
Abstract
High-quality seeds improve the germination rate. Therefore, seed selection before sowing peanuts is crucial. Current peanut seed selection methods include color sorters and sieving machines, which are efficient but lack accuracy due to their reliance on a single indicator. Manual selection is inefficient and subject to subjective influences. Although machine vision and deep learning have performed well in crops such as corn and pepper, most existing research is based on PC or MATLAB platforms, which are not portable and are prone to interference, making them unsuitable for field applications. This study developed a lightweight model for recognizing peanut seed epidermal features. The model was based on deep learning and model quantization techniques. The transfer learning method was used to use four pre-trained models, EfficientNet_b0, EfficientNetv2-b0, MobileNet_v2_35_224, and NasNet_Mobile, as feature extraction layers, the input layer was added before the feature extraction layer, and the dropout and dense layers were added after the feature extraction layer to construct a classifier. The peanut seed selection network(PSSNet) models were constructed and named PSSNet-E, PSSNet-E2, PSSNet-M, and PSSNet-N, respectively, and trained on the Huayu 22 peanut seed dataset constructed in this study. The constructed models were compressed using model quantization technology, and four quantized models were obtained, namely PSSNet-Ef, PSSNet-E2f, PSSNet-Mf, and PSSNet-Nf. Finally, PSSNet-Mf, which had the best model evaluation, was selected as the peanut selection model for this study and deployed on a prototype for testing. Compared with the unquantized model, the size of the quantized model was reduced by two-thirds and the running speed was increased by 37%. A total of 400 Huayu 22 peanut seeds were selected as test samples, and 5 selection tests were conducted.The results showed that the average accuracy was 95.3%, which met the requirements of peanut selection at the production site.
Introduction
Peanut is an important cash crop.1,2 As a large peanut-growing country, in 2021, the peanut planting area in China was 4.75 million hectares, with a total yield of 18.2 million tons. 3 Approximately 8%–10% of the total peanut production is used as seeds for sowing every year. Peanuts have hard husks; manual and mechanical shelling can easily cause damage to the peanut kernels. If the seeds for sowing are not properly selected, it will not only reduce the germination rate of peanut seeds but also cause extensive waste. Therefore, identifying good peanut seeds quickly and accurately is essential for planting. The epidermal feature of peanut seeds can denote the planting quality to a certain extent. Seed selection is very important for production of crops.
Currently, two methods are commonly used. One is to use a peanut color sorter or a sieving machine for appromimate selection according to color or size. This method yields high efficiency but a single index which affects accuracy. The other is to manually select good peanut seeds with intact seed coats and full particles and remove broken and wrinkled peanut seeds. Manual selection is high performance but low efficiency. With China’s aging population, the rural labor population is gradually decreasing. In addition, the cost of manual selection is increasing, and meeting the quality of mechanized sowing is difficult. Therefore, developing intelligent peanut seed selection equipment that can replace manual selection process is an urgent requirement.
In recent years, with the advancement of science and technology, machine vision and deep learning (DL) technologies have been widely used in modern agricultural production and have achieved good results.4–7 A jujube (a fruit popular in China) classification model based on convolutional neural networks (CNNs) and transfer learning (TL) was established and achieved a test accuracy of 94.15% on a small dataset. 8 Using a deep classification model, an automatic grading system for zizania was designed and the accuracy of the system reached 95.62%. 9 A computer vision system, using machine learning (ML) and image processing technology, was proposed to identify defects and grade tomatoes by using features such as color, texture, and shape. This system achieved an accuracy of 97.09%. 10 It shows that it is feasible to use deep learning methods to recognize the epidermal feature of peanut seeds.
At present, there are many researches on the epidermal feature recognition of seeds. One such study developed a method for estimating maize impurity rates using deep residual networks, which can provide direction for the quality control in maize processing. 11 Haploid and diploid maize seeds were successfully identified by using convolutional neural network and transfer learning methods, with the highest accuracy rate reaching 94.27%. 12 Similarly, the classification of pepper seeds based on convolutional neural network and support vector machine was achieved, with a classification accuracy exceeding 99%. 13 However, there are few studies focused on the epidermal feature recognition and classification of peanut seeds. Futhermore, the existing studies are predominantly based on PC or MATLAB software platforms, which are inconvenient to move and prone to interference, making them less suitable for on-field applications.
Deploying model algorithms on embedded hardware platforms and employing them for on-field applications constitute a new research direction. As such, researchers are now focusing on the size, speed, and efficiency of models. A number of lightweight CNNs suitable for hardware deployment have emerged, such as NASNet-Mobile, 14 MobileNets,15,16 and EfficientNets. 17 TL (transfer learning) was used to improve the lightweight model MobileNetV3 for garbage classification, established a new GNet model, and successfully deployed it on Raspberry Pi 4B, achieving an accuracy of 92.62%. 18 Through the TL (transfer learning) of MobileNet, a plant disease classification model was developed and deployed on the Android platform. This model classified six grape leaf diseases with an average accuracy of 87.50%. 19 The lightweight Xception model, based on CNNs, was deployed on Raspberry Pi for detecting tomato leaf diseases. This reduced hardware costs while maintaining high accuracy (>99%), providing valuable insights for the development of portable embedded detection devices. 20 It can be seen that it is feasible to deploy the improved lightweight neural network model on the embedded hardware platform to improve the portability and real-time performance of the equipment.
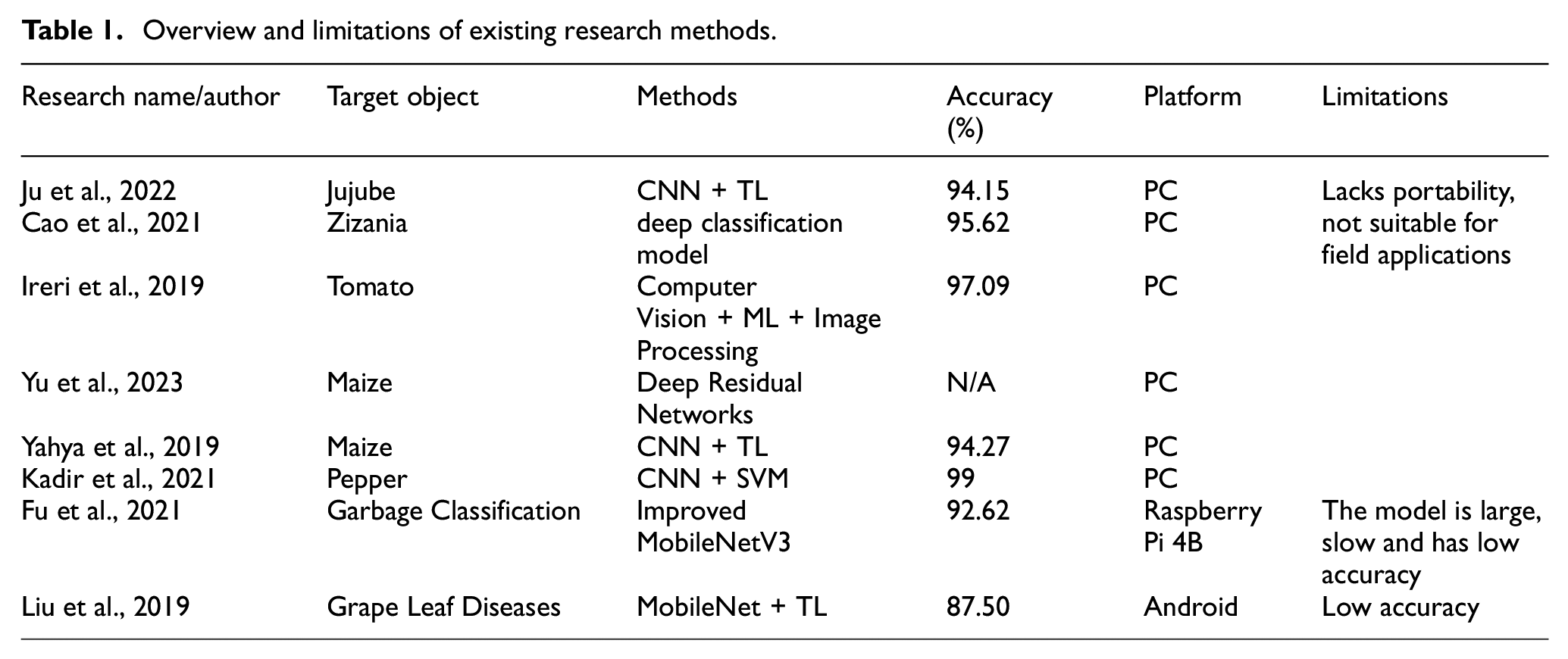
Table 1 provides an overview of existing research methods and their limitations. While these methods have made significant strides in agricultural product classification and sorting, they are primarily limited by their reliance on PC-based platforms. Despite their effectiveness in image recognition and classification tasks, such platforms are not suitable for practical field applications.These methods often depend on stationary computers, limiting image processing to controlled environments, which are far from real field conditions. This limitation hinders their ability to be directly applied in real-world scenarios where on-site seed sorting and selection are essential.
