
Abstract
Background:
As digital technologies advance, vast amounts of routinely collected health data are increasingly available for quality improvement and research. However, concerns persist around the reuse of personal health information. Understanding public attitudes and knowledge is essential to building social licence and enabling ethical, large-scale data use.
Objective:
This study explores key research themes in sharing health data for secondary use since 2020, highlighting major topics, emerging research frontiers and future directions for practice.
Method:
An analysis of 95 publications from Web of Science, PubMed and Scopus was conducted using scientometric methods. Citation, co-citation and keyword co-occurrence analyses, along with strategic diagrams, were performed using VOSviewer to identify thematic clusters.
Results:
Research has shifted from early exploratory studies to more multidisciplinary and technology-focused approaches. Key themes include digital tool adoption, integrated data systems and ethical data sharing solutions. The concept of consent has seen the most theoretical development, while public attitudes – particularly around ethical and sociocultural issues – remain underexplored but crucial.
Conclusion:
Ethical governance, transparency and community engagement are central to advancing health data sharing. Building public trust and securing a social licence are foundational to success, especially as challenges around consent, data linkage and public perception remain.
Implications for health information management practice:
This analysis provides insight into public willingness to share health data for secondary data use and offers guidance for fostering a strong social licence while building public trust. Strengthening these trust and engagement frameworks is vital to achieving ethical data use and maximising the potential health system benefits of secondary data use.
Keywords
Introduction
In an era of rapid digitalisation and the advancement of sophisticated health technologies (e.g. artificial intelligence, wearable devices, augmented reality), the management of health data, the dynamics of data sharing and public perceptions regarding the distribution and repurposing of data have become increasingly critical (Alam et al., 2024). Balancing patients’ right to personal privacy with the societal benefits of health data reuse presents a persistent and nuanced challenge. This tension became pronounced during the COVID-19 pandemic, when efforts to leverage information technology (e.g. contact tracing and telemedicine), relied heavily on the collection and dissemination of health data. These efforts aimed to enhance patient care and improve healthcare system efficiency (Hvalič-Touzery et al., 2024; Sullivan et al., 2021; Tosoni et al., 2022). These initiatives raised a range of privacy (both regulatory and legal aspects), ethical, political, technical and social concerns (Chan and Saqib, 2021; Gerke et al., 2020), while also highlighting their significant role in saving millions of lives. This underscores the importance of measuring and securing public trust and support for the use of health data, not only within direct healthcare delivery but also in broader public health contexts (Kerasidou and Kerasidou, 2023).
The concept of social licence – an intangible yet critical form of public, community or stakeholder approval – plays a pivotal role in activities that directly affect individuals, particularly when sensitive information such as health data are involved (Muller et al., 2021). Health data encompass any information related to individuals or populations’ health and may be structured, unstructured, identified, identifiable or de-identified. These data serve to advance medical research, improve the quality and efficiency of care, inform public health initiatives and ultimately improve healthcare outcomes (Murdoch and Detsky, 2013). In the context of secondary uses of health data, obtaining and maintaining a social licence requires more than legal compliance or technical safeguards; it depends on aligning data repurposing with public values, interests and expectations (Muller et al., 2021). A recent systematic review by Benevento et al. (2023) identified the type of data use as the most significant determinant of individuals’ willingness to share their health data. This willingness was shaped by trust and confidence in the responsible, ethical and transparent use and handling of data, which, in turn, depended on how effectively concerns regarding privacy, consent and potential misuse were addressed (Benevento et al., 2023). As technical capacity for data sharing and linkage grows, traditional mechanisms such as informed consent and de-identification may become insufficient to sustain public confidence (Adams et al., 2022). Social licence is therefore developed and maintained through ongoing engagement, transparent governance, ethical oversight and responsiveness to community concerns. Establishing such a foundation involves iterative dialogue with stakeholders, showing accountability and ensuring that data practices remain aligned with evolving societal values. Understanding these factors is essential for fostering social licence and developing strategies to support the ethical and effective use of health data at scale.
While research indicates that people are generally willing to share their health data for research purposes, this willingness is contingent on factors such as the type of data recipient, the nature of the data, consent, sociodemographic characteristics (e.g. race, education, religion) and health literacy (Brall et al., 2021; Cascini et al., 2024; Hutchings et al., 2020; Kim et al., 2019; Kirkham et al., 2022; Seltzer et al., 2019; Soni et al., 2019). Trust, emerging as a dominant factor, operates on multiple levels and is essential for establishing information exchange partnerships; it is a key component of social licence and results from transparency, mutual understanding and accountability (Kerasidou and Kerasidou, 2023; Naeem et al., 2022). Findings from Braunack-Mayer et al. (2024) reinforce these patterns: participants were highly supportive of sharing general practice data with their clinicians and for direct patient benefit, but showed lower willingness to share data for secondary purposes such as research or health service planning. These patterns are consistent with Australian citizen jury deliberations, which found that informed community members generally supported sharing government-held health data with private industry for research and development, provided the intended purpose was clearly in the public interest, responsible governance frameworks were in place and the data were securely managed (Street et al., 2021). Similarly, a national survey of Australians found that just over half of participants were willing to share government health data with private companies, with strong support for opt-in consent and conditions on data sharing (Braunack-Mayer et al., 2021). Participants expressed concerns about private sector corporate interests, profit motives. They also questioned the government’s ability to manage data safely, indicating that public confidence is conditional on transparency, ethical oversight and accountability. Collectively, these studies, along with earlier reviews provide a nuanced understanding of public preferences and concerns regarding health data sharing, particularly with private sector actors. They offer essential guidance for strengthening trust, fostering social licence and promoting responsible and ethical secondary use of health data.
Building on the existing literature, an identified gap lay in the tendency to generalise the nature of the social licence to share, and the challenges associated with it. This review aimed to address this gap by synthesising current trends, offering a comprehensive analysis and contextualising these findings within broader frameworks. By doing so, it sought to provide insights into how these challenges could be navigated, with a particular emphasis on building trust and securing social licence for secondary data sharing. Our inquiry was guided by the following research questions:
What were the primary conceptual themes that influenced the public’s willingness to share health data for secondary use, since 2020?
Which specific topics within health data sharing for secondary use attracted the most scholarly attention, and what were the research frontiers?
What contemporary trends are emerging from the literature that could shape future research priorities and practice approaches to health information management?
