
Abstract
This work investigates the strength of artificial neural network that is trained by an optimization technique called particle swarm optimization in the task of time series prediction of weekly and monthly significant wave heights. The suggested approach has been implemented at the location of New Mangalore Port in India. Three years of wave data measured during 2005–2007 are analyzed. It is found that the network trained with the help of the particle swarm optimization produces more accurate predictions of the significant wave heights and further with lesser amount of data than the traditionally trained feed-forward back-propagation network.
Keywords
Introduction
Information on wave heights at a site is required for design- as well as operation-related activities in the ocean. Forecasting of waves for operational or design purpose can be made by measuring and analyzing the actual wave observations at a given location. But considering the difficulties and costs involved in getting large-scale wave data, many times, the readily available wind information is gathered and then converted into corresponding wave information although this procedure is less accurate than the actual wave analysis.
A new model based on the working of human brain has been idealized to meet the objective of learning relationship between complex parameters involved in the interaction without having to know the underlying physics behind it. As it is an attempt to mimic the capabilities of the human neural system, it is called artificial neural network (ANN). It imbibes the qualities of exploiting non-linearity—adaptability to adjust free parameters by mapping input output data sets using various learning algorithms and fault tolerance.
A considerable amount of literature dealing with the use of ANN for wave forecasting is available. After McCulloch and Pitts (1943) introduced the concept of a basic ANN, many advanced architectures were presented. Among those models, the multi-layered network trained by back-propagation (BP) algorithm has been applied extensively to solve various engineering problems.
Tsai and Lee (1999) reported an application of the feed-forward neural network to forecast the wave heights at a given site based on the observed wave data of some other site within the Taichung Harbor. Results showed that the wave forecast at a local site has a better performance when the wave data of multisite observations are used.
The most common training algorithm is the standard BP, although numerous training schemes are available to impart better training with the same set of data as shown by Londhe and Deo (2003) in their harbor tranquility studies.
The work carried out by Rao and Mandal (2005) describes hind-casting of wave heights and periods from cyclone-generated wind fields using two-input configurations of ANN. They use advanced algorithms based on the BP neural network due to which the wave forecasting was better.
Deo and Sridhar Naidu (1999) described the application of ANNs in forecasting significant wave heights with a 3-hour lead period. They carried out different combinations of training patterns to obtain the desired output and used three different algorithms of BP, conjugate gradient descent, and cascade correlation to predict wave height.
Tsai et al. (2002) used BP ANN to forecast the ocean waves based on learning characteristics of observed waves and also based on wave records at the neighboring stations.
A comprehensive review of ANN applications in ocean engineering can be seen in Jain and Deo (2006). They pointed out that ANN can provide a good alternative to statistical regression, time series analysis and numerical methods. There are many comparison studies to find out the appropriate method for prediction. Altunkaynak and Ozger (2004) have performed a comparison between perceptron kalman filtering and classical regression for significant wave height and wind speed measurement from USA in the Coos Bay at Oregon. The results have shown that the PKF approach is better than the classical RM procedures. Wave forecasting was done using wind velocity, fetch and duration as input parameters (Deo and Chaphekar, 2001). The results were not satisfactory – fetch and duration were excluded as their presence did not have any effect on predictions. Deo and Jagdale (2003) carried out a study to predict the breaking wave height and depth using five different datasets. The results obtained were found to be better than those obtained by regression curves given by the US Army (1984). Balas et al (2004) used multilayered feed forward and recurrent networks with conjugate gradient and steepest descent with momentum method to predict wave parameters of significant wave height, zero crossing wave period, and wave direction. They compared the results with those obtained from stochastic models of Auto Regressive and Auto Regressive eXogenous input models. Mahjoobi and Shahidi (2008) employed feed forward network with three layers using the sigmoid and hyperbolic tangent function. Three models were created for each output of wave direction, significant wave height and peak wave period. Sensitivity analysis showed that wind speed and direction is the most important parameter for wave hind casting. They excluded fetch and duration in their work and developed an ANN model. Their results confirm that these two parameters do not play an important role in the model’s accuracy. Similar results were obtained by Deo et al (2001) and Deo (2010). They concluded that, unlike the deterministic models, fetch and duration do not seem to be important in ANN modeling. This fact can be generalized when we are using any kind of data mining approach (Mahjoobi et. al, 2008).
Jain and Deo (2007) also used the ANN for wave forecasting. They found that filling the gaps in the wave height time series, using both temporal and spatial approaches, improves the learning capability of the model. They also indicated that if the amount of gaps is restricted to about 2% per year or so, it is possible to obtain 12 h ahead forecasts with 0.08 m accuracy and 24 h ahead forecast with a mean accuracy of 0.13 m. Agrawal and Deo (2004) also used ANN and auto regressive models, i.e. ARMA (Auto Regressive Moving Average) and ARIMA (Auto Regressive Integrated Moving Average) for wave prediction. They used a 3-hourly significant wave height information as input and compared three training algorithms to find the best one. They found that ANN has higher accuracy than the auto regressive methods for 3 and 6 h lead times. Zamani et al. (2008) forecasted wave height in the Caspian Sea using ANN and Instance Based Learning (IBL) methods. They used Average Mutual Information analysis to determine the most relevant inputs of the model. They considered wind direction in their models and showed that the accuracy of ANN is more than that of IBL. They also found that the utilization of ANN in prediction of extreme values yields higher accuracy compared to the utilization of IBL. Several researchers have already worked on applications related to ANN in the areas of estimation of wave parameters, tide prediction, and prediction of short term operational water levels (Deo and Naidu, 1999); Rao et al., 2001; Tsai et al., 2002; Deo and Jagdale, 2003; Balas et al., 2004; Kalra et al., 2005; Makarynskyy et al., 2005; Mandal et al., 2008; Rao and Mandal, 2005; Londhe and Panchang, 2006; Londhe SN, 2008’ Mandal and Prabhaharan, 2006; Jain and Deo, 2007); Kalra and Deo, 2007; Charhate et al., 2008; Gunaydin, 2008; Londhe, 2008 Mahjoobi and Etemad -Shahidi, 2008; Mahjoobi et al., 2008; Zamani et al., 2008; Mandal and Prabhaharan, 2010; Kamranzad et al., 2011; Shiri et al., 2011; Asma et al., 2012; Rakshith and Dwarakish, 2013; Kamranzad et al, 2011; Kennedy and Eberhart, 1995.
Study area and data products
Three years of significant wave height data collected by a wave rider buoy from January 2005 to December 2007 at the location of New Mangalore Port (14°48′34.28″N, 74°07′02.85″E) were utilized in this study. The location map of study area is shown in Figure 1. Predictions were carried out using a week’s data of 56 time steps (8 hour × 7 days) and month’s data of 240 time steps (8 hour × 30 days) as input.