Overview and limitations of existing research methods.
In response to these limitations, this study developed a lightweight model for recognizing peanut seed epidermal features. The model was based on deep learning and model quantization techniques. This approach specifically addresses the need for a practical, field-deployable solution by implementing the model on an embedded hardware platform. This not only reduces the model size significantly but also enhances the processing speed, making it feasible for real-time applications directly in agricultural environments.
Materials and methods
Image acquisition
In this study, Huayu 22 peanut seeds were selected as the research materials due to their high yield, superior quality, and wide adaptability. This variety, developed by the Shandong Peanut Research Institute through 60Coγ radiation mutagenesis combined with hybridization, is known for its excellent drought and flood resistance, balanced disease resistance, and shorter growth period compared to other similar varieties.
The samples included three types of seeds: good peanut seeds, broken peanut seeds, and wrinkled peanut seeds. There are 5000 pictures of each type of peanut seeds. All images were acquired using a WX605V1 camera (VISHINSGAE, Shenzhen City, China) during the sorting and conveying of peanut seeds with a resolution of 640 pixels × 360 pixels. Images of the samples are shown in Figure 1.

Images of peanut seeds.
Image preprocessing
The reason for using images of the same size in CNN training is to ensure consistency and compatibility throughout the training process. The 1:1 aspect ratio adapts to the VGG model architecture, which facilitates convolution operations and provides symmetry information. The collected picture of peanut seeds has a pixel size of 640 × 360, and the peanut seeds are not in the center of the picture, so they need to be processed before they can be used Therefore, an image preprocessing program was designed using OpenCV and Python. The image processing process is illustrated in Figure 2.
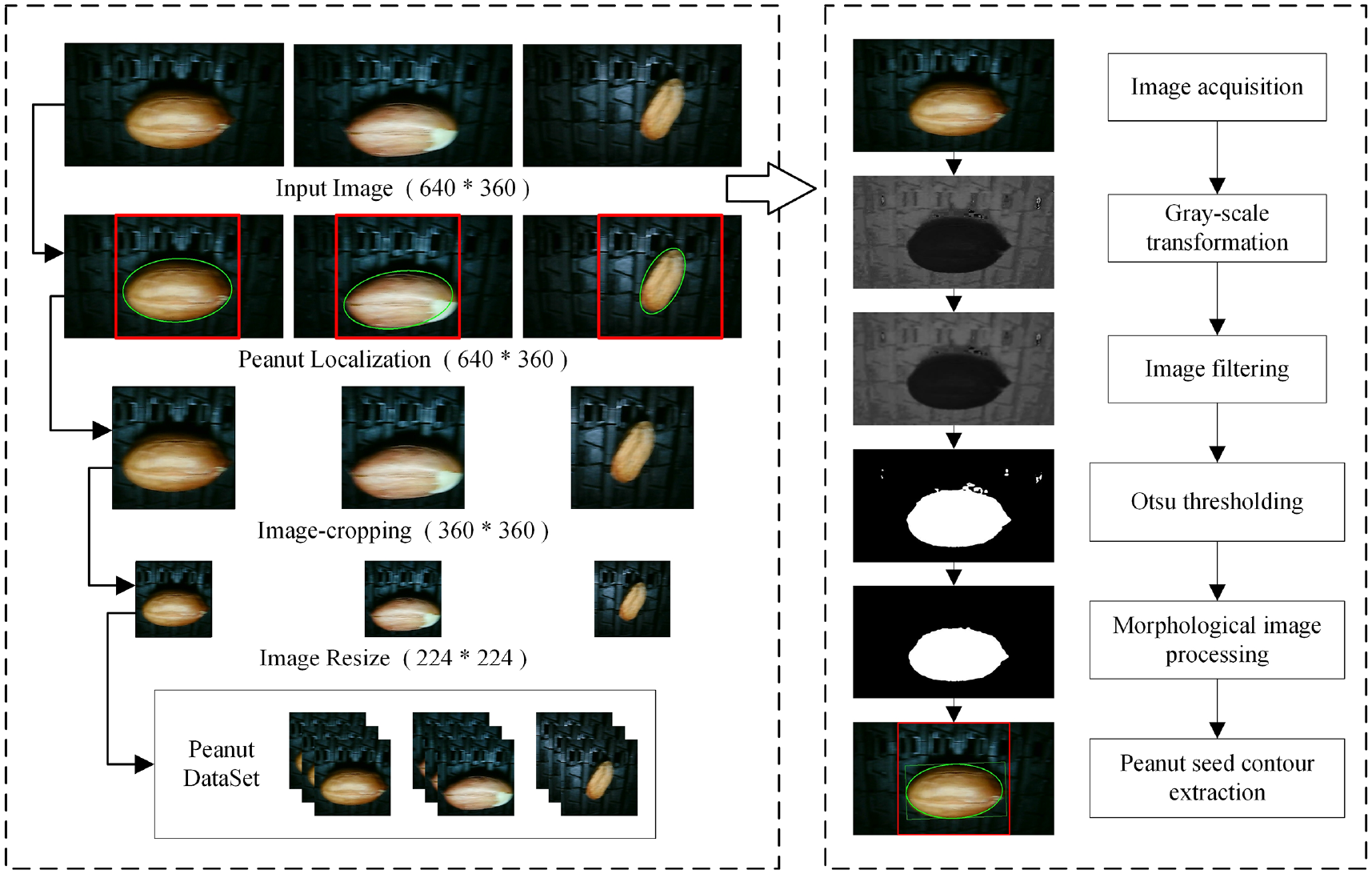
Preprocessing process.
First, the color images of peanut seeds were converted from the RGB color space to the HSV color space, followed by histogram analysis of the H channel (Hue), S channel (Saturation), and V channel (Value). As can be seen from Figure 3, the histogram of the H channel showed two distinct peaks, effectively distinguishing between the peanut seeds and the background. Therefore, the H channel was selected for further processing.
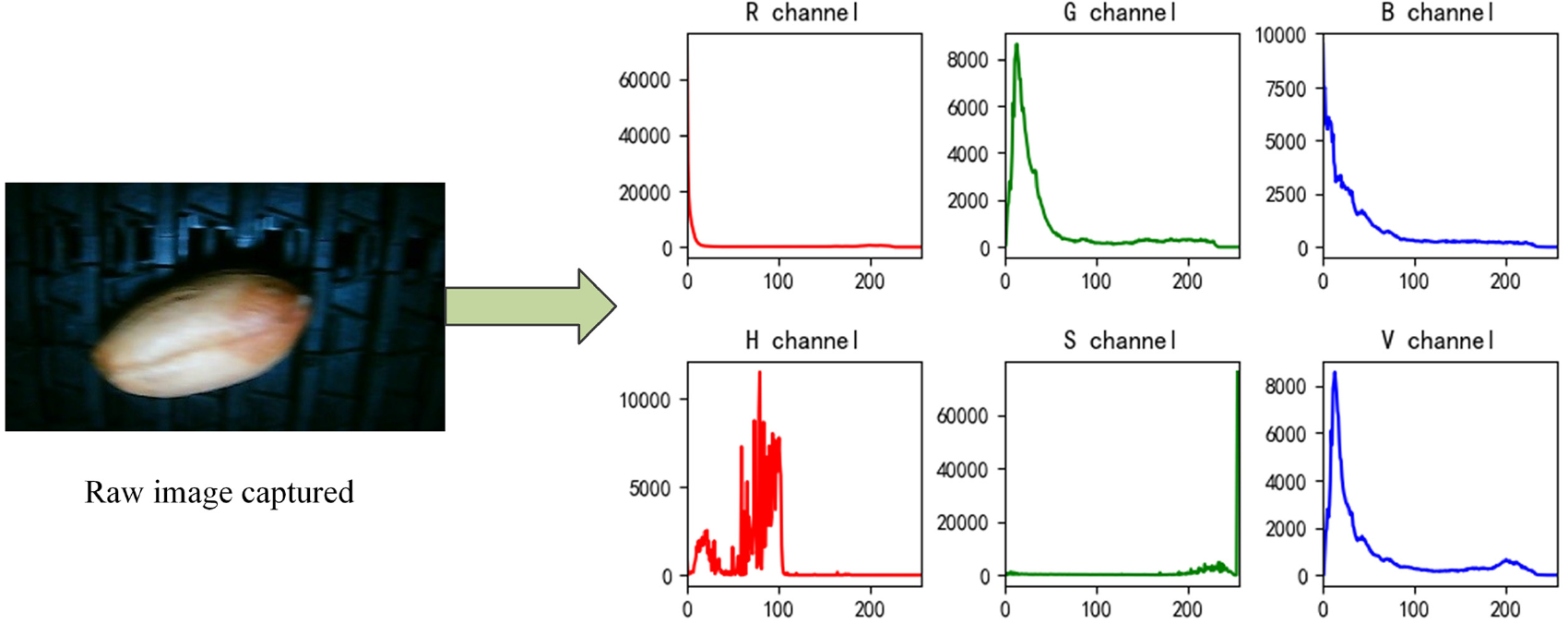
Color space conversion and histogram analysis of peanut seed images.
