
Abstract
Background
Word recognition tests must be conducted in the native language of the listener to obtain valid word recognition scores. Existing Singapore Mandarin speech audiometry test materials that are disyllabic lack in sensitivity and are not phonologically balanced.
Objective
The purpose of this study was to address those limitations and develop a set of word lists for testing speakers of Singapore Mandarin.
Methods
The word lists were developed over three phases. (1) Frequently occurring words were chosen from a database consisting of subtitles from local Mandarin programmes, and subjected to familiarity rating by 50 native Singapore Mandarin speakers. (2) Phonologically balanced word lists were created and professionally recorded using words rated as familiar in phase 1. (3) Psychometric curves of words were obtained from 20 normal-hearing native speakers and word lists were analysed for perceptual equivalence.
Results
Sixteen phonologically balanced word lists consisting of 25 monosyllables each were created in phase 2. Eight of the 16 lists were found to be perceptually equivalent.
Conclusion
Word lists developed in this study addressed the limitations of existing Singapore Mandarin speech audiometry materials. The word lists need to be validated with normal-hearing and hearing-impaired Singapore Mandarin speakers before they can be used clinically.
Keywords
Introduction
Speech audiometry is an integral part of the audiologic battery of tests. By using speech stimuli, it supplements information that pure tone audiometry and other tests within the battery are unable to provide. Speech audiometry can be used in validating pure tone audiograms, providing a differential diagnosis and assessing the amount of benefit that a hearing device is providing for an individual with hearing impairment.1–3
It is well documented that speech audiometry should be conducted in the native language of the patient,4,5 so as to minimise the chances of low speech scores being confounded by poor linguistic ability. As such, many countries have developed speech audiometry test materials in their non-English native language for testing their own population.6–8 For example, Mandarin speech audiometry materials have been developed in China9,10 and Taiwan 11 for their primarily Mandarin-speaking populations.
In Singapore where the total population is 5.69 million, 74.2% of the resident population is ethnic Chinese. 12 A total of 1.08 million residents who are over 5 years of age cited Mandarin as the language that they speak most frequently at home. 13 There is thus a need for Mandarin speech audiometry materials to be available in Singapore to test this group of Mandarin speaking residents. This was the motivation behind the development of the SC-10 – a set of word recognition test materials in Singapore Mandarin by Lee and Lee. 14 Soh and Loo 15 further supported this effort by Lee and Lee, 14 as the Mandarin speech audiometry materials developed in China and Taiwan were found to contain words that are unfamiliar to Singapore Mandarin speakers, and are hence not suitable to be adapted for local use.
The SC-10 Singapore Mandarin speech test materials developed by Lee and Lee 14 contains 10 lists of 10 disyllabic word pairs. The words were chosen from The Frequency Dictionary of Daily Chinese Words Encountered by Singapore Students. 16 Two-stage elimination process was carried out to shortlist the appropriate and most familiar words for final recording. The final wordlists were validated on 25 normal hearing subjects; test-retest reliability was established as there was no significant difference on test and retest scores for 20 of the normal hearing subjects. Although the SC-10 was developed with good intention for practical use in clinical setting, there are a few flaws with this existing Singapore Mandarin speech audiometry material.
First, Lee and Lee 14 rationalised that disyllabic words were more appropriate to be used in developing Mandarin speech test materials, as Mandarin words are hardly monosyllabic. However, the authors did not acknowledge the possibility of increased contextual cues in disyllabic words that might affect the speech recognition scores of hearing-impaired individuals. Word recognition (or discrimination) test materials in English have been traditionally designed to be monosyllabic with good reason. An increase in number of syllables within a word increases the chance of a word being heard correctly, due to the presence of contextual cues. 17 In Mandarin, the contextual cues added to each item by having an additional word is two-fold in terms of the possible word pairings and tones of the word pairs.
Validation of SC-10 had only been conducted with normal hearing subjects 14 . In contrast, Soh 18 conducted a preliminary study using the SC-10 word lists to test normal hearing participants (n = 29) as well as hearing-impaired participants (n = 23). The study found that the hearing-impaired participants with mild to severe sensorineural hearing loss (SNHL) scored as well as the normal hearing participants, achieving a maximum score of 95%–100% for speech recognition tests in quiet. This is inconsistent with existing literature for maximum scores in English word recognition tests, which are expected to decrease with greater severity of SNHL.19–21 In other words, the SC-10 wordlists are not sensitive in differentiating the hearing-impaired individuals from the normal hearing population.
