
Abstract
Large language models (LLMs) and related generative artificial intelligence (AI) systems are rapidly entering clinical workflows, including in gastroenterology and hepatology, where text-heavy documentation, guideline-driven care, and high-volume patient messaging create a strong demand for decision support and automation. Deployment raises distinctive risks: hallucinations and unsafe recommendations, automation bias, privacy and confidentiality threats, inequitable care, intellectual property and licensing uncertainty, and unclear allocation of responsibility across clinicians, institutions, and vendors. Regulators are increasingly emphasizing a lifecycle approach to trustworthy AI, including validation, risk management, human oversight, cybersecurity, monitoring, and transparency. Frameworks for healthcare protection regulate how health information may be shared with external model providers and how outputs should be logged, audited, and retained. This review synthesizes practical guidance for responsible LLM use, organized around (1) tiered use cases and risk stratification; (2) ethical principles (beneficence, non-maleficence, autonomy, justice, and accountability); (3) core legal and regulatory considerations; and (4) operational governance, evaluation, and monitoring strategies. Actionable checklists to support institutional adoption, use, and transparency are provided. Responsible use requires aligning LLM capabilities with risk, preventing inappropriate data sharing, validating performance in representative populations, ensuring human oversight and clear accountability, mitigating harm, and maintaining an evidence-based, continuously monitored deployment lifecycle.
Plain language summary
Large language models (LLMs) are powerful AI tools that can help clinicians by drafting notes, summarizing information, and assisting with patient messages. They are becoming common in gastroenterology and hepatology as the field relies heavily on written documentation and synthesis of complex clinical data. However, these tools can sometimes produce confident but incorrect information, overlook important details, or reflect biases found in their training data. Owing to these risks, LLMs must always be used with human oversight, not as independent medical decision‑makers. Privacy remains a major concern. When LLMs process patient information, organizations must follow strict rules such as Health Insurance Portability and Accountability Act (HIPAA) and General Data Protection Regulation (GDPR) to protect confidentiality, manage cybersecurity risks, and ensure that data shared with vendors is appropriately controlled. To use LLMs safely, health systems should match the tool to the level of clinical risk, from simple administrative tasks to high‑stakes decision support. They should build in safeguards like human review, high‑quality medical sources, transparency about AI use, and continuous monitoring for errors or drift in performance. LLMs also need to be checked for fairness, since they may unintentionally reproduce biased medical assumptions, which can contribute to inequitable care. Overall, LLMs can reduce burden and support high‑quality care in gastroenterology and hepatology, but only when paired with strong governance, human oversight, privacy protections, and responsible workflows.
Keywords
Introduction
High volumes of unstructured text (clinic notes, procedure and pathology reports, imaging data, discharge summaries) are generated in day-to-day Gastroenterology and Hepatology (GI/Hep) practices that require continual synthesis in the context of evolving evidence, guidelines, and patient-specific factors. These characteristics make the specialty an attractive early adopter for large language model (LLM) assisted documentation, summarization, and decision support.1,2 There are high-stakes decision points (e.g., acute gastrointestinal bleeding, endoscopy triage, decompensated cirrhosis, and hepatocellular carcinoma staging), where hallucinated or biased outputs can lead to harm. The World Health Organization (WHO) has emphasized that generative artificial intelligence (AI) can improve healthcare only if risks are identified and actively governed across the model lifecycle.3,4
GI/Hep share many AI-governance challenges with other specialties (privacy, bias, automation bias, and unclear liability), but several features make GI/Hep a particularly relevant testing case for responsible LLM deployment. Being a procedure-intensive specialty that generates image-rich and narrative reports that must be translated into actionable recommendations (e.g., polyp pathology letters and surveillance intervals).5,6 In addition, guideline-dense longitudinal care (IBD, chronic liver disease), high-volume patient messaging (diet/medication questions, bowel preparation, symptom flares), and high-acuity triage decisions (acute GI bleeding, decompensated cirrhosis, and referral urgency) are highly prevalent. These characteristics make LLMs attractive for summarization and communication, but also amplify the impact of omission, hallucination, and misalignment with patient-specific contraindications or local practice constraints.
