
Abstract
The question of why music evolved has been contemplated and debated for centuries across multiple disciplines. While many theories have been posited, they still do not fully answer the question of why humans began making music. Adding to the effort to solve this mystery, we propose the socio-affective fiction (SAF) hypothesis. Humans have a unique biological need for emotion regulation strengthening. Simulated emotional situations, like dreams, can help address that need. Immersion is key for such simulations to successfully exercise people's emotions. Therefore, we propose that music evolved as a signal for SAF to increase the immersive potential of storytelling and thereby better exercise people's emotions. In this review, we outline the SAF hypothesis and present cross-disciplinary evidence.
Introduction
The question of why and how music evolved is a popular and hotly debated topic in music research today (e.g., Mehr et al., 2020; Savage et al., 2020). Music has been universally present and popular across most of human history (Mehr et al., 2019; Savage et al., 2015). Bird bone flutes found in France date back to 35,000–20,000 years ago (Banning, 2020; Benito et al., 2016). Several bone flutes date back even further, such as the 60,000-year-old flute from Divje Babe Cave in Slovenia, although there is some speculation that the holes in these older flutes are from gnawing carnivores rather than human craft (Banning, 2020; d’Errico et al., 1998; Diedrich, 2015). The French bird bone flutes, however, have features more consistent with purposeful human engineering (Banning, 2020; Benito et al., 2016). The emergence of musical instruments coincides with what is referred to in evolutionary theory as “The Great Leap Forward” around 50,000–35,000 years ago: When the human skeleton more or less stabilized, human behavior suddenly began to advance rapidly, and elements of culture began to emerge, including cave paintings, necklaces, and sculptures (Diamond, 1989; Klein, 2002).
The big question of why music evolved hinges on the fact that despite its persistence and popularity in human culture, it puzzlingly lacks an obvious evolutionary function. For instance, human's evolved ability to make tools, like hunting weapons, has the clear evolutionary benefit of making it easier to successfully hunt for food and therefore easier to survive. The case for music, however, is much less clear. This perplexing dichotomy has provoked many theories and debates on why and how music evolved (e.g., Honing, 2018; Wallin et al., 2001). We here present a brief overview of several of these theories.
Survey of the Literature
Music Serves No Adaptive Function
The null hypothesis in the debate is the non-adaptationist view, that music is an invention or technology born out of previously evolved faculties that serve no adaptive function. Steven Pinker spearheaded this point of view writing that “as far as biological cause and effect are concerned, music is useless,” and that “music appears to be a pure pleasure technology, a cocktail of recreational drugs that we ingest through the ear to stimulate a mass of pleasure circuits at once” (1998, p. 528). Patel (2010) also describes music as a technology reliant on previously developed brain functions, such as those for language, but also points out its transformative capabilities on the human brain and in culture. Panksepp (2009) proposes that music was born as a by-product from other adaptations, such as rhythmic motion from basic movements and from affective vocal sounds. Trainor (2015) theorizes that music is a cultural creation, similar to the idea that it is a technology or invention, that relied on previously developed auditory processing abilities that evolved to perform auditory scene analysis (ASA). ASA includes perceiving the source and location of sounds, crucial for survival (Trainor, 2015).
All these non-adaptationist views share the common opinion that music and music-making abilities were not primary targets for evolutionary processes but were either spandrel to primary traits selected by evolution or evolved as exaptations from primary traits. The concept of exaptation (Gould, 2002; Gould & Vrba, 1982; Huron, 2006) would indicate that traits that were necessary pre-conditions to music evolved first due to selection pressures, and then happily enabled the evolution of music (without selection pressures). However, the universal pervasiveness of music across human history strongly suggests that music had an adaptationist function. If it did not have an evolutionarily beneficial function, it is likely music would have ceased to exist long ago in the course of human history. Therefore, these non-adaptationist views potentially fail to provide a satisfactory explanation for the continued existence of music.
Sexual Selection Hypothesis
More recent arguments have been trending toward the adaptationist view. One adaptationist theory is that music evolved due to sexual selection. This theory was first proposed by Charles Darwin (1871) who noted that early humans, or pre-humans, probably made musical sounds to attract the opposite sex, and that these early musical cries may have led to the evolution of language. Darwin's theory has resurfaced in more recent discourse on the evolution of music. For example, Miller (2000) argues that musical activities could have evolved to indicate the physical fitness of the music maker while also being aesthetically pleasing, both important traits for sexual selection. Some researchers have recently attempted to empirically investigate the sexual selection hypothesis. Mosing et al. (2015) investigated the hypothesis in a modern sample of people, specifically in 10,975 Swedish twins. After measuring musical aptitude and mating success, they found little evidence supporting the theory that music may have evolved for mate attraction purposes (Mosing et al., 2015). Madison et al. (2018) examined whether music might signal physical fitness and therefore be an effective signal for sexual selection by studying how the perceived musical performance quality of improvised performances correlated with ratings of mate preferences and values. With 27 male and 17 female Swedish students participating, they found that ratings of mate values (health, intelligence, social status, and parenting skill) were positively correlated with music performance quality consistent with the sexual selection hypothesis (Madison et al., 2018). Marin et al. (2017) studied how musical priming might influence ratings of attractiveness and dating desirability for neutral faces with 64 female and 32 male participants. They found that music significantly influenced women's ratings of both attractiveness and dating desirability, but not men's, and that highly arousing and complicated music had the strongest effect (Marin et al., 2017). These results suggest that music might increase arousal and thereby indirectly impact human courtship behavior (Marin et al., 2017). However, in a recent review of investigations of the sexual selection hypothesis, Ravignani (2018) concluded that while research is moving in an encouraging direction in the field by implementing testable hypotheses, the current evidence is yet inconclusive.
Parent–Infant Bonding Hypothesis
Another adaptationist theory is that music evolved for parental care purposes; it helped parents communicate to and bond with their children. Infant-directed singing has existed for millennia across the world and is still prevalent today (Trehub and Russo, 2020). Theories regarding the evolution of infant-directed singing rest on the comparison of singing to “motherese”—the universal way in which mothers address their infants differently from other adults (Dissanayake, 2008). Compared with normal speech, motherese is higher in pitch and has more enhanced features, such as exaggerated tonal information in Cantonese speakers (Wang et al., 2018). Dissanayake (2008) claims that motherese is a proto-musical behavior that evolved for the purpose of increasing mother–infant bonding and was eventually culturally and socially developed into more complex musical behaviors. Some studies have empirically investigated the value of singing in mother–infant bonding today. Fancourt and Perkins (2018) recruited 43 mother–infant pairs in the Greater London area to participate in two consecutive workshops in small groups, one involving singing-centered social activities and the other involving non-musical social activities. They found that singing led to higher levels of perceived mother–infant closeness, a more positive emotional state, lower feelings of anxiety, and lower levels of hormones associated with emotional stress (Fancourt & Perkins, 2018). Kostilainen et al. (2021) studied the impact of singing on mother–infant bonding during kangaroo care with pre-term infants. Kangaroo care consists of initiating skin-to-skin contact between a parent and their baby by dressing the baby in only a nappy (and possibly a hat and socks to keep warm) and then placing them on their parent's chest (Cunningham et al., 2022). The practice has been found to have many benefits for premature babies, such as providing pain relief, reducing their risk of infection, and promoting regular breathing, faster weight gain, improved sleep cycles, and more (Cunningham et al., 2022; Parvin et al., 2019; Wang et al., 2022). With instruction from a music therapist, Kostilainen et al. (2021) had 24 mothers sing or hum to their babies during kangaroo care and found that singing significantly decreased their reported anxiety levels by promoting perceived closeness and leading to early interactions. Steinberg et al. (2021) investigated how musical engagement impacted parent–child relations during the COVID-19 pandemic by surveying 177 caregivers online. They found that parent–child attachment was significantly predicted by the amount of parent–child music engagement and that parents used music engagement with their children for both emotion regulation and social engagement (Steinberg et al., 2021).
