
Abstract
Introduction:
Artificial intelligence (AI) has demonstrated transformative potential in medical education and assessment, with large language models achieving competitive results across multiple high-stakes examinations. In this study, we evaluated the performance and inter-run reliability of 10 widely adopted large language models (LLMs) on the European Board of Hand Surgery written examination.
Methods:
Ten LLMs were assessed on the complete 300-item European Board of Hand Surgery written examination using standardized zero-shot prompting. The models included five proprietary systems (GPT-5 Pro, Claude Sonnet 4.5, Gemini 2.5 Pro, Grok-4 and ERNIE 4.5 Turbo) and five open-source architectures (DeepSeek V3.2, Qwen3 Max, Mistral Medium 3.1, Llama 3.3 and Falcon H1). Each LLM completed five independent runs, producing 15000 answers analysed for mean accuracy, 95% confidence intervals and inter-run reliability using Cohen’s kappa (κ).
Results:
Mean accuracy across the LLMs ranged from 72 to 85%, corresponding to total European Board of Hand Surgery scores between 131 and 211 points. Seven of the 10 LLMs reached or exceeded the illustrative pass threshold of 75%, equivalent to 150 of 300 points. Proprietary systems showed consistently higher mean accuracy than open-source systems. The highest-performing LLM (GPT-5 Pro) achieved 85% accuracy with a 95% confidence interval of 84 to 86% and a mean inter-run reliability measured by Cohen’s κ of 0.739. The overall reliability across the LLMs was 0.821.
Conclusions:
Contemporary LLMs show robust and reproducible performance on a complex surgical certification examination, with proprietary architectures tending to outperform open-source counterparts. Although several models reached or exceeded an illustrative pass threshold, persistent gaps in subspecialty knowledge remain such as congenital anomalies and complex reconstructions. Therefore, LLMs may assist in structured learning and examination preparation but require specialist oversight and remain unsuitable for independent subspecialty decision-making.
Level of evidence:
Not applicable.
Keywords
Introduction
Artificial intelligence (AI) has demonstrated transformative potential in medical education and assessment, with large language models (LLMs) achieving competitive results across multiple high-stakes examinations. Recent research has shown that these models can approach or even exceed human-level accuracy on written medical licensing tests such as the US Medical Licensing Examination, national board examinations, and specialty-specific assessments (Gilson et al., 2023; Gordon et al., 2024; Kung et al., 2023; Lee et al., 2021; Liu et al., 2024; Ouanes and Farhah, 2024; Takagi et al., 2023). These advances have intensified academic interest in the role of LLMs for knowledge evaluation, clinical reasoning assessment, and medical education.
The European Board of Hand Surgery (EBHS), administered by the Federation of European Societies for Surgery of the Hand, is recognized across Europe and described in international guidance and candidate reports (Calcagni, 2018; Nachemson, 2000). To date, evidence indicates modest accuracy and considerable variability among LLMs on EBHS content. In recent evaluations, ChatGPT-4o1 scored 202 points, ChatGPT-4o scored 180 points, Claude scored 174 points and Gemini scored 110 points (Mert et al., 2025; Thibaut et al., 2024; Traoré et al., 2023). These totals should be interpreted on the full EBHS scale, which ranges from −300 to +300 points. Even the best performing models leave substantial headroom relative to the maximum possible score, and several systems do not reach the pass threshold. This distribution indicates that progress has been made, but further improvements are required before LLMs can reliably cover the full breadth of subspecialty hand surgery knowledge.
Despite these promising results, methodological shortcomings in prior work limit interpretation and practical application. Many earlier studies, including both exam-focused evaluations and broader investigations into the application of AI and LLMs in clinical medicine, education and research, relied on single runs without reporting reliability, used small samples, or were conducted before the release of several 2025 architectures and more competitive open-source systems, limiting their current generalizability. Variability in prompting strategies and reporting practices may have introduced bias, and statistical safeguards such as corrections for multiple comparisons were not consistently applied, complicating between-model inference. Moreover, several investigations addressing AI reliability and performance reproducibility emphasize that systematic analyses of inter-run stability remain uncommon, leaving uncertainty about consistency under repeated testing (Bolgova et al., 2025; Gumilar et al., 2024; Hager et al., 2024; Jung et al., 2023; Lai et al., 2024; Liu et al., 2020; Meskó, 2023; Tam et al., 2024; Wei et al., 2024; Windisch et al., 2024).
To address these gaps, we performed a standardized, multi-model evaluation of 10 contemporary LLMs on the complete 300-statement EBHS written examination, balancing five proprietary and five open-source architectures. In this study, the EBHS Exam is not treated as an examination goal in itself but rather as a controlled-stress test of subspecialty hand-surgery knowledge. By systematically challenging LLMs with standardized, high-stakes content, this format enables identification of clinically relevant failure patterns that may translate into real-world misuse of AI systems in surgical education and informal clinical decision support.
