
Abstract
Background:
Rheumatology has experienced notable changes in the last decades. New drugs, including biologic agents and Janus kinase (JAK) inhibitors, have blossomed. Concepts such as window of opportunity, arthralgia suspicious for progression, or difficult-to-treat rheumatoid arthritis (RA) have appeared; and new management approaches and strategies such as treat-to-target have become popular. Statistical learning methods, gene therapy, telemedicine, or precision medicine are other advancements that have gained relevance in the field. To better characterize the research landscape and advances in rheumatology, automatic and efficient approaches based on natural language processing (NLP) should be used.
Objectives:
The objective of this study is to use topic modeling (TM) techniques to uncover key topics and trends in rheumatology research conducted in the last 23 years.
Design:
Retrospective study.
Methods:
This study analyzed 96,004 abstracts published between 2000 and December 31, 2023, drawn from 34 specialized rheumatology journals obtained from PubMed. BERTopic, a novel TM approach that considers semantic relationships among words and their context, was used to uncover topics. Up to 30 different models were trained. Based on the number of topics, outliers, and topic coherence score, two of them were finally selected, and the topics were manually labeled by two rheumatologists. Word clouds and hierarchical clustering visualizations were computed. Finally, hot and cold trends were identified using linear regression models.
Results:
Abstracts were classified into 45 and 47 topics. The most frequent topics were RA, systemic lupus erythematosus, and osteoarthritis. Expected topics such as COVID-19 or JAK inhibitors were identified after conducting dynamic TM. Topics such as spinal surgery or bone fractures have gained relevance in recent years; however, antiphospholipid syndrome or septic arthritis have lost momentum.
Conclusion:
Our study utilized advanced NLP techniques to analyze the rheumatology research landscape and identify key themes and emerging trends. The results highlight the dynamic and varied nature of rheumatology research, illustrating how interest in certain topics has shifted over time.
Keywords
Introduction
Over the past decades, the volume of academic literature has experienced significant growth.1,2 The field of rheumatic and musculoskeletal diseases (RMDs) has not been immune to this growth (Supplemental Figure 1). Moreover, RMDs have undergone an unprecedented change in recent years. To begin with, a drug development revolution took place in the early 2000s—which is still active today—with the arrival of promising drugs such as biologic agents or Janus kinase (JAK) inhibitors.3–5 Furthermore, the adoption of therapeutic strategies, such as treat-to-target, 6 the earlier initiation of disease-modifying treatments, or the paradigm shift in how diseases are analyzed, not only by their mortality rate but also by their disability, propitiated a new scenario for RMDs.7,8 Concepts such as the window of opportunity, 9 arthralgia suspicious for progression, 10 erosive disease, 11 or difficult-to-treat rheumatoid arthritis (RA) 12 have gained momentum.
In this context of continuous change, we hypothesize that the study of trends in scientific publications could be beneficial to better understand the historical research priorities in rheumatology and the evolving landscape of RMD management and treatment. However, with almost 100,000 original articles published in the last 23 years, the process of comprehending and identifying the main trends is becoming increasingly challenging.
Conventional review methods can be labor-intensive, overwhelming or unfeasible, and non-exhaustive. Hence, we propose the use of modern natural language processing (NLP) techniques to characterize the evolution of the research topics addressed over time in rheumatology scientific publications. Topic modeling (TM) techniques are ideally suited for this, as they can model the evolution of topics over time. Briefly, TM is a suite of unsupervised learning algorithms (i.e., no tags/labels are provided with the input data), within the field of machine learning, designed to identify prevalent topics within a corpus of documents, usually through probabilistic methods.13,14 In that collection, the documents are observed while the topic structure (i.e., the topics, per-document topic distributions, and the per-document per-word topic assignments) is hidden.15,16 The outcome of a typical TM algorithm is clusters of related words. These techniques operate under the assumption that each topic is defined by a distinct collection of words and that a document consists of a blend of multiple topics in varying proportions. One of the most widely used TM techniques is Latent Dirichlet Allocation (LDA), a generative probabilistic model. However, with the recent advances in NLP and the introduction of the transformer’s architecture, new TM techniques that consider semantic relationships among words and their context have arisen (i.e., BERTopic).