Soh 18 posited that the unexpectedly good performance of the hearing-impaired group using the SC-10 wordlists might be due to the rich contextual cues present in disyllabic Mandarin wordlists. Mandarin is a tonal language with most of the word finals and suprasegmental tones present in low frequencies. As most of the participants with SNHL had better hearing in lower frequencies as compared to high frequencies, it is not surprising that they were able to correctly guess the words in SC-10 based on the possible final and tonal pairings. Thus, the resulting scores were inflated by the presence of contextual cues derived from possible word pairings, instead of a true reflection of the discrimination difficulties faced by a person with hearing-impairment.
Second, Lee and Lee 14 also claimed that the need to have a phonetically balanced wordlist for speech audiometry materials remains debatable based on the report by Martin, Champlin and Perez. 22 Hence, the SC-10 wordlists have been designed based on word familiarity, instead of meeting the criteria of phonetic or phonemic balance. The concept of phonemic balance in speech audiometry17,23,24 serves the purpose of ensuring different sounds occurring in the language are tested when word recognition tests are conducted. This enables clinicians to identify specific sounds that the patient might have more difficulty in recognising. However, Mandarin words have a different structure from English words. Therefore, instead of phonetic or phonemic balance, an equivalent concept in Mandarin would be that of phonological balance, where initial consonants, finals and tones are balanced in the same way that they occur naturally throughout the language. 9 Although Lee and Lee 14 recognised the importance of phonological balance by having sufficient words (at least 50) per list, the authors only created 10 words per list in the SC-10 for clinical use, citing practicality as the main reason. Hence, the SC-10 wordlists are limited in their ability to incorporate phonological balance due to the brevity of each list.
Moreover, Thornton and Raffin 25 found that the variability of word recognition scores (WRS) increases when the number of items within the lists decreases. At a word recognition score of 50% where standard deviation is the largest, the intra-subject standard deviation for a 50-item list is around 7%. This increases to approximately 10% for a 25-item list, and further increases to about 16% for a 10-item list. Hence, 10-item word lists such as those in the SC-10 may not be reliable in providing an estimate of a patient’s speech recognition abilities, even though they take the least amount of time to administer.
As such, the aim of this study is to develop an alternative set of Singapore Mandarin word recognition test materials that will address the identified gaps of the existing SC-10 wordlists. This new set of monosyllabic speech audiometry materials has been designed to incorporate phonological balance into each word list, such that the proportions of initial consonants, finals and tones within each word list mimic their respective frequencies of occurrence in Singapore Mandarin. To maintain a balance between clinical efficiency and a reasonable standard deviation in the obtained WRS, 25 items (monosyllabic words) were created for each list. As the materials are ultimately meant for auditory testing, emphasis was placed on sources of spoken Singapore Mandarin instead of written texts. With reference to Brysbaert and New’s 26 study which found film subtitles to be good estimates of word frequencies, a database of spoken Singapore Mandarin samples was approximated from subtitles of local Mandarin television programmes. This database served as the basis on which the occurrence frequencies of the initial consonants, finals and tones were determined. Phonologically-balanced word lists were created based on analysis of this database, and the word lists were subsequently tested to be perceptually equivalent to one another.
Methods
The development of the word recognition test materials in this study involved three phases: (1) selection of suitable words to be included as test items, (2) creation of phonologically-balanced word lists and (3) establishing the perceptual equivalence of word lists.
Phase 1: Selection of suitable words and familiarity rating
It is important that the test materials are made up of words that are familiar to the average speaker within the test population, so that test results are not affected by one’s language competency. 5 Conventionally, corpora of written texts have been used as sources of test items to be included in a speech recognition test.17,23,27 There are limitations to this approach as written texts are often edited to read better and have fewer repetitions. 26 This could mean the inclusion of words that would not normally be used in spoken speech. On the other hand, building a corpus of spoken speech can be extremely laborious as it involves recording spontaneous speech and transcribing the collected data thereafter. 28 Brysbaert and New 26 proposed using film subtitles as a convenient and valid way to establish a speech corpus, since subtitles are essentially transcriptions of spoken speech. Instead of using local films which are produced at a rate of only about 11 films per year with poor attendance, 29 a database of commonly spoken Singapore Mandarin words was built using subtitles from local Mandarin variety shows on free-to-air channels.
Free-to-air television has traditionally enjoyed high viewership in Singapore, and the two available Mandarin channels are among the top three channels with the highest reach. 30 The variety shows that had their subtitles included were those that were produced locally and featured local hosts and guests. In total, over 45 hours of content from 15 different programmes were included. The programmes covered a range of themes such as food, media, health, and Singaporean history. The total number of words extracted from the subtitles of these programmes was over 500,000, and the number of unique Mandarin characters totalled up to 3,391. These words formed the database of words that were commonly spoken and heard by the average Singapore Mandarin speaker.
