
Abstract
Recent work incorporating autonomy into an evaluative conditioning procedure provided evidence of a sampling decision effect in which high-autonomy participants positively shifted their evaluations of frequently sampled conditioned stimuli (CSs), regardless of whether they were consistently paired with positive or negative unconditioned stimuli (USs). The current work modified this paradigm by also measuring participants’ evaluations of the sampled USs. Two experiments replicate the sampling decision effect for neutral CSs in a new variant of the paradigm while ruling out the alternative possibility that the effect is driven by idiosyncratic variance in participants’ reactions to the USs. In addition, Experiment 2 suggests that the sampling decision effect does not extend to the paired, valent stimuli. Together, these results further suggest that it is the act of sampling a stimulus more frequently that predicts a positive evaluative shift toward it.
In everyday life, people have a good deal of autonomy over the information they learn about: we often have choice over the foods we eat, the people we interact with, the shows we watch, and so on. Not surprisingly, the outcomes of these decisions (e.g., whether the food was good or bad) can then be used to update one’s attitudes and influence future sampling decisions (Denrell, 2005). Interestingly though, the act of choosing or sampling an object can itself carry evaluative weight, for instance, by leading people to infer they like an object more if they chose it (Bem, 1972; Hütter & Genschow, 2020) or motivating them to like it more to justify the choice (Festinger, 1957).
Despite this, most evaluative learning research strips participants of the autonomy to make such decisions, requiring them to passively view the stimuli they learn about. In addition, some paradigms distract participants during learning, further preventing them from exerting even a minimal amount of autonomy in the task (Jones et al., 2009; Olson & Fazio, 2001; Priluck & Till, 2004; Sweldens et al., 2010). Although such paradigms provide high experimental control, understanding evaluative learning in everyday life requires supplementing them with features of real-world learning such as autonomy.
Hütter and colleagues (2022) sought to bridge this gap by incorporating autonomy into an evaluative conditioning (EC) paradigm. Participants viewed an array of conditioned stimuli (CSs), and on each trial, chose one to sample. The sampled CS was then paired with a positive or negative unconditioned stimulus (US). This process was repeated, providing participants control over how frequently they viewed pairings for each CS.
Such a procedure differs from typical EC paradigms in which pairings are determined by the experimenter and provides participants genuine autonomy over the stimuli they learn about in the task. In addition, whereas typical EC paradigms present a balanced number of positive and negative pairings, by allowing participants to choose the pairings they viewed, the paradigm developed by Hütter et al. (2022) resulted in an ecology with more positive than negative pairings.
Thus, to tease apart effects of autonomy and the stimulus ecology, the paradigm also included a low-autonomy condition in which each participant passively viewed the CS-US pairings that mirrored those sampled by a yoked high-autonomy participant. Hütter and colleagues (2022) found that US valence shifted CS evaluations in both the high- and low-autonomy conditions, suggesting the passivity typical of EC paradigms is not a pre-requisite for the effect.
The paradigm also provided evidence of a sampling decision effect in the high-autonomy condition: increased sampling frequency was related to a positive evaluative shift, regardless of paired US valence. Among low-autonomy participants, the effect of US valence tended to become stronger with increased frequency of presentation. Thus, they found that sampling decisions have the power to change the evaluation of initially neutral stimuli. However, this research program ignored participants’ evaluations of stimuli that already carry valence (e.g., the USs).
As USs, Hütter et al. (2022) used International Affective Picture System (IAPS) images that were normed to be comparable in terms of extremity, but there is also idiosyncratic variability around people’s reactions to the images (Lang et al., 2008). This idiosyncratic variability in evaluations of the USs allows for an alternative mechanism underlying the sampling decision effect observed for CSs. Rather than the sampling decision itself conferring valence, it is possible that high-autonomy participants sampled more frequently those CSs that were paired with USs that they personally evaluated more positively. As such, more (vs. less) frequently sampled CSs would be paired with USs that were more positive/less negative for the high-autonomy participant who sampled them, but not for their yoked low-autonomy counterparts. Thus, testing this alternative explanation is of critical importance for understanding the mechanism underlying the sampling decision effect observed for CSs.
In addition, the fact that individuals exhibit variability in their reactions to IAPS images suggests it is possible that other factors modulate the strength of affective reactions to a given image. Accordingly, might the sampling decision effect observed for CSs also occur for the USs that high-autonomy participants caused to appear? Testing such a possibility is useful in understanding the scope and limits of the sampling decision effect. If such an effect extends to the paired USs, this would suggest that merely causing an outcome to occur (e.g., a US appearing) can positively shift people’s reactions to that outcome (i.e., evaluations of the US). In contrast, if the effect does not extend to the paired USs, this may suggest the effect holds for initially neutral or weak attitude objects, but not objects for which one’s attitude is polarized or strong. Indeed, much of the previous research on effects of choice on evaluation has focused on novel and/or relatively neutral attitude objects (e.g., Bem, 1972; Hütter et al., 2022; Hütter & Genschow, 2020), which is theorized to serve as an important condition for self-perception mechanisms in attitude change (Fazio et al., 1977). In this way, testing if the sampling decision effect extends to the USs provides insight into whether it is similarly bound to initially neutral stimuli, or if instead, it constitutes an additional mechanism that might induce attitude change for valent stimuli as well (e.g., Albarracin & Shavitt, 2018).