Material and methods
Study design
This cross-sectional evaluation assessed the performance of 10 contemporary LLMs on the complete EBHS written examination. Data collection was conducted between October and November 2025. Each model underwent five independent runs across all 300 examination statements, yielding 50 total evaluation sessions and 15,000 individual responses. This multi-run design enabled statistical inference through estimation of inter-run reliability, pairwise performance comparisons and effect size calculation.
A standardized zero-shot evaluation was used to assess pre-trained medical knowledge and to ensure fair comparison across architectures. All procedures were transparently documented to reflect realistic web-interface access, representing how most users interact with these systems. The study followed current best practices for medical AI evaluation and adhered to CONSORT-AI reporting standards (Liu et al., 2020; Rivera et al., 2020; Zaghir et al., 2024).
The study did not involve human participants, patient data or identifiable information; therefore, institutional review board approval was not required.
LLM selection
Ten LLMs were selected to represent a balanced spectrum of proprietary (privately owned and controlled by specific companies) and open-source architectures, geographic origins and parameter scales.
Proprietary models (n = 5)
GPT-5 Pro (OpenAI, USA), Claude Sonnet 4.5 (Anthropic, USA), Gemini 2.5 Pro (Google, USA), Grok-4 (xAI, USA), and ERNIE 4.5 Turbo (Baidu, China).
Open-source models (n = 5)
DeepSeek V3.2 (DeepSeek AI, China), Qwen3 Max (Alibaba Cloud, China), Mistral Medium 3.1 (Mistral AI, France), Llama 3.3 (Meta, USA), and Falcon H1 (Technology Innovation Institute, UAE).
Although the Mistral Medium 3.1 model is a proprietary, hosted system, it originated with a developer whose flagship architectures are open source. To maintain group balance and acknowledge this lineage, the Mistral Medium 3.1 model was classified within the open-source category.
All systems were accessed exclusively through publicly available web interfaces rather than application programming interfaces (APIs), reflecting the predominant interaction patterns of clinical and educational end users. Model versions and timestamps were documented for every evaluation session.
EBHS examination format
The EBHS written examination comprises 60 multiple-choice questions, each containing five independent true/false statements (300 total binary decisions). The exam covers trauma, nerve surgery, congenital anomalies, microsurgery, degenerative conditions and reconstructive procedures, as described in published reports of the EBHS Examination Committee. A negative-marking scheme applies: +1 for correct, −1 for incorrect and 0 for no answer. Scores range from −300 to +300 points (Calcagni, 2013; Federation of European Societies for Surgery of the Hand; Muir et al., 2018; Siala et al., 2023).
Prior guidance therefore commonly refers to a practical target of 150 points (50% of the maximum) for candidates (Mert et al., 2025). Owing to the +1/−1 scoring, a raw score of 150 points corresponds to 75% accuracy on the 300 items (score = (2 × accuracy − 1) × 300 and accuracy = (score/300 + 1)/2). We therefore report model performance both as a percentage accuracy and as equivalent EBHS points, and we adopt 75% accuracy (150/300 points) as the illustrative pass threshold for this study.
Prompt engineering methodology
All evaluations used an identical zero-shot prompt across models and runs to assess pre-trained medical knowledge and to minimize elicitation bias. The prompt followed the CO-STAR structure (Context, Objective, Style, Tone, Audience, Response format) to specify task parameters and required concise true/false answers without explanations or hedging. Models were instructed to answer every question and to judge each statement as true or false. The same prompt was used for all sessions. This standardized procedure improved reproducibility and reduced potential confounding from interface behavior or transient model updates, although such sources of variability cannot be fully excluded (Kuerbanjiang et al., 2025; Zaghir et al., 2024).
Data collection protocol
Data collection took place between October and November 2025 under strict session-independence protocols to ensure the statistical validity of reliability analyses. Each of the 10 models completed five independent runs across all 300 examination statements, yielding 50 sessions and 15,000 binary observations.
Session independence was maintained by starting each run in a new browser session or incognito window, clearing all previous chat history and creating a fresh conversation for every evaluation. Model order was randomized across runs, and timestamps and exact model versions were documented for each session. Data capture involved manual transcription of model outputs from the web-based chat interfaces. Double data entry was performed independently by two researchers.
Models accessed examination content through standardized web chat interfaces rather than APIs, reflecting typical end-user interaction patterns in clinical and educational contexts. Responses were recorded as binary outcomes (1 = correct, 0 = incorrect) based on comparison with the official EBHS answer key. Quality control procedures included verification of response completeness, documentation of any model refusals or formatting inconsistencies, and automated flagging of discrepancies for review.
Statistical analysis
Statistical analyses were performed in R. A significance threshold of α = 0.0011 was applied to control the family-wise error rate after Bonferroni correction for the 45 pairwise model comparisons. Primary outcomes were: (1) mean accuracy per model with 95% confidence intervals computed by the Wilson score method (Wilson, 1927); (2) inter-run reliability quantified by Cohen’s κ with interpretation according to Landis and Koch (Landis and Koch, 1977); and (3) pairwise comparisons between models using McNemar’s test for correlated proportions (McNemar, 1947). Cohen’s κ was selected for inter-run reliability because the data consisted of binary, item-level decisions, and the primary objective was to assess agreement in responses to identical examination statements rather than stability of aggregated summary scores. Effect sizes were reported as odds ratios with 95% confidence intervals.
