
Abstract
Background:
Artificial pancreas (AP) systems reduce the treatment burden of Type 1 Diabetes by automatically regulating blood glucose (BG) levels. While many disturbances stand in the way of fully closed-loop (automated) control, unannounced meals remain the greatest challenge. Furthermore, different types of meals can have significantly different glucose responses, further increasing the uncertainty surrounding the meal.
Methods:
Effective attenuation of a meal requires quick and accurate insulin delivery because of slow insulin action relative to meal effects on BG. The proposed Variable Hump (VH) model adapts to meals of varying compositions by inferring both meal size and shape. To appropriately address the uncertainty of meal size, the model divides meal absorption into two disjoint regions: a region with coarse meal size predictions followed by a fine-grain region where predictions are fine-tuned by adapting to the meal shape.
Results:
Using gold-standard triple tracer meal data, the proposed VH model is compared to three simpler second-order response models. The proposed VH model increased model fit capacity by 22% and prediction accuracy by 12% relative to the next best models. A 47% increase in the accuracy of uncertainty predictions was also found. In a simple control scenario, the controller governed by the proposed VH model provided insulin just as fast or faster than the controller governed by the other models in four out of the six meals. While the controllers governed by the other models all delivered at least a 25% excess of insulin at their worst, the VH model controller only delivered 9% excess at its worst.
Conclusions:
The VH Model performed best in accuracy metrics and succeeded over the other models in providing insulin quickly and accurately in a simple implementation. Use in an AP system may improve prediction accuracy and lead to better control around mealtimes.
Keywords
Introduction
Artificial pancreas (AP) systems can reduce hypoglycemia (<70 mg/dL) while increasing time in the normoglycemic range (70-180 mg/dL). 1 Single hormone AP systems consist of an insulin pump, a continuous glucose monitor (CGM), and a control algorithm implemented on an embedded device or smartphone, while bi-hormonal systems use an additional pump for glucagon.1,2 Commercially available AP systems offer hybrid closed-loop functionality, meaning only basal insulin rates are adjusted while the user is still required to bolus for meals. The proposed work is aligned with Step 5 of the JDRF Pathway to Artificial Pancreas Systems, fully closed-loop functionality with insulin only. 3 To achieve this the control algorithm must correctly detect the meal, accurately estimate its size, and administer insulin in a manner that effectively attenuates the postprandial blood glucose (BG) rise.
AP systems can use model predictive control (MPC), proportional-integral-derivative, or fuzzy logic control algorithms. 4 MPC is a popular strategy for BG control because of its predictive nature and ability to enforce constraints. 5 Another advantage is the tailoring of MPC for the application. If the dynamics and timing of disturbances are known, MPC can provide feedforward disturbance rejection with a model of the dynamics. 6 Unannounced meals do not provide the luxury of feedforward knowledge but use of a meal disturbance model paired with meal detection can improve postprandial predictions.7-19 MPC relies on accurate predictions by design, so improved predictions lead to improved control.
Prediction of postprandial BG is complicated by meal size (eg, a snack vs Thanksgiving dinner) and carbohydrate absorption rate (eg, soda vs pizza), and these combined with inter/intra-patient variability of digestion leads to a gamut of postprandial responses.20-22 Another obstacle for AP systems coping with unannounced meals is the slow pharmacodynamics of subcutaneous injection insulin relative to meal dynamics. 23 This often leads to a desire to bolus 15-20 minutes before the meal. 24 Pizza, however, is best controlled with an 8-hour square wave bolus.25,26 Since slow insulin action presents a fundamental problem for control, effectively coping with unannounced meals requires fast and accurate prediction of meal size, which is traded off against safety. Risk of hypoglycemia increases when we predict meals that are slowly digested or nonexistent.
An unexplained rise in BG is observed after unannounced meals. Existing meal detection and estimation frameworks rely heavily on the initial rise. Meal size is inferred directly using the magnitude and duration of the glucose rise,8-11,13,27-29 or with a scaled meal shape.19,30
What these methods are missing is the full meal absorption shape. Published data,31-34 shown in Figure 1, shows cases where meals have similar initial rate of rise (meals 1, 4, 5), but due to different compositions (rice/sorghum, mac and cheese, and glucose in jello), have widely varying meal sizes (area under the curve).
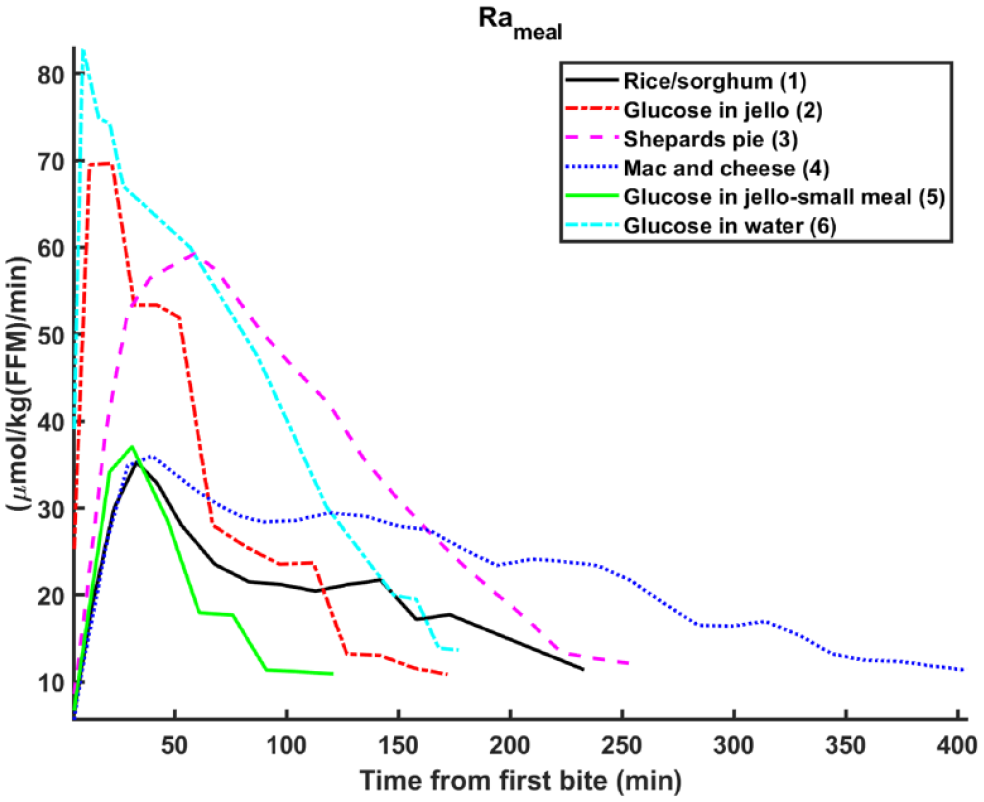
Triple tracer studies of carbohydrate turnover for meals of varying compositions.
Methods relying directly on initial rise to estimate meal size will fail because they assume the meal shape. An assumed meal shape also leads to overconfidence in the meal size estimate, and potential over administration of insulin. Reliable indicators of meal size that reduce uncertainty exist after the rise portion of the meal, but existing methods do not know to wait. Uncertainty of the meal size is accounted for indirectly using conservative insulin dosing strategies,9,11,30 requirement of persistent excitation,8,10,12,13,29 probabilistic modeling methods, 19 or bi-directional control.27,35
To avoid the issues mentioned above, we propose a meal model that divides meal absorption into two disjoint regions around the peak absorption. Before the peak, there are coarse estimates of meal size, which are fine tuned in post-peak region. The three-model system is composed of a linear rise model pre-peak, and linear drop and exponential decay models post-peak. We use Bayes’ Rule to determine when the peak occurs. We compare the proposed model to other models of increasing complexity.
Background
Many frameworks for detecting and rejecting unannounced meal disturbances have been proposed. The present work is focused on disturbance rejection rather than detection, so only that aspect will be considered in the review of existing work.
Dassau et al. 30 proposed an MPC that uses the glucose simulation model developed by Dalla Man et al.36,37 in addition to a generic meal input from Hovorka et al. 37 Lee and Bequette developed an MPC that used a finite impulse response filter to estimate meal size. 38 Lee et al. takes a similar approach, compensating for unannounced meals using BG impulses. 8
Cameron et al. presented a probabilistic multiple model approach to compensate for unannounced meals. 19 Prior probabilities based on the last mealtime are assigned to new models, which assume either a new meal or no meal. Xie and Wang propose a finite impulse response filter that is updated with measurements to estimate meal size. 10
The framework developed by Turksoy et al. uses an Unscented Kalman Filter to estimate the rate of meal carbohydrate appearance. 11 When absorption thresholds are reached, a correction bolus is calculated using the current BG and the subject’s body weight in addition to tuning parameters.