Thus, the current work has two major theoretical aims: first, to test whether the sampling decision effect for CSs can be explained via idiosyncratic variance in participants’ reactions to the paired USs, and second, to test if the sampling decision effect also extends to the paired affective stimuli (i.e., the USs). Two experiments modified the paradigm employed in Hütter et al. (2022) by including measures of participants’ US evaluations. To increase the power of the study design for the present purpose, we also adjusted the CS-US pairing schedule so that each CS was assigned one unique US. If the sampling decision effect is driven by idiosyncratic variance in reactions to the USs, then pairing each CS with a single US (rather than a novel US on each sample) should more reliably allow for this alternative mechanism to account for the effect. Likewise, if USs also show an effect of sampling decisions on evaluation, a paradigm that allows participants to reliably cause specific USs to appear should be more likely to produce such an effect. We tested our predictions regarding the sampling decision effect on CSs and USs in two experiments.
Transparency and Openness
The experiments were pre-registered (Experiment 1: https://aspredicted.org/ue9dp.pdf; Experiment 2: https://aspredicted.org/wy6us.pdf). For both experiments, we approximated the required sample size by basing the power analysis on a simpler, mixed-design analysis of variance (ANOVA) (vs. the multilevel models used to analyze the data in the current experiments) that reconceptualized number of samples as a binary (high vs. low) variable. 1 Using this approach, 260 participants would provide high power (1 –β = .95) to detect a small effect of size f = 0.10 (Faul et al., 2007). In both experiments, we aimed to recruit slightly above this amount to cope with potential data loss due to technical error. In addition, the full materials, data, and analysis scripts for both experiments are publicly available at: osf.io/j6xr9.
Experiment 1
Experiment 1 provided an initial test of the relation between the sampling decision effect and people’s idiosyncratic evaluations of valent stimuli by modifying the EC paradigm from Hütter et al. (2022). In particular, Experiment 1 included a measure of participants’ evaluations of the USs and used a pairing schedule in which each CS was consistently paired with the same US. We first tested whether the sampling decision effect for CSs replicated in this modified version of the paradigm, and whether any such effect could be better explained by potential effects on evaluations of the USs. We then turned to evaluations of the USs themselves, to see if high-autonomy participants’ sampling behavior predicted more positive post-evaluations of the USs that were part of the CS-US pairs they sampled more frequently, regardless of normative valence.
Method
Participants
We recruited 280 participants on Prolific (www.prolific.co). We only accepted native English-speaking participants between the ages of 18 and 60, with an approval rate above 90%. The experiment lasted 15 min and participants were paid 1.25£. As the low-autonomy condition could only be run once data for some high-autonomy participants was available, we ran conditions in alternating blocks of roughly 20 participants. No participant data was excluded in Experiment 1, resulting in 140 participant pairs (127 women, 152 men, one preferred to self-identify, Mage = 41.78, SDage = 12.51).
Materials and Procedure
The experiment closely followed the paradigm in Hütter et al. (2022). Participants first answered, “What is your impression of this face?” on a continuous 200-point sliding scale ranging from negative to positive to provide evaluative ratings of 50 faces. The 12 most neutral faces (i.e., symmetrically surrounding the median rating) for each participant were selected for the conditioning phase.
Participants in the high-autonomy condition then viewed an overview of the 12 faces (CSs) randomly arranged in a four by three grid. On each trial, participants chose who they wanted to interact with by clicking on a face. The face then appeared next to its paired US for 2,500 ms. Next, participants returned to the overview and selected the next face. This process repeated across 48 trials (reduced from the original paradigm’s 60 trials, given the simplified nature of the pairing schedule). For USs, we used the same pool of positive and negative images from the IAPS as in Hütter et al. (2022; Lang et al., 2008). For each participant, 12 USs were randomly selected (six positive and six negative) for the conditioning phase, such that each CS was paired with a single US. Sampling participants were told they were completely free to choose whom to interact with on each trial.
After the conditioning phase, participants were re-shown each of the 12 CSs and asked to provide post-ratings using the same question and scale as used for the pre-ratings. Analyses of evaluative learning for CSs are based on the evaluative shift from pre- to post-rating to control for pre-existing attitudes. In addition, participants were also shown each of the 12 USs and asked to rate “What is your impression of this image?” using the same scale as used for the CS ratings. As in the original experiment, participants also completed a few exploratory measures including certainty ratings of their post-evaluations for CSs and USs, a base rate estimate of the positive versus negative pairings they viewed, an estimate of the number of times they viewed each of the CSs, and their memory for the paired valence of each CS. Finally, participants completed a brief demographic questionnaire before finishing the experiment.
For participants in the low-autonomy condition, the experiment followed a nearly identical procedure, but rather than choosing the CSs, participants were told the computer would decide with whom they interacted on each trial. The sequence of interactions was determined by yoking each participant to the sampling decisions of another participant from the high-autonomy condition. Participants in the low-autonomy condition also saw the four-by-three grid alternating with the conditioning trials. However, the screens switched automatically after 2,500 ms each.