For each model, all pairwise κ values across the five runs were calculated (10 combinations per model), yielding 100 coefficients in total; the mean κ per model summarized overall inter-run reliability. McNemar’s test compared paired responses across the 300 items for each model pair, with exact methods applied when appropriate. All analyses followed predefined protocols and were documented with software and package versions (Gamer et al., 2019; Pocock et al., 2002; Signorell, 2025).
Results
Overall model performance
Performance differed among the evaluated systems, with proprietary architectures reaching the higher end results. GPT-5 Pro was the leading model, followed by Gemini 2.5 Pro and Grok-4, while several open-source models approached or, in some cases, reached the adopted passing level. Overall, most systems demonstrated solid baseline competence on the EBHS examination, and the majority reached performance levels compatible with meaningful educational use. Proprietary models generally outperformed open-source architectures, although individual exceptions were observed (Table 1, Figure 1).
Performance of large language models on the EBHS examination.
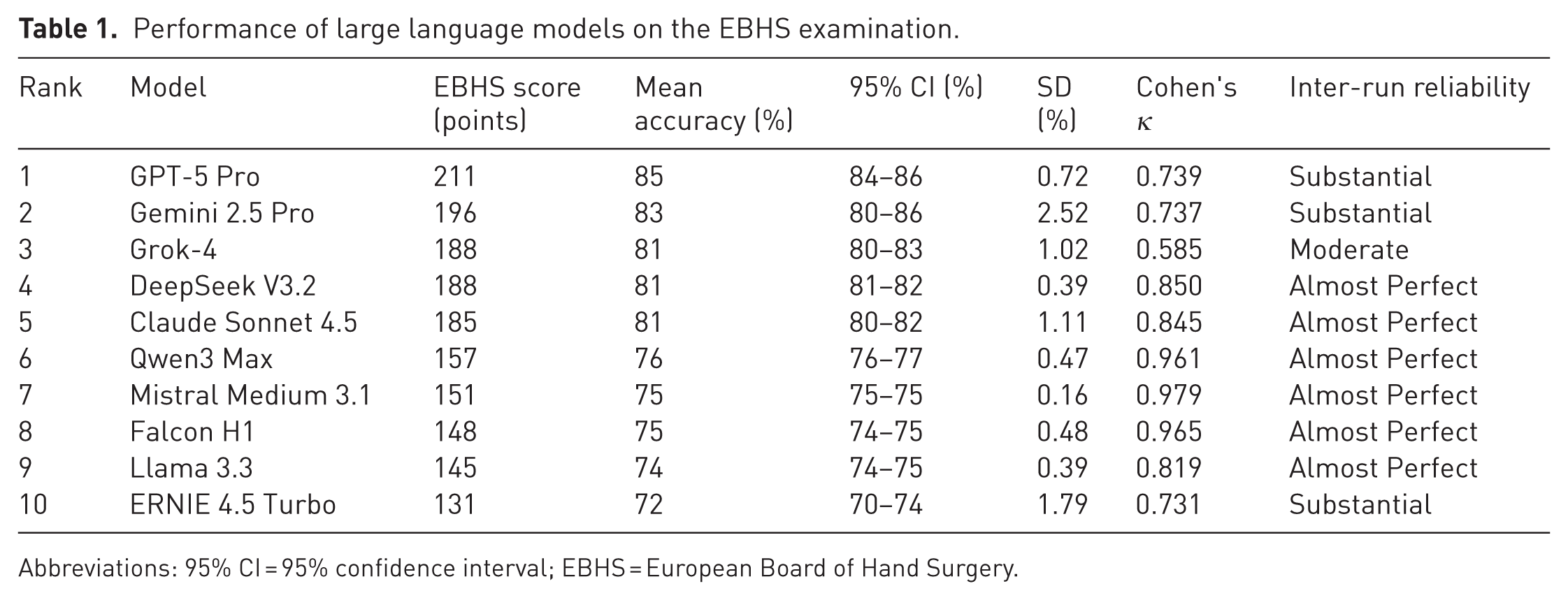
Abbreviations: 95% CI = 95% confidence interval; EBHS = European Board of Hand Surgery.