Method
This review employed the scientometric methods of document co-citation and keyword co-occurrence analyses to examine the contemporary knowledge base and trends in a defined body of literature representing the public’s (e.g. patients, health consumers, citizens) perceptions of the secondary use of health data (Du et al., 2024). Scientometrics is a branch of bibliometrics, characterised by documenting and visualising the structural and relational features of the accumulated knowledge base within a specific discipline or topic (van Eck and Waltman, 2014). Given its ability to capture the evolution and focus of research, this approach is well-suited for analysing the conceptual and topical trends in a body of literature.
Identification of documents
The dataset used in this review is drawn from our systematic review and meta-analysis, which examined public perceptions of health data repurposed for secondary use (Olsen et al., 2025). The review was scoped to include peer-reviewed, full-text primary research articles (qualitative, quantitative or mixed-methods) published in English between January 2020 and December 2023 (to map the contemporary research front). Eligible studies explored the perceptions of the public or health consumers across all demographic groups. Studies were excluded if they focused on health care professionals, representatives from commercial health organisations, or data generated and stored outside health organisations (e.g. wearable devices, social media). Clinical trials (where consent for data sharing had already been obtained), reviews, editorials, commentaries, grey literature, protocols and conference abstracts were also excluded. All records identified and screened in the systematic review formed the source dataset for this scientometric review.
Data analysis and visualisation
Bibliometric data were sourced from the core collection database of Web of Science, PubMed or Scopus on 17 December 2024, and metadata were collated into a CSV file for analysis. Data analysis and visualisation were conducted using VOSviewer software (version 1.6.7; van Eck and Waltman, 2010).
Document citation and co-citation analysis
The first research question was addressed through document citation and co-citation analyses. Citations are frequently used in bibliometric studies as a metric of scholarly influence, with highly cited documents often reflecting key research foci within a field. Document citation analysis was used to identify the most frequently cited documents and examine distinguishing conceptual themes. Co-citation analysis was used to assess the frequency with which documents are cited together in the reference lists (Saxena et al., 2024).
Keyword co-occurrence analysis
The second research question was addressed using keyword co-occurrence analyses to explore the relationships between keywords. Co-word analysis is a text-mining technique that analyses the co-occurrence of word pairs, where keywords frequently appearing together in the same documents, are likely related. In this analysis, keywords (i.e. author-defined and indexed terms) – key terms or phrases in the titles and abstracts frequently associated with a specific topic or research area – were extracted. Keywords with three or more co-occurrences were retained and manually reviewed for ambiguous or insignificant words, such as function words and irrelevant verbs, which subsequently were excluded. The synonyms of keywords were merged and standardised (e.g. secondary use and secondary data use).
Data visualisation
A network map was generated using VOSviewer. To identify thematic clusters, the force-directed layout algorithm with linlog/modularity normalisation method was applied to adjust for potential bias (van Eck and Waltman, 2014). Each keyword is represented by a node, with the size reflecting the frequency of the keyword’s occurrence. The edges (i.e. connections) between nodes represent co-occurrence relationships, indicating that two terms appeared together in a document; the thickness of the edge reflects the frequency of co-occurrence, with the maximum number of lines set to 500. Closely related nodes are grouped into clusters distinguished by unique colours, which represent sets of words that frequently co-occur and form distinct thematic areas. The clusters are described using the metrics:
Keywords: A set of keywords that constitute a particular cluster (i.e. research theme).
Size: The number of keywords in the cluster.
Frequency: The average number of keyword occurrences for all keywords in the cluster.
Total Link Strength (TLS): The total strength of the links between a keyword and other keywords, for all keywords in the cluster.
Average Citation Score (ACS): The average citation impact of all documents associated with the keywords in that cluster.
A density map was generated to visualise the evolution of research topics based on the relative frequency of keyword occurrences over time. Colour graduations illustrate the frequency with which keywords appear on average across different time periods. Darker-coloured (i.e. purple and blue) nodes are associated with topics studied in earlier literature, while lighter-coloured nodes correspond to topics in more recent documents.
Strategic diagram
The third research question was addressed using strategic diagram analysis, a bibliometric method that visually maps thematic research clusters. This approach positions clusters within a four-quadrant layout based on two key dimensions: centrality (their degree of external connectivity) and density (the level of internal cohesion). This analytic technique, widely adopted in recent scientometric studies (Cobo et al., 2011), provides insights into both the maturity and relevance of research themes, helping to reveal how topics are structured and interlinked across the field. For this study, centrality and density values were calculated using Gephi (version 0.10; Bastian et al., 2009), following standard co-word network analysis protocols.
The x-axis represents betweenness centrality, which reflects how strongly a thematic cluster connects to other clusters in the network. Higher centrality values indicate a theme’s influence and its role in bridging different areas of research, highlighting interdisciplinary significance.
The y-axis represents density, capturing the internal strength and cohesion of the cluster. High-density clusters typically indicate a well-developed theme with substantial conceptual and methodological consistency.
The diagram is divided into four quadrants:
Results
From an initial 4085 documents, 95 met the inclusion criteria and formed the primary dataset for this study. Overall, a gradual increase in publication frequency over time was observed – from 17 documents (17.9%) published in 2020, to 32 (33.67%) published in 2023. In terms of increasing annual scientific production, the median yearly growth rate was 18.5%, with a maximum of 42.1% in 2022. Research included contributions by 33 countries or regions (63.6% developed), 293 organisations or institutions and 515 authors. The 95 documents were published in 68 journals, with 38 (55.89%) appearing in 10 journals. The three most frequently occurring journals in the dataset are BMC Medical Ethics (n = 10), Journal of Medical Internet Research (n = 6), and the International Journal of Medical Informatics (n = 5).
