
Abstract
In 2022 the Australian Data Availability and Transparency Act (DATA) commenced, enabling accredited “data users” to access data from “accredited data service providers.” However, the DATA Scheme lacks guidance on “trustworthiness” of the data to be utilised for reuse purposes.
Keywords
In the last two decades there has been a global increase in the sharing and reuse of data arising from policies for open data (Australian Government Department of Finance, 2022), advances in technology (Sielemann et al., 2020), and research funding and publication policies linked to data sharing (Sheehan, 2016). The potential advantages of data sharing and data reuse have been well-documented in the literature. These include (but are not limited to): potential increased cost-efficiencies through reduction in both duplication of and time spent on primary data collection (Curty, 2016; Whitlock et al., 2016); potential enrichment of research through new insights (Curty, 2016); increased transparency in data production and use (Roche et al., 2014); and an enhanced analytical capacity to inform decision-making (Verhulst, 2021).
Governments have been keen to adopt open government data (OGD) models (Umbaldi, 2013) with intent to enhance evidence-based decision making through responsible and secure sharing of data. There is widespread recognition among OGD advocates that “good information management is essential to building trust in the creation, collection and use of . . . Government information” (National Archives of Australia [NAA], n.d.).
Trust has been defined in many ways (Walterbusch et al., 2014) and in many different contexts (Huang, 2007; Sztompka, 2000). It is one of the most researched factors within the knowledge management and knowledge sharing domains (Asrar-ul-Haq and Anwar, 2016). Scholars have identified the complex and dynamic nature of trust in relation to data use and reuse (Sexton et al., 2017; Yoon, 2017; Yoon and Lee, 2019). For example, in their research into “factors of trust in data reuse” in the United States, Yoon and Lee (2019: 1248) identified several trust factors including “data, data producer, community and intermediary.” Steedman et al. (2020: 817, 829), in their research into trust in “data-driven practices,” postulated the multi-factorial nature of trust in data that either enhanced or undermined a user’s trust in situations which were “context dependent.” There is agreement among many scholars that data trust development is “situation specific” (Bauer and Freitag, 2016: 2).
The Australian Government promotes trust in its data production and data management abilities through a range of policies and organisational processes. In 2009, the Australian Bureau of Statistics (ABS) released its data quality framework enabling data users to self-assess the quality of government data and information outputs. In 2010, heads of Australian Government agencies agreed to principles for integrating government data for research purposes, with accredited agencies (“Integrating Authorities”) to be utilised for potentially “high risk” (sensitive) data integration (Greenall-Ota et al., 2021). In 2021, the Australian Government implemented the policy, Building trust in the public record: Managing information and data for government and community (NAA, n.d.). It aimed to foster community trust by creating transparency and accountability in organisational data and information management. However, provision of policies and procedures for effective data governance and data quality management does not presuppose their implementation. In 2020, the average information management maturity score for Australian Government Departments was 3.25/5 (NAA, 2021), indicating the need for considerable improvement in public sector organisations’ data and information management practices.
A recent component of the Australian Government’s digital data strategy was the enactment of the national Data Availability and Transparency Act 2022 (Cwth) (DATA Scheme). The main aim of the Act is to provide best practice guidelines to facilitate the sharing of Australian Government data safely and securely. The three defined “public interest” purposes for the sharing of government data include: “government service delivery; informing government policy and programs; and research and development” (Office of the National Data Commissioner [ONDC], 2023a: 2). Data custodians can provide their data to “accredited data service providers,” from whom accredited “data users” can access data (ONDC, 2023a). This structure places the onus on research organisations and their employees for responsible and ethical use and management of data. Guidance is provided by the ONDC (2023b) on how to prepare and describe a dataset to ensure its system integrity for sharing on the Australian Government centralised data sharing platform, data.gov.au. However, the DATA Scheme does not provide guidance to researchers about the “trustworthiness” of these data.
Giddens (1991) theorised that “trust [and trustworthiness] presumes . . . a quality of ‘faith’ which is irreducible. . . [it] brackets the limited technical knowledge which most people possess about coded information which routinely affects their lives” (p. 19). In their critique and extension of Giddens’ theory, Meyer et al., (2014: 180) reiterated Giddens’ notion that trust is required where there is “ignorance” or lack of knowledge or understanding and that, conversely, there is no need for trust where there is a situation of “complete knowledge.” When applied in the context of Australian Government (health) datasets, this suggests that the apparent absence of a mandate for documentation on specific data quality attributes or information integrity processes for each shared, government dataset, is problematic. At the practical level of health dataset management, the Open data toolkit (Australian Government, n.d.) indicates that the application programming interface or data visualisation will only work if “clean” data files are provided. “Clean” data files are considered to be those that have “as few mistakes or bad entries as possible” (Australian Government, n.d.). No further metrics for evaluating or describing the dataset quality or information integrity, beyond system integrity, are provided.