This review focuses on considerations for responsible LLM use with these aspects: (i) describe plausible use cases and categorize them by risk; (ii) outline ethical principles and common failure modes; (iii) summarize relevant legal and regulatory obligations; and (iv) propose a practical governance and evaluation framework, including checklists and tables designed for multidisciplinary adoption teams. The manuscript focuses on text-based LLMs because they are the most mature and widely deployed in clinical documentation and communication. The same governance principles may extend to other generative AI (e.g., multimodal models used with endoscopic images or pathology), and additional safeguards may be needed in those situations.
Methods
A targeted review of peer-reviewed literature and policy documents published was performed, prioritizing sources relevant to LLM use, medical ethics, health data privacy, cybersecurity, and regulation. PubMed/MEDLINE was searched for English-language sources published from January 2018 through January 2026 using combinations of terms including: “large language model,” “LLM,” “ChatGPT,” “generative AI,” “foundation model” AND “gastroenterology,” “hepatology,” “endoscopy,” “colonoscopy,” “inflammatory bowel disease,” “cirrhosis,” “hepatocellular carcinoma,” as well as governance terms (“HIPAA,” “GDPR,” “EU AI Act,” “medical device,” “clinical decision support,” “cybersecurity,” “prompt injection”). Reporting guidelines for clinical AI studies (CONSORT-AI, SPIRIT-AI, DECIDE-AI) and publisher/journal policies on AI disclosure were reviewed.7–10 Given rapid policy changes, sources from regulators and standards bodies such as the WHO, National Institute of Standards and Technology (NIST), U.S. Food and Drug Administration (FDA), Office of the National Coordinator for Health Information Technology (ONC), European data protection board (EDPB), and others are included where available. Additional references were identified by citation chaining. Given the heterogeneity of study designs and rapidly evolving policy, a formal systematic review or meta-analysis was not performed. Instead, evidence was synthesized into a practical risk-tier taxonomy and matched safeguards and evaluation expectations to intended use.
LLM-enabled workflows: A risk-tier taxonomy proposal
A practical starting point is to match the intended use, balancing benefits and harm. Deployment of LLMs can be for activities ranging from low-risk administrative tasks to high-risk decision support. Table 1 proposes a taxonomy and corresponding safeguards.2,11,12
Representative LLM use cases and recommended safeguards.

Risk tiers are illustrative: Tier 0 (no clinical data), Tier 1 (limited PHI/administrative), Tier 2 (documentation/communication), Tier 3 (clinical support), Tier 4 (autonomous clinical action).
AI, artificial intelligence; EHR, electronic health record; GI, gastroenterology; HCC, hepatocellular carcinoma; LLM, large language models; PHI, protected health information; RAG, retrieval-augmented generation.
To operationalize “responsible use” into implementable safeguards, a pragmatic risk-tiering approach based on the principle that LLM-related risk increases as outputs move closer to patient care and clinical action is proposed in this manuscript. Tier assignment is driven by four primary dimensions: (1) clinical proximity and actionability (administrative support vs decision support vs autonomous actions), (2) severity and reversibility of potential harm (documentation errors vs unsafe treatment recommendations), (3) degree of autonomy and opportunity for human oversight (draft-only with mandatory review vs direct-to-patient vs automated execution), and (4) data sensitivity (no patient data vs limited PHI vs full electronic health record (EHR) context). This framework emphasizes workflow realities where time-sensitive decisions and guideline-intensive care make the consequences of confident but incorrect outputs particularly salient. When a tool spans multiple functions, it is suggested that the tier be assigned according to the highest-risk function or the function with the most direct impact on patient care.
Tier 0: No clinical data, non-clinical support
Tier 0 includes use cases that do not involve patient information or clinical decision-making (e.g., general writing assistance, generic education materials, and workflow brainstorming). The primary risks are misinformation, reputational harm, or inappropriate reliance rather than direct patient harm. Safeguards emphasize basic information governance (approved tools, acceptable-use policy) and avoidance of unintended expansion beyond the intended use, user, or context into clinical recommendations.
