
Abstract
Audio classification tasks like speech recognition and acoustic scene analysis require substantial labeled data, which is expensive. This work explores active learning to reduce annotation costs for a sound classification problem with rare target classes where existing datasets are insufficient. A deep convolutional recurrent neural network extracts spectro-temporal features and makes predictions. An uncertainty sampling strategy queries the most uncertain samples for manual labeling by experts and non-experts. A new alternating confidence sampling strategy and two other certainty-based strategies are proposed and evaluated. Experiments show significantly higher accuracy than passive learning baselines with the same labeling budget. Active learning generalizes well in a qualitative analysis of 20,000 unlabeled recordings. Overall, active learning with a novel sampling strategy minimizes the need for expensive labeled data in audio classification, successfully leveraging unlabeled data to improve accuracy with minimal supervision.
Keywords
Introduction
Audio classification has become an indispensable technology empowering various modern applications including voice assistants, surveillance systems, and autonomous vehicles. Critical audio analysis tasks such as speech recognition, speaker identification, sound event detection, and acoustic scene classification all rely on the ability to accurately categorize audio signals. 1 The performance of these systems depends directly on the effectiveness of the underlying audio classification models.
In recent years, deep learning techniques have established themselves as the dominant approach for audio classification. Deep neural networks now consistently outperform classical machine learning models on nearly all major audio benchmarks. 2 However, a key limitation of deep learning is the massive labeled datasets required to reach peak generalization performance. For many audio domains, assembling such large labeled corpora is prohibitively expensive and time-consuming due to the need for manual human annotation. This severely restricts our ability to train deep audio classification models.
To address this limitation, active learning techniques have been proposed to achieve high accuracy with minimal labeling effort. Active learning aims to select the most informative examples from a pool of unlabeled instances to be manually annotated and added to the training set. By querying only, the most useful samples, active learning seeks to boost model performance with just a fraction of the labels needed for passive learning on the full dataset.
Prior audio-active learning approaches have employed classical machine learning pipelines with hand-engineered acoustic features and heuristics-based query strategies. However, these methods have inherent limitations in terms of model representation power, feature design, and the ability to effectively assess sample informativeness.
This paper proposes a new deep active learning framework to improve unlabeled audio classification by overcoming the limitations of prior work. Our approach uses a deep convolutional recurrent neural network (CRNN) to extract and classify high-level spectro-temporal audio features. 3 Uncertainty sampling based on the model's predictive entropy identifies the most informative instances for labeling.
Comprehensive experiments on speech recognition and acoustic scene classification tasks demonstrate that the proposed technique achieves significant improvements in accuracy over passive learning baselines under the same limited labeling budget. Our approach provides an efficient methodology to leverage unlabeled audio data to improve classification performance with minimal additional supervision. 4 The core ideas can be extended to enable deep active learning across a wide range of related audio analysis problems.
Sound classification is important for applications like noise monitoring, animal call classification, and music retrieval. Modern sound classification models use supervised learning, which requires large labeled datasets. Labeled audio data can be acquired through human annotation, but this is costly, especially for problems with idiosyncratic or unusual sound classes where existing data has little utility. 5 For such specialized classification tasks, new labeled data must be collected specifically for that problem, increasing the per-task annotation cost since the data has minimal reuse value across tasks.
Active learning is an approach in machine learning where the algorithm strategically chooses the most informative data points to be labeled by an oracle, usually a human annotator. This interaction allows the model to learn more from each labeled instance, greatly reducing the amount of annotated data needed to train an accurate classifier. Active learning has been successfully applied in domains like natural language processing and computer vision to minimize human effort. More recently, it has been used in audio tasks like sound classification and recognition.
Typically, active learning studies simulate the oracle by using existing labels. This work applies active learning in a real setting to train a binary classifier to detect a rare, application-specific sound. Multiple query strategies are evaluated, including a new alternating confidence sampling method proposed here. Using 20 human annotators to label useful instances, the resulting model achieves similar performance to a reference model with far fewer labeled examples. This demonstrates active learning can efficiently train specialized audio classifiers for unusual sounds using minimal human annotation effort6,7
Literature review
Active learning has been explored extensively for audio classification tasks to minimize labeling costs. Early work focused on leveraging traditional machine learning models with handcrafted audio features. Various query strategies were employed to select informative unlabeled instances for annotation. More recently, deep neural networks have been applied for audio-active learning. In this section, we review relevant prior art and discuss limitations addressed by our proposed approach.