Document citation and co-citation analysis
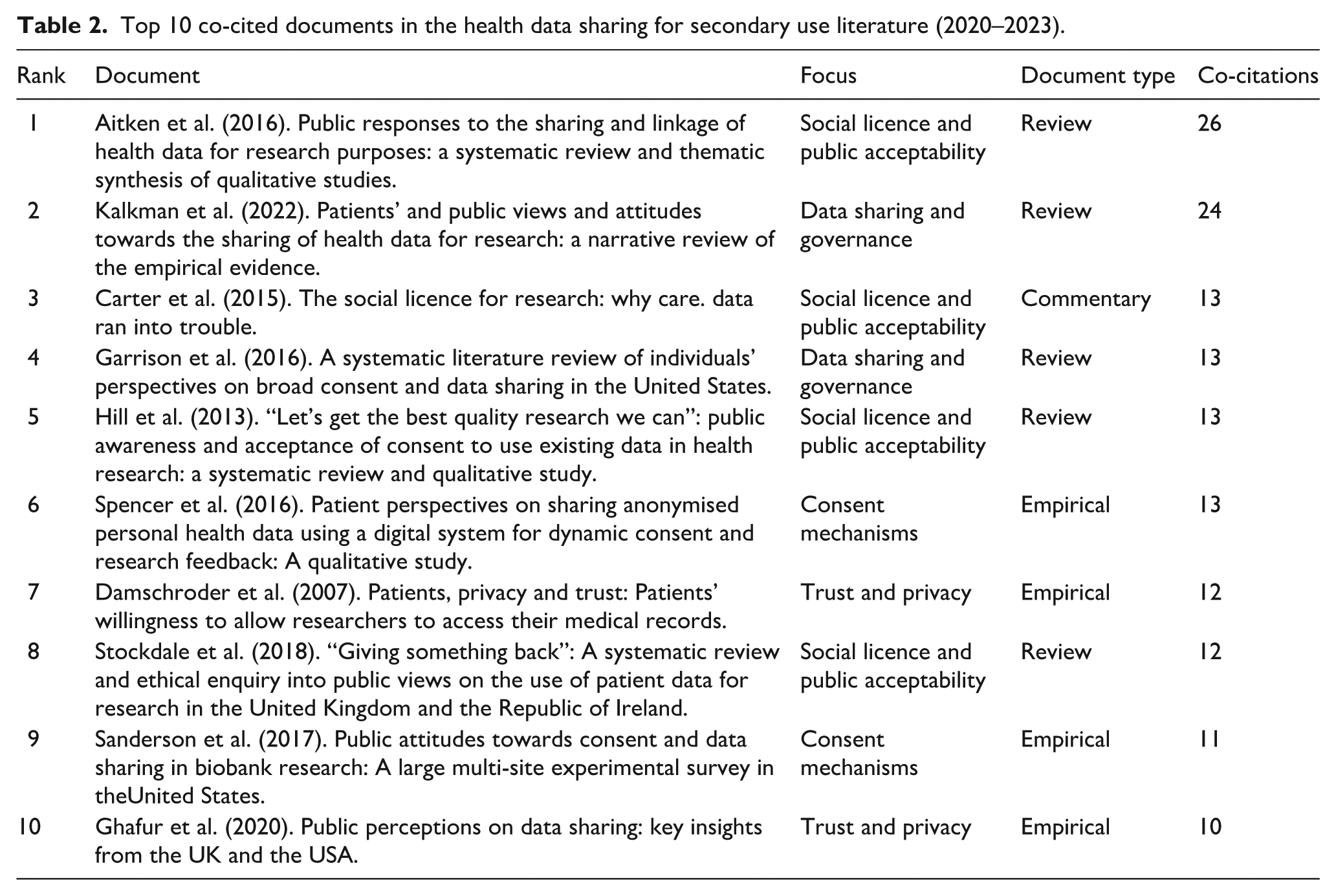
Table 1 presents the 10 most cited documents. Of these, survey designs (n = 6), focus groups (n = 2), interviews (n = 1) or a combination of surveys with workshops (n = 1) were used. Study cohorts varied in size, ranging from 30 to nearly 37,000 people, and the types of health data examined included general health data, and more specifically, personal medical records, and genomic datasets. The distribution of research focus included: how individuals perceive artificial intelligence (AI) and the secondary use of health data (n = 3), ethical and trust considerations in data reuse (n = 3) and factors that shape perceptions and willingness to share data (n = 4).
Top 10 cited documents on health data sharing for secondary use (2020–2023).

AI: Artificial intelligence; DNA: Deoxyribonucleic acid; NHS: National Health Service.
Document co-citation analysis identified 2670 citations from the reference lists of the primary documents. Table 2 shows the 10 most co-citations, representing the field’s most influential works. Of these, five were reviews, four were empirical, and one was a commentary. The research focus observed in the citation analysis (social licence and public acceptability, data sharing and governance, trust and privacy, and consent mechanisms) represents the organising concepts in this key literature.
Top 10 co-cited documents in the health data sharing for secondary use literature (2020–2023).
Keyword co-occurrence analysis
A final set of author-defined and indexed keywords was analysed (n = 67). The most frequently occurring keywords were privacy (n = 32; TLS = 196), data sharing (n = 29; TLS = 169), attitude (n = 26; TLS = 162), consent (n = 25; TLS = 161), and trust (n = 24; TLS = 157). Figure 1 is a co-word network map representing 67 nodes, 762 edges and a TLS of 1439. Keywords are organised into six coloured clusters, each representing conceptual similarity among the keywords. As shown in Table 3, the largest thematic cluster (C01:red) comprises 17 keywords, with a moderate ACS of 5.52 and the highest TLS of 685. The smallest clusters (C05:purple and C06:orange) each consist of seven keywords. Cluster 5 has the highest ACS (12.28) and the highest frequency (10.85), emphasising the prominence of these keywords within the dataset but also has the lowest TLS (206), indicating fewer connections with other clusters.