Results
Unless stated otherwise, all analyses relied on multilevel modeling to assess relationships within participants on the level of trials. All multilevel models contain random intercepts for participants and CS identities (Judd et al., 2012), as well as fixed effects for the predictors. 2 Effect sizes are reported in the form of standardized regression coefficients (β).
CS Sampling Decision Effect
We tested whether the sampling decision effect for CSs replicated in the current version of the paradigm and, critically, whether such an effect could be better explained by participants’ idiosyncratic ratings of the USs. We predicted evaluative shift for the CSs as a function of the interactions between autonomy (0.5 = high, −0.5 = low), number of samples (centered across participants and CSs), and normative US valence (0.5 = positive, −0.5 = negative). We also included in the model US post-ratings (person-mean-centered), as well as its interactions with autonomy and normative US valence. Thus, the full model contained two sets of predictor interactions, one including number of samples as a predictor and the other including US post-ratings. If the effect of number of samples on CS evaluative shift observed in previous work was merely a by-product of the effect of US post-ratings, we would not expect number of samples and its interaction with autonomy condition to be a significant predictor in this model.
There was a significant main effect of US post-ratings on evaluative shift for CSs, b = 0.23, SE = 0.02, t(2912.27) = 13.00, p < .001, β = 0.36, but its interactions with the other predictors in the model were not significant, |t|’s < 1.76, p’s > .078. Instead, there was a significant interaction between autonomy and number of samples, b = 2.58, SE = 0.48, t(3120.30) = 5.36, p < .001, β = 0.24, though it was qualified by a three-way interaction with normative US valence, b = −3.10, SE = 0.08, t(3080.84) = −3.13, p = .002, β = −0.28. 3
As can be viewed in Figure 1, in the high-autonomy condition, more frequent sampling was related to a positive evaluative shift, b = 2.20, SE = 0.34, t(3105.15) = 6.40, p < .001, β = 0.21, regardless of the normative US valence, b = −0.36, SE = 0.71, t(3141.79) = −0.51, p = .611, β = −0.03. In the low-autonomy condition, there was a significant interaction between number of samples and normative US valence, b = 2.74, SE = 0.69, t(3150.17) = 3.95, p < .001, β = 0.25, such that more samples predicted a positive evaluative shift for positively-paired CSs, b = 0.99, SE = 0.24, t(3002.28) = 4.10, p < .001, β = 0.09, and a negative evaluative shift for negatively paired CSs, b = −1.75, SE = 0.64, t(3150.85) = 2.74, p = .006, β = −0.16.
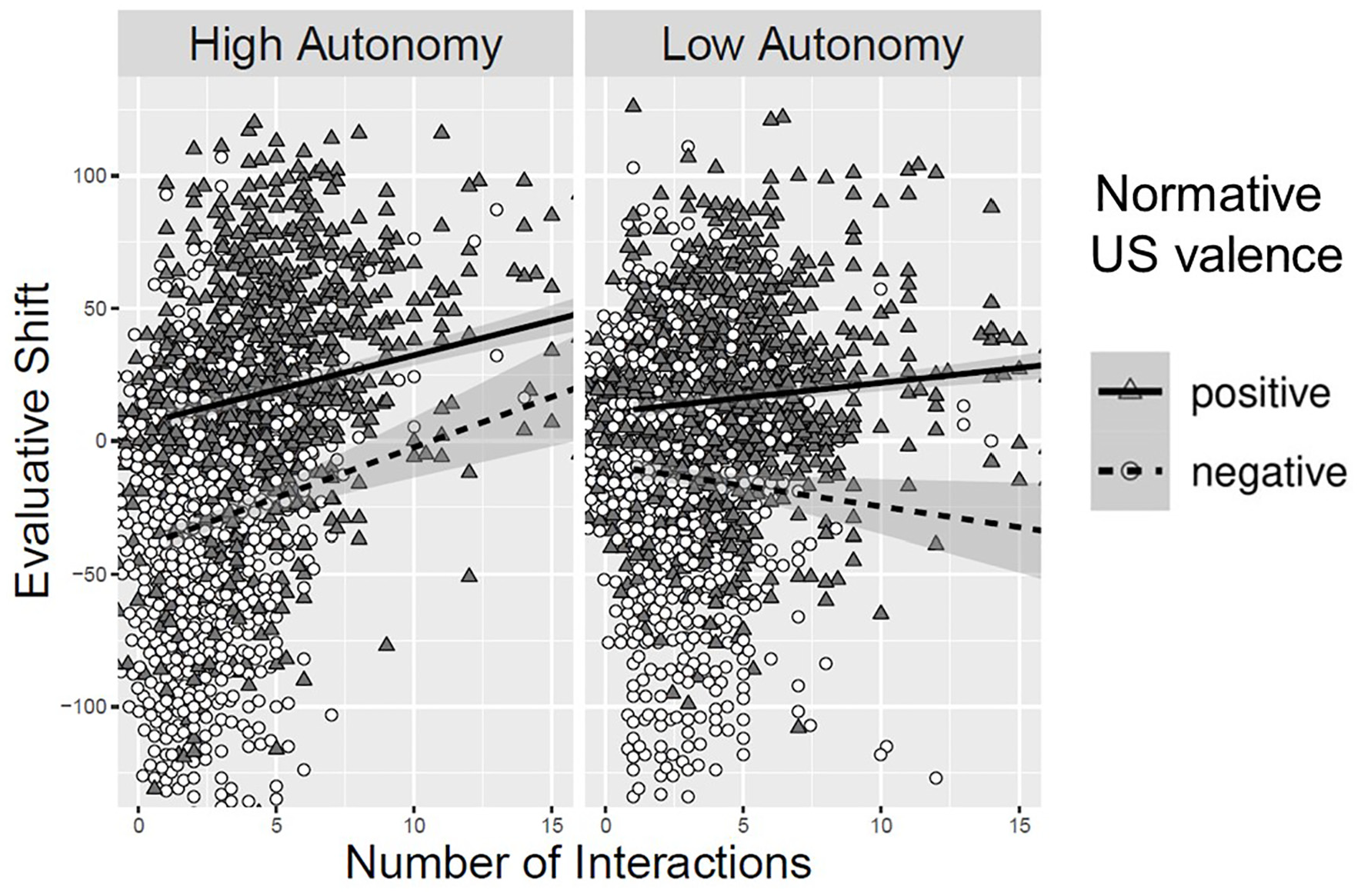
Evaluative Shift of CSs as a Function of Normative US Valence, Autonomy, and Number of Samples, While Controlling for Idiosyncratic US Evaluations in Experiment 1
US Sampling Decision Effect
Next, we tested for a possible sampling decision effect on USs by predicting US post-ratings from normative valence (0.5 = positive, −0.5 = negative), autonomy (0.5 = high, −0.5 = low), number of samples (centered across participants and CSs), and their interactions.
There was a significant interaction between autonomy condition and number of samples, b = 2.92, SE = 0.49, t(3046.06) = 5.99, p < .001, β = 0.04, mirroring the sampling decision effect observed for CSs, though this effect was also further moderated by normative US valence, b = −3.68, SE = 1.01, t(3159.83) = 3.64, p < .001, β = −0.04.