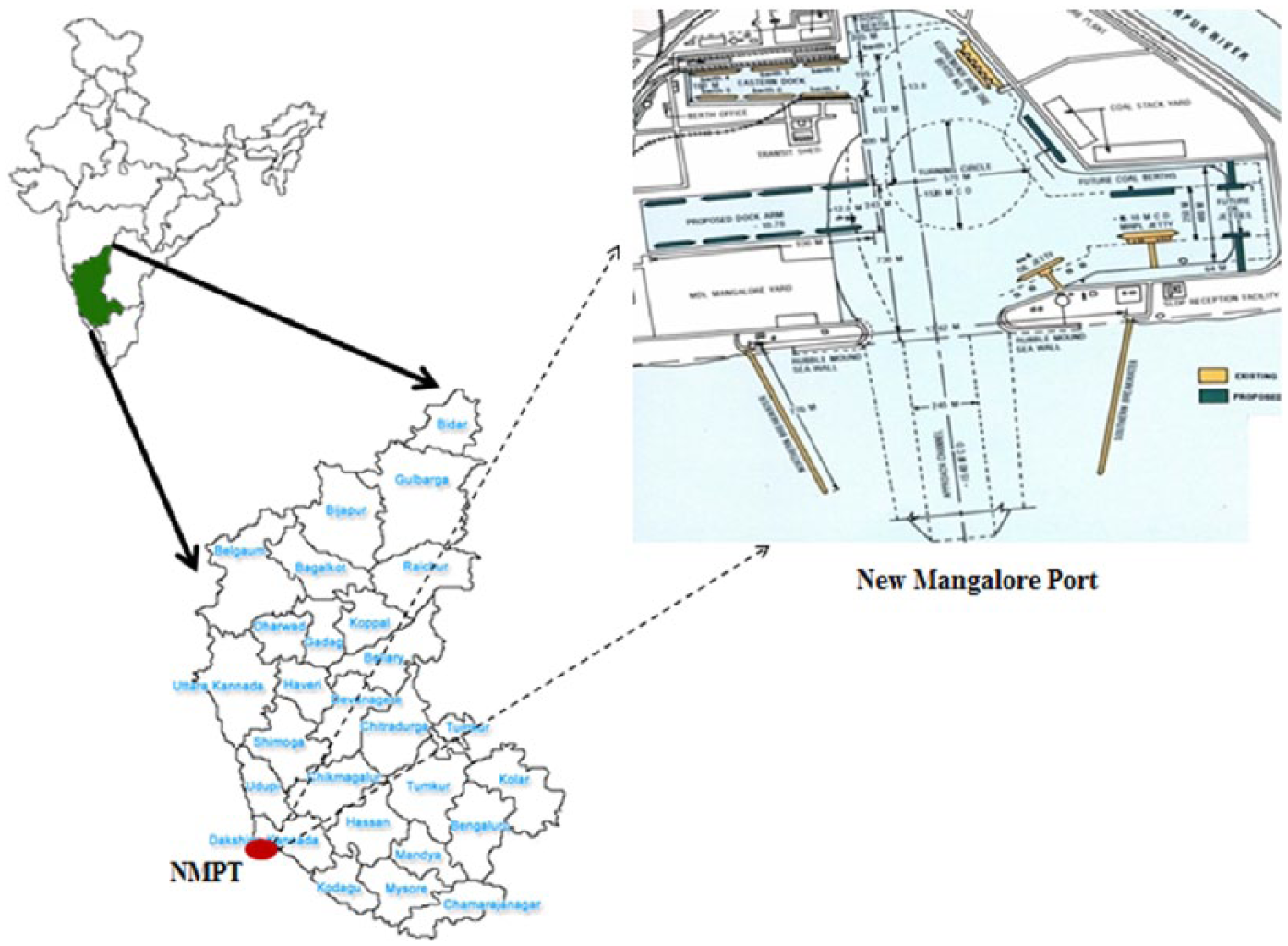
Location map of study area.
A three-layered feed-forward back-propagation (FFBP) network with an input layer, a hidden layer, and an output layer with training imparted by the Levenberg–Marquardt (LM) algorithm was employed. Tangent-Sigmoid (tansig) and linear (purelin) transfer functions were used in hidden layer and output layer, respectively. The data were normalized to fall in the range of −1 to 1 to speed up the learning process. In total, 1000 were set as the stopping criterion for the training process of network for all the predictions undertaken.
Methodology
FFBP network
ANNs are computing systems made up of simple, interconnected elements, which process information by their response to external inputs. The ANNs have developed from a biological model of the brain. A neural network consists of a set of connected cells or neurons. The neurons receive impulses from either input cells or other neurons and perform some kind of transformation of the input and transmit the outcome to other neurons or to output cells. The neural networks are built from layers of neurons connected so that one layer receives input from the preceding layer of neurons and passes the output on to the subsequent layer.
A graphical presentation of neuron is given in Figure 2. A neuron is a real function of the input vector x1, x2, x3, … xn and wk1, wk2, wk3, … wkn are the weights associated with it. Neuron k is the summation junction where the net input obtained is given by
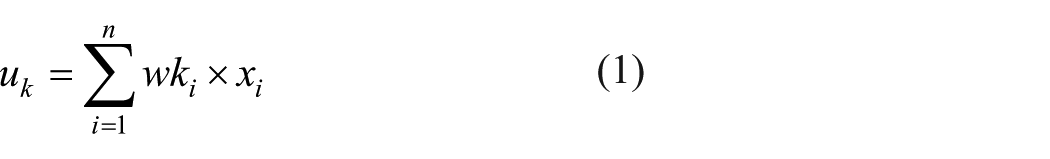
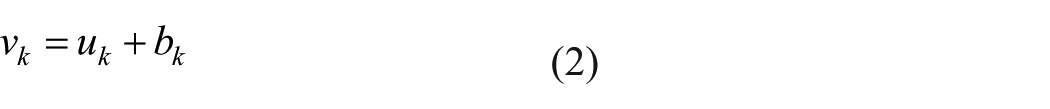
bk is the bias value at the kth neuron. The output Yk is the transformed weighted sum of vk and is represented by
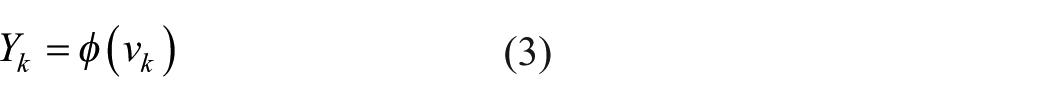
where
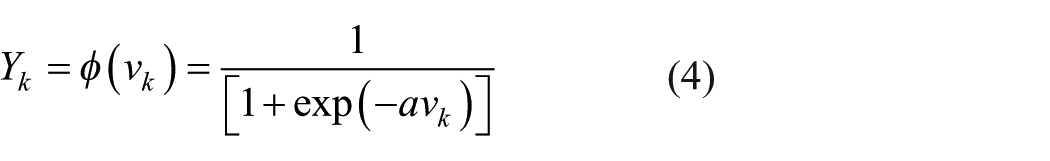
where a is the slope of sigmoid function. Once the activities of all output units have been determined, the network computes the error E, which is defined by the expression
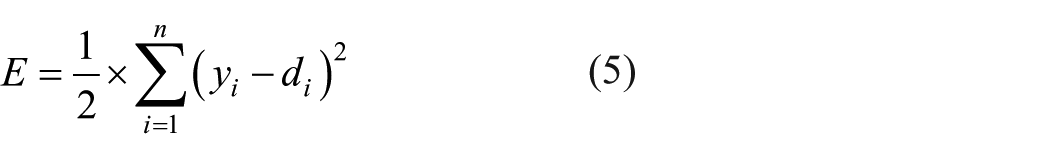
where yi is the activity level of the ith unit in the top layer and di is the desired output of the ith unit. The most commonly used learning algorithm in the past coastal engineering applications is the gradient descent algorithm. In this, the computed global error is propagated backward to the input layer through weight connections, during which the weights are updated in the direction of the steepest descent or in the direction opposite to the gradient descent. However, the overall objective of any learning algorithm is to reduce the global error, E, defined as

and
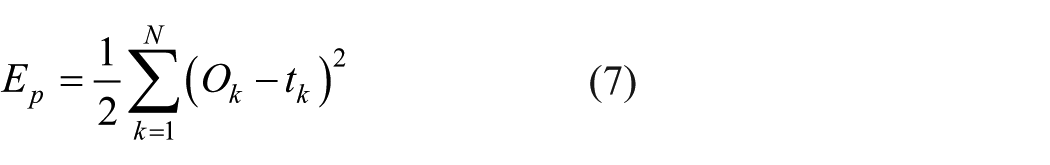
where Ep is the error at the pth training pattern, Ok is the obtained output from network at the kth output node, tk is the target output at the kth output node, and N is the total number of output nodes. The training algorithm of LM used in this study can be written as
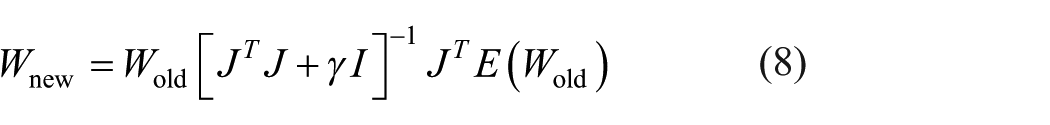
where J is the Jacobian of the error function (E), I is the identity matrix, and γ is the parameter used to define the iteration step value. It minimizes the error function while trying to keep the step between old weight configuration (Wold) and new updated one (Wnew) small.
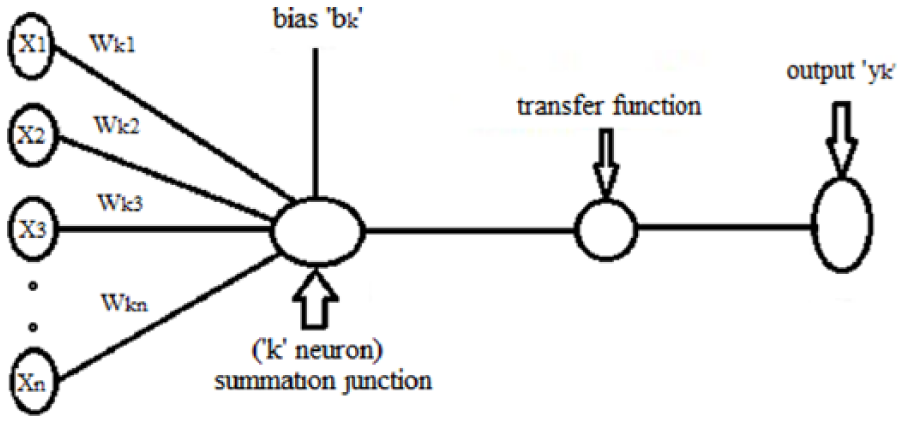
Basic model of ANN.