The cost of poor data quality to business is well-known. Gartner (2021) estimated that on average big companies annually lose $12.9 million USD due to poor data quality. Beyond the potential financial loss, poor data quality has ramifications for poor decision-making, loss of reputation, reduced productivity etc. (Haug et al., 2011). These risks also apply to government data and to the health and medical research context. For example, Carlisle (2021: 472) “reviewed the individual patient data of submitted randomised controlled trials” sent to the journal, Anaesthesia, between February 2017 and March 2020. He concluded that 44% of the submitted papers contained flawed data. Potential implications from these flawed data could lead not only to defective treatments and interventions but also potentially to patient morbidity and even death.
It is the aim of OGD to encourage the use and sharing of government datasets. Riley et al. (2023) demonstrated the widespread use and dissemination of Victorian government health data by researchers for reuse purposes without it being OGD. Therefore, given the breadth and scope of use of government health data, it is important to ensure that sufficient dataset documentation is provided for researchers by government/data custodians to facilitate their “trust” in the data as a “mediating variable between information quality and information usage” (Kelton et al., 2007: 363).
Research has been undertaken in Australia on consumers’ perceptions of the government’s ability to use, store and share personal data and information (Biddle et al., 2018; Lupton, 2019), on researchers’ experiences with using specific government datasets and on specific cases of data reuse (Henry et al., 2018; Pearson et al., 2015). Despite the many trust-building steps undertaken by the Government, there has been minimal investigation on what is required to build researchers’ trust in Australian Government health data for reuse purposes. This disparity has led to three research questions: (i) Do researchers using government health datasets for reuse purposes trust the data? (ii) What factors do researchers use to determine the trustworthiness of these data? and (iii) What are the implications of these findings for government and data custodians?
Method
The study design has been described elsewhere (Riley et al., 2024). Briefly, a cross-sectional quantitative survey (including four open-ended questions) was conducted between November 2022 and February 2023, with authors of peer-reviewed studies published between 2008 and 2020. This was part of a larger case-study of researchers who had utilised selected Victorian Government health information assets between 2008 and 2020 (Riley et al., 2023). The survey, administered via REDCap, collected information on the researchers’ data knowledge of and reuse practices pertaining to government health datasets (Parts A and B); and perceptions of government health data trustworthiness and demographic factors (Parts C and D). Respondents could reply for up to two datasets, so the findings showed more datasets than respondents. This article reports the responses to Parts C and D of the survey.
Sample
To determine sample representativeness, selected demographic characteristics (gender, highest educational level, years of work experience and professional discipline) of non-respondents were obtained from publicly available sources (i.e. LinkedIn, university and health research organisational websites). Non-respondents for whom all demographic details were not located were excluded from these analyses. Chi-square, alpha = 0.05, was calculated to determine if there were any statistically significant differences between respondents and non-respondents.
Development of survey items related to researchers’ perceptions of data trustworthiness
For the purposes of the survey, the Oxford Dictionary definition of trustworthiness was utilised (i.e. “the quality of always being good, honest, sincere . . . so that people can rely on you”, n.d., online). Survey constructs relating to researchers’ perceptions of data trustworthiness (Part C) were guided by literature that reported factors that influenced development of trust judgement in information management and data reuse (Adjekum et al., 2018; Sexton et al., 2017; Yoon, 2017; Yoon and Lee, 2019), data reuse behaviour (Curty et al., 2017; Kim and Yoon, 2017; Perrier et al., 2020; Sielemann et al., 2020; Tenopir et al., 2015) and other trust studies (Mayer et al., 1995) (see Supplemental material Table S1). Demographic questions in Part D were influenced by Kim and Yoon (2017). OGD principles were also reviewed for grouping of the constructs into data factors, data management factors and data provider factors (see Supplemental material Table S2). Definitions for trustworthiness constructs were provided in the survey to facilitate respondents’ understanding. Where possible, the definitions were derived directly from seminal data quality and data management literature (Caro et al., 2008; Wang and Strong, 1996; Wilkinson et al., 2016). Definitions of data provider constructs were adapted from Yoon and Lee (2019).
Ultimately, seven dimensions, incorporating 28 constructs related to factors influencing perception of data and information trustworthiness for reuse purposes, were selected. These included: Data Factors – Intrinsic properties; Data Factors – Extrinsic properties; Data Management Properties – Findability and Accessibility; Data Management Properties – Interpretability and Understandability; Data Provider – Reputation; Data Provider – Ability; Data Provider – Ethics (see Supplemental material Survey).
Analysis
Descriptive statistics were completed using IBM SPSS Version 28. To determine the relative importance for each survey construct for perceptions of data trustworthiness, individual questions for each dimension were scored as follows: 0 (Not important), 1 (Low importance), 2 (Neutral), 3 (Important) and 4 (Very important). The overall mean was calculated for each dimension including the individual questions for each dimension. A spider chart was generated wherein each dimension had its own spoke. The spokes were evenly distributed around the wheel: the farther towards the end of the spike, the larger the value for each dimension (more important) and those nearer to the centre equated to closer to zero (less important). Chi-square, α = 0.05, was calculated in OpenEpi Version 3.01 (Dean et al., 2013), to identify associations between categorical variables. Fisher’s Exact Test was used where cell numbers were less than five.