Fuzzy qualitative analysis of CGM measurements is used in Samadi et al. to detect meals and estimate size. 12 Singleton fuzzy sets informed by both insulin and CGM are used to increment estimated meal size. Mahmoudi et al. suggested a Rauch-Tung-Striebel smoother to estimate meal size after detection. 13
In addition to these frameworks, many models describing meal carbohydrate absorption have been developed, ranging from the work of Deutsch 39 to the model used in the UVa/Padova simulator. 40 A review of these models can be found in El Fathi et al. 23
Methods
Data
Data used to evaluate the models are taken from a collection of triple tracer (TT) studies; the TT technique is the gold-standard for measuring the rate of meal carbohydrate appearance. 41 Although not all subjects were people with Type 1 diabetes, it has been shown this has little effect.34,42,43
Rather than use all available TT data, which consist mostly of standard test meals (egg, bacon, and jello), we chose six distinct meal shapes spanning a range of compositions and sizes. Figure 1 shows the shapes, and Table 1 provides the study details.
The Triple Tracer Datasets, Which Consist of Meals with Varying Compositions and Sizes.
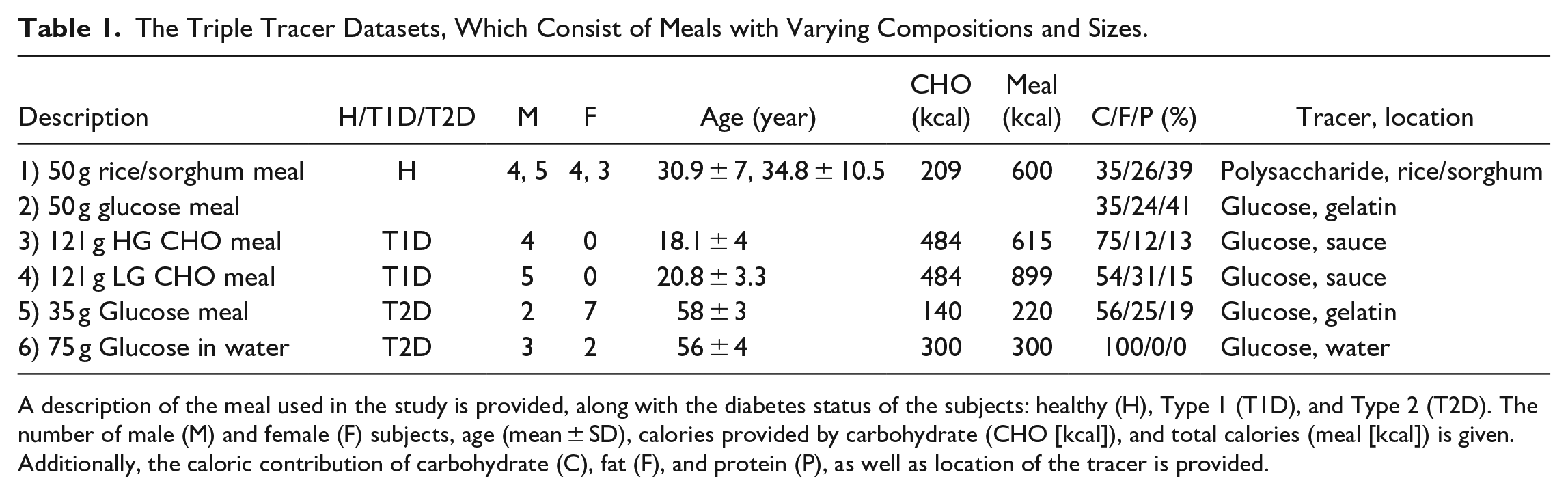
A description of the meal used in the study is provided, along with the diabetes status of the subjects: healthy (H), Type 1 (T1D), and Type 2 (T2D). The number of male (M) and female (F) subjects, age (mean ± SD), calories provided by carbohydrate (CHO [kcal]), and total calories (meal [kcal]) is given. Additionally, the caloric contribution of carbohydrate (C), fat (F), and protein (P), as well as location of the tracer is provided.
TT studies are resource intensive but provide excellent descriptions of postprandial carbohydrate turnover, which are not possible to extract from CGM data because of multiple confounding effects. To study the effect of complex carbohydrates, Basu et al. use the complex carbohydrate itself as the tracer. 31 Elleri et al. also study the effects of complex carbohydrates but use a glucose tracer, necessitating a different methodology. 44 Though the method may have drawbacks, 31 we still include their data. Data from over 50 individuals of differing diabetes conditions are included in the collected dataset.
Model Updating
All proposed models are linear time invariant and can be written as a discrete state space system:
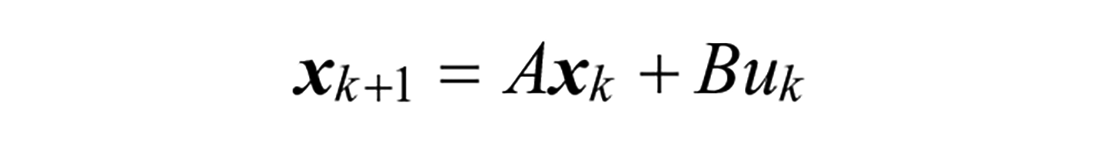
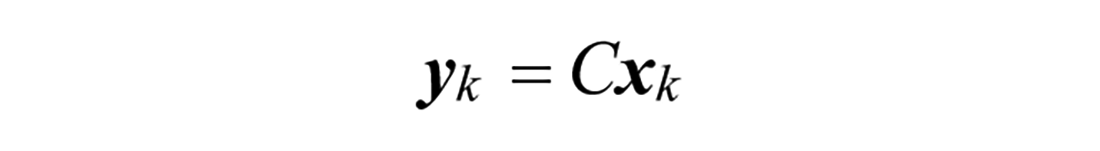
The states and covariance estimates of models are propagated through time and updated from measurements using the Kalman Filter time and measurement update equations:
Time update:
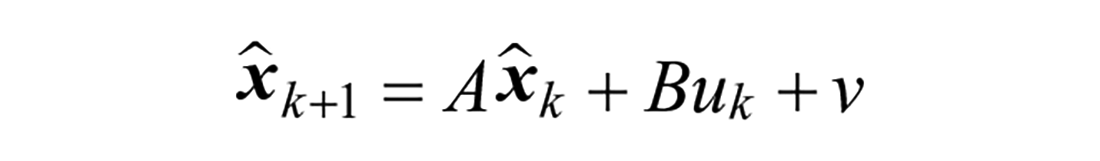
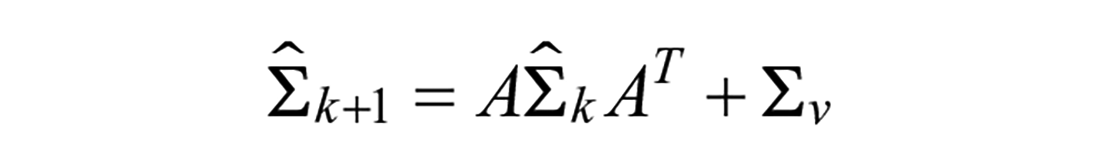
Measurement update:
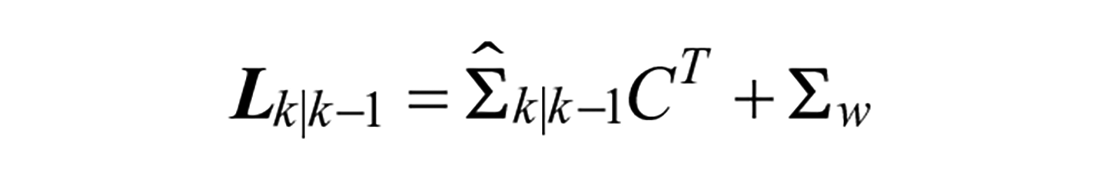
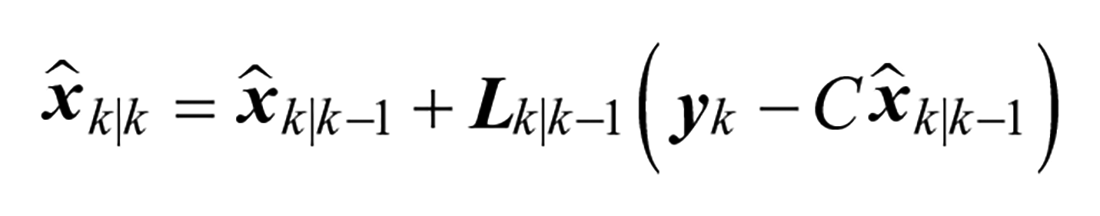
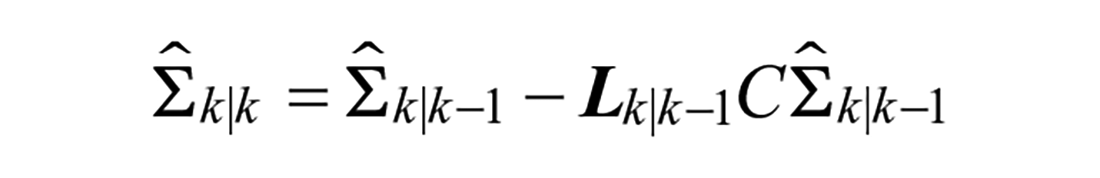
Model 1: Second Order Response
The first model proposed is a linear second order response inspired by previously developed two-compartment models.