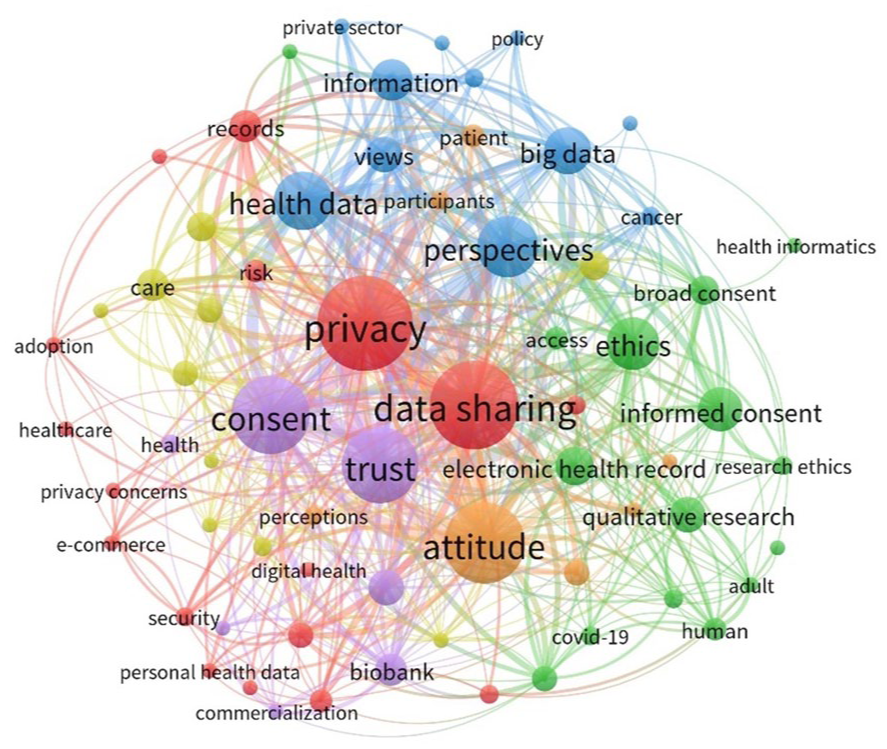
Co-word network visualisation of the health data sharing literature (2020–2023).
Thematic clusters in health data sharing research for the period of 2020–2023.
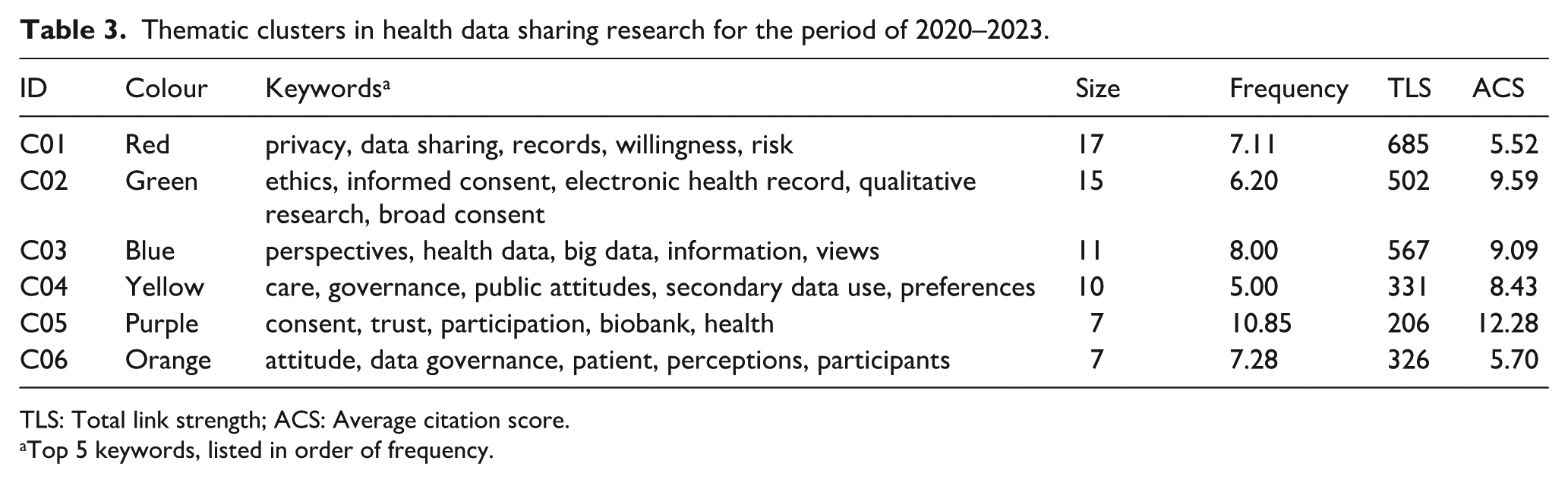
TLS: Total link strength; ACS: Average citation score.
Top 5 keywords, listed in order of frequency.
Figure 2 depicts the temporal development of co-words in health data sharing for secondary use research, grouped into three periods. The earliest period, represented by dark purple nodes, focused on public perceptions (perceptions, attitude, perspectives), ethical constructs (ethics, consent, public trust), and the potential of health data to advance medical research and support precision healthcare (data linkage, precision medicine, participation, big data, AI). The middle period, indicated by dark green nodes, marks a transition to a more multidisciplinary focus with an emphasis on the ethical, social and technical dimensions of data sharing. This phase also reflects the integration of advanced technologies (health informatics, DNA, biobank, data sharing), greater engagement with governance and public attitudes (data governance, public engagement, attitudes and deliberation, views), and a heightened urgency driven by global events like the COVID-19 pandemic (patient, research ethics, trust, privacy, risk, COVID-19). The research front appears as light green and yellow nodes. This research focuses on integrating health data (digital health, healthcare, technology), the adoption of digital tools (commercialisation, e-commerce) and data sharing solutions (security, privacy concerns).
