
Abstract
An approach to the design of learning environments where a social robot plays a role of a teacher is discussed in this study. Built-in robot functionalities provide a degree of situational embodiment, self-explainability, and context-driven interaction. The concept of embodiment enables immersion of the teacher into distant 3D environments. In that way the level of mutual understanding between participants is increased compared to a 2D world. Moreover, the tools that accompany the interaction empower augmentation by revealing the additional information present in gestures, facial expressions, or gaze direction. We use three distinct sources fused in a multimodal approach (face emotion recognition, level of loudness, and body movement intensity). The change in one modality can change the overall system reasoning. The teacher can benefit from this information by adapting a presentation style and achieve a better rapport with students. The theoretical basis is provided by studies of human communication in psycholinguistics and social psychology. Usability evaluation is based on the Wizard of Oz approach, allowing a teacher to interact with students through an interface. The conducted experiments show encouraging responses. Future studies will show in what way and to what extent a cognitive robot can be truly effective in technology-enhanced learning.
Introduction
In this study we proposed an approach where a social robot head called PLEA has the role of a teaching assistant to facilitate student–teacher interaction in higher education settings.
The problems associated with smart system control are recognized as being the most important open problems in the field of robotics. These problems are even more emphasized in Human–Robot Interaction (HRI), especially when a person needs to establish a certain level of interaction with the robot. In that case, such a robot could be autonomous or could be controlled remotely. Natural interaction is also highly contextual where participants analyze different inputs like previously memorized or currently sensed information, twisted or guessed facts, and so on. It is very challenging to design an autonomous conversational robot that works in real-world settings. We therefore employ the Wizard of Oz (WoO) approach (Riek, 2012), in which humans simulate the robot’s actions without the participant’s awareness. The social robot is used here just as a medium or interface that connects the teacher and learner. There are not many examples reported in the state-of-the-art where the robot is used in a similar way. For example, Höysniemi et al. (2004) argue that the “wizard” as a human experimenter simulates the behavior of an intelligent software application. In the application described in this work students often believe that they interact with an autonomous robot because the teacher is positioned outside the room.
The person who is interacting often does not know whether she or he is interacting with a software agent or a real person. Similar applications can be found in the HRI interfaces domain (Schieben et al., 2009). Some of them include human participants, for example, in maintaining high cognitive activities in the mental health of an elderly population (Solano et al., 2019).
As communication is essential in the service of performing common tasks, there is a wide variety of conversational modalities that can be used in a theoretical framework. The teacher can also benefit from feedback enabled in the technology-supported interaction based on information acquired, contextualized, and visualized using multimodal information fusion techniques. The presented work features couple techniques to support a context-driven and intuitive robot interaction.
Research background
The focus of this work is on the communicative effect of “implicit communications” that are nonverbal, such as gestures, facial expressions, gaze directions, attention, configuration of participants in shared space, and so on. Various studies emphasize the importance of nonverbal communication, especially in learning. Sutiyatno (2018) reported a significant positive effect on students’ achievement during English class. That study confirmed the direct effects on the students’ attitude toward the teacher, the course, and the students’ willingness to learn based on positive nonverbal cues. Hofert et al. (2015) reported the richness of nonverbal rules in communication and how those rules can differ depending on the current situation and characteristics of the people who use them. Nonverbal communication can often be in opposition to verbal. The same research has shown that people trust nonverbal messages more. Zeki (2009) also reported examining students’ perceptions about nonverbal communication in class focusing on eye contact, mimics, and gestures. The students were assigned to write a “critical moments reflection” report on any of the incidents that they considered to be critical. The findings revealed that nonverbal communication is an important source of motivation and concentration for students’ learning as well as a tool for taking and maintaining attention.
In studies of interaction, nonverbal communication is defined as facilitative feedback that participants provide while creating the common ground (Clark & Brennan, 1991; Clark & Schaefer, 1989; Nathan, Alibali, & Church, 2017; Tan, 2018). Originally, the concept of the common ground refers to a shared pool of knowledge that underpins human conversations. The common ground approach considers a conversation as the joint action by a group of people acting in coordination with each other. They jointly create a mutual understanding in order to work together more effectively. Recent studies, particularly in education, have adapted social psychology methods, including the Common Ground approach to computer-mediated interaction in learning situations (Chi & Wylie, 2014; Jonassen & Kwon, 2001).