Social Bonding Hypothesis
Mother–infant bonding can also be considered a sub-theory within another common school of thought: that music evolved for social bonding purposes (Launay and Pearce, 2020). Dunbar (2012) theorized that music arose for the purpose of influencing individuals to become more group-oriented by producing endorphins that cause people to feel warmer toward other humans. In particular, music may have arisen as a more effective method of social bonding for large groups compared to previously used methods such as grooming (Dunbar, 2012). Interestingly, Dunbar (2012) proposes that laughter may have led to the evolution of music since laughter also importantly improves social interactions and increases our endorphins, and is somewhat similar to group music making in that it can be a chorus of semi-synchronized sound production. More recently, Savage et al. (2020) posited that music, or rather musicality (the skills involved in creating and experiencing music), evolved for social bonding purposes, particularly to achieve social bonding on a larger scale than other previous methods could accomplish, like grooming. They further suggest that gene-culture coevolution is responsible for the evolution of musicality in that certain musical behaviors likely fed into how humans evolved biologically because of their social bonding effects (Savage et al., 2020).
Some researchers have developed testable hypotheses to study the social bonding hypothesis, like the studies mentioned above on parent–child bonding. For instance, Weinstein et al. (2016) collected self-report data on measurements of social bonding and pain threshold data from participants from small and large choirs after 90 min of singing. They found that both the smaller and larger group singing experiences increased feelings of social closeness and pain thresholds, which are indicative of a higher amount of endorphins that could lead to more effective social bonding (Weinstein et al., 2016). Relatedly, Beck and Rieser (2020) measured the prosocial behaviors of 62 preschool-aged children following different types of group activities, some with music and some without. They found that the children who participated in musical play were more likely to share and help spontaneously than their peers in the non-musical groups (Beck and Rieser, 2020). Dunbar et al. (2021) recently found further biological evidence that supports the idea that group participation in music making increases endorphins and could therefore enhance social bonding. Specifically, they theorized that nodding one's head, a common motion when listening to and engaging with music, might stimulate certain cochlear receptors that trigger the endorphin system (Dunbar et al., 2021). To test their theory, they compared participant pain thresholds before and after participating in the experimental condition (nodding their head along to music) and in several control conditions. They found that rhythmic motion does indeed increase pain thresholds but that music alone did not seem to have this effect (Dunbar et al., 2021). The results suggest that the soothing, pleasing effect of moving rhythmically, such as when dancing to music or rocking a baby to a lullaby, could underlie the evolutionary need for music for social bonding purposes (Dunbar et al., 2021).
Credible Signaling Hypothesis
Conversely, in a companion article to Savage et al. (2020), Mehr et al. (2020) propose a different theory: the credible signaling hypothesis. The credible signaling hypothesis posits that music evolved to serve as a convincing signal of at least two kinds of information: (1) coalition size, strength, a cooperation ability, and (2) parental attention for young children. Regarding coalition size and strength, echoing a similar theory proposed by Hagen and Bryant (2003), Mehr et al. (2020) argue that groups of ancient humans may have territorially signaled their presence to outsiders through coordinated, loud vocalizations, similar to those made by other social species such as wolves or chimpanzees. While loudness would communicate strength and size, Mehr et al. (2020) further claim that early humans would have been motivated to increase the complexity of their territorial advertisements to communicate an adept ability to work together, making the group more formidable to outsiders. They argue that these calls of increasing complexity could have preceded music, especially rhythmic elements of music (Mehr et al., 2020). Some recent empirical work offers support for the theory that music can effectively signal coalition size and strength. For example, Lee et al. (2020) examined how music and dance can signal group social closeness and formidability (physical fitness) by using realistic avatars that engaged in group dances with different levels of synchrony. They found that synchronized unison movements more strongly signaled both formidability and social closeness (Lee et al., 2020). Relatedly, Fessler and Holbrook (2016) had participants listen to groups of soldiers or terrorists with either synchronized or unsynchronized footsteps in two online studies (one with 698 participants, one with 534 participants) and found that participants rated groups with synchronized footsteps as more formidable.
Regarding the second function, signaling parental attention, Mehr et al. (2020) argue that early humans were motivated by infant attentional needs (communicated by crying) to create a sustained vocal signal that would be effective at communicating parental attention to an infant thereby fulfilling their attentional needs. They theorize that this vocal signal became singing, similar to theories on how “motherese” may have eventually become singing. However, Mehr et al. (2020) differ from other theories on motherese and music in that their theory focuses on the signaling ability of music rather than its general possible ties to the evolution of language. This second signaling function is also supported by the previously discussed evidence for the role of music in parent–child bonding.
Concluding Remarks on Existing Theories
As detailed above, there is strong empirical evidence for each of these adaptationist theories, excepting perhaps the sexual selection hypothesis. This evidence suggests that each of these theories is plausible and could all very well be factors in the evolution of music. However, we argue that they still do not fully answer the question of why music evolved into the art form that we know today. For instance, concerning the credible signaling theory (Mehr et al., 2020), what was the motivation for combining the melodic elements of motherese with the rhythmic elements of territorial displays? What other survival needs did early music serve?
We argue that there is yet another important signaling function that contributed to the early evolution of music. Specifically, we propose an additional credible signaling function for music: signaling socio-affective fiction for emotional development purposes, or the socio-affective fiction (SAF) hypothesis. In our theory, we highlight how emotion regulation and resilience are uniquely crucial to the survival of the human species and trace how music might have evolved to exercise and strengthen these functions by serving as a tool for SAF, particularly in the context of storytelling. In this review, we outline the reasoning behind the SAF hypothesis in detail and present cross-disciplinary evidence for our theory highlighting the adaptative function that music could have had for humans during evolution.
