
Abstract
Background:
Real-world evidence research plays an increasingly important role in diabetes care. However, a large fraction of real-world data are “locked” in narrative format. Natural language processing (NLP) technology offers a solution for analysis of narrative electronic data.
Methods:
We conducted a systematic review of studies of NLP technology focused on diabetes. Articles published prior to June 2020 were included.
Results:
We included 38 studies in the analysis. The majority (24; 63.2%) described only development of NLP tools; the remainder used NLP tools to conduct clinical research. A large fraction (17; 44.7%) of studies focused on identification of patients with diabetes; the rest covered a broad range of subjects that included hypoglycemia, lifestyle counseling, diabetic kidney disease, insulin therapy and others. The mean F1 score for all studies where it was available was 0.882. It tended to be lower (0.817) in studies of more linguistically complex concepts. Seven studies reported findings with potential implications for improving delivery of diabetes care.
Conclusion:
Research in NLP technology to study diabetes is growing quickly, although challenges (e.g. in analysis of more linguistically complex concepts) remain. Its potential to deliver evidence on treatment and improving quality of diabetes care is demonstrated by a number of studies. Further growth in this area would be aided by deeper collaboration between developers and end-users of natural language processing tools as well as by broader sharing of the tools themselves and related resources.
Introduction
As complexity and multidimensionality of patient care continue to grow, there is an increasing recognition that multiple sources of data are needed to provide a comprehensive picture of healthcare processes and outcomes. One important source of information that has been playing a progressively greater role in medical investigations is real-world evidence: the results of analysis of data that were generated in the course of routine patient care rather than specifically for research. 1 The 21st Century Cures Act calls for increasing use of real-world evidence in development and evaluation of new medical treatments and technologies. 2 The U.S. Food and Drug Administration (FDA) encourages using real-world evidence to support regulatory decision-making for drugs, biologics and medical devices. 3 To utilize this novel source of data effectively, it is critical that we develop and validate methods that can leverage its strengths to reliably answer research questions. 4
One important potential source of real-world evidence is so-called narrative electronic data. This category includes information in electronic health records that was generated as text rather than discrete data points (e.g. diagnoses on the problem list or laboratory values). It may comprise notes written by healthcare providers; reports describing results of imaging studies or conduct of surgical procedures; inpatient discharge summaries; etc. Narrative data in its native form cannot be analyzed using traditional analytical techniques and have to first be converted to structured (discrete) data. The suite of technologies that can accomplish this task is called natural language processing (NLP). 5 In particular, over the last decade multiple applications of natural language processing in medicine have been developed and utilized in research, population management and clinical operations.6,7 Natural language processing applications have been used in research and clinical operations in a number of fields including radiology, psychiatry and oncology, among others.8-10
Diabetes mellitus is a good example of a disease that could benefit from generation of real-life evidence using natural language processing. Treatment of diabetes often involves extended discussions between patients and healthcare providers involving multiple aspects of the care process, including lifestyle changes, goals of care, adverse reactions to medications, barriers to care, etc. 11 These discussions tend to be minimally represented in structured/discrete data and consequently are impossible to study or monitor on a population scale without a natural language processing solution. We therefore conducted a systematic review of studies of natural language processing systems focused on diabetes to describe the current state-of-the-art of the technology, its potential impact on diabetes care, and identify future directions for growth.
Methods
Study Design
We conducted a systematic review of original research studies focused on diabetes and natural language processing published prior to June 2020.
Data Sources and Searching Strategy
We searched for English language publications in June 2020 in PubMed, EBSCO and Clinical Key databases using Medical Subject Headings (MeSH) terms and keywords related to (a) diabetes and (b) natural language processing. Candidate articles were also identified based on the authors’ knowledge of the literature. The complete list of search terms is provided in the Appendix. The overall search strategy is illustrated in Figure 1.