The initial hypothesis was to support natural interactions in the learning context, where students and teachers together build a shared environment where they cooperate to carry out their learning/teaching tasks. They coordinate actions and focus on common artifacts (for example documents, drawings, or a computer screen) in the process of negotiating the meanings of words or images presented there (Robinson, 1993). Within the boundaries of the common ground, the participants can identify the objects referred to, come to understand each other’s goals and purposes, and cooperate and coordinate their actions. Indeed, common ground is regarded as fundamental to all coordination activities and to collaboration (Clark & Brennan, 1991). In this context, one of the key research questions was “How do people create the common ground in situations where the contact between them is influenced or mediated by technology?” (Greenberg, Rice, & Elliott, 1993; Krawczak, 2011). The used interactive technology is expected to facilitate the processes that shapes human cognition and communication in significant social and cultural contexts, thus fitting in with normal human activities. More specifically, in this work, a social robot is regarded as an integral part of the entire learning environment created by the interaction of people, learning environments, and artifacts where information is generated, exchanged, stored, processed, internalized, and externalized.
Nonverbal, implicit communication has been extensively analyzed as a ‘frame attunement’ activity of conversation participants (Kendon, 1985). We introduced here the frame attunement to the study of human–robot interaction, to develop a multidisciplinary theoretical framework and analytical method that will inform the design of technology-enhanced learning environments. More recent work includes linguistic expression of opinion and emotion with special emphasis on research methodology inspired by multidisciplinary influences (Bednarek, 2008; Greenberg, Rice, & Elliott, 1993; Krawczak, 2011).
An overview of human–robot interactive communication is provided by (Mavridis, 2015), covering its verbal and nonverbal aspects. That work presented the state-of-the-art in the field and explains the motivation of using nonverbal communication clues in HRI. Authors emphasized advancements that such technology can bring, including advanced cooperation for nonexpert users, maximized communication effectiveness, quick and effective application, and so on. Nonverbal signals, facilitative feedback, and implicit communication are regarded as important sources of information about participants in a particular communicative situation. Therefore, the initial motivation and objectives of this work were to contribute to:
knowledge of how people achieve mutual understanding through interaction with one another, understanding of interaction in a learning environment involving conversations mediated by a social robot, and design of a learning environment that supports communication in physical, mediated, and hybrid settings.
Research approach
The discussion in this article is directed toward focusing on the concept of the common ground and the role it can play in providing an analytical foundation for the study of interaction to simulate learning in a tutorial. Traditionally, the emphasis is on language use, but the “common ground” framework in this work aims to consider individual and social aspects of interaction in multimodal learning settings. Nonverbal communication is here very important because the overall analysis is performed to extract emotional cues from the student’s side. These findings are then used to provide additional information to the teacher so that she or he can timely direct the style and/or content of the presentation.
We introduced a context-driven approach to derive interacting and reasoning capabilities where the robot is immersed in the environment. Such processes are integrated into social interaction to support learning in a seamless, ubiquitous, and pervasive way. Built-in functionalities of the robot make use of state-of-the-art methods and strategies from artificial intelligence (AI) and HRI. These functionalities can provide a degree of situational embodiment, self-explainability, and context-driven interaction in order to increase interactivity, as explained in Jerbic et al., 2015 and Stipancic et al., 2013. Figure 1 depicts the WoO scenario where the teacher is presenting content using the robot as an interface.
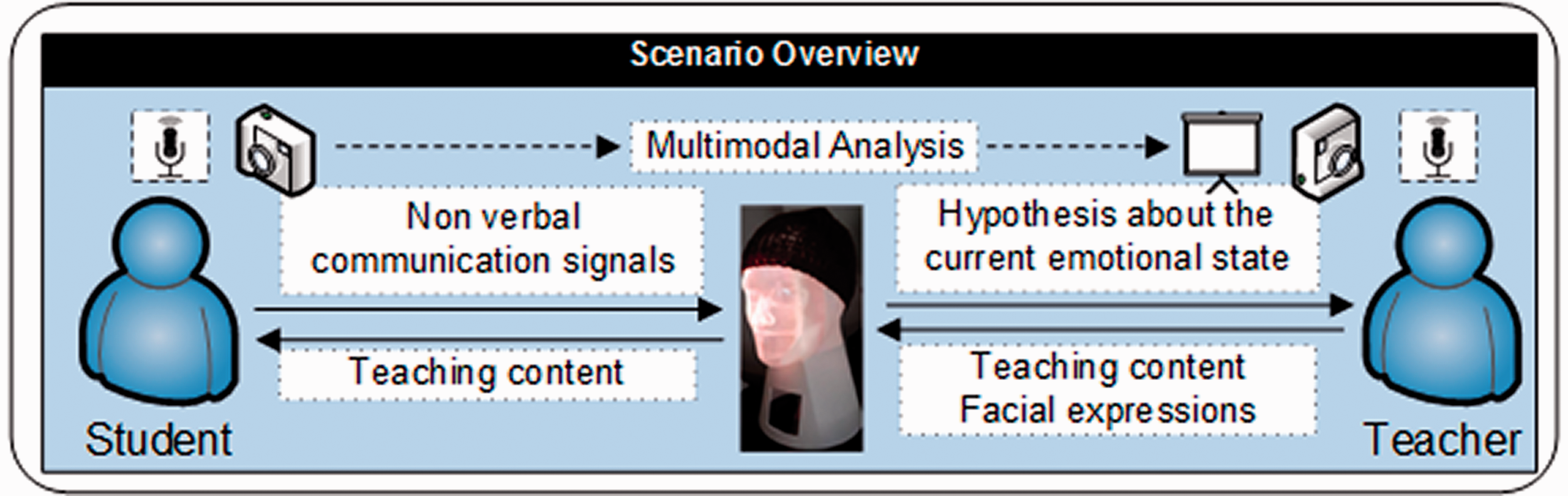
Wizard of Oz scenario overview in which the robot is used as an interface between the student and teacher. The presented scenario is enriched with additional information acquired by sensors placed within environments on both sides.