Our signaling theory aligns with an ethological approach to understanding musical emotions, as discussed, for example, by Huron (2015). In ethology, it is important to differentiate between signals and cues (Laidre & Johnstone, 2013; Tinbergen, 1963). Our proposed signaling function of music would qualify music specifically as a “signal” with potential communicative and performative functions for emotional meaning, rather than as simply an affective auditory “cue” with no primary communicative function (Huron, 2015). When hypothesizing about the information music can signal, it is important to consider its functionality. Of course, ancient humans could have used music quite differently from how we use it today. However, examining contemporary applications of music is still a useful starting point for evolutionary hypotheses. In outlining our theory, we begin by examining one of music's primary functions: portraying and/or inducing emotions (Eerola et al., 2018; Eerola & Vuoskoski, 2013; Juslin & Sloboda, 2011; Juslin & Västfjäll, 2008; Trevor et al., 2020, 2023).
Analysis and Proposed Solution
Music and Emotion
Music is constantly used to signal and influence emotions throughout our daily lives. When clothing store owners play music, they do so to improve the moods of their customers and entice them to stay and buy something (Andersson et al., 2012; Jain and Bagdare, 2011). People often listen to upbeat, energetic music while running to encourage themselves to run faster or decrease fatigue (Buttice, 2020; Karageorghis and Priest, 2012; Van Dyck and Leman, 2016). Music can also be used to calm anxiety (Panteleeva et al., 2018), soothe depressed individuals (Aalbers et al., 2017), and help people sleep better (Cordi et al., 2019) or focus on their work (Haake, 2011). It is also used almost constantly in films, videogames, television shows, and advertisements to convey the emotional states of characters or situations.
How exactly does music express emotions? While several theories abound (Juslin, 2019), a prominent view is that music conveys emotion through three types of coded information: iconic, intrinsic, and associative (Juslin, 2013; Sloboda and Juslin, 2001). Iconic coding is recognizable as formally similar to another kind of signal, such as a vocal sound (Juslin, 2013). Essentially a form of mimicry, it can be thought of as the lowest level or most obvious type of coding in expressive musical information. Intrinsic coding is communicated by structural phenomenon in the music itself that have affective associations (Juslin, 2013). For example, harmonic motions in the music can become tense and then resolve, conveying affective tension and release in the process. And finally, associative coding utilizes previously learned connections to signify affect (Juslin, 2013). For example, an upbeat melody played by a saxophone might have associations with bubbly jazz music for some and therefore signify emotions related to that kind of music, like joy or excitement. The latter two methods of coding require music to be in a well-established format that is prevalent in society to operate. To utilize culturally learned associations, associative coding is only possible when music is fairly pervasive in daily life. Intrinsic coding requires music to have established formal traits and for the listener to have a learned understanding of how music typically operates, again necessitating that music is popular and heard regularly. However, the first type of coding, iconic, needs little prior exposure to music to operate. It also does not require that music be in an evolved, structured state. Therefore, it is likely that iconic coding was the first kind of expressive musical information to be used. Essentially, to convey emotion, early musicians likely mimicked previously created signals, like the human voice or other natural sounds.
Music Mimicking the Voice
Comparisons of musical sounds to vocal or natural sounds have been ever present in Western art music for centuries. Music pedagogues frequently rely on common knowledge of vocal expressive behaviors or natural sounds to instruct students on how to play their music expressively. For instance, an instrument teacher might tell a student to think of whispering, crying, or laughing when describing how to play a passage. Healy and Gibbs (2020) researched the effectiveness of this technique in a case study with a flute masterclass. They found that the expert performer leading the master class was able to use comparisons with vocal sounds to instruct the students on their flute technique but also communicate broader concepts like performance authenticity and musicianship (Healy and Gibbs, 2020). Instances of instrumentalists, composers, and conductors advising musicians to model musical expressions after vocal behaviors or singing can be found throughout musicology literature. Leopold Mozart (1719–1787), one of the most famous violin pedagogues of all time, wrote in his treatise, “and who is not aware that singing is at all times the aim of every instrumentalist; because one must always approximate to nature as nearly as possible” (Mozart, 1948). Another violinist and composer, Edmund Severn (1862–1942), said in one of his pedagogy lectures, “Let us not forget that the violin is a singing instrument and that even [Joseph] Joachim [a famous violinist from the 19th century] said: ‘We must imitate the human voice’” (Martens, 1919). A tendency to use the voice as an expressive model is also evident in some of the codified expressive instructions composers write in their scores. For instance, in Italian musical terms, sospirando means “sighing” (Kennedy and Kennedy, 2013), gemendo means “moaning,” bisbigliando means “whispering,” piangendo means “crying out,” and singhiozzando means “sobbing” (Sissons, n.d.). Similar terms are evident in other languages as well, such as soupirant meaning “sighing” in French and flüsternd and gehaucht which mean “whispering” in German (Sissons, n.d.).
Music analysts have also documented the many ways in which music mimics voices or natural sounds, particularly in a branch of music theory called topic theory. In music theory, topics are “subjects for musical discourse” (Ratner, 1980) or, said another way, collections of musical characteristics that have gained a cultural association through repeated use in similar contexts (Hatten, 1992; Mirka, 2014; Ratner, 1980). This type of signification is essentially associative coding. However, topics also catalog instances of iconic coding in music as well. For instance, the pianto topic, also called the “sigh” topic, is a falling minor second motion associated with grief and weeping that “originally imitated the moan of someone in tears” (Monelle, 2000, p. 17). Some topics also reference non-human natural sounds. For example, the tempesta topic references storms (McClelland, 2017, 2014). Some of the musical features that characterize the tempesta topic amount to iconic codings, such as the use of actual thunder sound effect machines and dynamic swells and crashes in the music (McClelland, 2017). In another topic, ombra–music for supernatural suspenseful scenes, certain melodic or rhythmic figures used are sometimes evocative of racing heartbeats, approaching footsteps, or screams (McClelland, 2012).
This vast multitude of references to the voice and natural sounds in all fields of music has prompted empirical investigations of instances of vocal mimicry in music (Juslin and Laukka, 2003; Scherer, 1995). Juslin and Laukka (2003) reviewed 104 studies of vocal expression and 40 studies of musical expression and found many similar expressive devices shared across domains. They found that voice and music both utilize tempo/speech rate, voice intensity/sound level, voice/sound level intensity, voice/sound level variability, high-frequency energy, fundamental frequency (F0)/pitch, F0/pitch variability, F0/pitch contours, voice onset/tone attack, and microstructural regularity to express emotions (Juslin and Laukka, 2003). Their results showed that music and voice often use these features in similar ways to express emotions, but occasionally they differed (Juslin and Laukka, 2003). For example, for speech rate/tempo, they found that similar speeds are used to convey emotions across domains: a fast rate/tempo expresses anger, fear, and happiness and a slow one expresses sadness and tenderness (Juslin and Laukka, 2003). However, for high-frequency energy usage, fear is typically expressed with a lot of high-frequency energy in the voice and typically a lower amount in music (Juslin and Laukka, 2003).