The performance of the network is measured in terms of various error statistics such as the sum squared error (SSE), mean squared error (MSE), root mean squared error (RMSE), and coefficient of correlation (r) between the predicted and the observed values of the quantities. A low value of RMSE and high value of CC indicate better performance of the network. The major drawback of the FFBP is that of the network getting trapped in the local minima. Too many variations in the involved data set will diminish the accuracy of the network. The mentioned setbacks can, however, be overcome by selecting the optimum architecture of the network using various techniques like sensitivity analysis to select most effective input parameters and reduce network size to decrease the computational time required.
Particle swarm optimization–ANN network
The particle swarm optimization (PSO) is an optimization algorithm first proposed by Kennedy and Eberhart (1995). PSO is based on swarm intelligence, such as the behavior of swarms of bees seeking out flowers to pollinate. The swarm is composed of particles, where each particle represents a possible solution to an optimization problem. PSO is initialized with a group of random particles (solutions), which were assigned with random positions and velocities. The algorithm then searches for optima through a series of iterations where the particles are flown through the hyperspace searching for potential solutions. These particles learn over time in response to their own experience and other particles’ experience in their group. Each particle keeps track of its best fitness position in hyperspace that it has achieved so far. This best position value is called personal best or “pbest.” The overall best value obtained by any particle so far in the population is called global best or “gbest.” During iteration, every particle is accelerated toward its own “pbest” as well as in the direction of the “gbest” position. This is achieved by calculating a new velocity term for each particle based on the distance from its “pbest” as well as its distance from the “gbest” position. These two “pbest” and “gbest” velocities are then randomly weighted to produce the new velocity value for this particle, which will affect the next position of the particle in next iteration.
The advantage of the PSO over many of the optimization algorithms is its relative simplicity. The only two equations used in PSO are the movement equation and velocity update equation. The movement equation provides for the actual movement of the particles using their specific vector velocity, while the velocity updates equation provides for velocity vector adjustment given the two competing forces. Besides, inertia weight (w) is introduced to improve the convergence rate of the PSO algorithm. Mathematically
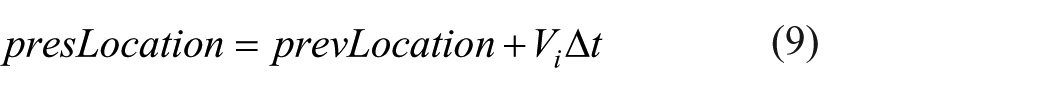
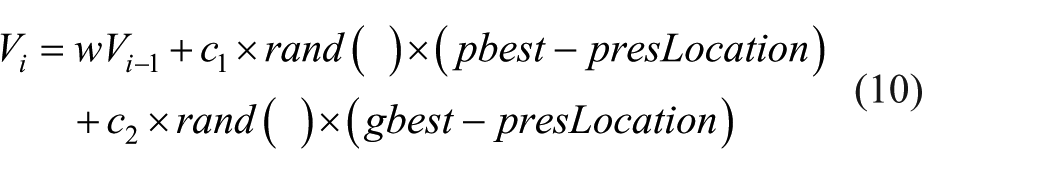
where Vi is the current velocity, Δt defines the discrete time interval over which the particle will move, w is the inertia weight, Vi−1 is the previous velocity, presLocation is the present location of the particle, prevLocation is the previous location of the particle, rand () is a random number between (0, 1), and c1 and c2 are the learning factors or stochastic factors or acceleration constants for “gbset” and “pbest,” respectively.