23
Contents enter the first compartment,
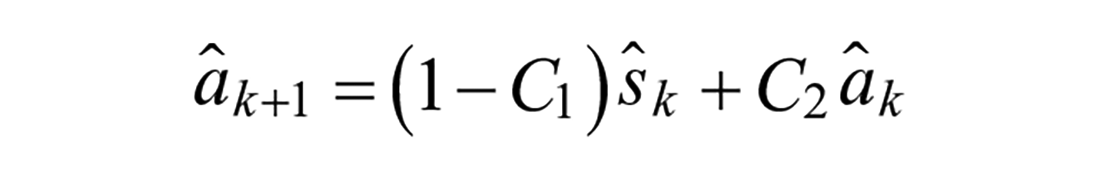
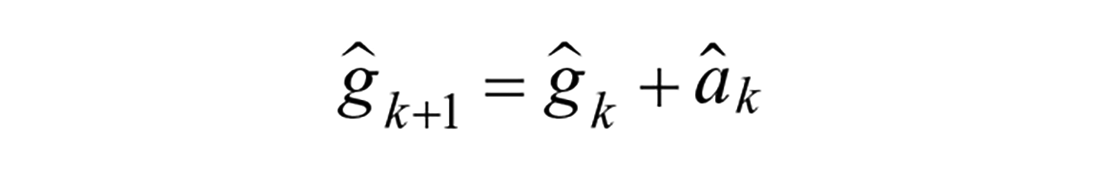
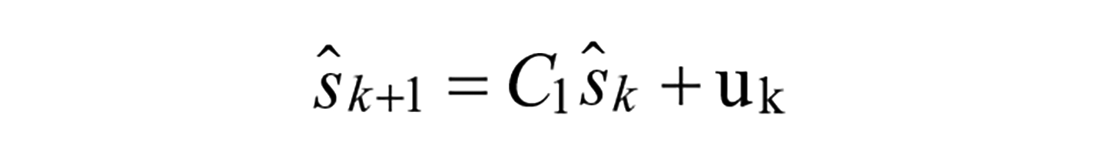
Model 2: Augmented Second Order Response
Modulations in shape of the meal absorption curve can be achieved with additional states
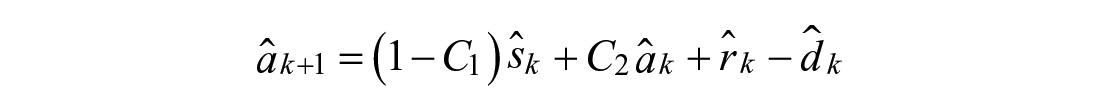
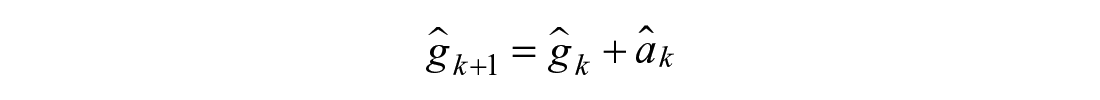
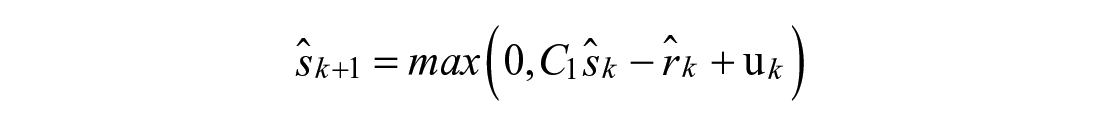
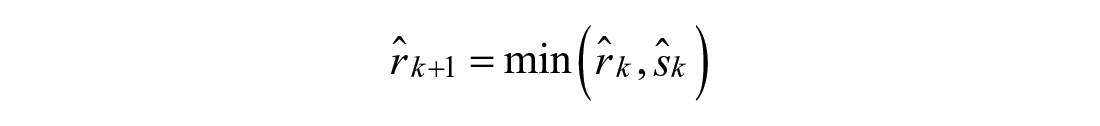
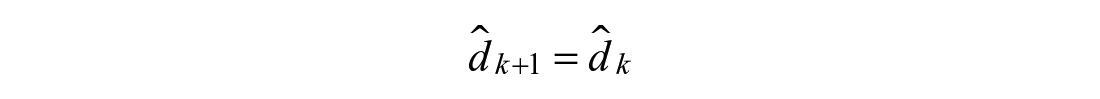
Model 3: Nonlinear Second Order Response
Model capacity may also be increased with a nonlinear model paired with an Extended Kalman Filter. To accurately describe gastric emptying, a nonlinear model may be necessary.
45
Towards this end, the coefficient of emptying from the first compartment is estimated as a state,
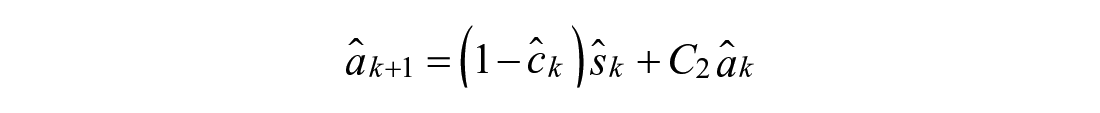
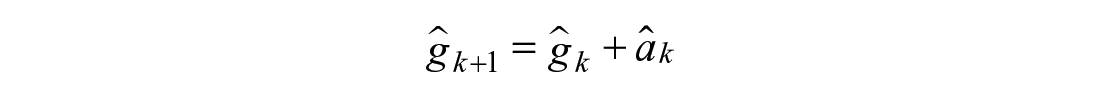
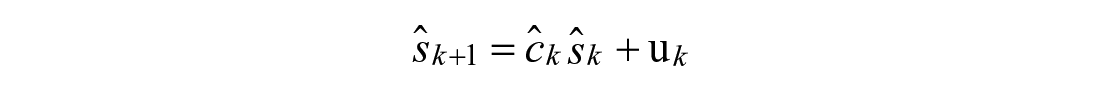
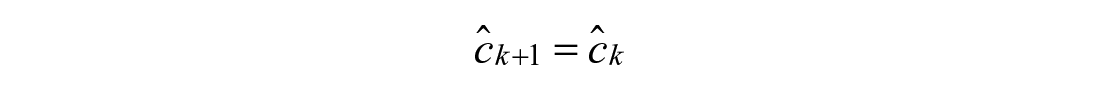
Variable Hump Model
The methods previously described represent attempts to increase model capacity but are still fundamentally limited as single models that assume a single shape. To infer both meal size and absorption shape, we propose a multiple model framework of three sub-models.
Linear Rise (1):
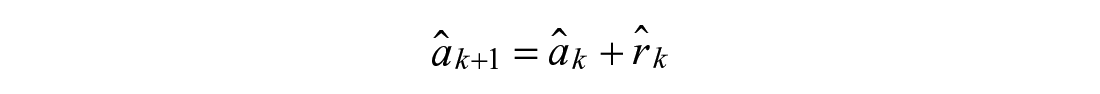
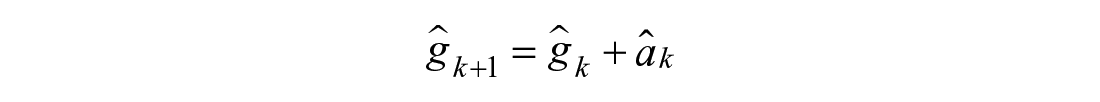
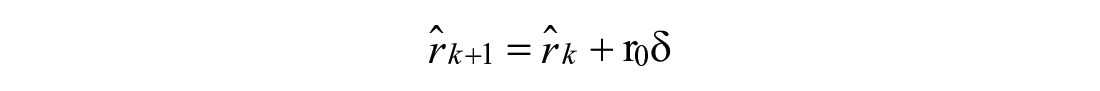
Linear Drop (2):
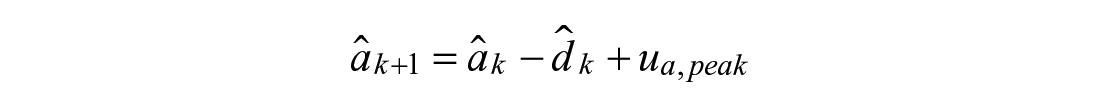
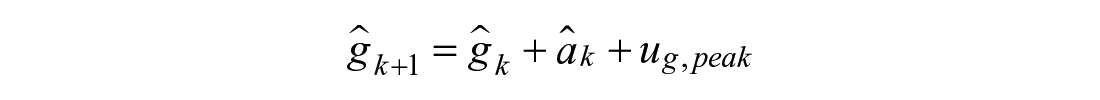
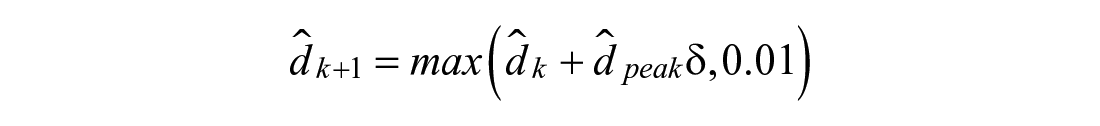
Exponential Decay (3):
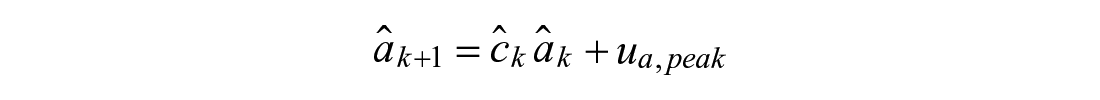
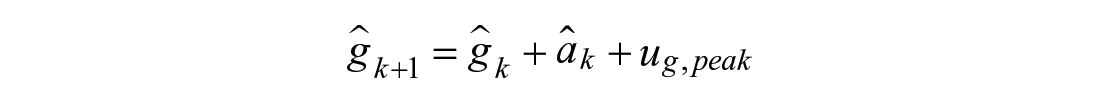
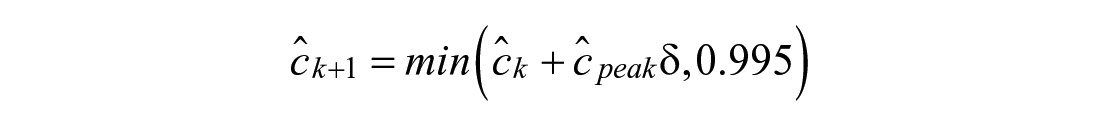
The modeling approach, presented in Figure 2, divides the meal absorption curve into two disjoint regions, pre-peak (←) and post-peak (→). Embedded are two switching systems. 45 The first determines peak time by considering possible models that change from pre-peak to post-peak behavior at a given time. Prior knowledge of peak time is incorporated with Bayes’ Rule. The second, which constitutes post-peak behavior, is a two-model switching system between drop and decay behavior.