According to Kendon (1985), body language involves different nonverbal indicators such as facial expressions, the intensity of the body movements, eye movements, touch, and the use of personal space. The intensity of environmental loudness can also be a significant indicator of the nature of some particular communicative situation. For the purpose of this study, three distinct sources of social signals are used, including: (1) face emotion recognition, (2) level of loudness in the interaction space, and (3) intensity of body movements.
The methodology relies on cameras and microphones placed seamlessly into the environment to collect raw data representing the first step in achieving a contextual perception. Based on these signals, the system can generate hypotheses about the current emotional states of the participants, in particular, students whose facilitative feedback provides additional information to the teacher. The teacher then uses this information to adjust the presentation style in order to achieve better rapport. This is a normal part of face-to-face teaching practice as it shapes and contextualizes the creation of mutual understanding (Chi & Wylie, 2014). In technology-enhanced learning settings, however, this has proved to be difficult to accomplish (Cornelius & Boos, 2003). The use of the social robot in this context is expected to contribute to technology-enhanced learning by improving student–teacher interaction and rapport.
Physical robot design
The head of the robot is carefully designed to be realistic and expressive in order to reflect a high level of physical embodiment. The final goal of such a design is to support the grounding process between the robot and the learner.
The images in Figure 2 represent four stages of the robot head development: (1) head design stage, (2) stage where a flat projection surface is used, (3) stage where a 3D-shaped projection surface is used, (4) 3D CAD model of the head, and (5) final stage where the robot head is finished. Flat projection surfaces show deficit in information visualization because they suffer from a Mona Lisa effect (Boyarskaya et al., 2015). In this phenomenon, the eyes in a portrait often seem to follow observers as they pass. The 3D realization of the head corrected this issue where the gaze direction can now be used to establish more realistic eye contact between the robot and the learner. The last image shows the final realization of the head where the face is now projected onto the curved surface by a light projector. The projector is physically positioned at the bottom of the head, inside the neck part of the robot (as shown in Figure 3).

The robot head development process. At the beginning of the design process, a flat projection surface is used. The 3D surface is used at the end of the development process to overcome the Mona Lisa effect in which the eyes in a portrait often seem to follow observers as they pass.