Other research in this area directly investigates how acoustically similar musical copies of vocal and natural sounds are to the originals, and whether they communicate a similar emotional meaning. Trevor et al. (2020) used acoustic analyses and behavioral data to test whether scream-like terrifying film music mimics the sound of, and is perceived similar to, actual human screams. Specifically, they measured a unique acoustic feature of human screams called “roughness” and collected valence and arousal ratings from participants for four types of stimuli: (1) human screams, (2) non-screaming vocalizations, (3) scream-like music, and (4) non-scream-like music. The results, shown in Figure 1, demonstrate that scream-like music (shown in dark blue) seems to mimic human screams (shown in orange) in that both exhibit higher amounts of roughness than their non-screaming counterparts (non-scream-like music in light blue, non-screaming vocalizations in yellow). Additionally, scream-like music was also rated as negatively valenced and emotionally intense (higher arousal) similar to actual human screams (Trevor et al., 2020). However, the scream-like music excerpts were still not perceived as quite as alarming as the real human screams, and did not exhibit quite as much “roughness” (Trevor et al., 2020). Therefore, while scream-like music is a good imitation, it is still processed clearly as an imitation and therefore less emotionally impactful than the real vocal signal. This finding could indicate a clear signal difference between vocal cues and musical imitations of these cues: The musical signal communicates clearly that it is a mimicry and not the real thing.
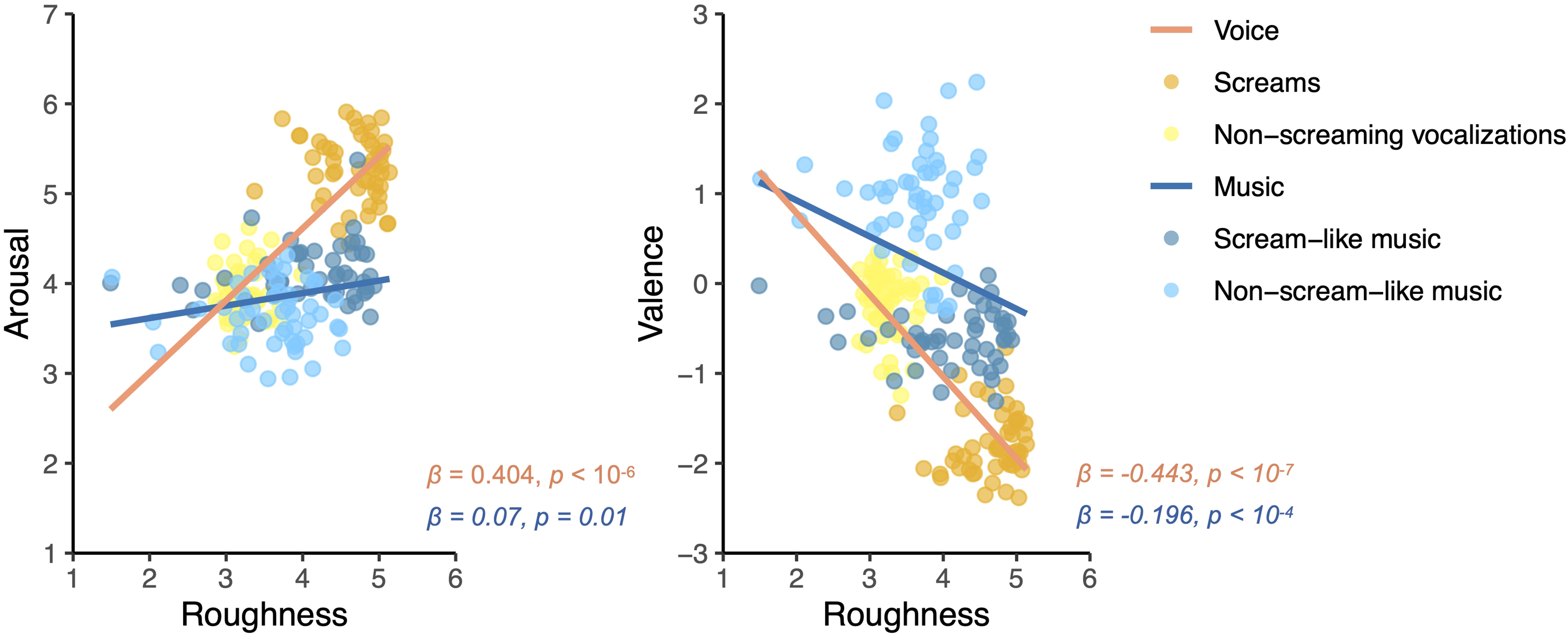
This figure shows the results of an investigation into whether scream-like music sounds like, and is perceived similarly to, human screams (Trevor et al., 2020). The results of the behavioral rating data (valence and arousal) and the acoustic analyses (roughness) demonstrate that while scream-like music exhibits higher roughness values and was rated as more negatively valenced and emotionally intense than non-scream-like music, akin to screams, human screams are still the more potent signal as demonstrated by even higher roughness values and more negatively valenced and emotionally intense ratings. Reproduced from [Trevor et al., (2020). Terrifying film music mimics alarming acoustic feature of human screams. The Journal of the Acoustical Society of America, 147(6), EL540–EL545. https://doi.org/10.1121/10.0001459], with the permission of the Acoustical Society of America.
The results of a related study further emphasize this signaling difference. Trevor and Huron (2019) examined whether composers of nominally humorous classical pieces mimic rhythmic acoustic cues of laughter, such as staccato rhythms, with a corpus study of piano pieces and a behavioral study. In the corpus study, they found that humorous pieces had more staccato rhythms than control pieces, consistent with their hypothesis, but did not have more instances of isochronous rhythms, inconsistent with their hypothesis (Trevor and Huron, 2019). The motivation for the behavioral study was to see whether participants could perceive a musical instrument as sounding laughter-like (Trevor and Huron, 2019). Participants were asked to adjust the speed (tempo) and duration (articulation) of repeating instrumental tones to sound the most like human laughter with the hypothesis that participants would make adjustments similar to reported speeds and durations of actual human laughter (Trevor and Huron, 2019). However, the results showed that participants adjusted the tones to be slower and longer than human laughter (Trevor and Huron, 2019). The authors conjectured that the longer, slower version of laughter was akin to “fake” laughter, such as that used in opera (Bryant & Aktipis, 2014; Lavan et al., 2016; Provine, 2001, 2008; Trevor & Huron, 2019). These results further strengthen the notion that musical copies of vocal sounds are meant to communicate clearly that they are not the true vocal sound.
As these papers show, musical imitations of vocal signals are less effective at communicating emotions than vocal ones. It seems that while musical versions of vocal signals communicate a similar, albeit dampened, emotional meaning, they also crucially communicate “emotional fiction”—that the musical signal is performative rather than real (e.g., a musical scream-like sound compared to a real human scream). The finding begs the question of why humans have a need for a tool that communicates and creates “emotional fiction”? What need do humans have for emotion simulations, especially in the early days of music making but also in modern cultures? And why does music seem to be better at creating emotional fiction than other evolved tools and cultural techniques?