Tier 1: Limited PHI and operational/administrative tasks
Tier 1 covers tasks where limited identifiers or operational context may be used (e.g., drafting prior authorization narratives, referral letters, scheduling support), but the output is not intended to guide clinical care directly. Risks include confidentiality breaches, administrative errors, and propagation of inaccuracies into downstream processes. Safeguards typically center on privacy compliance (minimum necessary data, approved platforms), access controls, auditing, and human verification before external submission. For purely internal Tier 1 administrative tasks (e.g., internal routing and scheduling optimization), disclosure to patients may not be practical or meaningful, but organizational transparency and documentation are still required.
Tier 2: Clinical documentation and communication with human-in-the-loop oversight
Tier 2 includes LLM use for drafting clinical notes, procedure reports, discharge instructions, and patient portal messages, where a clinician (or trained staff under protocol) reviews and approves content prior to filing or sending. Harm can arise through incorrect documentation, omission of red flags, hallucinations, misleading instructions, or unequal communication quality across patient groups (e.g., language or literacy barriers). Tier 2 safeguards emphasize mandatory human review, source-of-truth verification against the chart, standardized templates, escalation triggers, and transparency/labeling policies for patient-facing content.
Tier 3: Clinical decision support
Tier 3 encompasses tools that synthesize patient-specific data to propose diagnoses, triage, risk stratification, management steps, or guideline application. These outputs can materially influence care decisions even when the clinician remains the final decision-maker. Potential harm is higher because errors may be clinically plausible, time-sensitive, and difficult to detect. This tier therefore requires stronger controls: clear intended-use statements and limitations, rigorous validation in representative populations and settings, structured output constraints (e.g., retrieval from vetted sources), monitoring for drift and safety signals, and defined accountability and incident response pathways.
Tier 4: Autonomous clinical action
Tier 4 includes agentic or automated execution (e.g., placing orders, changing medications, scheduling urgent procedures without clinician sign-off, or sending definitive patient instructions autonomously). This tier carries the highest risk because the opportunity for human interception is minimized, and failures may directly cause harm. Tier 4 autonomy should be avoided or tightly constrained; if contemplated, it requires the most stringent governance: least-privilege permissions, dual authorization, formal safety case documentation, continuous monitoring, robust cybersecurity controls, and, where applicable, alignment with regulatory expectations for high-risk clinical AI.
Evidence base for LLM applications in GI/Hep by risk tier
Although LLM adoption is accelerating, the published GI/Hep evidence base remains heterogeneous, ranging from controlled question-set evaluations to retrospective analyses using de-identified clinical data and early workflow studies. This variability makes a risk-tier lens useful: it aligns evaluation intensity with potential patient impact and highlights where evidence is strongest today. A few examples for Tier 0–3 relevant to GI/Hep are outlined below. Table 2 outlines representative GI/Hep studies evaluating LLM applications by risk tier.
Representative GI/Hep studies evaluating LLM applications by tier.

GI, gastroenterology; HCC, hepatocellular carcinoma; Hep, hepatology; LLM, large language models.
Tier 0 in GI/Hep: No clinical data, non-clinical support
GI/Hep evidence is poised to use LLMs for patient-facing education/counseling and clinician education. In cirrhosis and hepatocellular carcinoma (HCC), ChatGPT responses to 164 curated questions were graded by transplant hepatologists and were frequently “correct” but often not “comprehensive,” with gaps in decision thresholds and regional guideline variation. 13 Similar evaluations in IBD demonstrate that LLMs can generate plausible answers to common patient questions, but may provide incomplete, outdated, or occasionally inaccurate recommendations, supporting their role as adjuncts for education rather than stand-alone advice.21–23 In medical education, GI/Hep studies show variable performance on exam-style questions (e.g., gastroenterology self-assessment tests and residency exam items), underscoring the need to treat LLMs as supplementary study tools and to teach verification habits.15–17
Tier 1 in GI/Hep: Limited PHI and operational/administrative tasks
Peer-reviewed GI/Hep-specific studies of LLMs for operational tasks (e.g., prior authorization letters, appointment scheduling, triage) are limited. Nevertheless, the same evaluation endpoints used in other fields are applicable: time saved, rate of factual errors, readability, and downstream operational outcomes (e.g., reduced cycle time for authorizations) while ensuring that protected data are handled under appropriate agreements and security controls.
