
Abstract
UAV (Unmanned Aerial Vehicle) black flight at low altitude could cause serious safety risks. Consequently, it is crucial to detect and manage low altitude small UAVs. The existing methods of low altitude small UAV detection suffer from problems such as high false alarm rate, and poor real-time performance. In order to solve the above problems, we present a novel approach, named AD-YOLOv5s, to achieve low altitude small UAV detection with high precision and high real-time performance. Firstly, the feature enhancement method is used to expand the dataset. We optimize the model feature fusion, the prediction head structure, and the loss function. Based on the CBAM (Convolutional Block Attention Module) attention mechanism, feature enhancement is performed to improve the detection accuracy. Secondly, the ghost module and depthwise separable convolution are used to reduce the number of parameters of the model, and we propose the method of lightweight design of model to improve the detection speed. Compared with the YOLOv5s model, the experiment result shows that our proposed AD-YOLOv5s model improves the value of mAP by 2.2% and the value of Recall by 1.8%, reduces the value of GFLOPs by 29.9% and parameters by 38.8%, and achieves 27.6 FPS when the proposed model deploy on a low-cost edge computing device (jetson nano).
Introduction
In recent years, with the rapid development of Wireless communications,3,1,2 panoramic Vision technology 4 and UAV technologies, the civilian UAV market has expanded rapidly. Most of the low altitude small UAVs are quadrotors, which have the characteristics of low altitude, slow speed and small size. However, there is also an increasing pressure of low-altitude UAV control. Borders, airports and nuclear power plants have become the most serious areas of UAV invasion. There are countless safety accidents caused by UAVs, and low-altitude security for UAVs is imperative.
It mainly oriented this paper to the border defense application scenario. Due to the weak communication coverage in the border scenario, the communication equipment cannot transmit large-scale video data. At the same time, the environmental constraints of border areas, such as shortage of power resources, make it impossible to deploy large equipment such as ground stations with powerful GPUs. Consequently, this scenario calls for detection algorithms to be deployed at the edge, as well as algorithms that can function properly and in real-time on systems with limited processing power. Due to the long borderline of border defense applications, numerous devices need to be deployed, so the scenario requires edge deployment of devices that are low cost.
The detection methods for low altitude small UAV 5 are radio, 6 audio, 7 radar 8 and image, 9 as well as multi-source detection information fusion. 10 Radio can locate UAV quickly, but Frequency Hopping, which allows airborne stations and ground stations to change channels at the same time, makes it much harder to locate. Audio has a certain effect on large UAV with a huge noise, but it is not suitable for small UAV with little noise. Radar can detect large-size UAV well, however it does net work well for small-size ones. Image detection methods are widely studied because of their low cost and easy expansion, but they rely on manual features based on prior knowledge and experience, so the design is difficult and inefficient.
With the increasing pressure of low-altitude security in recent years, traditional detection methods cannot meet the detection needs. At the same time, deep learning object detection algorithms have been widely used and played an important role in vehicle detection, face detection, automatic driving, 11 safety systems, and other fields. Compared with traditional detection methods, deep learning detection methods have the advantages of high detection accuracy and fast speed. Deep learning detection has two models: one-stage and two-stage. One-stage detection models include Yolo,13–15,12 SSD, 16 etc. The core is the idea of regression, and it does not need to use regional candidate networks. It can predict the object category and location directly with the feature extraction network. The two-stage detection models are represented by R-CNN (Region-Convolutional Neural Networks), 17 Fast R-CNN (Fast Region-Convolutional Neural Networks), 18 Faster R-CNN (Faster Region-Convolutional Neural Networks), 19 mask R-CNN (mask Region-Convolutional Neural Networks). 20 The basic idea is to extract images features with convolutional neural networks, then the regional candidate networks form candidate frames. The “matting” and further feature representation is executed. Finally, classification and regression get the type and location of objects. The performance of the two methods is also different. The two-stage model has advantages in detection accuracy and positioning accuracy. However, due to the complex detection process, it is difficult to meet the real- time requirements. The one-stage model is quicker in detection. The low-altitude security scenarios have higher requirements for detection speed, so this paper uses the one-stage method of the YOLO model.
The YOLO family contains various variants, such as YOLOv1-v7, YOLOX, YOLOR. The YOLOv5 has the characteristics of good portability and strong real-time performance. The YOLOv5s is a lightweight network in the YOLOv5 series. The network structure of YOLOv5s can divide into three parts, that is the feature extraction network backbone layer, the feature fusion network neck layer, and the prediction layer detection head.