In the high-autonomy condition, more samples predicted higher US post-evaluations for both normatively positive, b = 1.92, SE = 0.25, t(3058.74) = 7.68, p < .001, β = 0.11, and normatively negative USs, b = 4.16, SE = 0.66, t(3168.76) = 6.33, p < .002, β = 0.24. Furthermore, a significant interaction between normative US valence and number of samples, b = −2.24, SE = 0.71, t(3153.66) = 3.15, p = .002, β = −0.13, suggests this effect was stronger for normatively negative USs. In the low-autonomy condition, there was a significant interaction between normative US valence and number of samples, b = 1.43, SE = 0.71, t(3159.73) = 2.01, p = .045, β = 0.08, such that more samples predicted higher US post-evaluations for normatively positive USs, b = 0.96, SE = 0.25, t(3050.51) = 3.83, p < .001, β = 0.06, but not for normatively negative USs, b = −0.48, SE = 0.66, t(3176.10) = 0.72, p = .469, β = −0.03.
Discussion
Experiment 1 replicated the sampling decision effect for CSs: larger samples were related to a positive evaluative shift regardless of paired valence among high-autonomy participants. In contrast, larger samples predicted a stronger impact of paired valence among low-autonomy participants. Critically, these effects persisted while incorporating idiosyncratic US ratings into the model, suggesting the sampling decision effect is not explained by differences in US ratings between high-autonomy participants and their yoked counterparts.
In addition, the evaluative post-ratings of the USs mirrored the typical sampling decision effect for CSs: a higher number of samples predicted higher US ratings for both normatively positive and normatively negative USs among high-autonomy participants, but not low-autonomy participants. However, because Experiment 1 only incorporated US post-ratings, the results allow for the alternative explanation that high-autonomy participants simply sampled more frequently those USs that they already preferred. Experiment 2 sought to test these two hypotheses against each other by including pre and post US evaluations to assess evaluative shift of the USs.
Experiment 2
Experiment 2 replicated the procedure of Experiment 1 while also including pre-ratings of the USs to assess whether the relations documented by Experiment 1 indicate a sampling decision effect for USs. We first tested whether the sampling decision effect for CSs replicated in this modified version of the paradigm, and whether any such effect could be better explained by potential effects on evaluations of the USs. Then, we tested whether the relation observed in Experiment 1 between sampling frequency and US post-ratings replicated in the current experiment. Finally, we assessed whether this effect can be attributed to a sampling decision effect on the USs by testing if the effect held when analyzing evaluative shift for the USs.
Method
Participants
We recruited 273 participants on Prolific (www.prolific.co) using the same recruitment strategy and payment as in Experiment 1. Data from seven participants were excluded due to a technical error in the yoking procedure, resulting in 133 valid participant pairs (97 women, 168 men, one preferred to self-identify, Mage = 39.43, SDage = 11.47).
