studies were more likely to rate high-income and highly educated individuals are more intelligent, informed, and competent with respect to making sense of the survey’s instructions.
Recognizing these imperfections, Luskin nevertheless laments that interviewer ratings are “the only real option” for measuring intelligence in “a national probability sample extensively questioned about politics”. While internally and conceptually valid measurements such as Wordsum are administered regularly on the GSS, the words tested are protected by the National Opinion Research Center (Malhotra et al., 2007). Wordsum, for example, has been included only once in the ANES (in 2012), lending credence to Luskin’s concerns.
Thus, while scholars are certainly aware of methodological imperfections in the interviewer rating measures, they sometimes (perhaps because of the scarcity of viable alternatives) make use of them as a generally acceptable proxy for respondents’ cognitive abilities. Whether or not this is the case is an open empirical question, with important implications for the study of cognitive ability.
Theory and expectations: how survey-context explains interviewer intelligence ratings
I believe that there are at least two aspects of the ANES face-to-face survey-taking environment that cast doubt on the premise that interviewer ratings of intelligence are generally acceptable proxies for respondents’ cognitive abilities. The first pertains to the subjective context of the survey. The ANES, by and large, is a survey about politics. Thus, the considerations administrators have available for rendering a judgment about each respondent’s cognitive ability should be predominately political. As others have speculated (e.g. Luskin, 1990; Hauser, 2000), highly politically knowledgable and interested individuals should be better than less-knowledgable and less-interested individuals in transforming their abstract political attitudes and beliefs into coherent responses on the survey.
Thus, because the politically articulate are not observed in a non-political context, interviewers might reasonably infer that these individuals are generally articulate, and therefore more intelligent. From this theoretical expectation, I propose the “Subjective Survey Context Hypothesis”:
H1: Respondents’ levels of interest in, and knowledge about, politics will be more strongly associated with interviewer ratings of intelligence than actual measures of verbal cognitive ability.
A second aspect of the ANES survey-taking environment that might influence interviewer ratings is the physical context of the survey. Face-to-face ANES samples are typically conducted in individuals’ homes, 1 implying that the spaces and other physical contexts (e.g. respondents’ appearance) in which interviewers rate cognitive abilities vary at the level of individual respondents. Wealthier or more educated individuals might live in homes that provide interviewers with potentially misleading cues, suggestive of higher cognitive ability. Interviewers might associate voluminous bookshelves, nice clothing, and other status symbols (e.g. a luxury car) with literacy and financial success, and assume that their attainment is conditional upon being highly intelligent (potentially inaccurately, of course). 2 These findings would be consistent with the interviewer biases documented by Leal and Hess (1999).
This leads me to propose the “Physical Survey Context Hypothesis”:
H2: Respondents’ levels of education and income are more strongly associated with interviewer ratings of intelligence than actual measures of verbal cognitive ability.
Data and measures
Data
To test these hypotheses, I make use of data from the 2012 ANES, which included tests of individuals’ verbal cognitive skills (Wordsum), interviewer intelligence ratings, political knowledge and interest items, and a wide range of demographic controls. In total, the study interviewed over 5,000 respondents (N = 5,510), with those administered the survey face-to-face (N = 2,054) and online (N = 3,860) recruited via two different sampling procedures. 3 Because interviewer intelligence ratings can only be ascertained face-to-face, I make use of only that sample. Face-to-face interviews for the pre-election wave were conducted between 8 September and 5 November, and post-election interviews were conducted after 7 November; with a re-interview rate of 94% and a (RR1) response rate of 38%. 4
Measures
Interviewer intelligence ratings
As described previously, interviewers were asked to rate respondents on five-point scales with respect to their perceived levels of intelligence: ranging from “much below average” to “much above average”. These ratings were recorded by interviewers in both the pre- and post-interview surveys, both of which I scaled to range from 0 to 1 (such that an increase reflects higher levels of intelligence). More often than not (59% of the time), raters agreed on these assessments (κ = 0.39). Moreover, their independent ratings formed an internally reliable scale (α = 0.81). 5 In all analyses, I make use of both pre/post-interviewer ratings and the combined measure.