Consequently, this study aims to apply BERTopic, a state-of-the-art TM technique, to analyze 20 years of rheumatology research within specialty journals. By mapping thematic trends, we aim to reveal both long-term research priorities and shifts in focus areas, providing insights into evolving themes and pinpointing research strengths and potential gaps.
Related work
TM has been used in a multitude of fields, including social networks, software engineering, crime science, political science, geography, medicine, and linguistics. 17 In addition, it has proven effective in analyzing historical documents such as newspapers and humanistic texts, 18 as well as in educational research, 19 and the study of organizational phenomena. 20
TM has been widely applied in rheumatology research. Tedeschi et al. 21 employed a TM approach, sureLDA, followed by penalized regression, to predict pseudogout probability in large datasets. TM was also applied to characterize the temporal evolution of ANCA-associated vasculitis (AAV). 22 Temporal trends, in more than 113,000 clinical notes, before and after the treatment initiation date for a diagnosis of AAV, were modeled with LDA, finding 90 different topics that included diagnosis (e.g., granulomatosis with polyangiitis), treatments (e.g., AAV specific-treatment), and comorbidities and complications of AAV (e.g., glomerulonephritis, infections, skin lesions).
A prior study conducted by Dzubur et al. 23 explored the application of TM to understand the concerns and perceptions of patients with ankylosing spondylitis regarding biological therapies. The researchers analyzed over 25,000 social media posts using LDA and identified 112 topics. Medication uncertainty, lack of trust in physician’s decisions, patient worries, and seeking alternative treatments highlighted were those most prevalent.
On its behalf, Li and Yacyshyn 24 analyzed the posts published over a year in the Reddit subforum “r/Behcet” to investigate the perspectives and experiences of people affected by Behcet’s disease. The authors identified 6 themes and 16 subthemes, including finding connectedness through shared experiences, the struggles of the diagnostic odyssey, and sharing or inquiring about symptoms.
Tang et al. 25 pursue to uncover the themes present in the electronic health record (EHR) of patients with RA prior to the start of targeted treatments and to explore their relationship with the subsequent course of treatment. On the other hand, Flurie et al. 26 evaluated two social media communities, a Facebook group, and a public subreddit (i.e., r/gout), identified 30 topics, and conducted sentiment analysis.
Moreover, Eaneff et al. 27 characterized systemic lupus erythematosus (SLE) patients’ experiences in an online health community by applying LDA in free-text data extracted from the PatientsLikeMe community.
Eventually, Sperl et al. 28 applied LDA to analyze responses to open-ended questions from an online survey designed to assess motivations among health professionals for participating in postgraduate rheumatology education and to identify barriers and facilitators for participation in current EULAR educational offerings.
Supplemental Table 1 shows the most relevant characteristics of each study discussed above.
Materials and methods
Materials
Data from the RheumaLpack corpus, 29 which includes 96,004 rheumatology-related abstracts along with associated metadata, up to 19 variables including title, PMID/DOI, abstract, publication year, journal, keywords, or volume, were extracted. The criteria that were applied to select the articles used in the present work were as follows:
- Indexed in MEDLINE PubMed,
- A publication date between January 1, 2000 and December 31, 2023, both included,
- Belonging to journals classified by the 2023 Journal Citation Reports (Supplemental Table 2) as “RHEUMATOLOGY—SCIE,” and
- With an available abstract.
Briefly, the process that was followed to obtain the articles included the following steps: (a) we performed manual queries to retrieve PMIDs from PubMed, with the name of each journal followed by “[Journal]” (e.g., “Annals of the rheumatic diseases” [Journal]; Supplemental Table 3 shows the search strategy for each journal), saved using the PubMed save settings, and merged into a single document (122,426 PMIDs were recovered this way); (b) next, we used R’s rentrez library to collect the following information from each retrieved PMIDs: DOI, MeSH keywords, volume, issue, pages, abstract, has abstract, publication type, language, PubMed central papers citation, sort first author, and affiliation. These data were gathered in three batches: the first batch contained the abstract and other publication details such as Medical Subject Headings (MeSH) keywords; the second batch containing the language, the publication type, and the PubMed central papers citation; and the third one containing the affiliation data. The remaining variables (i.e., title, authors, citation, journal/book, publication year, create date, PMCID, and NIHMS ID) were directly retrieved from the PubMed webpage, during the previous step; (c) Finally, not all the selected articles had an abstract since this information is only collected for a certain type of articles (e.g., original research articles, reviews); therefore, we excluded those without this information.
