
Abstract
Social identity voting (SIV) is a new model of voting behavior based on the principles of social identity theory. We introduce and use this model to analyze roll call votes for the 35th through 112th US Congresses. Comparing out-of-sample accuracy of SIV and Poole and Rosenthal’s Weighted NOMINAL Three-step Estimation (W-NOMINATE), we find that SIV performs better than the one- or two-dimensional W-NOMINATE model and that generally, W-NOMINATE needs up to 10 dimensions to produce accuracy comparable to that of SIV. The differences between SIV and W-NOMINATE are further clarified in three case studies: first, a longitudinal examination of all Congresses; second, an analysis of the 112th House of Representatives; and third, a study of the Tea Party caucus in the 112th House of Representatives. Each study sheds new light on the potential motivations driving voting behavior, supporting our assertion that the SIV and W-NOMINATE models provide two distinct approaches to understanding voting records. SIV, with its emphasis on political identity derived from group membership, expresses combinations of individual and group preferences which contribute to legislators’ ideological classifications.
Introduction
Identifying and understanding ideological categories enables observers of and participants in a political process to summarize complex political positions efficiently. This observation provides the foundation for many models in political science used to determine ideological categories. Spatial models, most notably the NOMINAL Three-step Estimation (NOMINATE) models (Poole and Rosenthal, 1985), place both legislators and roll call votes into a spatial context where the relative positions of the legislators and the votes create the categories. In these systems, the positions of legislators, which are given as ideal points in the geometric space, serve as ideological markers.
One of the main findings in the NOMINATE literature is that for most of the history of the United States Congress, one-dimensional models reflecting our colloquial “liberal/conservative” dichotomy are sufficient to explain the great majority of roll call votes. The ideal points of the legislators on this ideological axis are estimated from the roll call votes. As such, they serve as summarizations of various forces that can influence the legislators’ votes, including personal preferences, party preferences, and constituent opinion. Ideological groups are then determined by groupings of ideal points. In this way, ideal point methods (spatial models) derive ideological categorizations from the characteristics of the individuals.
We take a different approach to the problem of identifying ideology and sorting legislators into ideological categories. While spatial models summarize legislators as ideal points measured relative to the positions of votes, our model, which we call social identity voting (SIV), views the legislator’s ideology in terms of a weighted sum of the ideologies of the groups to which they belong. This is motivated by social identity theory (SIT), which posits that an individual’s social identity is determined by the collection of groups to which the individual belongs (for a review, see Hogg, 2006). Legislators derive utility from voting with the groups to which they belong and from voting against those to which they do not belong. As a consequence, legislators will select groups with ideologies consistent with their own; subsequently, as group members, they face pressure to conform in ideology to the majority ideology of that group. Furthermore, in this model groups benefit from larger memberships, as determining the outcome of votes generates political power for the group and detracts from other groups’ political power.
Thus, the SIT framework suggests a model – the social identity voting model – whose components can be estimated from roll call data. First, we create the communities using the roll call votes to group legislators together. Second, we use the resulting mean votes of the communities to define their common ideological positions. Doing this allows the communities to evolve over time, without imposing groupings and labels that may not be universally appropriate. We make one exception to this principle – we fix the party caucuses as the dominant communities for all the Congresses we study. We do this for three reasons. First, in the United States, party affiliation carries a great deal of information and weight – parties often provide infrastructure and money to support campaigns, and within Congress, the legislative structure is defined entirely in the context of party caucuses. Second, parties form the largest coherent ideological units in a two-party system. Third, applying the algorithms described below to the data yields partisan communities broadly consistent with other results in the literature in almost all years (e.g. Porter et al., 2005; Waugh et al., 2012).
To detect the communities, we use a variant of the partition decoupling method (PDM) (Leibon et al., 2008) applied to roll call data. In this setting, the PDM detects and delineates multiple partitions of a legislature at different scales or layers. A first layer in the data is defined by party. After identifying and removing the effect of the first layer in the voting record, we derive the second layer from the residual data. This layer reveals ideological groupings that cannot be explained by party identification.