Verbal intelligence
I measure respondents’ cognitive abilities using the ten-item vocabulary test known as Wordsum (Thorndike, 1942; Thorndike and Gallup, 1944). The test first presents respondents with a word, and then asks them to select one of five other words that is closest in meaning to it. Scores are coded to range from 0 to 1, such that higher scores reflect higher intelligence.
While the Wordsum measure was originally conceptualized as a test of individuals’ verbal cognitive abilities, and is therefore not a direct measurement of general intelligence per se (Caplan and Miller, 2010), researchers often rely on it as a proxy of intelligence more broadly. Empirically, this decision appears well-founded. Scores on this test have been shown to be highly correlated with more general measures of intelligence on the Army General Classification Test (r > 0.70) (Wolfle, 1980), more formal IQ tests (r > 0.80) (Miner, 1957), and other measures of IQ (Rosenbaum, 2000; Malhotra et al., 2007). 6 Wordsum scores, much like IQ scores (Rosenbaum, 2000), are not distributed uniformly throughout the mass public, and tend to be higher amongst older, wealthier, and more educated individuals (Miner, 1957; Malhotra et al., 2007).
Of course, the Wordsum test is not without limitations. For example, an important body of literature finds that aggregate Wordsum scores have been decreasing over time despite gains in formal education, perhaps because the words used on the test have fallen out of popular usage (Dorius et al., 2016). Moreover, although the test has existed for more than half a century, scholars still debate how to properly use Wordsum, and the conditions under which it is a valid substitute for lengthier and more-direct intelligence tests (as Malhotra et al., 2007: review in their 2007 paper).
Political knowledge and interest
I incorporate one measure of respondents’ knowledge and two measures of respondents’ interest in politics in my analysis. Political knowledge was measured using a standard five-item civic knowledge test (α = 0.49) as recommended by Carpini and Keeter (1993, 1996). 7 One political interest item was measured using a five-point scale reflecting the extent to which respondents “pay attention to politics and elections”. A second measure was a five-item scale reflecting the extent to which individuals reported following the 2012 election making use of several different types of media (α=0.64). For brevity (and because all items are publicly available), please consult the appendix for specific question wording. All variables are recoded to range from 0 to 1, such that a score of one reflects the highest possible levels of interest and knowledge.
Demographic controls
All multivariate models control for a wide range of demographic, political, and psychological controls; all coded to range from 0 to 1. 8
Results
Bivariate analysis
As others have noted in the past (e.g. Luskin, 1990), I find that interviewer ratings of intelligence in the 2012 ANES are moderately correlated with actual verbal intelligence ratings. As the right-hand pane in Figure 1 demonstrates, higher scores on Wordsum are generally associated with higher scores on the (combined) intelligence ratings (weighted r = 0.38). Perhaps this is unsurprising, as the distribution of the two variables were similar across datasets (see left-hand pane of Figure 1). 9 This bivariate analysis offers some support for the conventional wisdom that interviewer ratings are generally acceptable (though by no means perfect) proxies for intelligence.