Responses to the open-ended survey question, “Do you consider these data to be trustworthy? i.e., ‘‘the ability to be relied on as honest or truthful” were analysed using a two-stage approach. First, an inductive approach was used to derive relevant themes. Multi-part responses that contained different foci were separated and assigned to appropriate themes, thereby showing more comments than respondents. Second, once assigned to a theme, comments were classified as “positive (use of affirmative adjectives/descriptor),” “neutral (statement of fact)” or “negative (unfavourable adjective/descriptor)” (Riley et al., 2024: 5). A second reviewer then analysed each stage independently. Points of difference were resolved by discussion and mutual agreement.
Ethics
Ethics approval for the study was provided by the La Trobe University Human Research Ethics Committee [HEC21401] in 2022.
Results
Demographic characteristics and sample representativeness
Fifty-one respondents completed Part C and 50 completed Part D of the survey (12.8%, n = 51/399 and 12.5%, n = 50/399 respectively). There were 338 non-respondents and 11 who completed Parts A and/or B only (Riley et al., 2024). To determine representativeness, respondents were compared to the demographic details of 256/399 non-respondents for whom all demographic details were available. There was no statistically significant difference in gender (female:male, χ2 = 2.9, p = 0.2), highest educational qualification (PhD/doctoral degree:other, χ2 = 0.31, p = 0.58) or years of work experience (<20 years:20+ years, χ2 = 1.06, p = 0.3). However, there was a statistically significant difference between respondents and non-respondents for professional discipline (χ2 = 25.3, p = 0.001). There were proportionally more non-respondents than respondents with a medical degree (54% and 34% respectively), and proportionately more respondents than non-respondents with an epidemiological (14% and 7.8%) or psychology/behavioural science background (14% and 2%).
Trustworthiness of the datasets
In response to the question, “Do you consider these data to be trustworthy?,” most respondents (88%) answered “yes” (i.e. the data could be considered “honest or truthful,” Oxford Dictionary, n.d., online). There was one negative response and six were unsure. There were no statistically significant differences in age, gender, work experience, or professional discipline between those who trusted the data and those who did not or were unsure of its trustworthiness.
Factors influencing trust perception
Most constructs within data factors, both intrinsic and extrinsic, were considered by over 90% of respondents to be important/very important in influencing perceptions of data trustworthiness. The only data construct of lower importance (at 80%) was timeliness (Figure 1).
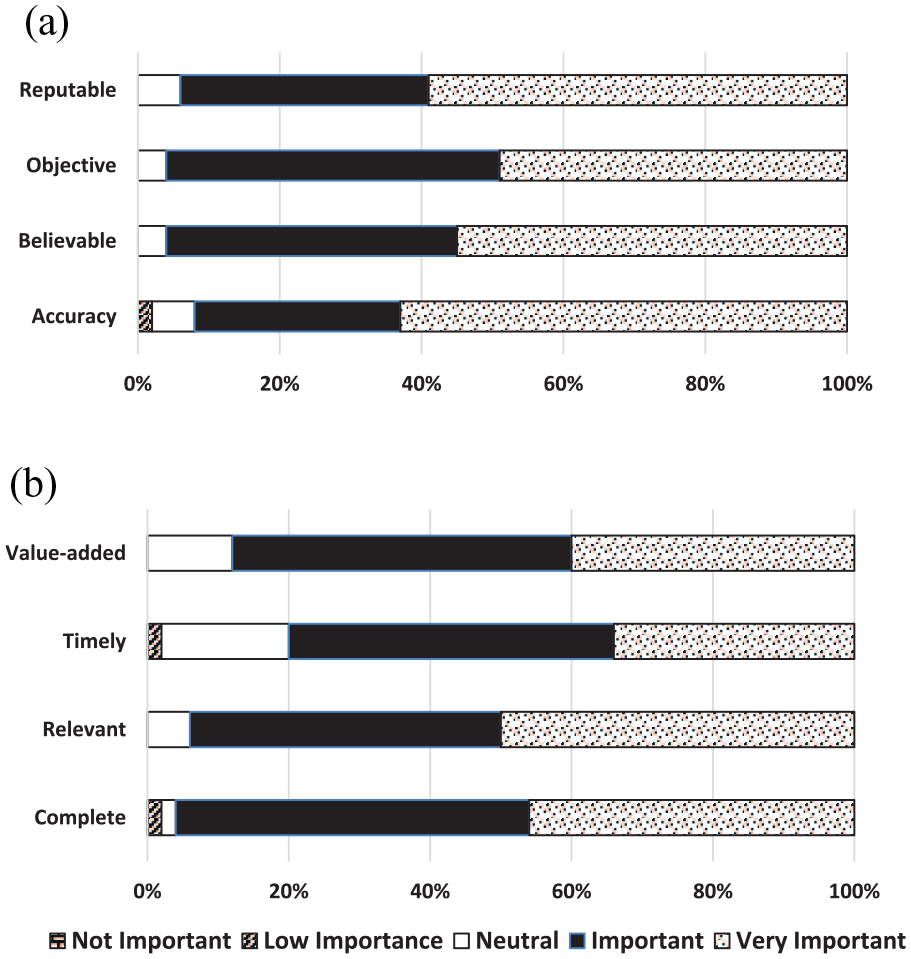
Level of survey respondents’ agreement on the importance of data factors for data trustworthiness. (a) DATA FACTORS – intrinsic properties. (b) DATA FACTORS – extrinsic properties.