Tier 2 in GI/Hep: Clinical documentation and communication with human-in-the-loop oversight
Emerging GI/Hep evidence supports LLM-assisted summarization and document triage when outputs are reviewed by clinicians. A 2026 study developed an LLM assistant to summarize hepatology referral documents using predefined data elements and tested it on 50 patient records; the AI summaries were substantially shorter, had high accuracy with a low hallucination rate, and reduced triage time by ~60% compared with reviewing original referral packets. 18 This illustrates a high-value, lower-risk pathway for LLM use that still requires careful validation for omissions, bias, and drift. Related work outside GI/Hep, such as LLM-generated discharge summaries and patient-friendly note transformations, highlights recurring safety concerns from omissions and inaccuracies, reinforcing the need for structured evaluation and human oversight before scaling patient-facing communication.
Tier 3 in GI/Hep: Clinical decision support
The highest-stakes GI/Hep evidence base is still early, but several studies show both promise and risk. For example, a real-world retrospective analysis entered de-identified colonoscopy and pathology data into ChatGPT-4 to generate rescreening/surveillance intervals and compared outputs with expert-panel guideline recommendations and routine endoscopist practice; ChatGPT-4 had higher concordance with guideline-based recommendations than routine practice in that study, but still produced discordant recommendations in a subset of cases (both earlier and later follow-up). 19 Separate comparisons across LLMs (e.g., ChatGPT vs Bard) also demonstrate variability in guideline adherence.20,24 Taken together, these data support Tier 3 tools only when they are tightly scoped, validated against contemporary guideline logic, instrumented to surface supporting evidence (e.g., citations/decision pathways), and deployed with explicit clinician accountability.
Multimodal and next-generation models
Finally, emerging multimodal LLM applications in endoscopy and liver pathology highlight that “generative AI” is expanding beyond text. Early studies exploring vision-enabled models for bowel preparation scoring and liver fibrosis staging suggest potential but also important performance gaps, underscoring that multimodal outputs require the same (or higher) validation thresholds as tier 2–3 text applications before clinical use.
Ethical considerations
Ethical analysis can be anchored in beneficence, non-maleficence, autonomy, justice, and accountability. LLMs create distinctive tensions because outputs are probabilistic and may be fluent yet incorrect, because training data may encode historical biases, and because interfaces can encourage overreliance.25–27
Beneficence and non-maleficence: Patient safety and error modes
A central risk is clinically plausible but incorrect output (“hallucination”) or omission of key contraindications. Another is automation bias: clinicians and patients may accept confident answers without sufficient verification, especially under time pressure.25,28 Mitigation requires explicit human oversight, verification workflows, and evaluation under realistic conditions, including adversarial testing (“red teaming”) and monitoring for performance drift.29,30
LLM safety risks extend beyond hallucination (fabrication). Three distinct error classes are important in clinical GI/Hep: (1) hallucination: confidently stated but unsupported facts; (2) omission: failure to surface key contraindications, red flags, or next steps (e.g., anticoagulation reversal considerations in GI bleeding; sedation risks in advanced cirrhosis); and (3) contextual misalignment: outputs that may be “generally correct” but are not the best recommendation for an individual patient because they fail to incorporate comorbidities, drug interactions, local resource constraints, or patient preferences (Table 3). Mitigations should be matched to each error mode (retrieval/citations for hallucination; structured contraindication/red-flag checklists for omission; scenario-based validation and required human rationale for contextual misalignment).
Common LLM failure modes and mitigation strategies.

GI, gastroenterology; LLM, large language models; OWASP, Open Worldwide Application Security Project; PHI, protected health information; RAG, retrieval-augmented generation.