Materials and Procedure
The experiment directly replicated Experiment 1 with some minor modifications. Most importantly, after providing pre-ratings for the CSs, participants also provided pre-ratings for each of the 12 USs using the same scale used for the post-ratings. We calculated evaluative shift in USs by subtracting pre-ratings from the post-ratings. For exploratory purposes, participants then also provided unipolar ratings for how positive and how negative their impression was of each image.
Results
CS Sampling Decision Effect
We tested for a sampling decision effect on CSs using the same analytic approach as in Experiment 1, but this time including US pre-ratings and its interactions with the other predictors (rather than US post-ratings as in Experiment 1). Replicating Experiment 1, there was a significant main effect of US pre-ratings on evaluative shift for CSs, b = 0.21, SE = 0.02, t(2965.36) = 10.90, p < .001, β = 0.30, but its interactions with the other predictors were not significant, |t|’s < 1.14, p’s > .252. Further replicating Experiment 1, there was a significant interaction between autonomy and number of samples, b = 2.38, SE = 0.44, t(2860.08) = 5.37, p < .001, β = 0.24, though it was again moderated by normative US valence, b = −3.76, SE = 0.91, t(2898.26) = 4.14, p < .001, β = −0.38.
As can be viewed in Figure 2, in the high-autonomy condition, more frequent sampling predicted a positive evaluative shift, b = 1.97, SE = 0.31, t(2859.84) = 6.28, p < .001, β = 0.20. This effect was technically moderated by normative US valence, b = −1.26, SE = 0.64, t(2899.97) = −1.96, p = .050, β = −0.12, though number of samples predicted a positive shift for both positively paired CSs, b = 1.34, SE = 0.25, t(2839.00) = 5.38, p < .001, β = 0.14, and negatively paired CSs, b = 2.61, SE = 0.59, t(2896.27) = 4.45, p < .001, β = 0.26. In the low-autonomy condition, there was a significant interaction between number of samples and normative US valence, b = 2.49, SE = 0.64, t(2900.19) = 3.90, p < .001, β = 0.26, such that more samples predicted a positive evaluative shift for positively paired CSs, b = 0.84, SE = 0.25, t(2833.10) = 3.43, p = .001, β = 0.09, and a negative evaluative shift for negatively paired CSs, b = −1.65, SE = 0.58, t(2895.35) = 2.84, p = .005, β = −0.17.
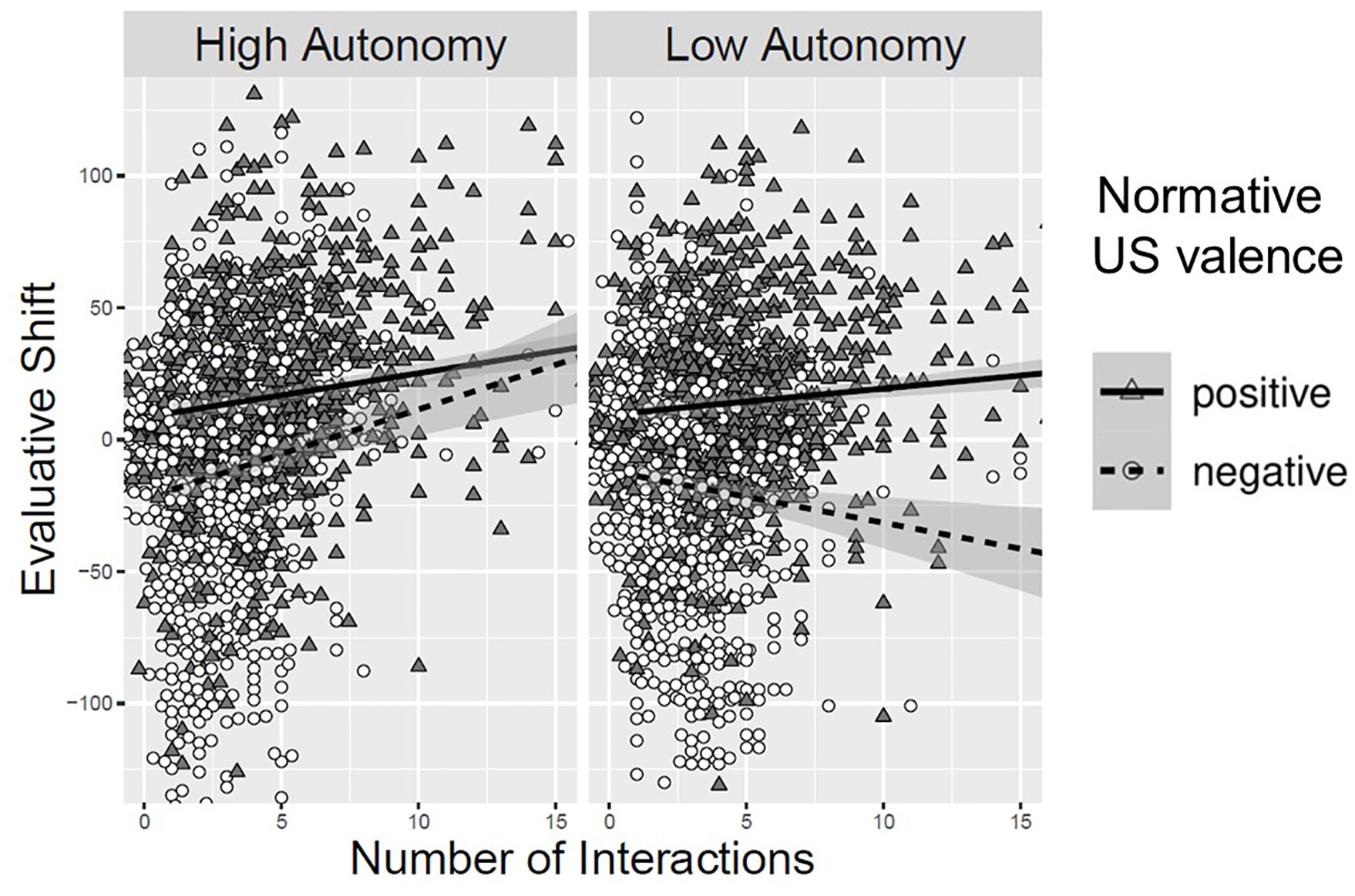
Evaluative Shift of CSs as a Function of Normative US Valence, Autonomy, and Number of Samples, While Controlling for Idiosyncratic US Evaluations in Experiment 2
US Sampling Decision Effect
Predicting US Post-Ratings
We first sought to test whether the effect on US post-ratings observed in Experiment 1 replicated by predicting US post-ratings from normative valence (0.5 = positive, −0.5 = negative), autonomy (0.5 = high, −0.5 = low), number of samples (centered across participants and CSs), and their interactions. There was a significant interaction between autonomy condition and number of samples, b = 1.50, SE = 0.44, t(2910.40) = 3.37, p < .001, β = 0.02, though this effect was further moderated by normative US valence, b = −1.88, SE = 0.90, t(2906.60) = 2.08, p = .038, β = −0.02.