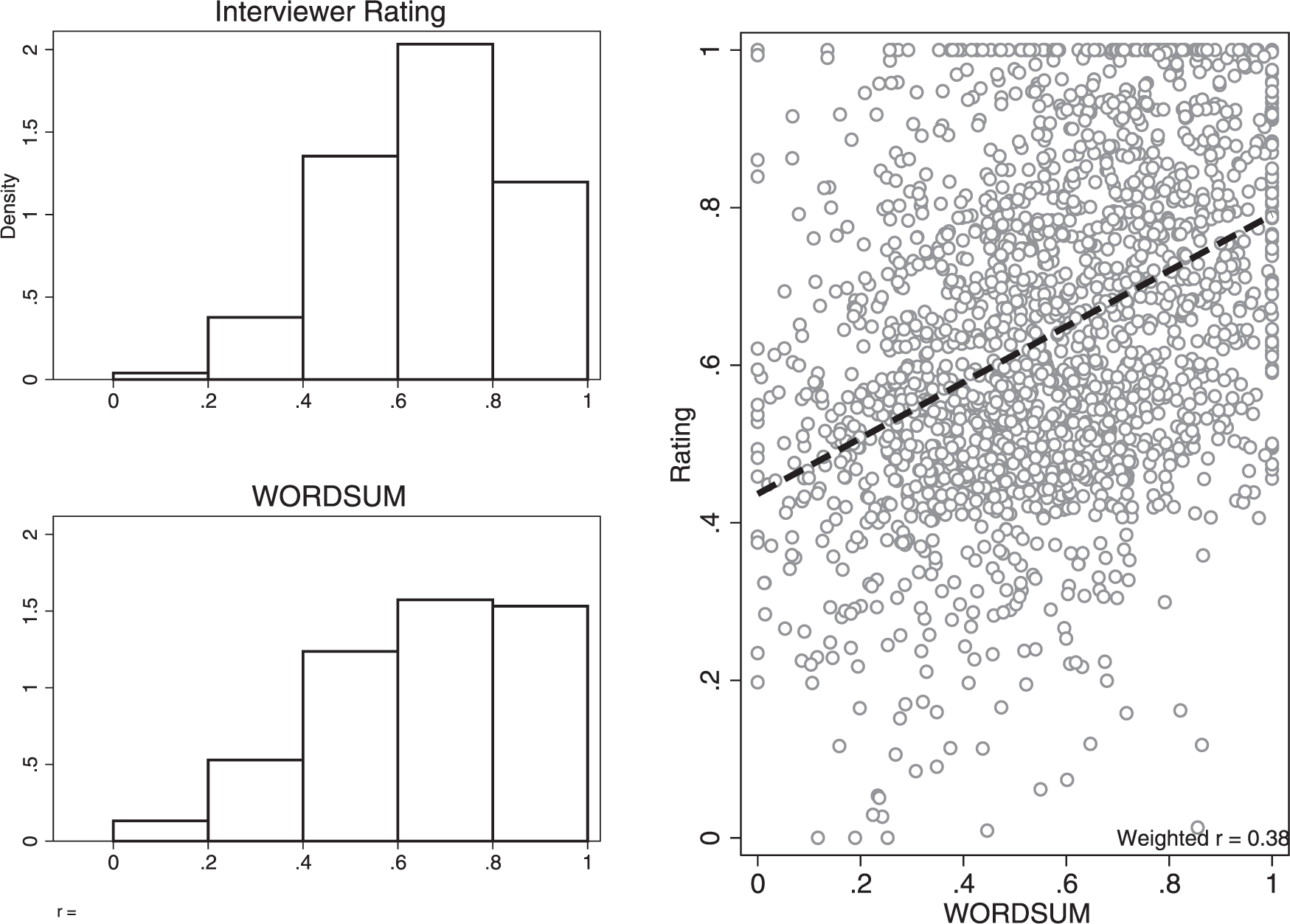
The bivariate relationship between interviewer ratings and verbal intelligence in the 2012 ANES. Left-hand panels display the weighted frequency distributions of the interviewer rating and Wordsum measures of intelligence, respectively. The right-hand panel is a scatterplot of the two, with the line best fitting the data displayed in black. Values of zero represent the lowest possible score on each variable, while values of one represent the highest possible score. Correlation estimate (lower right-hand corner) is based on weighted survey data. For display purposes, five random shocks are added to each point in the scatterplot.