Results and discussion
Prediction using FFBP network
Weekly predictions
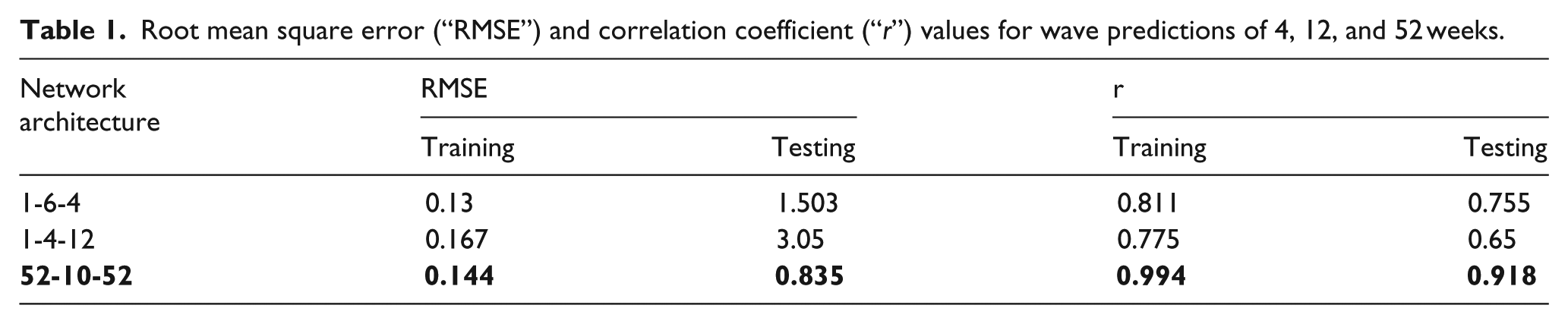
In this study, the prediction over a horizon of 4 weeks was carried out using 1 week’s wave data from 1 January 2005 to 7 January 2005 as input. The target data set comprised readings of 4 weeks’ duration from 8 January 2005 to 4 February 2005 (28 days), 1 week’s data having 56 time steps (8 hours × 7 days) representing a single node in this case which is represented as row matrix (1 × 56), and similarly an output layer consisting of four nodes for 4 weeks of data. Subsequent weeks in similar fashion were given as input and target for testing the trained network. The “r” values showed marginal increase in 4-week prediction which might be due to the increased number of target values available for the network generalization. However, the “r” value decreased for the 12-week wave prediction as 1 week’s data range is too small for predicting a long duration of 12-week wave data. The number of neurons was increased in the hidden layer by one, after every prediction. The best performance was obtained at six and four neurons in the hidden layer during 4- and 12-week prediction of wave height as shown in Table 1. The training performance showed that considerable increase in “r” values drastically reduced hinting at the overfitting behavior of the network when the number of neurons was increased beyond six and four during 4- and 12-week wave prediction. This phenomenon refers to a state where there is a large number of neurons in hidden layer increasing the complexity of the network, but there is no significant amount of patterns to be learnt by the network based on given input-target data sets. Also in both the cases, the prediction duration is large compared to input data. Naturally, the range of targets will be greater than those of input provided, weakening the prediction capability of the network when new data set is fed to the network.
Root mean square error (“RMSE”) and correlation coefficient (“r”) values for wave predictions of 4, 12, and 52 weeks.
Similarly, yearlong predictions are carried out using data of year 2005 as input and data of year 2006 as target in the training process and next two consecutive year’s data (2006 and 2007) as input and target for simulation purpose, respectively. The input and output layers consisted of 52 nodes representing 52-week data for a single year. The prediction done using yearlong data yielded good results with training process “r” value reaching up to 0.99 and simulation “r” value reaching a value of 0.91. The optimum number of neurons is found to be 10 and the “MSE” values are 0.021 and 0.698 for training and simulation purpose, respectively. The increase in the number of neurons beyond 10 led to a decrease in the prediction capability of the trained network when simulation data sets are presented to the network. The plot of observed values and predicted values shown in the Figures 3 and 4 gives the scatter plot of training and simulation of the network.
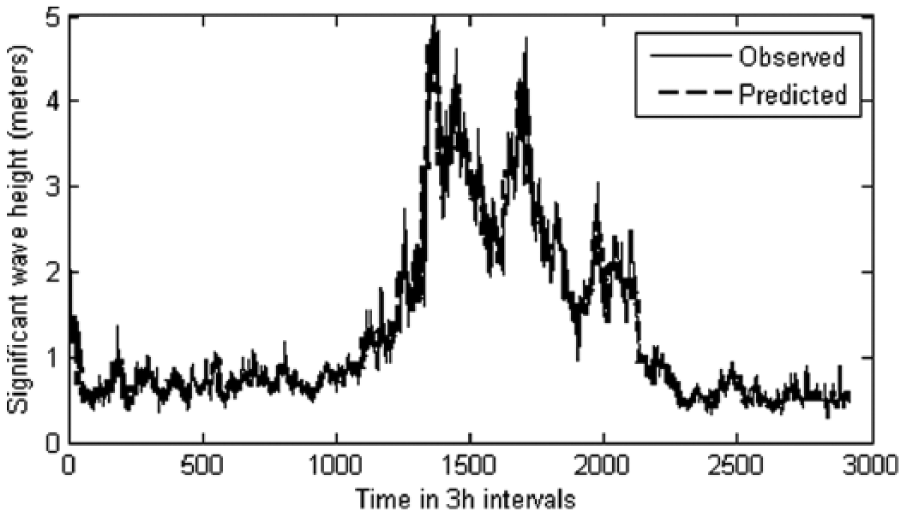
Graph showing the predicted and observed waves for the year 2006 using weekly data sets (1 January 2005 to 30 December 2005) in the FFBP network.