The Evolutionary Benefit of Simulated Emotions
To understand the evolutionary benefit of simulated emotions, it is useful to examine the role of simulated emotional activities in our lives today. In particular, we focus on recreational activities that simulate scary situations, such as haunted houses, horror movies, or scary video games. Lots of people enjoy taking part in these scary simulations even though they invoke negative emotions, like fear and anxiety (Andersen et al., 2020; Clasen et al., 2020). Andersen et al. (2020) recorded heart rate, video, and self-report data from 110 participants in a haunted house to study how people feel while partaking in recreational fear. They found that self-reported fear and large-scale heart rate fluctuations were positively correlated showing that participants experience physiological symptoms of fear consistent with their reported feelings (Andersen et al., 2020). However, they also found an inverted U-shaped correlation between self-reported enjoyment and self-reported fear suggesting that there is an optimal level of fear for maximum enjoyment (Andersen et al., 2020). How is it possible that people enjoy these activities even though they feel some level of fear while doing so?
Clasen et al. (2020) recently surveyed 1070 participants on personality traits, paranormal beliefs, and their usage and preferences regarding horror entertainment to study this phenomenon. They found that sensation seeking and “intellect/imagination” (from the Big Five factors, also called “openness to experience”) were personality traits that positively correlated with the enjoyment of horror entertainment (Clasen et al., 2020). People with these personality traits seem to consume horror media as a sort of challenge (Clasen et al., 2020). They seem to get pleasure during the experience from successfully coping with the averse emotional reactions that horror media induce (Clasen et al., 2020). The authors further suggest that this proposed rewarding feedback loop supports the hypotheses that simulated scary situations, like those in horror media, may have the adaptive function of preparing one for threatening situations in real life (Clasen et al., 2020). Morin et al. (2019) tested a similar hypothesis, one they coined as the “ordeal simulation hypothesis,” in which they theorize that perhaps narrative fiction was born from the adaptive benefit of mentally rehearsing threatening encounters to increase our survival chances. Focusing on literature, they specifically predicted that in line with the hypothesis, (1) the odds of dying in a year would be exaggerated in novels compared to real life, and (2) novels would mention deaths caused by some kind of agent (i.e., homicide) more often in fiction than in non-recreational texts, namely, letters (Morin et al., 2019). They found that novels indeed greatly exaggerated the odds of dying in a given year compared with real-life statistics, especially for homicides, consistent with the hypothesis, but did not find that death was mentioned more in fiction than in letters, inconsistent with their hypothesis (Morin et al., 2019).
Relatedly, there are theories that nightmares might have also evolved to rehearse threat perception and avoidance (Revonsuo, 2000; Zadra et al., 2006). Zadra et al. (2006) tested this hypothesis with a sample of 212 recurrent dreams recorded through the use of a questionnaire. While they found that 66% of the recurrent dreams contained one or more threats, with dreamers being the object of the threat 94% of the time, the events in these dreams were often highly unlikely to happen in real life and the dreamers rarely escaped or handled the threat adequately (Zadra et al., 2006). Overall, the results provide mixed support for the hypothesis that dreams evolved for threat preparedness (Zadra et al., 2006). Relatedly, Bown and Gackenbach (2016) reviewed recent findings in videogame research that suggest that playing combative videogames reduces the amount of nightmares one has. They theorize that gamers might have less nightmares because the videogames satisfy the role that nightmares normally play in threat preparedness (Bown and Gackenbach, 2016). Combative videogames or virtual reality programs can also be used to prevent nightmares therapeutically. McNamara et al. (2018) studied 19 volunteers who participated in a four-week virtual reality and rescripting nightmare treatment program. Their results showed a significant reduction in nightmare frequency, distress, and effects as well as overall anxiety levels at the end of the program (McNamara et al., 2018). These results further support the threat preparedness hypothesis for the evolution of nightmares and its connection to horror media today.
An important part of threat preparedness is strengthening emotion regulation and resilience. Some studies have shown that engaging with fearful recreational activities does just that in both recreational and therapeutic contexts. For example, Scrivner et al. (2020) surveyed 310 fans of horror films to investigate how prepared they were for the COVID-19 pandemic. They found that horror film fans, and morbidly curious people, showed more robust psychological resilience to the pandemic, especially if they enjoyed “prepper” films (e.g., zombie or apocalypse themed), consistent with the hypothesis that these films could benefit viewers by increasing their threat preparedness (Scrivner et al., 2020). There is some evidence that videogames can be used to strengthen emotion regulation (Pallavicini et al., 2018). Lobel et al. (2016) report on a horror videogame that utilizes player biofeedback and discuss how it can be used to improve emotion regulation. The game in question, called Nevermind, is a horror-themed game that alters its atmosphere and events to be more or less scary depending on player arousal thereby encouraging players to work on controlling their emotions (Lobel et al., 2016). Bouchard et al. (2012) had 41 soldiers participate in a three-day study in which they either had no stress management training or had stress management training while playing a horror combat videogame. After the three-day period, as participants took part in a live training session with a simulated ambush, the experimenters measured their stress levels via salivary cortisol levels and heart rate (Bouchard et al., 2012). Their results suggested that the stress management training within the immersive videogame was effective at lowering the soldiers’ stress levels during in-person training simulations (Bouchard et al., 2012).
Emotion regulation and resilience are uniquely crucial to human survival. Unlike most animals, humans are able to imagine the future and alternative realities, enabling us to plan for future events (Suddendorf, 2013). This ability unfortunately also grants humans with an awareness of our inevitable mortality (Suddendorf, 2013). The burden of these cognitive abilities is that humans can become anxious about the future or suffer from depression. These issues are globally significant. In 2017, the World Health Organization estimated that more than 322 million people suffered from depression and 264 million suffered from anxiety (World Health Organization, 2017). In fact, there is a theory that the only way in which humans are able to survive and evolve is through an adaptive ability to deny our eventual death, to live as if the inevitable will not happen (Hogenboom, 2016; Varki, 2009). As the only animals that can envision a world without themselves in it, humans are also the only animals capable of suicide (Hogenboom, 2016; Suddendorf, 2013; Varki, 2009). Humans are also at risk of losing control of their emotions, sometimes resulting in irrational or dangerous actions, such as a “crime of passion”: the murder of a significant other. According to a recent report by the United Nations Office on Drugs and Crime, 34% of all female homicides in 2017 were committed by an intimate partner (UNODC, 2019). In summary, exercising resilience and emotion regulation is paramount to our survival. Thus, emotion simulations had significant adaptive value for early humans. We argue that music evolved in part to fulfill this survival need.
The Socio-Affective Fiction Theory
Recall that our driving question is why would early humans spend energy creating and developing a signal that mimics vocal and natural sounds but is effectively weaker, seemingly designed to communicate emotional fiction? In our theory on the evolution of music, we propose that early humans created and developed music for emotion simulation purposes, particularly in attachment to the most ancient and universal form of emotional simulation: storytelling (Anderson, 2010; Boyd, 2009; Smith et al., 2017). Recent musicology research has shown that listening to pure instrumental music can trigger imagined narratives and stories (Margulis et al., 2022). This mechanism of imagined narratives during music listening seems to appear universally across distinct modern and rural cultures (Margulis et al., 2019; Margulis, 2022). However, the imagined narratives seem to have strong culture-bounded connotations (Margulis et al., 2019; Margulis, 2022).