Initial active learning studies on speech and audio problems used Gaussian mixture models and support vector machines with standard acoustic features like MFCCs.8,9 Query strategies were based on uncertainty sampling, querying samples closest to the decision boundary. While these methods outperformed passive learning, they were limited by the representation power of shallow models and hand-designed features.
More recent work has explored query strategies like diversity and density-based sampling to choose diverse, representative samples covering the feature space.10,11 However, defining appropriate diversity metrics and densities over high-dimensional audio features remains challenging. There is also limited consensus on the optimal query strategy for different audio tasks.
With the rise of deep learning, recent audio-active learning approaches have used CNNs and RNNs which learn robust high-level feature representations.12,13 However, most techniques still rely on uncertainty or random sampling heuristics for querying. Deep Bayesian Active Learning has also been proposed to formally model uncertainty 14 however such methods are difficult to scale to large datasets.
Our key observation is that existing audio-active learning methods are inherently limited by the use of shallow models, hand-engineered features, and heuristics-based query strategies. Our proposed approach aims to overcome these limitations by leveraging a deep convolutional recurrent neural network and predictive entropy-based uncertainty sampling. We demonstrate significant gains over passive learning on two audio classification benchmarks.
In summary, prior audio active learning has provided useful query strategies and showed promise with deep learning. However, our work is the first to combine the strengths of deep neural networks, spectro-temporal feature learning, and formal uncertainty sampling within a unified active learning framework tailored for audio. Our approach can serve as a foundation for further research into deep active learning techniques for audio analysis.
Proposed framework
In this section, we introduce our proposed deep active learning framework for audio classification. An overview of the core components is provided along with a discussion of the expected benefits compared to passive learning baselines.
This study employs a pool-based active learning strategy, involving the following steps: (1) Start by initializing the labeled training pool with one positive and one negative example. (2) Train a random forest classifier using the labeled pool. (3) Use the trained model to identify the most informative query from unlabeled data, using a certainty-based sampling strategy. (4) Have an annotator listen to and assign labels to the selected audio clip. (5) Incorporate the newly labeled clip into the training pool. (6) Iterate through steps 2 to 5, continuously querying labels for valuable instances to enhance the model, until the desired target performance is achieved.
This iterative process selectively obtains labels for informative samples to efficiently train the audio classification model
In the experiments, each model is trained for 200 iterations. A random forest classifier is used since it is robust for small datasets and can be rapidly updated with new labeled instances. At each iteration, only a single query is labeled by the annotator to minimize the human annotation effort required, as the goal is to reduce total labeling costs.
Pool-Based active learning
In pool-based active learning, there is an initial pool of unlabeled data, and samples are selectively chosen in successive rounds to be labeled by an oracle Figure 1. This approach applies to many real-world tasks like text, video, image, and speech classification, information retrieval, and information extraction. At each round, the most useful instances are identified from the pool using informativeness criteria. These are sent to the oracle for labeling, and the newly labeled samples are added to the training set to improve the model. This pool-based framework allows progressively building a labeled dataset by selectively requesting labels for the most valuable samples from a batch of unlabeled data. Pool-based active learning approach process.
The algorithm has five main components as shown in Figure 2: (1) Seed set - A small random subset of unlabeled data used for initial training. (2) Batch size (B) - The number of instances queried in each iteration. (3) Instances - Audio recordings represented as index vectors. (4) Stopping criterion - Condition that determines when to stop querying and training. (5) Query strategy (φ) - Method to estimate the informativeness of each unlabeled instance (UI) to select the most useful for labeling. Pool-based active learning algorithm process.

At each iteration, the query strategy identifies the top B most informative instances from the unlabeled pool U to query the oracle for labels. This iterative process continues until the stopping criterion is met.
15
L: the set of labeled instances U: the set of unlabeled instances φ (u¡): query strategy where u¡ E u B: number of instances to be selected at each iteration (batch size)
1- Select a seed set to form
2- Train a classifier on L 3- For all u¡ E u do: a.ϕ u¡ - ϕ (u¡) 4- For b = 1 to B do: a. ub = arg max uj Eu φ u¡ b. L = LU (ub, label (ub)) c. U = U-ub
Procedure
Repeat
Until the stopping criterion met
The most critical component of pool-based active learning is the query strategy, also known as the sampling criterion. This strategy selects which instances from the unlabeled pool should be queried for annotation at each iteration based on the informativeness of each instance - how useful labeling that instance is expected to be for improving the classifier's performance. 16 The goal is to query the most valuable instances to maximize the impact of each obtained label.