SIV applied to the US Congresses yields three main findings. First, SIV outperforms W-NOMINATE with respect to out-of-sample accuracy when we restrict to one- or two-dimensional spatial models. In order to obtain comparable accuracy for the Senate, W-NOMINATE requires 10 dimensions. Even with this, in contrast to higher dimensions in the W-NOMINATE model, the SIV clusters are readily interpretable. For the House of Representatives, the two are comparable except for two periods – after the Civil War, and in the 1970s and 80s – where SIV uses only one layer based on party and substantially outperforms W-NOMINATE. Second, we find that in many instances SIV and W-NOMINATE contain different information: there is no clear mapping from ideal points to SIV groups. This indicates that SIV is a new explanatory model for ideological voting behavior. Third, SIV reveals interesting and subtle details about the divisions between groups. In our analysis of the 112th House of Representatives, for instance, while some issues reveal groups whose members are defying their party’s position, we find that several groups are differentiated from each other by journal votes taken in advance of contentious votes. Following Patty (2013), we interpret this as intra-party signaling, demonstrating a milder break from party orthodoxy for some groups than others. Building on this new fine-grained ability to differentiate inter-party signals, we also use SIV to understand the extent to which the Tea Party is an independent ideological unit within the Republican Party at that time. We find that it is not, but that it is rather two dominant, ideologically distinct subgroups defined in opposition to the broader party. In total, these findings demonstrate the novelty and utility of SIV.
Theoretical underpinnings
Group membership and SIT
SIT is a theoretical framework for understanding group dynamics. The foundation of SIT (Tajfel and Turner, 1979, 1986) rests on a distinction between personal and social identities, where social identity is largely constructed through group membership. Central to SIT is the thesis that in social situations, social identity is the dominant force in decision-making and action.
There is a large volume of literature on the construction and maintenance of social identity through group affiliation (see Hogg, 2006), and while the full properties of these mechanisms are not yet settled, there are some basic principles that form a common foundation. First, individuals aim to create and sustain a positive social identity through group membership. Positivity is derived from favorable comparisons between the individual’s group(s) and groups to which the individual does not belong. Thus, individuals are motivated both to accentuate the differences between groups and raise the reputation of their group(s). Second, once formed, groups can exhibit in-group bias (Messick and Mackie, 1989; Mullen et al., 1992). Bias can be both a result and a source of group cohesion, although it is not a necessary accompaniment (Hinckle and Brown, 1990).
These kinds of ideas carry over to the political arena. In political bodies, social identity is formed through membership in many different types of groups, including political parties, caucuses, and committees. We posit that the public ideology of a legislator is largely determined by their social identity, which in turn is at least in part articulated through their group memberships. Not all group memberships are explicitly declared; some can be revealed through action. To this end, the theoretical underpinnings of SIT motivate the articulation of group structure derived from legislator’s votes.
Social identity voting
SIV, based on SIT, thus emphasizes the construction of social identity and its role in ideological identification. SIV is built by delineating groups within the legislative body, which in turn enables the estimation of weights measuring degrees of group membership for each legislator. To comport with the other aspects of SIT, groups must be coherent and facilitate intergroup comparison, which we accomplish by assigning utility to the legislator based on his/her actions with respect to the group’s positions. We assess the utility through the observation of public votes: legislators will have high utility when voting in line with their group(s) and low utility when voting against them. A central component of group reputation is political power – large, ideologically coherent groups have greater ability to determine the outcome of votes. Thus, groups strive to maximize membership without compromising their ideological profiles.
The NOMINATE family of models makes the strong basic assumption that both legislators and bills can be embedded into a spatial landscape where their relative positions determine voting behavior. One of the key novel features of SIV is a relaxation of this assumption: in SIV, legislators’ votes are determined by the potentially conflicting ideological markers of the groups to which they belong.