With the intention to create at least 16 initial word lists of 25 monosyllables each, the top 500 most frequently occurring characters in the database were chosen. These 500 characters were divided into non-overlapping sub-lists of 100 characters each and subjected to a familiarity rating exercise by Singapore Mandarin speakers. Participants had to be born and raised in Singapore, or have grown up in Singapore ever since they began formal education. They needed to be able to read local Mandarin newspapers and be conversant in Mandarin. Ethics approval for the study in this phase was granted by the National University of Singapore Institutional Review Board (S-20-012). Participants provided informed written consent before participating in the study.
Fifty Singaporean participants, aged between 40 and 90 years old, were recruited for this familiarity rating exercise. This age group was chosen because it has the highest number of native speakers of Singapore Mandarin, as Chinese schools (that used Chinese as the language of instruction) were as popular as schools that taught using English as a medium (English schools) in early years. Due to the change in education policies four decades ago, English has become the main instructional medium used in schools. Hence, the majority of the Singaporeans younger than 40 years of age are primarily English speakers. 31
During the familiarity rating exercise, each participant was presented with a sub-list of the 100 characters in print, with the Hanyu Pinyin accompanying each character. For each character, they were asked “How frequently do you hear this word in your daily life?” and instructed to provide a rating on a 5-point Likert scale (1-Never; 2-Almost never; 3-Sometimes; 4-Frequently; 5-Always). The mean rating was calculated for each of the characters, and characters that were rated as familiar were used in the creation of phonologically balanced word lists.
Phase 2: Creation of phonologically balanced word lists
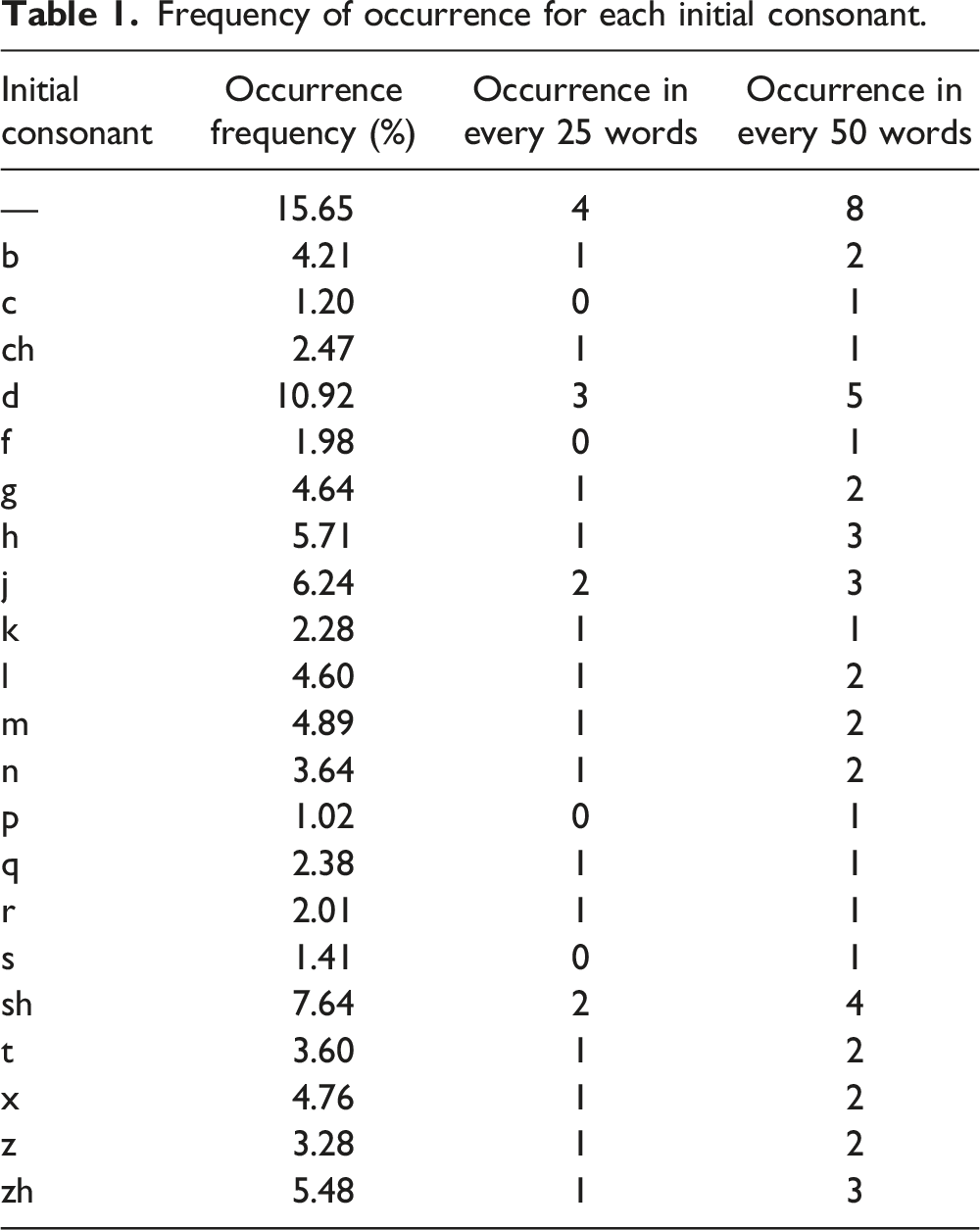
Frequency of occurrence for each initial consonant.