In practice, the detection of low altitude small UAV needs to be low cost, low delay(
A feature enhancement method is proposed to optimize the feature fusion layer and detection head structure. An attention mechanism is used to enhance the features of a single feature map. The EIoU (Efficient Intersection over Union loss)
21
is used as the loss function to make the model converge faster and more accurately.Experiment results show that the proposed method improves the value of MAP (Mean Average Precision) by 5.4% and Recall value has increased by 5.5%. Based on the ghost module and depthwise separable convolution for model lightweight design, the AD-YOLOv5s is proposed to achieve lightweight low altitude small UAV detection. At the same time, the technology of TensorRT
22
is used to accelerate the proposed model.Experiment results show that the proposed method reduces the floating-point number calculation by 29.9%.
Experiment results show that the proposed method is suitable for deployment in low-cost edge equipment.
Related work
In recent years, many vision-based UAV detection algorithms have been proposed. Mejias et al. proposed a method for tracking UAVs with morphological preprocessing and Hidden Markov Models to detect UAV objects within a distance of 1000 meters, but the detection speed is slow. 23 Rozantsev et al. proposed a regression-based video UAV detection method, which solved the problem of UAV size change, but it still has the disadvantage that cannot detect fast UAV. 24 In order to solve the difficulty of detecting the fast flying speed of the UAV, Lian Du combine CNN (Convolutional Neural Networks) and SVM (Support Vector Machine) to propose a UAV detection method on a moving camera. The detection method can detect fast UAV, but the detection speed is poor. 25 For the problem of multi-category detection, Sommer et al. studied UAV detection with dynamic and static data and proposed a convolutional neural network to detect and classify six types of flying objects (including UAV). 26 Hu et al. replaced the feature extraction network of DiafonalNet with the improved Hourglassnet, which made the detection accuracy higher, but the disadvantage was that there was no further test for speed. 27 Seidaliyeva et al. detected moving objects in the static background, then they classified the moving objects to further improve the accuracy of the model, but the disadvantage is that the model had poor real-time performance. 28 Makirin used a web application for real-time detection when he participated in the UAV Chasing Challenge. The precision and recall rate could be improved in the detection process, but this method relied on high computing resources. 29
The current Yolo-based anti-drone detection algorithm has two limitations. Firstly, the current algorithm can only identify targets with a minimum size of 8*8 pixels. Secondly, the number of parameters of current models is so large that the model cannot be computed in real time on low-cost edge computing devices.
The analysis shows that there are many excellent algorithms for UAV detection, but these models is unsuited for the detection the UAV in low-altitude security scenarios, the reasons are the size of the detection object is much smaller than the size of the conventional object in low-altitude security scenarios, and its posture is changeable over time. Therefore, researchers committed to developing a robust low-altitude object detection algorithm suitable for detecting small UAV in low-altitude security scenarios.
Considering the low-altitude small UAV detection task has high requirements for detection accuracy and real-time performance, it is necessary to consider the accuracy performance and the detection speed when designing the low-altitude small UAV detection algorithm. However, the existing model are bloated relatively, and this lead the poor real-time performance on intelligent monitoring equipment. The deep learning has powerful processing ability, and it has become a hot research by applying it to low-altitude security. In summary, we proposed a lightweight low-altitude small UAV detection model based on deep learning.
AD-YOLOv5s low altitude small UAV detection algorithm
The algorithm framework
The YOLOv5s model has two problems when applied to low altitude small UAV detection. Firstly, the object size distribution of low altitude small UAV detection is inhomogeneous extremely, and it includes numerous small objects, and even smaller than those small objects, that is, tiny object. The existing YOLOv5s detection model cannot detect small and tiny objects very well, so we need to optimize the model with the object size distribution of low altitude small UAV detection. Secondly, low altitude small UAV detection scenarios need to be supported by low-cost edge devices. Although the YOLOv5s model is a relatively lightweight in the YOLOv5 family, due to the limited memory and computing resources on the low-cost edge device, the model cannot effectively play the performance of the model when deployed on the above low-cost edge device. As shown in Figure 1, we obtain the network structure of the AD-YOLOv5s model with feature enhancement optimization and structural lightweight improvement. Therefore, we proposed a low altitudes mall UAV detection algorithm based on AD-YOLOv5s in the paper. Figure 2 shows the object detection algorithm framework.