Next, the H channel was transformed into a grayscale image, and Gaussian filtering was applied to remove noise while preserving edge information. Following this, the Otsu thresholding method was used to binarize the image, automatically calculating the optimal threshold to separate the foreground (peanut seeds) from the background. The binarized image contained the contours of the peanut seeds and some noise, which was further refined using morphological operations (erosion and dilation) to remove noise and enhance the seed contours.
The minimum enclosing ellipse fitting algorithm was then used to extract the seed contours, and the image was cropped based on the center coordinates of the ellipse. Finally, the cropped image was resized to 224 pixels × 224 pixels to meet the input requirements of the neural network model. This preprocessing ensured that the processed peanut seed images not only met the training requirements but also avoided the loss of phenotypic features caused by image distortion.
Dataset settings
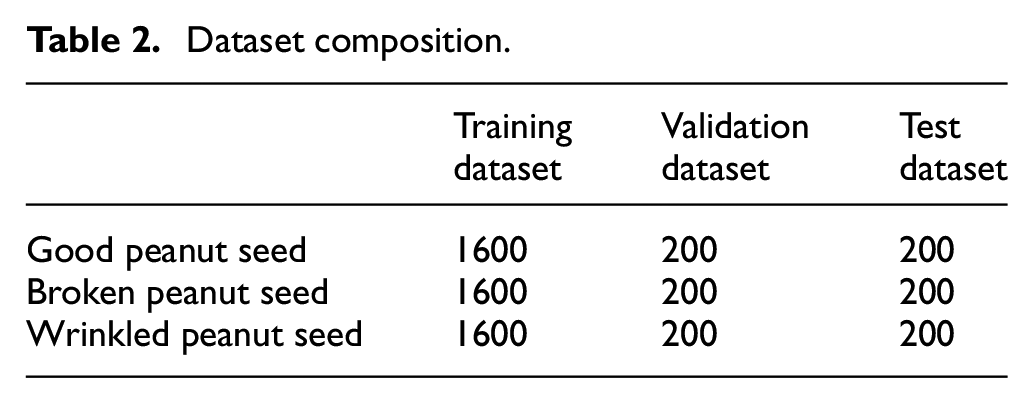
In total, 2000 images of good, broken, and wrinkled peanuts were manually selected from the preprocessed images to establish a dataset. The division ratio of the training dataset, validation dataset, and test dataset was 8:1:1. The dataset distribution is presented in Table 2.
Dataset composition.
Construction of selected models of peanut seeds
TL (transfer learning) has been a popular research direction in ML since it was proposed. 21 TL (transfer learning) refers to the construction of a new neural network by using a pretrained model. Because the weights in the pretraining model are obtained using a large amount of data training, the training time of the new model can be greatly reduced while ensuring the performance of the model.
The pretrained model in TensorFlow Hub 22 was used as the basic network for TL (transfer learning) to construct a lightweight CNN. TensorFlow Hub is an open-source ML model library developed by Google and includes a large number of neural network models trained on the ImageNet (ILSVRC-2012-CLS) dataset. The ImageNet dataset contains 1000 categories of images, and image classification neural networks trained on this dataset have better weights. The steps involved in model construction are as follows:
First, the input and top classification layers of the pretrained model were removed, and the remaining network was used as the feature extraction layer of the model. Next, the input layer was added before the feature extraction layer, and the dropout and dense layers were added after the feature extraction layer to construct a classifier. Dropout and regularization can effectively prevent overfitting, thereby improving the generalization ability of the model. Finally, higher model accuracy was accomplished by fine-tuning, and the peanut seed selection network (PSSNet) model architecture was established. The model architecture is depicted in Figure 4.
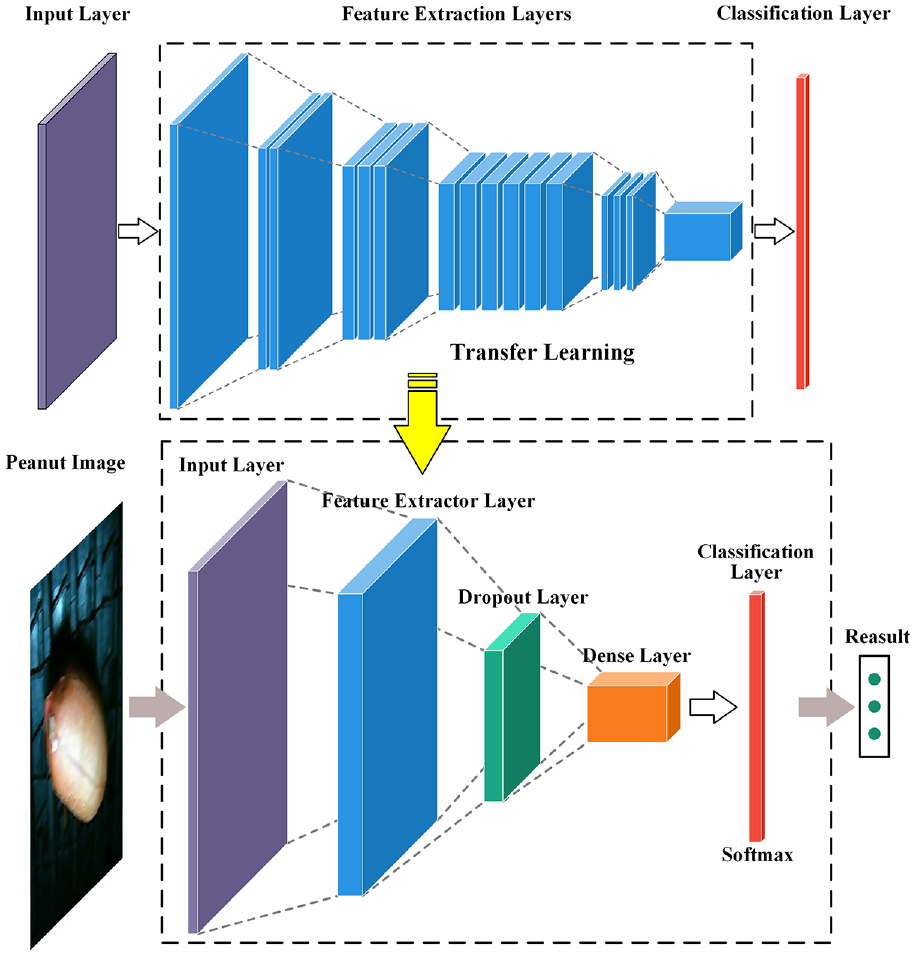
Schematic of the PSSNet transfer learning model structure.
Because the SGD optimizer offers the advantages of fast calculation gradient and good generalization performance, it was used for training the model to improve the learning speed.23,24 The learning effect of the model is the best when Learning_rate = 0.0001 and Batch_size = 32. 25 Other hyperparameter settings of the model are presented in Table 3.
Hyperparameter settings.

Quantification of peanut seed selection model
To further improve the performance of the model to meet the requirements of hardware deployment, model quantization technology was used to optimize the model. Model quantization 26 reduces the precision of the network model’s weights and activation values, transforming them from high to low precision, and is a key technique for compressing neural networks. It can be divided into post-training quantization (PTQ) and quantization-aware training (QAT).
Post-training quantization is the process of converting a trained floating-point model into a low-precision integer or fixed-point model. In post-training quantization, a fixed quantization method can be used to quantize all weight parameters and activation values to a specified accuracy. The advantage is that it is simple and easy to operate, and there is no need to modify the training process. The disadvantage is that the quantized model has lower accuracy, requires more quantization bits, and takes up more storage space.
Quantization-aware training considers quantization errors during the training process, making the model more suitable for quantization. Quantization-aware training introduces quantization errors during training, converting floating-point values and weights into low-precision integers or fixed-point numbers. This improves model accuracy after quantization. The advantage of quantization-aware training is that it can obtain better model accuracy, but the disadvantage is that the training process is relatively complex and requires the introduction of additional calculations. Through model quantification, the storage space and calculation amount of the model can be greatly reduced, thereby improving the deployment efficiency of the model in resource-limited environments such as mobile devices.