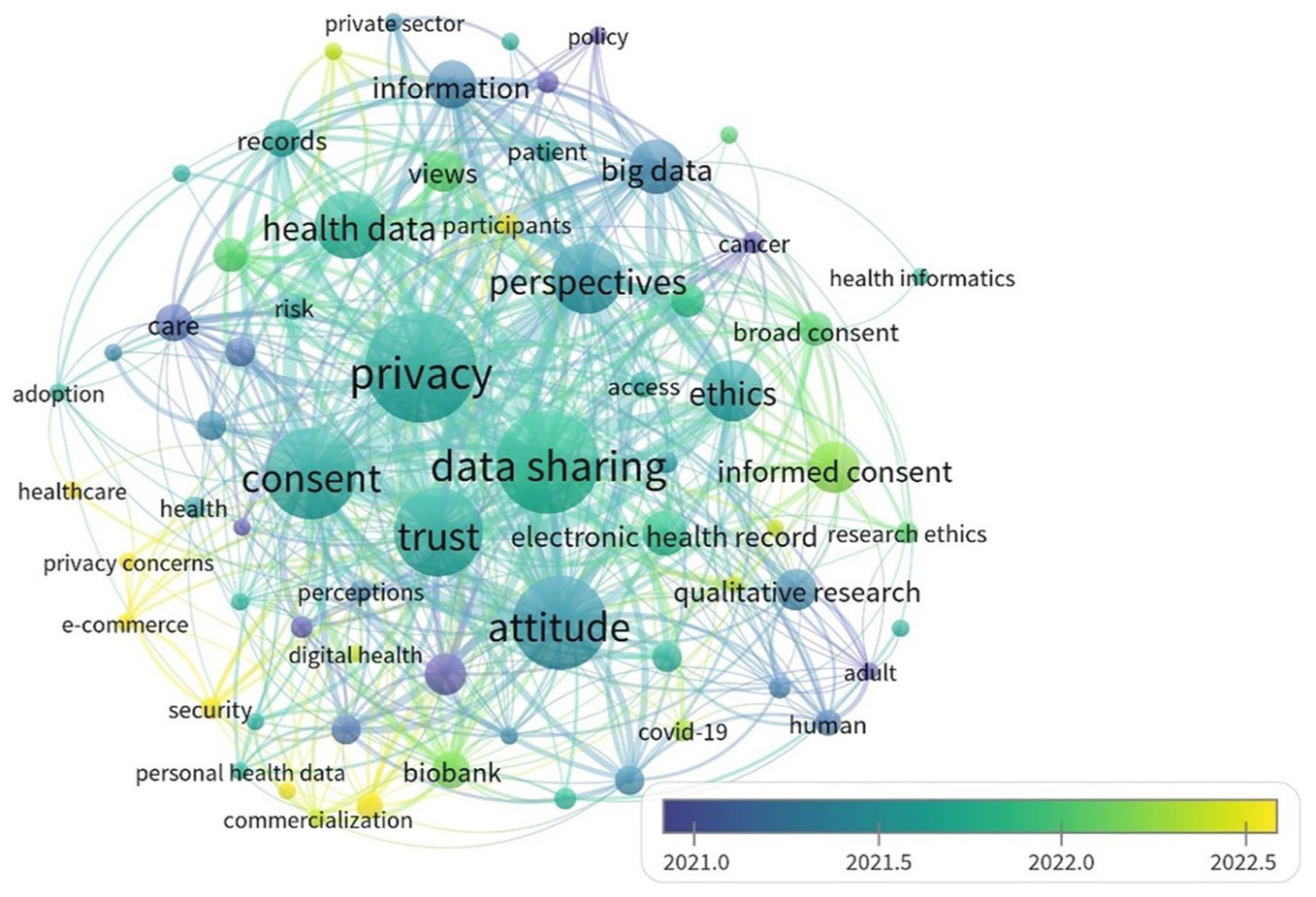
Co-word network map with density overlay according to average publication year.
Strategic diagram
Figure 3 visually represents the relationships between each of the thematic keyword clusters using a quadrant-based layout. These are described below and in more detail in the discussion section.
Q1 – Core Themes: Cluster 5 keywords are characterised by high centrality and density, indicating that it represents the most central and well-developed research theme and acts as a bridge across different research areas.
Q2 – Specialised Themes: Cluster 6 keywords have a high density but low centrality, suggesting it is a well-developed but narrowly focused area. While it may not strongly influence other themes, it represents a specialised field that complements broader research directions.
Q3 – Emerging or Declining Themes: Clusters 2, 3 and 4 are positioned in the lower-left quadrant, indicating low density and low centrality. Their proximity to one another and partial overlap suggests interconnected subfields that might be evolving in parallel. These keyword themes may either be gaining relevance and integrating into the field or losing prominence as research priorities shift.
Q4 – Foundational Themes: Cluster 1 keywords have a low density but higher centrality, representing foundational knowledge or broad conceptual frameworks to the field. Given the central positioning, this cluster could act as a bridge between more specialised themes and the broader research landscape.
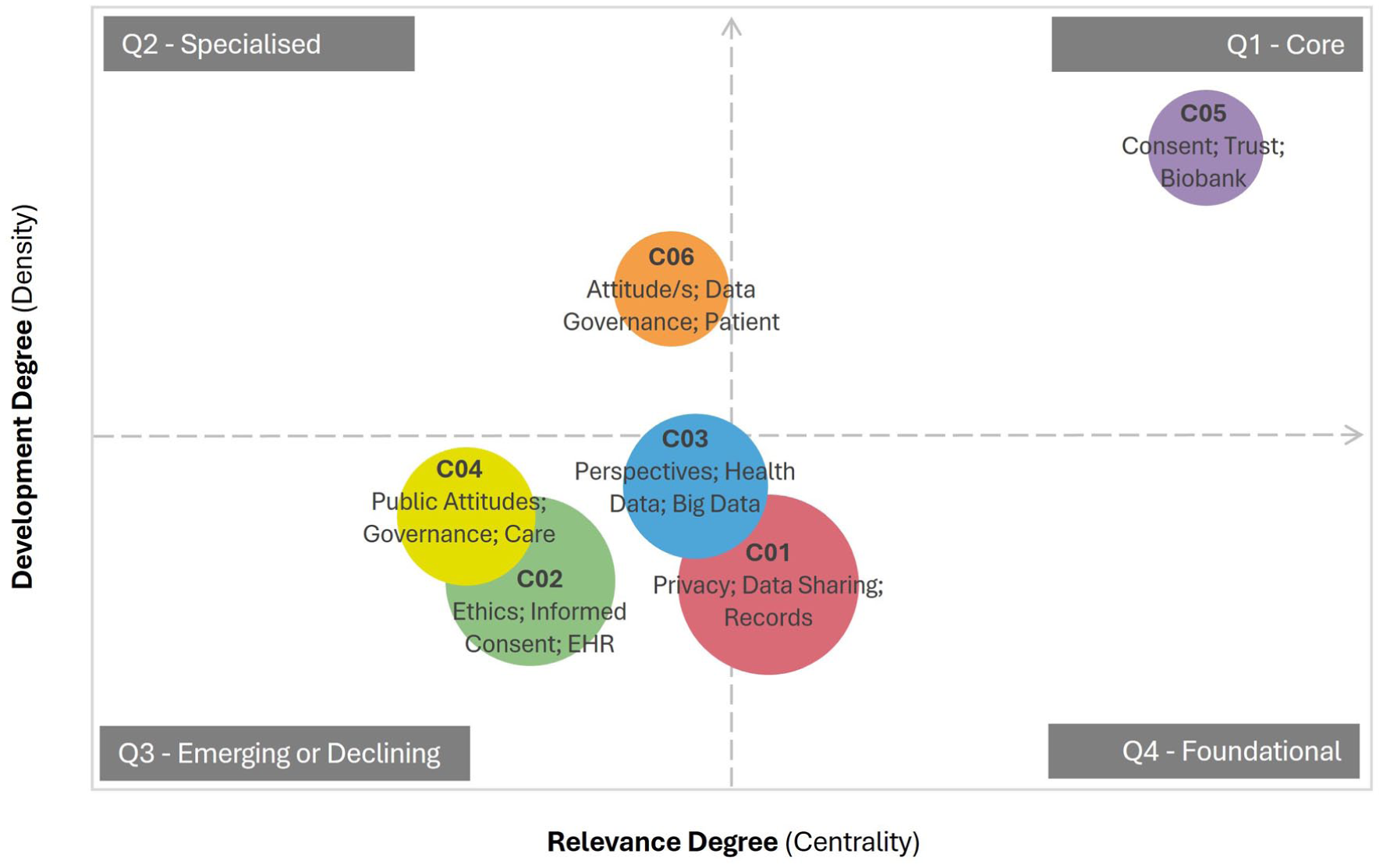
Strategic diagram of thematic research clusters associated with health data sharing for secondary use (2020–2023).