BERTopic was used for TM. 30 This technique generates topic representations through three steps. First, each abstract is converted into a vector representation (i.e., embeddings), using language models (e.g., all-mpnet-base-v2). Abstracts with similar meanings will have closely related vector representations, making them more likely to be grouped into the same topic. Second, since the generated vectors are of high dimensionality, they are transformed to reduce dimensionality and make clustering less computationally intensive and more efficient. This is achieved with a dimensionality reduction algorithm (e.g., UMAP). Following this, the reduced embeddings are grouped using clustering algorithms (e.g., HDBSCAN) to form distinct topics. Third, the significance of each word within a topic is calculated using a weighting scheme (i.e., c-TF-IDF). For more details, see the “Supplemental BERTopic: topic representation generation” section and Supplemental Figure 2.
Methodology
The abstract, title, publication year, and journal information for the 96,004 original articles were retrieved from the RheumaLpack corpus. The number of tokens per abstract was computed to guide the selection of the embedding model. This is crucial because texts that exceed the model’s maximum length limit are truncated during the embedding process, leading to a loss of information. Depending on the median token size, two options were considered: (a) to concatenate the title and the abstract, so only a complete and single text for each article is studied and (b) to focus the study solely on abstract information.
Data pre-processing was omitted to preserve the original text structure, which is relevant for transformer-based models to effectively comprehend the context. Hence, stopwords were not omitted. From here onward, the modular approach of BERTopic was applied, with considerations made for each step. For a more detailed explanation of how BERTopic’s modularity features were applied, please refer to the “Supplemental BERTopic: methodology followed and application” section.
The number of words extracted per topic was set to 20 (i.e., top_n_words), as the optimal number of words in a topic is between 10 and 20. Beyond this range, topics tend to lose coherence. We explored all potential combinations involving two embedding models (i.e., all-mpnet-base-v2 and S-PubMedBert-MS-MARCO), three different dimensionality reduction UMAP initialization states (i.e., seeds 42, 52, and 62), and five cluster minimum size values (i.e., 50, 100, 150, 200, and 250). A total of 2 × 3 × 5 = 30 models were explored.
Two final models were selected for further analysis: one using all-mpnet-base-v2 and the other using S-PubMedBert-MS-MARCO. This selection was based on several criteria, including the number of outliers, the number of topics, and the topic coherence score (i.e., u_mass). The chosen models were required to contain fewer than one-third of the total documents classified as outliers (n < 32,000), support more than 40 topics, and minimize the u_mass score. This score is an intrinsic evaluation method (i.e., measures the quality of the topic model itself without considering any specific external task) that evaluates the quality of a topic based on co-occurrences of word pairs, 31 which was introduced in the study conducted by Mimno et al. 32 Other coherence measures were calculated (i.e., c_v, c_nmpi, and c_uci) but the final decision was guided by u_mass. Afterward, outliers were excluded from the analyses.
After analyzing the keywords and the different topic representations, the topics were labeled through a mutual agreement among DF-N and LR-R authors. (B) Tag was used to identify basic science topics, and (C) tag was used to identify clinical science topics. Word clouds were generated to show the keywords linked to the topics and the topics’ distribution. The size of each word is proportional to its relevance to the topic. Hierarchical clustering representations were generated to show how topic embeddings can be combined at various cosine distances. Dynamic TM was employed to explore the evolution of topics over time, using the two selected models.
Eventually, we applied the same methodology described in Karabacak and Margetis 33 to model trends. The publication year and the topic probabilities (i.e., the probability of an abstract being classified under a particular topic based on its content) were retrieved. The mean topic probability per publication year and per topic was computed. Bivariate linear regression models were developed for each topic, with the mean topic probability serving as the dependent variable, and the publication year as the independent variable. By examining the slopes of these regression lines, topics were categorized as hot if they had positive slopes and cold if they had negative slopes.