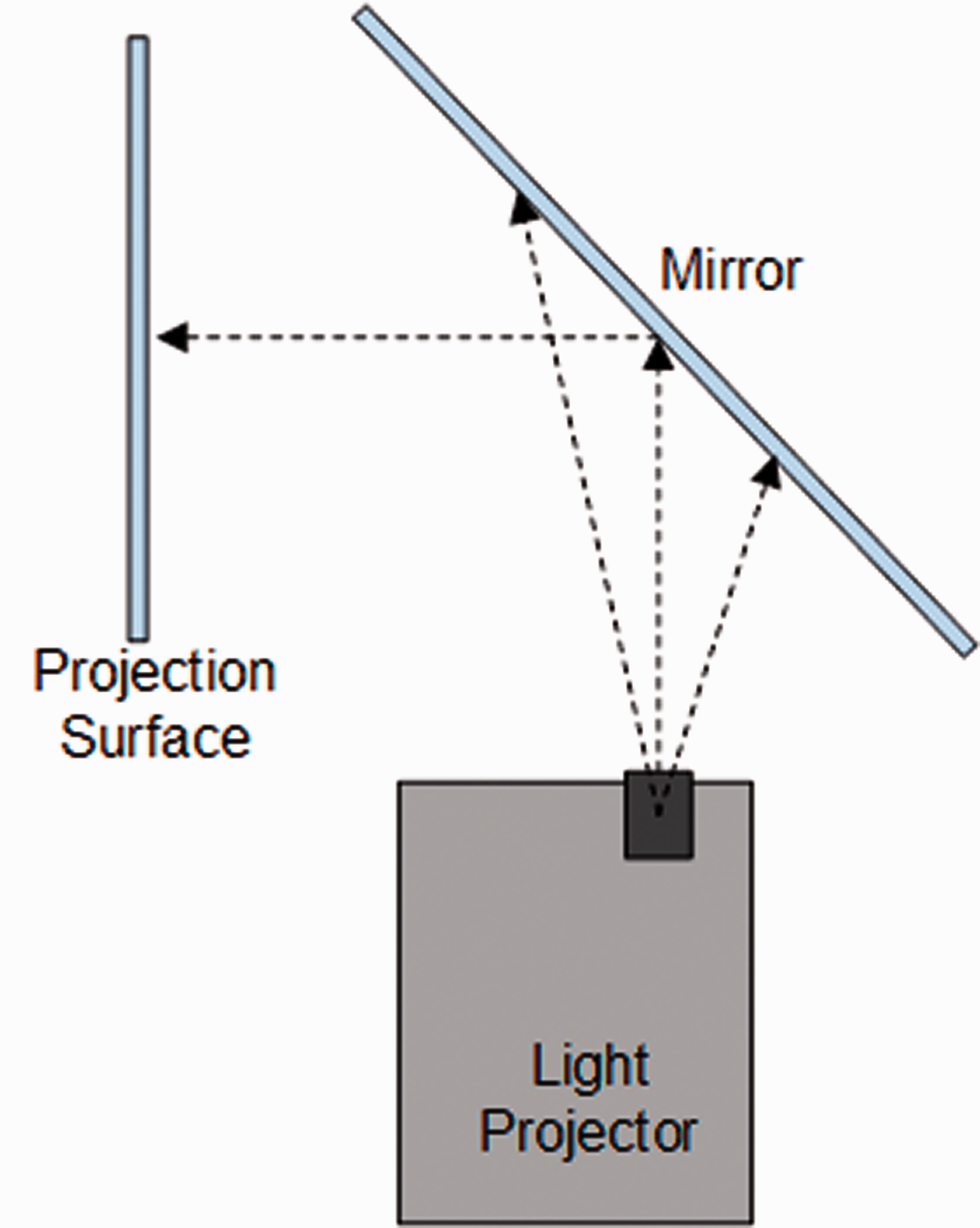
Light projection solution in which the overall projection mechanism is integrated within the robot head.
The light is projected onto the mirror fixed at the angle of about 45 degrees inside the head. The reflection of the mirror is then projected onto the front face surface. This design of the head is not completely original, and a comparable concept, but with a different realization, is the FURHAT robot developed at KTH, Stockholm (Al Moubayed et al., 2012). The main difference between those two systems is in the software architecture design. While the FURHAT robot focuses on strong Natural Language Processing, the PLEA robot is relying on the WoO approach and multimodal interaction that encompassed nonverbal social signals.
Software system architecture
A dedicated PC is controlling two interfaces, one used by the teacher and the other one used by the student. Figure 4 shows the overview of the software architecture used to control the functionalities of the robot.

Overview of the software architecture that integrates teacher and student interfaces. Abbreviations: AU—Action Unit, FACS—Facial Action Coding System.
As a source of social signals, emotions also play an important role in communication (Stipancic et al., 2017; Greenberg, Rice, & Elliott, 1993; Barrett, 2017). Knowledge about the emotional state of some person is used here to alter the level of a person’s attunement to a particular communicative situation.
Teacher interface is used to ensure a real-time face-mimicking system capability. In social interaction, mimicry is the behavior of aligning the postures, facial expressions, mannerisms, and other verbal and nonverbal communication signals of the other party in a conversation (Chartrand & Bargh, 1999). It is one of the most natural forms of human response and can be associated with the behavior of a small baby while mimicking the facial or body expressions of other people. Although some studies question this view (Oostenbroek et al., 2016), our research started from these initial assumptions. A corresponding point-matching and alignment procedure is achieved between the teacher and virtual agent (VA). This methodology relies on the Facial Action Coding System (FACS) originally proposed in by Ekman and Friesen (1978) and the OpenFace module (Baltrusaitis et al., 2018) used to determine the points of interest on the face (Baltrusaitis, 2018). FACS is an anatomically based system for describing facial movements. It breaks down facial expressions into individual components of muscle movement, called action units (AUs). The Convolutional Neural Network (CNN) learns how to map the corresponding points between FACS and points of interest determined by the OpenFace module, similar to that proposed by Van der Struijk et al. (2018). In this way, the student is able to see the animated avatar shown on a semi-transparent surface representing the face of the robot. Images of the teacher’s face are synchronized in real time with movements of the avatar’s face representation. By presenting the teaching materials to the student, the teacher is transferring not only the sound of the voice but also emotions and other nonverbal signals.