Active learning query strategies
The core of active learning is assessing the informativeness of unlabeled data and selecting samples to query based on this evaluation. There are various query strategies like certainty-based sampling, query-by-committee, expected error reduction, and medoid-based active learning. This study focuses on certainty-based strategies due to their direct relationship with prediction probabilities from the random forest model. Specifically, we comprehensively evaluate three certainty-based variations: least-confidence sampling, semi-supervised active learning, and alternating-confidence sampling. By examining these active learning techniques, our goal is to identify effective strategies for querying informative unlabeled instances, improving the random forest classifier. The objective is to systematically compare certainty-based sampling methods to determine optimal active learning query approaches for enhancing the random forest model's performance on unlabeled data.
Least-Confidence sampling
Least-confidence sampling (LC) is a commonly used active learning approach where the model selects the example it is least confident about labeling. For binary classification, LC is similar to other popular certainty-based methods like maximum entropy and smallest margin sampling. Least-confidence (LC) sampling is equivalent to selecting the sample with a predicted probability closest to the decision threshold (Td) in a random forest model.
We evaluate two LC sampling techniques that differ in how they determine Td: • Fixed threshold, where Td is fixed at 0.5. • Varied threshold, where Td is adjusted in each iteration to optimize validation performance.
The two techniques vary in how the decision threshold Td is set - either fixed at 0.5 or dynamically adjusted each iteration based on validation results. Both aim to pick samples with probabilities closest to the optimized threshold Td for querying. Although unrealistic, the varied threshold provides insight into whether the decision boundary impacts active learning performance. By analyzing LC sampling with fixed and varied thresholds, we aim to understand how the decision boundary affects certainty-based query strategies for active learning with random forests. This examination of LC sampling methods helps identify optimal certainty-based strategies to efficiently query informative examples and improve active learning for random forest classifiers.

Semi-Supervised active learning
Semi-supervised active learning (SSAL) combines active learning with semi-supervised learning (SSL). In SSAL, a model pre-trained on a small labeled dataset automatically annotates a larger unlabeled pool. We implement an SSAL approach similar to prior work. 21 The model updates twice per iteration - first with active learning, then SSL. In the active stage, the model performs standard active learning using least confidence sampling with a fixed threshold Td. In the SSL stage, the model predicts labels for the unlabeled pool. Predictions exceeding a confidence threshold TSSL are added to the labeled set for retraining. Since the model was biased towards confident negative predictions, we selected a balanced subset of positive and negative high-confidence labels.
SSAL incorporates SSL into active learning, by having the model automatically annotate high-confidence predictions from the unlabeled data pool to augment the actively queried samples. This allows leveraging both labeled and unlabeled data to improve the model. We evaluate two TSSL values: 0.95 and 0.98. By integrating LC active learning and semi-supervised label propagation, SSAL aims to maximize model improvement from both annotated and high-confidence predicted samples. The two-stage update allows active querying of uncertain instances along with semi-supervised utilization of the model's unambiguous predictions.
Alternating confidence sampling
Active learning with alternating confidence (AC) targets instances the model is least and most confident about to make active learning more robust to annotation errors. 22 Least confidence (LC) sampling only queries uncertain examples, making it difficult to correct errors if the model becomes overconfident on mislabeled data. To address this, AC also actively selects high-confidence instances that the model may be mistaken about. We implement AC by occasionally sampling from predictions exceeding a high confidence threshold THC = 0.85. Alternating-confidence sampling incorporates periodic high-confidence querying between standard active learning iterations. This allows annotators to catch and fix errors in high-confidence predictions during training. We test two frequencies for high-confidence querying: selecting one high-confidence sample (1) every five iterations, and (2) every 10 iterations. In all other iterations, standard active learning is performed using least confidence (LC) sampling with a fixed threshold Td.