Justice: Bias, inequity, and representativeness
Bias can arise from unequal representation in training data, biased documentation, or legacy clinical “dogmas” or “truths” that embed misconceptions. A study of commercial LLMs found that all produced some race-based medical misconceptions and were inconsistent across repeated runs, underscoring the need for equity-focused evaluation and governance. 3 Tools should be tested in the populations they will serve, with disaggregated performance reporting and bias mitigation plans.25,26
Autonomy and transparency: Informed use and appropriate reliance
Patients should not be unknowingly triaged or counseled by systems in ways that meaningfully affect care. Organizations should disclose when LLMs are used in patient-facing interactions or in clinician workflows that materially influence recommendations. Transparency also supports clinician autonomy, providing users with clear indications of tool purpose, limits, and contexts in which outputs become unreliable.25,31
Respect for autonomy supports transparency about when LLMs contribute to patient-facing communication or clinical recommendations, and where feasible, an ability for patients to request a human-only alternative. Practical opt-out pathways are most applicable for Tier 2 patient messaging/letters and selected Tier 3 decision-support tools (e.g., AI-assisted triage or interval recommendations). For backend Tier 1 uses, opt-out may be impractical, but institutions should still ensure that LLM use does not materially change clinical decisions without clinician review, and should provide clear channels for patients to ask questions, request clarification, or escalate concerns.
Accountability and professional integrity
LLMs cannot assume professional responsibility, and accountability ultimately rests with clinicians and organizations. Liability standards are continuing to evolve as AI becomes more integrated into clinical practice, reinforcing the need for clear governance, documentation, and clinician training. 4
Legal and regulatory considerations
Legal obligations differ across jurisdictions and settings, but several themes recur: confidentiality and data protection; cybersecurity and safety; documentation, traceability, and transparency; medical device and health information technology (IT) regulation when LLMs function as clinical decision support; and allocation of responsibility across clinicians, institutions, and vendors (Table 4).31–34
Selected legal and regulatory touchpoints relevant to LLM use.
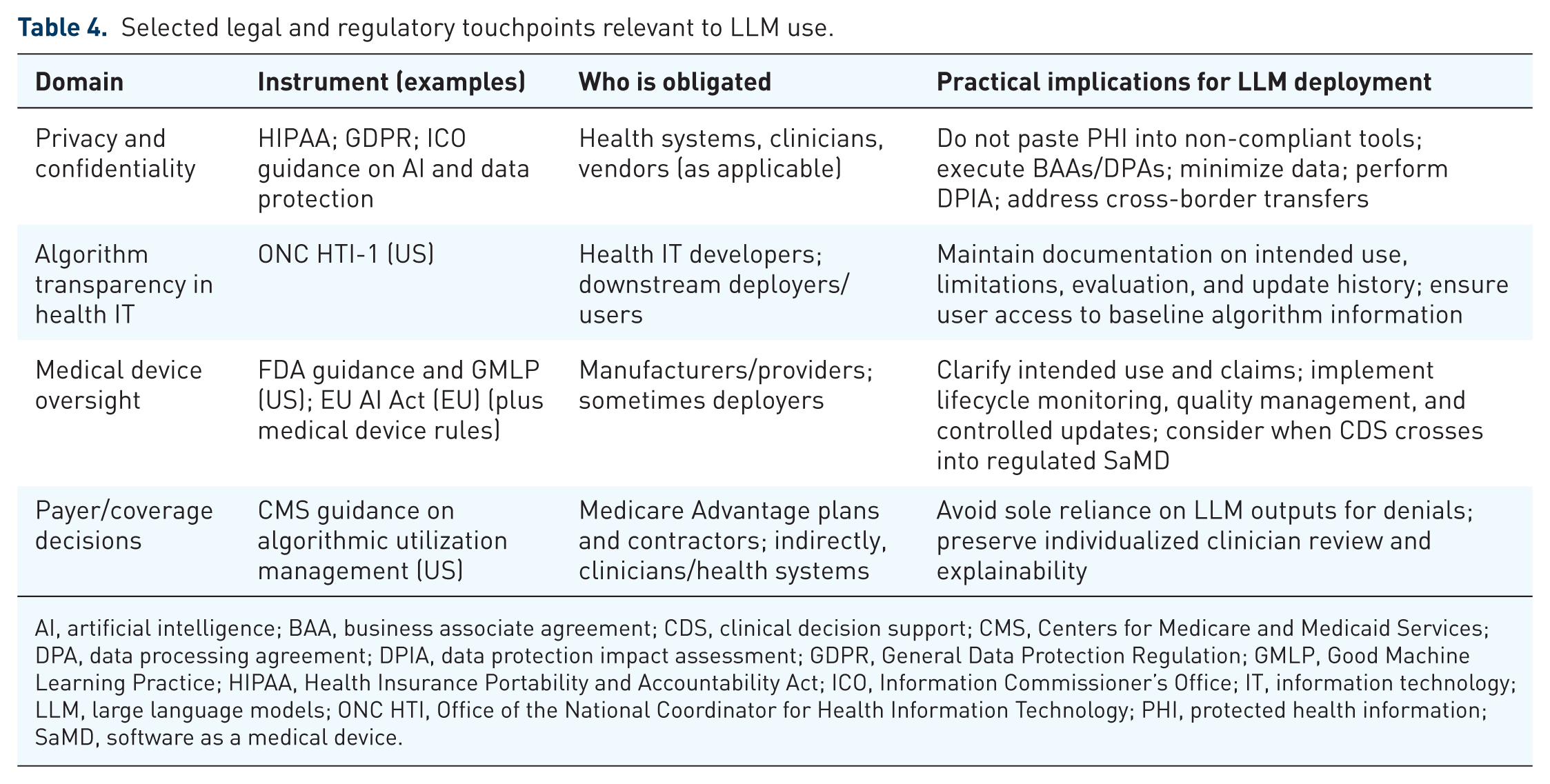
AI, artificial intelligence; BAA, business associate agreement; CDS, clinical decision support; CMS, Centers for Medicare and Medicaid Services; DPA, data processing agreement; DPIA, data protection impact assessment; GDPR, General Data Protection Regulation; GMLP, Good Machine Learning Practice; HIPAA, Health Insurance Portability and Accountability Act; ICO, Information Commissioner’s Office; IT, information technology; LLM, large language models; ONC HTI, Office of the National Coordinator for Health Information Technology; PHI, protected health information; SaMD, software as a medical device.
Data protection and confidentiality
When LLMs process protected health information (PHI), organizations must ensure that disclosures are available and provided, minimum necessary standards are applied, and vendor relationships are governed by appropriate agreements. Under the Health Insurance Portability and Accountability Act (HIPAA), service providers that create, receive, maintain, or transmit electronic PHI on behalf of covered entities or business associates generally function as business associates and require a business associate agreement, even in “no-view” encrypted scenarios. 32