In the high-autonomy condition, more samples predicted higher US post-ratings, b = 1.91, SE = 0.31, t(2914.37) = 6.05, p < .001, β = 0.12, regardless of normative US valence, b = −0.94, SE = 0.64, t(2906.58) = 1.47, p = .142, β = −0.06. In the low-autonomy condition, number of samples did not significantly predict post-ratings, b = 0.41, SE = 0.31, t(2913.61) = 1.30, p = .195, β = 0.03, nor did it significantly interact with normative US valence to predict US post-ratings, b = 0.94, SE = 0.64, t(2907.01) = 1.47, p = .143, β = 0.06.
Thus, as in Experiment 1, an analysis of the US post-ratings shows evidence of a possible sampling decision effect for USs. However, it is possible that this effect is not driven by sampling decisions, but rather could also arise if high-autonomy participants sampled those CS-US pairs that contain USs that they already rated more positively. Thus, we next conducted an analysis of evaluative shift to test these competing possible explanations for the observed effect.
Predicting US Evaluative Shift
We tested for a sampling decision effect on USs using the same analytic approach as for the US post-ratings, but this time predicting evaluative shift for the USs. There was a main effect of normative US valence on evaluative shift, b = 14.86, SE = 1.16, t(2768.32) = 12.75, p < .001, β = 0.49. As can also be viewed in Figure 3, no other effects were significant, |t|’s < 1.48, p’s > .138, providing no evidence for a sampling decision effect for USs as underlying the effect observed for US post-ratings in the two experiments.
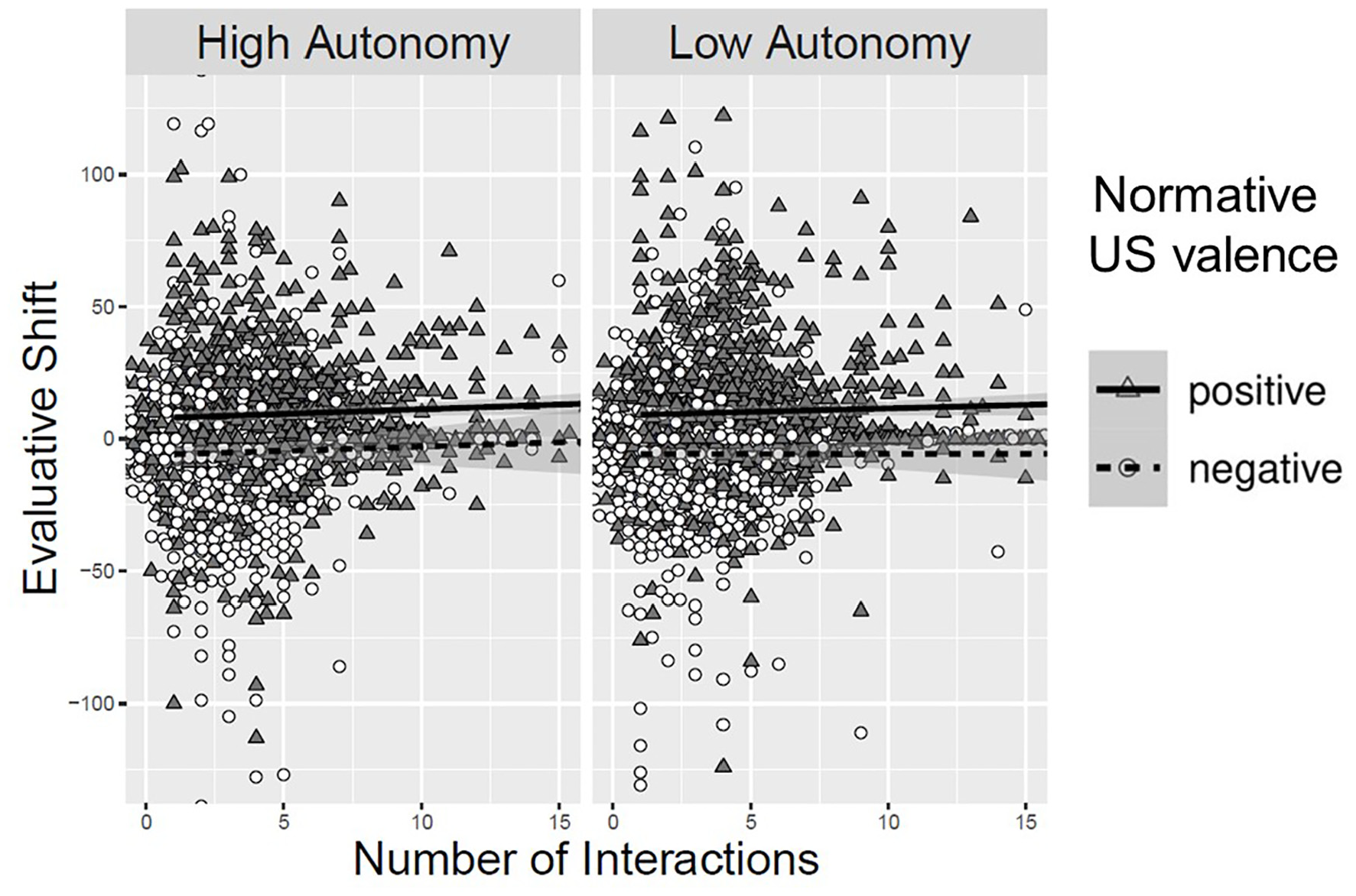
Evaluative Shift of USs as a Function of Normative US Valence, Autonomy, and Number of Samples in Experiment 2
Discussion
Experiment 2 replicated the sampling decision effect for CSs and again found that it was not better explained by participants’ idiosyncratic evaluations of the USs, providing further evidence that it is the act of sampling a (initially neutral) stimulus more frequently that predicts a positive evaluative shift toward it. In addition, Experiment 2 replicated the relation between US post-ratings and sampling frequency for high-autonomy participants. However, when applying a more sensitive measure of evaluative shift, this relation disappears, suggesting it is not driven by a sampling decision effect on USs, but instead is better attributed to high-autonomy participants sampling those CSs that were paired with USs that they already preferred. Indeed, consistent with this interpretation, analyses of high-autonomy participants’ sampling behavior (presented in full in the supplement) find that, as the task progressed, they became increasingly more likely to sample those USs that they already preferred based on US pre-ratings, b = 0.14, SE = 0.03, t(6211.66) = 4.25, p < .001.