Methodology
Formal presentation of SIV
The vote data of legislator l who casts

where
The motivations
For a given vote,
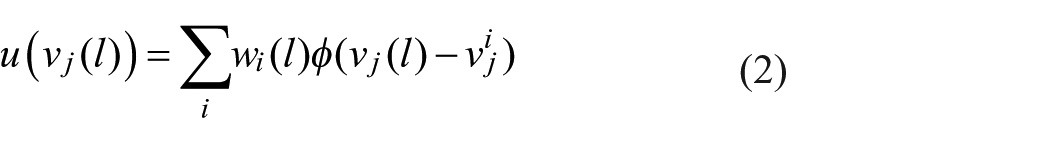
where
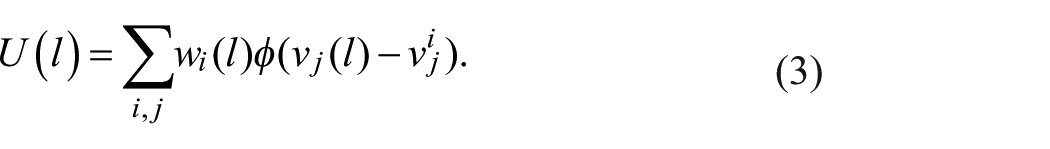
It is easy to maximize utility if there are no other constraints by simply placing each legislator into his or her own ideological group. Then, the motivation of such a (singleton) group is simply the vote vector of the legislator, and utility is maximized. But this group consisting of a single legislator has little political power. Consequently, we require groups which are simultaneously large and have high total utility over all members to balance political power and coherent ideology.
After computing a set of motivations and weights, we have an ideological representation of each legislator and an approximation of their voting pattern according to their ideology:

The initial application of SIV produces the components of this representation: the partitioning of the legislators into groups, the ideological marker associated with those groups, and the social identity of the legislators derived from group membership. Moreover, we can iterate SIV multiple times, revealing different overlapping layers of ideological composition.
Determining the elements of SIV
There are many different methods to find the groups that define SIV. At one extreme, we can fix the groupings according to information external to the roll call votes. At the other, the groupings are determined from iterative analysis of the roll call data itself. The latter thus shares some similarities with NOMINATE, where the components of the model are estimated directly from the data. We take something of a hybrid approach and construct a SIV model with two layers, one fixed a priori and the other derived from data. The groups forming the first layer,

The associated weight vector is the least squares solution to

We then consider the residual data set consisting of the voting data not accounted for in the approximation given by equation (4):

The various pieces of the model for a second layer are now calculated using a network theoretic formulation wherein legislators are linked together by edges weighted by the similarity of their voting records. Groupings are derived as an optimal partitioning of the network. We use spectral clustering to partition the legislator set into k clusters,
Spectral clustering requires two parameters: k, the number of clusters, and r, a parameter internal to the algorithm related to the innate dimensionality of the data. To estimate these, we use a holdout validation framework often used in machine learning. We form a testing and training set from the data. Using the training data to fit the model, we then predict the testing data and measure the out-of-sample accuracy of the model:
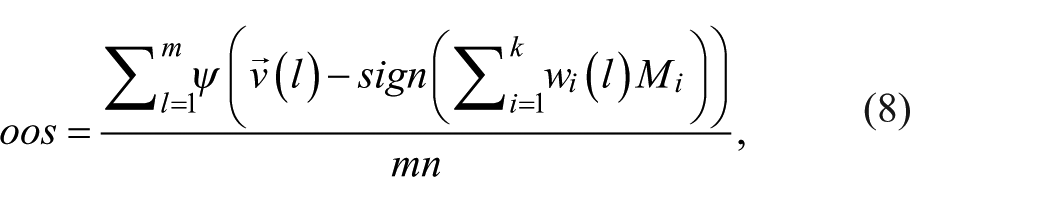
where
Others have used singular value decomposition (Porter et al., 2005, 2007, 2009) or modularity (Waugh et al., 2012; Zhang et al., 2008) for network community detection in voting data. These methods differ by optimizing different objective functions than does spectral clustering, but the main difference between SIV and these approaches is the construction of a subsidiary layer of overlapping structure.
For purposes of exposition and considerations of length, technical details, code, and instructions for its use appear in Appendix 1.