The basic formula for quantification is shown in equation (1):
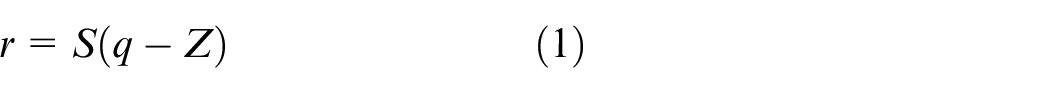
where r is a real floating value, q is a quantized integer, S is the scaling factor (an arbitrary positive real constant) required to convert the floating value into an integer and is usually expressed as a floating number in the software, and Z is the offset required for a floating value to become an integer zero point and is a constant of the same type as the quantization value q:
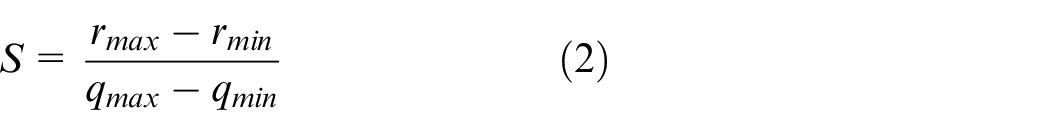
where


Equation (4) is the precision conversion during the quantization process; the parameters required in equation (4) are obtained using equations (2) and (3).
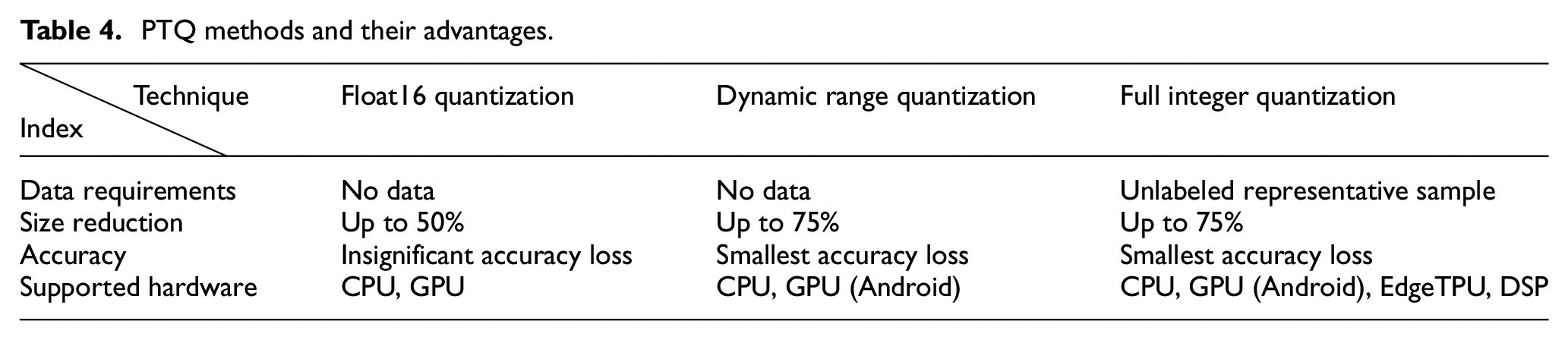
Compared with QAT (quantization-aware training), PTQ (post-training quantization) has a stronger generalization ability for neural network models and does not change the network structure, thus making it more suitable for model deployment applications. 27 The PTQ (post-training quantization) methods supported by the TensorFlow framework are listed in Table 4. As can be seen from the table, full integer quantization has the best effect on model size compression and supports a wide range of deployment hardware. Therefore, in this study, full integer quantization was used to compress the model.
PTQ methods and their advantages.
Training & testing platform
Google’s Colaboratory (Colab) was used as the model training and testing platform in this study. The software environment was Ubuntu 18.04 LTS 64-bit system. The open-source TensorFlow DL framework was adopted, and Python was used as the programing language. The platform configuration is presented in Table 5.
Platform configuration.

Evaluation metrics
To evaluate the performance of the model objectively and comprehensively, the precision, recall, and F-measure (PRF) evaluation method was used. 28
The variables were defined in the standard format confusion matrix for accuracy evaluation as follows:
TP: True positives, TN: True negative, FP: False positives, and FN: False negatives.
Accordingly, the aforementioned evaluation indices were defined as follows:
Positive predictive value (PPV), commonly referred to as Precision (P):
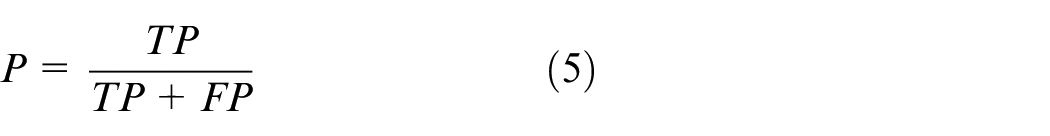
True positive rate (TPR), commonly referred to as Recall (R):
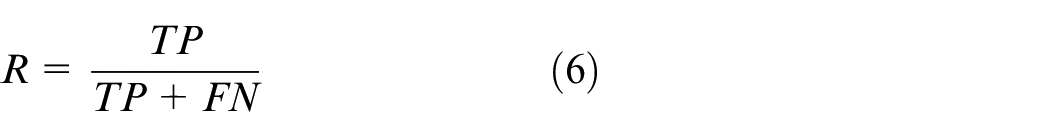
Accuracy (Acc):
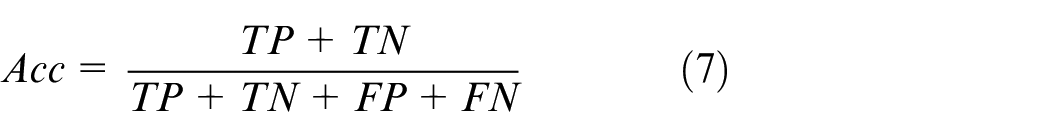
F-measure (

α = 1 was substituted into equation (8) to obtain the comprehensive evaluation index F1:
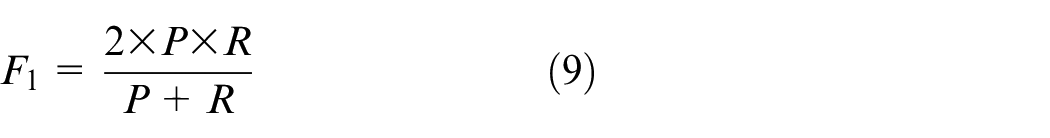
F 1 integrates P and R and can comprehensively reflect the network performance. When F1 is higher, it means that the test method is more effective.
Macroaverage is the arithmetic average of each type of performance indices, as shown in equations (10)–(13):
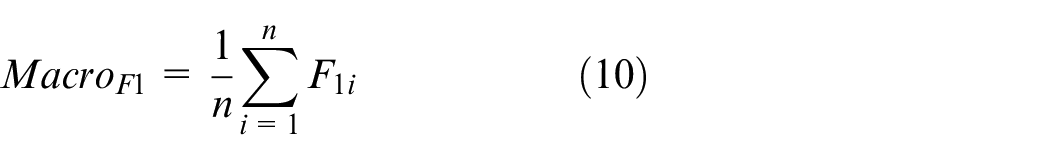
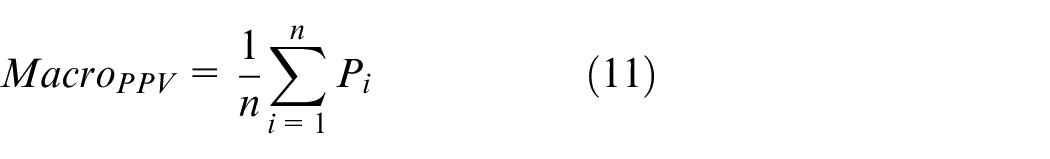
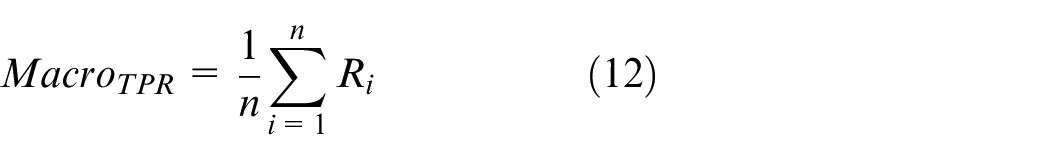
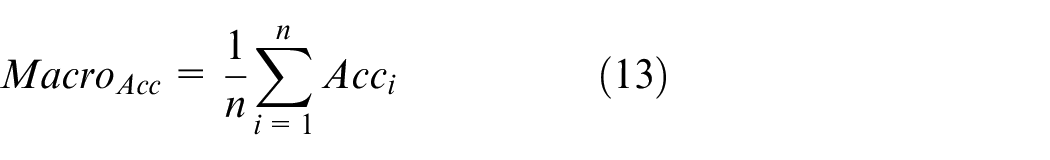
Hardware implementation
The schematic of the prototype machine designed in this study is illustrated in Figure 5. The prototype machine mainly comprises a vibrating seed metering device, a conveyor, an image acquisition device, a rejecting device, and a control system power device. The vibrating seed metering device and conveyor realize the continuous single-line and orderly conveying of peanut seeds. Image acquisition and rejection of bad peanut seeds (broken and wrinkled peanut seeds) are performed on the conveyor. Finally, the remaining peanuts are good peanut seeds.