Frequency of occurrence for each final.

Frequency of occurrence for each of the four suprasegmental tones.

Word lists were created by mimicking the occurrence frequency of each initial consonant, final and tone as much as possible, using the syllables that had been rated as familiar to the local population in phase 1. In general, the number of initial consonants within each list was determined first according to Table 1. For example, the initial consonant “b” had a frequency occurrence of 4%, and was to occur once in every list. All syllables rated as familiar in phase 1 and beginning with initial consonant “b” were put through a random list generator to determine which list each “b-” syllable would be assigned to. This was repeated for every initial consonant in accordance with Table 1. With each list now populated by syllables and meeting the targets for initial consonants, the occurrence of each final and tone within each list was then tabulated. The subsequent step required manual swapping of syllables within the list of familiar syllables to ensure that the finals and tones were represented in the proportions stated in Tables 2 and 3 respectively. Finals with occurrence frequency of less than 0.5% were excluded from the word lists as they were deemed as uncommon occurrences in everyday speech sounds. Neutral tones were also excluded from the count as they cannot occur independently in isolated monosyllables. 32 A total of 16 word lists (Lists 1–16) consisting of 25 monosyllables each were created (Appendix A). Words within each list were randomised, and subsequently arranged such that consecutive test items do not have the same initial consonant, final or tone.
Of the 400 test items contained in the 16 lists of 25 monosyllables, there were 144 duplicated syllables. The remaining 256 unique syllables were recorded with the voice of one male and one female, both of whom are native speakers of Singapore Mandarin. The male speaker majored in linguistics and is proficient in Mandarin and English. The female speaker is a speech therapist and is also effectively bilingual in Mandarin and English. Both speakers were born and raised in Singapore and received at least 12 years of formal education in Singapore.
Recording was carried out in a professional recording studio with the assistance of a recording engineer. In line with the International Organization of Standardization (ISO) 33 standards of recording requirements for speech audiometry, the recording environment had a reverberation time of 0.24 s and the signal-to-noise ratio was maintained above 40 dB throughout the recording process. A condenser microphone (Neumann KM184) with a linear frequency response (125 Hz–8000 Hz) was used together with a SE Electronics pop filter. A Unison Enabled Mic Preamplifier was used, and signal digitization was done with the Apollo Firewire audio-interface from Universal Audio. The sampling rate and bit depth employed were 44.1 kHz and 16 respectively.
Each speaker was asked to record each syllable four times before moving on to record the next syllable. This was done to make allowances for any tokens that were not pronounced ideally during the recording process. Thereafter, a three-step approach was taken to pick the best token for each syllable. The tokens were first analysed acoustically and visually via their spectrograms in Praat software. Tokens that had unintentional distortions, clicks, noise and uneven tone contours were removed. 34 Subsequently, four listeners were asked to listen to the remaining tokens of each syllable and (1) type out what they thought the syllable was and (2) pick the token that sounded the most natural. The four listeners consisted of two audiologists and two speech therapists, all of whom are native Singapore Mandarin speakers. Syllables had to be correctly identified by at least three out of four listeners in order to be included in the subsequent phase of the study. For each of these syllables, the token with the highest number of votes for naturalness was used. The average root-mean-square (RMS) value of all the tokens was calculated and all the tokens were then scaled to this value using Audacity software.