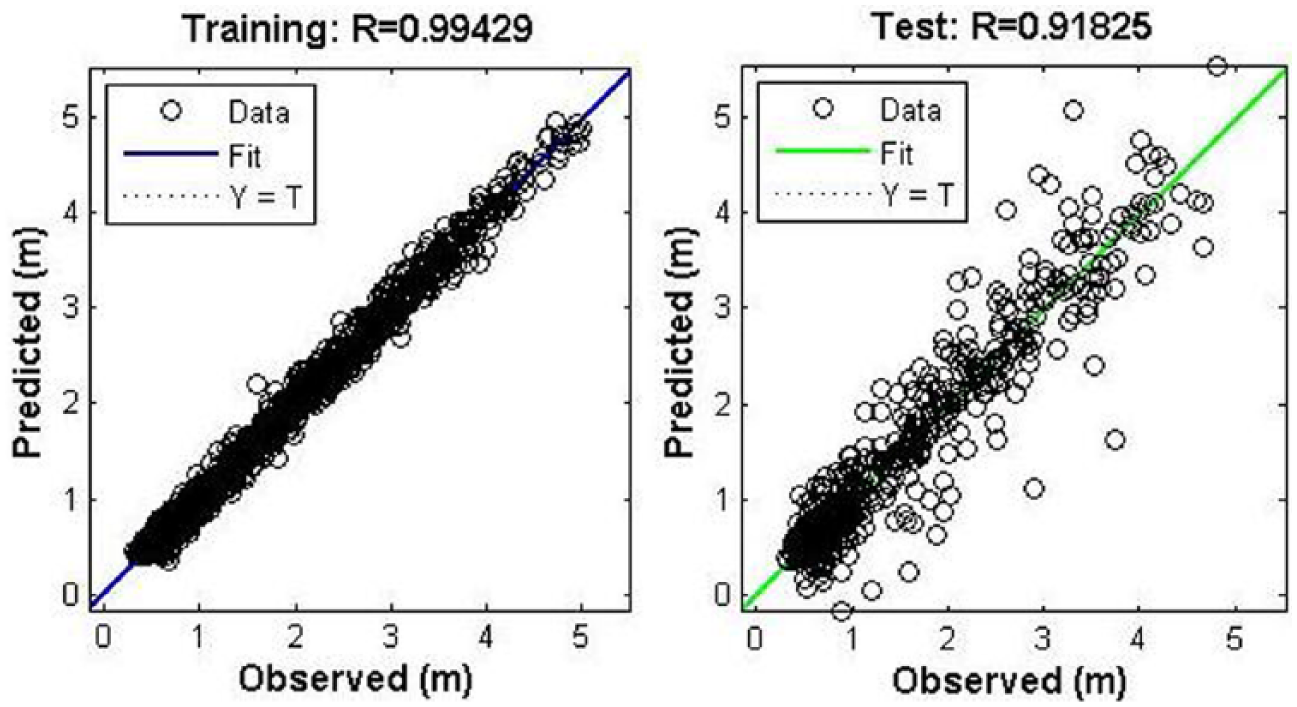
The scatter plot of training and simulation of the network during yearly predictions done using weekly data sets in the FFBP network.
Monthly predictions
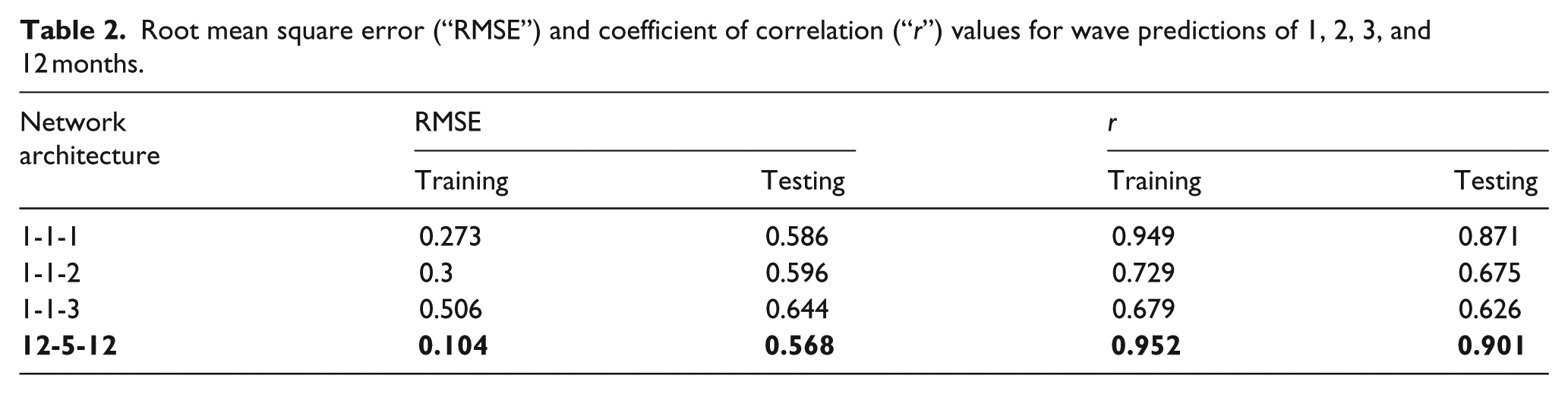
Monthly prediction involved feeding the network with 1 month’s data having 240 data points in a single input node (1 × 240). The year 2005 hourly wave data are divided into 12 sets having 240 data points, each corresponding to 30 days of observation; hence, the yearly data comprised 1 January 2005 to 26 December 2005 (360 days). For training of 1 month’s wave prediction, data from 1 January 2005 to 30 January 2005 and from 31 January 2005 to 1 March 2005 were given as input and target data, respectively. The subsequent data of the 30-day period were given as input and target data for simulation purpose. The number of neurons is increased in the hidden layers; however, not much appreciable improvement is seen in the “r” value; hence, the number of neurons was taken as one for all the forthcoming predictions for 2-month and 3-month wave data which have 1 month’s data as input in a single node as shown in Table 2. A year’s hourly data set contains 2920 readings; however, this was cut short to 2880 readings so that the data can be divided equally into 12 months comprising 30 days (240 readings) each. Hence, the first month will comprise data from 1 January 2005 to 30 January 2005, second month from 31 January 2005 to 1 March 2005, and so on till 26 December 2005. Prediction for an entire year using 12-month data of the year 2005 as input with equal number of input nodes is carried out giving the year 2006’s wave data of 12 months as target during the training process. The trained network is then used to predict the 2007’s wave data using 2006 wave height as input. The results obtained are good in this case, and “MSE” values as low as 0.011 and 0.323 were obtained for training and simulation, respectively, and also high “r” values of 0.952 and 0.901 were obtained. The optimum number of neurons in the hidden layer is found to be five in this case. The increase in the number of neurons beyond five led to a decrease in the prediction capability of the trained network when simulation data sets are presented to the network. The plot of observed values and predicted values is shown in Figure 5. Figure 6 gives the scatter plot of training and simulation of the network.
Root mean square error (“RMSE”) and coefficient of correlation (“r”) values for wave predictions of 1, 2, 3, and 12 months.