AD-YOLOv5s network structure.

Low altitude small UAV detection algorithm based on AD-YOLOv5.
First, we optimized the accuracy based on the yolov5s model: we add the CBAM module in the backbone network to improve the model’s extraction of image features; we use feature enhancement methods in the neck layer to enhance the model’s extraction of minute target features; we use EIOU loss in the prediction head for a more accurate model evaluation. Secondly, we optimize the accuracy- improved model for lightweight we use the ghost module to reduce the computation of the backbone; we use depth-separable convolution to replace the regular convolution to reduce the number of neck network module parameters.
The performance optimization of low altitude small UAV detection based on feature enhancement
The feature enhancement of feature fusion layer
The feature maps of normal YOLOv5s model use 8 times down-sampling, 16 times down-sampling and 32 times down-sampling as the prediction layer to detect the object. The shallow features of the image include contour, edge, colour, texture and shape features. The edge and contour can reflect the image content. The low-level feature semantic information of the image is small relatively, but the location of target is accurate. Although the reduction of the feature map enriches the semantic information, it will lose the shallow feature information. The small UAV detection depends more on shallow feature information, so the improvement of the detection accuracy is inhibited without shallow feature information.
We analyzed the object size distribution, and the receptive field mapping relationship of the convolutional neural network is:

The default input size of YOLOv5s model is
The evidence shows that the detection layer of the original YOLOv5s set three sizes of detection heads, it can detect targets with a size of 8*8 and larger. However, when the 32 times down-sampling process original image, the object whose size is smaller than 8*8 in the original image will lose a lot of shallow feature information. Even if the feature layer uses the size of 80*80 to detect, the object cannot be detected.
Object Size Classifications.

Considering the low altitude security scene, the UAV object to be detected generally has the characteristics of small volume and few available features, which makes it become a tiny object with the size less than 8*8 in the image. In order to further improve the detection performance of the model, it is necessary to count the object proportion of each size in the low altitude security data set.
As can be seen from Figure 3, the proportion of big object is only 6.7%, the proportion of medium object has reached 54.0%, the proportion of small object has reached 24.5%, and the proportion of tiny object has reached 14.8%. There are a large number of tiny object in the dataset of this paper. Therefore, the existing object detection methods are not suitable for low-altitude security dataset. The method ignores the existence of a large number of the small object and tiny object in the dataset, which seriously affects the model detection accuracy and detection recall rate.

Statistical of object Size of Low Altitude Security Data Set.
In order to solve the above problems, we added a detection layer for detecting tiny object, while retaining the detection layer for detecting small object and medium object, and deleted the detection layer for detecting big object. The optimized object size classification table is shown in Table 1.
Since the feature map of the detection layer comes from the feature fusion layer, after the modification of the above detection layer is determined, we optimize the corresponding feature fusion layer for feature enhancement. The feature fusion layer network structure of YOLOv5s adopts the structure of Feature Pyramid Network (FPN) +Path Aggregation Network (PAN), 12 which adds a bottom-up feature pyramid behind the FPN layer. 30 The feature pyramid contains two PAN Structures. 31 Figure 4 shows the structure.

Conventional neck feature fusion layer.
The detection head layer uses three types of feature maps, 8 times down-sampling gets the 80*80 feature maps, 16 times down-sampling gets the 40*40 feature maps, and 32 times down-sampling gets the 20*20 feature maps. Based on the above analysis, in order to match and optimize the improved object size classification table, the existing feature fusion layer needs to be optimized. Figure 5 shows the optimized feature fusion layer network structure.

The optimized neck feature fusion layer.
Firstly, a new layer of up-sampling operation is added behind the two up-sampling in the FPN structure. The pyramid structure of FPN layer is improved from the initial three layers to four layers. The feature extraction layer performs the Concat operation for the feature map corresponding to the same size, and it can get a feature map with a size of 160*160 to detect tiny object. Although the prediction layer does not use the feature map of 20*20, the FPN layer reserve the feature map of 20*20, so that it can extract more detailed semantic feature information and can transfer to other feature maps with the FPN structure. It is beneficial to the detection of a tiny object. At the same time, two PAN structures are added behind the 160*160 feature map to generate feature maps with sizes of 80*80 and 40*40, respectively. The FPN layer is used to convey strong semantic features from top to bottom, and the PAN conveys strong positioning feature from bottom to top. This is the feature enhancement operation of the feature fusion layer. This paper does not put forward detection requirements for big objects with a size of 32*32 or more, so we delete the PAN with the size of 20*20 feature map.
Meanwhile, in order to match the improvement of the feature fusion layer, we further optimize the detection head layer, as shown in Figure 6. The two detection heads are retained for detecting small and medium objects from feature maps of 80*80 and 40*40. We delete the detection head of detecting big object and related sampling convolution processes. At the same time, the 160*160 feature map is used as a detection head for detecting tiny object.