However, a more-thorough look into the data suggest that this correlation might be a spurious one. As Figure 2 demonstrates, several other variables hypothesized to play a role in shaping interviewer ratings of intelligence are also moderately correlated with the interviewer ratings. In fact, respondents’ levels of knowledge about politics, interest in campaigns, attentiveness to campaigns in the media, income, and education, are all more highly correlated with the ratings than are verbal intelligence. This finding offers preliminary support for the Subjective Survey Context Hypothesis, suggesting that interviewer ratings are influenced by a wide range of political and demographic factors. In order to determine which factors are most strongly associated with the ratings, it is necessary to pit these variables against one another in a multivariate framework.

The bivariate relationship between interviewer ratings and other factors in the 2012 ANES. Each panel is a scatterplot of the relationship between interviewer intelligence ratings and some other political or demographic variable, with the line best fitting the data displayed in black. Correlation estimates (lower right-hand corner of each figure) are based on weighted survey data. For display purposes, five random shocks are added to each point in the scatterplot.
Multivariate analysis
In Table 1, I provide a stricter test of my expectations by constructing six ordinary least-squares (OLS) models (see Leal and Hess, 1999) estimating the impact of a wide range of factors on interviewer intelligence ratings. The models vary whether or not the outcome variable is a single-wave (pre, post; columns 1–4) or combined rating (i.e. pooled across pre and post election surveys; columns 5 and 6). 10 They also alternate whether education is operationalized as a dichotomous indicator of whether or not individuals completed college, or the broader degree-attainment scale.
Predicting interviewer ratings of intelligence. OLS coefficients with standard errors presented in parentheses (weighted survey data). Outcomes variables are pre-election (columns 1 and 2), post-election (columns 3 and 4), and combined (columns 5 and 6) interviewer ratings. Because outcomes in columns 1–4 are five-point scales, I re-estimate each model using ordered probit regression in Table A1 in the online appendix. The results are substantively and statistically robust to this specification.

Because all variables are coded to range from zero to one, the coefficients can be interpreted as percent change in intelligence ratings, moving from the minimum to maximum value on that covariate (i.e. a “first difference”). The results show that political knowledge, political media use, interest in politics, education (both specifications), and income are consistently strong and statistically significant predictors of intelligence ratings. Often, first differences in these covariates approach or exceed effect sizes of 10%. The media use index, for example, plays a particularly strong substantive role in predicting interviewer ratings, as it is associated with increases in intelligence ratings of at least 19% in all models. 11
Strikingly, though, the actual measure of verbal intelligence was never statistically associated with increased ratings on the intelligence scale. Moreover, the substantive effect sizes associated with the intelligence parameters were uniformly small once accounting for these other variables. 12
Figure 3 offers an additional level of detail to these substantive effects, showing the percentage changes in linear predictions on the intelligence rating outcome across the lowest and highest observed values of each of the covariates described above (with 95% confidence intervals extending outward from each one). All covariates depicted, except for actual levels of verbal intelligence, are associated with large substantive gains on intelligence ratings. 13

The effect of political and demographic factors on predicted interviewer ratings. Linear predictions derived from the fifth OLS model displayed in Table 1 (with a combined intelligence rating outcome, and dichotomous measure of college degree attainment). The 95% confidence intervals extend outward from each estimate. All differences are statistically significant, with the exception of intelligence scores on the Wordsum measure.
The results in Table 1 and Figure 3 are strongly consistent with both sets of theoretical expectations. Individuals who are highly interested and knowledgable about politics are rated as more intelligent in the ANES than are individuals who less interested and knowledgable (the Subjective Survey Context Hypothesis). Moreover, wealthier and more educated individuals are also rated as being more intelligent than those less well-off financially and with lower levels of education (the Physical Survey Context Hypothesis).
Clearly, scholars making use of these ratings in the past were correct to point out that “seepage” (Luskin, 1990) from other variables colors interviewers’ ratings of respondent intelligence. What scholars perhaps did not anticipate, though, is that this seepage completely explains away the modest relationship between actual measures of verbal intelligence and interviewer ratings. Interviewer intelligence ratings are less a summary of individuals’ cognitive abilities, and more accurately a depiction of their interest in politics and financial status.