Data
We retrieved roll call vote data for the 35th through 112th sessions of the US Congress from Keith Poole’s Voteview website. In order to make comparable the results of SIV to W-NOMINATE, we use the standard pre-processing used in W-NOMINATE’s implementation in R: votes with less than 2.5% of the total legislative body in the minority are removed, as are legislators who voted on less than two thirds of the votes. For SIV, we code “yea” votes as 1, abstentions as 0, and “nay” votes as −1.
Results and discussion
One layer SIV: Party labeling carries a great deal of information
The one-layer model, encoding only party identification, has excellent out-of-sample accuracy (median 84.3% in the House of Representatives and 80.6% in the Senate). This result is consistent with literature that demonstrates party as a dominant factor in determining voting patterns and further supports our choice of the fixed first layer.
SIV outperforms W-NOMINATE
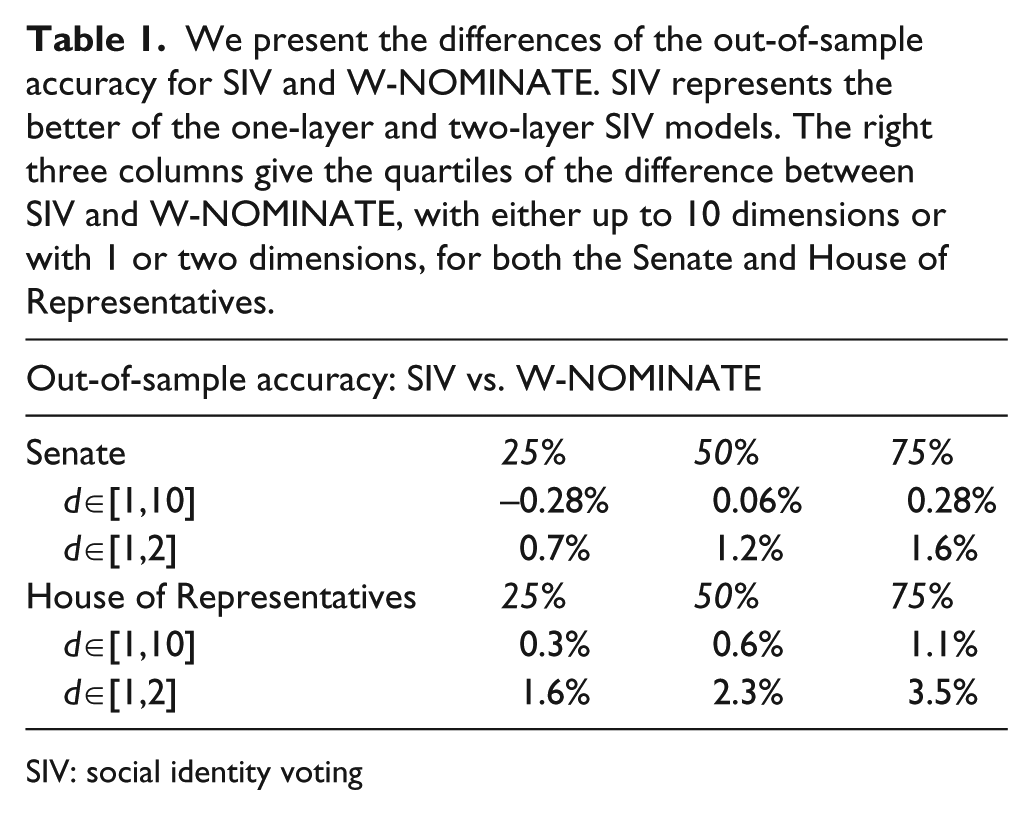
In out-of-sample accuracy, SIV generally performs as well or better than high dimensional NOMINATE models. 1 Comparing SIV to what Poole calls the “substantive dimensions” (Poole, 2005: 141–155) – dimensions one and two – we find a persistent small advantage to using SIV. Figure 1 shows the out-of-sample accuracy of the SIV one- and two-layer models (denoted SIV-1 and SIV-2) and that of W-NOMINATE with at most 10 dimensions (WN-10). Table 1 shows the quartiles of the differences between the out-of-sample accuracy of SIV vs. WN-10 or W-NOMINATE with one or two dimensions (WN-2). In the Senate, SIV-2 always outperforms SIV-1 and WN-2, while it is very similar to WN-10. The picture in the House of Representatives is more complicated. In two periods, after the Civil War (1876–1883) and again in the 1970s and 1980s, SIV-1 outperforms all models and the better of the two SIV models outperforms both WN-10 and WN-2.