The number of images used in training, evaluation, and testing procedures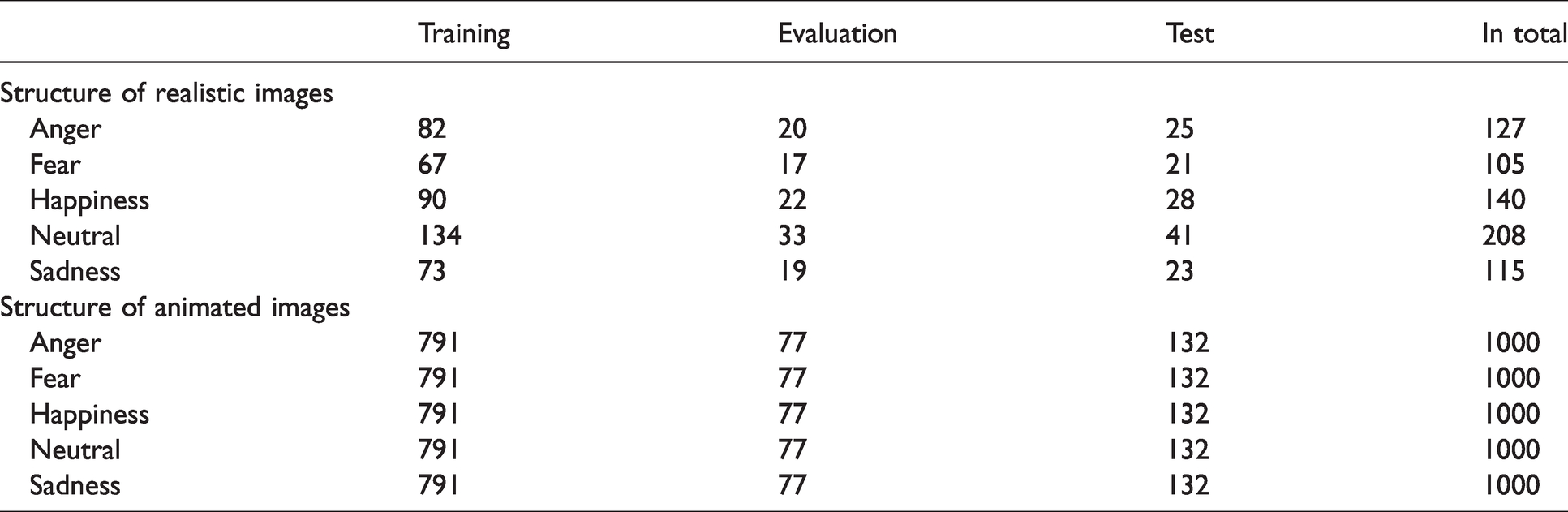
Angry emotion table. The similar procedure is derived for each emotion during the training procedure.
Accuracy graph describes the network performances during the network training in relation to three different data sets.
To additionally evaluate CNN performances, we used a graphical representation method, known as a confusion matrix (Deng et al., 2016). A confusion matrix is a tool of Machine Learning for analyzing classification problems. This method can help in the assessment of classification procedures in problems of distinguishing different classes. In this work, we used five basic emotions represented as five classes (as illustrated in Figure 7). While the x-axis of the matrix is representing predicted classes, the y-axis is used for the original ones. In this way, it is possible to evaluate how well the network can predict solutions and find out if there is some overlapping between classes. The diagonal of the matrix contains numbers that represent correct predictions. For example, a “happy face” is 28 times correctly predicted as “happy.” At the same time, “sad face” is four times incorrectly classified as “angry.” In this way, it is possible to point out some problems in the work of the network (e.g., wrong assumptions), which are partially revealed previously within the accuracy graph.