Detection head structure.
Feature enhancement by attention mechanism
As shown in Figure 7, the feature map generated by the convolution operation. We can see that the small and tiny object occupies less feature information on the feature map, and the background of the detection object is the sky background, mostly. Most of the feature map is a single-color gamut, and there is no obvious colour gamut distinction. As a result, there is a problem that a large amount of invalid feature information occupies computing resources in a single feature map, and the model cannot locate the detection object quickly, which affects the detection performance.

Input image and convolved feature map.
In order to focus on more important feature information and suppress invalid feature information, and improve the detection accuracy of small and tiny object, we need to consider feature enhancement operations for feature extraction operations on a single feature map. In this paper, based on the Convolutional Block Attention Module (CBAM) 32 in the mixed domain, we propose the feature enhancement, and the feature representation ability is stronger. Figure 8 shows the structure. CBAM (Convolutional Block Attention Module) is a lightweight convolutional attention module, which combines the attention mechanism modules of channel and space. CBAM includes CAM (Channel Attention Module) and SAM (Spatial Attention Module) sub modules, which respectively perform attention operations on channels and spaces. Given a feature map, the CBAM module can serialize the attention feature map information on the channel and space dimensions, and then multiply the two feature map information with the original input feature map for adaptive feature correction to generate the final feature map. CBAM module can not only reduce the amount of parameters and computing power but also embed in any existing network architecture to improve performance. The attention module enriches the extracted high-level features in the channel dimension and the space dimension by taking the global average pooling operation and the global maximum pooling operation. After obtaining the weight of the space and the channel, it is weighted to the initial features to complete dual attention adjustment of features.

CBAM Attention Mechanism Module Structure.
In order to visualize the improvement effect of the attention module on the feature information of small and tiny object, two typical attention modules of Squeeze-and-Excitation (SE) 33 Attention module and Effective Channel Attention (ECA) 34 module are selected for comparing with this paper’s CBAM, as shown in Table 2. The CBAM attention module used in this paper improves the model performance which is better than the SE module and the ECA module. This is because the CBAM attention module can learn the importance of different feature channels of the feature map at a deeper level, and reinforce the important information of the object, and weak the irrelevant unimportant information. It can enhance the shallow perception and representation ability of small target features. Since the CBAM module considers feature extraction in both the channel dimension and the space dimension, the high-level features can enrich and the accuracy of small and tiny object detection can improve.
The optimized object size classification.

Therefore, this paper embeds the CBAM module into the feature extraction network backbone of YOLOv5s. We propose the improved CBAM-YOLOv5s model, as shown in the Figure 9.

Feature extraction network structure.
Loss function
The loss function in the YOLOv5s model consists of three parts: the bounding box regression score, the objectness score and the class probability score. Its expression is as follows.


The definition and calculation diagram of GIoU loss.
GIoU loss adds the measurement method of the intersection scale. On the one hand, this operation solves the problem that the loss function is non-differentiable when IoU = 0, that is, the IoU loss cannot optimize the situation when the prediction box and target box do not coincide. On another hand, it also solves the situation that the IoU loss cannot distinguish the prediction box when the prediction boxes are the same and the IoUs are also the same. However, GIoU loss cannot deal with the situation when the prediction box is inside the target box and the size of the prediction box is the same. In this situation, the difference set between the prediction box and the target box is the same. Therefore, the GIoU values of these three states are also the same. As shown in Figure 11.

The situation of the same GIOU.
In order to solve the shortcomings of the above GIoU loss, the Complete Intersection over Union loss (CIoU loss)
36
is used to achieve prediction. The formula is as follows.
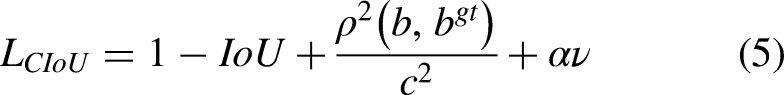
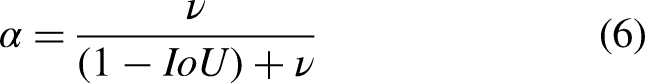