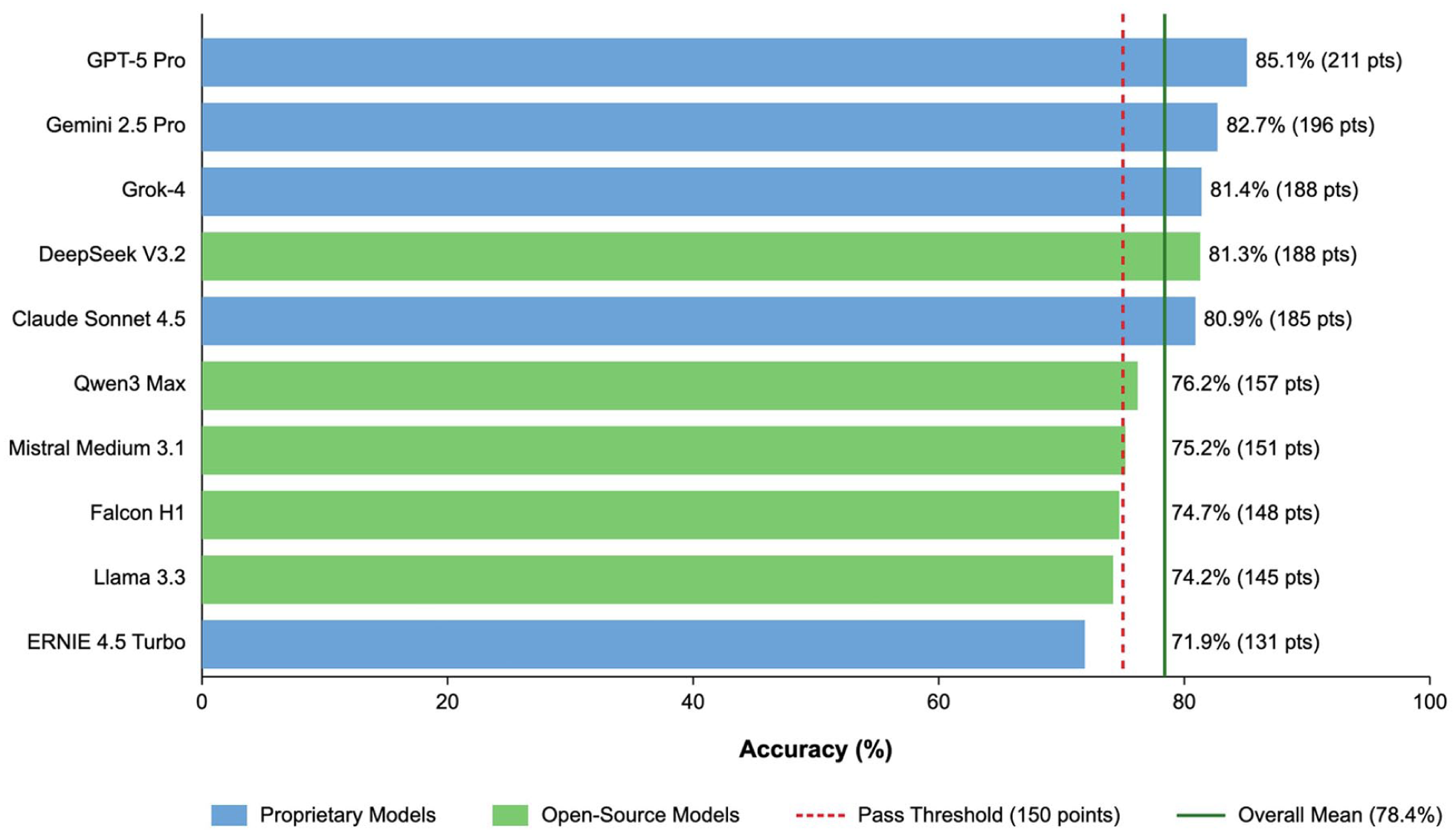
Overall model performance by AI models: mean accuracy (%) and EBHS scoring system (points). Note: mean accuracy (%) for each evaluated model with corresponding EBHS points in parentheses. The red dashed vertical line indicates the illustrative pass threshold used in this study (75% accuracy, equivalent to 150/300 EBHS points). The green vertical line indicates the overall mean accuracy across all models (78 %). Proprietary models are shown in blue and open-source models in green. Abbreviations: AI = artificial intelligence; EBHS = European Board of Hand Surgery; LLM = large language model.