A comparison of the out-of-sample accuracy of the one- and two-layer SIV models and W-NOMINATE (using up to 10 dimensions) for the 35th –112th US Congresses. In both graphs, the SIV one-layer model is represented by diamonds, the two-layer model by circles, and W-NOMINATE by squares.
We present the differences of the out-of-sample accuracy for SIV and W-NOMINATE. SIV represents the better of the one-layer and two-layer SIV models. The right three columns give the quartiles of the difference between SIV and W-NOMINATE, with either up to 10 dimensions or with 1 or two dimensions, for both the Senate and House of Representatives.
SIV: social identity voting
This is a new contribution to the discussion of the dimensionality of roll call data (Cragg and Donald, 1997; Heckman and Snyder, 1997; Poole, 2005; Poole and Rosenthal, 2008; Poole et al., 1992). The debate over dimensionality has been lively at times, but the general conclusion that has emerged is that one or two substantive dimensions explain virtually everything for US Congresses (Poole, 2005). Additional dimensions seem to be “largely fitting ‘noise’” (Poole and Rosenthal, 2008: Figure 3.6; 64), a point of view justified in part by the difficulty researchers have finding apt descriptions for the higher dimensions (the first dimension is interpreted in terms of economic issues and the second, when relevant, is tied to social issues). In distinction, SIV provides a different set of dimensions which, when used predictively, significantly best WN-2 in out-of-sample accuracy. These dimensions are also interpretable: the contrast between the motivation vectors of the groups provides ideological markers with which to discriminate between them.
Both W-NOMINATE and SIV have a comparable number of variables that are estimated or calculated from the roll call data. We can encode the W-NOMINATE model with
The 112th House of Representatives: a closer look
A detailed analysis of the 112th House shows two things: SIV and W-NOMINATE uncover different information about the legislators, and the motivation vectors give natural interpretations of the SIV groups.
To start, suppose the two models contain similar information. We then would expect similar W-NOMINATE scores for SIV group members and score separation between different groups. We find some groups follow this pattern, but others are not well-characterized by W-NOMINATE scores. Figure 2 shows groups 1–6 are bipartisan and contain members with very disparate W-NOMINATE scores. Groups 7–9 are partisan – one group of moderate Democrats (7) and two Republican groups (8, 9) – and while their W-NOMINATE scores are fairly coherent, they still overlap with those of other groups. Table 2 in Appendix 2 lists group membership.