In a similar manner to today, storytelling had many roles in ancient societies, such as preserving historical and cultural information, providing mythological explanations of natural events, enabling humans to communicate their experiences to one another, and also for entertainment (Anderson, 2010). It is the first method by which humans could simulate situations and emotions outside of their own dreams. Boyd (2009) theorizes that this capability is part of why fictional storytelling evolved so that humans could practice scenarios in simulation and thereby sharpen certain cognitive capacities, such as planning ahead or empathizing with others. In our theory, we focus on how storytelling can allow humans to exercise emotion regulation and thereby strengthen their resilience. To make storytelling more emotionally impactful, immersion is key. Dreams are such effective simulations due to the nearly complete immersion of the dreamer into the dream. While dreaming, people typically believe that the events happening to them are real, except in the rare case of lucid dreams (Baird et al., 2018). In fact, dreams are almost too effective in that nightmares are aversive to experience, while viewing a scary film can be fun because it is not quite as immersive, thankfully.
Immersion has powerful value in storytelling even today. Movie theaters use surround sound and total darkness to immerse the audience in the film-viewing experience. Videogame systems incorporate haptic feedback to make gameplay feel more real. Concerning storytelling, speech on its own is not always satisfyingly immersive enough. When parents tell stories to their children today, they often manufacture different voices for each character and make sound effects for different animals (e.g., mooing for a cow, clicking one's tongue to mimic the sound of a horse trotting) or events (e.g., vocalizing a creaking sound to mimic the sound of a door opening). This low level but effective immersion technique would also have been accessible to humans in ancient times. The sound effects early humans probably made would likely have imitated their natural soundscape, such as snakes hissing, thunder crashing, or people whispering. We theorize that the need for greater immersion for more powerful storytelling then pushed humans to move beyond creating sounds with their voice to creating external imitative noise makers—early instruments.
Many ancient musical instruments were created to imitate natural sounds. An instrument called the bull-roarer was used by the O’odham people of the United States to imitate the sound of rain as part of a ritual calling for rain (Levine, 2014). Found in many parts of the world, it consists of a piece of wood tied to a piece of string that is then whirled through the air to make a noise (Levine, 2014). Another instrument used for rain-calling rituals was the rainstick which originated in Chile (Kvistad, 2014). Consisting of a hollowed-out piece of wood or cactus with stones or seeds sealed inside, it makes a sound like water or rain when tilted (Kvistad, 2014). The morache, also called a bear growler, is a type of rasp: a notched wooden instrument that one scrapes with a stick to produce sound (Densmore, 1922; Patterson and Duncan, 2014). Figure 2 shows two photos of rasps: a Native American (Pueblo) rasp from the 19th century (on the left), and a rasp carved from bone from the 19th century that is possibly Guyanese in origin (on the right; Catalogue of the Crosby Brown Collection of Musical Instruments: Oceanica and America, 1913). The morache was used by the Ute people of the United States to mimic the sound of a bear's voice for the Bear Dance (Densmore, 1922; Patterson and Duncan, 2014). As shown through each of these examples, a lot of these instruments were developed to literally mimic a natural sound as a way of representation, in either a ritual or a dance.

Photos of rasps from the 19th century (Catalogue of the Crosby Brown Collection of Musical Instruments: Oceanica and America, 1913). These photos are available for use under a Creative Commons Zero (CC0) license from The Metropolitan Museum of Art, New York.
It is easy to imagine natural sounds that, when mimicked, would become the two universal main elements of music: melodies and rhythms. Heartbeats, footsteps, and other human and animal movements would become rhythmic elements when mimicked. Illustratively, some Native American oral traditions describe drumbeats as the earth's heartbeat (Harris, 2016). On the other hand, many vocal sounds would be quite melodic when mimicked: crying, sighs, laughter, and so on. Furthermore, calls made by birds and other animals would also be melodic when mimicked. For example, the Aboriginal tradition of gumleaf playing 1 in Australia grew from mimicking bird calls to playing full complex melodies (Taylor, 2015). We propose that as these sounds were mimicked and combined in the service of creating more immersive storytelling, music was born.
Musical instruments have universally been used in storytelling throughout much of human history. Music was also often seen as a way of connecting to the spirit realm. For example, the Sámi people, who live in northern territories of Russia, Sweden, Finland, and Norway, had shamans (called noaidi) with magic drums of wood and reindeer hide (Joy, 2015). They beat these drums to enter a trance and communicate with the spirit world to help their community (Joy, 2015). Kazakh and Kyrgyz shamans from Central Asia used the plucked string komuz, or dombra, to communicate with the spirit world, among other instruments as well (Aslanova et al., 2018). In such practices, music was used to signal “otherworldliness.” This usage strongly parallels our concept of signaling “emotional fiction,” something that is not “real,” or not “of this world.”
We theorize that as society became safer and more stable, music then transcended its initial mimetic form to become more like what we expect music to sound like today. However, across the vast transformation music has undergone over time and across cultures, music still retains the strong primary function of portraying and inducing emotions, still frequently mimics the voice and natural sounds, and is still often connected to storytelling (although not always, e.g., absolute music, non-narrative music, etc.). For instance, many contemporary compositions either contain a story in themselves (such as a pop song about a breakup) or are written to accompany stories in film, theater, dance, and other formats.
Our theory is summarized in Figure 3. In the left-most panel, we show that before music, humans were only exposed to human-generated and nature-produced sounds, like laughter or crickets chirping. Then, in the middle panel, we show how music could have emerged from sound effects used to make storytelling a more immersive experience and thereby a more effective simulation. These proto-musical sounds were likely imitations of the sounds they knew: human and nature-produced sounds. Then, as shown in the right-most panel, we theorize that music eventually transcended its original mimicry-based form, growing in complexity while still retaining its use as a powerful emotional fiction signal.