Inter-run reliability
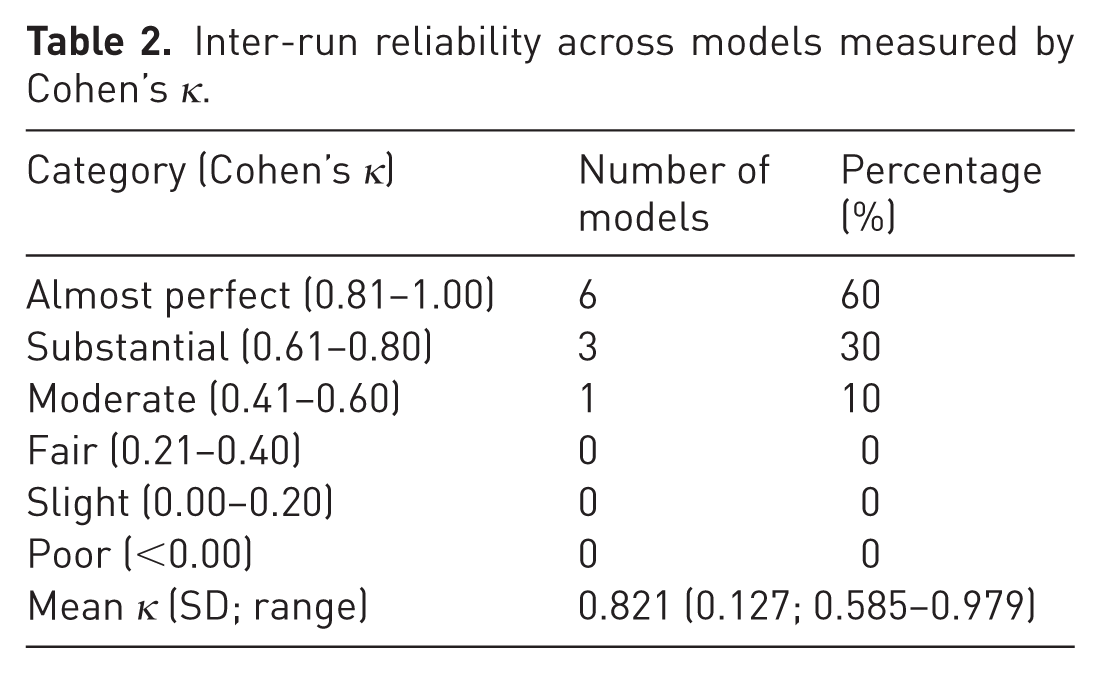
Inter-run reliability was consistently high across the evaluated systems. Most models demonstrated agreement levels consistent with the upper interpretive categories, indicating that repeated evaluations under identical conditions produced stable, reproducible outputs. Only a small minority showed lower but still acceptable consistency. These patterns show that model performance is not driven by stochastic variability alone but reflects stable internal representations of factual knowledge across independent runs (Table 2, Figures 2 and 3).
Inter-run reliability across models measured by Cohen’s κ.
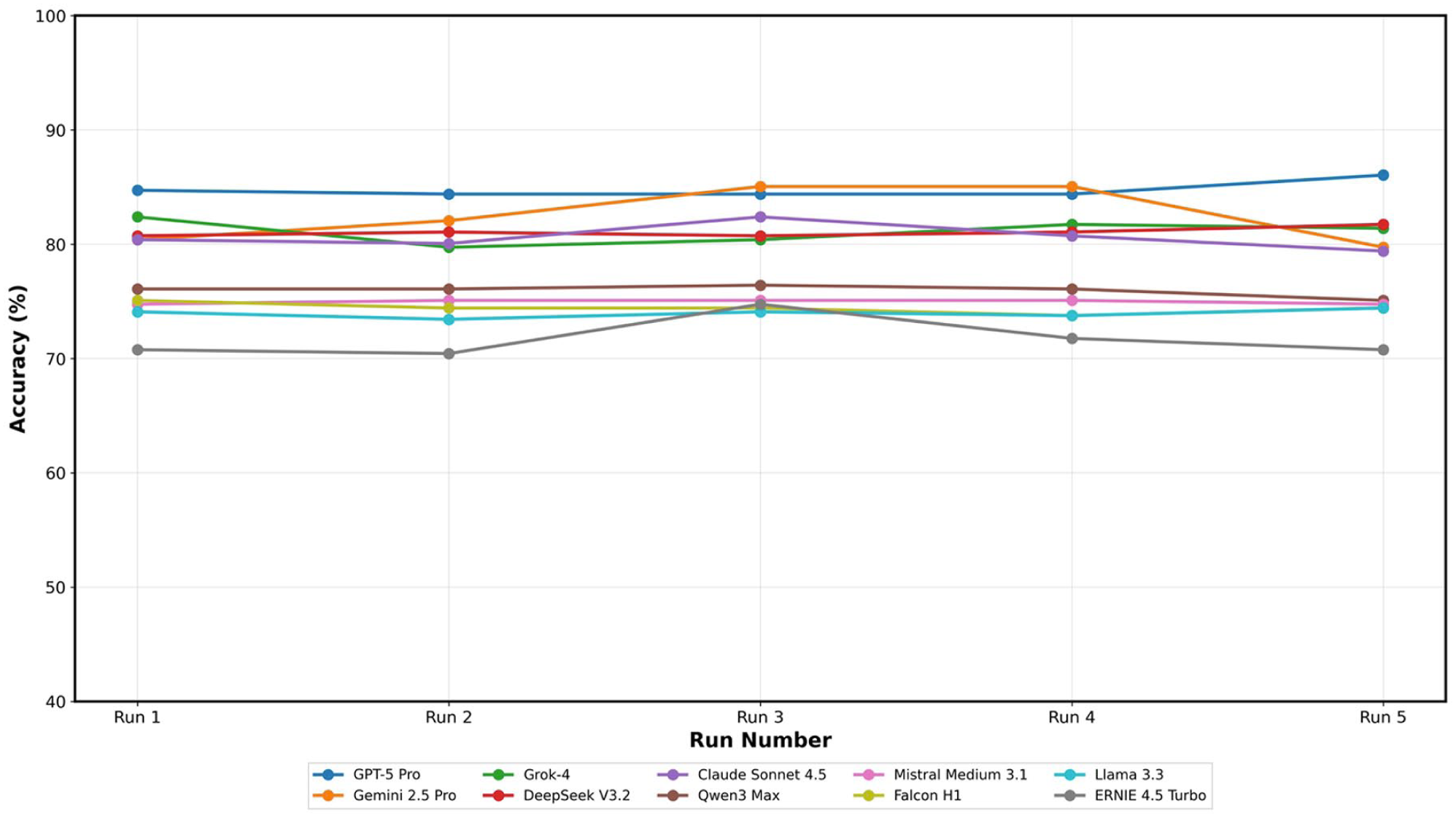
Inter-run consistency across AI models: individual run accuracy for five independent evaluations. Note: Line plot showing model accuracy (%) across five independent evaluation runs. Each coloured line represents one model and markers indicate run-level mean accuracy. The grey dashed horizontal line denotes the illustrative pass threshold (75%). Abbreviations: AI = artificial intelligence.