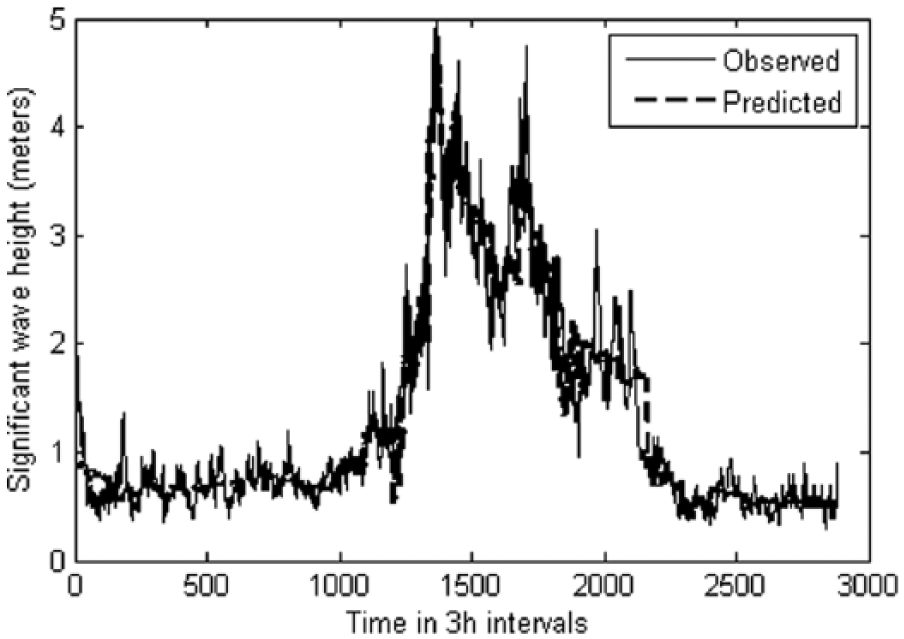
Graph showing the predicted and observed waves for the year 2006 using monthly data sets (1 January 2005 to 26 December 2005) in the FFBP network.
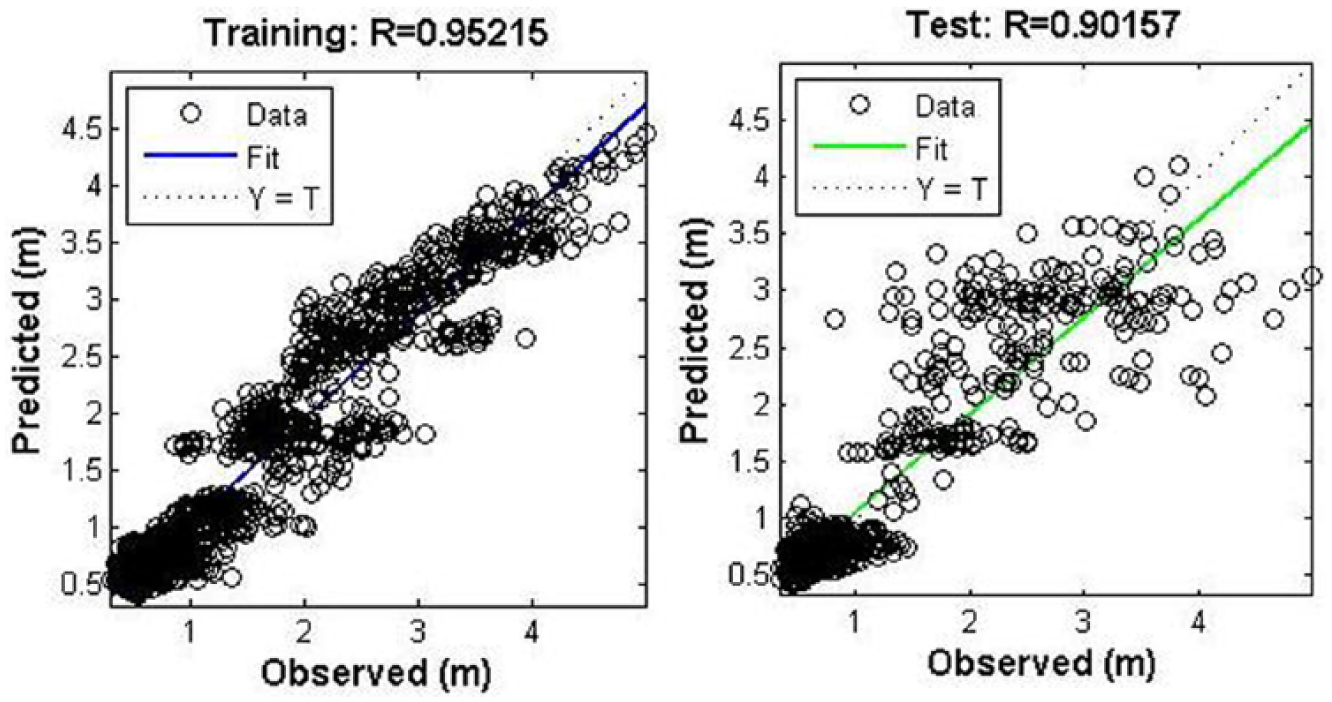
The scatter plot of training and simulation of the network during yearly predictions done using monthly data sets in the FFBP network.
Prediction using PSO-ANN
Weekly predictions
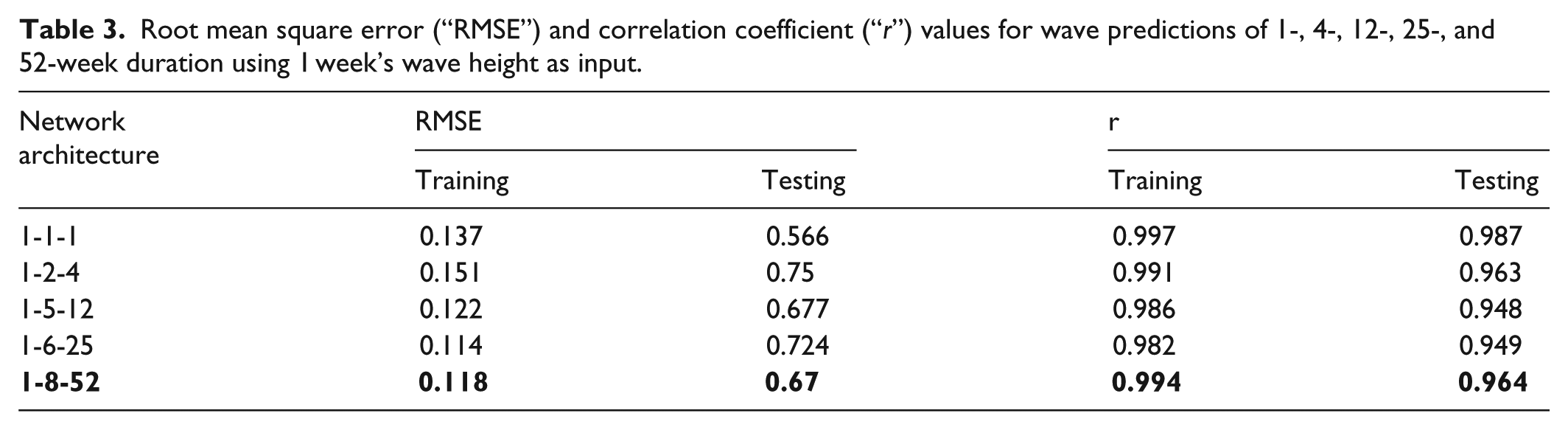
In this study, the PSO was applied to train the neural network for enhancing the convergence rate and the learning process. The learning process involves finding a set of weights that minimizes the learning error. Weekly predictions were carried out using 1 week’s input data to predict wave predictions of 4, 12, 25, and 52 weeks. The results obtained in terms of “MSE” and “r” were good, from 0.98 for 1 week’s prediction to greater than 0.96 for 52-week prediction. The variation of “r” values for the case is shown in Table 3. The increase in the number of neurons beyond eight led to a decrease in the prediction capability of the trained network. A scatter plot for training and simulation of the network for 52-week prediction is given in Figure 7. The “r” value will be 1 when the plot of observed versus predicted values follows a perfect straight line pattern passing through the origin. The time series plot of the observed versus predicted wave heights is shown in Figure 8.