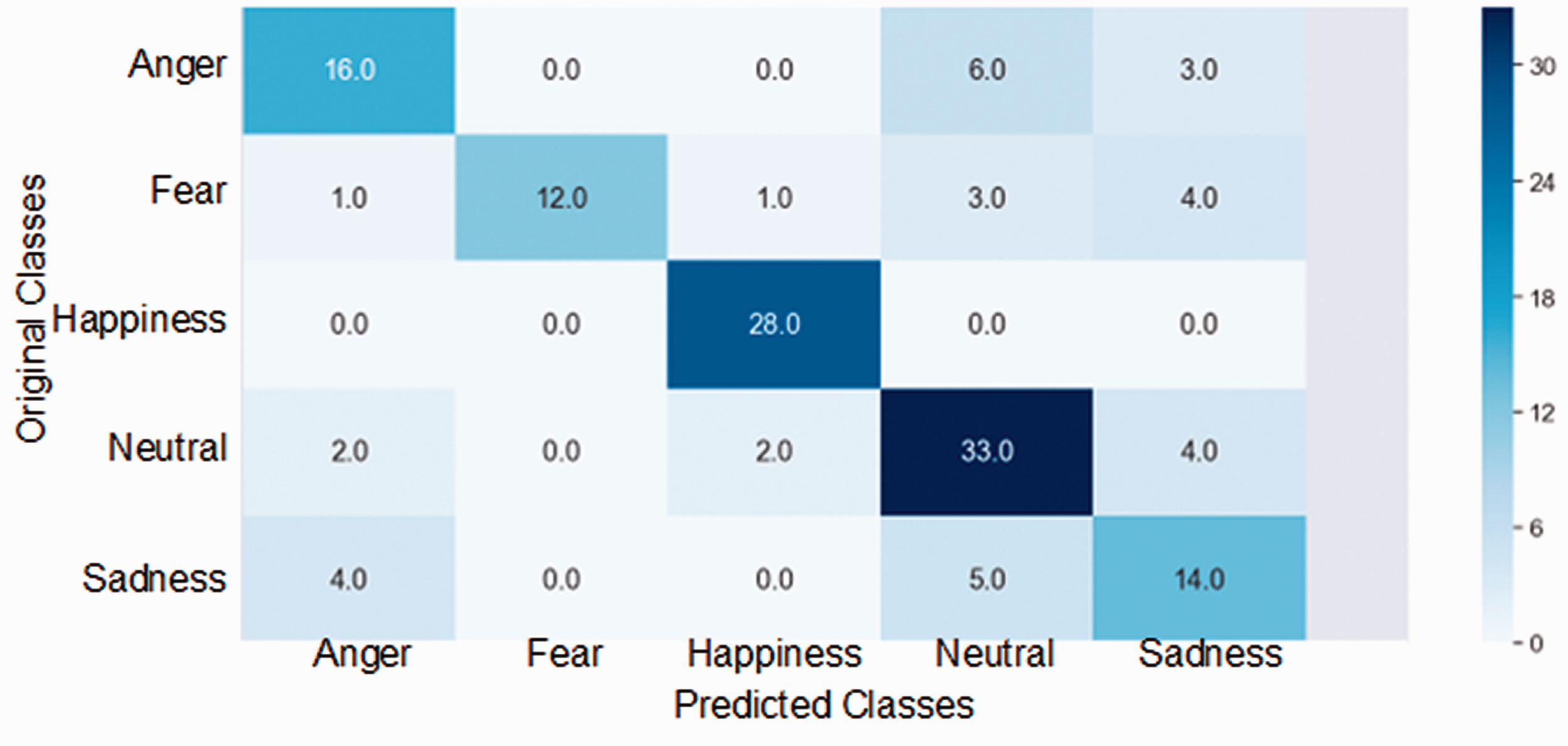
Confusion matrix is used to reveal the possible classification mistakes of the network.
Several directions are indicating how the overall performance of the network could be improved. For example, one direction is to provide more images showing the faces of real people for the training to increase the accuracy of the network prediction. This direction is often time-consuming and tedious to perform. Within the other approach, which is used in this work, we employed two more sensing modalities in a multimodal approach to strengthen the reasoning hypothesis. We used the level of loudness in the room (Yanushevskaya, Gobl, & Ni Chasaide, 2013) and intensity of body movements (Tai, 2014).
The first additional modality (second in total) is the level of loudness. This modality is based on Python library “pyaudio” for sensing the level of noise in the room via a microphone. Figure 8 depicts the algorithm representing this modality in a form of a flowchart. The algorithm receives a number as an input value representing the level of loudness in the room. This value is then connected to the emotional conditions of the analyzed person.

Level of Loudness flowchart is used to define the level of loudness modality in which the algorithm returns emotional state in relation to the level of noise.