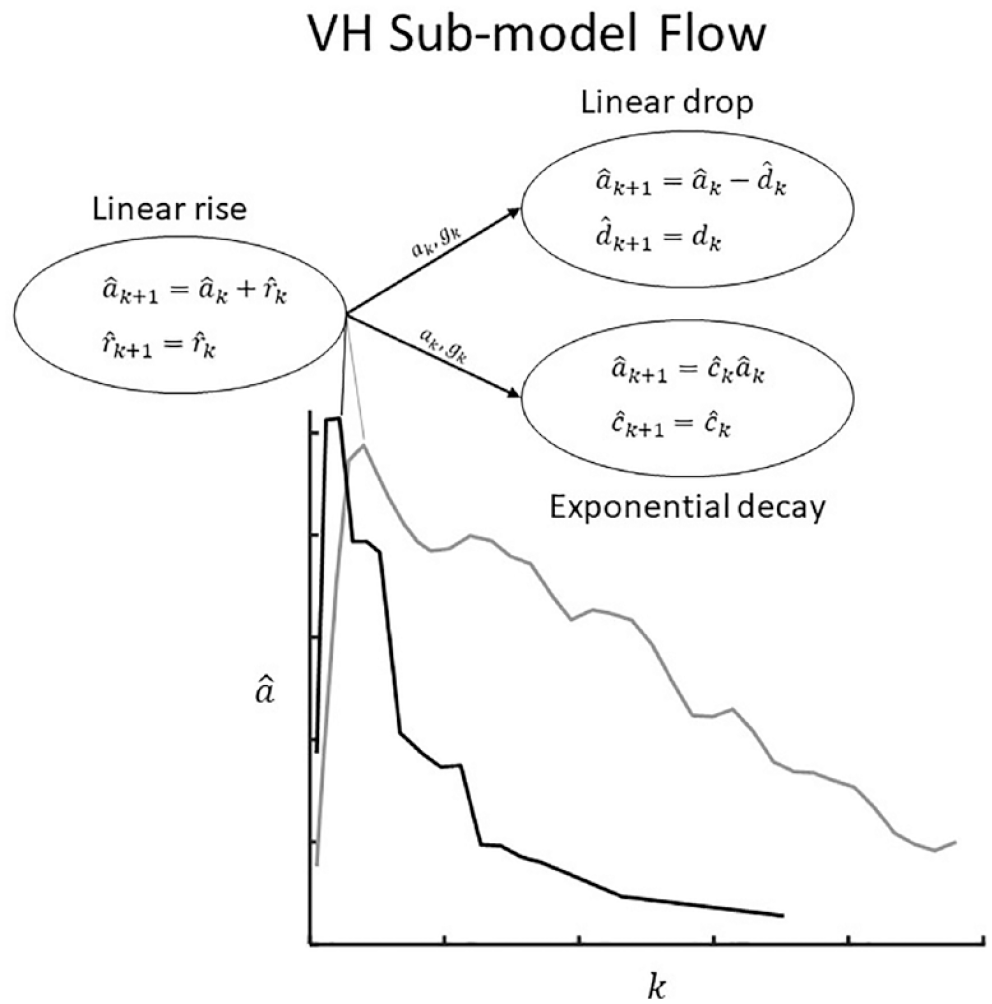
Modeling framework of proposed Variable Hump (VH) Model: After the peak, two models are used to capture different meal shapes.
Pre-peak behavior
The rise sub-model fully governs in the pre-peak region. To detect the peak with Bayes’ rule we reset the drop and decay models every time,
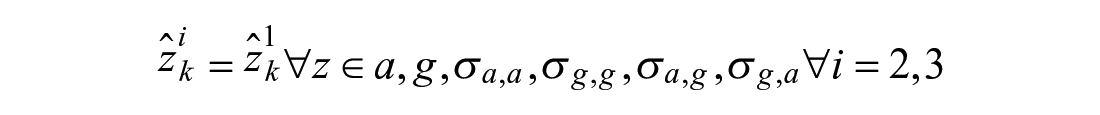
The superscript 1 indicates the rise sub-model whereas superscripts 2 and 3 indicate drop and decay sub-models, respectively.
The drop rate
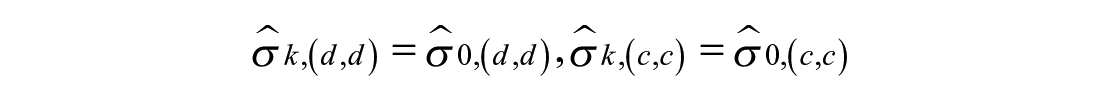
Peak absorption switch
Peak absorption occurs when post-peak behavior is equally or more probable than pre-peak behavior:
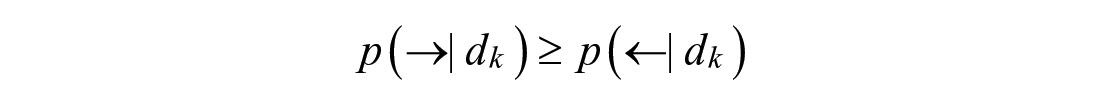
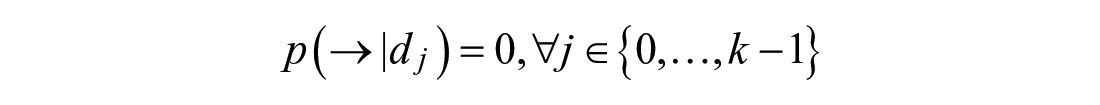
Bayes’ Rule is used to incorporate prior knowledge:
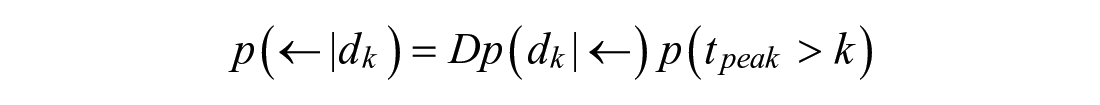
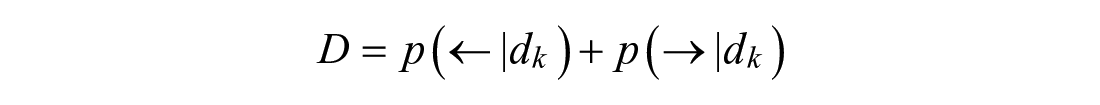
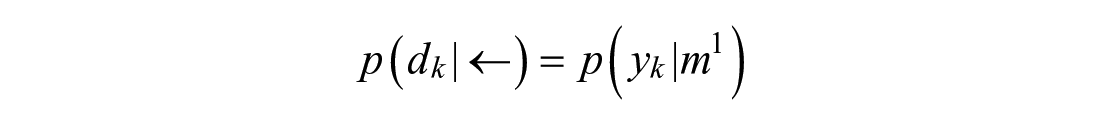
The innovation’s probability in a Gaussian function of zero mean and standard deviation following sensor noise
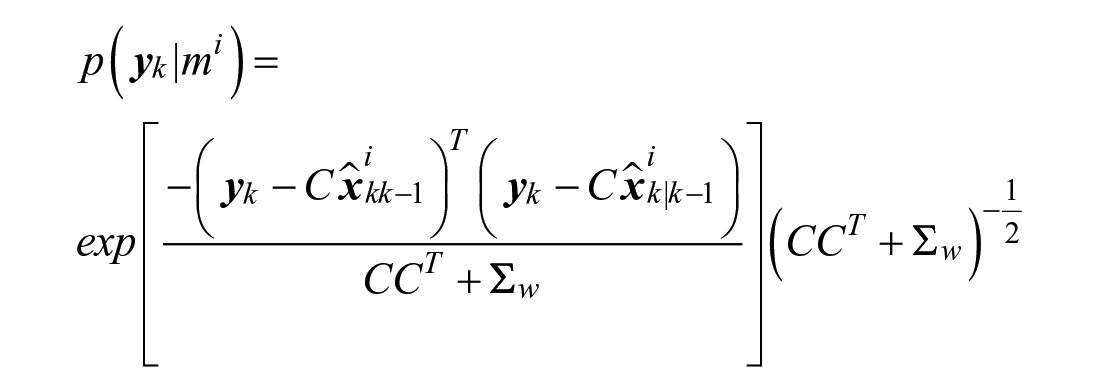
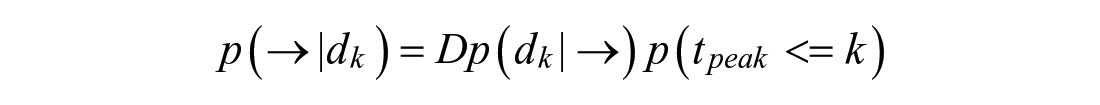
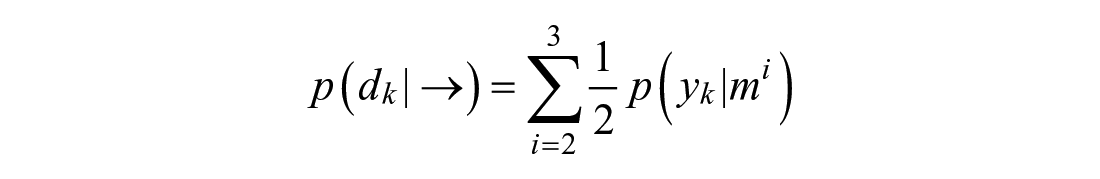
The prior probability of post-peak behavior is the remaining probability from the pre-peak prior:
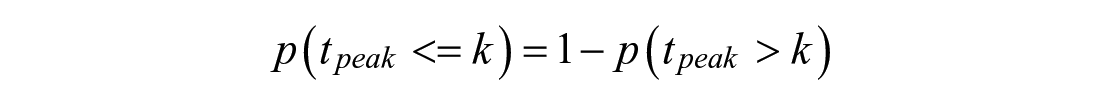