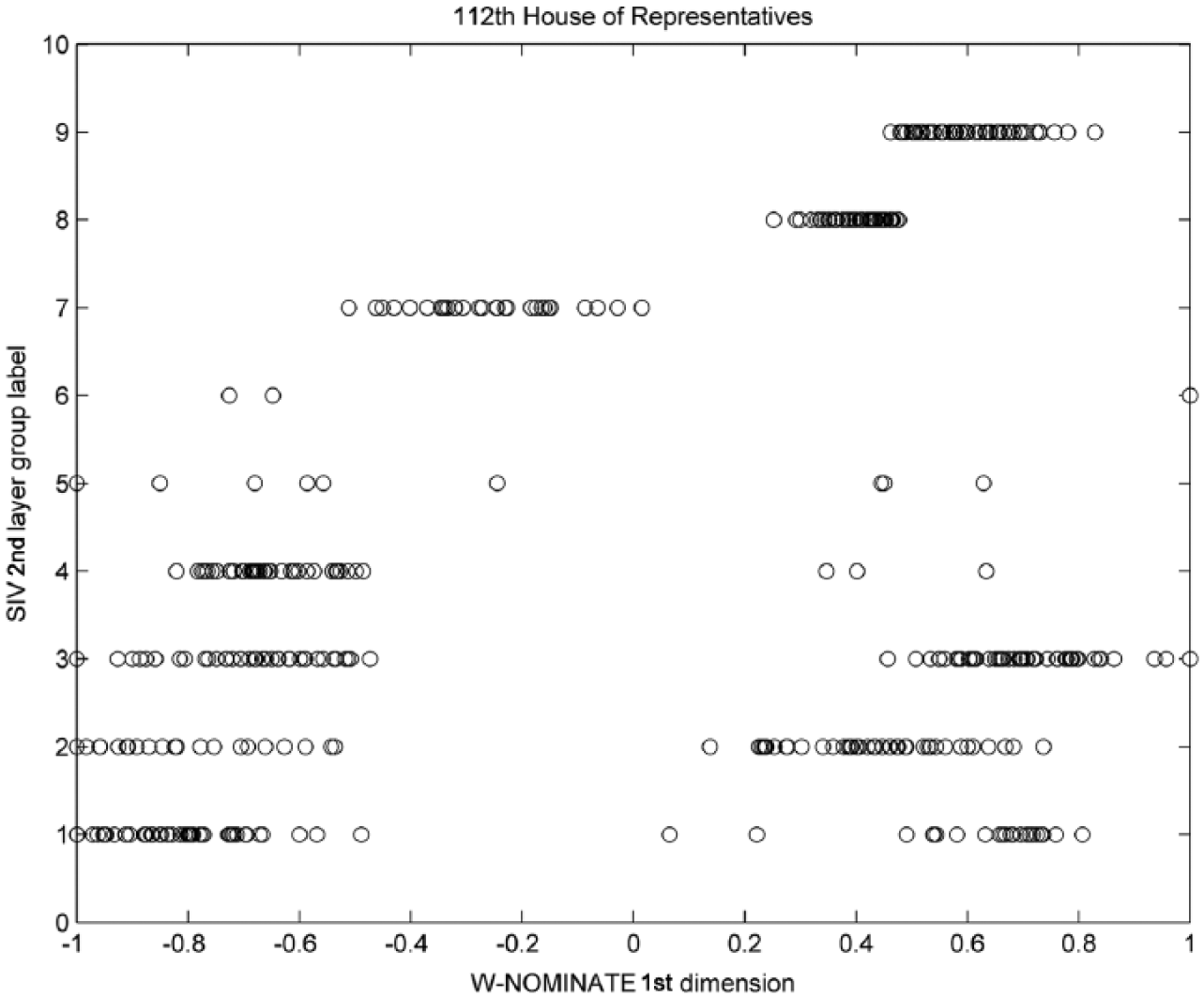
W-NOMINATE scores for the nine groups identified in the second layer of the SIV model for the 112th House of Representatives.
We can assess what distinguishes these groups by considering their motivation vectors. To compare group
A significant number of these votes are journal votes, or procedural votes that record the day’s work. Some have argued these journal votes serve a vital organization role as a form of intra-party signaling: party leaders call for such votes as a type of quorum call in advance of important or controversial votes to ensure that a sufficient number of their votes are present before proceeding (Patty, 2013; Sinclair, 1995).
Appendix 2 details the Congressional votes before which the journal votes were called. While these votes appeared as distinguishing votes between several pairs of groups, they were most significant in distinguishing Group 1 from 2, and 2 from 3 and 4. In these cases, the journal votes give a measure of the members’ loyalty to their party. For example, most of the members of Group 1 vote with their party on both the journal votes and the associated controversial votes that follow, while most of the members of Group 2 vote against their party on journal votes but vote with their party during the subsequent Congressional vote.
Other than journal votes, these groups are defined primarily along issues of appropriations and matters of national security. This illumination of ideological structure is not directly available via spatial models such as W-NOMINATE, where one would need to look directly at these votes and the groups of legislators to parse the same information. One of the strengths of SIV over such spatial models is the ability to identify such groups and their motivation vectors automatically.