Discussion
This review sought to identify the conceptual themes and topical developments that define the contemporary knowledge base on the public’s perspectives on health data sharing for secondary use and articulate emerging research and practice opportunities. Using a scientometric analysis of scholarly output between 2020 and 2023, we identified key themes, contemporary trends, and emerging areas in the field.
Interpretation of results
Conceptual themes in health data sharing for secondary use
This review identified three areas of research focus in the contemporary knowledge base (AI and secondary data applications, ethical and trust considerations and factors influencing willingness to share data), which have received sustained attention since 2020. The first focus (AI and the secondary use of health data) underscores the expanding role of AI in healthcare, such as predictive analytics, risk stratification, personalised medicine, genomics and epidemiology (Rieke et al., 2020). As AI applications become more prevalent, understanding AI governance will be essential for fostering public trust and addressing ethical concerns (Birkstedt et al., 2023). The second focus (ethical and trust considerations) highlights the complexities of building and sustaining public confidence in data reuse. Transparency in data governance, stringent protection measures and respect for informed consent are all crucial components of ethical data sharing (Kim et al., 2019). While informed consent and de-identification are essential components of ethical health data sharing, they alone may not adequately address the complexities of large-scale data linkage. Challenges include variations in data quality and standards, the involvement of multiple governments, agencies and private organisations, data custodians’ lack of trust in external organisations, differences in legal and privacy regimes and uncertainties about whether community support extends across national borders (Adams et al., 2022). These challenges highlight the importance of robust governance frameworks, transparency and ongoing public engagement to complement consent and de-identification practices and to support ethical, effective data sharing. Additionally, ethical considerations must account for cultural and societal variations, necessitating context-specific approaches to ethical data sharing (Warren et al., 2023). The third focus examines the conditions shaping individuals’ willingness to share health data with stakeholders such as healthcare providers, commercial companies and researchers. Trust, privacy concerns and perceived benefits play a critical role in these decisions.
Co-citation analysis highlighted the contributions of four prominent themes (social licence and public acceptability, data sharing and governance, consent, trust and privacy) to the theoretical underpinnings of health data sharing for secondary use. First, social licence and public acceptability play a crucial role in attitudes, as individuals are more likely to support data sharing initiatives when they perceive them as fair, transparent and beneficial (Muller et al., 2021). Historical cases like care data in the United Kingdom underscore the risks of inadequate public consultation and perceived commercial exploitation, which can lead to strong opposition (Aggarwal et al., 2021). Second, effective governance structures are critical for balancing the benefits of data sharing with ethical obligations and privacy concerns (Gross et al., 2022). Policies and regulations that ensure accountability, equitable data access and robust security measures influence public confidence in data sharing and help mitigate fears of data misuse and reinforce public trust. Third, consent mechanisms also remain a central consideration in public attitudes towards data sharing (Kaplow et al., 2024; Sánchez et al., 2023). Traditional broad consent models, where individuals provide a one-time agreement for future data use, have been scrutinised in favour of more flexible approaches (Cumyn et al., 2023; Lee et al., 2023; Richter et al., 2023). Ensuring consent processes are transparent and adaptable to evolving public expectations is key to fostering sustained participation. Finally, trust and privacy concerns are fundamental to public willingness to share health data. Individuals often express hesitancy due to fears of privacy breaches, data misuse, and a lack of control over their personal information. Trust is influenced by perceptions of institutional integrity, the presence of strong privacy safeguards and clear communication about data usage. Regulatory protections, encryption technologies and transparent accountability measures can help address these concerns. Ultimately, fostering public trust requires ethical data stewardship, ongoing public engagement and a commitment to responsible data governance.
Together, the conceptual themes of social licence, governance, consent mechanisms and trust, shape public willingness to share health data for secondary use. Collectively, they frame a broader discourse on how policies and governance frameworks can either enhance or restrict data sharing practices and highlight the need for a balanced approach that prioritises ethical considerations and facilitates the potential benefits of data sharing for secondary use.
Frontiers in health data sharing for secondary use
Keyword analyses conducted in this review identified dominant topics and research frontiers. Privacy emerged as a foundational theme closely intertwined with trust, attitudes, consent and broader societal perspectives. Trust serves as the cornerstone of data sharing, with individuals more inclined to provide consent when assured of secure and ethical data use. Concerns around the protection of privacy are found across all the themes and when lapses in privacy protection occur, trust is eroded. It is therefore crucial that robust safeguards are developed and transparently shared with the public. Attitudes towards data sharing are shaped by a delicate balance of perceived risks and benefits, making transparency in consent mechanisms essential (Baines et al., 2024). As privacy perspectives vary across cultural and societal contexts, data sharing frameworks must be adaptive, ensuring they uphold diverse values while fostering public confidence in ethical research and healthcare innovation (Li, 2022).