Root mean square error (“RMSE”) and correlation coefficient (“r”) values for wave predictions of 1-, 4-, 12-, 25-, and 52-week duration using 1 week’s wave height as input.
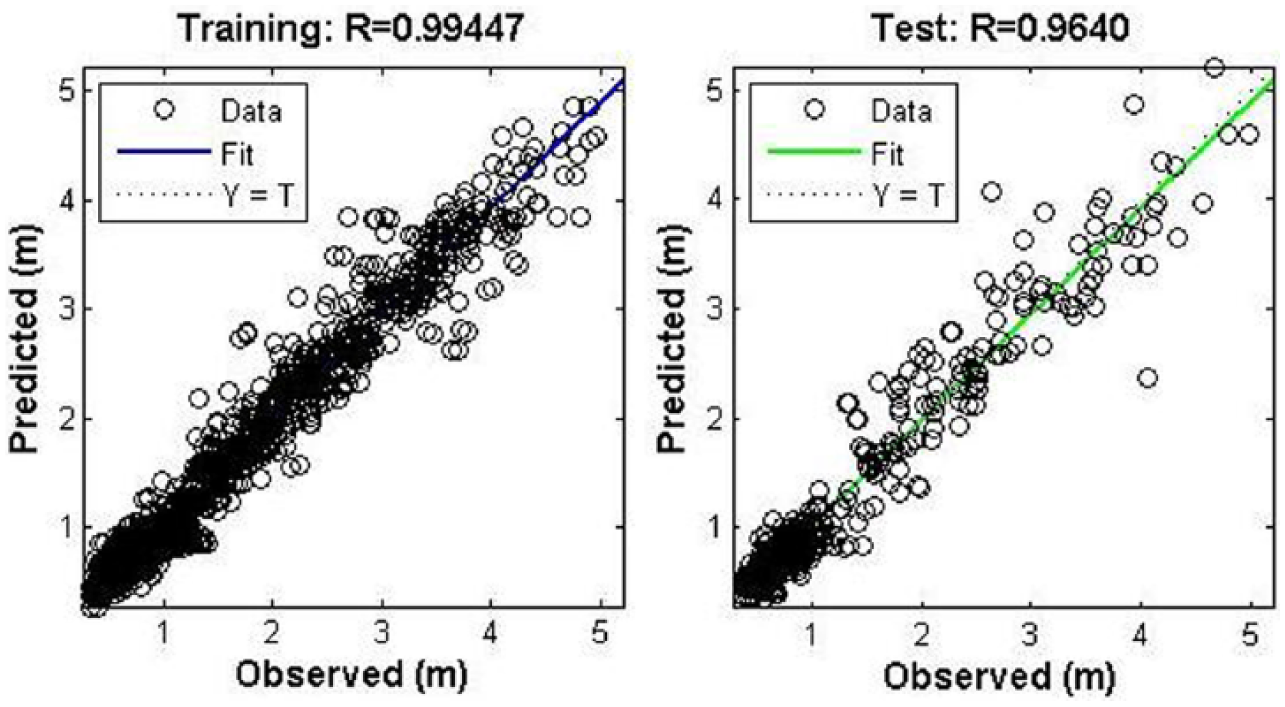
The scatter plot of training and simulation of the network during yearly predictions done using weekly data sets in the PSO-ANN network.
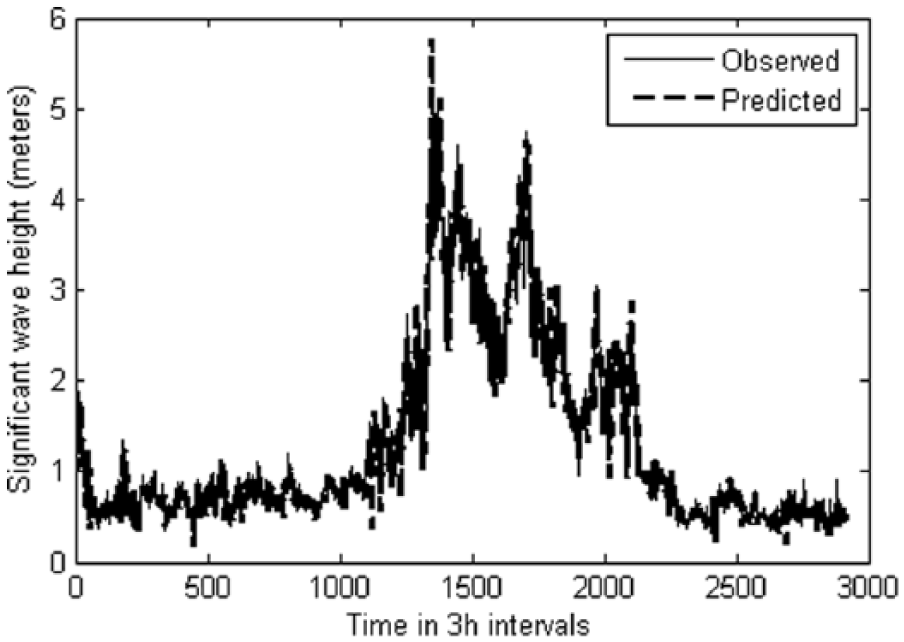
Graph showing the predicted and observed waves for the year 2006 using weekly data sets (1 January 2005 to 30 December 2005) in the PSO-ANN network.
Monthly predictions
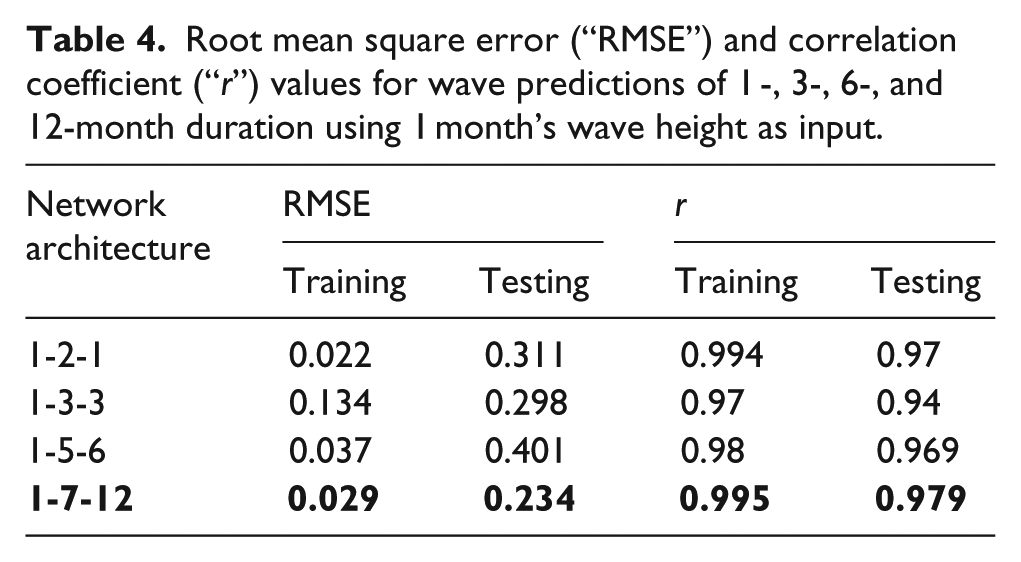
Monthly predictions were also carried out in similar way to that of weekly predictions using 1-month data set for predictions of waves with duration from 1 to 12 months, the results of which are tabulated in Table 4. One-year prediction can be obtained with accuracy greater than 0.97. The increase in neurons in the hidden layer beyond the best network architecture also showed gradual decrease in accuracy which would have rendered for 12-month prediction using 1-month data. Scatter plot and plot of observed versus predicted are shown in Figures 9 and 10.