When behavior switches from pre-peak to post-peak, the drop and decay sub-model’s glucose appearance and accumulation states/covariance are initialized using a probability-weighted combination between all sub-models:
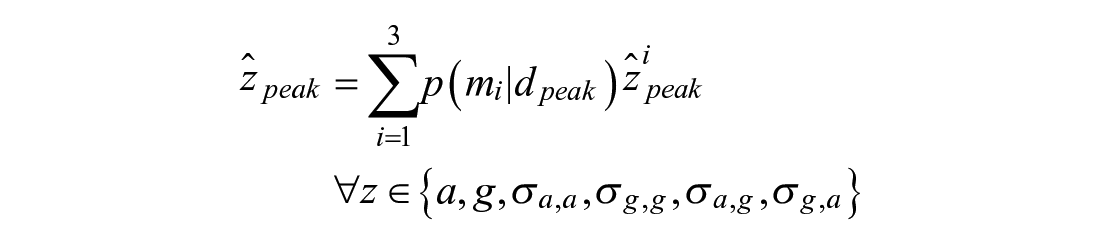
To initialize the drop
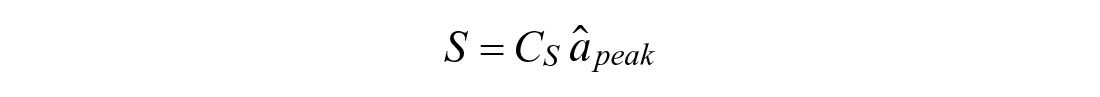
Given the estimated peak absorption value
A higher peak absorption value
The final item we consider at the peak is uncertainty. Following the assumptions that (1) meals with an absorption peak of zero (ie, meal size of zero) have no uncertainty, (2) uncertainty increases with predicted meal size, and (3) uncertainty increases with larger peak absorption uncertainty, we scale the uncertainty matrices. The scale,
xj represents sample points from the estimated distribution of peak absorption
Post-peak behavior
Post-peak behavior is characterized by a two-model switching system between the drop and decay sub-models. Bayes’ Rule is modified to consider all measurements since the peak:
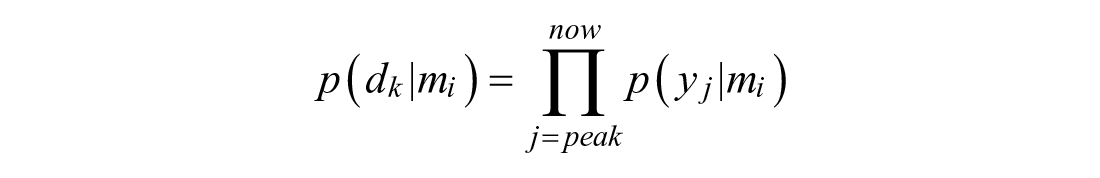
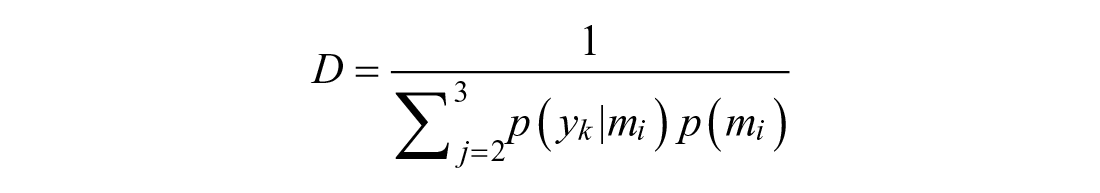
Note that the prior probability term
Prediction
To predict, the VH model states and covariance matrices are propagated into the future without measurement updates via the KF time update equations. Final predictions are a probability-weighted combination of the sub-models. This requires a prediction of the weights assigned to the sub-models.