To determine the approximate values and put them in context we use some control values, as defined in Table 2. This table is used to approximately connect the current emotional state of the person with the approximate level of noise the person could make. Based on these values the algorithm employs an appropriate emotion vector used for later multimodal operation. The emotion vector has the following format:

Sound intensity levels relative to the threshold of hearing
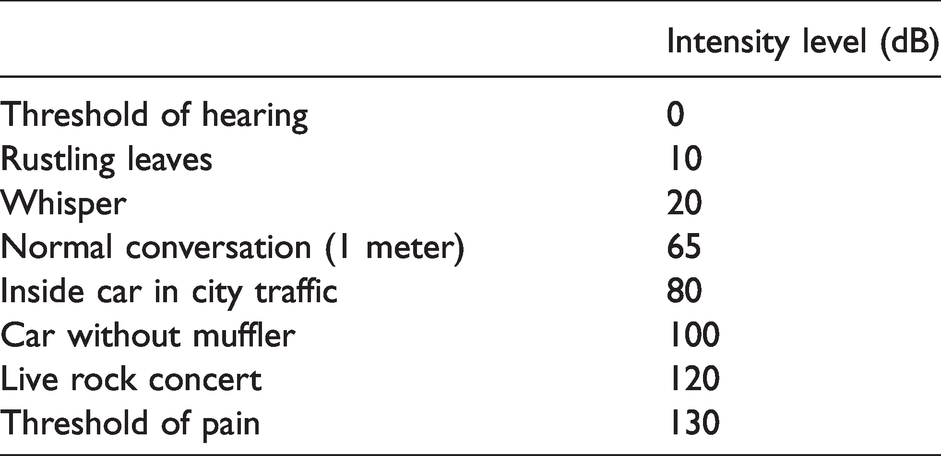
The numbers placed in the vector represent different values of the loudness level for each emotion. These numbers range from 0 to 1, where 0 is the value for the minimum contribution of some particular emotion and 1 is the value for the maximum contribution. For example, the vector that contains the values [0.6, 0.8, 0.1, 0, 0.5] defines the emotional state of the person that is relatively angry, frightened, and sad. In this way, the vector could describe a possible loss of some dear family member of the person. This analysis is subjective and should be taken as an approximation. Such an approach requires a thorough future analysis to assess a connection between emotions and the corresponding average level of loudness, and the research presented in this article is a work in progress in that direction.
The third modality is the intensity of body movements. Here we used Optical Flow, which is a method in Machine Vision. Optical Flow is the pattern of apparent motion of objects, surfaces, and edges in a visual scene caused by the relative motion between an observer and scene (Kemouche et al., 2013). Figure 9 defines a corresponding algorithm in a form of a flowchart. The Optical Flow method calculates the motion between two image frames, which are taken at times t and t+ δt at every position (Lai, 2004). In relation to this work, we use Farnebäck’s algorithm for Optical Flow implemented in OpenCV (Farnebäck, 2003). The algorithm estimates motion using polynomial expressions. A direction of movements is not used in consideration in this application but just the movement intensity. The algorithm outputs a number that represents the intensity of movements as a result of a video-stream analysis. Based on this value, the right emotion vector is employed for later multimodal operation, as depicted in Figure 8. The emotion vector has the same format as in (1). For example, in a case the Optical Control sensor outputs the value between 0 and 150,000, the modality will output the emotion vector [0.1, 0.2, 0.2, 0.4, 0.1]. As can be concluded, this vector favors the Neutral emotion with a value of 0.4. Intuitively, the lower values of movement intensity suggest the less intense emotional stages of the person. In this way, higher movement intensities can be associated with the emotions of anger or great excitement. We also assigned the mean values for motion intensities in emotions like happiness, fear, or sadness. To determine more objective connections between each emotion and corresponding motion intensity, we are planning to carry out a more thorough analysis in the future. In this analysis, labeled video material representing the emotional gesticulations of different individuals will be used to build a predictive model. This modality proved to be sensitive to background movements and changes in light conditions. Therefore, it would be desirable to develop some method of adaptive vision where vision sensor parameters can be dynamically adapted to different light conditions, as stated in Stipancic & Jerbic (2010). The promising approach could also be to focus on the physical body of the person and neglect the other information coming from the background.

Movement intensity flowchart is used to define the intensity of body movements in which the algorithm returns emotional state of the person based on assessing how intense the micro movements of the person during the interaction are.
After the initial information acquired by three sensing modalities in real time, the multimodal information fusion algorithm (Figure 4) suggested the most probable hypothesis, as shown in Table 3. To determine a fused emotional state of the person a kind of linear information fusion procedure is used. The results of all three modalities are summed together and divided by the overall sum of emotions in the array to get average results. At the end, the classification procedure determines the emotion within the array with the maximum value.
The multimodal information fusion algorithm

Table 4 contains the example with results based on the provided image.