Alternating-confidence sampling alternates between LC sampling and periodically querying high-confidence samples. This allows for correcting potential errors in high-confidence predictions while still focusing on uncertain instances. We evaluate two frequencies - high-confidence querying every five or 10 iterations - to test the impact of the high-confidence query rate.
By alternating between least confidence and high confidence querying, AC provides a balanced active learning approach to identify both informative uncertain instances and potential overconfident mistakes. This makes the iterative training process more robust to annotation errors.
Experiments and results
Utilized datasets
This section provides an in-depth examination of the datasets used in our experiments, including a detailed overview. It also elaborates on our experimental setup, including training parameters and the methodology used to evaluate the effectiveness of our classification models.
This section covers: • An in-depth look at the datasets utilized in our experiments • An overview of our experimental setup • Details on training parameters • The methodology used to assess the performance of our classification models.
The goal is to provide a comprehensive description of the datasets and experimental procedures, to facilitate understanding and reproducibility.
To build a robust classification model for detecting noise artifacts, we conducted experiments using the active learning (AL) framework described in Section 2. Section 4.2 provides a thorough evaluation of the AL query strategies introduced in Section 3, utilizing an annotator skilled at identifying the target sound.
Section 4.3 then compares the most effective AL approach to baseline methods, establishing benchmark performance.
Following this, Section 4.4 investigates whether models trained by non-expert annotators can achieve performance comparable to our expert-trained models.
We first assess different AL strategies using an expert annotator (Section 4.2), then compare the top AL method to baselines (Section 4.3), and finally examine if non-experts can produce models reaching expert-level performance (Section 4.4).
Concluding our experimentation, Section 4.5 undertakes a qualitative evaluation of the best AL-trained model on an unlabeled dataset, scrutinizing its generalization capability. In essence, our experiments systematically scrutinize AL sampling techniques, draw comparisons with baselines, investigate the impact of non-expert annotation, and assess the model's generalization—a comprehensive framework designed to develop an accurate and robust noise detection model through active learning.
Datasets description
We conduct extensive experiments to evaluate our proposed active learning approach on two audio classification tasks using standard datasets described below.
To enable active learning (AL), an unlabeled dataset is used as the sampling pool, while the reference baseline utilizes a labeled dataset. The labeled data has 1000 balanced 1 s audio clips from 20 sensors. 23 These are split into training, validation, and test sets in a 6:2:2 ratio for 6-fold cross-validation. For AL, the initial training data per fold is two random clips (1 positive, one negative) to demonstrate performance trends.
The unlabeled pool contains 100,000 random 1 s clips from the remaining sensors. Input features for both datasets are extracted using a pre-trained vggish neural network model 24 originally trained on YouTube-8M data, generating a 64-dimensional embedding.
Each experiment undergoes 6-fold cross-validation, with model performance estimated using F-measure. During training, the random forest threshold is tuned on the validation set, with test performance reported. This methodology ensures robust evaluation to develop an effective noise detection model.
AL uses an unlabeled pool while baselines use labeled data. Input features are extracted using a pre-trained vggish neural network model. Performance is evaluated via 6-fold cross-validation and optimized on the validation set. This provides a robust assessment to build an accurate noise detector.
Evaluating different query strategies
To evaluate different query strategies over iterations, individual models were trained for each strategy using the framework in Section 2. The table shows the mean and max F-measure, and the iteration with peak performance within 100 training iterations per model.
First, LC sampling with fixed versus varied Td was compared. The results (rows 1-2) indicate that fixed Td gives better model performance. Varied Td tends to bias queries toward negatives, causing overconfidence and class imbalance. Fixing Td at 0.5 encourages more balanced query sampling.
Next, SSAL with two TSSL values was compared. The results (middle rows) suggest adding an (SSL) stage does not improve performance here. Though higher TSSL shows better results, excessively high values make SSL equivalent to standard AL due to low-confidence positive predictions during testing. Careful TSSL tuning is essential with minimal labeled data.
Finally, AC with different high-confidence sampling frequencies was explored. The findings show sampling one high-confidence instance every 15 iterations achieves better performance than every 6. Sampling every 15 iterations balances error correction and information per label, enabling more effective learning.
Fixed Td outperforms varied, SSAL does not help here, and AC sampling high-confidence instances every 15 iterations is most effective.