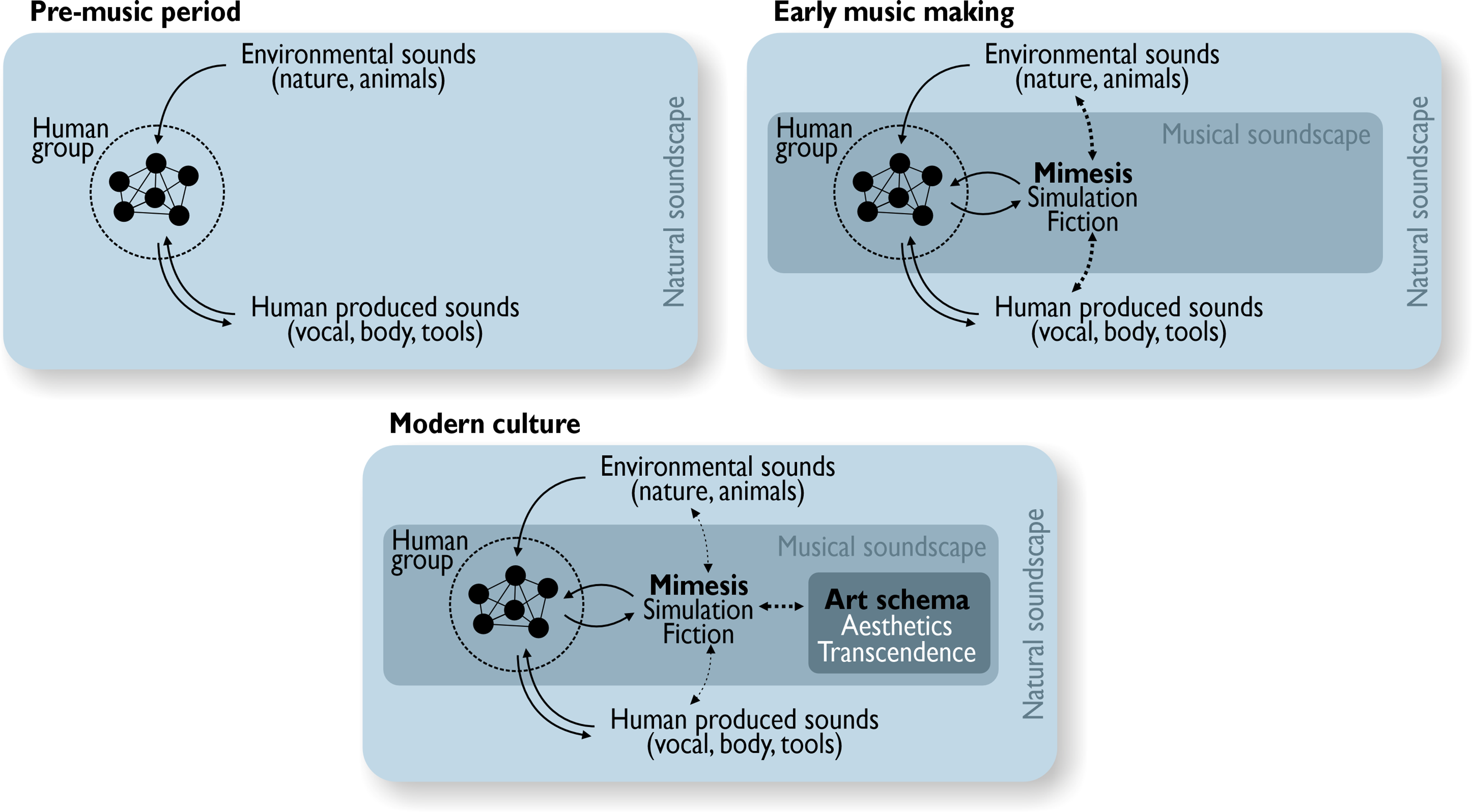
The three panels outline our socio-affective fiction (SAF) theory for the evolution of music. Moving from left to right, we show the pre-music period (environmental and human sounds only), then the period of early music making where proto-musical sounds may have mimicked natural ones. Finally, the last panel shows how music eventually transcended this mimicry-based form to become the complex artform we know today, all the while retaining its function as a signal for emotional fiction.
Additional Cross-Disciplinary Evidence for the SAF Theory
Research on art perception demonstrates that the concept of “emotional fiction” is still vital to audiovisual processing today. We hypothesize in our SAF theory that the differentiation of real life from fiction, as communicated by musical versions of natural sounds, eventually evolved into a mental template called the “art schema” (see Figure 2, right panel). When we mentally categorize something as art, we activate the “art schema” and that template then shapes our emotional response (Wagner et al., 2014). For example, we respond differently emotionally to a photograph of a real crime scene compared to a still from a film that depicts an artificial crime scene (Wagner et al., 2014). The safety of a simulation, this “art schema”, also allows humans to cathartically experience difficult emotional experiences in a more controlled, structured way. For instance, Millar and Lee (2021) describe how viewing horror films can be cathartic for bereaved individuals because they can work through grief-related emotions while experiencing the movie in a more structured and regulated way than real life allows. They describe this process as a type of emotional “scaffolding” (Colombetti and Krueger, 2015; Millar and Lee, 2021). This process could be a huge evolutionary benefit of using music for emotion induction: scaffolding intense emotions to allow us to experience them and work through them in a safer way, eliminating the risk of losing control and harming oneself or others. Perlovsky (2015) relatedly theorizes that humans use music to overcome cognitive dissonance by embodying abstract emotions. Cognitive dissonance results from having conflicting ideas, beliefs, or impulses, such as when one believes that cruelty to animals is wrong but still wants to eat a cheeseburger. Cognitive dissonance causes many uncomfortable emotions, some not even consciously experienced. Perlovsky (2010, 2012, 2015) theorizes that music evolved from affective vocal prosody to provide a space for us to consciously experience those abstract, unconscious emotions and thereby make cognitive dissonance more palatable to experience.
Research in music and neuroscience shows that listening to music seems to activate mind-wandering, perhaps indicating the power of the “emotional fiction” signal still inherent in music today. For example, a common observation in music and neuroscience research (Frühholz et al., 2014, 2016) is that listening to music involves more activity in the medial frontal cortex (MFC) (Koelsch, 2020)—an area associated with mind-wandering, and in the hippocampus (HC) (Koelsch, 2020; Trost et al., 2012; Trost and Frühholz, 2015)—an area associated with memory retrieval and elicitation of imaginary associations. In Figure 4, panel “a” shows how the HC and MFC are both active while processing musical emotions (Trost et al., 2012), and panel “b” demonstrates how the hippocampus (HC) and medial frontal cortex (MFC) are more active for musical emotions than for nonhuman sounds, nonverbal expressions, or speech with affective prosody (Frühholz et al., 2016). It is worth noting that these brain areas are not activated as much by non-musical emotional sounds, such as vocal or natural ones (Frühholz et al., 2016). In a related study, Koelsch et al. (2019) investigated the influence listening to different types of emotional music has on your mind and found that listening to both heroic and sad music increases mind-wandering and that the valence of the music influenced the valence of the content of this mind-wandering. Nostalgic music can also induce strong states of remembrance, which seems to be associated with hippocampal activity (Frühholz et al., 2014; Trost et al., 2012). It appears that music communicates a simulation setting so strongly that it alone can transport the mind into its own “story” with coinciding emotional experiences.