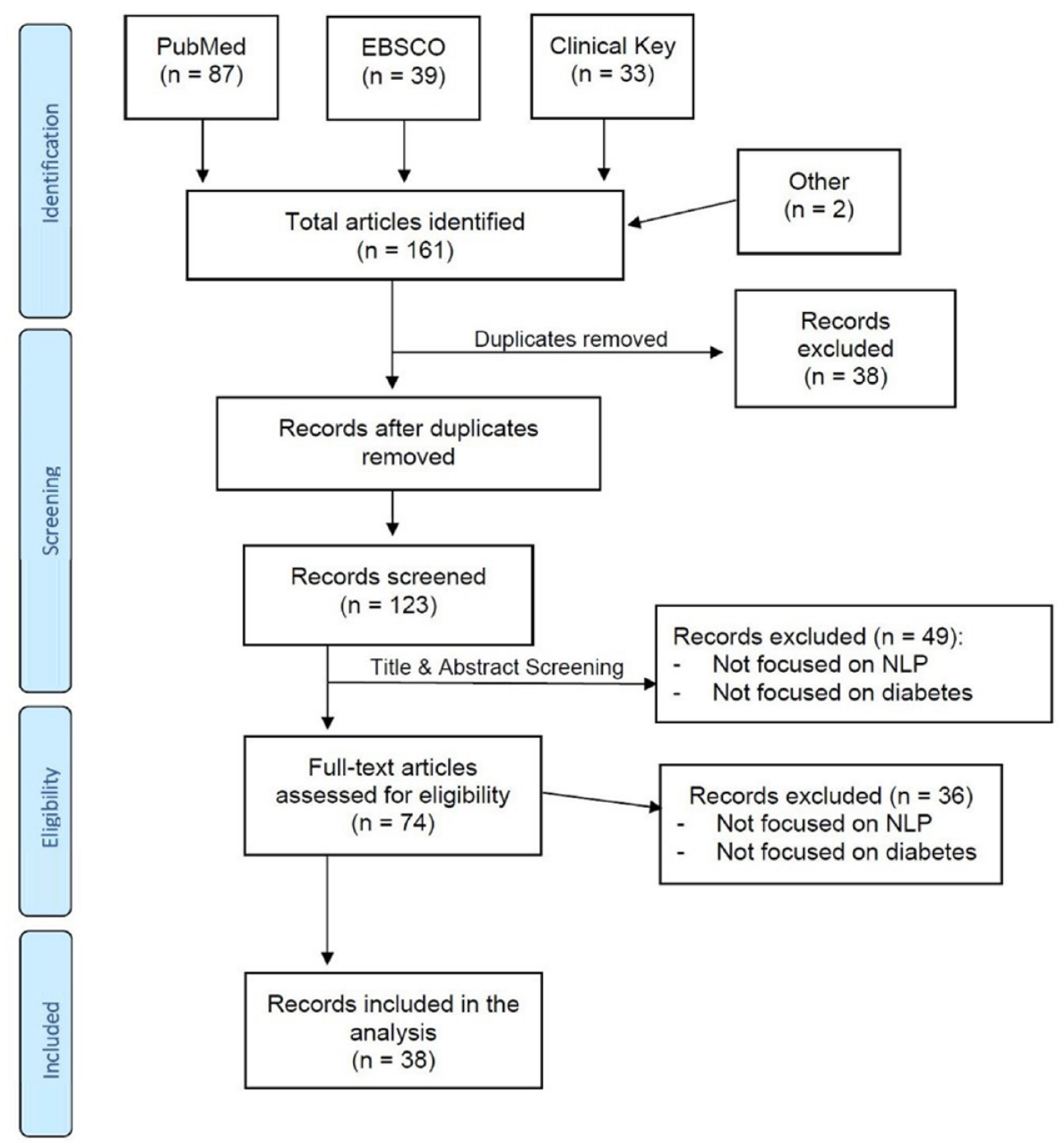
PRISMA flow diagram.