General Discussion
The current experiments provide additional insight to the role of autonomy in evaluative learning. Recent work demonstrated a sampling decision effect, whereby high-autonomy participants positively shifted evaluations toward CSs they sampled frequently regardless of paired valence (Hütter et al., 2022). Beyond replicating this effect in a different variant of the EC paradigm that tests whether the effect is attributable to idiosyncratic variance in participants’ evaluations of the USs, the present experiments assessed whether sampling decisions have the power to influence evaluations of the paired valent stimuli.
Sampling Decision Effect for Initially Neutral Stimuli
The present experiments replicate and extend the sampling decision effect on neutral stimuli that was demonstrated by Hütter et al. (2022). Existing research implemented a paradigm in which CSs were paired with variable USs. That is, each time a CS was sampled, it was shown with a new US. Previous research suggests that the variability of the USs influences the processes via which the CSs acquire valence (e.g., Sweldens et al., 2010; see also Reichmann et al., 2023). Different USs lead to the acquisition of more abstract representations that do not retain the details of the individual USs. By contrast, if a CS is repeatedly paired with the same US, the representation will contain the details of the US. These substantive differences raise the question as to whether both procedural variants allow for a concurrent sampling decision effect. The present experiments implemented a fixed CS-US schedule and demonstrated that the sampling decision effect indeed generalizes to this setting, thereby attesting to the generality of the effect.
However, investigating direct effects of sampling decisions on evaluations fundamentally amounts to a correlation between sample size and evaluative shift, making it critical to consider alternative, inverse causal explanations (e.g., the effect may stem from autonomous participants sampling those stimuli they already prefer more). As in the original experiments (Hütter et al., 2022), we took methodological and statistical steps to hedge against this alternative account. Methodologically, we selected the 12 most neutral stimuli for each participant and focused on the change in evaluation (rather than absolute evaluation) as the dependent measure. Furthermore, to more directly test the influence of differences in pre-existing CS ratings, we also conducted additional analyses (presented in the supplement) that predicted CS post-ratings while including CS pre-ratings as an additional independent variable in the model. Consistent with the previous work (Hütter et al., 2022), we find that this alternative analytic approach reproduces the findings reported in the main text. Thus, the current evidence is consistent with previous work in suggesting this alternative mechanism is unlikely to account for the sampling decision effect.