Case study: the Tea Party caucus
The “Tea Party” is a faction of the Republican Party that, in the 112th Congress, formalized its membership as a recognized caucus. Using SIV, we can analyze the ideological structure of the Tea Party to understand the extent to which it is an independent ideological faction.
In the 112th House, the Tea Party caucus splits mainly between groups 3 and 9, with 40% of the Caucus in each of these groups. Group 3 includes Representatives King (R-IA), Bachmann (R-MN), and Gohmert (R-TX), while 9 includes Miller (R-CA), Barton (R-TX), and Sessions (R-TX). Figure 3 shows a version of Figure 2 with the Democrats removed and the Tea Party caucus highlighted. As noted, groups are separated from one another on issues of foreign policy and Defense – specifically on a resolution to remove troops from Libya, appropriations for the Department of Defense, and bills funding military construction and the U.S. Department of Veterans Affairs (VA). They are also separated by two other bills: a bill funding the Department of Agriculture, Rural Development and the FDA, and one concerning the Education Sciences Reform Act. The clearest delineation between the Tea Party portions of the groups comes on an amendment to the Defense Appropriations bill: the majority of the Tea Party members in Group 9 voted against the amendment, while a majority of those in Group 3 voted for it.
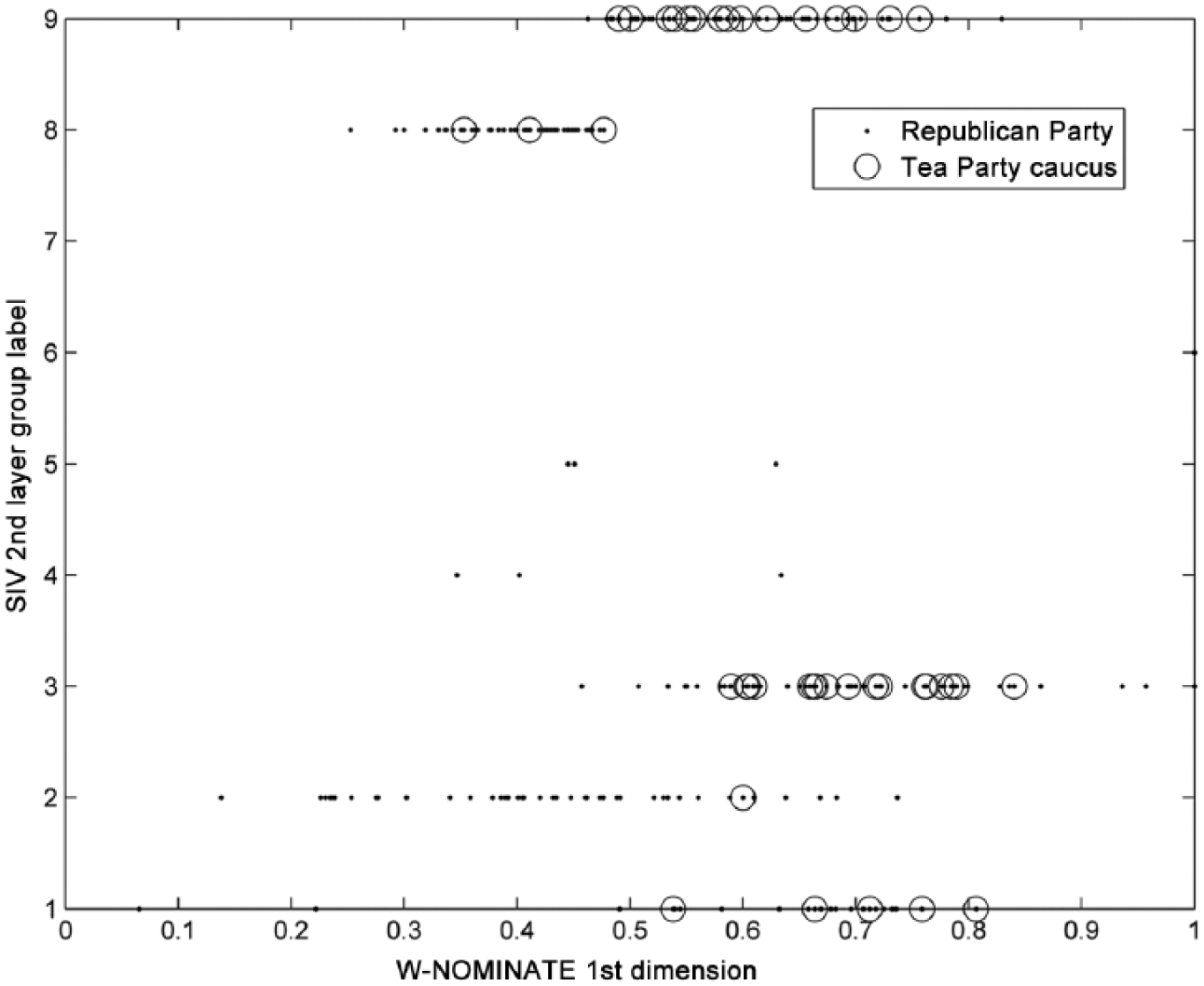
W-NOMINATE scores for the Republicans in the 112th House arranged by the group labels of the SIV second layer. Circled black dots represent Republican members of the House who are members of the Tea Party caucus.
If the Tea Party caucus is an independent ideological unit, we would expect that the Tea Party would largely aggregate against other factions of the Republican Party after we remove the first layer. Instead, it breaks down into two primary groups with particular issues separating the subsets. While the one-dimensional W-NOMINATE model also demonstrates that the Tea Party is diffused throughout the Republican Party, with ideal points scattered through the ranks of the entire party, the one-dimensional model misses the multiple party divisions that only the SIV approach can illuminate.
Conclusion
SIV provides a new method for understanding ideological categorizations based on voting behavior. SIV solidly outperforms W-NOMINATE in out-of-sample accuracy when the latter is restricted to one or two dimensions. Allowing W-NOMINATE to use more dimensions brings its out-of-sample accuracy roughly in line with SIV, but at a cost: higher dimensions in NOMINATE models are difficult to interpret, while the groups in SIV are easily compared through differences in their motivation vectors.