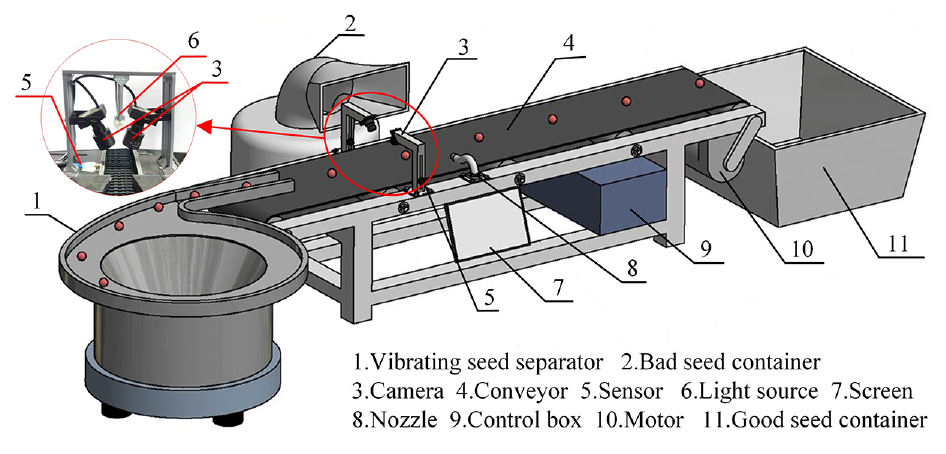
Schematic of the prototype machine.
The control system includes a Raspberry Pi 4B unit, an optocoupler isolation module, and a driver module. It is the brain of the prototype and controls the operation of the entire equipment, including the collection of images, analysis, and identification of images, and removal of bad peanut seeds. The other hardware configurations are listed in Table 6.
Prototype hardware parameters.

The image acquisition device mainly includes a diffuse reflection sensor, two CCD cameras (VISHINSGAE, Shenzhen City, China), and a light source. Two cameras were placed 50 mm above the conveyor at a 90° angle, with the light source in the middle of the two cameras. The image acquisition device was placed in a dark room to avoid interference from other light sources.
The rejection device includes a solenoid valve, a pneumatic nozzle, and an air compressor. When bad peanut seeds are identified, the control system sends an instruction to open the solenoid valve, and compressed gas is ejected from the pneumatic nozzle to remove the bad peanut seeds from the conveyor.
Results and discussion
Based on the aforementioned experimental setup and data processing workflow, we will present the training and testing results of the model, with a focus on evaluating its accuracy, efficiency, and performance after quantization.
Analysis of training results
Traditional lightweight neural networks, namely EfficientNet, MobileNet, and NASNet-Mobile, have a small size, high accuracy, and few parameters, and are suitable as TL (transfer learning) models for peanut seed selection tasks. Thus, four pretraining models, namely EfficientNet_b0, EfficientNetv2-b0, MobileNet_v2_35_224, and NasNet_Mobile, were used as the feature extraction layer to construct the peanut seed selection model, respectively termed as PSSNet-E, PSSNet-E2, PSSNet-M, PSSNet-N. They were then trained on the HuaYu 22 peanut seed dataset constructed in this study.
The training result data curve is shown in Figure 6. The model learning accuracy and loss curves show that the accuracy and loss of the four models stabilized after about 20 training rounds. By 50 rounds, their accuracy exceeded 97%, indicating that the PSSNet model structure proposed in this study has a fast convergence rate and performs effectively, significantly reducing training time.
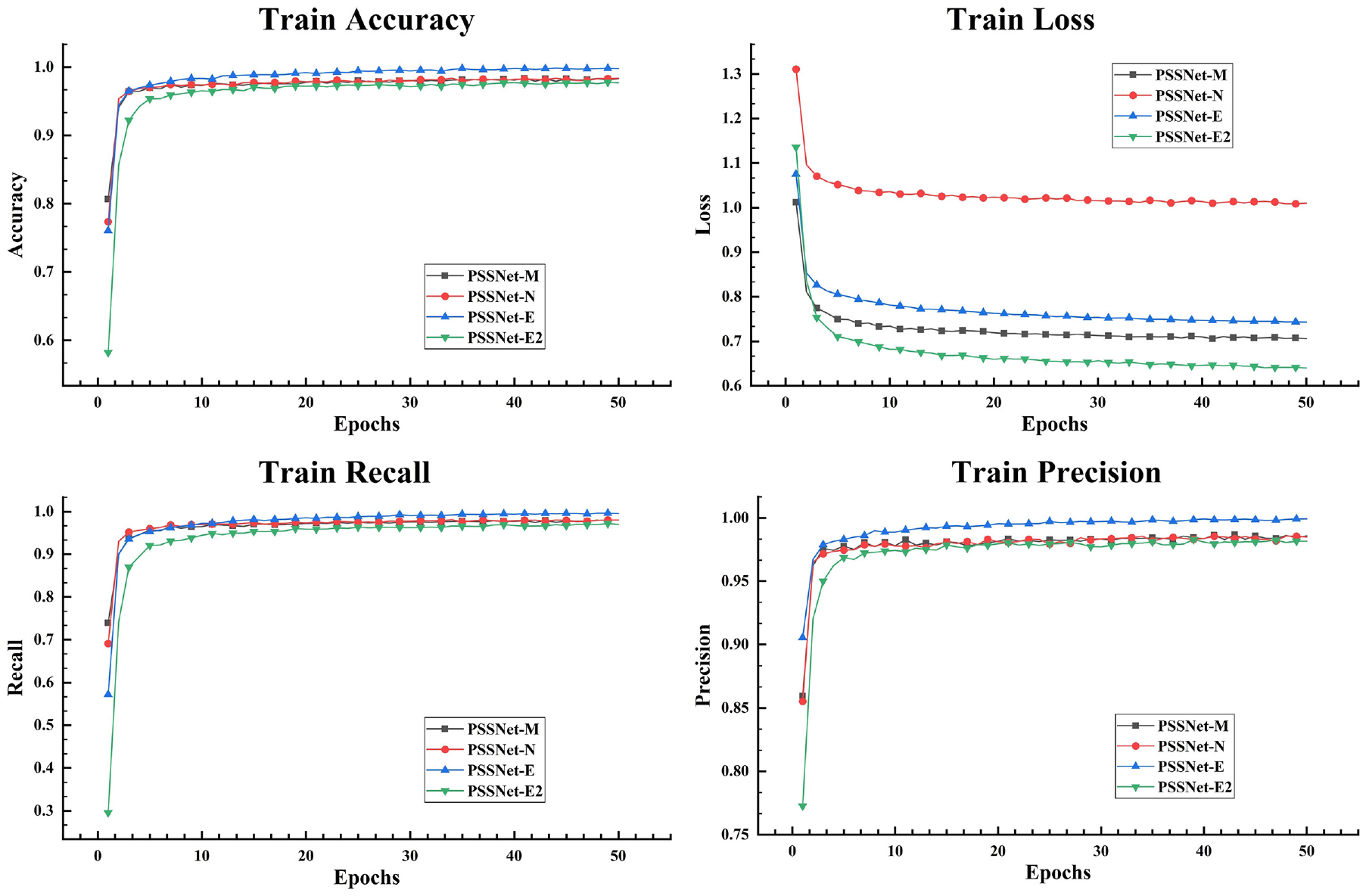
Model training curves.
The validation curves are shown in Figure 7. The validation accuracy curve indicates that all models converge quickly in the early stages of training and stabilize after around the 10th epoch. Among them, PSSNet-N and PSSNet-E are slightly ahead, showing validation accuracy close to or exceeding 98%, while the validation accuracy of PSSNet-M and PSSNet-E2 also remains at a high level, both above 97.5%. PSSNet-M and PSSNet-E2 have the lowest validation loss, indicating that they perform well in preventing overfitting and have strong generalization ability. In contrast, the validation loss of PSSNet-N is relatively high. Although it performs well in accuracy, the high loss value may mean that it is prone to overfitting in some cases. The accuracy of all models exceeds 98%, showing strong classification ability. In particular, PSSNet-N and PSSNet-E show high accuracy throughout the training process, but the differences between the models are small and the overall performance is relatively close. The validation recall curve shows that, except for PSSNet-E2 which exhibits large fluctuations in the early stages, the recall curves of other models are relatively smooth. All models stabilize at a high level after the 10th epoch, and basically remain above 98%, which indicates that these models perform well in detecting positive samples.