To predict from the pre-peak region, the peak absorption time (
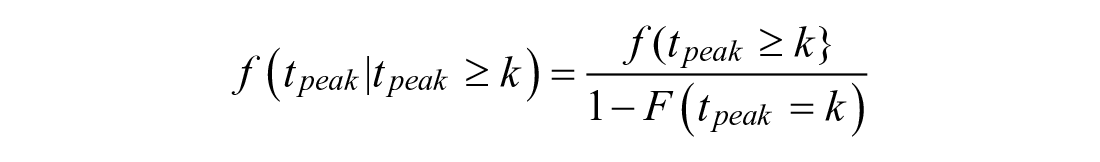
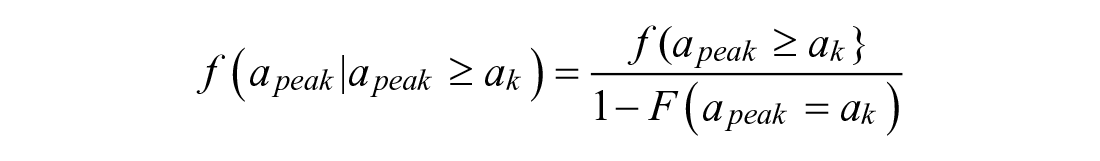
To predict peak absorption time and magnitude, let
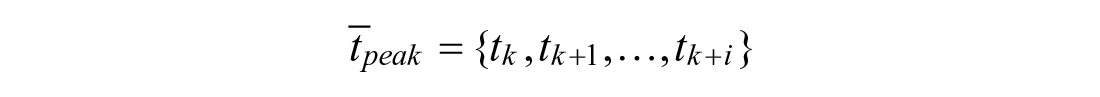
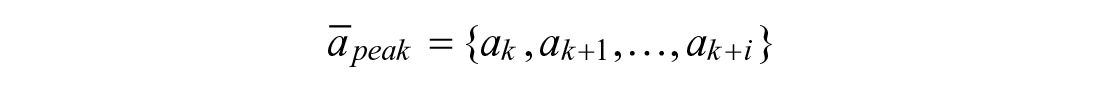
The peak occurs at the time step
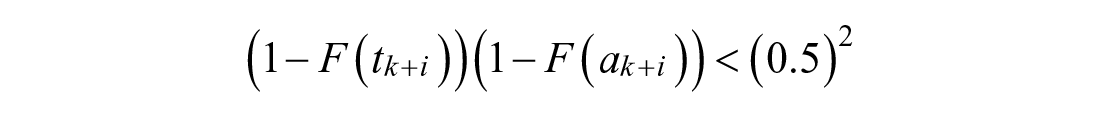
Letting
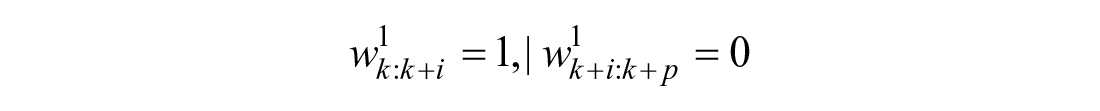
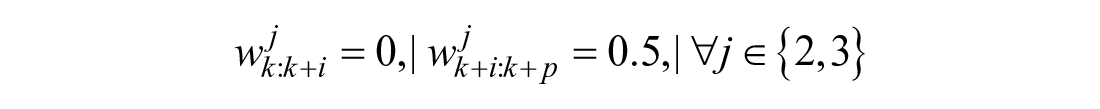
Calculating the predicted weights is much simpler when predicting from the post-peak region:
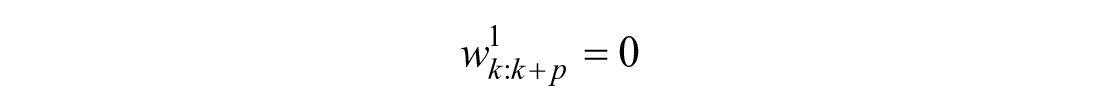
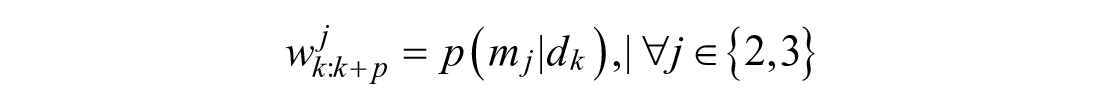
Model invalidation
When infeasible states are estimated, we choose to constrain the model in both state and covariance. If the rise rate
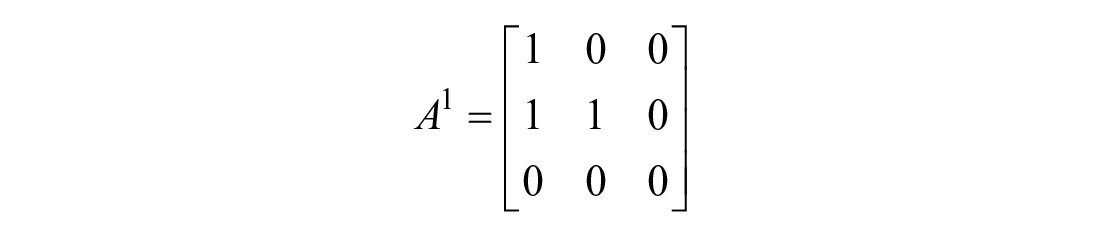
This has the effect of holding absorption constant. If the estimated glucose absorption of the drop sub-model becomes negative,

Model Evaluation
Capability of model fit to data is determined by optimization of model parameters (
Prediction accuracy is evaluated by performing Kalman Filtered predictions at every measurement update. Starting model state was initialized to the mean of all optimal initial states found above, while initial model uncertainty was initialized to the variance. Values for sensor
The ability of each model to estimate the time of peak absorption was considered. To evaluate how well each model predicts its accuracy, the actual percentage of readings within symmetric confidence bounds of a given theoretical percentage were tallied. Finally, we examine a simple implementation of the models.
Results
Within the VH Model, adaptability to the meal shape is aided by using two sub-models post-peak. Behavior is better described by the decay sub-model in some cases and by the drop sub-model in others. In the left panel of Figure 3, the decay (red) provides a better fit to the data than the linear drop (RMSE: 235 vs 2051
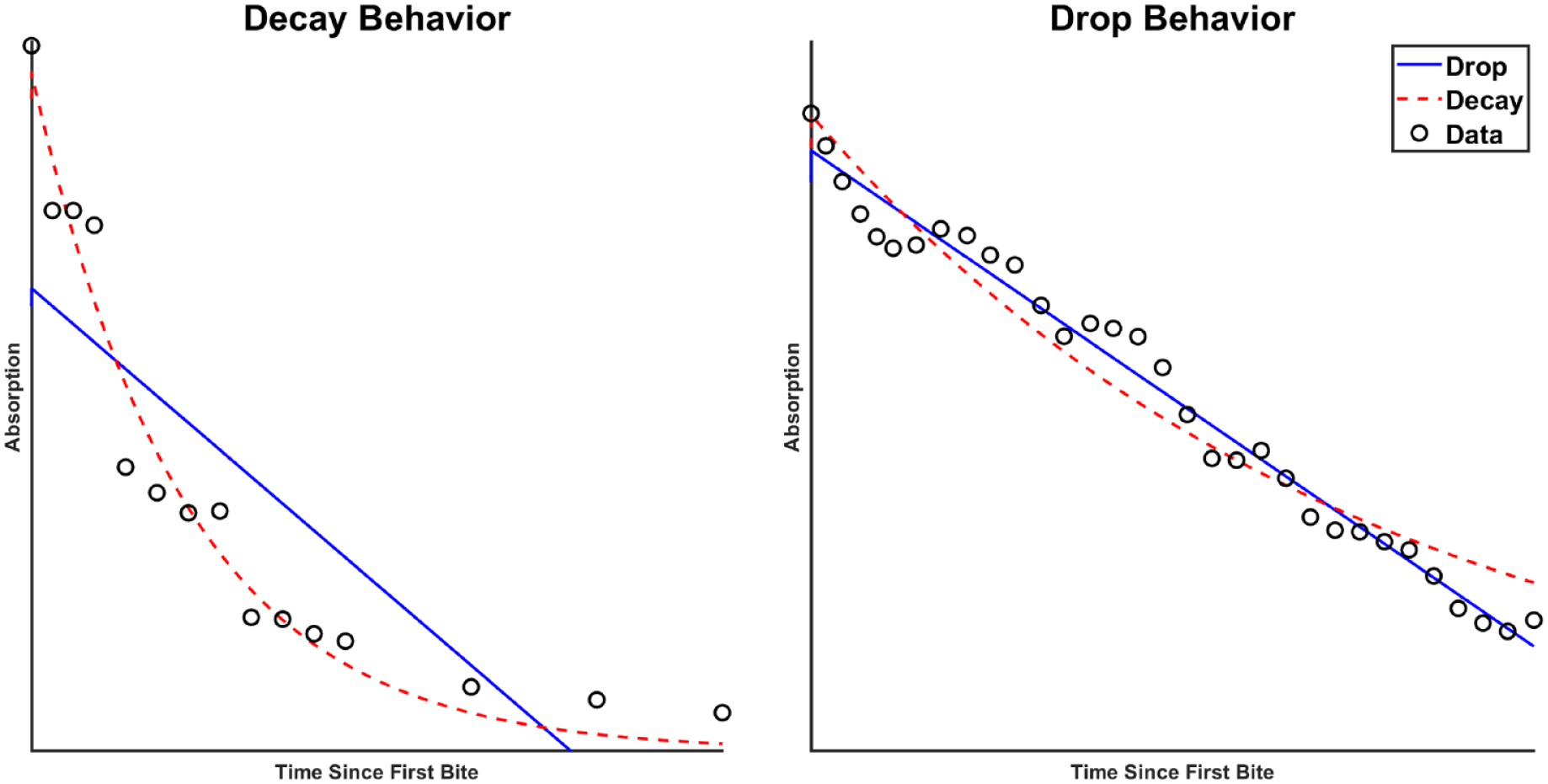
Some curves are better described by a decay behavior (left), whereas others a drop behavior (right). The left panel shows the least-squares fits to Meal 2, while the right panel shows fits to Meal 4. Absorption has units of µmol/kg (FFM)/min. FFM: fat free mass.
Among all models, Model 1, which assumes a single shape, is the least capable of fitting the data per Table 2. Models 2 and 3, which allow modulations in shape, provide better fit. The multiple-model VH framework is the most capable of fitting the data.
Fit, Prediction Accuracy, and Run Time of the Evaluated Models on the Triple Tracer Dataset.