Temporal co-word analysis highlighted the evolution of health data sharing for secondary use across three time periods (i.e. exploratory phase, transitional phase and research front). The earliest period represents the foundational work characterised by understanding public perceptions of data sharing, with a focus on attitudes, perceptions and ethical constructs (i.e. consent, public trust and privacy). This phase laid the groundwork for more specialised research by establishing the fundamental ethical, social and technical concerns related to health data use. The middle period marks a transition towards a more multidisciplinary approach, with research shifting to include advanced technologies and broader governance issues. This phase saw the integration of health informatics, biobanks and the complex challenges in data sharing in both local and global contexts. Research during this time started to move beyond theoretical concerns to address practical, scalable solutions for data sharing. The most recent period focuses on themes related to the application of health data in specific health contexts and the integration of technology. Research during this phase is centred around the adoption and integration of health data and digital health technologies, including commercialisation and e-commerce aspects. This finding is also supported by a scientometric analysis of data sharing for precision medicine (Texier et al., 2019), which observed the emergence of keywords such as cloud, encryption, security and interoperability as newer areas of research. This period also marks the growing use of secondary health data for targeted areas like mental health (Bakken et al., 2022; Kirkham et al., 2022; Watson et al., 2023) and rare diseases (Amorim et al., 2022; Zawistowski et al., 2023), signalling a shift from broad exploratory research to the application of health data in solving specific, context-driven health challenges.
Structure and development of the research
The strategic mapping of thematic clusters offers key insights into the structure and development of research in this field. The most developed research themes focused on trust, informed consent and participation, with particular emphasis on their implications for health research and commercialisation. The presence of keywords such as biobank and DNA suggests a focus on the collection, storage and use of genetic materials in health-related research contexts. This aligns with broader discussions around precision medicine, biomedical innovation and commercialisation of health research. The specialised status of attitudes (cluster 6) towards data use and governance is well-developed but remains isolated from other areas. This highlights an opportunity for greater integration of these dimensions into other areas, such as digital health research to build more trusted, transparent and equitable digital health solutions. Addressing the public’s concerns regarding data sharing for secondary use will build public trust and foster engagement with digital health technologies. The foundational themes within Cluster 1, particularly those concerning privacy, AI and data security, highlight critical yet underdeveloped research areas. As digital health technologies become more prevalent, there is a need for further exploration of privacy-enhancing mechanisms, ethical AI implementation and public policy frameworks to ensure secure and equitable data usage. Overall, these findings suggest a research landscape in transition, with well-established themes continuing to shape the field, while emerging topics such as AI and digital privacy signal important future directions.
Future research and practice priorities for health information management
As digital technologies become deeply integrated within health systems, securing and sustaining social licence will be pivotal to the success of data-driven research, innovation and healthcare. In addition to synthesising current trends and offering a comprehensive analysis, this review also seeks to contextualise our findings within the broader framework of health information management. Understanding and addressing the factors that influence individuals’ willingness to share their health data for secondary use requires a coordinated, multilevel approach. Box 1 summarises the key focus areas, including corresponding research and practice priorities, while Figure 4 illustrates the interrelationships and interdependence between factors. An online interactive version is also available. 1
Key focus areas for future research and practice priorities to health data sharing for secondary use.
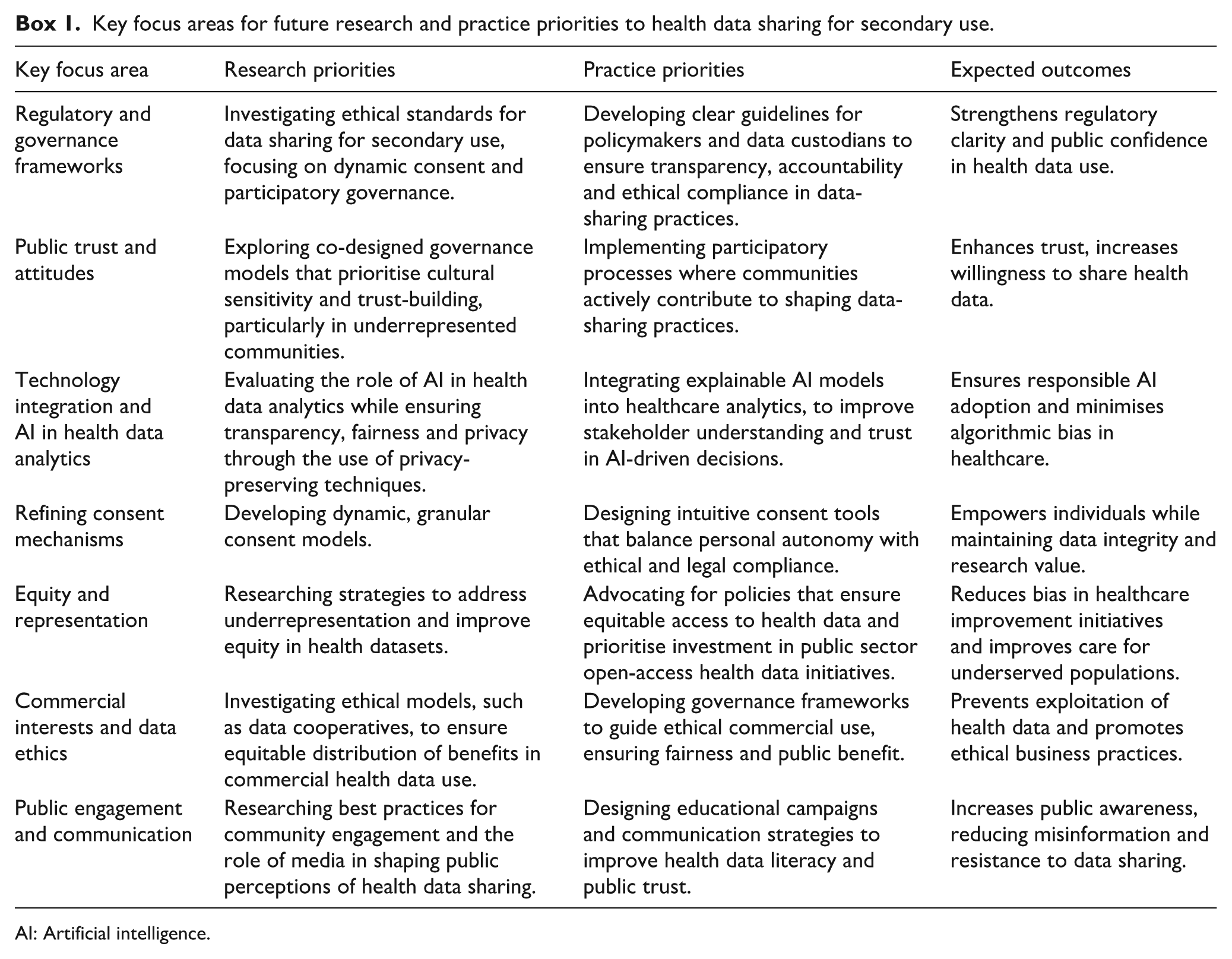
AI: Artificial intelligence.