Most constructs within data management properties were also considered to be important/very important in influencing perceptions of data trustworthiness. Contextual documentation (94%), accessibility and scientific rigour (90% each) were considered the most valuable data management constructs. The presence of data quality documentation was the least important data management construct for perceptions of trustworthiness (76%) (Figure 2).
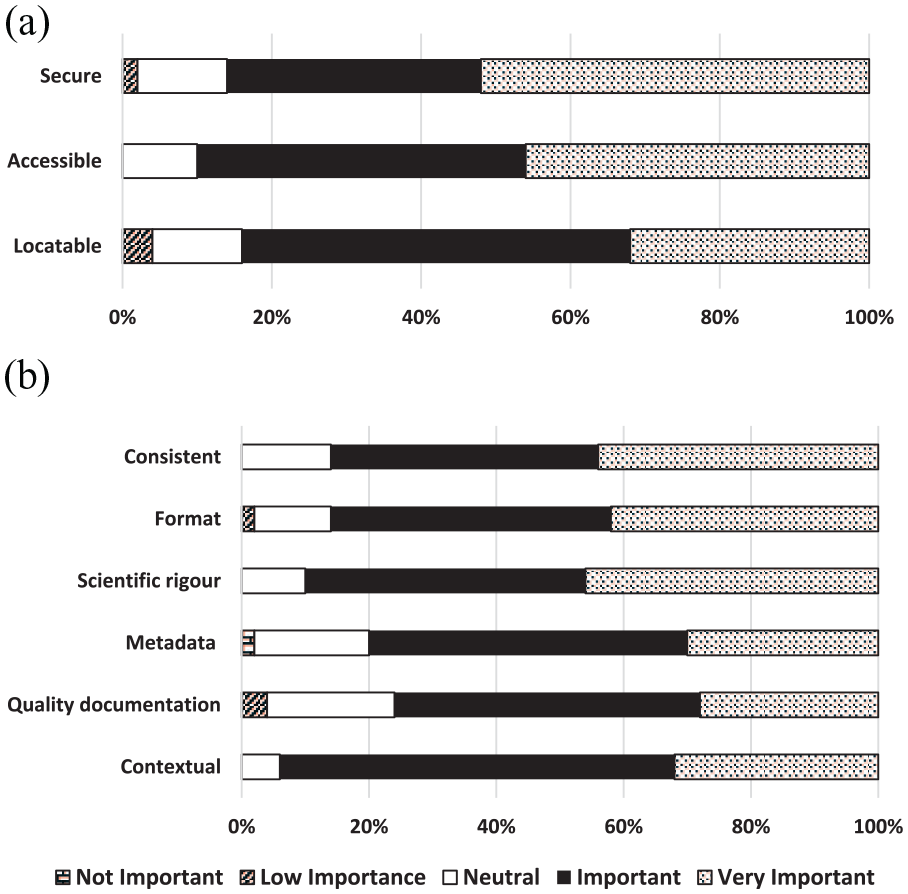
Level of survey respondents’ agreement on the importance of data management properties for data trustworthiness. (a) DATA MANAGEMENT PROPERTIES – Findability and accessibility. (b) DATA MANAGEMENT PROPERTIES – Interpretability and understandability.
Data provider factors had the highest proportion of constructs which respondents perceived as low/not important or neutral in influencing perceptions of data trustworthiness, including knowledge of “participant consent” (56%), the “major focus of the data provider was research” (50%), “data providers being experts in field of research” (42%) and “data is reviewed before circulation/publication” (40%). Conversely, the only construct among the 28 to be reported as important/very important by all respondents (100%) was “compliance with ethical regulation” (Figure 3). When analysing the importance of researchers knowing if “participant consent” had been obtained for the secondary use of data held in government datasets, medical researchers were significantly more likely to consider this of no/low/neutral importance compared to other researcher disciplines (χ2 = 6.2, p < 0.05). There was no significant difference between researchers’ age, gender or years of work experience and their perspectives on the importance of participant consent.