Screening Criteria
The articles identified using search criteria were first screened for duplicates, both within and across databases. After duplicates were removed, the title and abstract of each article were examined to determine whether both diabetes and natural language processing were a significant focus of the investigation. We subsequently examined the full text of articles that passed this initial screening to confirm their focus on diabetes and natural language processing. Articles were included if they focused on any aspect of diabetes care, including prevention, diagnosis, treatment and complications. All aspects of diabetes treatment were considered, including lifestyle changes, pharmacological and technology-based treatment approaches.
Study Measurements
Each article included in the analysis was rated on the following aspects:
Study Focus: we determined whether the study presented in the paper focused solely on development and validation of the natural language processing tool (NLP Tool) or utilized the natural language processing tool for analysis of any aspects of diabetes care (Research).
NLP Concepts: we identified concepts that were being ascertained by the natural language processing tool (for example, diagnosis of diabetes or hypoglycemia).
Concept Composition: we determined whether concepts that were being ascertained by the natural language processing tool were single- or multi-component. Single-component concepts are typically represented by either a single word (e.g. hypoglycemia) or a phrase/several words located next to each other (e.g. diabetes mellitus). Multi-component concepts are represented by sub-concepts (words/phrases) that can be located apart from each other in the document. An example of a multi-component concept could include side effects of medications, where the medication sub-concept and the side effect sub-concept may not be located next to each other in the sentence (e.g. She tried
Accuracy: F1 score 12 (a harmonic mean of sensitivity and positive predictive value) was preferentially reported as a representation of the natural language processing tool accuracy if it was either directly available in the article or could be calculated from data presented. If accuracy data for several concepts were presented, micro-averaged F1 score was reported, if available; otherwise the highest accuracy described in the article was reported.
Competition: we reported whether the article described a natural language processing tool developed as part of a competition.
Analysis Category: for articles that described utilization of the natural language processing tool for analysis of diabetes care (i.e. articles whose Study Focus was rated as Research), we determined whether they presented an investigation that was Descriptive, Predictive Modeling or Hypothesis-Testing in nature.
Diabetes Care Impact: for articles that described utilization of the natural language processing tool for analysis of diabetes care, we determined whether any recommendations for changes in how diabetes care is delivered could potentially be derived from their findings. For example, if an article solely described predominance of hypoglycemia among patients with diabetes, it would be rated as No Diabetes Care Impact. On the other hand, if an article described higher prevalence of hypoglycemia among patients treated with insulin, it would be rated as Diabetes Care Impact because its findings implied that changing insulin to another diabetes medication could decrease the risk of hypoglycemia.
Results
We identified 38 articles describing original research studies focused on diabetes and natural language processing published prior to June 2020. The earliest article was published in 2005 and most were published in the last decade (Table 1). The majority of the studies (24; 63.2%) were focused solely on development and validation of natural language processing tools, but over a third used the tools to conduct clinical research. Most (23; 60.5%) studies identified single-component concepts. The most common concept identified by the natural language processing tools was the diagnosis of diabetes (17; 44.7%) and hypoglycemia was the second most common (5; 13.2%). Six (15.8%) studies described natural language processing tools developed for a competition held in 2014. 13
Selected Studies.