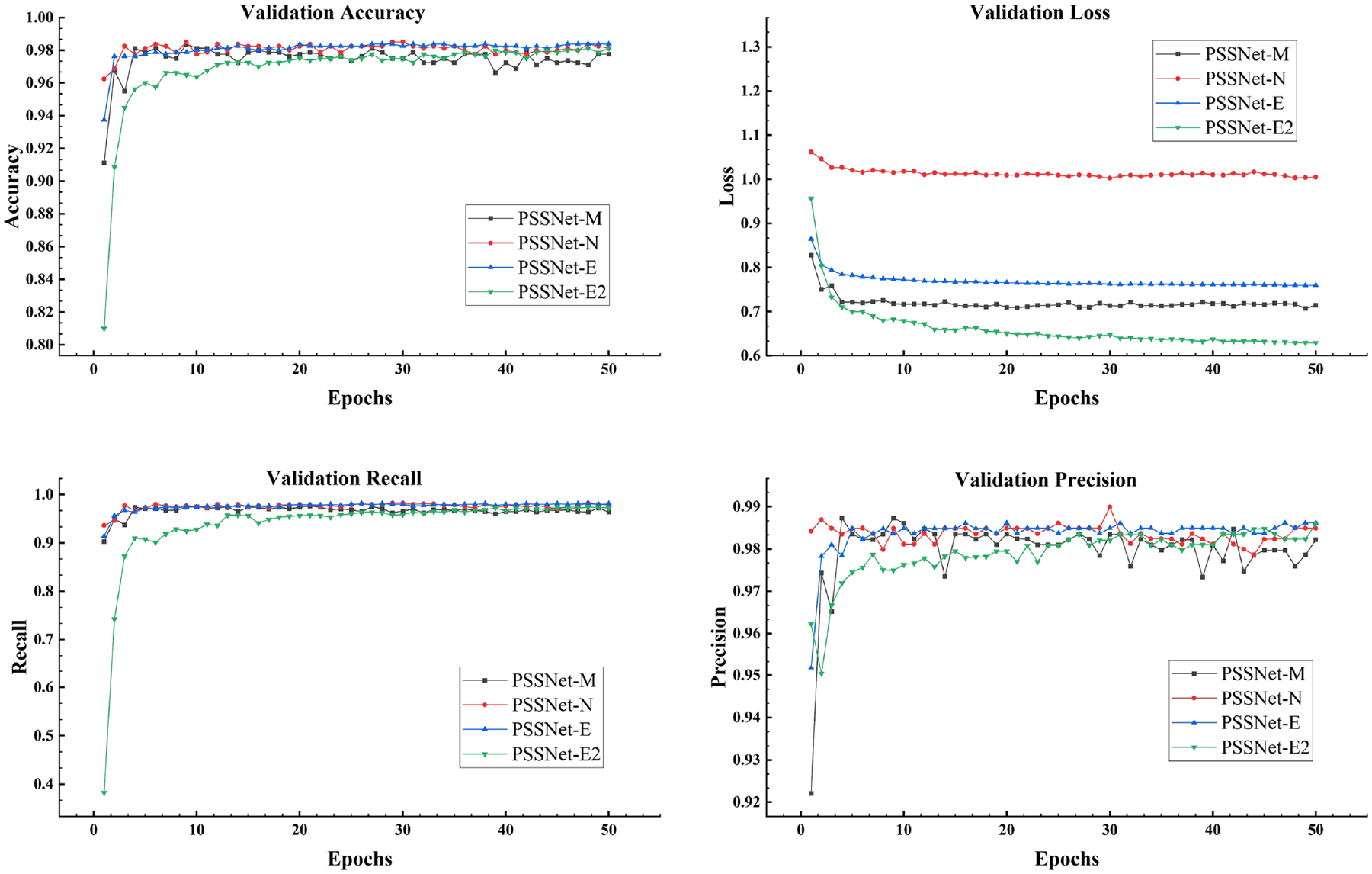
Model validation curves.
Figure 8 is the performance of the four models on the test dataset. The recognition accuracy of the four models for wrinkled peanuts all reached 100%. PSSNet-E2 had the best recognition effect. Only one broken peanut was mistakenly identified as a good peanut seed, which might be caused by the small broken area of the peanut seed. While the recognition accuracy of the three models, PSSNet-N, PSSNet-E, and PSSNet-M, decreased in turn.
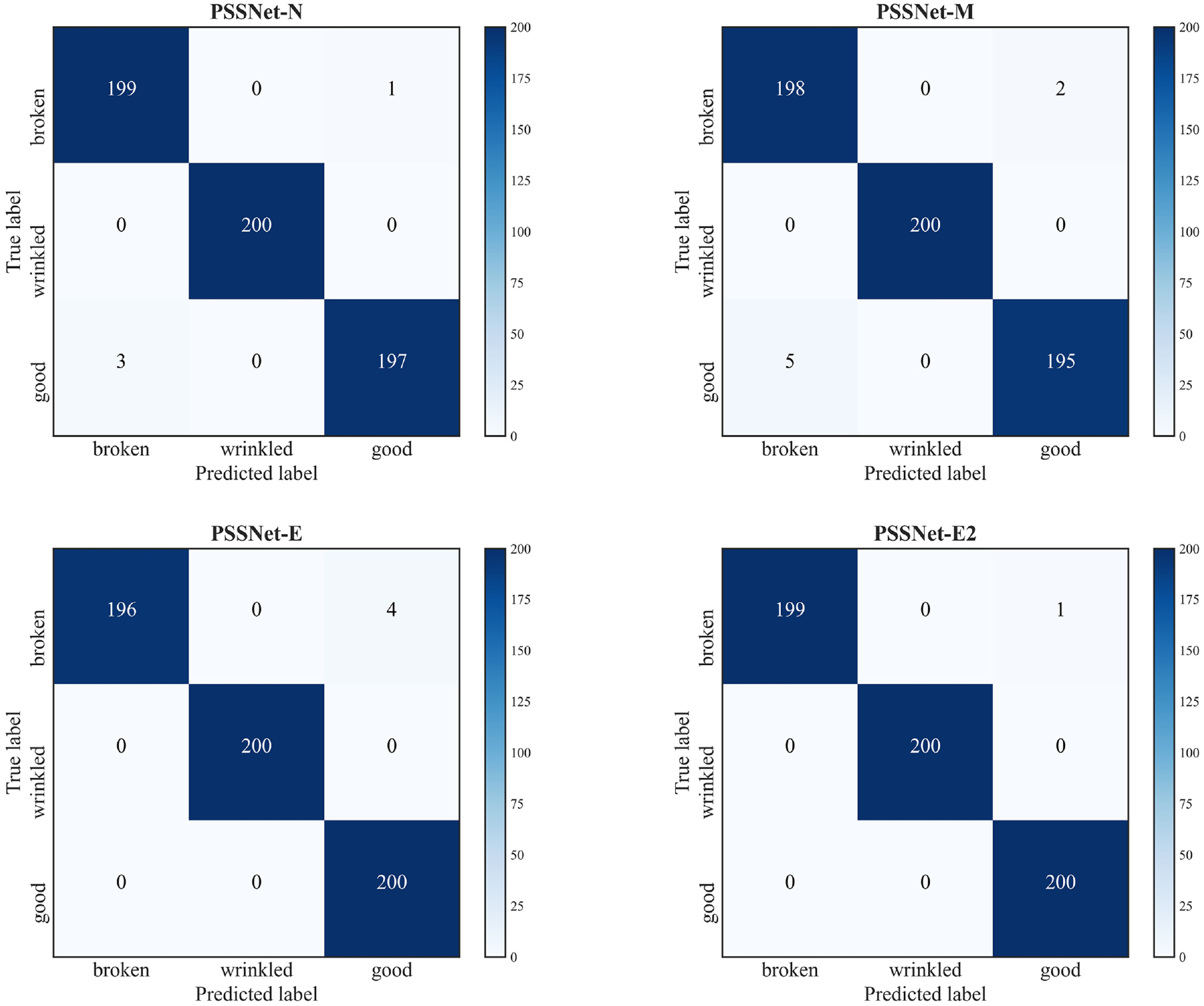
Model confusion matrices.
Comparison before and after model quantization
After validating the accuracy of the model, we further analyzed the impact of model quantization on computation speed.