De-identification can enable broader use, but both Safe Harbor and Expert Determination approaches retain residual re-identification risk, particularly for free-text data. 35 In the European Union (EU), the General Data Protection Regulation (GDPR) imposes obligations around lawful basis for processing, purpose limitation, data minimization, and cross-border transfers, all of which may affect cloud-hosted LLMs and fine-tuning workflows. 31 Guidance from the United Kingdom on AI and data protection emphasizes accountability and governance and notes ongoing updates as legislation changes. 36
Medical device and healthcare IT oversight
Whether an LLM-enabled tool is regulated as a medical device depends on intended use, claims, and functional role in clinical decision-making. In the US, FDA guidance and the international “Good Machine Learning Practice” principles stress rigorous lifecycle controls, including data management, transparency, performance evaluation, and post-deployment monitoring.37,38 The ONC HTI-1 Final Rule established algorithm transparency requirements for certain predictive decision support interventions in certified health IT. 34 In the EU, the AI Act introduces obligations for high-risk AI and additional transparency requirements, with staged applicability dates.35,39
Professional liability and standard of care
Clinicians remain responsible for the care delivered, even when decision support tools are used. Liability analyses emphasize that clinicians may face risk both when they rely on faulty AI recommendations and when they unreasonably ignore reliable AI warnings, depending on the evolving standard of care. 4 Regulatory guidance cautions against using algorithms as the sole basis for coverage decisions and emphasizes that medical necessity determinations require individualized, grounded review. 40
Operational governance for responsible LLM use
Responsible deployment requires operational controls that convert principles into practice. The NIST Artificial Intelligence Risk Management Framework and its generative AI profile provide a useful structure: govern, map, measure, and manage risks across the lifecycle, with explicit accountability and continuous monitoring.26,30 Reporting guidelines for clinical AI studies reinforce the need to specify intended use, human–AI interaction, error analysis, and system versioning.7–9
Governance: Roles, policies, and acceptable use
Health systems should establish a multidisciplinary governance structure that includes clinicians, nursing, informatics, legal/compliance, privacy, cybersecurity, and patient representatives. Key outputs include an acceptable-use policy, a risk-tier framework (Table 1), vendor due diligence standards, and a process for incident reporting and corrective action.26,27,30
Technical safeguards: Architecture, security, and data controls
Common controls include retrieval-augmented generation (RAG) with curated local knowledge bases; role-based access; input/output filtering; prevention of sensitive information disclosure; and limiting agentic capabilities to least privilege. The Open Worldwide Application Security Project (OWASP) highlights prompt injection, sensitive information disclosure, excessive agency, and overreliance as recurring failure modes that should be explicitly addressed in design and testing. 27
Privacy and leakage risk: Why “don’t upload PHI” is not enough
Privacy risk can arise through memorization, training data extraction, especially for large models trained on sensitive data. 41 In addition, targeted misinformation and model-manipulation attacks can deliberately inject incorrect biomedical facts into model behavior, reinforcing the need for robust access control and monitoring.42–44
GDPR and international data protection