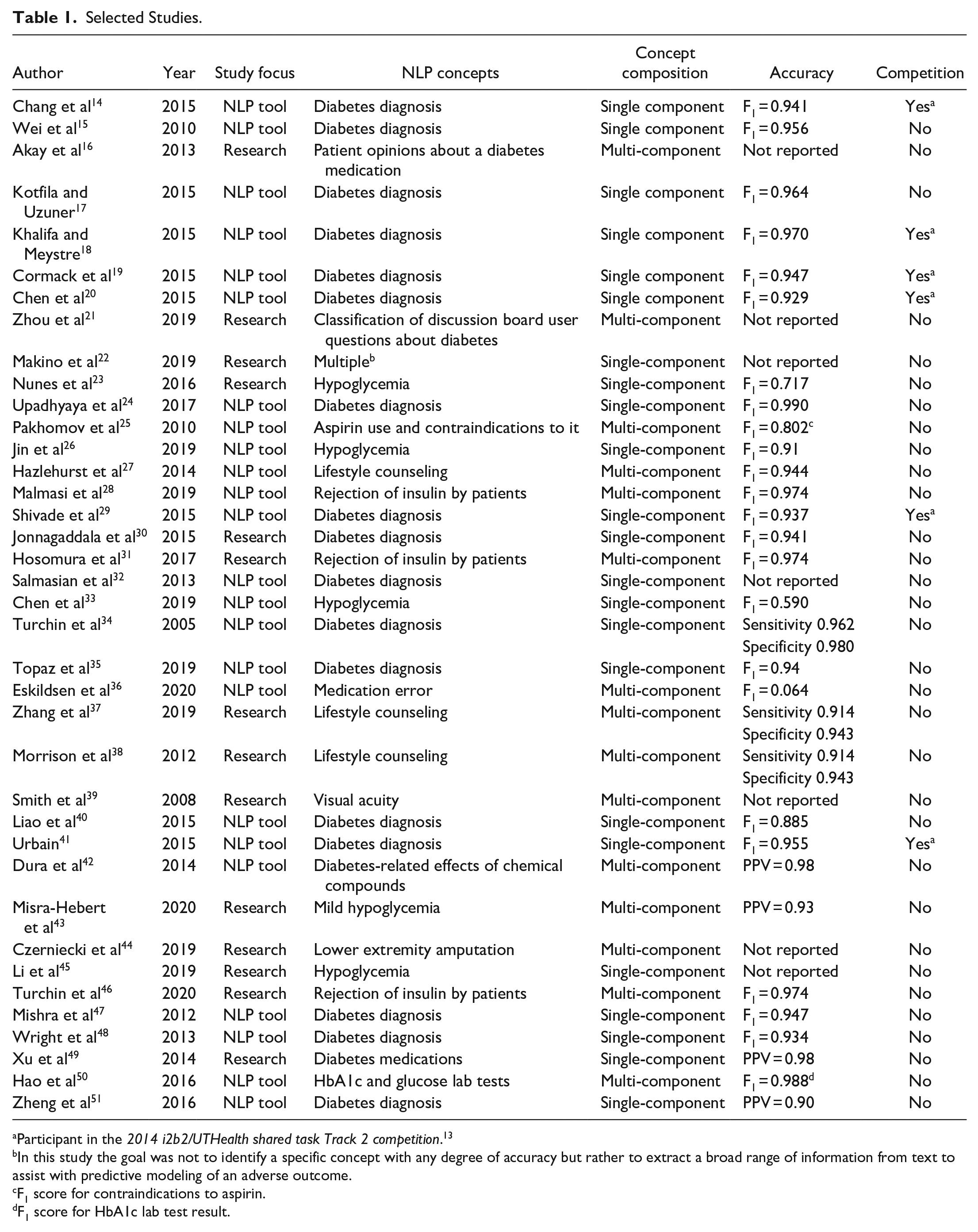
Participant in the 2014 i2b2/UTHealth shared task Track 2 competition. 13
In this study the goal was not to identify a specific concept with any degree of accuracy but rather to extract a broad range of information from text to assist with predictive modeling of an adverse outcome.
F1 score for contraindications to aspirin.
F1 score for HbA1c lab test result.
All studies that reported on development of NLP tools described the patient population used in the analysis in sufficient detail. Majority of studies (24; 63.2%) reported F1 scores as one of their measures of accuracy of natural language processing tools. The mean F1 score was 0.882. Studies that focused on identification of diagnosis of diabetes reported uniformly high accuracy, with 13 out 14 studies reporting F1 score >0.92; their overall mean F1 score was 0.945. By comparison, the remaining 10 studies that reported F1 scores had a broad range of F1 between 0.064 and 0.988 with the mean of 0.793. None of the studies that focused on identification of diagnosis of diabetes involved identification of clinically important diabetes characteristics, such as diabetes type (e.g. type 1 vs. type 2) or duration of diabetes. Within the second most common subject of study, hypoglycemia, F1 scores ranged from 0.59 to 0.91 with a mean of 0.739.