Prediction accuracy follows a similar trend as model fit, but Model 3 provides superior predictions compared to Model 2. The VH model most accurately predicts total meal size, showing a 21% improvement over Model 1 and an 11% improvement over Model 3. The trend of predicted meal size across all meals and models is shown in Figure 4. Specifically, the predicted meal size (
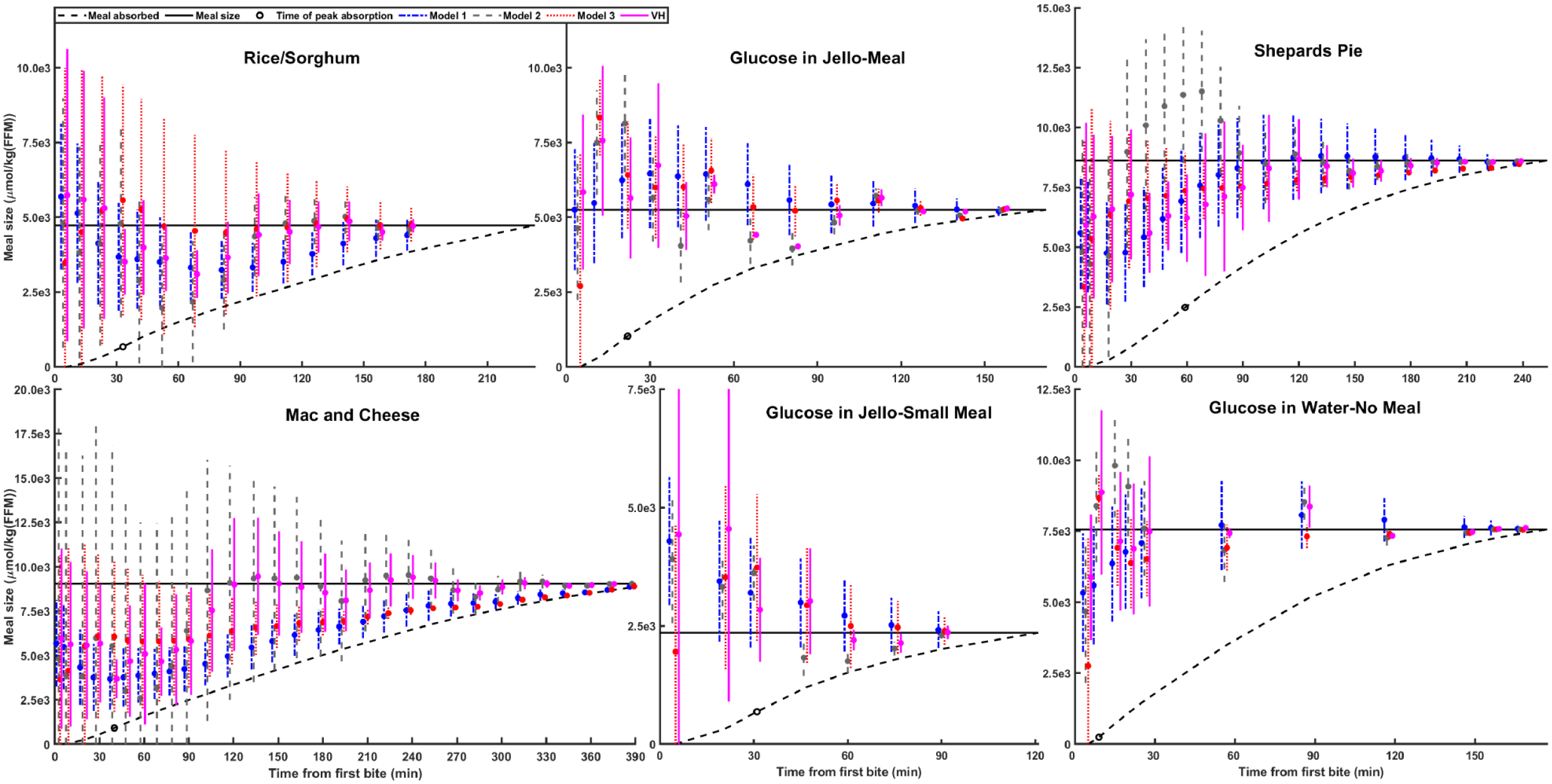
Evolution of predicted meal size
Figure 5 shows residuals of the model-estimated peak time from the true peak time (vertical black line). A constant peak time (depicted by digits 1-6) equal to the mean of the dataset peak times (32 minutes) is included for comparison. Arrows represent the adaption from the constant peak time to the VH estimated peak time. The VH model most accurately estimates the true RA peak time, see Table 3. Additionally, the empirical cumulative distribution functions of the actual peak times along with model-estimated peak times is presented in the Appendix (Figure S1).
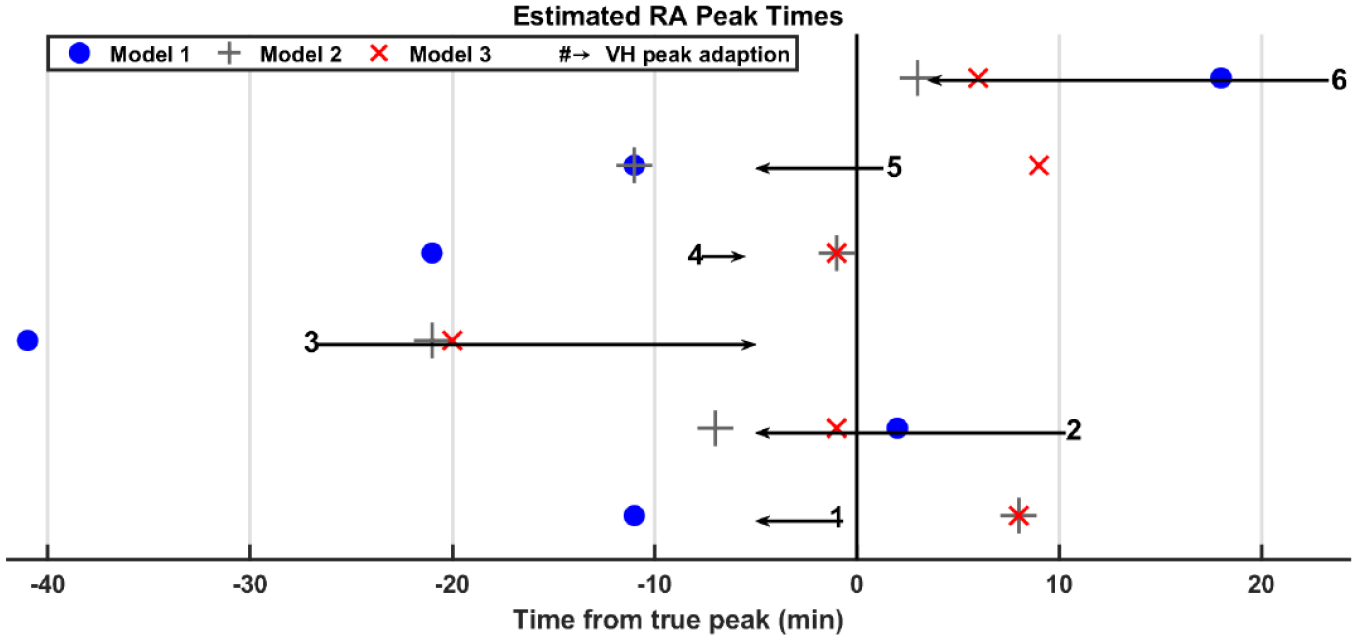
Residuals of estimated model-absorption peak time from time of true absorption peak (blue dot: Model 1, gray +: Model 2, red x: Model 3, black arrowhead: VH Model, #: Assumed constant peak time of 32 minutes). An arrow connects the assumed constant peak time (32 minutes) to the VH Model estimated peak time. VH: Variable Hump.
Mean Absolute Error (Minutes) of the Estimated Peak Absorption for All Models.

Figure 6 shows how well each model predicts its accuracy. Specifically, it shows agreement between the theoretical confidence interval of predicted meal size and the actual coverage. Intervals of theoretical confidence spanning 1%-99% are generated using:
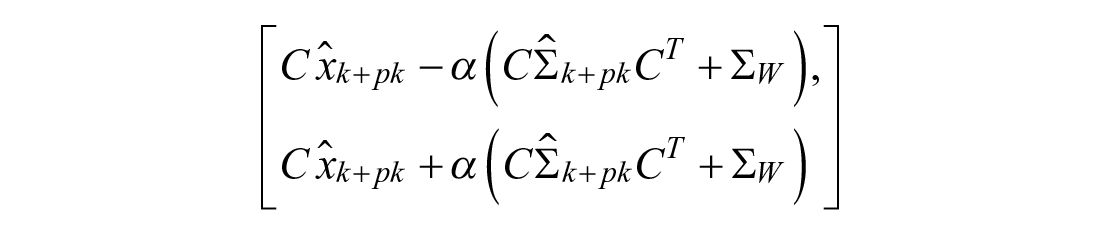
A model with perfect predictions of uncertainty would follow the 1:1 line in Figure 6. The VH Model provides the closest agreement between the theoretical and actual coverage, see Table 4.