To further improve the speed of the model and reduce its size, we performed full integer quantization on the four trained models, resulting in four quantized models: PSSNet-Ef, PSSNet-E2f, PSSNet-Mf, and PSSNet-Nf. Since accuracy is only one measure of model evaluation, and peanut seed selection is a multiclassification task with an equal number of samples in each category, the macroaverage index was used for a comprehensive evaluation of the model. Macroaverage indices are shown in equations (10)–(13):
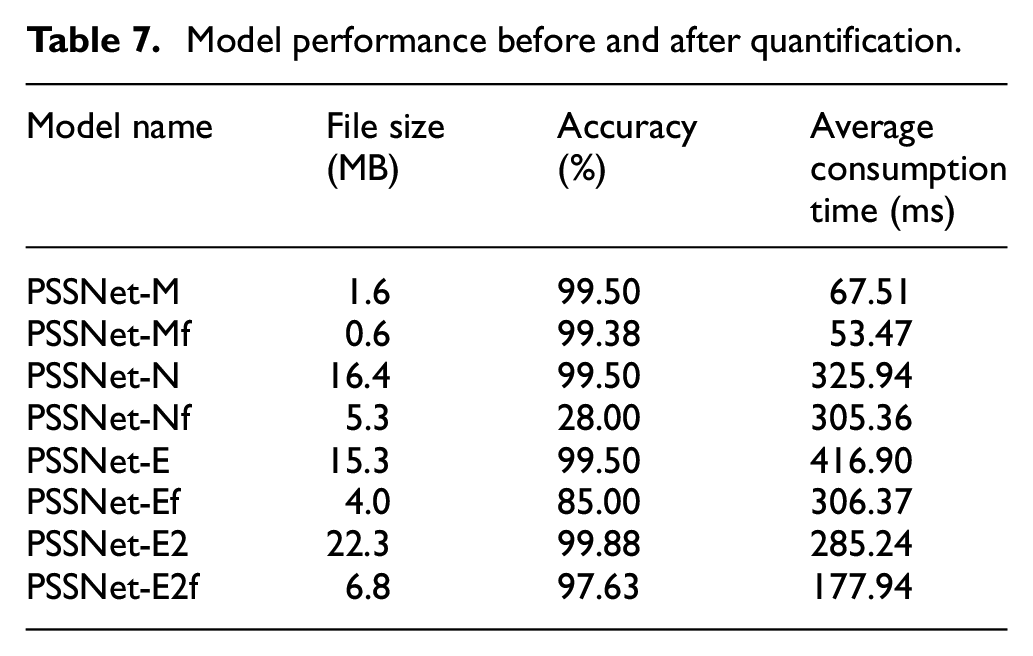
As can be seen from Table 7, full integer quantization significantly reduced model size and increased running speed, with a maximum reduction of two-thirds in size and a maximum increase of 37% in running speed. Among them, the PSSNet-M model exhibited the best performance, with only a 0.12% loss in accuracy after quantization and the shortest time consumption (∼53.47 ms).
Model performance before and after quantification.
The other parameters of the model and its performance on the test set are shown in Figure 9. The macroaverage indicators of the PSSNet-E2 model exceeded 99.8%; however, in terms of the number of model parameters and the volume of the model, the number of parameters of the PSSNet-M model was approximately half that of the PSSNet-E2 model, and its volume was only two-fifths.
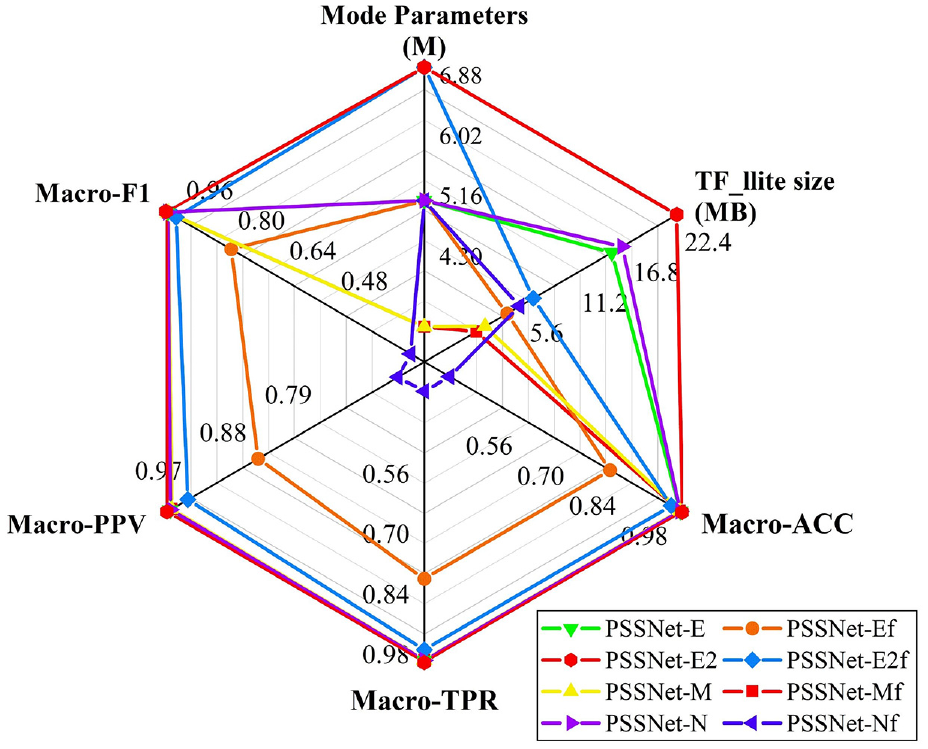
Model performance on the test set.
In summary, the PSSNet-Mf model has high accuracy, small volume, and few parameters. Its overall performance is better, and it is the most suitable model for embedded deployment. Therefore, in this study, PSSNet-Mf was employed as the peanut seed selection model.
Analysis of the generalization ability of PSSNet-Mf
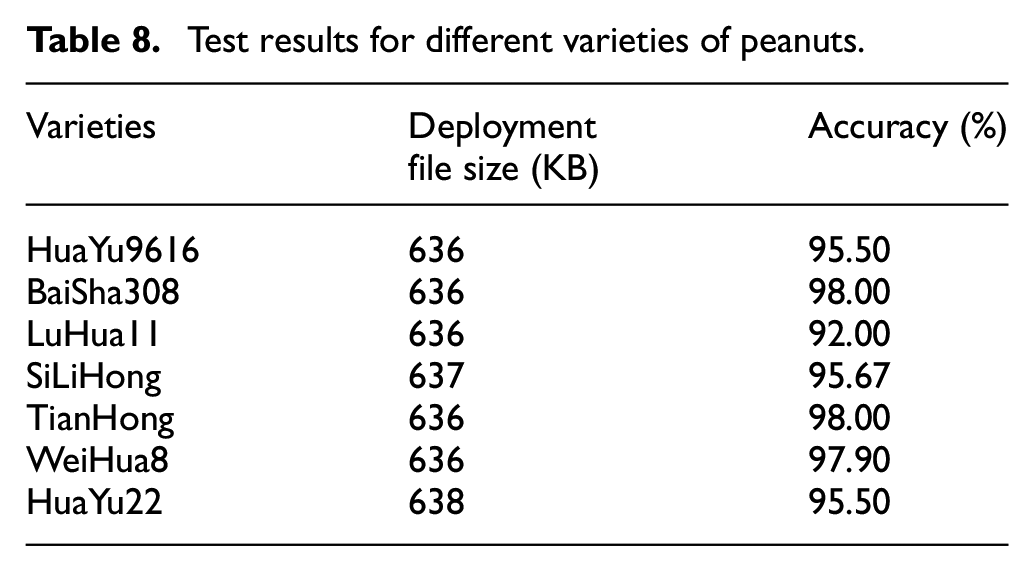
There are many varieties of peanuts. To verify the generalization ability of the algorithm, we tested the developed model on small datasets consisting of seven varieties of peanuts (100 images per category), as shown in Figure 10. The performance of the model on the test set after deployment is shown in Table 8. The model exhibited a good selection effect on different varieties of peanut seeds. The test accuracy of the model on the HuaYu 22 dataset was 95.5%, which is only 3.88% lower than that on the large dataset (2000). Thus, the developed peanut seed selection model is suitable for the selection of different varieties of peanut seeds and performs well on small datasets.

Seven varieties of peanut seeds used in the test.
Test results for different varieties of peanuts.
Equipment test analysis
The peanut seed selection equipment constructed in this study is shown in Figure 11. We deployed the PSSNet-Mf model on the embedded hardware platform for testing. We selected 400 peanut seeds of HuaYu 22 (300 good, 50 broken, and 50 wrinkled) as test samples and performed the selection experiment five times. An average accuracy of 95.3% and the highest selection speed of 14 grains/s were achieved.