Out of 14 studies that used natural language processing tools for clinical research, five included only descriptive statistics, five tested a hypothesis and four developed a predictive model (Table 2). Of the four predictive modeling studies, only one reported any measure of accuracy of their natural language processing tool. All five hypothesis-testing studies and two out of four predictive modeling studies, but none of the five descriptive studies, had findings with potential implications for delivery of diabetes care.
Research Studies.
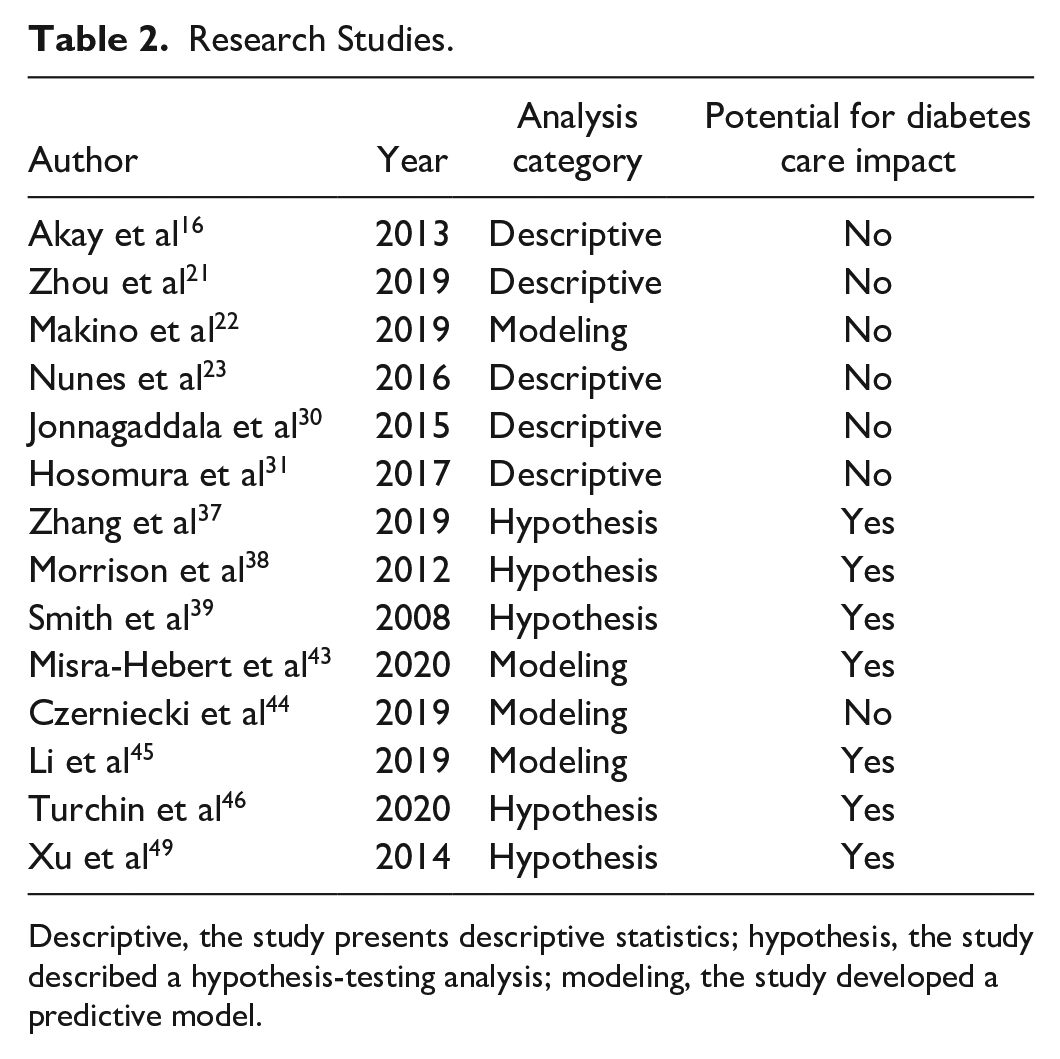
Descriptive, the study presents descriptive statistics; hypothesis, the study described a hypothesis-testing analysis; modeling, the study developed a predictive model.