All models were trained in Google Colab, with a T4 GPU and a high-RAM runtime, using Python.
The reporting of this study conforms to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR) Checklist 34 (Supplemental File PRISMA Checklist). Although this article is not a scoping review per se, we found this checklist to be the most suitable for reporting our work.
Results
The number of articles retrieved per year and journal can be found in Supplemental Table 4. The median number of tokens per abstract was 375 (Q1: 287, Q3: 442). When combining both the abstract and title, the median was 401 (Q1: 310, Q3: 471); therefore, we chose to analyze only the abstract. The number of topics identified by the models ranged from 42 to 296, while the number of initial outliers ranged from 19,075 to 35,332. In Supplemental Table 5, the results of the 30 trained models are shown, including the minimum cluster size, the seed, the number of topics and outliers, and the coherence score values. As the number of topics decreases (and the number of the minimum cluster size increases), the topic coherence scores are better. In Supplemental Excel File Models Output, the topic number, the count, the default topic name, the different topic representations, and the three abstracts that best encapsulate the thematic content of each topic are shown. Supplemental Excel File Top 5 Topics shows the five topics with the highest number of documents for all models.
The model that exhibited the lowest u_mass coherence score utilized a minimum cluster size of 250, with seed values of 52 for the all-mpnet-base-v2 model (−0.279) and 42 for the S-PubMedBert-MS-MARCO model (−0.288). A total of 73,736 and 69,316 abstracts were classified into 47 topics and 45 topics for the all-mpnet-base-v2 and the S-PubMedBert-MS-MARCO models, respectively. The remaining documents were classified as outliers and discarded. Tables 1 and 2 present a detailed overview of the topics, outlined by a unique set of keywords that capture their essential themes.
Summary of the topics for the all-mpnet-base-v2 model.

Summary of the topics for the S-PubMedBert-MS-MARCO model.

JAK, Janus kinase.
Hierarchical clustering plots and word clouds for the top 10 topics are shown in Supplemental Figures 3 and 4, and 5 and 6, respectively.
Regarding the dynamic modeling of topics, for each model, we studied the themes in batches of 10. Figures 1 and 2, and Supplemental Figures 7 and 8 show the results. Moreover, a bar chart of the hot and cold topics for the two models is displayed in Figures 3 and 4. Finally, a comparison of the topics of the two final models is presented in Supplemental Table 6.
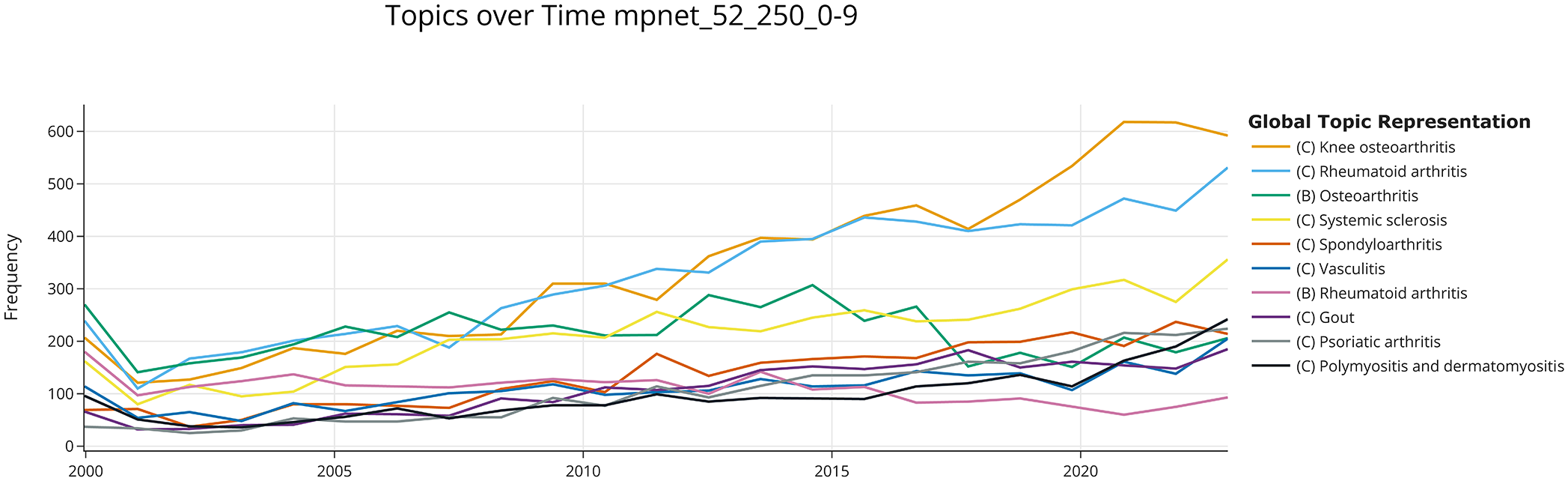
Dynamic topic modeling of the best all-mpnet-base-v2 model.