The CIoU loss considers the overlapping area, centre point distance and aspect ratio of bounding box regression, but it ignores the real difference between width and height and its confidence, the effectiveness of model optimization is limited. For solving this problem, Yi-Fan Zhang et al. disassembled the aspect ratio on the basis of CIoU loss,
21
and he proposed an effective intersection over union loss function (EIoU loss). The penalty term of EIoU loss is based on the penalty term of CIoU loss, the influence factor of aspect ratio is disassembled, and the length and width of the target box and anchor box are calculated separately. The loss function consists of three parts: overlap loss, centre distance loss and width high loss, where the width height loss minimizes the difference between the width and height of the target box and the anchor box. EIOU Loss is shown in the formula:
The design of lightweight model
The design of redundancy feature map
The feature extraction of object detection relies on conventional convolution, and a certain number of convolution kernels are used to convolve the input image to generate a corresponding number of feature maps. In Figure 12, the Focus convolution operation of one image generates 32-dimensional channels feature maps.

Feature map of different channels with convolution operation.
The feature map of Figure 12 contains rich and redundant feature information to ensure the understanding of the input and to identify and locate the object. However, a large amount of redundant information also brings unnecessary computation.
In order to reduce the calculation of the model, this paper optimizes the feature map generation method of the feature extraction network backbone by introducing the ghost module. It would generate the redundant feature maps in a low-cost way, and it can reduce the model parameters without losing vital feature information. The model’s calculation is reduced. The ghost module adopts a new convolution method, the principle is as follows: first, conventional convolution with less calculation amount can generate a few feature maps, and then using fewer feature maps with linear operations can generate a new similar feature map. Finally, it combines the information from two sets of feature maps and outputs as all feature information.
If the size of input feature map is 

The feature extraction network of YOLOv5s is composed of four layers of conventional convolution and three layers of convolution-fused cross-stage local bottleneck network (bottleneckCSP). If we replace the original bottleneckCSP structure and conventional convolution with ghost module directly, on the one hand, it will bring a large amount of model calculation and increase the complexity of the model, on the other hand, it will lead to the repetition of gradient information, and even lead to the problem of gradient vanishing.
In order to solve the above problems, based on the ghost module, this paper designs ghost-bottleneck structures and ghost-bottleneck CSP structures, as shown in Figure 13.

Improved ghost-bottleneck structure and ghost-bottleneck CSP structure.
The bottleneck structure is a structure improvement method that proposed in order to reduce the number of parameters. The Table 3 analyzes the number of parameters.
Comparison of introducing ghost-bottleneckCSP structure.

In Figure 14, it is assumed that the input feature map is a 256 dimensional channel and the output feature map is also a 256 dimensional channel. If the