The optimal performance was with the AC strategy sampling high-confidence instances at 1/15 frequency. This certainty-based approach allows annotators to correct model mistakes, improving generalization. This top alternating confidence AC strategy is used to train AL models in all remaining experiments.
Comparison of Query Strategies: - Least confidence (LC) sampling with fixed threshold Td achieved the best mean F-measure of 0.904 and maximum F-measure of 0.947, peaking at iteration 77. - LC sampling with varied Td attained lower mean and max F-measures of 0.891 and 0.924, peaking at iteration 86. - Semi-supervised active learning (SSAL) with a high TSSL of 0.95 showed poorer performance, with a mean 0.857 and max 0.910 at iteration 24. - SSAL with TSSL 0.98 demonstrated improved mean 0.892 and max 0.928 at iteration 56, but still below LC. - Alternating confidence (AC) sampling every five iterations achieved a mean of 0.897 and a max of 0.939 at iteration 48. - AC sampling every 10 iterations performed best overall with mean 0.913 and max 0.962 at iteration 90.
In summary, the AC strategy with a high-confidence instance sampling frequency of 1/10 demonstrates the best overall performance, achieving a mean F-measure of 0.913 and a maximum F-measure of 0.962 at iteration 90.
Contrasting active learning with traditional methods
We compare active learning (AL) with two traditional methods:
Random sampling within the AL framework, using two initial examples and 200 training iterations. Here, the query is randomly selected from the unlabeled pool for each iteration, unlike the certainty-based sampling in AL.
A reference model trained on the full labeled dataset, following the same cross-validation to show optimal performance with 700 labeled examples.
Figure 3 shows the model performance per iteration. The AL model with an expert annotator consistently exceeds random sampling, quickly reaching comparable performance to the reference model after 60 iterations. Illustrates the performance of the model at each training iteration, showcasing variations across different training methods.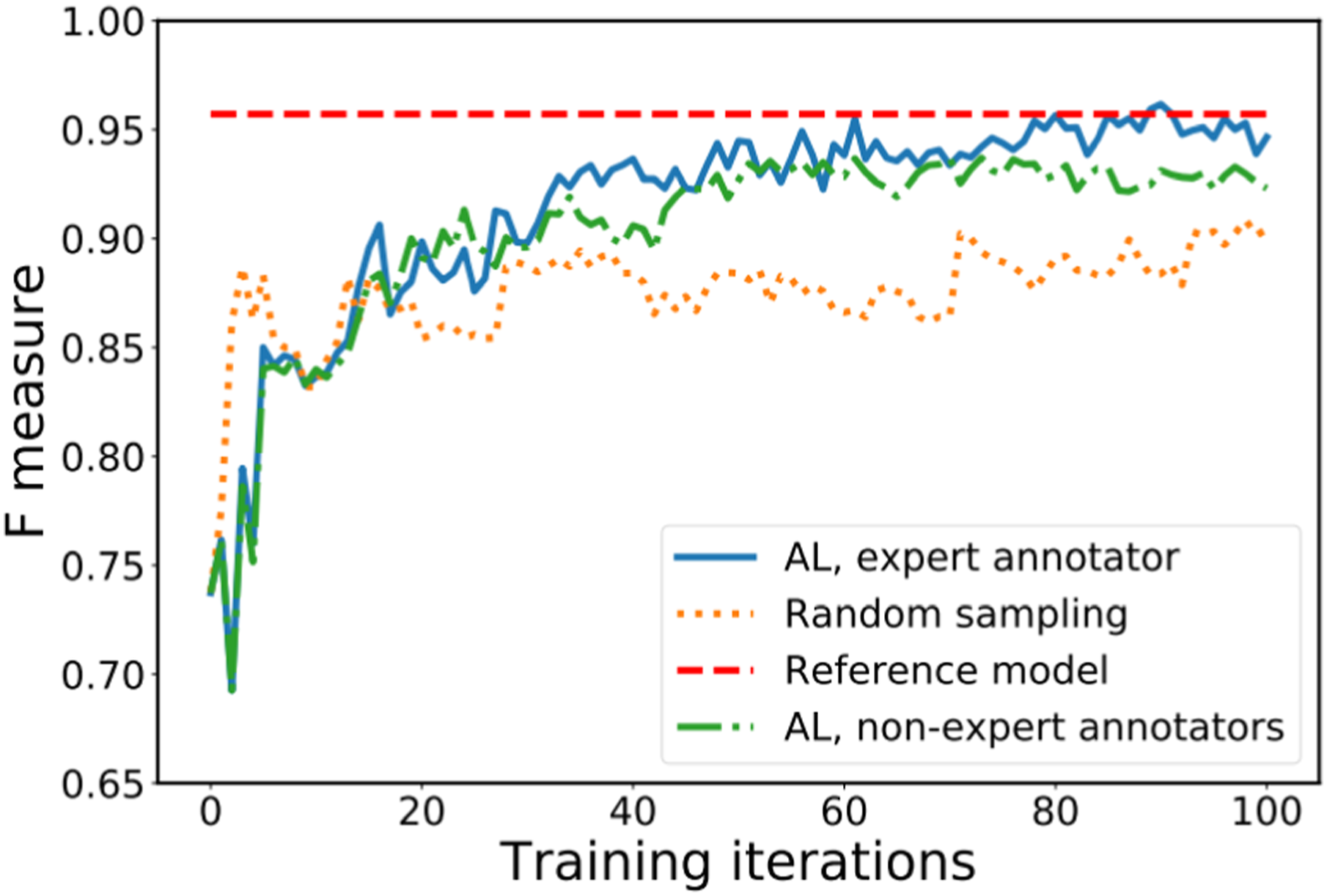
The mean and maximum F-measures within 200 iterations, and the iteration of peak performance. Remarkably, the AL model reaches peak performance at iteration 90, meaning it is effectively trained on just 92 labeled examples, including the initial two. Despite far fewer labels than the reference model, AL efficiently leverages the unlabeled data for more effective training.
AL also results in a more balanced query distribution than random sampling. This equilibrium enhances efficiency and develops a more robust model.
AL with an expert annotator substantially outperforms random sampling and achieves comparable performance to the full labeled dataset using far fewer labeled examples. - For the training method involving expert annotators in Active Learning (AL), the mean value is 0.913, the maximum iteration is 90, and there are 42% positive queries. - In the case of Random Sampling, the mean value is 0.875, the maximum iteration is 98, and only 3% of queries are positive. - The Reference Model has a mean value of 0.957, and a maximum iteration value of 0.957, and the information about positive queries is not available. - When utilizing non-expert annotators in Active Learning, the mean value is 0.903, the maximum iteration is 73, and 43% of queries are positive.