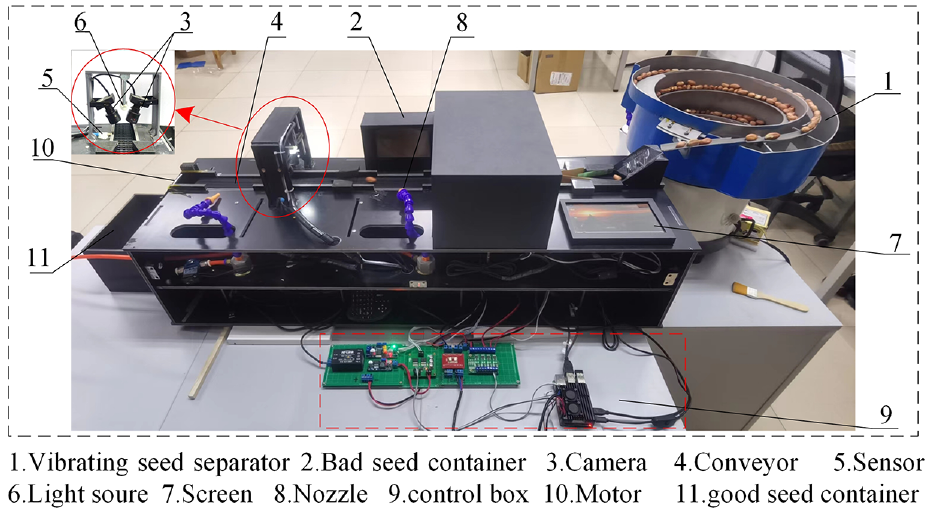
Peanut seed selection equipment.
The training and validation results of the model, as well as the testing results on the actual hardware platform, demonstrate its high accuracy and efficiency in peanut seed selection. In the following section, we will further discuss the significance of these results and how they help address the practical application challenges in peanut seed selection.
Discussion
Comparison with prior works
A wheat grain monitoring network named WGNet based on the improved YOLOv5, was developed to perform wheat grain quality detection. It achieved an average detection accuracy of 97.0%. 29 By studying the soybean seeds, a soybean classification model named SNet was proposed, which yielded a classification accuracy of 96.2% with a model parameter size of 1.29 MB. 30 The improved VGG16 was used to classify twelve types of peanut pods and achieved an average accuracy of 96.7%. 2 These studies contribute valuable insights into the classification and selection of agricultural products, serving as a reference for this study. However, despite their contributions, several research gaps remain unaddressed.
Firstly, these models were primarily tested on PCs, which limits their practicality in on-site agricultural applications. Their lack of portability and high resource requirements make them unsuitable for real-world deployment, where embedded systems are typically required. Secondly, the relatively large size and slower running speeds of these models hinder their effectiveness in environments that demand quick, efficient processing. These limitations highlight the need for more lightweight, efficient models that can be deployed on embedded hardware for practical, real-time applications in agriculture.
In this study, we addressed these gaps by proposing a lightweight peanut seed selection network model named PSSNet. After quantization, the model’s size was reduced to only 0.6 MB, allowing it to be successfully deployed on embedded equipment. The prototype testing results demonstrate that the proposed model is not only feasible but also offers high recognition accuracy, fast processing speed, and strong generalization capabilities. This advancement has significant implications for the application of deep learning in agricultural product sorting, offering a viable solution to the current limitations in the field.
Problems and prospects
This study has some limitations:
As can be seen in Figure 10, the peanut seeds were wrongly identified. Figure 12(a), (b), (d), and (e) were peanut seeds with less broken husks but were misidentified as good seeds, whereas Figure 12(c) was a seed with a larger hilum but was misidentified as a bad seed. The model exhibited a larger recognition error for peanuts with smaller broken areas or larger hilum. The proportion of small-area damage peanut seeds was small, resulting in poor recognition effect of the trained model for small-area damage. In addition, the subjectivity of the dataset selection criteria and the varying proportions of peanut seeds with different levels of damage were key factors. In future research, we will continue to refine the grading standards for peanut seeds, including the seed size, percentage of broken area, and plumpness, to further improve the accuracy and efficiency of peanut seed selection.
The accuracy of the equipment test was slightly lower than that of the model test, mainly due to the misidentification caused by some peanuts facing down during the test. Although two cameras were used at a fixed angle for cross-type image acquisition, the image information of up to three-fourth of the surface area of peanut seeds could be captured at most. Therefore, peanut seeds inevitably faced down on their broken sides, leading to misidentification. In future work, new image acquisition methods will be studied to achieve full-area acquisition of peanut image information. For example, by making the peanut seed fall, the full-area acquisition of peanut seed image information can be achieved using two cameras, as shown in Figure 13.
The single-channel method was adopted in this study, and the efficiency was relatively low. In future research, the multichannel selection method will be used to improve the efficiency of peanut seed selection.

Wrongly identified peanut seeds: (a) Seed with a slightly broken area misidentified as good; (b) Seed with similar breakage misidentified as good; (c) Good seed misidentified as broken; (d) Slightly broken seed misidentified as good; and (e) Broken seed misidentified as good.
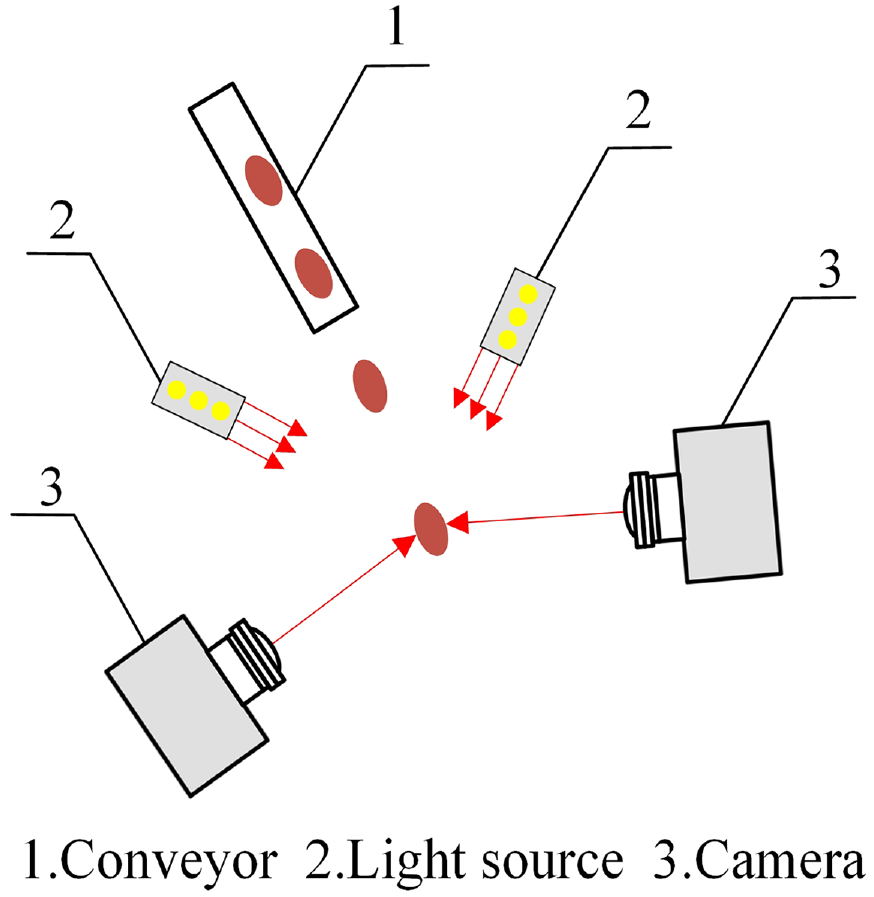
Schematic of the falling image acquisition method.
Based on the above discussion, the conclusions demonstrate the effectiveness of the proposed method in peanut seed selection and highlight potential directions for future research.
Conclusion
A peanut seed selection method based on DL and machine vision was proposed. Using the architecture of the lightweight CNN MobileNetV2, a model was constructed with transfer learning (TL) and model quantization technology. This model was then deployed on an embedded hardware platform, which enabled the development of peanut seed selection equipment. The main conclusions are as follows:
Seed datasets of seven peanut varieties were constructed. Each peanut variety was classified separately into three categories, namely good, broken, and wrinkled peanut seeds, to establish a standard dataset.
A peanut seed selection network model named PSSNet (accuracy: 99.38%) was proposed. It offers the advantages of small size, high accuracy, fast speed, and low deployment cost. It was deployed on an embedded hardware platform, and the development of prototype equipment was accomplished. The average accuracy of the test on the principal prototype was approximately 95.3%, and the speed was 14 grains/s, which meets the requirements of the on-site application.
The proposed peanut seed selection model exhibits a good generalization performance. It is suitable for selecting different varieties of peanut seeds and performs well even with small training datasets. Furthermore, it greatly reduces the training time and cost of the model.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Shandong Provincial Natural Science Foundation (ZR2022MC152), Central government guiding local science and technology development special plan (23-1-3-6-zyyd-nsh), and Shandong Province Key R&D Plan (2023TZXD023).
Data availability statement
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.