Phase 3: Establishing perceptual equivalence of word lists
This phase of the study involved recruiting native Singapore Mandarin speakers to establish the psychometric curve of each recorded monosyllable. A total of 20 subjects participated in the study, and they all had normal hearing in at least one ear (i.e. hearing thresholds that were less than or equal to 20 dBHL at octave frequencies from 250 Hz to 8000 Hz). Insert earphones were used and participants’ better hearing ear (determined by the pure tone average of 500 Hz, 1 kHz and 2 kHz) was tested in this study. Each monosyllable was played from a sub-threshold level in 2 dB increments and participants were asked to repeat the syllable out loud as soon as they can recognise the syllable. There were no carrier phrases, but a predictable brief interval was held after every presentation to allow the participant time to respond should they have recognised the word. If there was no response from the participant, the same syllable was then presented at 2 dB louder than the previous presentation. The lowest intensity level at which the syllable was correctly recognised was documented. This was repeated for 247 syllables recorded in the female voice and 252 syllables recorded in the male voice. Ethics approval for this phase (phase 3) of the study was granted by the National University of Singapore Institutional Review Board (NUS-IRB-2021-24). Participants provided informed written consent before participating in the study.
Based on the percentage of participants who could correctly recognise the syllable at each intensity level, psychometric curves were fitted for each syllable, using the following function:
Results
Phase 1: Selection of suitable words as test items
A total of 50 participants (13 males, 37 females) took part in this phase of the study. The mean age of all participants was 55 years old (SD = 9.99). All 50 participants had completed at least primary school education and 22 of them attended primary schools that used Mandarin as the primary language of instruction. Of the 500 most commonly occurring characters within the database, 494 characters had mean ratings of 3.0 or higher. Out of these 494 characters, 467 of them had less than 25% of respondents that gave a rating of 1 (Never) or 2 (Almost never).
Even though there were a total of 467 characters that met the criteria to be deemed as familiar to the participants, the number of unique syllables from these 467 characters was only 389. This is because there are many homophones in Mandarin. For example, the character “不” which means “no”, and the character “步” which translates into “(a) step” both have the Hanyu Pinyin of “bù” and have identical pronunciations. In Mandarin speech audiometry, having two different characters with the same pronunciation is redundant as they would essentially be regarded as the same syllable. Hence, the focus here is on the number of unique syllables, and these 389 syllables were used as a basis for the creation of the PB word lists in the subsequent phase.