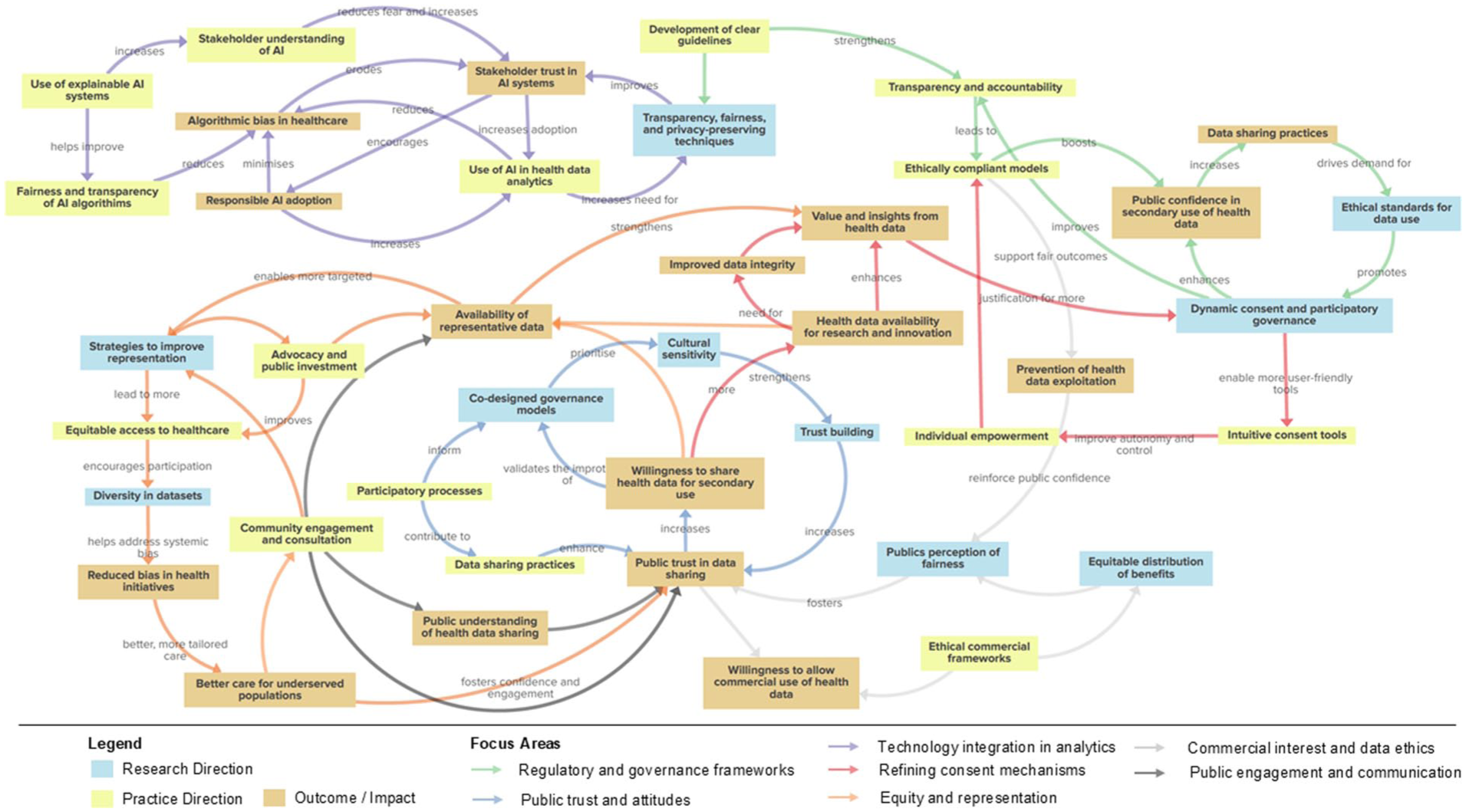
Conceptual map of research and practice directions to improve willingness to share health data for secondary use.
Limitations of the study
While scientometric analysis provides a comprehensive overview of publication patterns, trends and research outputs, it inherently focuses on high-level metrics and may not capture the detailed contextual or methodological nuances of individual studies. Consequently, our findings should be interpreted as reflecting broad patterns in the literature rather than detailed qualitative insights. Our future work complements this approach with an in-depth systematic review and meta-analysis (Olsen et al., 2025) to explore the nuanced aspects of research practices and findings. The predominance of systematic and narrative reviews among the most cited publications also highlights a potential citation bias, as reviews tend to attract more citations than primary research. Document and keyword co-occurrence analyses provide valuable structural insights but remain surface-level representations of the underlying landscape. Keyword-based analyses are constrained by database indexing practices, author-defined terms and metadata availability and can limit the ability to capture the depth of emerging or nuanced topics. Furthermore, the dataset is restricted to publications from 2020 to 2023, which should be interpreted as a contemporary snapshot rather than a long-term trend analysis. Despite these limitations, our focused approach – drawing on a systematically selected dataset – reduces false positives common in broader scientometric analyses. Future research could expand the temporal scope, include pre-COVID-19 literature and incorporate additional primary research to capture longitudinal trends and emergent topics. Together with our complementary systematic review (Olsen et al., 2025), these findings provide a more comprehensive understanding of public perceptions on health data sharing for secondary use.
Conclusion
This study presents a comprehensive scientometric analysis of the conceptual foundations and topical developments that shape the current literature on public perceptions on health data sharing for secondary use. Integrating theoretical insights with practice and research opportunities will support responsible advancement in a technology-driven healthcare landscape. By prioritising ethical governance, technological transparency and meaningful community engagement, future efforts can build public trust and secure a social licence for data sharing. These measures together promote more equitable, effective and trustworthy approaches to secondary data use, supporting better health outcomes and increased societal trust.
Footnotes
Author contributions
All authors conducted the systematic literature review to identify the dataset. MK, RE and LW designed the study with assistance from JP, BR, NP, QO and AD. MK conducted the analysis and drafted the manuscript with assistance from RE and LW. All authors contributed to editing and approved the final version.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
ORCID iDs
Data availability statement
All data utilised in this study is available on request from the authors.