Discussion
Applications of natural language processing in medicine have a long history, having started their development in 1990s.52-55 In this systematic review we found that natural language processing tools focused on diabetes are a relative newcomer to the field, with the first study appearing in 2005. 34 Nevertheless, the field has grown quickly and is now represented by several dozen studies, reviewed in this analysis.
On the other hand, while the number of applications of natural language processing in diabetes is growing quickly, their diversity is lagging behind. Nearly half of the applications we found focused on the same task: identification of documented diagnosis of diabetes. This is particularly surprising because patients with diabetes can be identified with a reasonable degree of accuracy using structured data, such as diagnoses, medications and laboratory test results.47,56 Furthermore, most studies in this area showed a similarly high level of accuracy, with almost all F1 scores above 0.9. It is therefore likely that return on further investment in this particular area will be low and researchers’ efforts would be more productively redirected elsewhere. While a number of clinically important characteristics of diabetes, such as diabetes type or duration, remain difficult to determine from structured electronic medical record data, these were not addressed by the studies we identified.
Hypoglycemia, on the other hand, is a good example of a clinically important event that is poorly documented in structured electronic data. 57 A high-fidelity natural language processing tool that could identify documentation of hypoglycemia in provider notes could do much to advance our understanding of its prevalence, risk factors and consequences. Unfortunately, the efforts to develop this tool appear to remain disparate and uncoordinated. Most natural language processing tools described in the studies have not been validated on external (to the institution/locale where they were originally developed) dataset or made available to the public (either through open-source or licensing). Lack of coordination and sharing of tools and resources needed for their development (e.g. annotated de-identified datasets) remains one of the major impediments to advancement of medical natural language processing as a field58,59—in contrast with non-medical natural processing, where such sharing is common.60-62
Majority of studies focused on relatively simple, single-component concepts (of which diagnosis of diabetes was the most common example). There were fewer studies that attempted identification of the more linguistically complex multi-component concepts, and their accuracy tended to be lower (mean F1 of 0.817 vs. 0.909 for single-component concept studies). Analyzing more complex multi-component concepts remains a challenge in the natural language processing field in general because neither of the two predominant approaches—machine-learning (statistical) models or grammar (rule-based) models—include a complete representation of the syntactic and semantic relationships that govern language. Technologies that do involve parsing sentence structure in an attempt to identify these relationships exist, but remain too computationally intensive for practical implementation on a large scale. New technological developments are therefore likely needed to achieve a qualitative improvement in natural language processing accuracy. It should also be noted that many texts (e.g. a punctuation-less sentence I have two hours to kill someone come see me), particularly so in medicine where many documents are not carefully proofread, may be ambiguous. As a result, even highly trained human annotators of medical texts do not usually reach a complete concordance, likely representing the upper bound of the possible accuracy of information extraction.63,64
Most articles described only development of diabetes natural language processing tools that did not appear to have been utilized for any practical purpose—whether direct patient care, population management or research. This was true even for the majority (16 out of 19/84.2%) of natural language processing tools that achieved high accuracy ratings with F1 ≥ 0.9 and were thus apparently ready for prime time. This could have several possible explanations. One is that the natural language processing tools that were developed were not made available to potential users. Another is that the natural language processing tools that were developed were not actually the ones that the users needed. Either way, greater collaboration and cooperation between developers and users of natural language processing tools is needed to ensure that resources being devoted to design and evaluation of this sophisticated technology are utilized most effectively for the benefit of patients and the public-at-large.