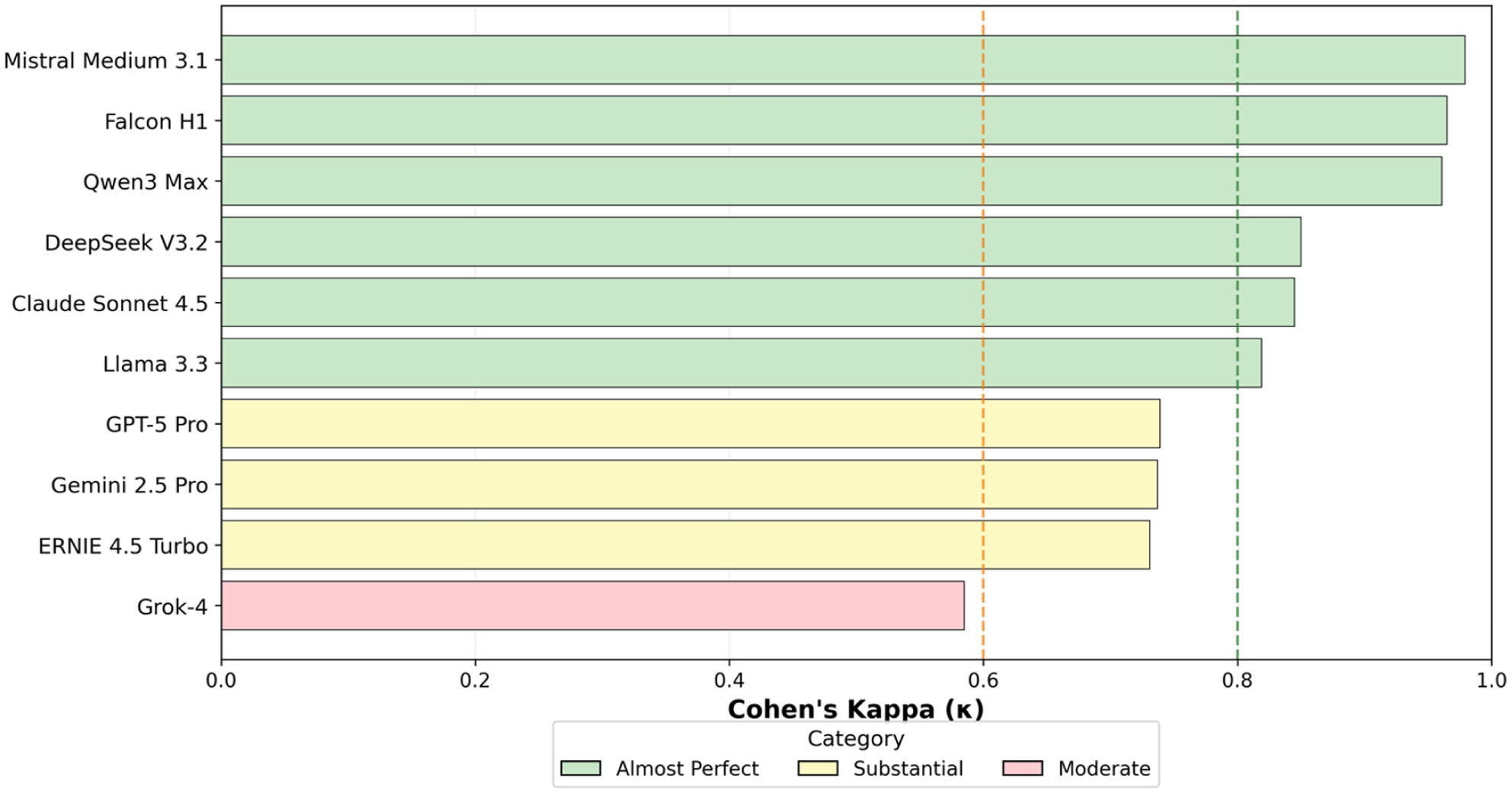
Inter-run reliability (Cohen’s κ): agreement between runs for each AI model. Note: Line plot of model-wise Cohen’s kappa coefficients. Dashed vertical lines indicate Landis and Koch interpretation thresholds (κ ≥ 0.81 ‘almost perfect’; κ ≥ 0.61 ‘substantial’). Corresponding summary values are listed in Table 2 (Landis and Koch, 1977).