Comparative analysis of model performance: expert versus non-expert annotators
To investigate if models trained by non-experts can achieve similar performance to expert-trained models, we engaged 20 non-expert annotators. Each annotator was labeled one-fold, resulting in three annotations per fold and 15 models total (3 per fold across five folds). The optimal threshold at each iteration was determined based on the best mean F-measure across all 15 non-expert models. In summary, 20 non-experts were recruited to annotate the data, with each annotating one-fold. This resulted in 15 models total, with three non-expert models per fold. The threshold was optimized based on the mean performance across all non-expert models, to evaluate if non-experts can attain comparable performance to expert-trained models. Figure 3 shows similar performance trends between models trained by experts and non-experts. Although non-expert models do not reach the reference performance of expert-trained ones, they consistently outperform the random model trained by experts. Additionally, the table shows the average percentage of positive queries from Active Learning during 100 iterations, exhibiting a similar trend to expert annotators. While non-experts do not match experts, Active Learning still provides meaningful improvements with non-expert annotators.25,26
Assessment of the quality of unlabeled data
To evaluate the adaptability of our most effective noise classifier trained with Active Learning (AL), we applied it to unlabeled, unseen data to predict labels. Since ground truth was unavailable, we used t-SNE
27
for visualization in Figure 4(a) to (c). In each plot, t-SNE projected 20,000 unlabeled points into 2D space using vggish neural network features as input with perplexity 30. The point color indicates the predicted label - orange as positive, green as negative. Figure 4(a) to (c) show predictions at iterations 1, 20, and 100. The label distribution evolves over iterations, with positive predictions converging into clusters. Depicts the progression of forecasted labels across training iterations 1, 20, and 100 through t-SNE plots (a)-(c), where orange denotes predicted positive labels and green signifies predicted negative labels. Additionally, spectrograms (d)-(f) showcase power spectrogram instances from chosen excerpts within regions A, B, and (c)
For qualitative assessment, we listened to 15 randomly selected clips from the highlighted regions in Figure 4(c). Corresponding spectrograms from one clip per region are shown in Figure 4(d) to (f). Clips from regions A and B contain the target noise, very noticeable in 2(d) and softer amid other sounds in 2(e). Clips in region C lack the noise, having similar environmental sounds without the harmonic pattern in 2(f), explaining false positives early in training. This demonstrates the model's learning and refinement during AL. It also shows the active learning-trained classifier can generalize to unseen data, effectively identifying the target noise in varying contexts, enabling exploration in the UST-V2 dataset.