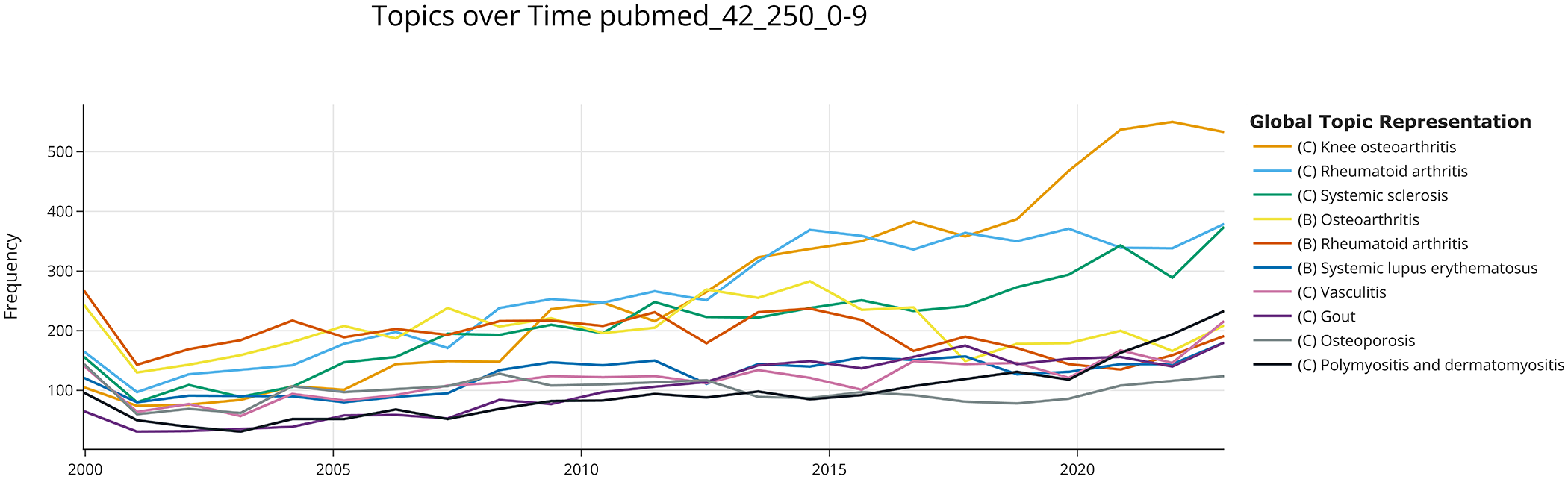
Dynamic topic modeling of the best S-PubMedBert-MS-MARCO model.

Bar chart of hot and cold topics. All-mpnet-base-v2 model.

Bar chart of hot and cold topics. S-PubMedBert-MS-MARCO model.
Trends in rheumatology
When comparing the top 10 topics identified in the two models, all-mpnet-base-v2 and S-PubMedBert-MS-MARCO, there is considerable overlap between them. This overlap could lend credibility to the findings. For instance, 8 of the 10 primary topics were consistent across the models, with (C) Knee osteoarthritis, and (C) Rheumatoid arthritis being the most studied topics. The relevance of (C) Spondyloarthritis, (C) Psoriatic arthritis, (B) Systemic lupus erythematosus, and (C) Osteoporosis topics differ between both models. However, when combining all the topics related to RA and SLE, the number of documents is 13,927 and 5950 for the all-mpnet-base-v2 model, and 13,297 and 7149 for the S-PubMedBert-MS-MARCO. Therefore, globally, the three most studied topics are RA, SLE, and OA.