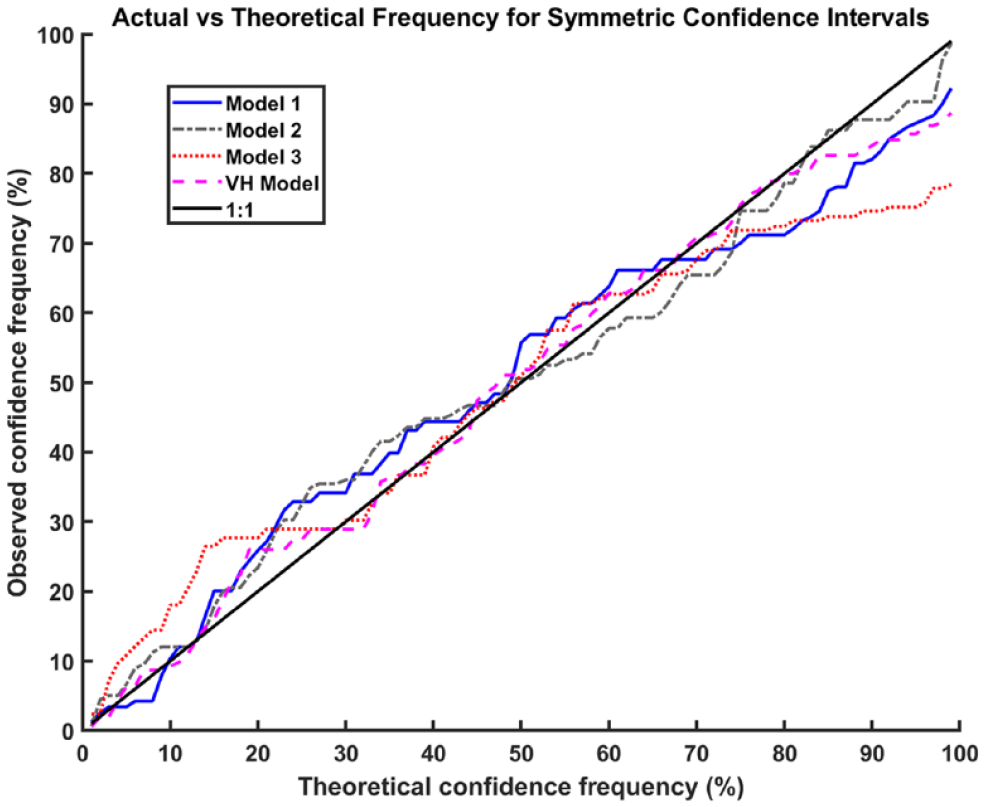
Agreement between symmetric confidence intervals of a theoretical width with the actual percentage of readings within the interval.
Root Mean Squared Error of Observed Frequency from Actual Frequency (%).

A simple implementation is considered in Figure 7. Since underestimation is preferred, we compensate with insulin assuming a meal size equal to the lower bound of predicted meal size
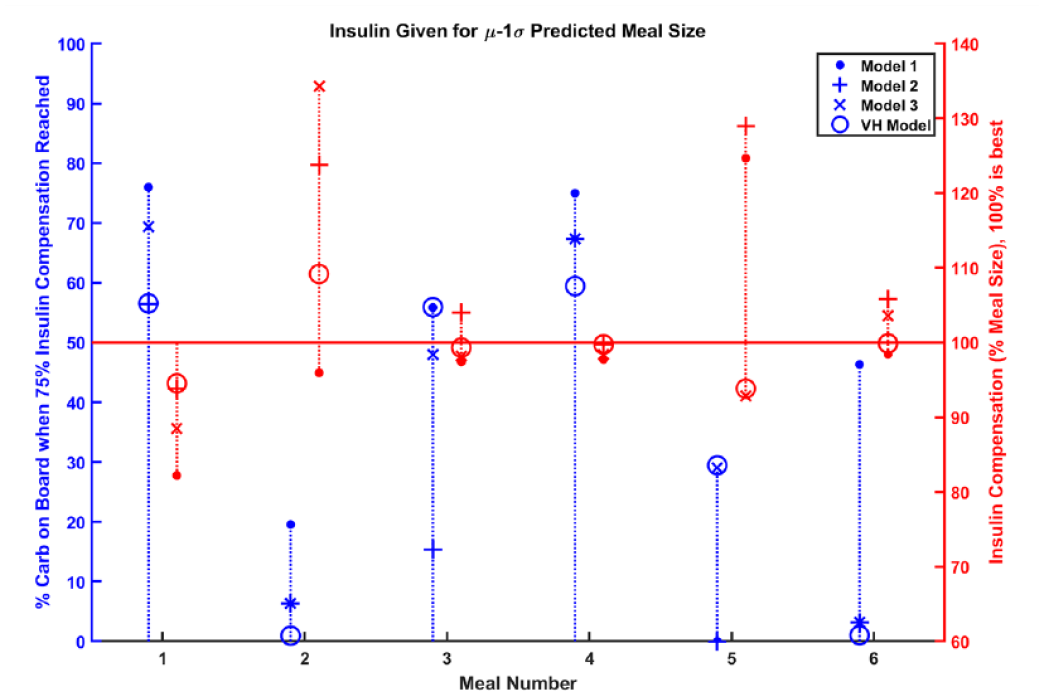
Since underestimation of meal sizes is preferred to overestimation, one may choose to deliver insulin assuming a meal size determined from the lower bound of predicted meal size (µ-1σ). Compensation for 75% of the meal is shown on the left axis and as blue data. The total insulin compensation is shown on the right axis and as red data.
In four out of six meals, the controller governed by the VH Model is the quickest to compensate for 75% of the meal. A controller that over-compensates is considerably handicapped because of the safety implications of hypoglycemia. In at least one meal, the controllers for Models 1-3 overcompensate by at least 25%, while the maximum overcompensation for the VH Model controller is 9%.
Increases in model capacity should be weighed against added computational burden since model predictions must be made online in an AP. The run-time required to make a prediction was: 0.0011 s, 0.0014 s, 0.0030 s, and 0.035 s for Models 1, 2, 3, and VH, respectively.
Discussion
The drawbacks of assuming a single meal shape are shown with Model 1, which yielded prediction performance comparable to the VH model on meals with simple carbohydrates (total MSE for Meals 2, 5, and 6: 8.00e5 vs 8.01e5, respectively) but not slow meals with complex carbohydrates (total MSE for Meals 1, 3, and 4: 5.16e6 vs 2.92e6, respectively). While Model 3 adapts to complex carbohydrate meals (MSE: 3.23e6), prediction accuracy is degraded on the simple carbohydrate meals (MSE: 1.54e6). Model adaptability clearly matters, but single models (Models 1-3) present a trade-off between prediction accuracy and adaptation.
Research suggests that gastroparesis affects 40% of individuals with Type 1 Diabetes. 46 This logically increases digestive variability, leading to varied postprandial BG responses. A model that can describe and adapt to a wide array of meal types, such as the VH Model, would be preferred in these cases.
Variability in the time of peak absorption is not captured when a fixed peak time is assumed. The VH model, which explicitly considers the peak, exhibits the largest degree of adaptation, as shown in Figure 5 and Table 3. The rounded peak in Meal 3 (Shepard Pie) appears as an outlier compared to the sharp peak transition characteristic of the other meals. The late peak combined with inter-individual variability of digestion speed might have exacerbated the difference in glucose absorption profiles, leading to a rounded peak after averaging. The VH model expects a sharp transition and initially estimates a peak absorption time at 34 minutes after the first bite of the meal. However, the VH Model has the capability to revert to pre-peak rise behavior and estimates a refined peak absorption time at 54 minutes while all other models estimate a peak time much earlier than what actually occurs (Figure 5).
Erroneous control decisions present severe consequences in BG control, particularly hypoglycemia. A model that correctly predicts its accuracy, such as the VH Model, is desired because a substantial amount of insulin is delivered following meal consumption.
Insulin needs to be fast and accurate to attenuate the effects of meals. By considering the possibility of different meal shapes while remaining uncertain until appropriate, the VH model excels at providing fast and accurate insulin in the potential implementation (Figure 7).
Conclusion
In conclusion, we introduced a model with increased capacity to describe varying meal shapes. The model infers both size and shape of the meal by adapting around the peak. To address the inherent uncertainty before the peak, the multiple model framework considers two disjoint regions that consist of coarse and fine-grain predictions of meal size, respectively. Using gold-standard data, we show improvement over simpler models in terms of (1) fit capacity, (2) prediction accuracy, (3) peak time estimation, (4) prediction of accuracy, and (5) a hypothetical control scenario. The small dataset limits this work to a proof of concept study, but a retrospective analysis of prediction accuracy on real data may reveal more benefits of this new approach.
Supplemental Material
sj-pdf-1-dst-10.1177_1932296821990111 – Supplemental material for A New Meal Absorption Model for Artificial Pancreas Systems
Supplemental material, sj-pdf-1-dst-10.1177_1932296821990111 for A New Meal Absorption Model for Artificial Pancreas Systems by Travis Diamond, Faye Cameron and B. Wayne Bequette in Journal of Diabetes Science and Technology
Footnotes
Acknowledgements
The authors would like to acknowledge Pranesh Navarathna for his helpful comments during the drafting process.
Abbreviations
AP, Artificial Pancreas; BG, Blood Glucose; CGM, Continuous Glucose Monitor; CDF, Cumulative Distribution Function; EKF, Extended Kalman Filter; FFM, Fat Free Mass; IID, Independent and Identically Distributed; MSE, Mean Square Error; MPC, Model Predictive Control; PID, Proportional-Integral-Derivative; PDF, Probability Density Function; RMSE, Root Mean Square Error; TT, Triple Tracer; VH, Variable Hump.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by NIH grant 1R01DK102188, and JDRF 1-SRA-2019-817-S-B.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.