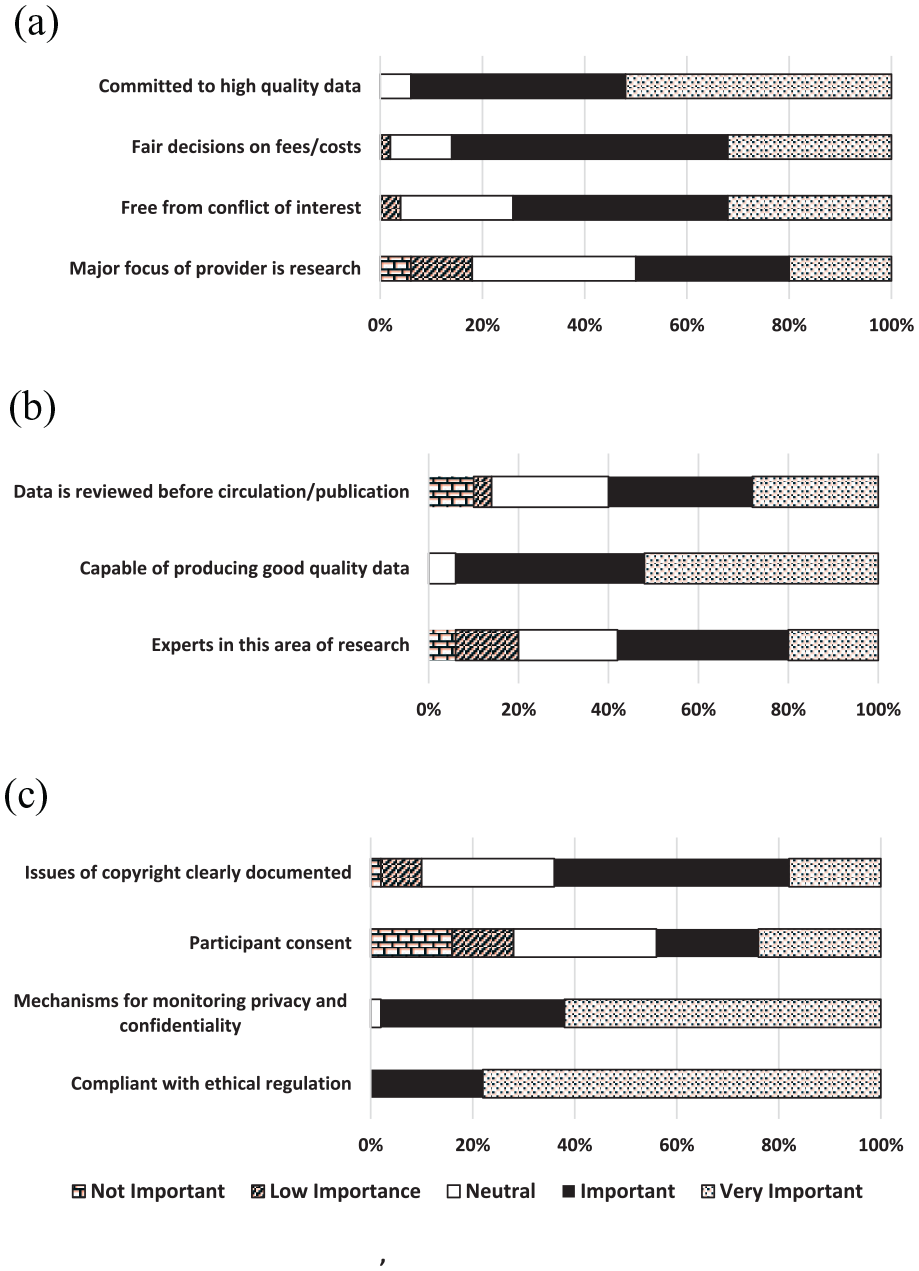
Level of survey respondents’ agreement on the importance of data provider factors for data trustworthiness. (a) DATA PROVIDER – Reputation. (b) Data PROVIDER – Ability. (c) DATA PROVIDER – Ethics.
Overall, the five constructs of greatest influence upon researchers’ perceptions of data trustworthiness (combining important/very important) were: compliant with ethical regulation (100%); mechanisms for monitoring privacy and confidentiality (98%); believability (96%); objectivity (96%); and completeness (96%).
Grouping constructs
When data were grouped and analysed according to the seven dimensions, data factors (extrinsic and intrinsic) and data management properties (findability and accessibility; interpretability and understandability) were more important than data provider factors (ethics, reputation and ability) in influencing researchers’ perceptions of data trustworthiness (see Figure 4).