Among studies that utilized natural language processing tools for research, predictive modeling was a popular area of interest. Notably, many predictive modeling studies did not assess accuracy of their natural language processing tools. This could be because many predictive models that use data derived from natural language processing are not looking for a pre-specified set of variables. Instead, they use what could be described as a “generalized” natural language processing data collection, whereupon the model includes numerous—hundreds or even thousands of variables—that are derived from the data empirically rather than based on pre-existing evidence or expert opinion. These variables could be as simple as frequencies of unique words (often adjusted for how common they are in a particular document vs. the entire dataset). In that approach the accuracy of any given variable is less critical because mistakes in one variable can be compensated for by many others. Predictive modeling has the potential to significantly impact measurement and interventions to improve quality of diabetes care by helping define at-risk populations that would reap the greatest benefit from interventions. It is a very active area of research and natural language processing has the potential to significantly enhance its accuracy by allowing the models to incorporate information not found in other data sources.65-67
Finally, several studies of natural language processing in diabetes used the technology for “traditional” hypothesis-testing analyses. Several of these investigations were able to link information that was often only found in narrative data (e.g. visual acuity of counseling on lifestyle changes) to outcomes of significant importance to patients (quality of life, risk of malignancy and cardiovascular events). While observational in their nature and thus not able to definitively demonstrate a causal relationship, studies like these can serve to both generate hypotheses that can subsequently be tested in interventional clinical trials and help accumulate body of evidence in areas where clinical trials are not feasible or not likely to be conducted. Once sufficient evidence to support the relationship between the metric identified by natural language processing and diabetes care outcomes is accrued, the technology can then be used to measure quality of treatment of diabetes as delivered in real-world settings and target appropriate interventions, coming full circle to support improvement of outcomes for patients with diabetes.
The findings of the present study should be interpreted in the context of several limitations. Heterogeneity of the studies reviewed did not allow direct analytical comparison of methods or results. We were also not able to find a study that quantified the contribution of narrative vs. structured data in modern electronic health records, and specifically in the care of patients with diabetes.
Conclusion
In summary, natural language processing of data related to treatment and quality of diabetes is a blossoming field of research. It has already been used to power real-world evidence studies addressing a broad range of subjects in care and outcomes of diabetes. Further growth in this area would be aided by deeper collaboration between developers and end-users of natural language processing tools as well as by broader sharing of the tools themselves and related resources.
Supplemental Material
sj-docx-1-dst-10.1177_19322968211000831 – Supplemental material for Using Natural Language Processing to Measure and Improve Quality of Diabetes Care: A Systematic Review
Supplemental material, sj-docx-1-dst-10.1177_19322968211000831 for Using Natural Language Processing to Measure and Improve Quality of Diabetes Care: A Systematic Review by Alexander Turchin and Luisa F. Florez Builes in Journal of Diabetes Science and Technology
Supplemental Material
sj-docx-2-dst-10.1177_19322968211000831 – Supplemental material for Using Natural Language Processing to Measure and Improve Quality of Diabetes Care: A Systematic Review
Supplemental material, sj-docx-2-dst-10.1177_19322968211000831 for Using Natural Language Processing to Measure and Improve Quality of Diabetes Care: A Systematic Review by Alexander Turchin and Luisa F. Florez Builes in Journal of Diabetes Science and Technology
Footnotes
Abbreviation
NLP, natural language processing.
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Alexander Turchin: equity in Brio Systems; consulting fees from Proteomics International; research funding from Astra Zeneca, Edwards, Eli Lilly, Novo Nordisk, Pfizer and Sanofi.
Luisa F. Florez Builes: none.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Patient-Centered Outcomes Research Institute (ME-2019C1-15328, Turchin).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.