Some of the topics expected to be found (e.g., (C) COVID-19 and (C) JAK inhibitors) were present after applying dynamic TM, which further strengthens the reliability of the results. Conversely, other unexpected topics such as (C) Spinal surgery or (C) Bone fractures have gained relevance in recent years. As shown in Figures 3 and 4; (C) Gout, (C) Spondyloarthritis, and (C) Psoriatic arthritis are nowadays hot topics, whereas (C) Antiphospholipid syndrome, (C) Septic arthritis, or (C) Reactive arthritis are cold topics.
As the final number of topics is relatively low, no specific topics related to artificial intelligence (AI) or new statistical learning techniques that became popular a few years ago, such as trajectory analysis, were identified. However, when analyzing models with a higher number of topics such as all-mpnet-base-v2 (minimum number of cluster: 50, seed: 42), we found the following topics: [learning, machine, algorithms, machine learning, algorithm, ai, deep learning, artificial intelligence, artificial, intelligence]. Something similar occurs with social media data topic [websites, internet, information, social media, readability, search, media, social, google, online], with telemedicine [app, apps, mobile, smartphone, digital, application, care, health, mhealth, patient], and with wearables: [app, apps, mobile, smartphone, digital, application, care, health, mhealth, patient]. A similar situation appears when considering topics related to patients’ education, a fundamental issue in rheumatology. Hence, the use of models with a larger number of topics could be useful to identify new emerging trends. See Supplemental Excel File Models Output.
Discussion
We applied BERTopic, an NLP-based TM technique, to explore trends and research themes within rheumatology journals over the past 23 years. Our study uncovered 45 and 47 distinct topics when using the models with the greatest topic coherence. These topics represent a wide array of clinical and basic research areas, demonstrating the heterogeneous nature of RMDs. Shifts in emerging and declining areas of focus were also assessed. The three most populated topics, common to both models, were those related to the clinical aspects of knee OA (kOA), RA, and systemic sclerosis (SSc). The frequent focus on kOA and RA aligns with their significant prevalence and burden, which drives research aimed at improving disease outcomes.35–37 SSc, a complex multisystem disorder, continues to garner attention due to recent advances in diagnosis and therapeutic approaches, including the development of targeted treatment strategies. 38
Our analysis of research trends reveals a significant shift in publication priorities. The “hottest” topics (clinical research in kOA, COVID-19, and spinal surgery) offer further insight into current clinical priorities. The increasing attention on kOA may be related to a growing interest in the study of risk factors, and other clinical aspects of this condition, considering the aging population and the rising incidence of degenerative joint diseases. 39 COVID-19, as expected, emerged as a significant focus, reflecting its impact on RMDs, including how the pandemic has influenced the management of immunosuppressive therapies in rheumatology. 40
The rise in “spinal surgery”-related research corresponds to the significant burden of low back pain (LBP), the leading cause of disability. 41 Degenerative spine conditions, such as disc degeneration, lumbar stenosis, and spondylolisthesis, are among the main causes for LBP 42 and spinal surgeries, 43 despite limited evidence supporting its use for degenerative LBP, except in cases involving radiculopathy, neurogenic claudication, cancer, or infection. 44 Nonetheless, studies have shown an increase in surgical interventions for LBP.44,45
Conversely, certain topics have cooled off, such as antiphospholipid syndrome (APS), and OA and RA basic research. This decline could signal that the foundational understanding of these areas has stabilized, or that fewer groundbreaking developments have emerged recently. For example, APS treatments have not seen significant breakthroughs in recent years. 46
Regarding RA and OA basic research, the substantial progress made in understanding their pathophysiology may have shifted the research focus toward translating this knowledge into clinical applications, such as the development of new therapies for RA. 47 For OA, research emphasis may have moved toward prevention strategies, non-pharmacological management, and personalized medicine approaches.48–50
The use of TM techniques on PubMed abstracts is not new. These methods have been used in different medical fields for trend analysis and for uncovering hidden topics over the past few years. For example, Sperandeo et al. 51 evaluated the usage of “personality” and “mental health” terms within the titles and abstracts of articles published in PubMed from 2012 to 2017. The researchers employed LDA on more than 7500 abstracts and found 30 topics organized in 8 hierarchical clusters, concluding that personality is linked to a broad spectrum of conditions. The suitable number of clusters was determined using a five-fold cross-validation approach.