GDPR considerations for LLM deployment extend beyond “do not upload identifiable data.” Health data are “special-category” personal data, requiring both a lawful basis and a separate condition for processing special-category data, as well as transparency about purposes, recipients, and retention. LLM workflows can stress core GDPR principles: purpose limitation and data minimization (e.g., broad reuse of clinical notes for fine-tuning); accuracy (model outputs may be incorrect about individuals); and data subject rights (access, rectification, restriction, objection, and erasure). In practice, controller/processor roles must be explicit (including for cloud LLM vendors), with appropriate contractual safeguards, audit rights, and limits on downstream model training. Many clinical deployments will trigger a Data Protection Impact Assessment, particularly when using novel technology at scale on sensitive health data. Cross-border transfers and sub-processor chains must be mapped and controlled. Recent European work, including the EDPB ChatGPT Taskforce report and EDPS guidance on generative AI, emphasizes risk-based governance, clear role allocation, and practical mechanisms to uphold data subject rights. For GI/Hep implementations, a conservative approach is to prefer enterprise-grade deployments where PHI/personal data are not used for model training, to log prompts/outputs securely for quality oversight, and to validate that generated summaries or recommendations do not introduce inaccurate personal data into the record.
Evaluation and monitoring
Evaluation should be proportional to risk and should reflect real-world workflow. For Tier 1–2 applications, this includes documentation accuracy audits, clinician satisfaction, and time saved. For Tier 3–4 applications, prospective evaluation and safety monitoring are needed, ideally aligned with DECIDE-AI/CONSORT-AI guidance.8,9,29
Responsible scholarly use: Authorship, disclosure, and publication ethics
Medical journals and publishers increasingly require transparency about generative AI use in manuscript preparation. Some journals distinguish assistive uses (e.g., grammar) from generative uses that produce substantive text, images, or references; the latter typically requires disclosure, and authors retain responsibility for accuracy and originality. ICMJE similarly emphasizes disclosure of AI-assisted technologies and reiterates that chatbots cannot be listed as authors because they cannot take responsibility for integrity and accuracy. 10 Authors should also recognize intellectual property constraints: U.S. copyright guidance emphasizes human authorship requirements for copyright protection of AI-generated material.45,46
Education
Education is an early and common entry point for LLM use by trainees in GI/Hep. Programs should teach trainees to treat LLM outputs as unverified drafts, to cross-check against primary sources and local guidelines, and to avoid entering any identifiable patient information into non-approved tools. 47 Training curricula can incorporate “AI literacy” (prompting, citation/verification habits, bias awareness, and recognizing automation bias) and can use local, institutionally governed models for low-risk educational tasks. 47 Studies in GI/Hep show that LLM performance on exam-style questions is variable, supporting use as a supplementary learning tool rather than a replacement for standard educational resources.15–17
Preventing harm: Practical safeguards for LLM use
Preventing harm from LLMs requires a safety-by-design approach that matches safeguards to risk, recognizes that LLM outputs can be fluent yet wrong, and anticipates both clinical and cybersecurity failure modes. Guidance emphasizes human oversight, transparency, equity, and lifecycle governance, including post-release auditing and monitoring where LLMs are deployed at scale.25,26,30,48
Start with intended use and risk tier
Harm prevention begins by defining the intended use, the user (clinician vs patient facing), the setting (inpatient vs outpatient), and the level of autonomy. Tier 1–2 applications (documentation assistance, controlled messaging) generally allow stronger human review than Tier 3 applications (clinical decision support) and should be prioritized for early adoption. Risk tiering should explicitly identify prohibited uses (e.g., autonomous ordering, medication changes, or triage decisions without clinician sign-off) and have inbuilt escalation triggers.25,26 Table 5 outlines a tier-by-tier ethical crosswalk with the risk-tiered approach.