Comparison between conventional convolution and bottleneck convolution.
So, the ghost-bottleneck structure is designed with the ghost module, as shown in Figure 13(a). The ghost-bottleneck is composed of two stacked ghost modules. The first ghost module is used as an extension layer to increase the number of channels. The second ghost module is used to reduce the number of channels to match the shortcut path. Then the shortcut is used to connect the input and output of these ghost modules. It added the batch normalization operation and the Leaky Relu activation function behind the first ghost module, and the second module only adds batch normalization. After that, the residual structure is used to superimpose features with the input, which can enhance the gradient value of back-propagation between layers. This operation also can avoid the gradient vanishing caused by the deepening of the model depth, and can extract more fine-grained features without worrying about network degradation.
In order to further reduce the computational bottleneck and improve the problem of gradient vanishing, the CSP structure is introduced to form the ghost-bottleneck CSP structure, as shown in Figure 13(b). It divided the input into two branches. One of branch passes through a standard GBL module, that is, ghost module + batch normalization operation + Leaky Relu activation function. Then it passes through the ghost-bottleneck structure, and batch normalization is used to reduce internal covariate shifts and to accelerate the network training process. We perform the concatenate operation between another branch that deal with conventional convolution and above result. The design of this CSP structure is to reduce computational bottlenecks and memory consumption, and improve the problem of gradient vanishing, so that it can extract richer feature information.
This paper uses the new ghost-bottleneckCSP structure to replace the original bottleneckCSP structure, and obtains the ghost-bottleneckCSP YOLOv5s model. The Figure 15 shows the feature extraction network backbone.
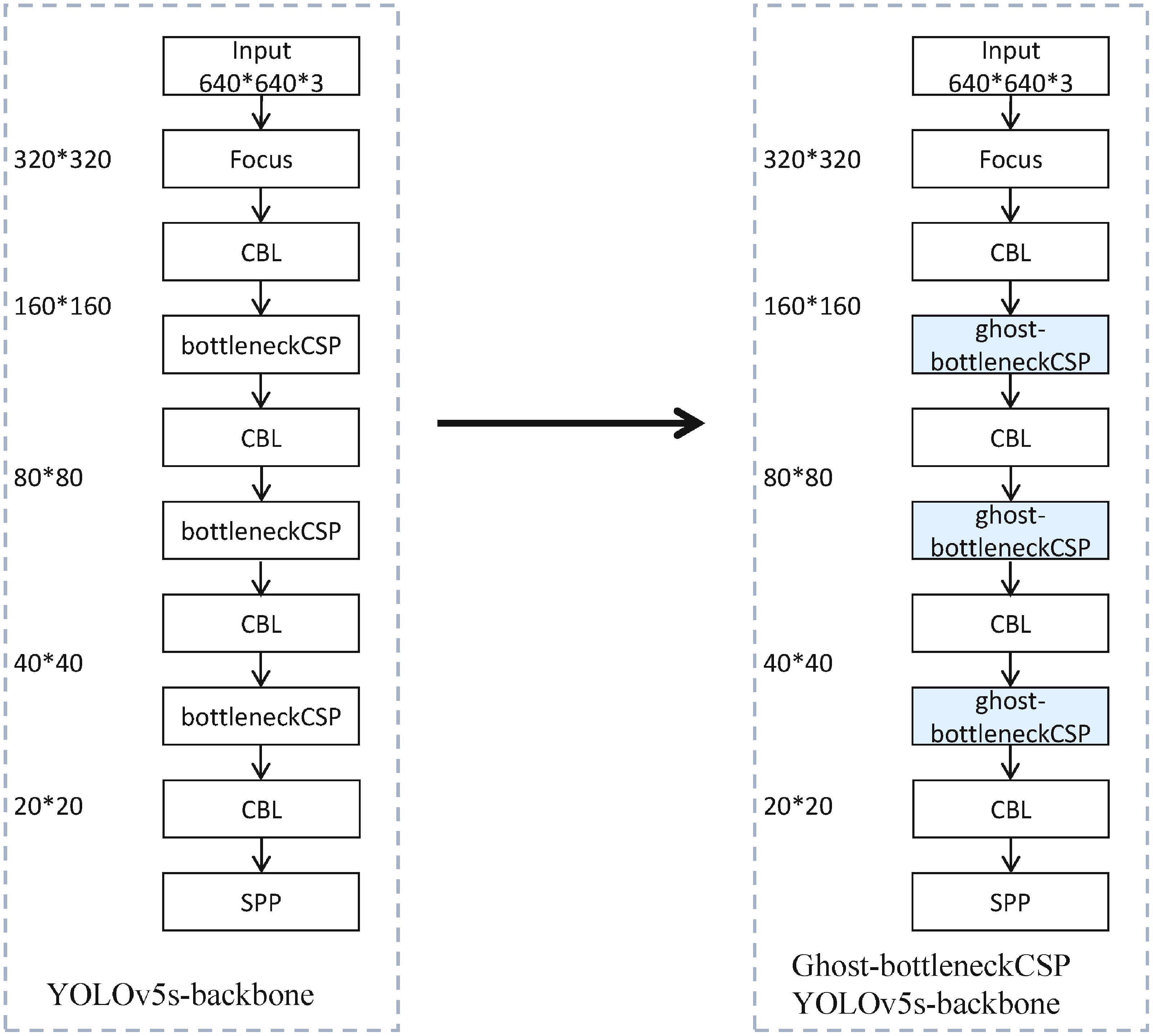
Comparison of backbones.
The Table 3 shows the parameters and floating-point calculations of the model.
As can be seen from the above table, after using the new module, the number of parameters of the model decreased by 9.2%, while the amount of floating-point operations decreased by 24.3%. The effect of lightweight improvement is also confirmed.
The design of depth separable convolution
The feature fusion network neck layer of YOLOv5s has four CBL structures (Conv + Batch Normalization + Leaky Relu), that is, the feature fusion network contains numerous conventional convolution. The conventional convolution leads to a large amount of parameters, it is difficult to deploy on low-cost edge devices. So, it is necessary to make lightweight improvements for conventional convolution. Based on the existing research, 37 we can use the Depthwise Separable Convolution (DSConv) 38 to replace conventional convolution, this operation can reduce the large number of parameters in the convolution operation.
Suppose 
Comparison of models using DSConv.