Tighe et al. 52 applied TM on a corpus of more than 200,000 abstracts related to pain. The abstracts collected, retrieved through searches using the “pain” [MeSH] term, corresponded to articles published between 1949 and 2017. On this occasion, both LDA and latent semantic indexing techniques were employed. After following a topic coherence strategy, the researchers identified an optimal topic count of 40. One of the conclusions of this research was that TM can help identify critical research avenues by evaluating the gaps in the literature concerning a specific topic.
On their behalf, Abba et al. 53 focused on the use of TM techniques to uncover hidden topics from 100 years of peer-reviewed hypertension publications (i.e., 1900–2018). LDA was applied to more than 580,000 abstracts. Most of the identified topics, n = 20, fell into four distinct categories: preclinical, epidemiology, complications, and treatment-related studies. Topic trends were evaluated by calculating the annual proportion of abstracts for each topic relative to the cumulative total of articles associated with that topic.
Shi et al. 54 examined AI-related studies published in PubMed, from 2000 to 2022, to highlight the current situation of medical AI research and to provide insights into its future developments. With that aim, scholars downloaded metadata from 307,000 articles (e.g., title, abstract, journals, authors) and applied LDA to titles and abstracts. They divided the data into intervals of 5 years, performing unique TM for each period. The authors presented the five main topics in eight different domains of AI. These domains were described by the European Commission Joint Research Centre.
Depression, anxiety, and burnout in academia were studied using BERTopic. 55 The authors extracted 2846 abstracts from PubMed ranging from 1975 to 2023 using a complex query that did not include MeSH terms. Afterward, the authors compared BERTopic models with different sets of parameters, each of them being run three times. The best model was chosen based on different criteria (i.e., proportion of outliers, topic interpretability, topic coherence, and diversity); this model comprised 27 topics. After studying their evolution, the authors showed, among others, how the COVID-19 pandemic influenced the burnout of medical professionals.
Eventually, Grubbs et al. 56 studied the topics present in a specific academic journal—Gynecologic Oncology—over a 30-year period (i.e., 1990–2020), as well, as the interest in them over time. With that aim, they used LDA on 11,200 abstracts and determined the number of topics using the coherence score. The best model contained 26 topics, and 3 of them were merged after manual assessment by 3 reviewers. Thanks to the experiments carried out, researchers could hypothesize the evolution of some topics related to oncology gynecology for the next years, such as an increase in surgical topics and epidemiological and health outcomes research topics; and a decrease in chemotherapy and radiation.
As can be seen from the above studies, there is a real interest in uncovering latent topics in medical documentation. In this study, we have demonstrated how dynamic TM can be applied to abstracts indexed in PubMed, and published in Rheumatology journals from 2000 to 2023.
To the best of our knowledge, the BERTopic approach has not been previously applied to examine trends within this medical field. A potentially more intriguing application of dynamic TM would involve its use with EHR data, to characterize the natural history of diseases. This approach was taken a few years ago, but applying LDA over AAV histories. 22
Furthermore, each clinical note could be categorized into specific topics. Should there be a requirement for a manual review of the record contents, pre-classifying them by topic could assist physicians in assembling patient cohorts for targeted studies.
Finally, these models could be used as recommendation systems to direct unpublished scientific articles to the journal that maximizes their likelihood of publication based on the latent topics contained in the abstract and other structured data (e.g., year, affiliation of the first author).