Conclusion and future work
In our study, we introduced an innovative deep active learning framework designed to improve the performance of audio classification by effectively utilizing unlabeled data. Below, we provide a summary of the key findings, limitations, and future research directions.
We presented a deep active learning approach that incorporates convolutional recurrent neural networks (CRNNs) and uncertainty sampling to enhance the classification of unlabeled audio data. Through extensive experiments on tasks such as speech recognition and acoustic scene analysis, we observed significant improvements in accuracy when compared to passive learning baselines with the same labeling budgets.
Our proposed technique offers an efficient way to achieve high accuracy with minimal human annotation by selectively querying the most informative samples. The use of deep CRNNs and uncertainty sampling outperformed standard classifiers and random sampling.
We employed active learning to tackle the challenges of annotating a specialized sound classification task, where utilizing existing datasets was impractical. Using a pool-based active learning framework with human annotators, we introduced an innovative certainty-based query strategy known as alternating confidence sampling.
This approach showcased enhanced model performance compared to two other certainty-based strategies, allowing annotators to rectify errors by intermittently selecting high-confidence instances. Models trained using this strategy surpassed a baseline model employing random sampling, achieving performance levels comparable to the reference model with a significantly reduced number of labeled examples. Through the application of active learning, our artifact noise classifier achieved an F-measure of 0.962 after only 92 labeled examples.
Furthermore, we evaluated our sampling strategy with 20 non-expert annotators and observed similar performance to a model trained by an expert. Qualitative evaluation showcased the classifier's ability to generalize to unseen data, accurately identifying target noise in different contexts. This study emphasizes how active learning can enhance efficiency and substantially reduce annotation effort in real-world scenarios. Future work will include a quantitative analysis of alternating confidence sampling and exploration of additional strategies with non-experts. We hope our research motivates others to leverage active learning for developing datasets in complex, resource-intensive audio tasks, representing a promising paradigm for future applications and research in this domain.
The deep active learning framework proposed can benefit various companies, industries and academic researchers working with specialized audio classification tasks involving unusual, idiosyncratic or niche sounds. For example, wildlife conservation groups seeking to detect rare animal vocalizations, smart home assistants or IoT devices targeting recognition of niche custom commands, linguists studying dialectical variations in speech, and sound designers working with unique Foley sound libraries can all leverage our approach to minimize annotation costs. Additionally, our methodology has important academic implications - it provides a blueprint for researchers across audio domains like bioacoustics, surveillance systems, autonomous vehicle perception, music information retrieval etc. To synergistically combine active learning with deep neural network pipelines to maximize efficiency. The core technical ideas can be adapted to minimize labeling costs when developing datasets for specialized audio classification research problems with limited available training data. Overall, this work opens up a promising new paradigm for efficiently advancing audio-based AI research as well as building real-world applications targeting unusual acoustic inputs, via actively learning enhanced deep neural network classifiers.
While we have demonstrated the effectiveness of our deep active learning approach, there remain some limitations to be considered. Firstly, our experiments were focused on speech recognition and acoustic scene classification tasks on standard datasets. Further evaluation on a wider range of niche, real-world audio problems could provide greater insight. Additionally, factors like diversity in sampling pool composition and annotator expertise could influence performance - studying these effects more rigorously can help optimize the approach. We also relied mainly on certainty-based sampling strategies due to their compatibility with our model - comparing many other query strategies was outside the scope. Finally, computational complexity and training times for deep neural models remains a practical challenge - exploring efficiency enhancements would enable easier adoption. We aim to address these limitations through extended experiments and model optimizations in future work, while also applying our approach to tackle more specialized audio classification problems facing constraints in acquiring labeled training data. Nevertheless, our proposed methodology represents an important first step in enabling deep active learning for efficient audio data annotation.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.