It can be seen from the above table that, after using the DSConv, the number of parameters reduce by 12.7%, and the calculation of floating-point numbers reduce by 7.3%, which proves that DSConv plays a positive role in model lightweighting.
Experimental results and analysis
Dataset
In this paper, the low-altitude small UAV is used as the detected object. But there is no suitable dataset for low- altitude small UAV detection. It improved the dataset used in this paper on the basis of the UAV dataset provided by Google. The original dataset contains 9000 images of civil UAVs in different environments. Firstly, we filter the dataset to remove the unqualified detection images. Then, we expand the dataset by collecting relevant pictures on the network. Finally, we further expand the dataset by intercepting some UAV video images. We produce an AntiDrone dataset, which contains 7500 images, 6750 of which are used for training and 750 for testing and verification. Figure 16 shows some data samples.

Dataset part image.
Lightweight deployment and experimental configuration
Embedded device selection
We choose the Jetson nano as the AD-YOLOv5s deployment platform. The device can deliver 472 GFLOPs for taking on modern AI algorithms, and it has great advantages in price. It uses a 64 bit quad-core ARM A57 processor with a working frequency of 1.43 GHz. It has 128 CUDA cores at just 5 to 10 watts. It also includes a 4 GB LPDDR4 memory. The operating environment JetPack4.4 developed by NVIDIA provides a complete desktop Linux environment, which supports CUDA Toolkit and cuDNN.It is an AI edge computing device suitable for developing a small structure, low cost, and low energy consumption.
TensorRT acceleration
Jetson nano can use TensorRT to accelerate model inference. TensorRT uses inter-layer fusion (tensor fusion) and data accuracy calibration to optimize and accelerate neural network models. During model inference, the GPU completes the data calculation by launching different CUDA cores. Since the expression range of
Evaluation indicator
For object detection, Precision and Recall are used usually to evaluate the detection performance of the model. Since the Precision and Recall are affected by the confidence, these indicators cannot reflect fully the performance of the detection model. In the experiment, we introduce the average precision 
Experiment configuration and training
The training server of model is Ubuntu 16.04 operating system, Intel (R) Xeon (R) CPU E5-2630 v3 @ 2.40 GHz, NVIDIA GeForce RTX2080Ti video card (with 12G video memory). It built the model based on the PyTorch deep learning framework, and the development environment is PyTorch1.4, cuda10.1 and python3.7.
In the model training process, we use the Adam optimizer for training. We set the initial learning rate to 0.01, the weight attenuation is 0.0001, the momentum is 0.9, and the batch size is 16. Single-scale training is used in all experiments, and the input size of image is 640*640 pixels. According to the characteristics of the model, the pre-training model is yolov5s.pt. Each experiment runs 200 iterations.
We can see from the Figures 17 and 18, after 200 rounds of epoch training, the loss function curves and the evaluation indicator curves of the model tend to be stable, which verifies that the convergence of the model is effective.

Line chart of loss function of model loss.

Line chart of evaluation indicator values.
Comparison experimental analysis of object detection performance
Table 5 shows the comparison results between the AD-YOLOv5s model and the YOLOv5s model. The only embeds CBAM modules is named CBAM-YOLOv5s, it named the model of optimizing the feature fusion layer as improved-YOLOv5s, and the model of combining structural lightweight design with feature enhancement is named as AD-YOLOv5s. As shown in Table 5, compared with the YOLOv5s model, we introduced the CBAM attention mechanism to make the mAP, Recall and
Comparison results of different model.
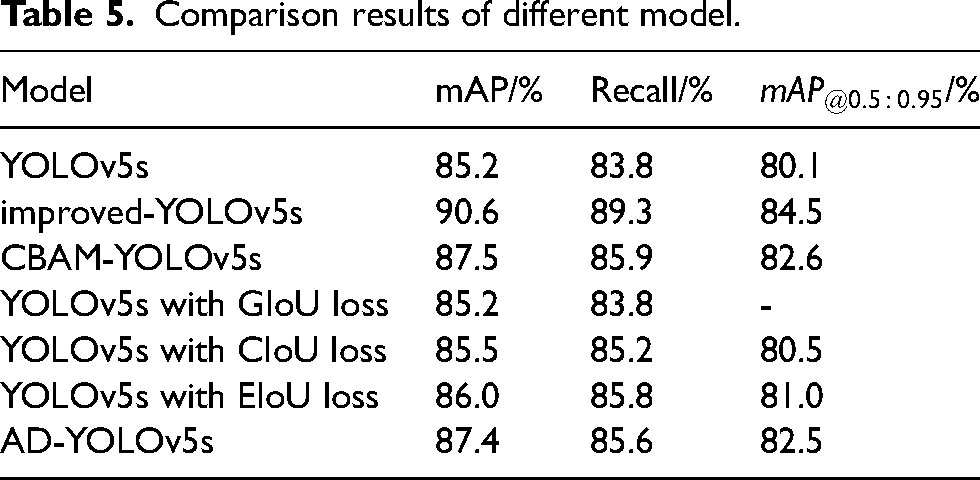
The
Finally, Table 5 shows that compared with the yolov5s model, the proposed AD-YOLOv5s model has a 2.2% increase in the mAP value, a 1.8% increase in the Recall value, and a 2.4% increase in the