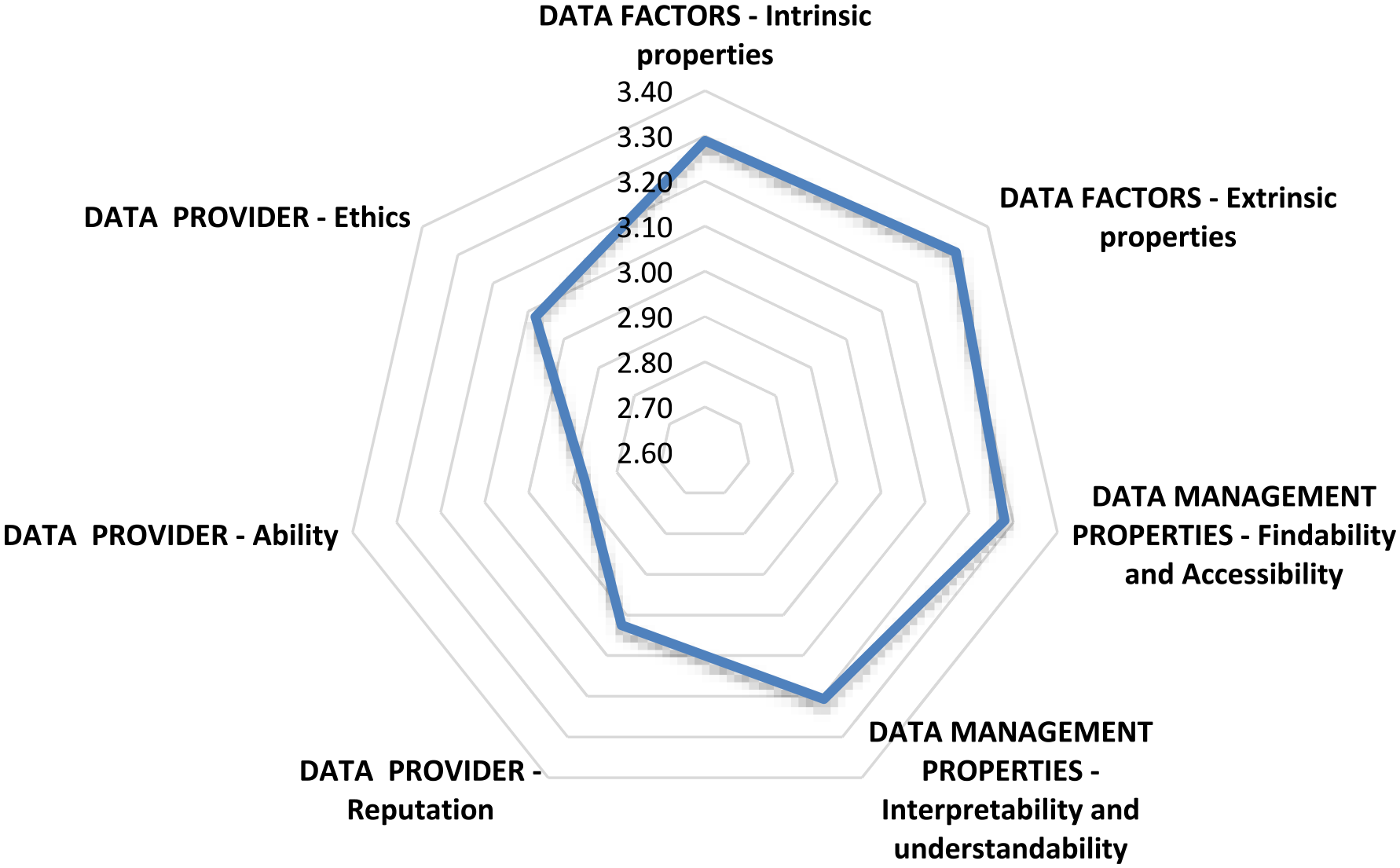
Relationship between grouped factors influencing researchers’ perceptions of data trustworthiness.
Qualitative comments in response to “Do you consider these data to be trustworthy?”
Eight themes were identified from respondents’ reasons for trusting the data (or not): data validation and quality processes; custodial staff or data collector; knowledge and relationship; reputation and output; purpose; data management and governance; content and coverage. Examples of qualitative statements reflecting the reasons for these responses are shown in Table 1. Fifty-eight free text responses were provided for this question; several were complex responses which, when analysed, comprised 79 points that were coded according to thematic foci (see Supplemental material Table S3).
Examples from the analysis of qualitative responses to the question “Do you consider these data to be trustworthy? i.e. ‘‘The ability to be relied on as honest or truthful”.

Of greatest importance in influencing respondents’ perceptions of data trustworthiness were data validation and quality processes, reflected in a quarter of all comments. Examples included comments related to “state of the art techniques” [Participant 3] or “as stated in the user manual . . .” [Participant 22]. Of equal importance in influencing respondents’ perceptions of trustworthiness were staffing – those who managed the data or completed data collection – and knowledge of, or relationship with, the dataset custodians/organisation. The phrasing, “I understand . . .” or “I understood . . .” was frequently used to indicate acceptance of trustworthiness. Conversely, several respondents commented that the type of custodial organisation responsible for the dataset influenced perceptions of trustworthiness [Participants 3, 6, 13, 16, 18, 46]; for example, “I feel the data is trustworthy as that is what is collected from hospitals” [Participant 16] or “I trust the government to produce decent data” [Participant 18].
Six respondents were unsure of the data trustworthiness: one did not provide a reason, one could not recall, three commented on the staff who collected the data as being very busy and sometimes prone to error and one commented that the administrative purpose of the data collection was insufficient to capture person experience. The one respondent who did not trust the data reported that data management processes and unhelpful staff had severely limited their use of the data; they indicated the data was only fit-for-purpose because they had conducted their own validation measures.