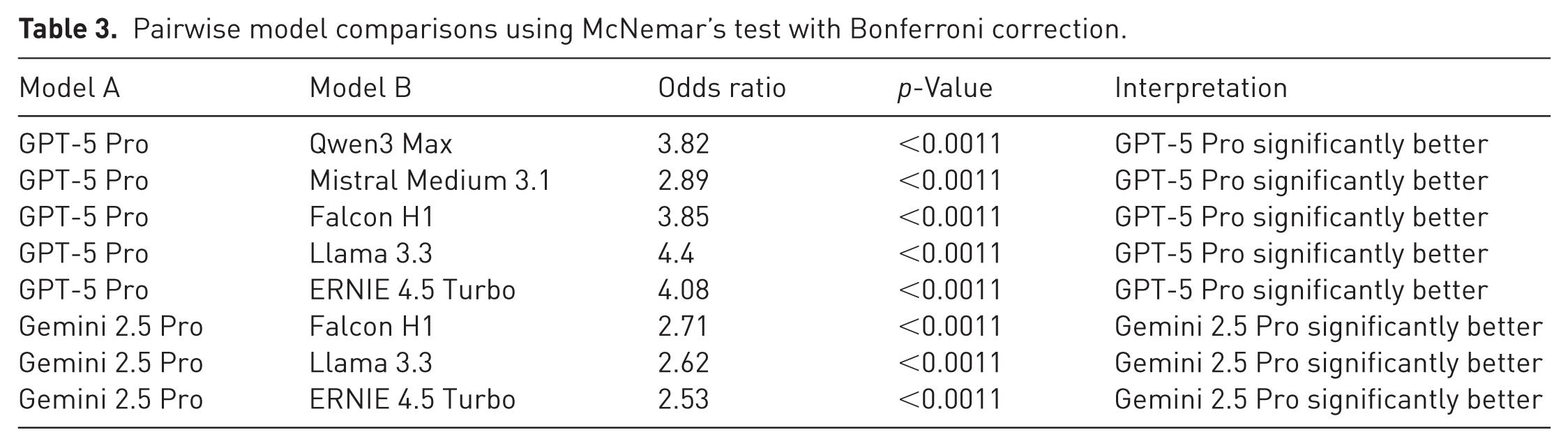
A clear performance hierarchy was apparent across the full spectrum of evaluated systems, with proprietary models forming the leading tier and open-source architectures generally occupying lower ranks. Pairwise comparisons identified a limited number of statistically significant differences, most of which favoured the highest-performing proprietary systems. Overall, these comparisons reflect a stable ranking structure among models, even though the absolute gaps between systems were moderate and do not limit the potential educational use of several mid-tier architectures (Table 3).
Pairwise model comparisons using McNemar’s test with Bonferroni correction.
Question difficulty analysis
Most examination statements were classified as easy based on aggregated model performance, with a smaller proportion requiring intermediate levels of reasoning. Easy items primarily covered fundamental anatomical relationships, straightforward clinical presentations and well-established treatment principles. Medium items typically required nuanced diagnostic distinctions, the selection of appropriate techniques for complex scenarios or the interpretation of ambiguous clinical findings. Hard items were concentrated in specialized domains, including rare congenital anomalies, controversial management strategies, subtle biomechanical principles and questions requiring integration of multiple knowledge domains.
A small subset of questions consistently produced incorrect responses across most or all models, suggesting persistent knowledge gaps shared among architectures. These challenging items frequently involved European-specific practice patterns differing from North American conventions, historical terminology and eponyms, or detailed numerical data from specialized surgical techniques. Overall, the distribution demonstrates broad competency in fundamental hand-surgery knowledge while highlighting ongoing limitations in subspecialty depth and regional practice variability.
Discussion
This evaluation of 10 contemporary LLMs on the EBHS diploma examination demonstrates robust baseline performance and high inter-run reliability while revealing persistent gaps in subspecialty depth and region-specific knowledge. Overall performance formed a clear ranking across the full model spectrum, with proprietary systems occupying the leading tier and most open-source architectures following at lower ranks. Although several models reached performance levels compatible with structured educational use, a closer look reveals both reproducible errors and inconsistent responses alongside notable weaknesses on highly specialized questions. Taken together, these findings support the potential role of modern LLMs in knowledge consolidation and question validation and formative assessment while underlining the continuing necessity of specialist supervision.