Tier-by-tier ethical crosswalk (benefits, risks, safeguards).

CDS, clinical decision support; PHI, protected health information.
Safety guardrails to reduce hallucinations and unsafe recommendations
For clinical tasks, guardrails should reduce the probability that an LLM generates unsupported facts, misapplies guidelines, or omits contraindications. Practical strategies include: RAG from curated, date-stamped guideline repositories; requiring the model to quote or cite only from retrieved sources; structuring prompts to force uncertainty and differential diagnoses; and limiting output scope (e.g., “draft a note” vs “recommend therapy”). Because outputs vary stochastically, safeguards should be tested across repeated runs and across realistic prompt formats (short questions, copied notes, portal messages).25,26,29
Human oversight and human factors: Design the human–AI team
Human oversight must be operationalized, not assumed. Interfaces should make review easy (source links, highlighted uncertainties, and structured contraindication checks) and should avoid creating false confidence. Human factors/usability engineering is widely used in medical device development to minimize use-related hazards; similar principles apply when LLM tools are embedded in EHR workflows or patient messaging systems.48,49
Equity and bias: Test for subgroup harms and avoid race-based medicine
Explicit testing for bias and inequitable recommendations must be carried out. LLMs have been shown to reproduce race-based medical misconceptions and may yield inconsistent outputs across repeated runs, increasing the risk of differential harm. 3 Implementations should include language-access evaluation (reading level and translation quality), subgroup performance reporting, and guardrails to prevent race-based heuristics unless explicitly evidence-based and current.25,26,50
Privacy and cybersecurity: Treat LLMs as a new attack surface
LLM-enabled systems introduce cybersecurity risks that can translate into patient harm: prompt injection, sensitive data disclosure, excessive “agency” via tools/plugins, and overreliance are highlighted in the OWASP Top 10 for LLM applications. 27 Threat modeling should incorporate adversarial AI tactics and techniques, drawing on resources such as MITRE ATLAS (MITRE Adversarial Threat Landscape for Artificial-Intelligence Systems).43,44 Privacy threats also include potential memorization and extraction of training data and membership inference in some settings, reinforcing the need for strict data minimization, contractual controls, and secure logging. 41 Healthcare-specific risks include targeted manipulation of medical LLMs (e.g., injecting incorrect biomedical facts while preserving apparent performance), which underscores the need to control model access, monitor updates, and validate knowledge integrity after any change. 42
Future directions
Near-term value is likely greatest in Tier 1–2 applications (documentation, summarization, controlled patient messaging) with strong human oversight, while Tier 3–4 applications should proceed only with rigorous validation, monitoring, and clear accountability.2,26 Policy landscapes are also evolving, reinforcing the need for ongoing compliance monitoring.36,39
Conclusion
LLMs can help teams manage information overload and reduce clerical burden, but safe use depends on aligning capabilities with clinical risk, protecting patient data, validating performance across diverse populations, and sustaining governance throughout the deployment lifecycle. A risk-tier taxonomy, NIST-aligned governance, OWASP-informed security testing, and transparent disclosure practices provide a practical path toward responsible adoption (Boxes 1–4).
Point-of-care checklist for clinicians using LLM output (Tier 2–4 use cases).

AI, artificial intelligence; LLM, large language models.
Institutional pre-deployment checklist.

AI, artificial intelligence; BAA, Business Associate Agreement; DPA, Data Processing Agreement; GDPR, General Data Protection Regulation; HIPAA, Health Insurance Portability and Accountability Act; LLM, large language models.
Manuscript AI-disclosure checklist.

AI, artificial intelligence.
Preventing harm in LLM workflows.

GI, gastroenterology; LLM, large language models; PHI, protected health information; RAG, retrieval-augmented generation.