Phase 3: Establishing perceptual equivalence of word lists
Steepness of slope at 50% of psychometric curves fitted for male and female recordings.

The selected recordings were grouped according to the 16 PB lists created in Phase 2. Each participant’s WRS for each list was calculated for a range of intensity levels, from 5 dBHL to 50 dBHL in 5-dB steps. At each intensity level, repeated measures ANOVA (RMANOVA) was conducted to find out if there were significant differences in mean scores across lists. Whenever the RMANOVA determined that there were significant differences in mean scores across lists (p < 0.05), post hoc analysis with a Bonferroni adjustment was done to reveal which pairs of lists had statistically different mean scores (Figure 1(a)). Figure 1(b) summarises the number of times each list appeared in Figure 1(a). Lists that appeared frequently, such as Lists 6, 8 and 13, were lists that had significantly different scores from many other lists. They were deemed to be not perceptually equivalent to the rest of the word lists and were removed. (a) List pairs with statistically significant mean difference in scores at various intensity levels. For instance, at 15 dBHL, participants’ scores on list 1 and list 12 were significantly different. (b) Participants’ scores for list 8 differed significantly from their scores on other lists in 15 instances.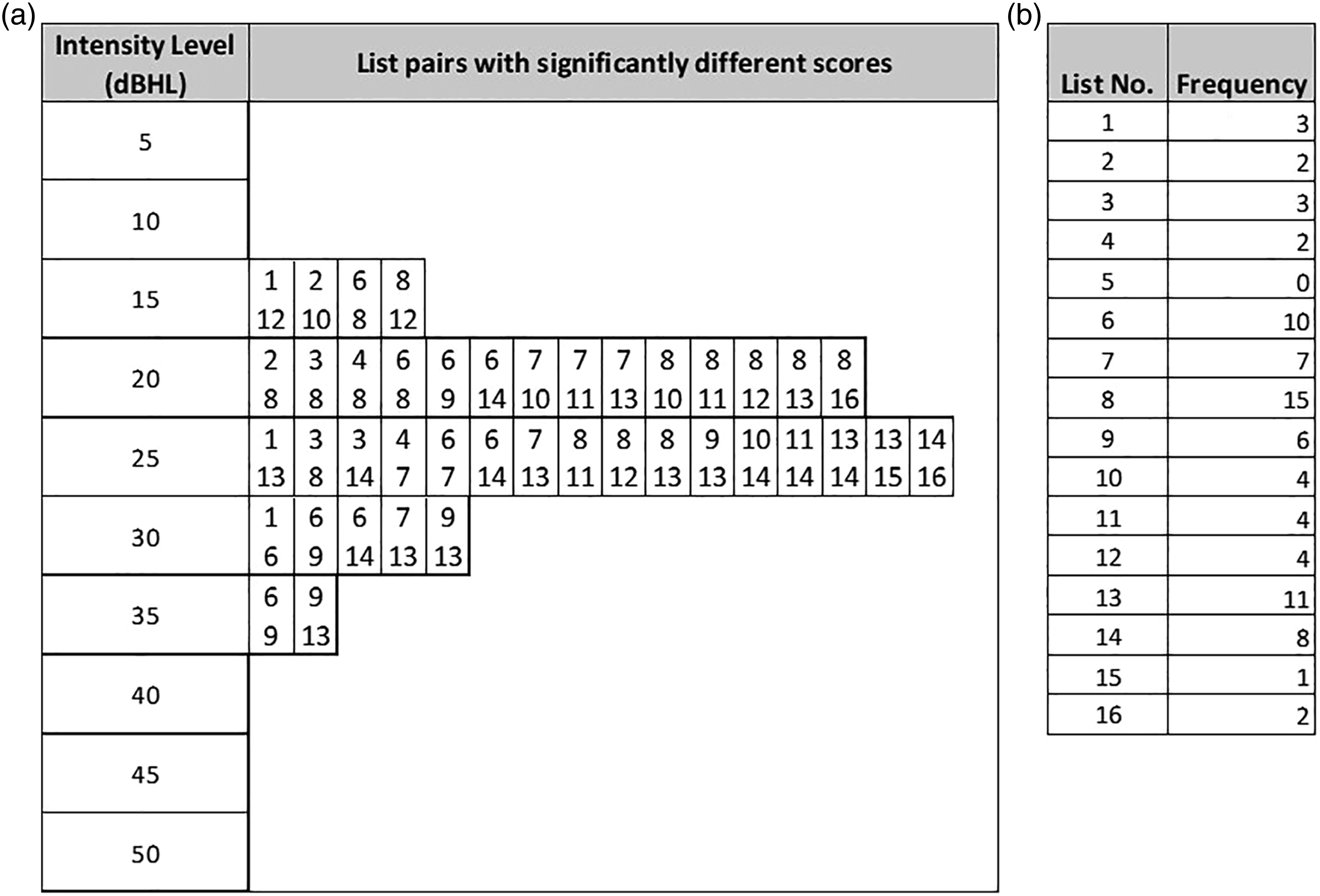
Figure 2(a) and (b) show results of the same process after removing Lists 6, 8 and 13. Since the aim of the study was to produce lists that are perceptually equivalent, the process was repeated and Lists 7, 10 and 14 were removed. The remaining lists that had significantly different scores from others are shown in Figure 3. (a) List pairs with statistically significant mean difference in scores at various intensity levels, after lists 6, 8 and 13 were removed from the analysis. (b) Lists 7, 10 and 14 had relatively high number of instances whereby participants’ scores on them differed significantly from their scores on other lists. Remaining list pairs with statistically significant mean difference in scores at various intensity levels, after further removal of lists 7, 10 and 14.
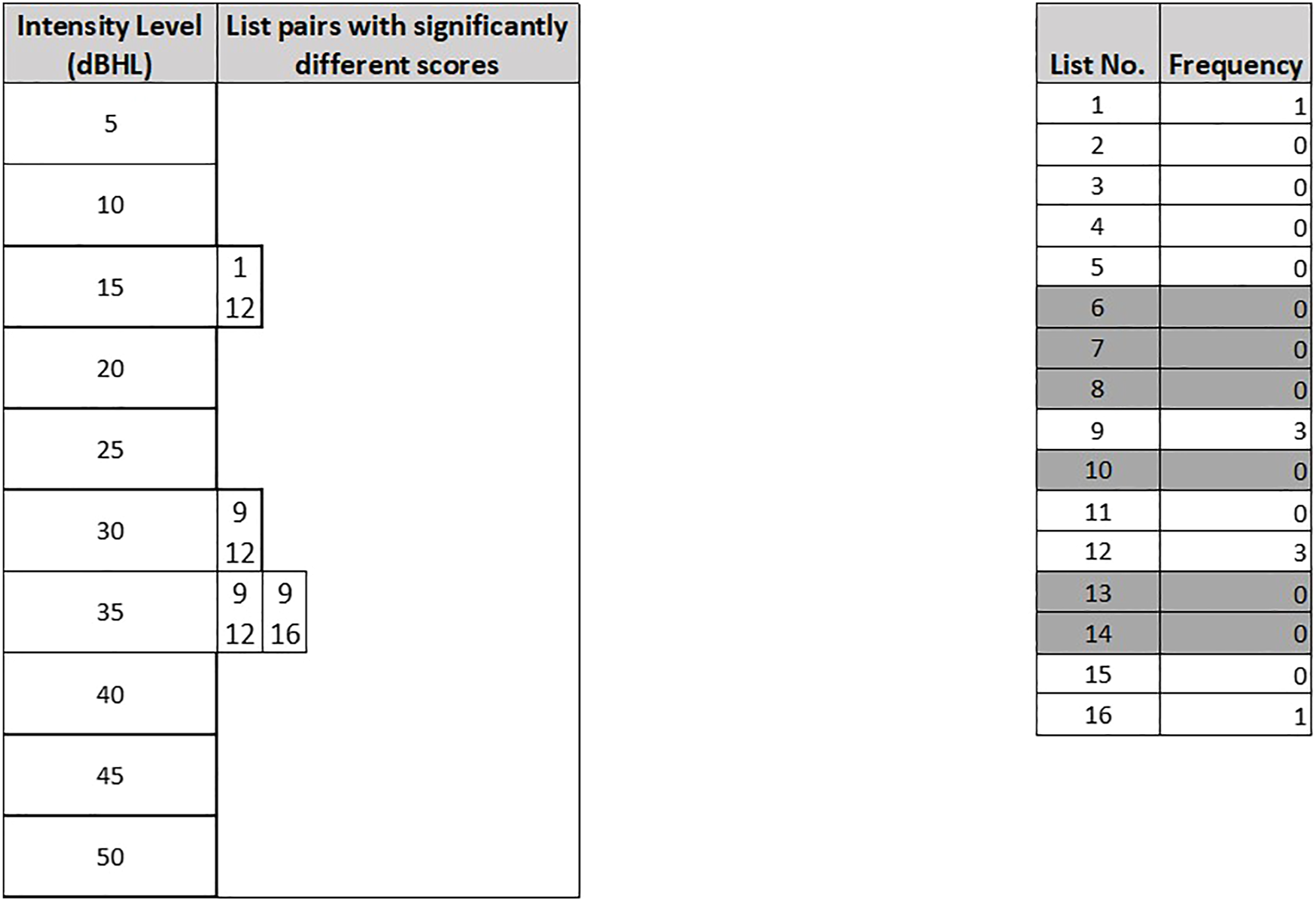