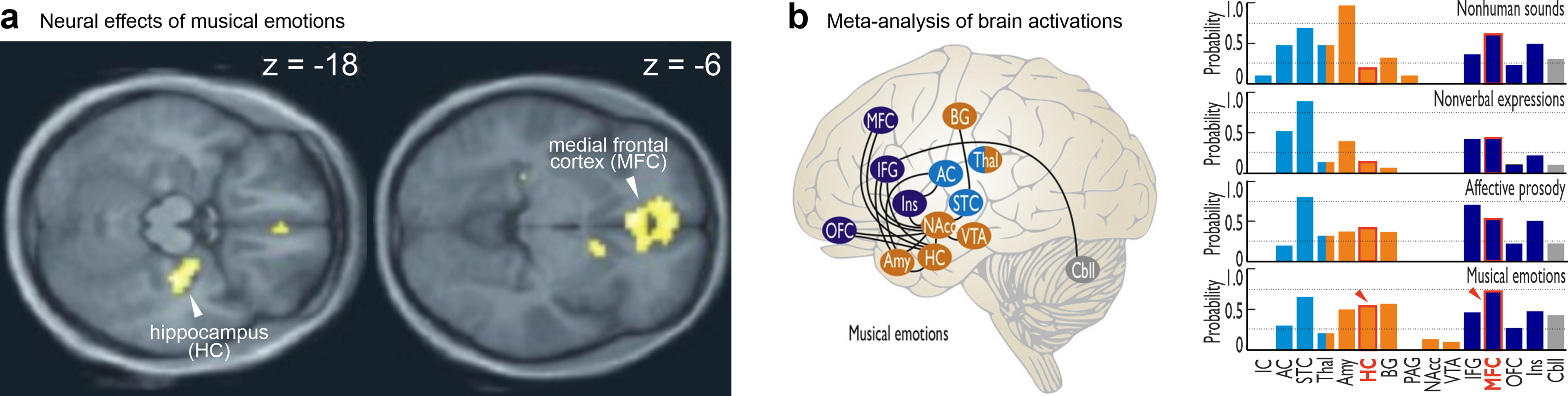
Neural network for processing musical emotions as constructed from a review of music and neuroscience studies (Frühholz et al., 2016; Trost et al., 2012). Both panels show results demonstrating that the hippocampus (HC) and the medial frontal cortex (MFC) are active while processing musical emotions. Panel ‘a’ is reproduced and adapted from [Trost et al. (2012). Mapping aesthetic musical emotions in the brain. Cerebral Cortex, 22(12), 2769–2783. https://doi.org/10.1093/cercor/bhr353] which is available for non-commercial use under a Creative Commons CC-BY-NC license from Oxford University Press. Panel ‘b’ is reproduced and adapted from [Frühholz et al. (2016). The sound of emotions-Towards a unifying neural network perspective of affective sound processing. Neuroscience and Biobehavioral Reviews, 68, 1–15. https://doi.org/10.1016/j.neubiorev.2016.05.002] with permission from Neuroscience & Biobehavioral Reviews.
There is also neuroscientific evidence connecting music and the voice as highly similarly processed, further supporting our theory that music might have evolved from vocal affective mimicry (Frühholz et al., 2014). Paquette et al. (2018) compared how short musical bursts and nonverbal emotional expressions are processed in the brain using an fMRI paradigm with 20 participants. In their results, they found that a machine learning classifier trained on fMRI patterns for vocal-emotional fragments was able to correctly categorize the emotions of musical excerpts played by the violin or clarinet (Paquette et al., 2018). These results suggest a strong overlap between the neural networks that respond to vocally and musically conveyed emotions (Paquette et al., 2018), consistent with the theory that music evolved from mimicking vocal sounds. More recently, Paquette et al. (2020) used EEG to compare how musical and vocal emotions are processed in time with 15 participants. The results suggested that the brain prioritizes processing vocal sounds over musical ones, likely related to their biological relevance (Paquette et al., 2020). However, musical affective bursts designed to be similar to vocal affective sounds (Paquette et al., 2018) were also preferentially decoded by the brain, supporting the notion that music may have evolved in parallel with speech (Paquette et al., 2020), or as we propose, in mimicry of vocal sounds.
Some behavioral and acoustic investigations further support the strong similarity between musical and vocal-emotional processing. Correia et al. (2020) investigated whether vocal emotion perception and musical skill are connected in 169 participants with varying degrees of musical training. They found that music perception abilities, even when untrained, correlated positively with strong vocal-emotional perception abilities (Correia et al., 2020). These results further strengthen the theory that music was born from vocal-emotional mimicry. Nordström and Laukka (2019) used an auditory gating paradigm 2 to investigate how much of a given vocal or musical emotional excerpt participants needed to hear (e.g., how many milliseconds of exposure) to correctly identify the emotion being expressed. They found that emotion recognition took longer to stabilize for musical excerpts than for vocal ones, possibly because some musical emotional cues take more time to unfold (Nordström and Laukka, 2019). However, detailed acoustic analyses of the stimuli revealed strong correlations between the music and vocal-emotional cues further highlighting the similarity between how music and the voice convey emotions (Nordström and Laukka, 2019).
Concluding Remarks and Future Directions
We were motivated to develop the SAF theory by our feeling that something was still missing from the current discussion on the evolution of music. It seemed that the very initial start of music making, especially the impulse to make the first musical instruments, had not yet been fully addressed. To work on closing this gap, we present the SAF theory. Specifically, we propose that music evolved from (1) humans mimicking natural sounds for storytelling purposes, and (2) that humans were motivated to use and develop these proto-musical sound effects for the purpose of creating a strong emotional fiction tool that helped humans develop their emotion regulation abilities and strengthen their resilience. We also present cross-disciplinary evidence for our theory including (1) the primary function of music to signal and induce emotions, (2) numerous accounts of music striving to mimic the voice and natural sounds both in modern times and ancient musical practices, (3) the adaptive value of simulated emotions, and (4) the ability of music to provide and enhance essential emotion simulation experiences.
We consider our SAF theory to be an adaptationist take on the evolution of music. As we outlined in the first section, there is an ongoing and lively debate between scholars proposing adaptationist versus non-adaptationist views on the evolution of music. Non-adaptationist scholars would argue that the evolution of music only occurred due to the prior evolution of precursory human capabilities, such as language and its accompanying cognitive abilities (e.g., associative learning, memory, etc.) (Patel, 2010), or precursory functional properties of the neural auditory system for ASA (Trainor, 2015). While these proposals make valid assumptions, we still felt that there was a missing piece explaining the earliest forms of music making in humans. A core proposal of the SAF theory is that music making and music listening can strengthen human resilience, especially in threat-rich and uncertain environments. Music can simulate emotions and emotional experiences in safe contexts by mechanisms of mimesis (Aristotle, 2006), which can later develop into more codified art schemas (Wagner et al., 2014). Resilience seems like a primary evolutionary target, which, if improved, can have direct benefits on human survival and fitness.
Finally, the current objective for music evolution research is to devise testable hypotheses for the many theories that exist, including the SAF theory. We would like to take this opportunity to suggest a few directions such work might go to test the SAF theory. Further investigations of the similarity between how music and the voice are processed in the brain would be invaluable, especially using musical stimuli that mimic vocal cues but are ideally still ecologically valid. Additionally, it would be useful to investigate how music impacts the neural networks active during a storytelling experience, such as film or videogames. For example, does adding music to the experience increase activity in areas associated with induced emotion and mind-wandering? Overall, we hope that our theory contributes to the ongoing debate on the origins of music and that it will inspire further hypothesis-driven research on this topic.
Footnotes
Acknowledgments
We thank Huw Swanborough for their helpful comments on the manuscript. Additionally, we would like to thank the members of the Cognitive and Affective Neuroscience Laboratory at the University of Zurich for their valuable feedback and support.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung, H2020 Marie Skłodowska-Curie Actions (grant numbers: SNSF #PP00P1_157409/1 and #PP00P1_183711/1, H2020 #835682).