Hard items clustered around rare congenital anomalies, eponyms, complex reconstructions or context-specific surgical details. Notably, these scenarios correspond to clinical situations in which non-specialists or trainees often seek AI-assisted guidance, even though the highest level of subspecialty expertise is required for safe management. A small subset of questions produced incorrect responses across nearly all models, indicating systematic knowledge gaps shared among architectures. These items often reflected European-specific practice patterns, historical terminology or detailed numerical data that are underrepresented in mainstream training corpora. Given that most leading LLMs are trained predominantly on English-language, US-centred data sources, limited exposure to European guidelines and examination standards is likely. For a European subspecialty community, this limitation is particularly relevant and warrants cautious interpretation of LLM-generated outputs in region-specific clinical contexts. The observed distribution therefore reflects broad competence in fundamental hand-surgery knowledge and incomplete coverage of regional, historical and culturally contextual material (Celi et al., 2022; Choi et al., 2025; Schmallenbach et al., 2024). European hand surgeons may therefore need to interpret AI-generated advice with caution when addressing questions governed by European standards or regional practice variations. For candidates preparing for the EBHS examination, this analysis identifies specific topic areas where current LLMs are unreliable.
Across models, responses were frequently reproducible across runs, which may convey a perception of reliability even when subspecialty depth is insufficient. The clinical risk lies less in overtly incorrect answers than in convincingly selected responses that are incomplete or contextually inappropriate. In highly specialized fields such as hand surgery, where decision-making often depends on nuanced anatomical, reconstructive or region-specific considerations, systematic errors may lead to false reassurance rather than error detection, especially in situations where national practice standards differ.
These findings support the view that LLMs should be regarded strictly as decision-support systems rather than autonomous decision authorities. In light of the knowledge gaps identified in this study, the present data underscore that AI-generated outputs require continued specialist oversight and critical appraisal rather than uncritical acceptance.
From an educational perspective, these findings warrant a cautious interpretation of the role of LLMs in hand surgery training. While models with stable behaviour may be used in supervised settings to generate formative question variants or structured self-assessments, their observed performance also exposes important limitations that directly affect learning processes. In the context of postgraduate training, these performance patterns raise concerns regarding knowledge calibration. High accuracy on fundamental concepts combined with systematic deficits in subspecialty depth may lead trainees to overestimate both model reliability and their own level of understanding. This miscalibration represents a subtle but clinically relevant risk, particularly when LLMs are perceived as surrogate supervisors rather than supplementary learning tools. The increasing use of LLMs for clinical documentation, including operative reports, discharge summaries and educational materials, introduces additional medico-legal considerations. Our findings underscore the need for cautious integration of such systems into surgical workflows and for continued expert review of AI-assisted outputs before clinical use or official documentation.
Limitations should be acknowledged. Evaluation through web interfaces may introduce small differences compared with API use but better reflects real-world access. Results represent a single time point and model behaviour may change with subsequent updates. Model versioning remains an important source of variability because provider-side updates can alter accuracy, calibration or response style without explicit disclosure, which limits longitudinal comparability. The Federation of European Societies for Surgery of the Hand did not publish the EBHS items and no model fine-tuning on exam material was performed. However, the possibility that some statements or closely related content appear in public training datasets cannot be entirely ruled out.
Finally, the EBHS examination, while comprehensive in hand surgery, may not generalize to other specialties or to multimodal question formats. Generalization to domains with different curricular structures, imaging-heavy assessments or open-ended tasks is therefore uncertain, and dedicated evaluations across diverse specialties will be required to determine broader applicability.
Future research directions could examine how augmenting LLMs with targeted textbook corpora or curated subspecialty databases affects performance on board-style examinations. Retrieval-augmented generation using authoritative subspecialty resources could address remaining knowledge gaps. Prospective educational trials could measure the real-world impact of AI-assisted learning on trainee performance and confidence calibration. An alternative experimental approach could allow models to abstain from answering when internal uncertainty exceeds a predefined threshold, enabling assessment of confidence calibration. Ideally, future studies could administer a new EBHS examination simultaneously to human candidates and multiple LLMs on the day of the exam, allowing direct comparison under identical conditions before any test content enters public training datasets.
In conclusion, contemporary LLMs demonstrate reliable, reproducible performance on a structured, specialty-focused written examination, but exhibit persistent limitations in depth and region-specific knowledge. Apparent competence on foundational medical knowledge may conceal pronounced deficits in subspecialty knowledge, which risks fostering uncritical reliance during training and everyday clinical practice.
Footnotes
Acknowledgements
We thank the EBHS Examination Board for providing access to the complete written examination, for their collaboration during the project, and for granting formal approval for publication of the final manuscript. The project was conducted in coordination with its responsible members.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Ethical approval
Ethical approval was not sought for the present study because the study did not involve human participants, patient data or identifiable information.
Informed consent
Not applicable – this study did not involve human participants.
AI statement
Generative AI (ChatGPT 5 Pro) was used for language editing.
Data availability
The datasets generated during the current study are available from the corresponding author upon request.