Robustness check: political information ratings
In addition to rating individuals’ intelligence, interviewers were also asked to rate respondents on a number of other characteristics, including their levels of information about politics ( e.g. Zaller, 1992; Levendusky, 2011).
If intelligence ratings are truly a better indicator of political knowledge and interest than cognitive ability, we should expect these two ratings to be highly correlated. Relying on two pooled (pre/post) rating scales, I find that this is indeed the case (weighted r = 0.80). Moreover, in multivariate analyses presented in the Appendix (Table A2), I find that political knowledge and interest, but not cognitive ability, were strongly associated with increased ratings on the information scale (more so than in Table 1). When interviewer ratings of intelligence are added to this model (e.g., the penultimate column of Table A2, with a pooled pre/post information rating outcome, a dichotomous college indicator, and all other controls present in Table 1), it is a statistically significant (p < 0.05) and substantively large (
Conclusion
As hypothesized, survey context plays a key role in explaining the intelligence ratings that interviewers assign to ANES respondents. This research has provided evidence in support of the following four claims.
Tests of verbal cognitive ability are somewhat associated with interviewer ratings of intelligence in bivariate analysis.
Several other factors (e.g. political knowledge and interest, education, income) are at least as highly correlated with interviewer ratings in bivariate analyses.
In multivariate analyses, verbal cognitive ability plays no statistical or substantive role in explaining interviewer ratings of intelligence. Interviewer ratings of intelligence are more strongly shaped by respondents’ levels of political engagement, education, and financial status.
Interviewer information ratings are very highly correlated with intelligence ratings, suggesting that the two are likely measuring substantively similar respondent traits.
The key results also appear to be robust to a number of alternate estimation strategies and model specifications, all of which can be found in the online supplementary materials (Tables A1–A4 and Figures A1 and A2).
Discussion
Political scientists have been interested in the link between cognitive ability and political attitudes for decades, and continue to be interested in the relevance of intelligence in politics. Cognitive ability is an important predictor of voter behavior and competency (e.g. Hillygus, 2005; Hodson and Busseri, 2012; Condon, 2015; Wodtke, 2016), and ought to be studied in more detail with respect to motivated reasoning and other aspects of political judgment formation. This research cautions that scholars hoping to make use of interviewer ratings of intelligence in the ANES for these purposes (or any others) ought to reconsider whether or not these measures are valid measures of cognitive ability. These ratings, in my view, are probably better indicators of political engagement and financial/educational resources.
Yet, while the study of cognitive ability is certainly of interest to political scientists, intelligence ratings remain the most accessible way to measure it in public opinion surveys focusing predominantly on political matters. More-objective measures such as Wordsum have been administered only once in the ANES. Because they make use of protected content, they are not easily administered amongst researchers hoping to study cognitive ability in their own studies and datasets. In order to facilitate this research, large publicly available surveys about politics (such as the ANES) ought to consider offering (or continuing to offer) cognitive ability tests such as Wordsum (perhaps with some modifications, as proposed by Malhotra et al. (2007) and Cor et al. (2012), or constructed in such a way that specific words need not be kept secret) more frequently.
Footnotes
Acknowledgements
I thank Paul Goren, Joanne Miller, Chistina Farhart, Aaron Rosenthal, and members of the American Politics Proseminar & Center for the Study of Political Psychology at the University of Minnesota for their invaluable feedback and suggestions.
Correction (June 2025):
Conflict of interest
The author has no conflicts of interest to declare.
Funding
This research is supported by a grant from the National Science Foundation [grant number 000039202].
Supplemental material
The supplementary files are available at http://rap.sagepub.com/content/3/3. The replication files are available at ![]()
Notes
Carnegie Corporation of New York Grant
The open access article processing charge (APC) for this article was waived due to a grant awarded to Research & Politics from Carnegie Corporation of New York under its ‘Bridging the Gap’ initiative. The statements made and views expressed are solely the responsibility of the author.