Strengths and limitations
The study’s findings can offer practical insights for healthcare and policy. By identifying evolving research trends, this analysis allows the assessment of whether rheumatology research aligns with global health priorities, such as those in the Global Burden of Disease study. This alignment could help optimize resource allocation and support efficient policymaking for prevalent, high-cost diseases. The “hot” and “cold” topic analysis can further guide research funding toward areas with significant clinical potential. In addition, understanding these trends enables healthcare systems to anticipate future demands, particularly for conditions like OA, informing public health strategies and ultimately enhancing patient outcomes and healthcare efficiency. However, this study has limitations. Our analysis window begins in 2000, missing the early evolution of biological agents introduced in 1999. TM carries subjectivity, and BERTopic assumes each document covers only one topic, potentially overlooking multifaceted articles. Limiting our dataset to rheumatology journals ensures focused results but may exclude interdisciplinary perspectives. While a broader journal scope could offer a fuller view, varying editorial standards may also complicate trend analysis. Research trends are not correlated with other metrics, such as patents or clinical trials. In addition, patient education was not a predominant theme despite its complementary role in disease management, especially for conditions like fibromyalgia, where programs promoting patient-centered care and self-management (e.g., “Amigos de Fibro” 57 ) can significantly improve quality of life. Finally, by limiting the corpus to rheumatology-specific journals, our thematic analysis may primarily reflect traditional or well-established themes within rheumatology, potentially overlooking emerging interdisciplinary perspectives that appear in broader medical or life sciences journals. However, considering that a substantial number of papers within each topic is critical for creating well-defined themes in TM, including isolated or infrequent papers from non-specialized journals would likely have resulted in outliers rather than cohesive topics, thus compromising the robustness of the analysis. Furthermore, research with significant interdisciplinary impact, such as COVID-19 studies, often migrates into rheumatology journals as its relevance to the field becomes apparent. Therefore, we believe this approach provides a balanced view of core research trends while capturing key interdisciplinary developments.
Conclusion
To our knowledge, this is the first study that uses BERTopic, and dynamic TM to identify the key topics in rheumatology research using a set of abstracts extracted from PubMed. The two-sentence embedding models employed provided similar results, highlighting the dynamic and varied nature of rheumatology research and illustrating how interest in certain topics has shifted over time. As the number of scientific publications increases, the use of NLP techniques will be necessary to efficiently analyze and synthesize information, helping to identify trends, gaps, and emerging areas of interest across various medical fields.
Supplemental Material
sj-docx-1-tab-10.1177_1759720X241308037 – Supplemental material for Mapping two decades of research in rheumatology-specific journals: a topic modeling analysis with BERTopic
Supplemental material, sj-docx-1-tab-10.1177_1759720X241308037 for Mapping two decades of research in rheumatology-specific journals: a topic modeling analysis with BERTopic by Alfredo Madrid-García, Dalifer Freites-Núñez, Beatriz Merino-Barbancho, Inés Pérez Sancristobal and Luis Rodríguez-Rodríguez in Therapeutic Advances in Musculoskeletal Disease
Supplemental Material
sj-xlsx-2-tab-10.1177_1759720X241308037 – Supplemental material for Mapping two decades of research in rheumatology-specific journals: a topic modeling analysis with BERTopic
Supplemental material, sj-xlsx-2-tab-10.1177_1759720X241308037 for Mapping two decades of research in rheumatology-specific journals: a topic modeling analysis with BERTopic by Alfredo Madrid-García, Dalifer Freites-Núñez, Beatriz Merino-Barbancho, Inés Pérez Sancristobal and Luis Rodríguez-Rodríguez in Therapeutic Advances in Musculoskeletal Disease
Supplemental Material
sj-xlsx-3-tab-10.1177_1759720X241308037 – Supplemental material for Mapping two decades of research in rheumatology-specific journals: a topic modeling analysis with BERTopic
Supplemental material, sj-xlsx-3-tab-10.1177_1759720X241308037 for Mapping two decades of research in rheumatology-specific journals: a topic modeling analysis with BERTopic by Alfredo Madrid-García, Dalifer Freites-Núñez, Beatriz Merino-Barbancho, Inés Pérez Sancristobal and Luis Rodríguez-Rodríguez in Therapeutic Advances in Musculoskeletal Disease
Footnotes
Acknowledgements
The authors would like to thank professors Anselmo Peñas and Alejandro Rodríguez González for their feedback and guidance.
Declarations
ORCID iDs
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.