Figure 3 shows that Lists 9 and 12 were the remaining lists that had significantly different scores from the other lists. After removing Lists 9 and 12, the post hoc analysis revealed no more pairs of lists with Bonferroni-adjusted p-value of less than 0.05. The remaining eight lists, which have been analysed to be perceptually equivalent from 5dBHL to 50dBHL at 5-dB intervals, are Lists 1, 2, 3, 4, 5, 11, 15 and 16.
Discussion
Word selection process
The development of speech audiometry test materials typically begins with selection of test items from an existing corpus of the language of interest.14,17,27 Existing corpora enable speech audiometry test developers to easily select words or sentences that are common and frequently seen in texts. Although there is The Frequency Dictionary of Daily Chinese Words Encountered by Singapore Students 16 for Singapore Mandarin, this study began by amassing a database of subtitles from local television programmes. This was due to the fact that The Frequency Dictionary of Daily Chinese Words Encountered by Singapore Students was developed by analysing a compilation of textual sources. Words found in textual sources may not be those that are used in daily conversations.
Of the resident population that identified Mandarin as the language that they speak most frequently at home, 47% of them do not possess post-secondary level qualifications. 36 As such, word recognition test materials should consist of simple, everyday words that even the illiterate but conversant speakers of Singapore Mandarin would be able to recognise. This warrants a source that consists of common, spoken materials rather than textual collections. In view of this, the authors in this study chose to reference Brysbaert and New 26 ’s study, which found film subtitles to be good estimates of word frequencies.
It is worth highlighting though, subtitles from local television programmes were used in the current study instead of film subtitles as used in the study by Brysbaert and New. 26 As this modified method has yet to be validated to yield high frequency characters that are familiar to the population, the additional step of recruiting Singapore Mandarin speakers to rate the characters for familiarity had been included in this study. The results obtained suggest that a large majority (98%) of the characters were indeed familiar to the local population, and that these characters could therefore be included into the word lists developed in phase 2 of this study. This also indicates that the modified method of using subtitles from television programmes could be a good starting point for studies that are looking to examine conversational languages used by other ethnic groups in Singapore (i.e. Malay and Tamil).