Multimodal information fusion results

The Sensor Results column in the table shows the estimation of emotions based on the video (image) source provided at some particular time frame. The sensors output the values about each of the three single modalities. The sensor for evaluation of intensity of body movements informed about the value of approximately 77,000, which is the lower intensity based on the scale depicted at Figure 9. With the current room conditions, the level-of-loudness sensor informed about the noise value of 42 dB. If the system is using only one modality (e.g., face emotion modality) and neglects information acquired by the other two modalities, the result about the most dominant emotion would be Anger, which is arguable if the assessment of the current image is performed by a real person. The multimodal approach is therefore employed to change the reasoning output in this case where each modality can influence the final hypothesis. Data collected by the sensor are now fused in the multimodal approach, as shown at the right part of the table. The results reveal that the most dominant emotion is now Neutral. Based on the quick view at the image of the analyzed face, it can be concluded that the multimodal approach corrected the wrong assumption of the emotion detection modality. It can also be concluded that the other emotions are also intensified. The reason that the modality fusion works in such a way lies in the fact that the values determined by the other two modalities influence the final hypothesis to change the output of the emotion recognition modality.
Experiment results
User intention and attitude are crucial issues in the field of information technology (Tsai et al., 2017). In order to evaluate them quantitatively, we used the Technology Acceptance Model (TAM). TAM has been widely used to develop application tools that can evaluate and predict whether users will accept or not new information systems or technology (Davis, Bagozzi, & Warshaw, 1989). We have conducted an experiment with ten students in five-minute robot-mediated presentations. The teaching content and the teacher remain the same across all ten lectures. During the lectures, the teacher uses information derived from the multimodal sensing system to assess the emotional state of the student and to alter the teaching process if necessary (for example, to change the tone of voice or to ask questions about the status of the student to increase the level of student attunement to the subject of teaching).
After the teaching activity has ended, all students one by one filled out the questionnaire available in Table 5. The results and the student feedback are summarized in Table 6.
TAM questionnaire

Students’ feedback on the questionnaire about technology acceptance

Even when the process of analysis is not thoroughly carried out, students who conducted the questionnaire revealed their impressions relevant to the technology acceptance. The results showed that students recognized and accepted the social perspective of the robot having the potential to result in better learning outcomes. The students were more critical when assessing the quality of interaction in relation to the overall acceptance of the technology. Better quality of interacting media could thus reduce the interaction issues and result in smoother interaction.
Discussion
As the results showed, a students’ recognition of PLEA is at a medium level compared to classical face-to-face teaching. This can be concluded from the fact that technology-mediated teaching, where an affective robot in a form of the HRI interface can assess emotional cues, is a novelty for students and can result in a lack of trust. In order to have better insight into the results, more students should approach the experiment and provide feedback. These results have to be analyzed thoroughly to output a more realistic level of technology acceptance, as explained in Tsai et al. (2017). The experiment hypotheses could be evaluated using some multivariate technique that facilitates the specification of the relationships between and among variables, for example Structural Equation Modeling (SEM), as described in Oztekin et al. (2009).
Conclusion and future work
The methodology used in this project demonstrated the potential of HRI and information transfer. Robot PLEA can achieve a sufficient level of embodiment and attunement to be perceived as a dynamic part of the environment. Usability evaluation that is conducted so far shows encouraging and positive responses of participants in communication. For future studies, we will perform a more thorough analysis of results where experiments will be conducted on a larger number of participants. It is expected to show whether novelty is a significant factor or whether a cognitive robot can indeed be truly effective in technology-enhanced learning. User-experience evaluation, on the other hand, points to other issues over and above technology acceptance. From a theoretical perspective, bringing together social psychology, human communication, and learning can at this stage only be tentative. Multidisciplinary issues arise at the very start of research since the fundamental assumptions on both sides need to be reexamined if an integrated approach were to be created. As far as methodology is concerned, research experimentation in real-life settings has shown reliable results in discovering how users respond to technologies such as augmented reality, context-aware robots, and, more generally, in social information engineering (Fruchter, Nishida, & Rosenberg, 2007; Devlin & Rosenberg, 2008; Walkowski, Doerner, Lievonen, & Rosenberg, 2011; Englmeier, Mothe, Murtagh, Pereira, & Rosenberg, 2011). The lack of other examples regarding similar research within the state-of-the-art suggests that the findings of this work are a contribution.
Further development of the robot from a technical aspect will be directed toward establishing more autonomous robot behavior where the face mimics will not be copied from a real person but aligned to a current environmental situation. In this way, the face gestures will become autonomous and attuned to the emotional status of the person in the interaction.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported in part by the Croatian Science Foundation under the project “Affective Multimodal Interaction based on Constructed Robot Cognition—AMICORC (UIP-2020-02-7184).”