SIV expresses ideological information differently from W-NOMINATE, providing an alternate analysis complementary to the analysis of ideal points. A direct comparison of the two for the 112th House of Representatives shows that there is no clear mapping between the two descriptions, a result that is typical of many sessions of Congress. Consequently, we conclude that SIV and W-NOMINATE provide different but equally valid methods for distilling roll call voting data into manageable representations.
Three investigations demonstrate the potential usefulness of SIV over NOMINATE. We identify two periods – between 1876 and 1883, and in the 1970s and 1980s – where the one-layer SIV model, using only party identification, outperforms W-NOMINATE significantly. This indicates that situating legislators with respect to the mean voting vectors of the two party caucuses is in those periods a superior predictive model. Second, we discover that several groups distinguished from each other by journal votes in the 112th House. These votes, interpreted as within-party signaling near contentious votes, show that SIV detects fractures within party caucuses on two levels. When journal votes distinguish groups, the groups are loyal to their caucus, but are willing to send discordant signals to their leadership. On the other hand, when the actual votes distinguish groups, we see groups whose members are publicly and directly voting against the party wishes. Lastly, an SIV-directed analysis of the Tea Party in the 112th House shows a split into essentially two subgroups which have issue-specific ideological differences, demonstrating that the Tea Party is not an ideologically distinct faction of the Republican Party.
None of these findings are easily derived from the ideal points produced by W-NOMINATE. By focusing on group rather than individual preference, SIV provides a new lens through which to view the forces that impact legislators’ voting behaviors and motivations.
Footnotes
Appendices
Funding
This work was supported by AFOSR under award FA9550-11-1-0166.
Declaration of conflicting interest
The authors declare that there is no conflict of interest.
Supplementary material
The replication files are available at: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/IMLVVG&version=DRAFT