Root mean square error (“RMSE”) and correlation coefficient (“r”) values for wave predictions of 1 -, 3-, 6-, and 12-month duration using 1 month’s wave height as input.
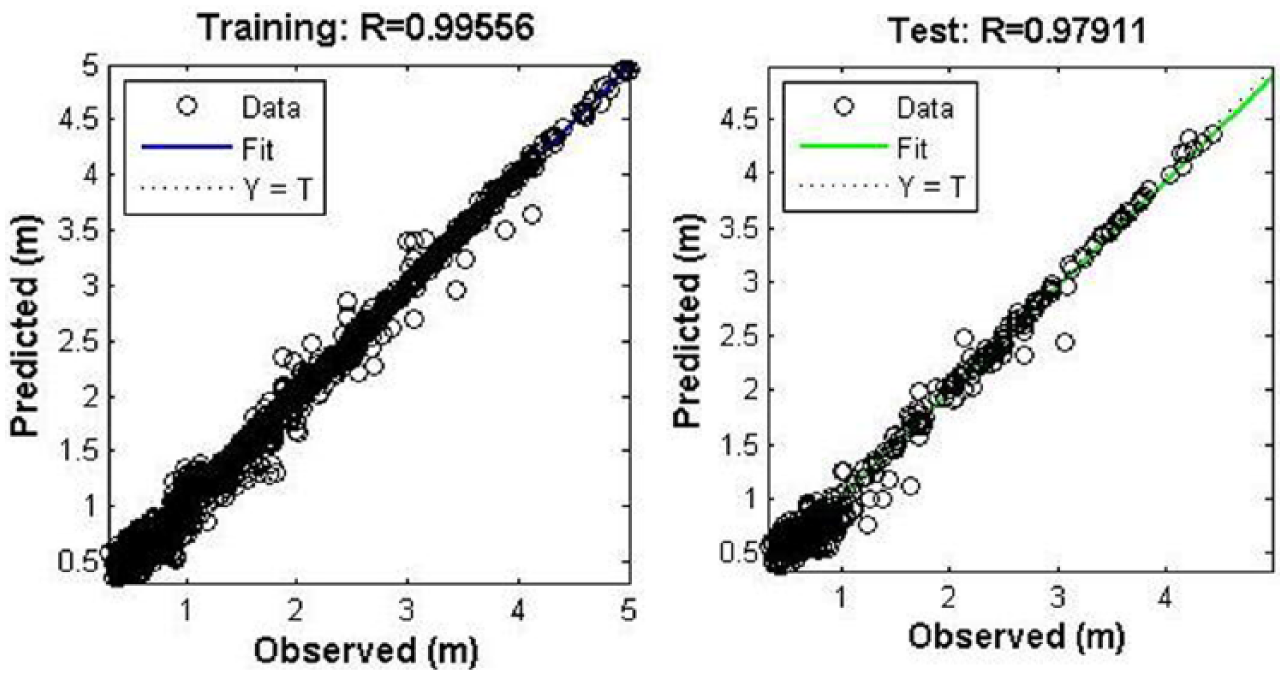
The scatter plot of training and simulation of the network during yearly predictions done using monthly data sets in the PSO-ANN network.
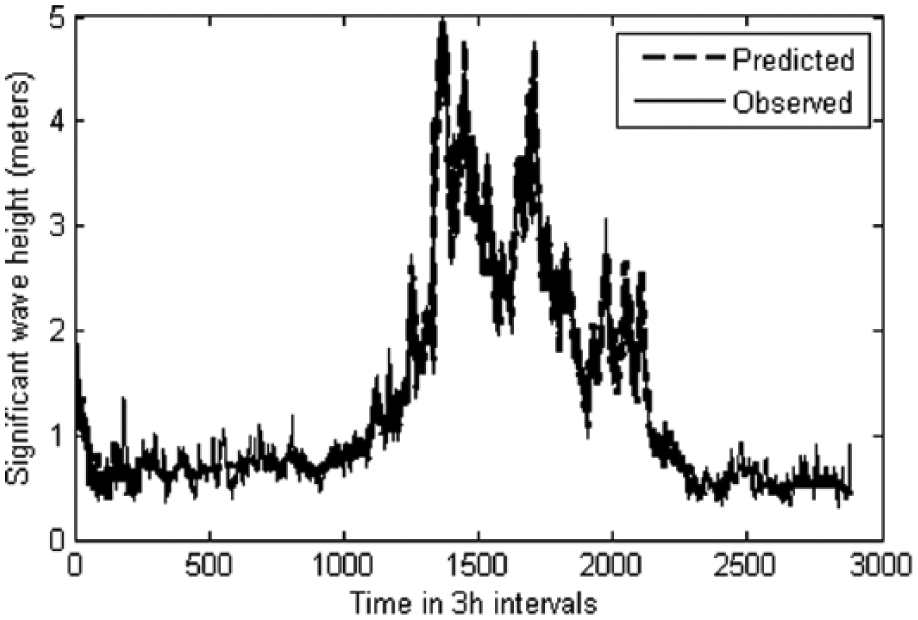
Graph showing the predicted and observed waves for the year 2006 using monthly data sets (1 January 2005 to 26 December 2005) in the PSO-ANN network.
Conclusions
ANN has been widely used in the field of coastal engineering for various applications. In this study, first the conventional FFBP network was used to predict the waves at New Mangalore Port Trust (NMPT) located along west coast of India, and the results were thereafter compared with those of the PSO-ANN model. The end results indicate that in the conventional FFBP network, the accuracy of the trained network depended on the length of the data segment used as input in model building, but in the case of the PSO-ANN network, accurate training was possible with relatively much smaller length of the input segment. In this application, the PSO-ANN network outperformed the conventional FFBP network in terms of the length of historical values used as input, training time, and accuracy.
Footnotes
Acknowledgements
The authors would like to thank New Mangalore Port Trust, Panambore, for providing us with the data of 8 months of continuous 3-hourly significant wave height measurements recorded at NMPT for this study.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.