Comparison of test results with different model.
Figure 19 show that after we improved the feature fusion layer of yolov5s model, added CBAM attention mechanism and improved loss function operation, the accuracy of the new model for small UAV detection has been improved and the object false detection rate has been reduced, which proves the feasibility of the proposed method in this paper.
Comparison experimental analysis of model lightweight
Table 6 analyzes the AD-YOLOv5s network framework of this paper.
AD-YOLOv5s network framework.

We calculate the parameters and GFLOPs of the network models, as shown in Table 7. The total number of parameters of the AD-YOLOv5s network model in this paper is about 4.32 million, and the number of parameters of the original YOLOv5s network model is about 7.06 million. Compared with the original model, the number of AD-YOLOv5s model parameters reduce by 38.8 %. The GFLOPs of the AD-YOLOv5s model is 70.1 % of the original model. Experiments result show that the parameters and computational complexity of AD-YOLOv5s network model is lower than the YOLOv5s network model.
Comparison of parameters and GFLOPs.

We perform a comparative experiment on the lightweight optimization of the model. In this experiment, the TensorRT module is used to accelerate the optimization of the model. The trt suffix is uniformly used to represent the accelerated model. Table 8 shows the comparison results.
Comparison of parameters and GFLOPs.

The Table 8 shows that it has improved greatly the detection speed of each network model by introducing TensorRT acceleration. First of all, compared with the YOLOv5s model, the YOLOv5s-trt model use TensorRT acceleration to reduce the mAP value by 1.3% and the frame rate is increased to 20.5fps, the detection speed is twice times as before. Secondly, compared with YOLOv5s-trt, Ghost bottomleneckCSP-YOLOv5s has improved the mAP by 2.8%, but it reduced the GFLOPs by 24.3%. And then, compared with YOLOv5s trt, DWConv-YOLOv5s- trt model reduces the GFLOPs by 7.3%, and it would improve the mAP by 2%. Finally, compared with the YOLOv5s model, the AD-YOLOv5s-trt model has improved the mAP by 2% and reduced the GFLOPs by 29.1%, and it increased the frame rate to 27.6fps. From the experiment, we can see that the depth separable convolution can reduce the computational complexity while maintaining the model effect.
The proposed method of this paper enables YOLOv5s algorithm to achieve real-time detection effect on embedded devices. In order to show the real-time detection effect, this paper uses YOLOv5s and AD-YOLOv5s trt models to experiment respectively, and it shows the detection results at the bottom of Figure 19. The proposed AD-YOLOv5s model can detect low-altitude small UAV object effectively and improve the detection rate. However, the confidence of the model for small object detection is affected greatly by the environment. This issue needs to be studied in future work.
Conclusion
This paper proposed an AD-YOLOv5s model for low-altitude small UAV detection. Firstly, we proposed an optimization method for feature enhancement to solve the problem of small object detection, and introduced the EIoU loss function to replace the original GIoU loss function. Secondly, based on the ghost module and depth separable convolution, we optimized the feature extraction network backbone and feature fusion layer neck in YOLOv5s model. Finally, we used TensorRT to accelerate the model on Jetson nano. The experimental results show that the mAP of the proposed model is improved by 2.2%, and the value of Recall by 1.8%, and the value of GFLOPs is reduced by 29.9% and parameters by38.8%, and achieved 27.6 FPS when the proposed model is deployed on a low-cost edge computing device (jetson nano).The proposed model can be deployed on the low-cost edge device of Jetson nano, and it would improve the model detection frame rate from 12.6FPS to 27.6FPS, it can meet the detection accuracy of low-altitude security tasks and the lightweight requirements of deployment requirements.
Footnotes
Declaration of conflicting interests
The authors declare that there are no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Key R&D Program of China, No.2022YFC3320800 and Zhejiang Provincial Key R&D Plan of China, No.2021C01040.