A sub-theme arising from some of the major themes that reflected researchers’ perceptions was an absence of reasons for the data to be untrustworthy, rather than the presence of reasons for it to be trustworthy. This was reflected in the following comments.
We have no reason to believe it is not trustworthy. [Participant 4]: theme-reputation and output
As good as mandatory data can be. [Participant 15]: theme-content
No strong reasons to introduce bias so errors should be at random. [Participant 17]: theme-content
There is no point manipulating de-identified data. [Participant 57]: theme-content
The data were collected for administrative purposes, there is no incentive to be untruthful. [Participant 8]: theme-purpose.
Discussion
Consumer and researcher trust in the government’s role as custodian of sensitive, personal data is vital to progress OGD initiatives (Biddle et al., 2018), as is the importance of ensuring the trustworthiness of the data that researchers access. The foci of this case-study were to determine whether researchers using Victorian government health datasets trusted the data, what factors impacted their perceptions of data trustworthiness and the implications of these for government policy and/or data custodians.
Researchers’ trust in government health datasets
Majority of the survey respondents expressed confidence in the trustworthiness of government health datasets. The high affirmative response rate may reflect the extensive experience of the researchers represented within this study. Previous studies have demonstrated that data reuse, and a positive attitude (e.g. trust) for data sharing, are influenced by age and experience, among other factors (Adjekum et al., 2018; Kim and Yoon, 2017).
Some free-text comments stated the reason for trusting the government data was the absence of reasons to mistrust it. This may reflect reliance upon the data rather than genuine trust (Hawley, 2014). Government health datasets often provide the only source of information on specific variables so researchers may be reliant upon them rather than explicitly trusting the data itself as “honest and truthful” (Oxford Dictionary, n.d.).
Factors influencing researchers’ perceptions of government health dataset trustworthiness
Most important factors for trust development
When grouped, the most important factors influencing researchers’ perceptions of government health data trustworthiness were data factors, followed by data management factors. This supports Yoon and Lee’s findings from their United States study, that data producer factors and data quality significantly influenced trust development whereas scholarly community and data intermediary factors (p. 1245) did not. Based upon our survey definitions, our “data provider” is equivalent to Yoon and Lee’s (2019) “data intermediary,” supporting their findings on the lesser importance of the data provider in trust development compared to data factors and data management properties. However, in our study some respondents (15%) identified, in qualitative statements, that the organisational reputation of the data provider was important in confirming data trustworthiness. While numbers were small, the responses reflect the multi-factorial nature of trust development (Taylor et al. 2023; Zhu, 2019).
(1) Data factors (intrinsic and extrinsic): Several studies have demonstrated that high quality (i.e. fewer errors, timely, complete, etc.) and well-curated data (i.e. supported by appropriate documentation for reuse) are more likely to engender trust for reuse purposes rather than poor quality or poorly curated data (Adjekum et al., 2018; Imker et al., 2021; Sielemann et al., 2020; Yoon, 2016). This is supported by our findings. All intrinsic and most extrinsic data constructs were reported by more than 90% of respondents to positively influence their perceptions of data trustworthiness.
Australia’s DATA Scheme (ONDC, 2023a) has created a positive environment for “trusted” users of government data. However, the legislation does not directly address “trusted data” factors (intrinsic and extrinsic) which our respondents identified as the most important influences on their perceptions of data trustworthiness. This suggests a need for government and data custodians to be more attentive in providing information on these intrinsic and extrinsic data factors within the context of the DATA Scheme and promote the concept of specific data standards to be met for data trustworthiness (e.g. “accredited data.”)
(2) Relationship with data providers: Almost 30% of free-text responses related to knowledge and relationship or reputation and output of the data custodians/providers as grounds for data trustworthiness. From two research consortiums in the United States Pasquetto et al. (2019) identified that scientists intending to reuse data showed a preference for working with the data creators. Liu et al. (2022) also found that Australian data reusers gained more meaningful insight and support with reusing data when they engaged with data producers, as distinct from data providers.
The nature of access to government data (i.e. centralised repository), especially administrative data, makes it difficult for data reusers to engage with data producers; however, data experts are associated with many government datasets. If there were opportunities for experts to interact with researchers, perceptions of data trustworthiness could be enhanced. There was no construct within our survey which specifically focussed on the “relationship” between data provider and reuser. The importance of this construct should be considered in development of trust models into the reuse of government health data.
(3) Compliance with ethical regulation: Our survey revealed that, proportionally, the most important individual construct in determining data trustworthiness (i.e. 100% of respondents identified this as important/very important) was the data provider being “compliant with ethical regulation.” The importance of this construct has been recognised by the Australian Government and integrated within the DATA Scheme (2022) (Cwlth), which relies upon the use of “Accredited Data Services Providers.”