Furthermore, the current work moves beyond previous findings by ruling out an additional alternative mechanism by which the effect might occur: as a function of participants’ idiosyncratic evaluations of the USs. Indeed, analyses of high-autonomy participants’ sampling behavior and the relation between US post-ratings and sampling frequency observed in both experiments suggest such an alternative mechanism is plausible. However, it is unlikely that the sampling decision effect in the CSs can be explained by changes in the interpretation of the USs caused by sampling, given that we did not observe a sampling decision effect on the USs themselves. Furthermore, the present results also refute the possible explanation that the sampling decision effect is merely a function of participants sampling those CSs that were paired with USs that were idiosyncratically more positive (less negative) for the given participant. While idiosyncratic US ratings did shape sampling behavior in the current experiments, this phenomenon did not account for the sampling decision effect on CSs. Specifically, both experiments found the sampling decision effect for CSs persisted while simultaneously including idiosyncratic US ratings as a predictor. If the sampling decision effect were merely a by-product of pre-existing US ratings determining both sampling frequency and evaluative rating of the paired CS, one would instead expect the association between sampling frequency and evaluative ratings to disappear when including US ratings. Thus, these results further suggest it is the act of sampling a stimulus more frequently that predicts a positive evaluative shift toward it.
Sampling Decision Effect for the Paired Valent Stimuli?
Experiment 1 seemed to indicate a sampling decision effect for USs, but it relied on post-ratings only. Experiment 2 instead measured pre- and post-ratings, allowing it to analyze evaluative shift for the USs. While Experiment 2 replicated the effect on post-ratings observed in Experiment 1, the more sensitive measure of evaluative shift showed these results could not be attributed to a sampling decision effect on the USs.
This lack of effect is particularly interesting when considering high-autonomy participants’ sampling behavior. In both experiments, the USs did appear to shape high-autonomy participants’ sampling behavior such that participants developed a preference to sample CSs paired with positive (vs. negative) USs as the task progressed. Furthermore, in Experiment 2, high-autonomy participants were also more likely to sample CSs paired with USs that they idiosyncratically pre-rated more (vs. less) positively for both normatively positive and normatively negative USs. That is, both the normative valence of the USs and participants’ idiosyncratic pre-ratings of them influenced high-autonomy participants’ sampling decisions in the task (see the supplement for these analyses). Nevertheless, this did not lead to a positive evaluative shift for these more frequently presented USs. Thus, this result sheds light on the nature of the sampling decision effect by providing evidence consistent with other recent work, highlighting the importance of people’s interpretation of their sampling behavior in producing the effect (Niese & Hütter, 2023).
Limitations and Future Directions
By giving participants autonomy over the number of times they sampled a CS-US pairing, the paradigm used in the current experiments cannot completely rule out alternative explanations for the effect of sampling on evaluation. Nonetheless, as noted above, we took various steps to hedge against these alternatives (see also Hütter et al., 2022), and the current experiments rule out the possibility that the effect is merely a function of participants’ idiosyncratic reactions to the paired USs.
In addition, the sampling decision effect did not extend to the paired USs in the current experiments, which could be because the effect does not extend to clearly valent stimuli, or because it only applies to those stimuli which were directly sampled (i.e., the CSs). Future work should test these competing possibilities to provide further insight to the nature and boundaries of sampling decision effects.
Conclusion
The current findings bolster recent work seeking to bridge the gap between the autonomy people often experience in everyday learning and the lack of such autonomy typical in most evaluative learning paradigms (Hütter et al., 2022). The current work replicates evidence of a sampling decision effect for CSs in a new variant of the EC paradigm, thereby attesting to the generality of the effect. It also extends our understanding of the effect by considering people’s evaluations of the USs as well. Doing so provides further insight to the sampling decision effect (a) by ruling out an alternative mechanism through which it might occur and (b) by suggesting it does not extend to the paired-stimuli that already carry valence, at least not to strongly affective stimuli such as the IAPS. In sum, the act of sampling exerts an evaluative influence on the CSs that is separate from the influence of the USs.
Supplemental Material
sj-docx-1-spp-10.1177_19485506241235702 – Supplemental material for Choosing What You Like or Liking What You Chose? Sampling’s Impact on Evaluation and the Role of Idiosyncratic Reactions to Valent Stimuli
Supplemental material, sj-docx-1-spp-10.1177_19485506241235702 for Choosing What You Like or Liking What You Chose? Sampling’s Impact on Evaluation and the Role of Idiosyncratic Reactions to Valent Stimuli by Zachary Adolph Niese and Mandy Hütter in Social Psychological and Personality Science
Footnotes
Handling Editor: Tal Eyal
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by an Emmy Noether grant (HU 1978/4-1) and a Heisenberg grant (HU 1978/7-1) awarded to Mandy Hütter by the German Research Foundation.
Notes
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.