Length of word lists
The current study developed phonologically balanced (PB) word lists of 25 items each. As some initial consonants and finals have very low frequency of occurrence in the language, they were not represented in every single word list, but only once in every two or four word lists. This could have been avoided by having word lists that consists of more test items, such as 50-item word lists. Having more items within each word list would also decrease the standard deviation and variability in the results obtained. However, more items within each test list would increase the time required for test administration. To save on time required to administer the word recognition tests, it was reported that many audiologists in the United States regularly use half-lists of 25 words to test each ear, even though the materials were designed and validated as 50-word lists. 37 This practice is not ideal and could lead to inaccurate and invalid results, 38 but also shows how these time-pressed clinicians find it difficult to administer tests using 50-word lists.
Therefore, the current study designed word lists to contain 25 test items in order to strike a balance between clinical efficiency and results reliability. To ensure that using 25-word lists does not compromise on the validity and reliability of the results, the materials have to be designed and validated as 25-word lists from the onset. Although the test-retest reliability of these 25-item word lists will only be validated in the subsequent phases of the study (with normal-hearing and hearing-impaired participants), the test-retest reliability of a 25-word list might not be significantly different from a 50-word list. 39
Perceptual equivalence of word lists
The psychometric functions of the individual monosyllables from Phase 3 revealed that there was a wide range in the steepness of slopes across test items. In other words, the individual monosyllables were not perceptually equivalent to one another, even though the recordings had already been scaled to the same average RMS value. This variability in audibility is to be expected, and reflects the complex nature of speech sounds, where certain words tend to be more easily perceived than others due to their phoneme composition.
Of course, it is possible to scale the recordings of monosyllables further to achieve greater perceptual equivalence among individual test items. However, forcing the individual words to be perceived equally loudly would be an unnatural representation of them in everyday speech. 40 Furthermore, scaling the recordings to a particular reference point would only make them equally perceptible at a chosen intensity level, but would not alter the slope of the psychometric functions. Due to the different rates at which performance increases with intensity across the words, there will still be a lack of perceptual equivalence if the words are being presented at an intensity level that is different from the one chosen for scaling.
Therefore, this study chose to focus on ensuring homogeneity in scores across word lists, rather than across individual words. Word lists that had significantly different scores from the rest were removed from the set of materials. This process is essential to ensure that, when normal-hearing people are tested within 5 dBHL to 50 dBHL, they are likely to achieve similar WRS regardless of the list that was used to test them.
Of the initial 16 PB word lists, the study team eliminated eight of the lists that were not perceptually equivalent to one another. The number of remaining word lists in the current study is consistent with existing Mandarin speech recognition tests developed in China 10 and Taiwan, 11 both with 8 lists of 25-word test items.
Conclusion
This study has developed a set of phonologically balanced and perceptually equivalent word lists in Singapore Mandarin for word recognition testing. It has addressed the limitations of the SC-10, firstly by reducing the contextual cues that are present in disyllabic Mandarin test items, and secondly by incorporating phonological balance into the word lists while maintaining clinical efficiency. The gathering of suitable words as test items originated from a database of subtitles from local free-to-air television programmes. Words that were high in frequency of occurrence were rated as familiar by native Singapore Mandarin speakers, and subsequently composed into 16 phonologically balanced word lists of 25 monosyllables each. Psychometric functions of the words were obtained with normal-hearing participants and lists that were not perceptually equivalent to the rest were removed. Further work is required to validate the remaining eight perceptually equivalent word lists with the local Mandarin-speaking population. Test-retest reliability and normative data need to be established with normal-hearing and hearing-impaired Singapore Mandarin speakers before the materials can be ready for clinical use.
Supplemental Material
Supplemental Material - Development of phonologically-balanced and perceptually equivalent Singapore Mandarin word lists for word recognition test
Supplemental Material for Development of phonologically-balanced and perceptually equivalent Singapore Mandarin word lists for word recognition test by Kimberly Wanxian Soh and Jenny Hooi Yin Loo in Proceedings of Singapore Healthcare.
Footnotes
Acknowledgements
We would like to thank Mr Lim Hong Han for his assistance in data collection in Phase 1 of this research.
Author contributions
KWS researched literature and conceived the study. JHYL was involved in protocol development and gaining ethical approval. KWS carried out patient recruitment, data analysis, and wrote the first draft of the manuscript. Both authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was made possible by a gift donation from Sivantos Pte Ltd.
Ethical approval
Ethical approval for this study was obtained from National University of Singapore Institutional Review Board (S-20-012) and (NUS-IRB-2021-24).
Informed consent
Written informed consent was obtained from all subjects before the study.
Data availability
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.