Least important factors for trust development
(1) Knowledge of participant informed consent: The construct of least importance to researchers was knowledge of whether participant consent had been obtained for inclusion of participant data in the government datasets for reuse purposes. When reporting researchers’ knowledge and reuse practices of government health datasets from the same study population, Riley et al. (2024) highlighted that 78% of the respondents were unaware of whether informed consent had been obtained from participants involved in the datasets used. In this study, medical researchers were significantly less concerned with knowledge of participant consent for perceptions of data trustworthiness compared to researchers from other disciplines. Traditionally, medical professionals have been more active proponents of informed consent than social scientists (Hoeyer et al., 2005). Hutchings et al.’s (2021: 1) findings on “stakeholder perceptions of consent for the use of secondary data” demonstrated varying respondent attitudes to the need for additional consent for reuse of data which may have been impacted by age, gender, education, ethnicity or location. Our findings demonstrated that researchers’ perceptions of data trustworthiness were influenced more by data provider transparency surrounding legal obligations than by transparency to consumers on how their data were being used. Data custodians, on behalf of consumers, should inform researchers about whether or not participant informed consent has been obtained by acknowledging this openly on their dataset websites.
(2) Trust factors related to data provider. Data provider factors that were of least importance to 40–50% of researchers in their perception of data trustworthiness related to reputation (i.e. “Was the major focus [of the data provider] research?” and “Were they the experts in their field?”). Results from other studies are mixed on the importance of the data provider’s reputation (Kelton et al., 2007). Our findings may reflect the many experienced health researchers among our respondents who were discipline experts and, consequently, less concerned about the expertise of data providers.
Limitations
Measuring trust is subjective due to the complex, multi-factorial influences on trust development. We attempted to minimise this by providing construct definitions. PytlikZillig et al. (2016) demonstrated that how trust constructs were measured, and within what contexts they were measured, could affect their relative importance. They concluded it was best to consider each construct separately within its own context (PytlikZillig et al., 2016). Therefore, findings from the grouped dimensions of data factors, data management properties and data provider factors need to be interpreted with caution where they are not supported by the analysis of the individual constructs.
Author sourcing of non-respondent demographic details via relevant websites to determine sample representativeness did not allow for self-identification by non-respondents. Therefore, author interpretation of demographic variables (gender, highest educational level, years of work experience and discipline) may differ from how non-respondents would have answered the questions.
The sample size for this study was small. Notwithstanding this limitation, respondent characteristics were representative of the non-respondents’ characteristics of gender, highest educational level and years of work experience, but not of discipline. That is, proportionately more epidemiologists and psychologists completed the survey than medical researchers; non-response by medical researchers is not unique to this survey (Wiebe et al., 2012).
Implications for government and data custodians
In relation to OGD, government policies for trust-building currently place most emphasis on the role and reputation of data service providers (i.e. who “link” data) and data users (who access the data) (Lin, 2020). This has been demonstrated in Australia by the rise of accredited integrating authorities under the Population Health Research Network (PHRN, 2021), and built into the DATA Scheme (ONDC, 2023a). The quality of the data itself is assumed to be “clean” despite the absence of clear documentary evidence (Australian Government, n.d.).
While the emphasis on the accredited data service providers and accredited data users addresses some of the trustworthiness constructs considered by researchers to be important in influencing perceptions of health data trustworthiness (e.g. compliant with ethical regulation), it does not address the most important constructs related to data factors (e.g. reputable, objective, believable, accurate). Our survey findings both affirm government/data custodians’ current policies and practices in creating perceptions of data trustworthiness (88% of researchers trust Victorian government health data) and identify areas which require improvement. Researcher trust would be increased more effectively if government increased the focus on the data itself. We recommend the following:
Government should ensure the DATA Scheme incorporates mechanisms to validate that data utilised by accredited data users and accredited data providers has sufficient integrity (intrinsic and extrinsic) to meet the requirements of “trustworthiness” and that documentation is provided to support this, that is, “accredited data.”
Data custodians, on behalf of Government as data “owners,” should provide researchers with a point of contact with dataset experts to enhance trust and usefulness of the data.
Data custodians should ensure that issues of participant informed consent are highlighted in plain language statements on information asset websites and brought to the attention of researchers to increase their knowledge of informed consent for the ethical, transparent and trustworthy use of health data.
Trust concepts related to “relationship” between data provider and researcher should be incorporated into any further investigation into perceptions of government health data trustworthiness.
Supplemental Material
sj-docx-1-him-10.1177_18333583241256049 – Supplemental material for Researchers’ perceptions of the trustworthiness, for reuse purposes, of government health data in Victoria, Australia: Implications for policy and practice
Supplemental material, sj-docx-1-him-10.1177_18333583241256049 for Researchers’ perceptions of the trustworthiness, for reuse purposes, of government health data in Victoria, Australia: Implications for policy and practice by Merilyn Riley, Monique F Kilkenny, Kerin Robinson and Sandra G Leggat in Health Information Management Journal
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MFK received Future Leader Fellowship (105737) support from the National Heart Foundation of Australia. All other authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.